Flapping nella scalabilità automatica
Questo articolo descrive il flapping nella scalabilità automatica e come evitarlo.
L’instabilità fa riferimento a una condizione del ciclo che causa una serie di eventi di scalabilità opposti. Il flapping si verifica quando un evento di scalabilità attiva l'evento di scala opposto.
La scalabilità automatica valuta un'azione di ridimensionamento in sospeso per verificare se causerebbe il flapping. Nei casi in cui può verificarsi il flapping, la scalabilità automatica può ignorare l'azione di ridimensionamento e rivalutare l'esecuzione successiva, oppure la scalabilità automatica può essere ridimensionata in base al numero specificato di istanze di risorse. Il processo di valutazione della scalabilità automatica viene eseguito ogni volta che viene eseguito il motore di scalabilità automatica, ovvero ogni 30-60 secondi, a seconda del tipo di risorsa.
Per garantire risorse adeguate, il controllo del potenziale flapping non si verifica per gli eventi di scalabilità orizzontale. La scalabilità automatica rinvierà solo un evento di scalabilità orizzontale per evitare il flapping.
Si supponga, ad esempio, di assumere le regole seguenti:
- Aumentare il numero di istanze di 1 istanza quando l'utilizzo medio della CPU è superiore al 50%.
- Ridurre il numero di istanze di 1 istanza quando l'utilizzo medio della CPU è inferiore al 30%.
Nella tabella seguente in T0, quando l'utilizzo è al 56%, viene attivata un'azione di aumento del numero di istanze e si ottiene un utilizzo della CPU del 56% tra 2 istanze. In questo modo si ottiene una media del 28% per il set di scalabilità. Poiché il 28% è inferiore alla soglia di scalabilità orizzontale, la scalabilità automatica dovrebbe ridurre le prestazioni. La diminuzione del numero di istanze restituirà il set di scalabilità al 56% dell'utilizzo della CPU, che attiva un'azione di aumento del numero di istanze.
| Time | Numero di istanze | Contoso | % CPU per istanza | Evento di scalabilità | Numero di istanze risultanti |
|---|---|---|---|---|---|
| T0 | 1 | 56% | 56% | Aumentare il numero di istanze | 2 |
| T1 | 2 | 56% | 28% | Riduci numero istanze | 1 |
| T2 | 1 | 56% | 56% | Aumentare il numero di istanze | 2 |
| T3 | 2 | 56% | 28% | Riduci numero istanze | 1 |
Se lasciato incontrollato, ci sarebbe una serie continuativa di eventi di scalabilità. Tuttavia, in questa situazione, il motore di scalabilità automatica posticiperà l'evento di scalabilità orizzontale in T1 e lo rivaluterà durante l'esecuzione successiva della scalabilità automatica. Il ridimensionamento avverrà solo una volta che l'utilizzo medio della CPU è inferiore al 30%.
Il flapping è spesso causato da:
- Margini piccoli o nulli tra le soglie
- Ridimensionamento in base a più istanze
- Aumento e riduzione delle prestazioni con metriche diverse
Margini piccoli o nulli tra le soglie
Per evitare il flapping, mantenere margini adeguati tra le soglie di ridimensionamento.
Ad esempio, le regole seguenti in cui non esiste alcun margine tra le soglie, causano il flapping.
- Aumentare il numero di istanze quando il numero di thread >=600
- Aumentare le prestazioni quando il numero di thread è < 600
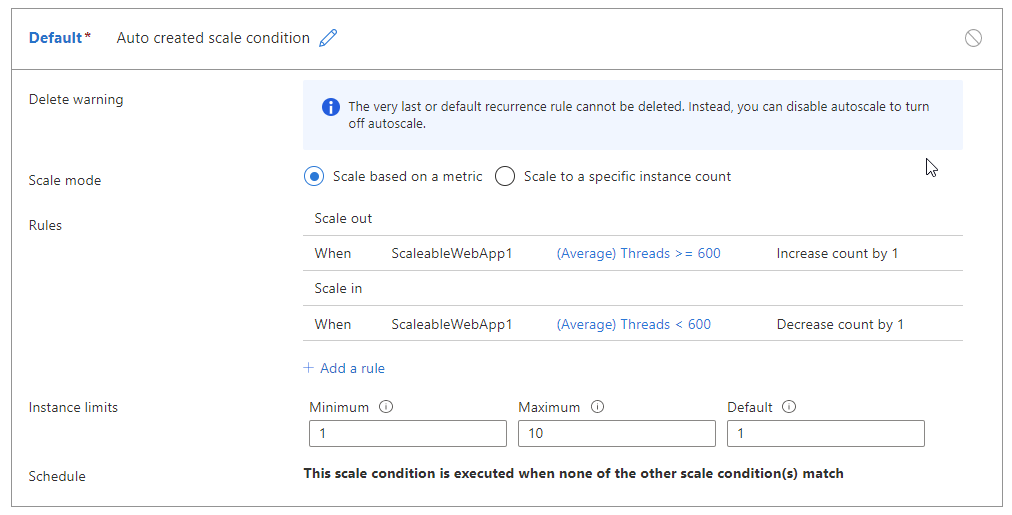
La tabella seguente illustra un potenziale risultato di queste regole di scalabilità automatica:
| Time | Numero di istanze | Conteggio thread | Numero di thread per istanza | Evento di scalabilità | Numero di istanze risultanti |
|---|---|---|---|---|---|
| T0 | 2 | 1250 | 625 | Aumentare il numero di istanze | 3 |
| T1 | 3 | 1250 | 417 | Riduci numero istanze | 2 |
- Al momento T0, sono presenti due istanze che gestiscono 1250 thread o 625 tapis per istanza. La scalabilità automatica aumenta fino a tre istanze.
- Dopo il ridimensionamento orizzontale, in T1, sono presenti gli stessi 1250 thread, ma con tre istanze, solo 417 thread per istanza. Viene attivato un evento di scalabilità orizzontale.
- Prima del ridimensionamento, la scalabilità automatica valuta cosa accadrebbe se si verificasse l'evento di scalabilità orizzontale. In questo esempio, 1250 / 2 = 625, ovvero 625 thread per istanza. La scalabilità automatica deve aumentare immediatamente le istanze dopo il ridimensionamento. Se è stato nuovamente ridimensionato, il processo viene ripetuto, causando un ciclo di instabilità.
- Per evitare questa situazione, la scalabilità automatica non viene ridimensionata. La scalabilità automatica ignora l'evento di scalabilità corrente e rivaluta la regola nel ciclo di esecuzione successivo.
In questo caso, sembra che la scalabilità automatica non funzioni perché non viene eseguito alcun evento di scalabilità. Controllare la scheda Cronologia di esecuzione nella pagina delle impostazioni di scalabilità automatica per verificare se è presente un instabilità.

L'impostazione di un margine adeguato tra le soglie evita lo scenario precedente. ad esempio:
- Aumentare il numero di istanze quando il numero di thread >=600
- Aumentare le prestazioni quando il numero di thread è < 400

Se il numero di thread con scalabilità orizzontale è 400, il numero totale di thread dovrebbe scendere al di sotto di 1200 prima che venga eseguito un evento di scala. Vedere la tabella riportata di seguito.
| Time | Numero di istanze | Conteggio thread | Numero di thread per istanza | Evento di scalabilità | Numero di istanze risultanti |
|---|---|---|---|---|---|
| T0 | 2 | 1250 | 625 | Aumentare il numero di istanze | 3 |
| T1 | 3 | 1250 | 417 | nessun evento di scalabilità | 3 |
| T2 | 3 | 1180 | 394 | ridurre il numero di istanze | 2 |
| T3 | 3 | 1180 | 590 | nessun evento di scalabilità | 2 |
Ridimensionamento in base a più istanze
Per evitare il flapping durante il ridimensionamento verticale o orizzontale di più istanze di più istanze, la scalabilità automatica può essere ridimensionata in base al numero di istanze specificate nella regola.
Ad esempio, le regole seguenti possono causare il flapping:
- Aumentare il numero di istanze di 20 quando il numero di richieste >=200 per istanza.
- OPPURE quando la CPU > 70% per istanza.
- Scalare in base a 10 quando il numero di richieste <=50 per istanza.
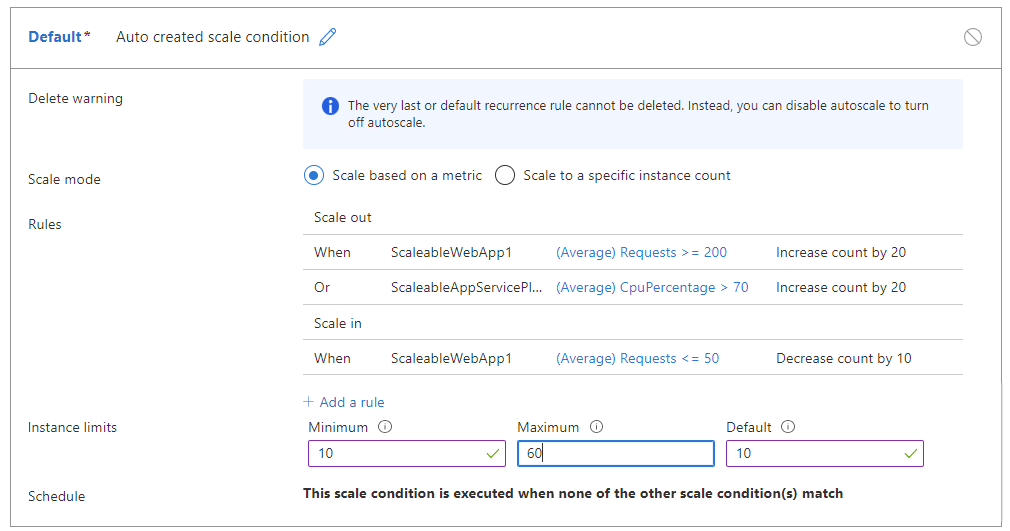
La tabella seguente illustra un potenziale risultato di queste regole di scalabilità automatica:
| Time | Numero di istanze | CPU | Conteggio richieste | Evento di scalabilità | Istanze risultanti | Commenti |
|---|---|---|---|---|---|---|
| T0 | 30 | 65% | 3000 o 100 per istanza. | Nessun evento di scalabilità | 30 | |
| T1 | 30 | 65 | 1500 | Ridimensionare in base a 3 istanze | 27 | Il ridimensionamento di 10 causerebbe un aumento stimato della CPU superiore al 70%, causando un evento di scalabilità orizzontale. |
Al momento T0, l'app è in esecuzione con 30 istanze, un numero totale di richieste pari a 3000 e un utilizzo della CPU del 65% per istanza.
In T1, quando il conteggio delle richieste scende a 1500 richieste o 50 richieste per istanza, la scalabilità automatica tenterà di ridimensionare di 10 istanze a 20. Tuttavia, la scalabilità automatica stima che il carico della CPU per 20 istanze sarà superiore al 70%, causando un evento di scalabilità orizzontale.
Per evitare il flapping, il motore di scalabilità automatica stima l'utilizzo della CPU per i conteggi delle istanze superiori a 20 fino a quando non trova un numero di istanze in cui tutte le metriche sono incluse nelle soglie definite:
- Mantenere la CPU inferiore al 70%.
- Mantenere il numero di richieste per istanza superiore a 50.
- Ridurre il numero di istanze inferiori a 30.
In questo caso, la scalabilità automatica può essere ridimensionata di 3, da 30 a 27 istanze per soddisfare le regole, anche se la regola specifica una diminuzione di 10. Un messaggio di log viene scritto nel log attività con una descrizione che include La riduzione del numero di istanze verrà eseguito con il numero di istanze aggiornato per evitare il flapping
Se la scalabilità automatica non riesce a trovare un numero appropriato di istanze, ignora la scalabilità nell'evento e rivaluta durante il ciclo successivo.
Nota
Se il motore di scalabilità automatica rileva che l'instabilità può verificarsi in seguito al ridimensionamento al numero di istanze di destinazione, tenterà anche di ridimensionare fino a un numero inferiore di istanze tra il conteggio corrente e il conteggio di destinazione. Se l'instabilità non si verifica all'interno di questo intervallo, la scalabilità automatica continuerà l'operazione di scalabilità con la nuova destinazione.
File di registro
Trovare il contrassegno nel log attività con la query seguente:
// Activity log, CategoryValue: Autoscale
// Lists latest Autoscale operations from the activity log, with OperationNameValue =="Microsoft.Insights/AutoscaleSettings/Flapping/Action
AzureActivity
|where CategoryValue =="Autoscale" and OperationNameValue =="Microsoft.Insights/AutoscaleSettings/Flapping/Action"
|sort by TimeGenerated desc
Di seguito è riportato un esempio di record del log attività per il flapping:

{
"eventCategory": "Autoscale",
"eventName": "FlappingOccurred",
"operationId": "1111bbbb-22cc-dddd-ee33-ffffff444444",
"eventProperties":
"{"Description":"Scale down will occur with updated instance count to avoid flapping.
Resource: '/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourcegroups/ed-rg-001/providers/Microsoft.Web/serverFarms/ScaleableAppServicePlan'.
Current instance count: '6',
Intended new instance count: '1'.
Actual new instance count: '4'",
"ResourceName":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourcegroups/rg-001/providers/Microsoft.Web/serverFarms/ScaleableAppServicePlan",
"OldInstancesCount":6,
"NewInstancesCount":4,
"ActiveAutoscaleProfile":{"Name":"Auto created scale condition",
"Capacity":{"Minimum":"1","Maximum":"30","Default":"1"},
"Rules":[{"MetricTrigger":{"Name":"Requests","Namespace":"microsoft.web/sites","Resource":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1","ResourceLocation":"West Central US","TimeGrain":"PT1M","Statistic":"Average","TimeWindow":"PT1M","TimeAggregation":"Maximum","Operator":"GreaterThanOrEqual","Threshold":3.0,"Source":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/ed-rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1","MetricType":"MDM","Dimensions":[],"DividePerInstance":true},"ScaleAction":{"Direction":"Increase","Type":"ChangeCount","Value":"10","Cooldown":"PT1M"}},{"MetricTrigger":{"Name":"Requests","Namespace":"microsoft.web/sites","Resource":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1","ResourceLocation":"West Central US","TimeGrain":"PT1M","Statistic":"Max","TimeWindow":"PT1M","TimeAggregation":"Maximum","Operator":"LessThan","Threshold":3.0,"Source":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/ed-rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1","MetricType":"MDM","Dimensions":[],"DividePerInstance":true},"ScaleAction":{"Direction":"Decrease","Type":"ChangeCount","Value":"5","Cooldown":"PT1M"}}]}}",
"eventDataId": "dddd3333-ee44-5555-66ff-777777aaaaaa",
"eventSubmissionTimestamp": "2022-09-13T07:20:41.1589076Z",
"resource": "scaleableappserviceplan",
"resourceGroup": "RG-001",
"resourceProviderValue": "MICROSOFT.WEB",
"subscriptionId": "aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e",
"activityStatusValue": "Succeeded"
}
Passaggi successivi
Per ulteriori informazioni sulla scalabilità automatica, vedere le risorse seguenti: