Modello di layout di Intelligence per documenti
Importante
- Le versioni di anteprima pubblica di Document Intelligence consentono l'accesso anticipato alle funzionalità in fase di sviluppo attivo.
- Le funzionalità, gli approcci e i processi possono cambiare, prima della disponibilità generale, in base al feedback degli utenti.
- La versione di anteprima pubblica delle librerie client di Document Intelligence per impostazione predefinita è l'API REST versione 2024-02-29-preview.
- L'anteprima pubblica versione 2024-02-29-preview è attualmente disponibile solo nelle aree di Azure seguenti:
- Stati Uniti orientali
- Stati Uniti occidentali2
- Europa occidentale
Questo contenuto si applica a:![]() v4.0 (anteprima) | Versioni precedenti:
v4.0 (anteprima) | Versioni precedenti:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
Questo contenuto si applica a:![]() v3.1 (GA) | Versione più recente:
v3.1 (GA) | Versione più recente:![]() v4.0 (anteprima) | Versioni precedenti:
v4.0 (anteprima) | Versioni precedenti:![]() v3.0
v3.0![]() v2.1
v2.1
Questo contenuto si applica a:![]() v3.0 (GA) | Versioni più recenti:
v3.0 (GA) | Versioni più recenti:![]() v4.0 (anteprima)
v4.0 (anteprima)![]() v3.1 | Versione precedente:
v3.1 | Versione precedente:![]() v2.1
v2.1
Questo contenuto si applica a:![]() v2.1 | Versione più recente:
v2.1 | Versione più recente:![]() v4.0 (anteprima)
v4.0 (anteprima)
Il modello di layout di Intelligence sui documenti è un'API avanzata di analisi dei documenti basata su Machine Learning disponibile nel cloud di Document Intelligence. Consente di acquisire documenti in diversi formati e restituire rappresentazioni strutturate dei dati dei documenti. Combina una versione avanzata delle potenti funzionalità OCR (Optical Character Recognition) con i modelli di Deep Learning per estrarre testo, tabelle, segni di selezione e struttura del documento.
Analisi del layout dei documenti
L'analisi del layout della struttura del documento è il processo di analisi di un documento per estrarre aree di interesse e le relative relazioni. L'obiettivo è estrarre testo e elementi strutturali dalla pagina per creare modelli di comprensione semantica migliori. Esistono due tipi di ruoli in un layout di documento:
- Ruoli geometrici: testo, tabelle, figure e segni di selezione sono esempi di ruoli geometrici.
- Ruoli logici: titoli, intestazioni e piè di pagina sono esempi di ruoli logici di testi.
La figura seguente mostra i componenti tipici in un'immagine di una pagina di esempio.

Opzioni di sviluppo
Document Intelligence v4.0 (2024-02-29-preview, 2023-10-31-preview) supporta gli strumenti, le applicazioni e le librerie seguenti:
| Funzionalità | Risorse | Model ID |
|---|---|---|
| Modello di layout | • Document Intelligence Studio • API REST• C# SDK • Python SDK • Java SDK • JavaScript SDK |
precompilt-layout |
Document Intelligence v3.1 supporta gli strumenti, le applicazioni e le librerie seguenti:
| Funzionalità | Risorse | Model ID |
|---|---|---|
| Modello di layout | • Document Intelligence Studio • API REST• C# SDK • Python SDK • Java SDK • JavaScript SDK |
precompilt-layout |
Document Intelligence v3.0 supporta gli strumenti, le applicazioni e le librerie seguenti:
| Funzionalità | Risorse | Model ID |
|---|---|---|
| Modello di layout | • Document Intelligence Studio • API REST• C# SDK • Python SDK • Java SDK • JavaScript SDK |
precompilt-layout |
Document Intelligence v2.1 supporta gli strumenti, le applicazioni e le librerie seguenti:
| Funzionalità | Risorse |
|---|---|
| Modello di layout | • Strumento di etichettatura di Document Intelligence• API REST• SDK della libreria client• Contenitore Docker di Document Intelligence |
Requisiti di input
Per ottenere risultati ottimali, fornire una foto chiara o un'analisi di alta qualità per ogni documento.
Formati di file supportati:
Modello PDF Immagine:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) e HTMLLettura ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Documento generale ✔ ✔ Predefinito ✔ ✔ Estrazione personalizzata ✔ ✔ Classificazione personalizzata ✔ ✔ ✔ (2024-02-29-preview) Per PDF e TIFF, è possibile elaborare fino a 2000 pagine (con una sottoscrizione di livello gratuito, vengono elaborate solo le prime due pagine).
Le dimensioni del file per l'analisi dei documenti sono di 500 MB per il livello a pagamento (S0) e 4 MB per il livello gratuito (F0).
Le dimensioni dell'immagine devono essere comprese tra 50 x 50 pixel e 10.000 px x 10.000 pixel.
Se i file PDF sono bloccati da password, è necessario rimuovere il blocco prima dell'invio.
L'altezza minima del testo da estrarre è di 12 pixel per un'immagine da 1024 x 768 pixel. Questa dimensione corrisponde a circa
8-point text a 150 punti per pollice (DPI).Per il training di modelli personalizzati, il numero massimo di pagine per i dati di training è 500 per il modello di modello personalizzato e 50.000 per il modello neurale personalizzato.
Per il training del modello di estrazione personalizzato, le dimensioni totali dei dati di training sono di 50 MB per il modello di modello e 1G-MB per il modello neurale.
Per il training del modello di classificazione personalizzato, le dimensioni totali dei dati di training sono
1GBpari a un massimo di 10.000 pagine.
- Formati di file supportati: JPEG, PNG, PDF e TIFF.
- Numero di pagine supportato: per PDF e TIFF vengono elaborate fino a 2.000 pagine. Per i sottoscrittori del livello gratuito, vengono elaborate solo le prime due pagine.
- Dimensioni del file supportate: le dimensioni del file devono essere inferiori a 50 MB e dimensioni almeno 50 x 50 pixel e al massimo 10.000 x 10.000 pixel.
Introduzione al modello di layout
Vedere in che modo i dati, inclusi testo, tabelle, intestazioni di tabella, contrassegni di selezione e informazioni sulla struttura vengono estratti dai documenti usando l'intelligence sui documenti. Sono necessarie le risorse seguenti:
Una sottoscrizione di Azure: è possibile crearne una gratuitamente.
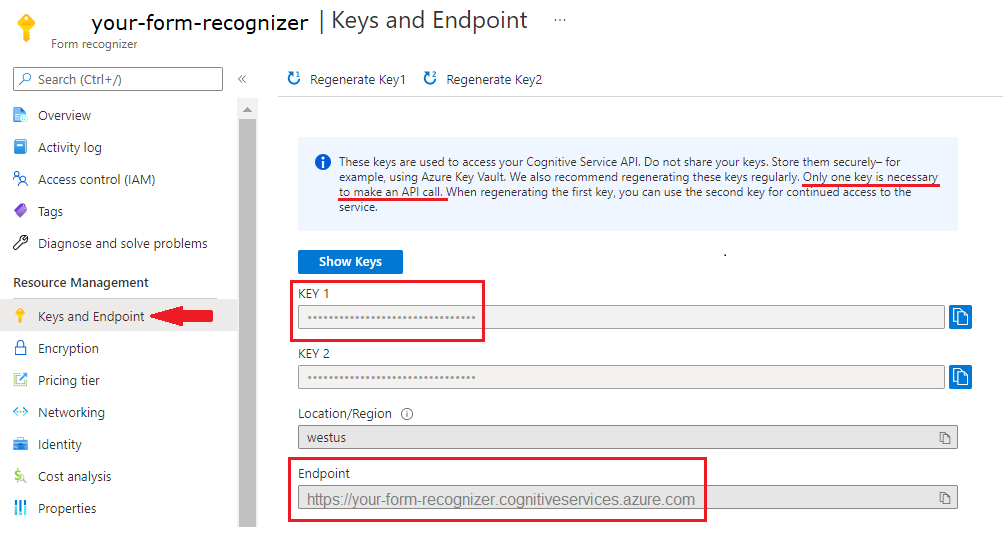
Istanza di Document Intelligence nel portale di Azure. Per provare il servizio, è possibile usare il piano tariffario gratuito (
F0). Dopo la distribuzione della risorsa, selezionare Vai alla risorsa per ottenere la chiave e l'endpoint.
Nota
Document Intelligence Studio è disponibile con le API v3.0 e le versioni successive.
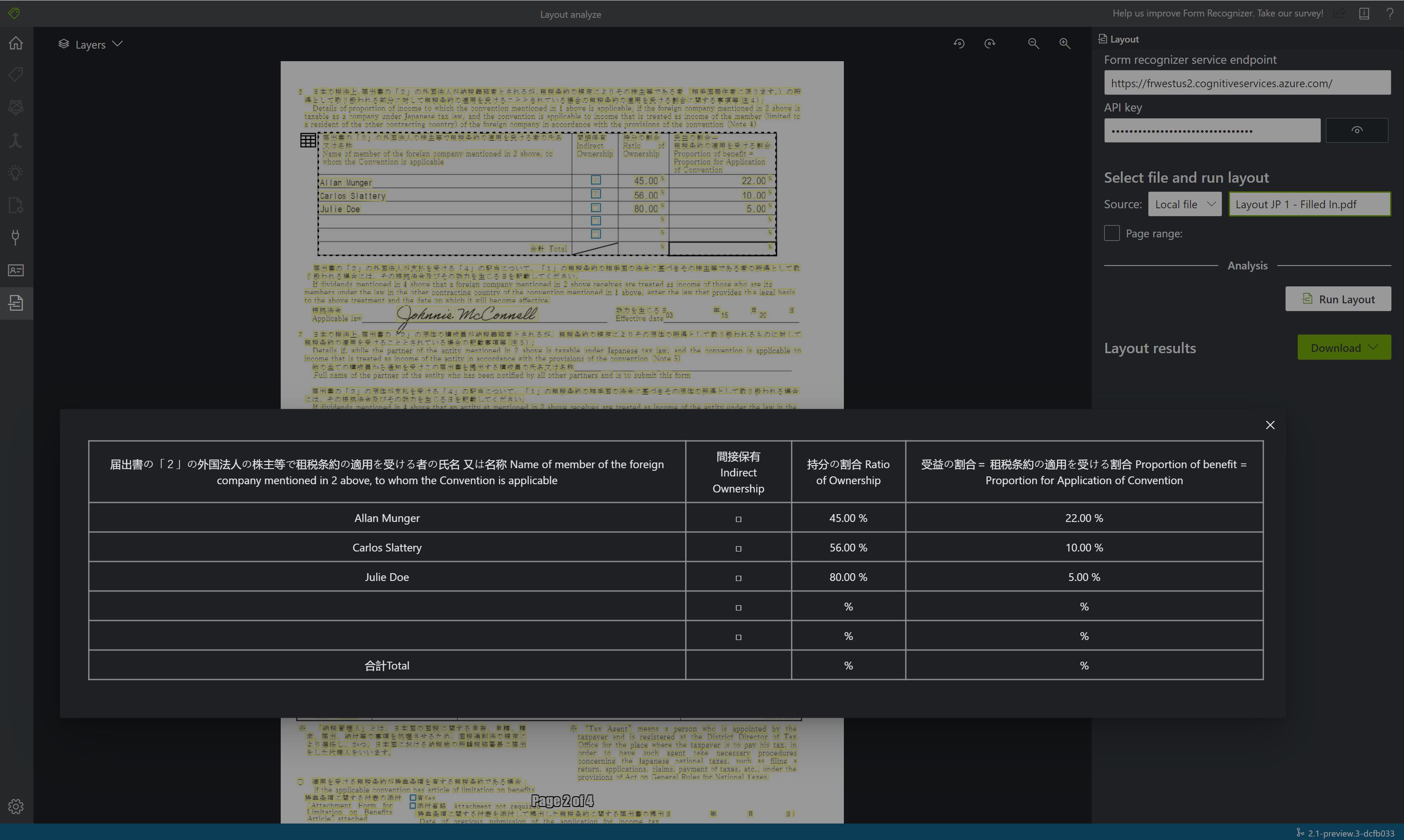
Documento di esempio elaborato con Document Intelligence Studio
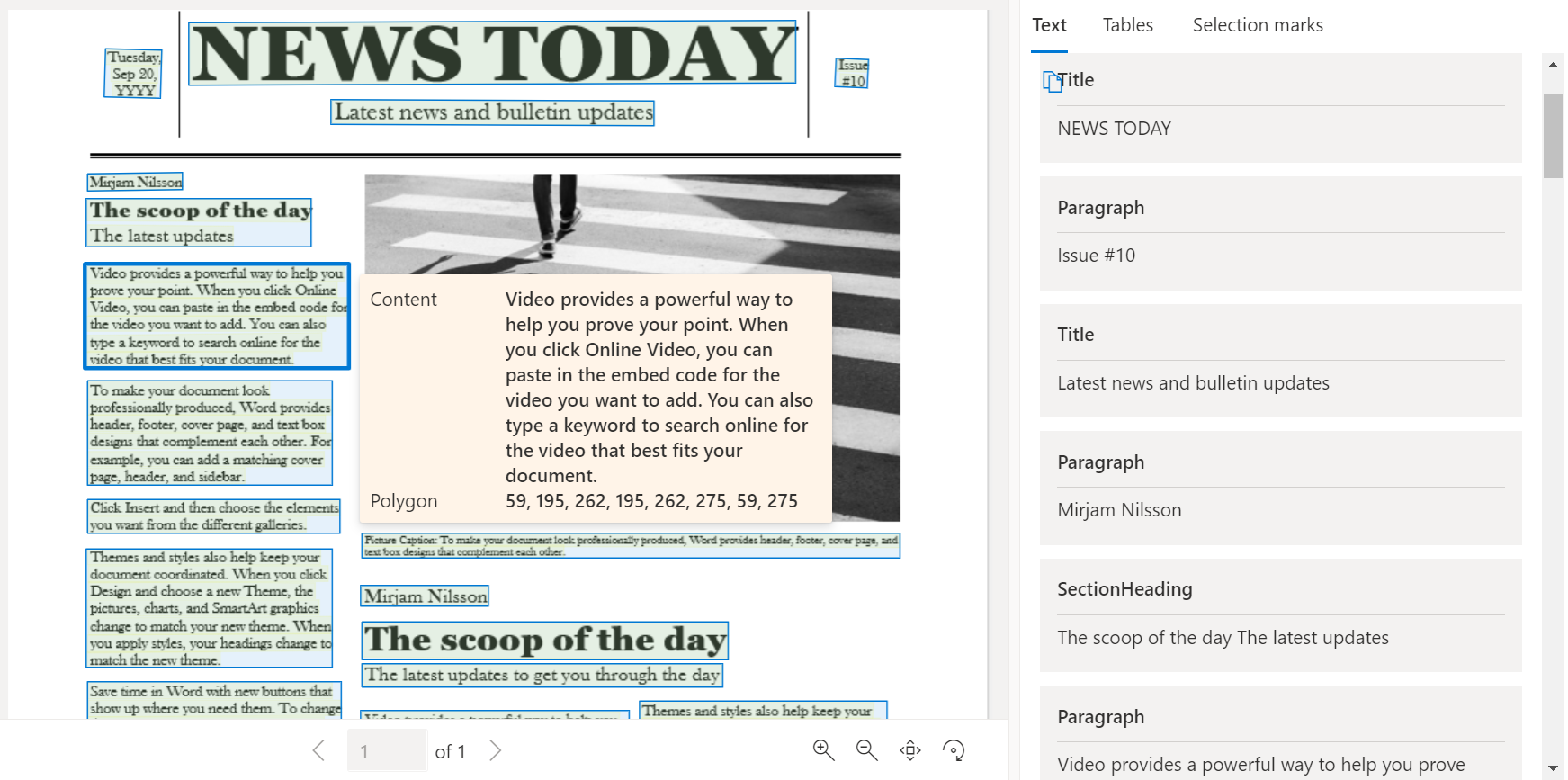
Nella home page di Document Intelligence Studio selezionare Layout.
È possibile analizzare il documento di esempio o caricare i propri file.
Selezionare il pulsante Esegui analisi e, se necessario, configurare le opzioni Analizza:

Strumento di etichettatura di esempio di Document Intelligence
Passare allo strumento di esempio document intelligence.
Nella home page dello strumento di esempio selezionare Usa layout per ottenere testo, tabelle e segni di selezione.
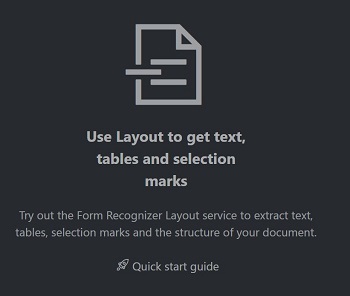
Nel campo Document Intelligence Service Endpoint (Endpoint servizio Document Intelligence) incollare l'endpoint ottenuto con la sottoscrizione di Document Intelligence.
Nel campo chiave incollare la chiave ottenuta dalla risorsa di Intelligence documenti.
Nel campo Origine selezionare URL dal menu a discesa È possibile usare il documento di esempio:
Documento di esempio.
Selezionare il pulsante Recupera .
Selezionare Run Layout (Esegui layout). Lo strumento di etichettatura di esempio di Document Intelligence chiama l'API
Analyze Layoutper analizzare il documento.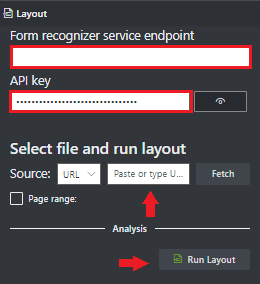
Visualizzare i risultati: vedere il testo estratto evidenziato, i segni di selezione rilevati e le tabelle rilevate.
{kind=link}
Lingue e impostazioni locali supportate
Per un elenco completo delle lingue supportate, vedere la pagina Supporto linguistico - Modelli di analisi dei documenti.
Document Intelligence v2.1 supporta gli strumenti, le applicazioni e le librerie seguenti:
| Funzionalità | Risorse |
|---|---|
| Layout API |
Estrazione dei dati
Il modello di layout estrae testo, segni di selezione, tabelle, paragrafi e tipi di paragrafo (roles) dai documenti.
Nota
Versioni 2024-02-29-preview, 2023-10-31-previewe versioni successive supportano i file HTML e i file MICROSOFT Office (DOCX, XLSX, PPTX). Le funzionalità seguenti non sono supportate:
- Nessun angolo, larghezza/altezza e unità con ogni oggetto pagina.
- Per ogni oggetto rilevato, non è presente alcun poligono di delimitazione o area di delimitazione.
- L'intervallo di pagine (
pages) non è supportato come parametro. - Nessun
linesoggetto.
Pagine
L'insieme pages è un elenco di pagine all'interno del documento. Ogni pagina viene rappresentata in sequenza all'interno del documento e include l'angolo di orientamento che indica se la pagina viene ruotata e la larghezza e l'altezza (dimensioni in pixel). Le unità di pagina nell'output del modello vengono calcolate come illustrato:
| Formato file | Unità di pagina calcolata | Totale pagine |
|---|---|---|
| Immagini (JPEG/JPG, PNG, BMP, HEIF) | Ogni immagine = 1 unità di pagina | Totale immagini |
| Ogni pagina nel PDF = 1 unità di pagina | Totale pagine nel PDF | |
| TIFF | Ogni immagine nell'unità di pagina TIFF = 1 | Totale immagini in TIFF |
| Word (DOCX) | Fino a 3.000 caratteri = 1 unità di pagina, immagini incorporate o collegate non supportate | Pagine totali di un massimo di 3.000 caratteri ciascuno |
| Excel (XLSX) | Ogni foglio di lavoro = 1 unità di pagina, immagini incorporate o collegate non supportate | Totale fogli di lavoro |
| PowerPoint (PPTX) | Ogni diapositiva = 1 unità di pagina, immagini incorporate o collegate non supportate | Diapositive totali |
| HTML | Fino a 3.000 caratteri = 1 unità di pagina, immagini incorporate o collegate non supportate | Pagine totali di un massimo di 3.000 caratteri ciascuno |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
Estrarre pagine selezionate dai documenti
Per i documenti a più pagine di grandi dimensioni, usare il pages parametro di query per indicare numeri di pagina o intervalli di pagine specifici per l'estrazione di testo.
Paragrafi
Il modello Layout estrae tutti i blocchi identificati di testo nell'insieme paragraphs come oggetto di primo livello in analyzeResults. Ogni voce di questa raccolta rappresenta un blocco di testo e include il testo estratto comecontente le coordinate di delimitazione polygon . Le span informazioni puntano al frammento di testo all'interno della proprietà di primo livello content che contiene il testo completo del documento.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Ruoli paragrafo
Il nuovo rilevamento oggetti pagina basato su Machine Learning estrae ruoli logici come titoli, intestazioni di sezione, intestazioni di pagina, piè di pagina e altro ancora. Il modello Document Intelligence Layout assegna determinati blocchi di testo nella paragraphs raccolta con il relativo ruolo o tipo specializzato stimato dal modello. Sono meglio usati con documenti non strutturati per comprendere il layout del contenuto estratto per un'analisi semantica più completa. Sono supportati i ruoli di paragrafo seguenti:
| Ruolo stimato | Descrizione | Tipi di file supportati |
|---|---|---|
title |
Intestazioni principali nella pagina | pdf, image, docx, pptx, xlsx, html |
sectionHeading |
Uno o più sottotitoli nella pagina | pdf, image, docx, xlsx, html |
footnote |
Testo nella parte inferiore della pagina | pdf, immagine |
pageHeader |
Testo vicino al bordo superiore della pagina | pdf, immagine, docx |
pageFooter |
Testo vicino al bordo inferiore della pagina | pdf, image, docx, pptx, html |
pageNumber |
Numero pagina | pdf, immagine |
{
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"role": "title",
"content": "NEWS TODAY"
},
{
"spans": [],
"boundingRegions": [],
"role": "sectionHeading",
"content": "Mirjam Nilsson"
}
]
}
Testo, righe e parole
Il modello di layout del documento in Document Intelligence estrae il testo dello stile stampato e scritto a mano come lines e words. L'insieme styles include qualsiasi stile scritto a mano per le righe, se rilevato insieme agli intervalli che puntano al testo associato. Questa funzionalità si applica alle lingue scritte a mano supportate.
Per Microsoft Word, Excel, PowerPoint e HTML, le versioni di Document Intelligence 2024-02-29-preview e 2023-10-31-preview Layout estraggono tutto il testo incorporato così come è. I testi vengono estratti come parole e paragrafi. Le immagini incorporate non sono supportate.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
Stile scritto a mano per le righe di testo
La risposta include la classificazione di ogni riga di testo dello stile di scrittura manuale o meno, insieme a un punteggio di attendibilità. Per altre informazioni, Vedere Supporto per la lingua scritta a mano. L'esempio seguente mostra un frammento JSON di esempio.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Se si abilita la funzionalità di componente aggiuntivo tipo di carattere/stile, si ottiene anche il risultato del tipo di carattere/stile come parte dell'oggetto styles .
Opzioni di selezione
Il modello Layout estrae anche i segni di selezione dai documenti. I segni di selezione estratti vengono visualizzati all'interno della pages raccolta per ogni pagina. Includono il delimitazione polygon, confidencee la selezione state (selected/unselected). La rappresentazione testuale (ovvero :selected: e :unselected) è inclusa anche come indice iniziale (offset) e length che fa riferimento alla proprietà di primo livello content che contiene il testo completo del documento.
{
"selectionMarks": [
{
"state": "unselected",
"polygon": [],
"confidence": 0.995,
"span": {
"offset": 1421,
"length": 12
}
}
]
}
Tabelle
L'estrazione di tabelle è un requisito fondamentale per l'elaborazione di documenti contenenti grandi volumi di dati in genere formattati come tabelle. Il modello Layout estrae le tabelle nella pageResults sezione dell'output JSON. Le informazioni sulla tabella estratte includono il numero di colonne e righe, intervallo di righe e intervallo di colonne. Ogni cella con il relativo poligono di delimitazione viene restituita insieme alle informazioni che indicano se l'area viene riconosciuta come o columnHeader meno. Il modello supporta l'estrazione di tabelle ruotate. Ogni cella della tabella contiene le coordinate dell'indice di riga e della colonna e del delimitazione del poligono. Per il testo della cella, il modello restituisce le span informazioni contenenti l'indice iniziale (offset). Il modello restituisce anche l'oggetto length all'interno del contenuto di primo livello che contiene il testo completo del documento.
Nota
La tabella non è supportata se il file di input è XLSX.
{
"tables": [
{
"rowCount": 9,
"columnCount": 4,
"cells": [
{
"kind": "columnHeader",
"rowIndex": 0,
"columnIndex": 0,
"columnSpan": 4,
"content": "(In millions, except earnings per share)",
"boundingRegions": [],
"spans": []
},
]
}
]
}
Annotazioni (disponibili solo nell'API 2023-02-28-preview ).
Il modello Layout estrae annotazioni nei documenti, ad esempio controlli e incroci. La risposta include il tipo di annotazione, insieme a un punteggio di attendibilità e al poligono di delimitazione.
{
"pages": [
{
"annotations": [
{
"kind": "cross",
"polygon": [...],
"confidence": 1
}
]
}
]
}
Output in formato markdown
L'API Layout può restituire il testo estratto in formato markdown. outputContentFormat=markdown Utilizzare per specificare il formato di output in markdown. Il contenuto markdown viene restituito come parte della content sezione.
"analyzeResult": {
"apiVersion": "2024-02-29-preview",
"modelId": "prebuilt-layout",
"contentFormat": "markdown",
"content": "# CONTOSO LTD...",
}
Figure
Le figure (grafici, immagini) nei documenti svolgono un ruolo fondamentale nell'integrare e migliorare il contenuto testuale, fornendo rappresentazioni visive che facilitano la comprensione di informazioni complesse. L'oggetto figure rilevato dal modello Layout ha proprietà chiave come boundingRegions (le posizioni spaziali della figura nelle pagine del documento, inclusi il numero di pagina e le coordinate poligono che delineano il limite della figura), spans (dettaglia gli intervalli di testo correlati alla figura, specificando gli offset e le lunghezze all'interno del testo del documento. Questa connessione consente di associare la figura al relativo contesto testuale pertinente), elements (identificatori per elementi di testo o paragrafi all'interno del documento correlati o descrivere la figura) e caption se presente.
{
"figures": [
{
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15",
...
],
"caption": {
"content": "Here is a figure with some text",
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15"
]
}
}
]
}
Sezioni
L'analisi gerarchica della struttura dei documenti è fondamentale per organizzare, comprendere ed elaborare documenti estesi. Questo approccio è fondamentale per segmentare semanticamente i documenti lunghi per migliorare la comprensione, facilitare la navigazione e migliorare il recupero delle informazioni. L'avvento della generazione aumentata di recupero (RAG) in un documento di intelligenza artificiale generativa sottolinea il significato dell'analisi gerarchica della struttura dei documenti. Il modello Layout supporta sezioni e sottosezioni nell'output, che identifica la relazione di sezioni e oggetti all'interno di ogni sezione. La struttura gerarchica viene mantenuta in elements ogni sezione. È possibile usare l'output per formattare markdown per ottenere facilmente le sezioni e le sottosezioni in markdown.
{
"sections": [
{
"spans": [],
"elements": [
"/paragraphs/0",
"/sections/1",
"/sections/2",
"/sections/5"
]
},
...
}
Output dell'ordine di lettura naturale (solo alfabeto latino)
È possibile specificare l'ordine in cui vengono restituite le righe di testo con il readingOrder parametro di query. Usare natural per un output dell'ordine di lettura più semplice, come illustrato nell'esempio seguente. Questa funzionalità è supportata solo per le lingue latine.

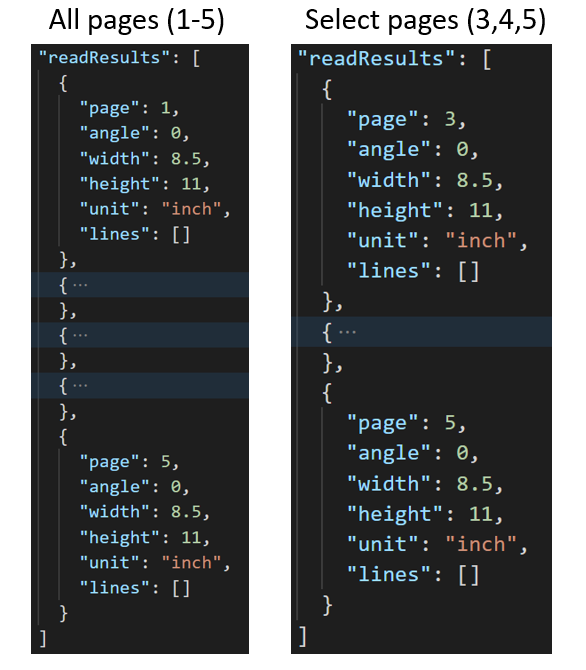
Selezionare numeri di pagina o intervalli per l'estrazione di testo
Per i documenti a più pagine di grandi dimensioni, usare il pages parametro di query per indicare numeri di pagina o intervalli di pagine specifici per l'estrazione di testo. L'esempio seguente mostra un documento con 10 pagine, con testo estratto per entrambi i casi: tutte le pagine (1-10) e le pagine selezionate (3-6).
Operazione Get Analyze Layout Result
Il secondo passaggio consiste nel chiamare l'operazione Get Analyze Layout Result .The second step is to call the Get Analyze Layout Result operation. Questa operazione accetta come input l'ID risultato creato dall'operazione Analyze Layout . Restituisce una risposta JSON che contiene un campo di stato con i valori possibili seguenti.
| Campo | Type | Possibili valori |
|---|---|---|
| stato | string | notStarted: l'operazione di analisi non è stata avviata.running L'operazione di analisi è in corso.failed Operazione di analisi non riuscita.succeeded Operazione di analisi riuscita. |
Chiamare questa operazione in modo iterativo fino a quando non restituisce il succeeded valore. Per evitare di superare la frequenza delle richieste al secondo (RPS), usare un intervallo da 3 a 5 secondi.
Quando il campo di stato ha il succeeded valore, la risposta JSON include il layout estratto, il testo, le tabelle e i segni di selezione. I dati estratti includono righe di testo estratte e parole, rettangoli delimitatori, aspetto del testo con indicazioni scritte a mano, tabelle e segni di selezione con indicato selezionato/non selezionato.
Classificazione scritta a mano per le righe di testo (solo alfabeto latino)
La risposta include la classificazione di ogni riga di testo dello stile di scrittura manuale o meno, insieme a un punteggio di attendibilità. Questa funzionalità è supportata solo per le lingue latine. Nell'esempio seguente viene illustrata la classificazione scritta a mano per il testo nell'immagine.

Output JSON di esempio
La risposta all'operazione Get Analyze Layout Result è una rappresentazione strutturata del documento con tutte le informazioni estratte. Vedere qui per un file di documento di esempio e il relativo output di layout di esempio di output strutturato.
L'output JSON ha due parti:
readResultsnode contiene tutto il testo riconosciuto e il segno di selezione. La gerarchia di presentazione del testo è pagina, quindi riga, quindi singole parole.pageResultsil nodo contiene le tabelle e le celle estratte con i rettangoli delimitatori, l'attendibilità e un riferimento alle righe e alle parole nel campo "readResults".
Output esempio
Testo
L'API Layout estrae testo da documenti e immagini con più angoli e colori di testo. Accetta foto di documenti, fax, testo stampato e/o scritto a mano (solo inglese) e modalità miste. Il testo viene estratto con informazioni fornite su righe, parole, rettangoli di delimitazione, punteggi di attendibilità e stile (scritti a mano o altro). Tutte le informazioni di testo sono incluse nella readResults sezione dell'output JSON.
Tabelle con intestazioni
L'API layout estrae le tabelle nella pageResults sezione dell'output JSON. I documenti possono essere analizzati, fotografati o digitalizzati. Le tabelle possono essere complesse con celle o colonne unite, con o senza bordi e con angoli dispari. Le informazioni sulla tabella estratte includono il numero di colonne e righe, intervallo di righe e intervallo di colonne. Ogni cella con il relativo rettangolo di delimitazione viene restituita insieme al fatto che l'area venga riconosciuta come parte di un'intestazione o meno. Le celle di intestazione stimate del modello possono estendersi su più righe e non sono necessariamente le prime righe di una tabella. Funzionano anche con tabelle ruotate. Ogni cella della tabella include anche il testo completo con riferimenti alle singole parole della readResults sezione.
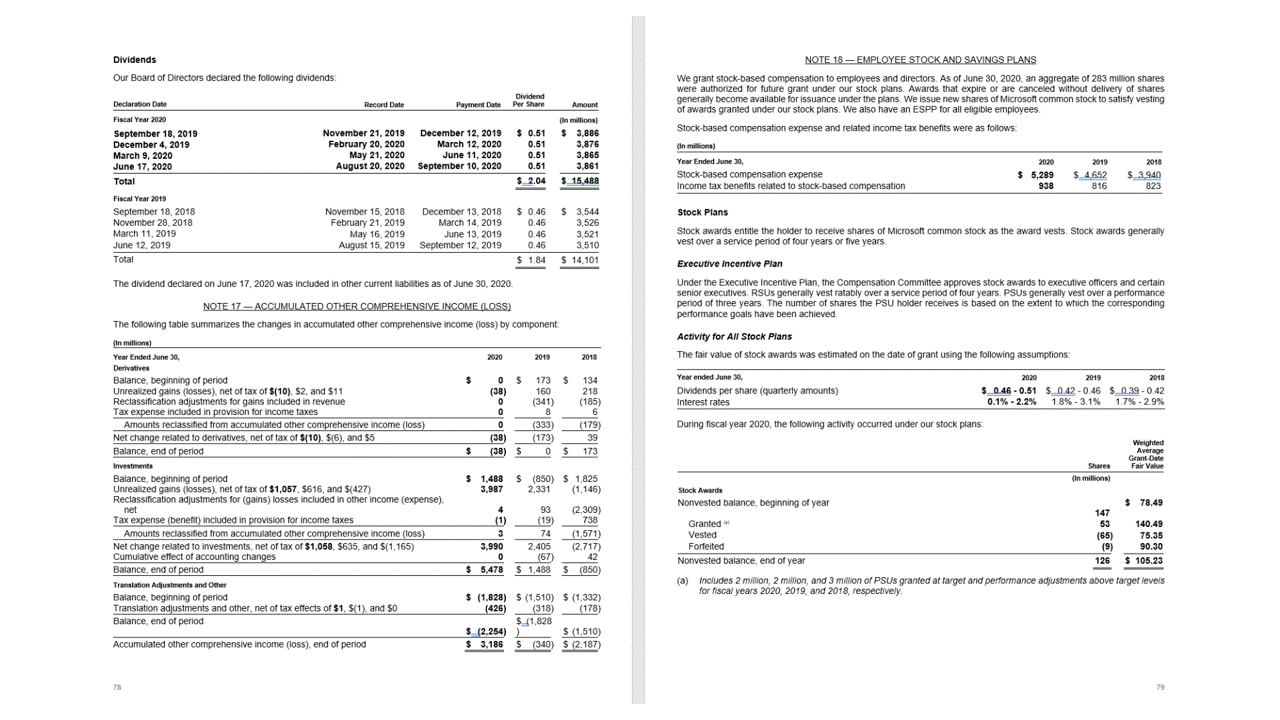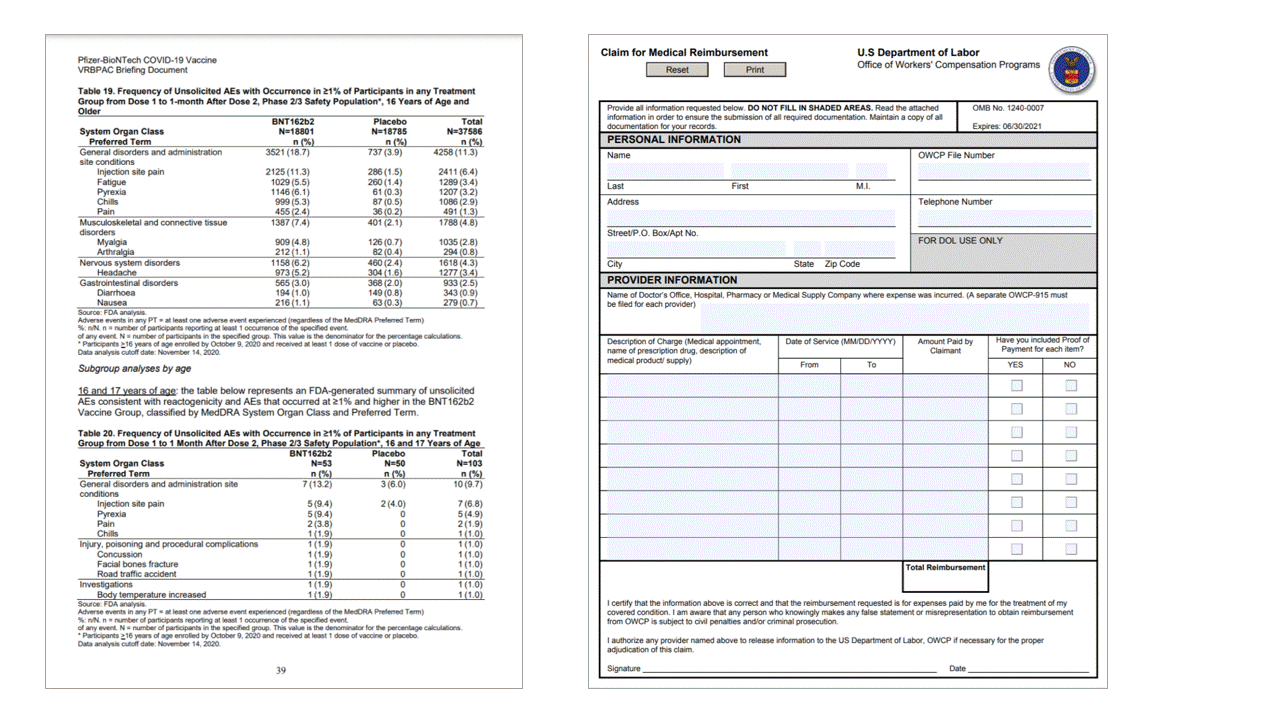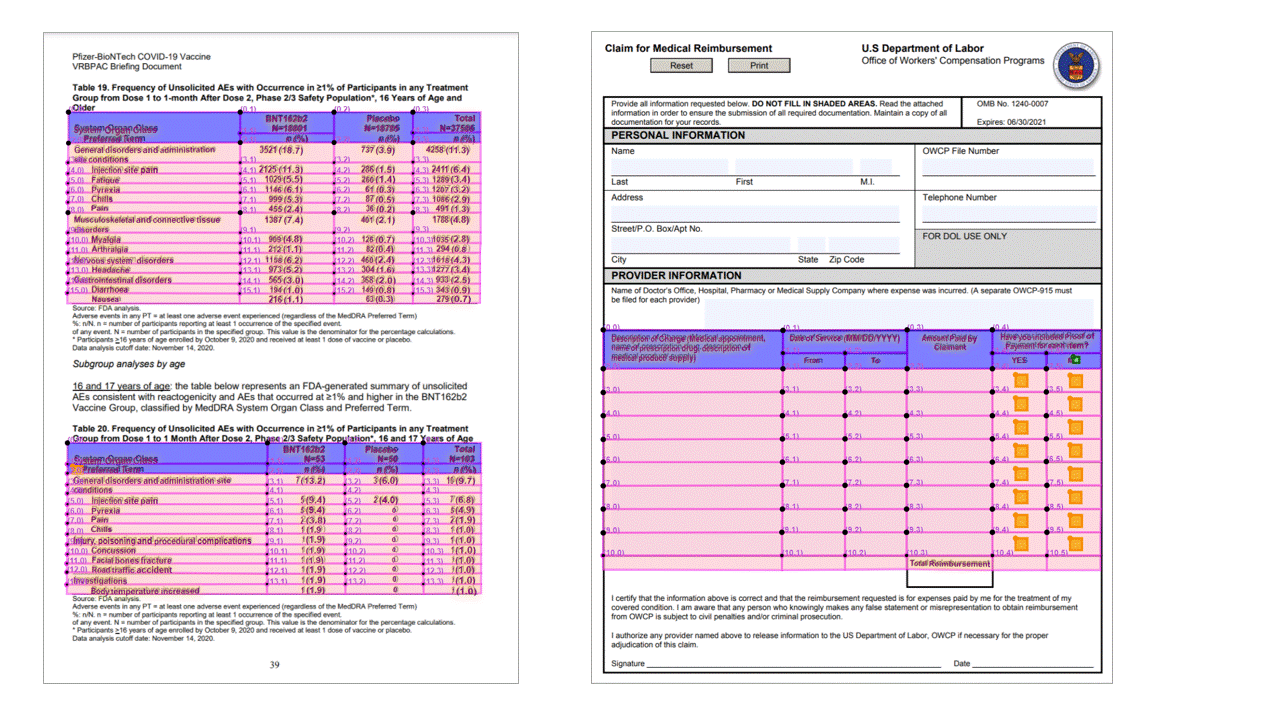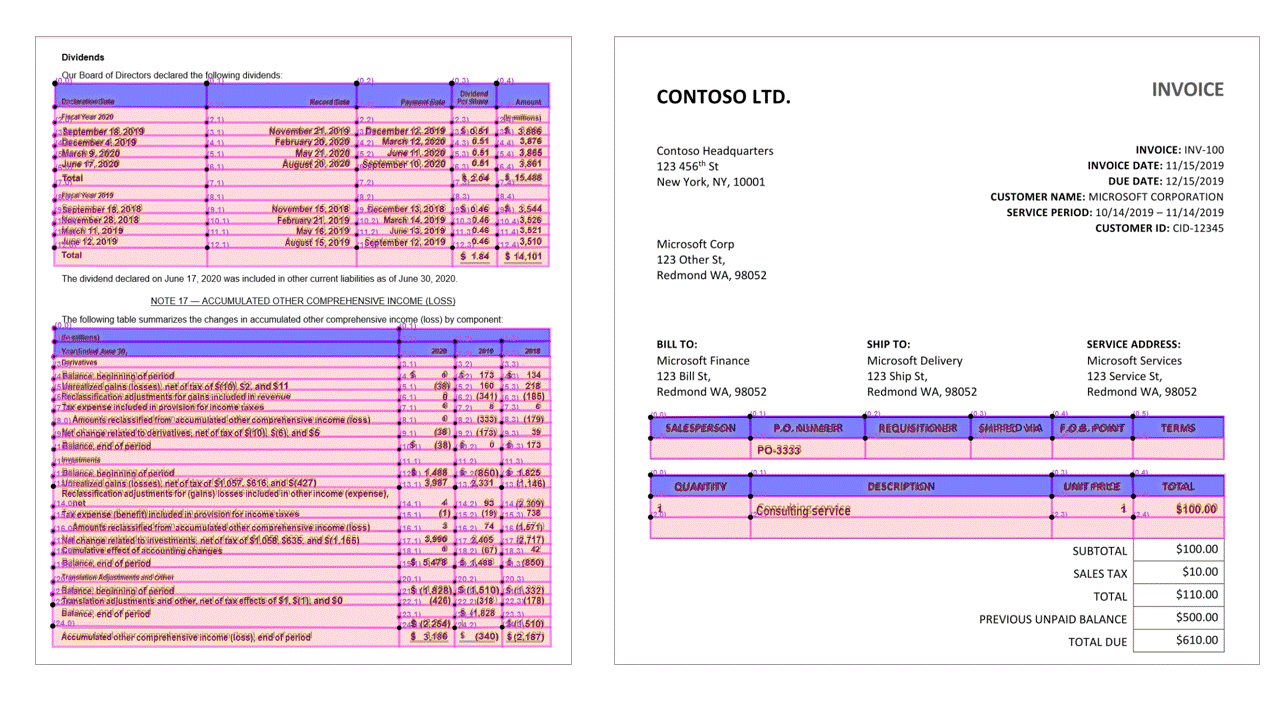
Opzioni di selezione
L'API layout estrae anche i segni di selezione dai documenti. I segni di selezione estratti includono il rettangolo di selezione, la confidenza e lo stato selezionati/non selezionati. Le informazioni sul contrassegno di selezione vengono estratte nella readResults sezione dell'output JSON.
Guida alla migrazione
Passaggi successivi
Informazioni su come elaborare moduli e documenti personalizzati con Document Intelligence Studio.
Completare una guida introduttiva di Intelligence sui documenti e iniziare a creare un'app per l'elaborazione di documenti nel linguaggio di sviluppo preferito.
Informazioni su come elaborare moduli e documenti personalizzati con lo strumento di etichettatura degli esempi di analisi dei documenti.
Completare una guida introduttiva di Intelligence sui documenti e iniziare a creare un'app per l'elaborazione di documenti nel linguaggio di sviluppo preferito.