Estensioni di PostgreSQL in Database di Azure per PostgreSQL - Server flessibile
SI APPLICA A:  Database di Azure per PostgreSQL - Server flessibile
Database di Azure per PostgreSQL - Server flessibile
Il server flessibile di Database di Azure per PostgreSQL offre la possibilità di estendere le funzionalità del database usando le estensioni. Le estensioni raggruppano più oggetti SQL correlati in un singolo pacchetto che possono essere caricati o rimossi dal database con un comando. Dopo il caricamento nel database, le estensioni funzionano come le funzionalità predefinite.
Come usare le estensioni di PostgreSQL
Prima di installare le estensioni nel server flessibile di Database di Azure per PostgreSQL, è necessario consentire l'elenco di queste estensioni da usare.
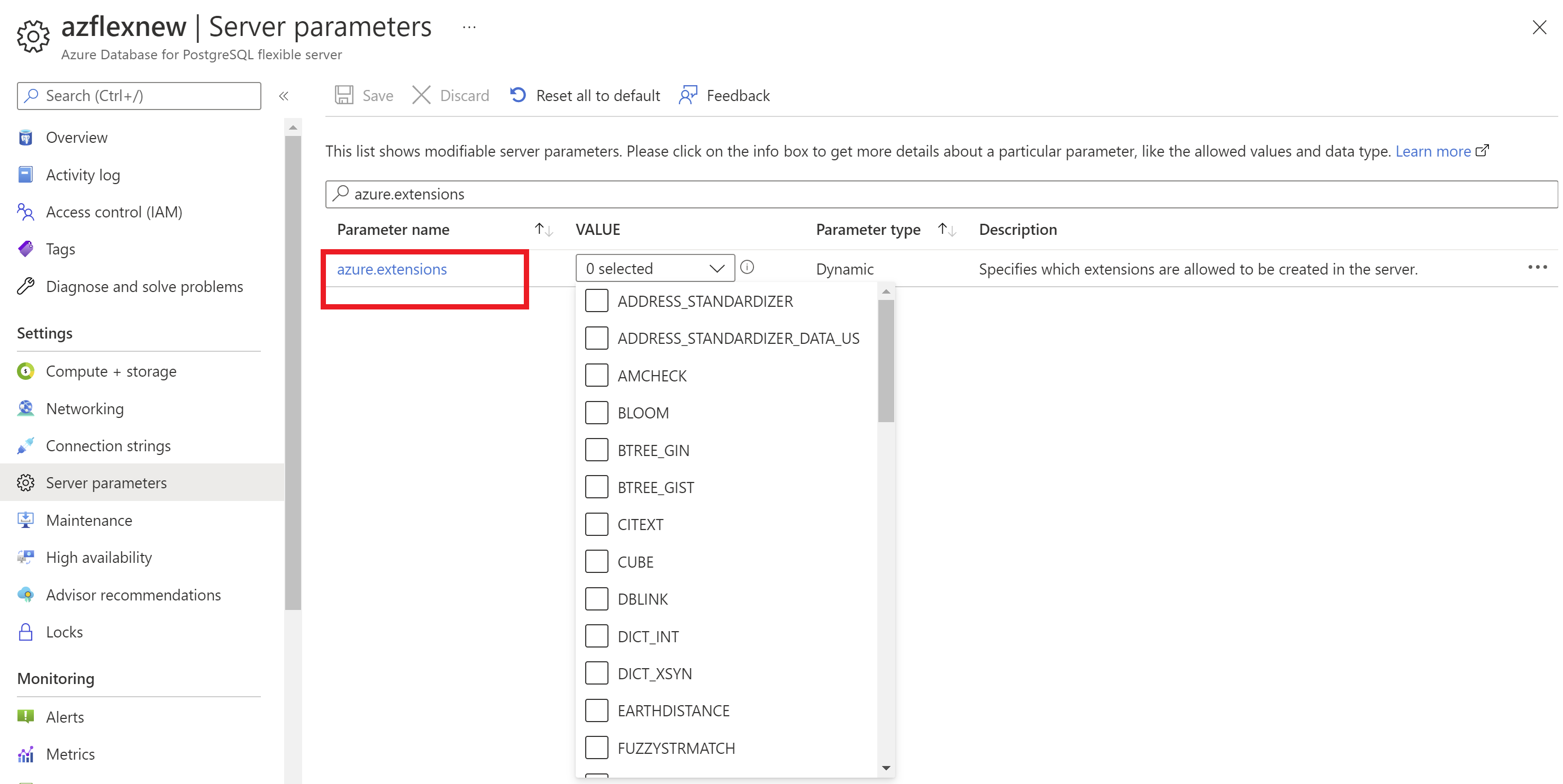
Tramite il portale di Azure:
- Selezionare l'istanza del server flessibile di Database di Azure per PostgreSQL.
- Nel menu della risorsa, nella sezione Impostazioni selezionare Parametridel server.
- Cercare il
azure.extensionsparametro. - Selezionare le estensioni da consentire.

Uso dell'interfaccia della riga di comando di Azure:
È possibile consentire le estensioni tramite il set di parametri dell'interfaccia della riga di comando comando.
az postgres flexible-server parameter set --resource-group <resource_group> --server-name <server> --subscription <subscription_id> --name azure.extensions --value <extension_name>,<extension_name>
Uso del modello di Resource Manager: nell'esempio seguente sono consentite le estensioni dblink, dict_xsyn e pg_buffercache in un server denominato postgres-test-server:
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"flexibleServers_name": {
"defaultValue": "postgres-test-server",
"type": "String"
},
"azure_extensions_set_value": {
"defaultValue": " dblink,dict_xsyn,pg_buffercache",
"type": "String"
}
},
"variables": {},
"resources": [
{
"type": "Microsoft.DBforPostgreSQL/flexibleServers/configurations",
"apiVersion": "2021-06-01",
"name": "[concat(parameters('flexibleServers_name'), '/azure.extensions')]",
"properties": {
"value": "[parameters('azure_extensions_set_value')]",
"source": "user-override"
}
}
]
}
shared_preload_libraries è un parametro di configurazione del server che determina quali librerie devono essere caricate all'avvio del server flessibile di Database di Azure per PostgreSQL. Tutte le librerie che usano la memoria condivisa devono essere caricate tramite questo parametro. Se l'estensione deve essere aggiunta alle librerie di precaricamento condiviso, seguire questa procedura:
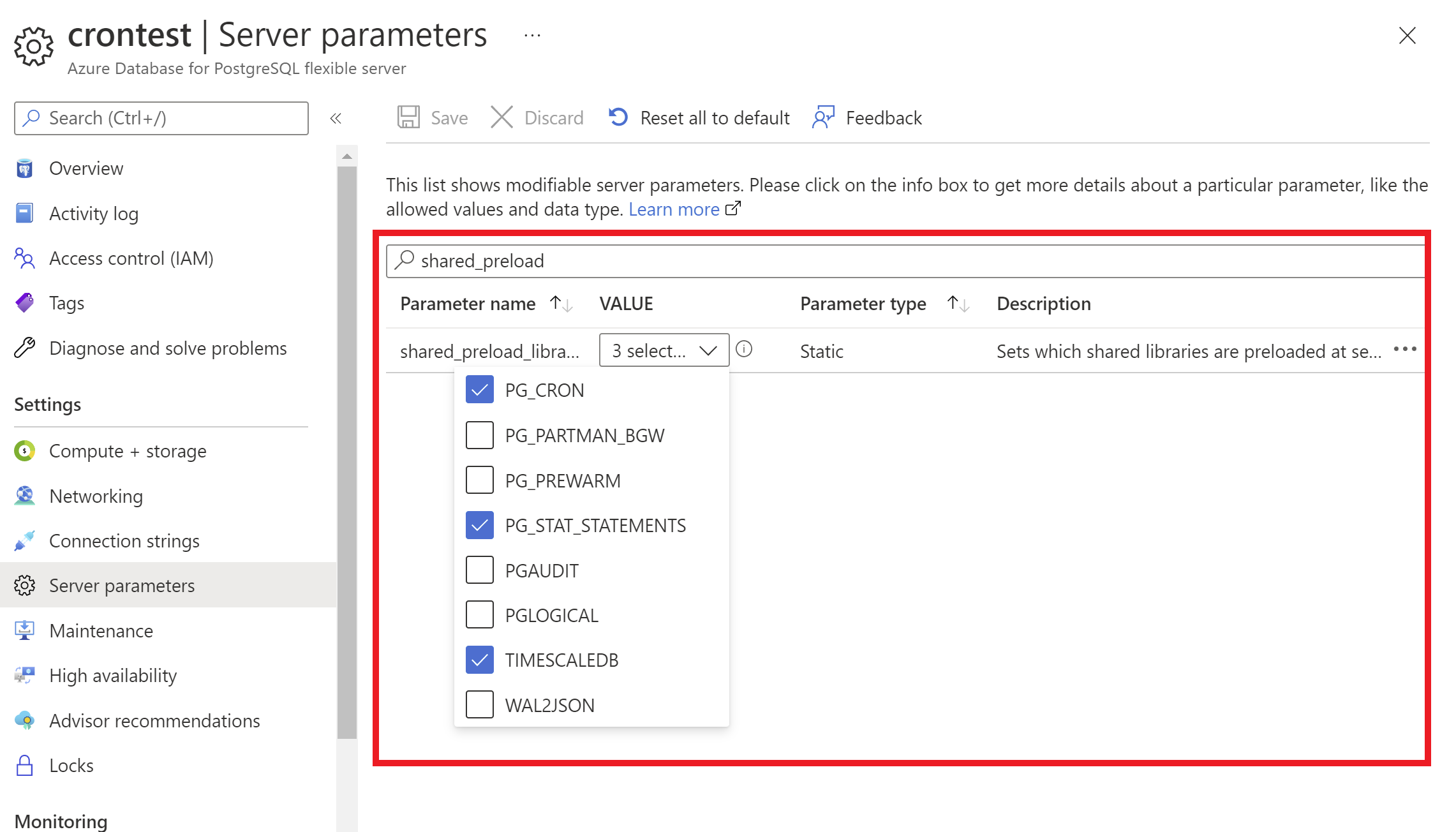
Tramite il portale di Azure:
- Selezionare l'istanza del server flessibile di Database di Azure per PostgreSQL.
- Nel menu della risorsa, nella sezione Impostazioni selezionare Parametridel server.
- Cercare il
shared_preload_librariesparametro. - Selezionare le librerie da aggiungere.

Uso dell'interfaccia della riga di comando di Azure:
È possibile impostare shared_preload_libraries tramite il set di parametri dell'interfaccia della riga di comando comando.
az postgres flexible-server parameter set --resource-group <resource_group> --server-name <server> --subscription <subscription_id> --name shared_preload_libraries --value <extension_name>,<extension_name>
Dopo aver autorizzato e caricato le estensioni, è necessario installarle in ogni database in cui si prevede di usarle. Per installare una particolare estensione, è necessario eseguire il comando CREA ESTENSIONE. Questo comando carica gli oggetti in pacchetto nel database.
Nota
Le estensioni di terze parti offerte nel server flessibile di Database di Azure per PostgreSQL sono codice con licenza open source. Attualmente, non sono disponibili estensioni o versioni di estensioni di terze parti con modelli di licenza Premium o proprietari.
L'istanza del server flessibile di Database di Azure per PostgreSQL supporta un subset di estensioni PostgreSQL chiave, come indicato nella tabella seguente. Queste informazioni sono disponibili anche eseguendo SHOW azure.extensions;. Le estensioni non elencate in questo documento non sono supportate nel server flessibile di Database di Azure per PostgreSQL. Non è possibile creare o caricare un'estensione personalizzata nel server flessibile di Database di Azure per PostgreSQL.
Versioni estensione
Le estensioni seguenti sono disponibili nel server flessibile di Database di Azure per PostgreSQL:
Nota
Le estensioni nella tabella seguente con il contrassegno richiedono l'abilitazione ✔️ delle librerie corrispondenti nel parametro server shared_preload_libraries.
| Nome dell'estensione | Descrizione | PostgreSQL 16 | PostgreSQL 15 | PostgreSQL 14 | PostgreSQL 13 | PostgreSQL 12 | PostgreSQL 11 |
|---|---|---|---|---|---|---|---|
| address_standardizer | Consente di analizzare un indirizzo nei suoi elementi costitutivi. In genere è utilizzata per supportare il passaggio di normalizzazione dell'indirizzo nella geocodifica. | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| address_standardizer_data_us | Esempio di set di dati Address Standardizer US | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| amcheck | Funzioni per la verifica dell'integrità delle relazioni | 1.3 | 1.3 | 1.3 | 1.2 | 1.2 | 1.1 |
| azure_ai | Integrazione di Machine Learning Services e intelligenza artificiale di Azure per PostgreSQL | 1.1.0 | 1.1.0 | 1.1.0 | 1.1.0 | 1.1.0 | N/D |
| azure_local_ai (anteprima) | Funzionalità di intelligenza artificiale locale per PostgreSQL | 0.1.0 | 0.1.0 | 0.1.0 | 0.1.0 | N/D | N/D |
| azure_storage | Integrazione di Azure per PostgreSQL | 1.4 ✔️ | 1.4 ✔️ | 1.4 ✔️ | 1.4 ✔️ | 1.4 ✔️ | N/D |
| bloom | Metodo di accesso Bloom: indice basato su file di firma | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| btree_gin | Supporto per l'indicizzazione di tipi di dati comuni in GIN | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 |
| btree_gist | Supporto per l'indicizzazione di tipi di dati comuni in GiST | 1,7 | 1,7 | 1.6 | 1,5 | 1,5 | 1,5 |
| citext | Tipo di dati per stringhe di caratteri senza distinzione tra maiuscole e minuscole | 1.6 | 1.6 | 1.6 | 1.6 | 1.6 | 1,5 |
| cube | Tipo di dati per i cubi multidimensionali | 1,5 | 1,5 | 1,5 | 1.4 | 1.4 | 1.4 |
| dblink | Connettersi ad altri database PostgreSQL dall'interno di un database | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| dict_int | Modello di dizionario di ricerca di testo per i numeri interi | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| dict_xsyn | Modello di dizionario di ricerca testuale per l'elaborazione estesa dei sinonimi | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| earthdistance | Calcolare le distanze ortodromiche sulla superficie terrestre | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| fuzzystrmatch | Determinare analogie e distanza tra stringhe | 1.2 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| hstore | Tipo di dati per l'archiviazione dei set di coppie (chiave/valore) | 1.8 | 1.8 | 1.8 | 1,7 | 1.6 | 1,5 |
| hypopg | Indici ipotetici per PostgreSQL | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 |
| intagg | Aggregatore di numeri interi ed enumeratore (obsoleto) | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| intarray | Funzioni, operatori e supporto dell'indice per matrici 1D di numeri interi | 1,5 | 1,5 | 1,5 | 1.3 | 1.2 | 1.2 |
| isn | Tipi di dati per gli standard di numerazione dei prodotti internazionali | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| lo | Manutenzione di Large Object | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| login_hook | Login_hook : hook per eseguire login_hook.login() al momento dell'accesso | 1,5 | 1.4 | 1.4 | 1.4 | 1.4 | 1.4 |
| ltree | Tipo di dati per strutture ad albero gerarchico | 1.2 | 1.2 | 1.2 | 1.2 | 1.1 | 1.1 |
| orafce | Funzioni e operatori che emulano un subset di funzioni e pacchetti dal sistema di gestione di database relazionali Oracle | 4.4 | 3.24 | 3.18 | 3.18 | 3.18 | 3.7 |
| pageinspect | Esaminare il contenuto delle pagine del database a un livello basso | 1.12 | 1.11 | 1,9 | 1.8 | 1,7 | 1,7 |
| pgaudit | Fornisce funzionalità di controllo | 16.0 ✔️ | 1.7 ✔️ | 1.6.2 ✔️ | 1.5 ✔️ | 1.4 ✔️ | 1.3.2 ✔️ |
| pg_buffercache | Esaminare la cache del buffer condiviso | 1.4 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 |
| pg_cron | Pianificatore di processi per PostgreSQL | 1.5 ✔️ | 1.4-1 ✔️ | 1.4-1 ✔️ | 1.4-1 ✔️ | 1.4-1 ✔️ | 1.4-1 ✔️ |
| pgcrypto | Funzioni crittografiche | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 |
| pg_failover_slots (anteprima) | Gestione slot di replica logica per scopi di failover | 1.0.1 ✔️ | 1.0.1 ✔️ | 1.0.1 ✔️ | 1.0.1 ✔️ | 1.0.1 ✔️ | 1.0.1 ✔️ |
| pg_freespacemap | Esaminare la mappa dello spazio disponibile (FSM) | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| pg_hint_plan | Consente di modificare i piani di esecuzione di PostgreSQL usando i cosiddetti hint nei commenti SQL. | 1.6.0 ✔️ | 1.5 ✔️ | 1.4 ✔️ | 1.3.7 ✔️ | 1.3.7 ✔️ | 1.3.7 ✔️ |
| pglogical | Replica logica di PostgreSQL | 2.4.4 ✔️ | 2.4.2 ✔️ | 2.4.1 ✔️ | 2.4.1 ✔️ | 2.4.1 ✔️ | 2.4.1 ✔️ |
| pg_partman | Estensione per gestire le tabelle partizionate in base all'ora o all'ID | 5.0.1 ✔️ | 4.7.1 ✔️ | 4.6.1 ✔️ | 4.5.0 ✔️ | 4.5.0 ✔️ | 4.5.0 ✔️ |
| pg_prewarm | Dati di relazione prewarm | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ |
| pg_repack | Riorganizzare le tabelle nei database PostgreSQL con blocchi minimi | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 |
| pgrouting | Estensione PgRouting | N/D | 3.5.0 | 3.3.0 | 3.3.0 | 3.3.0 | 3.3.0 |
| pgrowlocks | Mostrare informazioni sul blocco a livello di riga | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| pg_squeeze | Strumento per rimuovere lo spazio inutilizzato da una relazione. | 1.6 ✔️ | 1.6 ✔️ | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ |
| pg_stat_statements | Tenere traccia delle statistiche di pianificazione ed esecuzione di tutte le istruzioni SQL eseguite | 1.10 ✔️ | 1.10 ✔️ | 1.9 ✔️ | 1.8 ✔️ | 1.7 ✔️ | 1.6 ✔️ |
| pgstattuple | Mostrare le statistiche a livello di tupla | 1,5 | 1,5 | 1,5 | 1,5 | 1,5 | 1,5 |
| pg_trgm | Misurazione della somiglianza del testo e ricerca di indici in base ai trigrammi | 1.6 | 1.6 | 1.6 | 1,5 | 1.4 | 1.4 |
| pg_visibility | Esaminare le informazioni sulla mappa di visibilità (VM) e sulla visibilità a livello di pagina | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| plpgsql | Linguaggio procedurale PL/pgSQL | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| plv8 | Linguaggio procedurale attendibile PL/JavaScript (v8) | 3.1.7 | 3.1.7 | 3.0.0 | 3.0.0 | 3.0.0 | 3.0.0 |
| postgis | Funzioni e tipi spaziali di geometria postGIS e geografia | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_raster | Tipi e funzioni raster PostGIS | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_sfcgal | Funzioni SFCGAL PostGIS | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_tiger_geocoder | Geocoder tiger postGIS e geocoder inverso | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_topology | Tipi e funzioni spaziali di topologia PostGIS | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgres_fdw | Wrapper di dati stranieri per server PostgreSQL remoti | 1.1 | 1.1 | 1.1 | 1.0 | 1.0 | 1.0 |
| semver | Tipo di dati della versione semantica | 0.32.1 | 0.32.0 | 0.32.0 | 0.32.0 | 0.32.0 | 0.32.0 |
| session_variable | Session_variable - Registrazione e manipolazione di variabili e costanti di sessione | 3.3 | 3.3 | 3.3 | 3.3 | 3.3 | 3.3 |
| sslinfo | Informazioni sui certificati SSL | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| tablefunc | Funzioni che consentono di modificare intere tabelle, compresi i campi incrociati | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| tds_fdw | Wrapper di dati esterno per l'esecuzione di query su un database TDS (Sybase o Microsoft SQL Server) | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 |
| timescaledb | Abilita inserimenti scalabili e query complesse per i dati delle serie temporali | 2.13.0 ✔️ | 2.10.0 ✔️ | 2.10.0 ✔️ | 2.10.0 ✔️ | 2.10.0 ✔️ | 1.7.4 ✔️ |
| tsm_system_rows | Metodo TABLESAMPLE, che accetta il numero di righe come limite | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| tsm_system_time | Metodo TABLESAMPLE, che accetta il tempo in millisecondi come limite | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| unaccent | Dizionario di ricerca del testo che rimuove gli accenti | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| uuid-ossp | Generare identificatori universalmente univoci (UUID) | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| vector | Tipi di dati vettoriali e metodi di accesso ivfflat e hnsw | 0.7.0 | 0.7.0 | 0.7.0 | 0.7.0 | 0.7.0 | 0.5.1 |
Aggiornamento delle estensioni di PostgreSQL
Gli aggiornamenti sul posto delle estensioni di database sono consentiti tramite un semplice comando. Questa funzionalità consente ai clienti di aggiornare automaticamente le estensioni di terze parti alle versioni più recenti, mantenendo sistemi correnti e sicuri senza sforzo manuale.
Aggiornamento delle estensioni
Per aggiornare un'estensione installata alla versione più recente disponibile supportata da Azure, usare il comando SQL seguente:
ALTER EXTENSION <extension_name> UPDATE;
Questo comando semplifica la gestione delle estensioni di database consentendo agli utenti di eseguire manualmente l'aggiornamento alla versione più recente approvata da Azure, migliorando sia la compatibilità che la sicurezza.
Limiti
Durante l'aggiornamento delle estensioni è semplice, esistono alcune limitazioni:
- Selezione di una versione specifica: il comando non supporta l'aggiornamento alle versioni intermedie di un'estensione. Viene sempre aggiornato alla versione più recente disponibile.
- Downgrade: non supporta il downgrade di un'estensione a una versione precedente. Se è necessario un downgrade, potrebbe essere necessaria l'assistenza del supporto e dipende dalla disponibilità della versione precedente.
Estensioni installate
Per elencare le estensioni attualmente installate nel database, usare il comando SQL seguente:
SELECT * FROM pg_extension;
Estensioni disponibili e relative versioni
Per verificare quali versioni di un'estensione sono disponibili per l'installazione corrente del database, eseguire una query sulla vista del catalogo di sistema pg_available_extensions. Ad esempio, per determinare la versione disponibile per l'estensione azure_ai, eseguire:
SELECT * FROM pg_available_extensions WHERE name = 'azure_ai';
Questi comandi forniscono informazioni dettagliate necessarie sulle configurazioni delle estensioni del database, consentendo di mantenere i sistemi in modo efficiente e sicuro. Grazie all'abilitazione di semplici aggiornamenti alle versioni più recenti dell'estensione, Database di Azure per PostgreSQL continua a supportare la gestione affidabile, sicura ed efficiente delle applicazioni di database.
Considerazioni specifiche per il server flessibile di Database di Azure per PostgreSQL
Di seguito è riportato un elenco di estensioni supportate che richiedono alcune considerazioni specifiche quando vengono usate nel servizio server flessibile di Database di Azure per PostgreSQL. L'elenco è ordinato alfabeticamente.
dblink
dblink consente di connettersi da un'istanza del server flessibile di Database di Azure per PostgreSQL a un'altra o a un altro database nello stesso server. Il server flessibile di Database di Azure per PostgreSQL supporta connessioni sia in ingresso che in uscita a qualsiasi server PostgreSQL. Il server di invio deve consentire le connessioni in uscita al server ricevente. Analogamente, il server ricevente deve consentire le connessioni dal server di invio.
È consigliabile distribuire i server con integrazione della rete virtuale se si prevede di usare questa estensione. Per impostazione predefinita, l'integrazione della rete virtuale consente le connessioni tra server nella rete virtuale. È anche possibile scegliere di usare i gruppi di sicurezza di rete virtuale per personalizzare l'accesso.
pg_buffercache
pg_buffercache può essere utilizzato per studiare il contenuto di shared_buffers. Usando questa estensione è possibile stabilire se una determinata relazione viene memorizzata nella cache o meno (in shared_buffers). Questa estensione consente di risolvere i problemi di prestazioni (problemi di prestazioni correlati alla memorizzazione nella cache).
Questa estensione è integrata con l'installazione di base di PostgreSQL ed è facile da installare.
CREATE EXTENSION pg_buffercache;
pg_cron
pg_cron è un'utilità di pianificazione dei processi semplice basata su cron per PostgreSQL che viene eseguita all'interno del database come estensione. L'estensione pg_cron può essere usata per eseguire attività di manutenzione pianificata all'interno di un database PostgreSQL. Ad esempio, è possibile eseguire un vuoto periodico di una tabella o rimuovere processi di dati obsoleti.
pg_cron può eseguire più processi in parallelo, ma viene eseguita al massimo un'istanza di un processo alla volta. Se si prevede che una seconda esecuzione venga avviata prima del completamento del primo, la seconda esecuzione viene accodata e avviata non appena viene completata la prima esecuzione. In questo modo, viene garantito che i processi vengano eseguiti esattamente il numero di volte per cui sono pianificati e non vengano eseguiti simultaneamente con se stessi.
Alcuni esempi:
Per eliminare i vecchi dati il sabato alle 3:30 (GMT).
SELECT cron.schedule('30 3 * * 6', $$DELETE FROM events WHERE event_time < now() - interval '1 week'$$);
Per eseguire il vacuum ogni giorno alle 10:00 (GMT) nel database predefinito postgres.
SELECT cron.schedule('0 10 * * *', 'VACUUM');
Per annullare la configurazione di tutte le attività da pg_cron.
SELECT cron.unschedule(jobid) FROM cron.job;
Per visualizzare tutti i processi attualmente pianificati con pg_cron.
SELECT * FROM cron.job;
Per eseguire il vacuum ogni giorno alle 10:00 (GMT) nel database 'testcron' in azure_pg_admin account del ruolo.
SELECT cron.schedule_in_database('VACUUM','0 10 * * * ','VACUUM','testcron',null,TRUE);
Nota
L’estensione pg_cron viene precaricata in shared_preload_libraries per ogni istanza del server flessibile di Database di Azure per PostgreSQL all'interno del database postgres per consentire di pianificare i processi per l'esecuzione in altri database all'interno dell'istanza del database flessibile del server di Database di Azure per PostgreSQL senza compromettere la sicurezza. Tuttavia, per motivi di sicurezza, è comunque necessaria l’estensione elenco autorizzatipg_cron e installarla usando il comando CREATE EXTENSION.
A partire da pg_cron versione 1.4, è possibile usare le funzioni cron.schedule_in_database e cron.alter_job per pianificare il processo in un database specifico e aggiornare rispettivamente una pianificazione esistente.
Alcuni esempi:
Per eliminare i dati precedenti il sabato alle 3:30 (GMT) nel database DBName.
SELECT cron.schedule_in_database('JobName', '30 3 * * 6', $$DELETE FROM events WHERE event_time < now() - interval '1 week'$$,'DBName');
Nota
la funzione cron_schedule_in_database consente il nome utente come parametro facoltativo. L'impostazione del nome utente su un valore non Null richiede privilegi avanzati di PostgreSQL e non è supportata nel server flessibile di Database di Azure per PostgreSQL. Gli esempi precedenti mostrano l'esecuzione di questa funzione con il parametro facoltativo del nome utente omesso o impostato su null, che esegue il processo nel contesto della pianificazione utente del processo, che deve avere azure_pg_admin privilegi di ruolo.
Per aggiornare o modificare il nome del database per la pianificazione esistente
SELECT cron.alter_job(job_id:=MyJobID,database:='NewDBName');
pg_failover_slots (anteprima)
L'estensione Slot di failover PG migliora il server flessibile di Database di Azure per PostgreSQL quando si opera con la replica logica e i server abilitati per la disponibilità elevata. Risolve in modo efficace la sfida all'interno del motore PostgreSQL standard che non mantiene gli slot di replica logica dopo un failover. La gestione di questi slot è fondamentale per impedire le pause di replica o le mancate corrispondenze dei dati durante le modifiche del ruolo del server primario, garantendo la continuità operativa e l'integrità dei dati.
L'estensione semplifica il processo di failover gestendo il trasferimento, la pulizia e la sincronizzazione necessari degli slot di replica, offrendo così una transizione senza problemi durante le modifiche del ruolo del server. L'estensione è supportata per PostgreSQL versioni da 11 a 16.
Altre informazioni e come usare l'estensione Pg Failover Slots (Slot di failover PG) sono disponibili nella pagina GitHub.
Abilitare pg_failover_slots
Per abilitare l'estensione PG Failover Slots per l'istanza del server flessibile di Database di Azure per PostgreSQL, è necessario modificare la configurazione del server includendo l'estensione nelle librerie di precaricamento condiviso del server e modificando un parametro server specifico. È necessario eseguire le operazioni seguenti:
- Aggiungere
pg_failover_slotsalle librerie di precaricamento condiviso del server aggiornando il parametroshared_preload_libraries. - Modificare il parametro
hot_standby_feedbackdel server inon.
Per rendere effettive le modifiche apportate al parametro shared_preload_libraries, è necessario riavviare il server.
Tramite il portale di Azure:
- Selezionare l'istanza del server flessibile di Database di Azure per PostgreSQL.
- Nel menu della risorsa, nella sezione Impostazioni selezionare Parametridel server.
- Cercare il parametro
shared_preload_librariese modificarne il valore in modo da includerepg_failover_slots. - Cercare il parametro
hot_standby_feedbacke impostarne il valore suon. - Selezionare Salva per mantenere le modifiche. A questo punto, sarà possibile Salvare e riavviare. Scegliere questa opzione per assicurarsi che le modifiche siano effettive perché la modifica di
shared_preload_librariesrichiede un riavvio del server.
Selezionando Salva e riavvia, il server viene riavviato automaticamente, applicando le modifiche appena apportate. Quando il server è di nuovo online, l'estensione PG Failover Slots è abilitata e operativa nell'istanza del server flessibile di Database di Azure per PostgreSQL primaria, pronta per gestire gli slot di replica logica durante i failover.
pg_hint_plan
pg_hint_plan consente di modificare i piani di esecuzione di PostgreSQL usando i cosiddetti "hint" nei commenti SQL, ad esempio:
/*+ SeqScan(a) */
pg_hint_plan legge frasi di hint in un commento di forma speciale specificata con l'istruzione SQL di destinazione. La forma speciale inizia dalla sequenza di caratteri "/*+" e termina con "*/". Le frasi hint sono costituite dal nome dell'hint e dai parametri seguenti racchiusi tra parentesi e delimitati da spazi. Le nuove righe per la leggibilità possono delimitare ogni frase di hint.
Esempio:
/*+
HashJoin(a b)
SeqScan(a)
*/
SELECT *
FROM pgbench_branches b
JOIN pgbench_accounts an ON b.bid = a.bid
ORDER BY a.aid;
L'esempio precedente fa in modo che l'utilità di pianificazione usi i risultati di un seq scan nella tabella da combinare con la tabella b come hash join.
Per installare pg_hint_plan, inoltre, per consentire l'inserzione, come illustrato in Come usare le estensioni PostgreSQL, è necessario includerlo nelle librerie di precaricamento condivise del server. Per rendere effettiva una modifica al parametro shared_preload_libraries di Postgres, è necessario riavviare il server. È possibile modificare i parametri usando il portale di Azure o l'interfaccia della riga di comando di Azure.
Tramite il portale di Azure:
- Selezionare l'istanza del server flessibile di Database di Azure per PostgreSQL.
- Nel menu della risorsa, nella sezione Impostazioni selezionare Parametridel server.
- Cercare il parametro
shared_preload_librariese modificarne il valore in modo da includerepg_hint_plan. - Selezionare Salva per mantenere le modifiche. A questo punto, sarà possibile Salvare e riavviare. Scegliere questa opzione per assicurarsi che le modifiche siano effettive perché la modifica di
shared_preload_librariesrichiede un riavvio del server. È ora possibile abilitare pg_hint_plan nel database flessibile di Database di Azure per PostgreSQL. Connettersi al database ed eseguire il comando seguente:
CREATE EXTENSION pg_hint_plan;
pg_prewarm
L'estensione pg_prewarm carica i dati relazionali nella cache. Il preriscaldamento delle cache significa che le query hanno tempi di risposta migliori alla prima esecuzione dopo un riavvio. La funzionalità di preriscaldamento automatico non è attualmente disponibile nel server flessibile di Database di Azure per PostgreSQL.
pg_repack
Una domanda tipica che gli utenti fanno quando tentano di usare questa estensione è: pg_repack è un'estensione o un eseguibile lato client come psql o pg_dump?
La risposta a questa domanda è che in realtà è entrambi. pg_repack/lib contiene il codice per l'estensione, inclusi gli elementi dello schema e SQL creati e la libreria C che implementa il codice di diverse di queste funzioni. D'altra parte, pg_repack/bin mantiene il codice per l'applicazione client, che sa come interagire con gli artefatti programmabilità creati dall'estensione. Questa applicazione client mira a semplificare la complessità dell'interazione con le diverse interfacce rilevate dall'estensione lato server, offrendo all'utente alcune opzioni della riga di comando che sono più facili da comprendere. L'applicazione client senza l'estensione creata nel database a cui punta è inutile. L'estensione lato server da sola sarebbe completamente funzionale, ma richiederebbe all'utente di comprendere un modello di interazione complesso costituito dall'esecuzione di query per recuperare i dati usati come input per le funzioni implementate dall'estensione.
Autorizzazione negata per la ricompressione dello schema
Attualmente, a causa del modo in cui si concedono le autorizzazioni allo schema di ricompressione creato da questa estensione, è supportata solo per eseguire la funzionalità pg_repack dal contesto di azure_pg_admin.
Si noterà che, se il proprietario di una tabella, che non è azure_pg_admin, tenta di eseguire pg_repack, viene visualizzato un errore simile al seguente:
NOTICE: Setting up workers.conns
ERROR: pg_repack failed with error: ERROR: permission denied for schema repack
LINE 1: select repack.version(), repack.version_sql()
Per evitare questo errore, assicurarsi di eseguire pg_repack dal contesto di azure_pg_admin.
pg_stat_statements
L'estensione pg_stat_statements offre una visualizzazione di tutte le query eseguite nel database. Ciò è utile per comprendere l'aspetto delle prestazioni del carico di lavoro delle query in un sistema di produzione.
L'estensione pg_stat_statements viene precaricata in shared_preload_libraries in ogni istanza del server flessibile di Database di Azure per PostgreSQL per fornire un mezzo per tenere traccia delle statistiche di esecuzione delle istruzioni SQL.
Tuttavia, per motivi di sicurezza, è comunque necessario aggiungere all'elenco elementi consentitil'estensione pg_stat_statements e installarla usando il comando CREATE EXTENSION.
L'impostazione pg_stat_statements.track, che controlla le istruzioni conteggiate mediante l'estensione, è impostata su top. Ciò consente di rilevare tutte le istruzioni eseguite direttamente dai client. Gli altri due livelli di rilevamento sono none e all. Questa impostazione è configurabile come parametro del server.
È necessario trovare un compromesso tra le informazioni sull'esecuzione di query fornite da pg_stat_statements e l'impatto della registrazione di ogni istruzione SQL sulle prestazioni del server. Se non si usa attivamente l'estensione pg_stat_statements, è consigliabile impostare pg_stat_statements.track su none. Alcuni servizi di monitoraggio di terze parti potrebbero basarsi su pg_stat_statements per offrire informazioni dettagliate sulle prestazioni delle query. Verificare se questo è il proprio caso oppure no.
postgres_fdw
postgres_fdw consente di connettersi da un'istanza del server flessibile di Database di Azure per PostgreSQL a un'altra istanza o un altro database nello stesso server. Il server flessibile di Database di Azure per PostgreSQL supporta connessioni sia in ingresso che in uscita a qualsiasi server PostgreSQL. Il server di invio deve consentire le connessioni in uscita al server ricevente. Analogamente, il server ricevente deve consentire le connessioni dal server di invio.
È consigliabile distribuire i server con integrazione della rete virtuale se si prevede di usare questa estensione. Per impostazione predefinita, l'integrazione della rete virtuale consente le connessioni tra server nella rete virtuale. È anche possibile scegliere di usare i gruppi di sicurezza di rete virtuale per personalizzare l'accesso.
TimescaleDB
TimescaleDB è un database time series che viene creato in un pacchetto come estensione per PostgreSQL. TimescaleDB offre funzioni analitiche orientate al tempo, ottimizzazioni e scalabilità di Postgres per carichi di lavoro di serie temporali. Altre informazioni su TimescaleDB, un marchio registrato di Timescale, Inc. Il server flessibile di Database di Azure per PostgreSQL fornisce TimescaleDB edizione Apache-2.
Installare TimescaleDB
Per installare TimescaleDB, inoltre, per consentire l'inserimento nell'elenco, come illustrato in precedenza, è necessario includerlo nelle librerie di precaricamento condiviso del server. Per rendere effettiva una modifica al parametro shared_preload_libraries di Postgres, è necessario riavviare il server. È possibile modificare i parametri usando il portale di Azure o l'interfaccia della riga di comando di Azure.
Tramite il portale di Azure:
- Selezionare l'istanza del server flessibile di Database di Azure per PostgreSQL.
- Nel menu della risorsa, nella sezione Impostazioni selezionare Parametridel server.
- Cercare il parametro
shared_preload_librariese modificarne il valore in modo da includereTimescaleDB. - Selezionare Salva per mantenere le modifiche. A questo punto, sarà possibile Salvare e riavviare. Scegliere questa opzione per assicurarsi che le modifiche siano effettive perché la modifica di
shared_preload_librariesrichiede un riavvio del server. È ora possibile abilitare TimescaleDB nel database flessibile del server flessibile di Database di Azure per PostgreSQL. Connettersi al database ed eseguire il comando seguente:
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;
Suggerimento
Se viene visualizzato un errore, verificare di aver riavviato il server dopo aver salvato shared_preload_libraries.
È ora possibile creare un hypertable TimescaleDB da zero o eseguire la migrazione dei dati delle serie temporali esistenti in PostgreSQL.
Ripristinare un database di scalabilità temporale usando pg_dump e pg_restore
Per ripristinare un database di scala cronologica usando pg_dump e pg_restore, è necessario eseguire due procedure helper nel database di destinazione: timescaledb_pre_restore() e timescaledb_post restore().
Preparare prima di tutto il database di destinazione:
--create the new database where you want to perform the restore
CREATE DATABASE tutorial;
\c tutorial --connect to the database
CREATE EXTENSION timescaledb;
SELECT timescaledb_pre_restore();
È ora possibile eseguire pg_dump nel database originale e quindi eseguire pg_restore. Dopo il ripristino, assicurarsi di eseguire il comando seguente nel database ripristinato:
SELECT timescaledb_post_restore();
Per altri dettagli sul metodo di ripristino con il database abilitato per la scalabilità cronologica, vedere la documentazione relativa alla scalabilità cronologica.
Ripristino di un database di scalabilità temporale usando timescaledb-backup
Durante l'esecuzione della procedura SELECT timescaledb_post_restore() elencata sopra, è possibile ottenere autorizzazioni negate durante l'aggiornamento del flag timescaledb.restore. Ciò è dovuto a un'autorizzazione ALTER DATABASE limitata nei servizi di database PaaS cloud. In questo caso è possibile eseguire un metodo alternativo usando lo strumento timescaledb-backup per eseguire il backup e il ripristino del database di scala cronologica. Timescaledb-backup è un programma per rendere il dump e il ripristino di un database TimescaleDB più semplice, meno soggetto a errori e prestazioni più elevate.
A tale scopo, eseguire le operazioni seguenti
- Installare gli strumenti come descritto qui
- Creare un'istanza e un database flessibili del server flessibile di Database di Azure per PostgreSQL di destinazione
- Abilitare l'estensione Scala cronologica come illustrato in precedenza
- Concedere il ruolo
azure_pg_adminall'utente che verrà usato da ts-restore - Eseguire ts-restore per ripristinare il database
Altre informazioni su queste utilità sono disponibili qui.
Estensioni e aggiornamento della versione principale
Il server flessibile di Database di Azure per PostgreSQL ha introdotto una funzionalità di aggiornamento della versione principale sul posto che esegue un aggiornamento sul posto dell'istanza del server flessibile di Database di Azure per PostgreSQL con un semplice clic. L'aggiornamento della versione principale sul posto semplifica il processo di aggiornamento flessibile del server di Database di Azure per PostgreSQL, riducendo al minimo le interruzioni per utenti e applicazioni che accedono al server. L'aggiornamento della versione principale sul posto non supporta estensioni specifiche ed esistono alcune limitazioni per l'aggiornamento di determinate estensioni. Le estensioni Timescaledb, pgaudit, dblink, orafce e postgres_fdw non sono supportate per tutte le versioni del server flessibile di Database di Azure per PostgreSQL quando si usa la funzionalità di aggiornamento della versione principale sul posto.