Questa architettura di riferimento illustra come eseguire il training di un modello di raccomandazione usando Azure Databricks e quindi distribuire il modello come API usando Azure Cosmos DB, Azure Machine Learning e servizio Azure Kubernetes (AKS). Per un'implementazione di riferimento di questa architettura, vedere Creazione di un'API di raccomandazione in tempo reale in GitHub.
Architettura
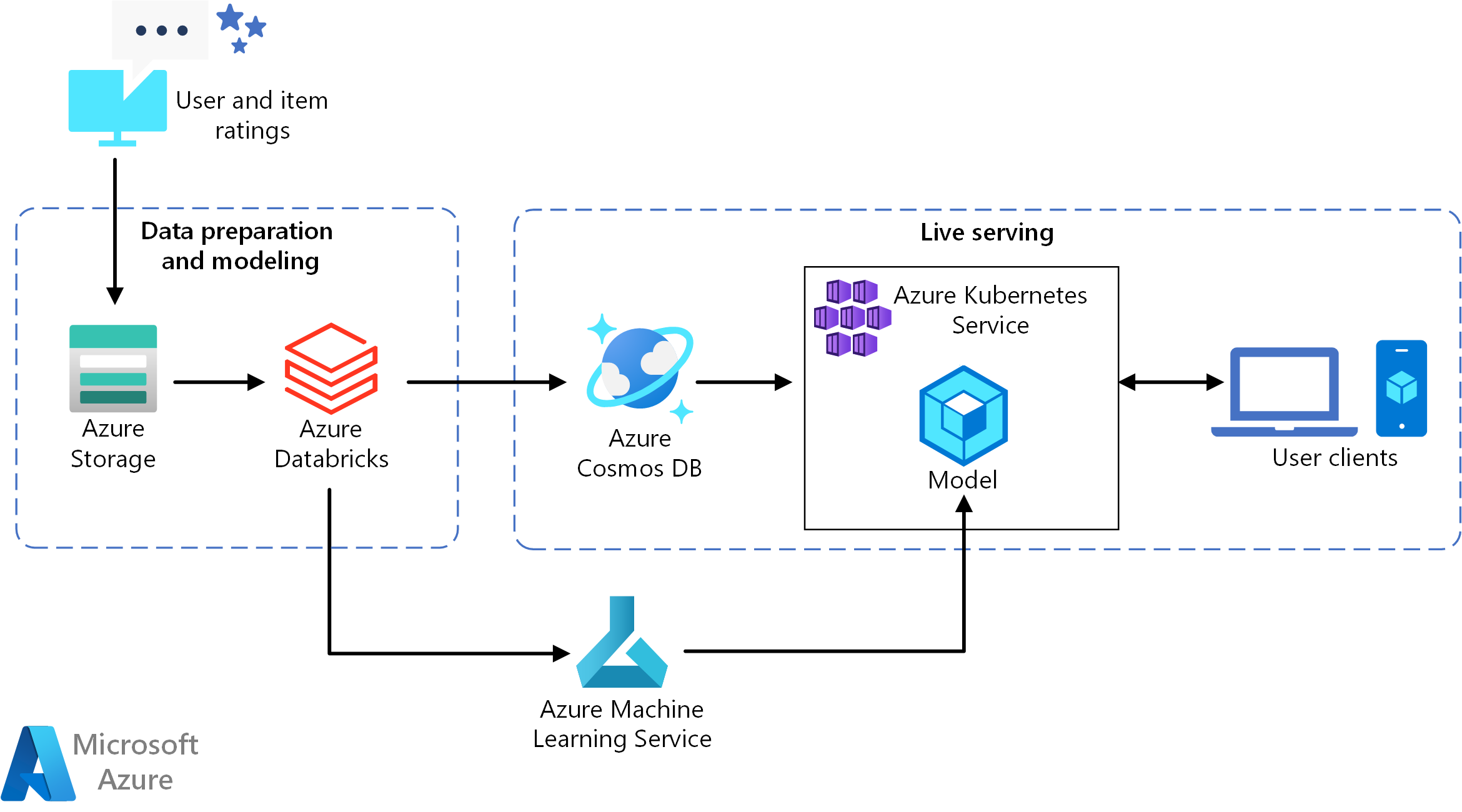
Scaricare un file di Visio di questa architettura.
Questa architettura di riferimento è destinata al training e alla distribuzione di un'API del servizio di raccomandazione in tempo reale che può fornire le prime 10 raccomandazioni sui film per un utente.
Flusso di dati
- Tenere traccia del comportamento degli utenti. Ad esempio, un servizio back-end potrebbe registrare quando un utente effettua il tasso di un film o fa clic su un prodotto o un articolo di notizie.
- Caricare i dati in Azure Databricks da un'origine dati disponibile.
- Preparare i dati e dividerli in set di training e di testing per il training del modello. (Questa guida descrive le opzioni per la suddivisione dei dati.)
- Adattare il modello di filtraggio collaborativo Spark ai dati.
- Valutare la qualità del modello con le metriche di classificazione e ranking. Questa guida fornisce informazioni dettagliate sulle metriche che è possibile usare per valutare il proprio consigliatore.
- Precalcolare le prime 10 raccomandazioni per ogni utente e archiviarle come cache in Azure Cosmos DB.
- Distribuire un servizio API nel servizio Azure Kubernetes usando le API di Machine Learning per la creazione di contenitori e la distribuzione dell'API.
- Quando il servizio back-end riceve una richiesta da un utente, chiamare l'API recommendations ospitata nel servizio Azure Kubernetes per ottenere le prime 10 raccomandazioni e visualizzarle all'utente.
Componenti
- Azure Databricks. Databricks è un ambiente di sviluppo usato per preparare i dati di input ed eseguire il training del modello del sistema di raccomandazione in un cluster Spark. Azure Databricks offre anche un'area di lavoro interattiva per eseguire e collaborare su notebook per qualsiasi attività di elaborazione dei dati o di apprendimento automatico.
- Servizio Azure Kubernetes. Il servizio Azure Kubernetes viene usato per distribuire e rendere operativa l'API del servizio del modello di Machine Learning in un cluster Kubernetes. Il servizio Azure Kubernetes ospita il modello nel contenitore, offrendo la scalabilità richiesta per soddisfare i requisiti di velocità effettiva, di gestione delle identità e degli accessi, di registrazione e di monitoraggio dell'integrità.
- Azure Cosmos DB. Azure Cosmos DB è un servizio di database distribuito a livello globale usato per archiviare i primi 10 film consigliati per ogni utente. Azure Cosmos DB è ideale per questo scenario, perché offre bassa latenza (10 ms al 99° percentile) per la lettura dei primi elementi consigliati per un determinato utente.
- Machine Learning. Questo servizio consente di tenere traccia e gestire i modelli di Machine Learning, quindi di creare un pacchetto per questi modelli e distribuirli in un ambiente del servizio Azure Kubernetes scalabile.
- Microsoft Recommenders. Questo repository open source contiene codice di utilità ed esempi per consentire agli utenti di iniziare facilmente a creare, valutare e rendere operativo un sistema di raccomandazione.
Dettagli dello scenario
Questa architettura può essere generalizzata per la maggior parte degli scenari di motore per la generazione di raccomandazioni, incluse raccomandazioni per prodotti, film e notizie.
Potenziali casi d'uso
Scenario: un'organizzazione multimediale vuole fornire suggerimenti per film o video agli utenti. Fornendo raccomandazioni personalizzate, l'organizzazione soddisfa diversi obiettivi aziendali, tra cui una maggiore frequenza click-through, un maggiore coinvolgimento sul sito Web e una maggiore soddisfazione degli utenti.
Questa soluzione è ottimizzata per il settore delle vendite al dettaglio e per i settori multimediali e di intrattenimento.
Considerazioni
Queste considerazioni implementano i pilastri di Azure Well-Architected Framework, che è un set di set di principi guida che possono essere usati per migliorare la qualità di un carico di lavoro. Per altre informazioni, vedere Framework ben progettato di Microsoft Azure.
L'assegnazione dei punteggi batch dei modelli Spark in Azure Databricks descrive un'architettura di riferimento che usa Spark e Azure Databricks per eseguire processi di assegnazione dei punteggi batch pianificati. È consigliabile usare questo approccio per generare nuove raccomandazioni.
Efficienza prestazionale
L'efficienza delle prestazioni è la capacità di dimensionare il carico di lavoro per soddisfare in modo efficiente le richieste poste dagli utenti. Per altre informazioni, vedere Panoramica dell'efficienza delle prestazioni.
Le prestazioni sono una considerazione principale per le raccomandazioni in tempo reale, perché le raccomandazioni in genere rientrano nel percorso critico di una richiesta utente nel sito Web.
La combinazione di servizio Azure Kubernetes e Azure Cosmos DB consente a questa architettura di offrire un buon punto di partenza per fornire raccomandazioni per un carico di lavoro di medie dimensioni con un overhead minimo. In un test di carico con 200 utenti simultanei, questa architettura offre raccomandazioni con una latenza mediana di circa 60 ms e una velocità effettiva di esecuzione di 180 richieste al secondo. Il testo di carico è stato eseguito sulla configurazione di distribuzione predefinita (cluster del servizio Azure Kubernetes 3x D3 v2 con 12 vCPU, 42 GB di memoria e 11.000 unità richiesta (UR) al secondo sottoposto a provisioning per Azure Cosmos DB).


Azure Cosmos DB è consigliato per la distribuzione globale e l'utilità chiavi in mano, in grado di soddisfare qualsiasi requisito per il database delle app. Per ridurre leggermente la latenza, è consigliabile usare cache di Azure per Redis anziché Azure Cosmos DB per gestire le ricerche. cache di Azure per Redis può migliorare le prestazioni dei sistemi che si basano principalmente sui dati negli archivi back-end.
Scalabilità
Se non si prevede di usare Spark o si dispone di un carico di lavoro più piccolo che non richiede la distribuzione, è consigliabile usare una data science virtual machine (DSVM) anziché Azure Databricks. Una DSVM è una macchina virtuale di Azure con framework e strumenti di Deep Learning per l'apprendimento automatico e l'analisi scientifica dei dati. Come con Azure Databricks, qualsiasi modello creato in una DSVM può essere reso operativo come servizio nel servizio Azure Kubernetes tramite Machine Learning.
Durante il training, effettuare il provisioning di un cluster Spark di dimensioni fisse maggiori in Azure Databricks o configurare la scalabilità automatica. Quando la scalabilità automatica è abilitata, Databricks monitora il carico nel cluster e aumenta e riduce le prestazioni in base alle esigenze. Effettuare il provisioning o aumentare il numero di istanze per un cluster più grande in presenza di dati di grandi dimensioni e se si vuole ridurre la quantità di tempo necessaria per le attività di preparazione dei dati o di modellazione.
Ridimensionare il cluster del servizio Azure Kubernetes in modo da soddisfare i requisiti di prestazioni e velocità effettiva. Prestare attenzione a selezionare il numero di pod ottimale per sfruttare appieno il cluster e configurare il numero di nodi del cluster adatto a soddisfare la domanda del servizio. È anche possibile impostare la scalabilità automatica in un cluster del servizio Azure Kubernetes. Per altre informazioni, vedere Distribuire un modello in un cluster servizio Azure Kubernetes.
Per gestire le prestazioni di Azure Cosmos DB, stimare il numero di letture necessarie al secondo ed effettuare il provisioning del numero di unità richiesta al secondo (velocità effettiva) necessario. Usare le procedure consigliate per partizionamento e scalabilità orizzontale.
Ottimizzazione dei costi
L'ottimizzazione dei costi riguarda l'analisi dei modi per ridurre le spese non necessarie e migliorare l'efficienza operativa. Per altre informazioni, vedere Panoramica del pilastro di ottimizzazione dei costi.
I principali elementi che generano costi in questo scenario sono:
- Le dimensioni del cluster di Azure Databricks richieste per il training.
- Le dimensioni del cluster del servizio Azure Kubernetes richieste per soddisfare i requisiti di prestazioni.
- Le UR di Azure Cosmos DB di cui viene effettuato il provisioning in modo da soddisfare i requisiti di prestazioni.
Gestire i costi di Azure Databricks con una frequenza minore di ripetizione del training e disattivando il cluster Spark quando non è in uso. I costi del servizio Azure Kubernetes e di Azure Cosmos DB sono legati alla velocità effettiva e alle prestazioni richieste per il sito e aumenteranno e diminuiranno a seconda del volume di traffico del sito.
Distribuire lo scenario
Per distribuire questa architettura, seguire le istruzioni di Azure Databricks nel documento di configurazione. Brevemente, le istruzioni richiedono:
- Creare un'area di lavoro di Azure Databricks.
- Creare un nuovo cluster con la configurazione seguente in Azure Databricks:
- Modalità cluster: Standard
- Versione del runtime di Databricks: 4.3 (include Apache Spark 2.3.1, Scala 2.11)
- Versione python: 3
- Tipo di driver: Standard_DS3_v2
- Tipo di lavoro: Standard_DS3_v2 (min e max in base alle esigenze)
- Terminazione automatica: (come richiesto)
- Configurazione di Spark: (in base alle esigenze)
- Variabili di ambiente: (in base alle esigenze)
- Creare un token di accesso personale nell'area di lavoro di Azure Databricks. Per informazioni dettagliate, vedere la documentazione sull'autenticazione di Azure Databricks.
- Clonare il repository Microsoft Recommenders in un ambiente in cui è possibile eseguire script, ad esempio il computer locale.
- Seguire le istruzioni di installazione rapida per installare le librerie pertinenti in Azure Databricks.
- Seguire le istruzioni di installazione rapida per preparare Azure Databricks per l'operazionalizzazione.
- Importare il notebook als Movie Operationalization nell'area di lavoro. Dopo aver eseguito l'accesso all'area di lavoro di Azure Databricks, eseguire le operazioni seguenti:
- Fare clic su Home sul lato sinistro dell'area di lavoro.
- Fare clic con il pulsante destro del mouse su spazi vuoti nella home directory. Selezionare Importa.
- Selezionare URL e incollare quanto segue nel campo di testo:
https://github.com/Microsoft/Recommenders/blob/main/examples/05_operationalize/als_movie_o16n.ipynb - Fare clic su Importa.
- Aprire il notebook in Azure Databricks e collegare il cluster configurato.
- Eseguire il notebook per creare le risorse di Azure necessarie per creare un'API di raccomandazione che fornisce le raccomandazioni per i primi 10 film per un determinato utente.
Collaboratori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autori principali:
- Miguel Fierro | Principal Scienziato dei dati Manager
- Nikhil Joglekar | Product Manager, algoritmi di Azure e data science
Per visualizzare i profili LinkedIn non pubblici, accedere a LinkedIn.
Passaggi successivi
- Creazione di un'API di raccomandazione in tempo reale
- Informazioni su Azure Databricks
- Servizio Azure Kubernetes
- Introduzione ad Azure Cosmos DB
- Cos'è Azure Machine Learning?