Idee per le soluzioni
Questo articolo è un'idea di soluzione. Per espandere il contenuto con altre informazioni, ad esempio potenziali casi d'uso, servizi alternativi, considerazioni sull'implementazione o indicazioni sui prezzi, inviare commenti e suggerimenti su GitHub.
Questo esempio illustra come eseguire il caricamento incrementale in una pipeline di estrazione, caricamento e trasformazione (ELT). Usa Azure Data Factory per automatizzare la pipeline ELT. La pipeline sposta in modo incrementale i dati OLTP più recenti da un database SQL Server locale in Azure Synapse. I dati transazionali vengono trasformati in un modello tabulare per l'analisi.
Architettura

Scaricare un file di Visio di questa architettura.
Questa architettura si basa su quella illustrata in Enterprise BI con Azure Synapse, ma aggiunge alcune funzionalità importanti per gli scenari di data warehousing aziendali.
- Automazione della pipeline con Data Factory.
- Caricamento incrementale.
- Integrazione di più origini dati.
- Caricamento di dati binari quali dati geospaziali e immagini.
Workflow
L'architettura è costituita dai servizi e dai componenti seguenti.
Origini dati
SQL Server locale. I dati di origine si trovano in un database di SQL Server locale. Per simulare l'ambiente locale. Come database di origine viene usato il database OLTP di esempio Wide World Importers.
Dati esterni. Uno scenario comune per i data warehouse consiste nell'integrazione di più origini dati. Questa architettura di riferimento carica un set di dati esterno che contiene la popolazione delle città per ogni anno e lo integra con i dati dal database OLTP. È possibile usare questi dati per ottenere informazioni dettagliate utili per capire ad esempio se l'incremento delle vendite in ogni area corrisponde o è superiore alla crescita della popolazione.
Inserimento e archiviazione dei dati
Archiviazione BLOB. L'archiviazione BLOB viene usata come area di gestione temporanea per i dati di origine prima di caricarli in Azure Synapse.
Azure Synapse. Azure Synapse è un sistema distribuito progettato per eseguire analisi su dati di grandi dimensioni. Supporta l'elaborazione parallela su larga scala (MPP), che può essere usata per l'esecuzione di analisi ad alte prestazioni.
Azure Data Factory. Data Factory è un servizio gestito che orchestra e automatizza lo spostamento e la trasformazione dei dati. In questa architettura coordina le diverse fasi del processo ELT.
Analisi e creazione di report
Azure Analysis Services. Analysis Services è un servizio completamente gestito che offre funzionalità di creazione di modelli di dati. Il modello semantico viene caricato in Analysis Services.
Power BI. Power BI è una suite di strumenti di analisi aziendale che consente di analizzare dati e condividere informazioni dettagliate. In questa architettura viene eseguita una query del modello semantico archiviato in Analysis Services.
Autenticazione
Microsoft Entra ID (Microsoft Entra ID) autentica gli utenti che si connettono al server Analysis Services tramite Power BI.
Data Factory può anche usare l'ID Microsoft Entra per eseguire l'autenticazione in Azure Synapse usando un'entità servizio o un'identità del servizio gestita.
Componenti
- Archiviazione BLOB di Azure
- Azure Synapse Analytics
- Azure Data Factory
- Azure Analysis Services
- Power BI
- Microsoft Entra ID
Dettagli dello scenario
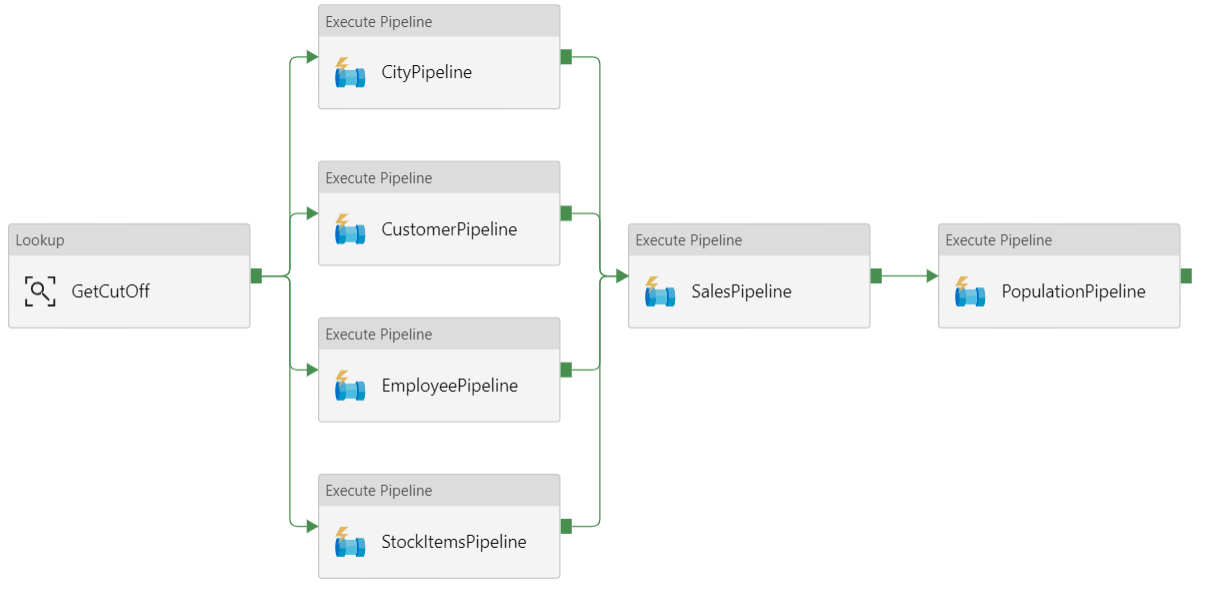
Pipeline di dati
In Azure Data Factory una pipeline è un raggruppamento logico di attività usate per coordinare un'attività, in questo caso caricando e trasformando i dati in Azure Synapse.
Questa architettura di riferimento definisce una pipeline padre che esegue una sequenza di pipeline figlio. Ogni pipeline figlio carica i dati in una o più tabelle del data warehouse.
Consigli
Caricamento incrementale
Quando si esegue un processo ETL o ELT automatizzato, risulta più efficiente caricare solo i dati modificati dopo l'esecuzione precedente. Si tratta di un caricamento incrementale, anziché di un caricamento completo che carica tutti i dati. Per eseguire un caricamento incrementale, è necessario potere identificare i dati modificati. L'approccio più comune consiste nell'usare un valore di tipo limite massimo, ovvero nel tenere traccia del valore più recente di una colonna nella tabella di origine, ad esempio una colonna di tipo data/ora o una colonna con numero intero univoco.
A partire da SQL Server 2016, è possibile usare tabelle temporali. Si tratta di tabelle con controllo delle versioni di sistema che mantengono una cronologia completa delle modifiche dei dati. Il motore di database registra automaticamente la cronologia di ogni modifica in una tabella di cronologia separata. È possibile eseguire query sui dati cronologici aggiungendo una clausola FOR SYSTEM_TIME a una query. Il motore di database esegue internamente query sulla tabella di cronologia, ma questo processo è trasparente per l'applicazione.
Nota
Per le versioni precedenti di SQL Server è possibile usare Change Data Capture (CDC). Questo approccio risulta meno efficiente rispetto alle tabelle temporali, perché è necessario eseguire query su una tabella di modifiche separata e le modifiche vengono registrate tramite un numero di sequenza di log, invece che un timestamp.
Le tabelle temporali sono utili per i dati relativi alle dimensioni, che possono cambiare nel tempo. Le tabelle dei fatti rappresentano una transazione non modificabile, ad esempio una vendita, e in questo caso la conservazione della cronologia delle versioni di sistema risulta superflua. Le transazioni includono invece in genere una colonna che rappresenta la data della transazione, che può essere usata come valore limite. Ad esempio, nel database OLTP "Wide World Importers" le tabelle Sales.Invoices e Sales.InvoiceLines includono un campo LastEditedWhen il cui valore predefinito è sysdatetime().
Ecco il flusso generale per la pipeline ELT:
Per ogni tabella del database di origine, tenere traccia del valore temporale limite relativo all'esecuzione dell'ultimo processo ELT. Archiviare tali informazioni nel data warehouse. Durante l'installazione iniziale tutti i valori temporali vengono impostati su '1-1-1900'.
Durante il passaggio di esportazione dei dati, il valore temporale limite viene passato come parametro a un set di stored procedure nel database di origine. Queste stored procedure eseguono query relative a eventuali record modificati o creati dopo il valore temporale limite. Per la tabella dei fatti Sales viene usata la colonna
LastEditedWhen. Per i dati relativi alle dimensioni vengono usate tabelle temporali con controllo delle versioni di sistema.Al termine della migrazione dei dati, aggiornare la tabella in cui sono archiviati i valori temporali limite.
È utile registrare anche una derivazione per ogni esecuzione di ELT. Per un record specifico, la derivazione associa tale record all'esecuzione di ELT che ha prodotto i dati. Per ogni esecuzione di ETL, viene creato un nuovo record di derivazione per ogni tabella, che illustra l'ora di inizio e di fine del caricamento. Le chiavi di derivazione per ogni record vengono archiviate nelle tabelle delle dimensioni e nelle tabelle dei fatti.
Dopo il caricamento di un nuovo batch di dati nel data warehouse, aggiornare il modello tabulare di Analysis Services. Vedere Aggiornamento asincrono con l'API REST.
Pulizia dei dati
È consigliabile includere la pulizia dei dati nel processo ELT. In questa architettura di riferimento un'origine di dati non validi è la tabella relativa alla popolazione delle città, in cui alcune città hanno una popolazione pari a zero, probabilmente perché non sono disponibili dati. Durante l'elaborazione, la pipeline ELT rimuove tali città dalla tabella relativa alla popolazione delle città. Eseguire la pulizia dei dati nelle tabelle di staging, invece che nelle tabelle esterne.
Origini dati esterne
I data warehouse eseguono spesso il consolidamento dei dati da più origini. Ad esempio, un'origine dati esterna che contiene dati demografici. Questo set di dati è disponibile nell'archiviazione BLOB di Azure come parte dell'esempio WorldWideImportersDW.
Azure Data Factory può copiare direttamente dall'archiviazione BLOB usando il connettore di archiviazione BLOB. Il connettore richiede tuttavia una stringa di connessione o una firma di accesso condiviso, quindi non può essere usato per copiare un BLOB con accesso in lettura pubblico. Come soluzione alternativa, è possibile usare PolyBase per creare una tabella esterna tramite l'archiviazione BLOB e quindi copiare le tabelle esterne in Azure Synapse.
Gestione di dati binari di grandi dimensioni
Nel database di origine, ad esempio, una tabella City include una colonna Location che contiene un tipo di dati spaziali geography . Azure Synapse non supporta il tipo geography in modo nativo, quindi questo campo viene convertito in un tipo varbinary durante il caricamento. Vedere Alternative per i tipi di dati non supportati.
PolyBase supporta tuttavia dimensioni massime di colonna pari a varbinary(8000), quindi è possibile che alcuni dati vengano troncati. Una soluzione alternativa per questo problema consiste nel suddividere i dati in blocchi durante l'esportazione e quindi riassemblare i blocchi, come illustrato di seguito:
Creare una tabella di staging temporanea per la colonna Location.
Per ogni città, suddividere i dati della posizione in blocchi di 8000 byte, con conseguente 1 - N righe per ogni città.
Per riassemblare i blocchi, usare l'operatore PIVOT di T-SQL per convertire le righe in colonne e quindi concatenare i valori delle colonne per ogni città.
Ogni città verrà tuttavia suddivisa in un numero diverso di righe, in base alle dimensioni dei dati geografici. Per consentire il funzionamento dell'operatore PIVOT, è necessario che ogni città abbia lo stesso numero di righe. Per eseguire questa operazione, la query T-SQL esegue alcuni trucchi per riempire le righe con valori vuoti, in modo che ogni città abbia lo stesso numero di colonne dopo il pivot. La query risultante risulta molto più veloce dell'esecuzione di cicli di una riga alla volta.
Lo stesso approccio viene usato per i dati di immagine.
Dimensioni a modifica lenta
I dati relativi alle dimensioni sono relativamente statici, ma possono cambiare. È ad esempio possibile che un prodotto venga assegnato a una categoria di prodotto diversa. Sono disponibili diversi approcci per la gestione delle dimensioni a modifica lenta. Una tecnica comune, definita Tipo 2, consiste nell'aggiungere un nuovo record ogni volta che viene modificata una dimensione.
Per implementare l'approccio Tipo 2, è necessario che le tabelle delle dimensioni includano colonne aggiuntive che specificano l'intervallo di date valide per un record specifico. Le chiavi primarie dal database di origine, inoltre, verranno duplicate, quindi la tabella delle dimensioni deve includere una chiave primaria artificiale.
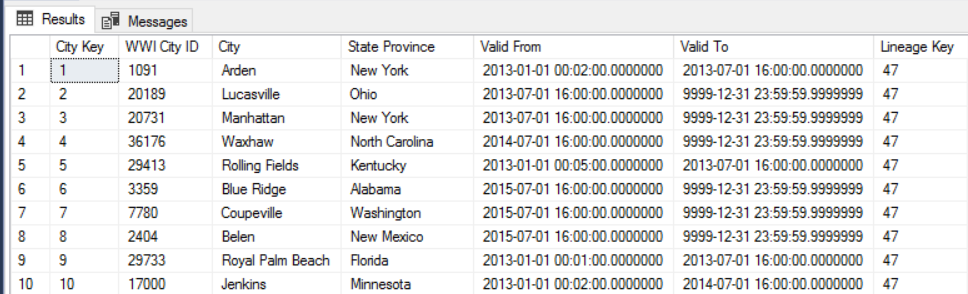
Ad esempio, l'immagine seguente mostra la tabella Dimension.City. La colonna WWI City ID è la chiave primaria dal database di origine. La colonna City Key è una chiave artificiale generata durante la pipeline ETL. Si noti anche che la tabella include le colonne Valid From e Valid To che definiscono l'intervallo di validità di ogni riga. Per i valori correnti Valid To è uguale a '9999-12-31'.
Il vantaggio di questo approccio consiste nella conservazione dei dati cronologici, che possono essere utili per l'analisi. Implica tuttavia che saranno presenti più righe per la stessa entità. Ecco ad esempio i record corrispondenti a WWI City ID = 28561:
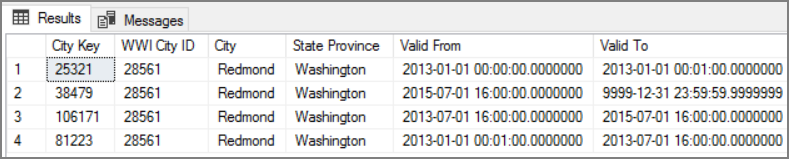
Per ogni fatto Sales si vuole associare tale fatto a una singola riga nella tabella delle dimensioni City, corrispondente alla data della fattura.
Considerazioni
Queste considerazioni implementano i pilastri di Azure Well-Architected Framework, che è un set di set di principi guida che possono essere usati per migliorare la qualità di un carico di lavoro. Per altre informazioni, vedere Framework ben progettato di Microsoft Azure.
Sicurezza
La sicurezza offre garanzie contro attacchi intenzionali e l'abuso di dati e sistemi preziosi. Per altre informazioni, vedere Panoramica del pilastro della sicurezza.
Per una sicurezza migliore, è possibile usare gli endpoint servizio di rete virtuale per proteggere le risorse dei servizi di Azure in modo che siano limitate solo alla rete virtuale specifica. In questo modo viene rimosso completamente l'accesso Internet pubblico a tali risorse, consentendo il traffico solo dalla rete virtuale specifica.
Con questo approccio è possibile creare una rete virtuale di Azure e quindi creare endpoint di servizio privati per i servizi di Azure. Questi servizi vengono quindi limitati al traffico proveniente da tale rete virtuale. È anche possibile raggiungerli dalla rete locale tramite un gateway.
Tenere presente le limitazioni seguenti:
Se gli endpoint di servizio sono abilitati per Archiviazione di Azure, PolyBase non può copiare dati da Archiviazione in Azure Synapse. È disponibile una mitigazione per questo problema. Per altre informazioni, vedere Impatto dell'uso degli endpoint di servizio di rete virtuale con Archiviazione di Azure.
Per spostare i dati dall'ambiente locale a Archiviazione di Azure, è necessario consentire gli indirizzi IP pubblici dall'istanza locale o da ExpressRoute. Per informazioni dettagliate, vedere Associazione di servizi di Azure a reti virtuali.
Per consentire ad Analysis Services di leggere i dati da Azure Synapse, distribuire una macchina virtuale Windows nella rete virtuale che contiene l'endpoint del servizio Azure Synapse. Installare il Gateway dati locale di Azure in questa VM. Connettere quindi Azure Analysis Services al gateway dati.
DevOps
Creare gruppi di risorse separati per gli ambienti di produzione, sviluppo e test. L'uso di gruppi di risorse separati semplifica la gestione delle distribuzioni, l'eliminazione delle distribuzioni di test e l'assegnazione dei diritti di accesso.
Inserire ogni carico di lavoro in un modello di distribuzione separato e archiviare le risorse nei sistemi di controllo del codice sorgente. È possibile distribuire i modelli insieme o singolarmente come parte di un processo CI/CD, semplificando il processo di automazione.
In questa architettura sono disponibili tre carichi di lavoro principali:
- Il server del data warehouse, Analysis Services e le risorse correlate.
- Azure Data Factory.
- Scenario simulato da locale a cloud.
Ogni carico di lavoro ha un proprio modello di distribuzione.
Il server del data warehouse viene configurato e configurato usando i comandi dell'interfaccia della riga di comando di Azure che seguono l'approccio imperativo della procedura IaC. Prendere in considerazione l'uso degli script di distribuzione e integrarli nel processo di automazione.
Prendere in considerazione la gestione temporanea dei carichi di lavoro. Eseguire la distribuzione in varie fasi ed eseguire controlli di convalida in ogni fase prima di passare alla fase successiva. In questo modo è possibile eseguire il push degli aggiornamenti negli ambienti di produzione in modo altamente controllato e ridurre al minimo i problemi di distribuzione imprevisti. Usare le strategie per la distribuzione blu-verde e le versioni Canary per aggiornare gli ambienti di produzione live.
Avere una buona strategia di rollback per la gestione delle distribuzioni non riuscite. Ad esempio, è possibile ridistribuire automaticamente una distribuzione precedente e corretta dalla cronologia di distribuzione. Vedere il parametro --rollback-on-error flag nell'interfaccia della riga di comando di Azure.
Monitoraggio di Azure è l'opzione consigliata per analizzare le prestazioni del data warehouse e l'intera piattaforma di analisi di Azure per un'esperienza di monitoraggio integrata. Azure Synapse Analytics offre un'esperienza di monitoraggio all'interno del portale di Azure per visualizzare informazioni dettagliate sul carico di lavoro del data warehouse. Il portale di Azure è lo strumento consigliato per il monitoraggio del data warehouse perché fornisce periodi di conservazione configurabili, avvisi, raccomandazioni e grafici e dashboard personalizzabili per metriche e log.
Per altre informazioni, vedere la sezione DevOps in Microsoft Azure Well-Architected Framework.
Ottimizzazione dei costi
L'ottimizzazione dei costi riguarda l'analisi dei modi per ridurre le spese non necessarie e migliorare l'efficienza operativa. Per altre informazioni, vedere Panoramica del pilastro di ottimizzazione dei costi.
Usare il calcolatore dei prezzi di Azure per stimare i costi. Ecco alcune considerazioni per i servizi usati in questa architettura di riferimento.
Azure Data Factory
Azure Data Factory automatizza la pipeline ELT. La pipeline sposta i dati da un database DI SQL Server locale ad Azure Synapse. I dati vengono quindi trasformati in un modello tabulare per l'analisi. Per questo scenario, i prezzi iniziano da 0,001 esecuzioni di attività al mese che includono attività, trigger e esecuzioni di debug. Questo prezzo è l'addebito di base solo per l'orchestrazione. Vengono addebitati anche i costi per le attività di esecuzione, ad esempio la copia di dati, ricerche e attività esterne. Ogni attività ha un singolo prezzo. Vengono addebitati anche i costi per le pipeline senza trigger o esecuzioni eseguite entro il mese. Tutte le attività vengono ripartite proporzionalmente al minuto e arrotondate.
Analisi dei costi di esempio
Si consideri un caso d'uso in cui sono presenti due attività di ricerca da due origini diverse. Uno richiede 1 minuto e 2 secondi (arrotondato fino a 2 minuti) e l'altro richiede 1 minuto con un tempo totale di 3 minuti. Un'attività di copia dei dati richiede 10 minuti. Un'attività stored procedure richiede 2 minuti. Totale esecuzioni di attività per 4 minuti. Il costo viene calcolato come segue:
Esecuzioni di attività: 4 * $ 0,001 = $ 0,004
Ricerche: 3 * ($ 0,005 / 60) = $ 0,00025
Stored procedure: 2 * ($ 0,00025 / 60) = $ 0,000008
Copia dei dati: 10 * ($0,25 / 60) * 4 unità di integrazione dati (DIU) = $0,167
- Costo totale per esecuzione della pipeline: $ 0,17.
- Eseguire una volta al giorno per 30 giorni: $ 5,1 mese.
- Eseguire una volta al giorno per 100 tabelle per 30 giorni: $ 510
Ogni attività ha un costo associato. Comprendere il modello di determinazione prezzi e usare il calcolatore prezzi di Azure Data Factory per ottenere una soluzione ottimizzata non solo per le prestazioni, ma anche per i costi. Gestire i costi avviando, arrestando, sospendo e ridimensionando i servizi.
Azure Synapse
Azure Synapse è ideale per carichi di lavoro intensivi con prestazioni di query più elevate e esigenze di scalabilità di calcolo. È possibile scegliere il modello con pagamento in base al consumo o usare piani riservati di un anno (risparmio del 37%) o 3 anni (risparmio del 65%).
L'archiviazione dei dati viene addebitata separatamente. Anche altri servizi, ad esempio il ripristino di emergenza e il rilevamento delle minacce, vengono addebitati separatamente.
Per altre informazioni, vedere Prezzi di Azure Synapse.
Analysis Services
I prezzi per Azure Analysis Services dipendono dal livello. L'implementazione di riferimento di questa architettura usa il livello Developer , consigliato per scenari di valutazione, sviluppo e test. Altri livelli includono il livello Basic , consigliato per ambienti di produzione di piccole dimensioni, ovvero il livello Standard per le applicazioni di produzione cruciali. Per altre informazioni, vedere Il livello corretto quando necessario.
Quando si sospende l'istanza, non vengono applicati addebiti.
Per altre informazioni, vedere Prezzi di Azure Analysis Services.
Archiviazione BLOB
Prendere in considerazione l'uso della funzionalità di capacità riservata Archiviazione di Azure per ridurre i costi per l'archiviazione. Con questo modello si ottiene uno sconto se è possibile eseguire il commit alla prenotazione per la capacità di archiviazione fissa per uno o tre anni. Per altre informazioni, vedere Ottimizzare i costi per l'archiviazione BLOB con capacità riservata.
Per altre informazioni, vedere la sezione Costo in Microsoft Azure Well-Architected Framework.
Passaggi successivi
- Introduzione ad Azure Synapse Analytics
- Introduzione ad Azure Synapse Analytics
- Introduzione al servizio Azure Data Factory
- Che cos'è Azure Data Factory?
- Esercitazioni su Azure Data Factory
Risorse correlate
Può essere utile esaminare gli scenari di esempio di Azure seguenti, che illustrano soluzioni specifiche usando alcune delle stesse tecnologie: