Questo articolo descrive un'architettura che usa Azure Machine Learning per stimare la delinquenza e le probabilità predefinite dei candidati ai prestiti. Le stime del modello si basano sul comportamento fiscale del richiedente. Il modello usa un set enorme di punti dati per classificare i candidati e fornire un punteggio di idoneità per ogni richiedente.
Apache®, Spark e il logo flame sono marchi o marchi registrati di Apache Software Foundation nei Stati Uniti e/o in altri paesi. Nessuna approvazione da parte di Apache Software Foundation è implicita dall'uso di questi marchi.
Architecture

Scaricare un file di Visio di questa architettura.
Flusso di dati
Il flusso di dati seguente corrisponde al diagramma precedente:
Archiviazione: i dati vengono archiviati in un database come un pool di Azure Synapse Analytics, se strutturato. I database SQL meno recenti possono essere integrati nel sistema. I dati semistrutturati e non strutturati possono essere caricati in un data lake.
Inserimento e pre-elaborazione: le pipeline di elaborazione di Azure Synapse Analytics e l'elaborazione ETL possono connettersi ai dati archiviati in Azure o origini di terze parti tramite connettori predefiniti. Azure Synapse Analytics supporta più metodologie di analisi che usano SQL, Spark, Azure Esplora dati e Power BI. È anche possibile usare l'orchestrazione di Azure Data Factory esistente per le pipeline di dati.
Elaborazione: Azure Machine Learning viene usato per sviluppare e gestire i modelli di Machine Learning.
Elaborazione iniziale: durante questa fase, i dati non elaborati vengono elaborati per creare un set di dati curato che eseguirà il training di un modello di Machine Learning. Le operazioni tipiche includono la formattazione dei tipi di dati, l'imputazione dei valori mancanti, la progettazione delle caratteristiche, la selezione delle caratteristiche e la riduzione della dimensionalità.
Training: durante la fase di training, Azure Machine Learning usa il set di dati elaborato per eseguire il training del modello di rischio di credito e selezionare il modello migliore.
Training del modello: è possibile usare una gamma di modelli di Machine Learning, tra cui modelli classici di Machine Learning e Deep Learning. È possibile usare l'ottimizzazione degli iperparametri per ottimizzare le prestazioni del modello.
Valutazione del modello: Azure Machine Learning valuta le prestazioni di ogni modello sottoposto a training in modo da poter selezionare quello migliore per la distribuzione.
Registrazione del modello: registrare il modello che offre prestazioni ottimali in Azure Machine Learning. Questo passaggio rende disponibile il modello per la distribuzione.
c. IA responsabile: l'IA responsabile è un approccio allo sviluppo, alla valutazione e alla distribuzione di sistemi di IA in modo sicuro, affidabile ed etico. Poiché questo modello deduce un'approvazione o una decisione di rifiuto per una richiesta di prestito, è necessario implementare i principi dell'IA responsabile.
Le metriche di equità valutano l'effetto del comportamento ingiusto e consentono strategie di mitigazione. Le caratteristiche e gli attributi sensibili vengono identificati nel set di dati e nelle coorti (subset) dei dati. Per altre informazioni, vedere Prestazioni del modello e equità.
L'interpretazione è una misura del modo in cui è possibile comprendere il comportamento di un modello di Machine Learning. Questo componente dell'intelligenza artificiale responsabile genera descrizioni comprensibili delle stime del modello. Per altre informazioni, vedere Interpretazione del modello.
Distribuzione di Machine Learning in tempo reale: è necessario usare l'inferenza del modello in tempo reale quando la richiesta deve essere esaminata immediatamente per l'approvazione.
- Endpoint online di Machine Learning gestito. Per l'assegnazione dei punteggi in tempo reale, è necessario scegliere una destinazione di calcolo appropriata.
- Le richieste online per i prestiti usano l'assegnazione di punteggi in tempo reale in base all'input del modulo richiedente o della domanda di prestito.
- La decisione e l'input usati per l'assegnazione dei punteggi del modello vengono archiviati nell'archiviazione permanente e possono essere recuperati per riferimento futuro.
Distribuzione di Machine Learning in Batch: per l'elaborazione dei prestiti offline, il modello è pianificato per l'attivazione a intervalli regolari.
- Endpoint batch gestito. L'inferenza batch è pianificata e viene creato il set di dati dei risultati. Le decisioni sono basate sull'affidabilità del richiedente.
- Il set di risultati di assegnazione dei punteggi dall'elaborazione batch viene salvato in modo permanente nel database o nel data warehouse di Azure Synapse Analytics.
Interfaccia ai dati sull'attività del richiedente: i dettagli inseriti dal richiedente, il profilo di credito interno e la decisione del modello vengono tutti gestiti e archiviati in servizi dati appropriati. Questi dettagli vengono usati nel motore decisionale per l'assegnazione dei punteggi futuri, quindi sono documentati.
- Archiviazione: tutti i dettagli dell'elaborazione del credito vengono conservati nell'archiviazione permanente.
- Interfaccia utente: la decisione di approvazione o negazione viene presentata al richiedente.
Creazione di report: le informazioni dettagliate in tempo reale sul numero di applicazioni elaborate e approvare o negare i risultati vengono presentate continuamente ai manager e ai responsabili. Esempi di report includono report quasi in tempo reale degli importi approvati, il portafoglio di prestiti creato e le prestazioni del modello.
Componenti
- Archiviazione BLOB di Azure fornisce un archivio oggetti scalabile per i dati non strutturati. È ottimizzato per l'archiviazione di file come file binari, log attività e file che non rispettano un formato specifico.
- Azure Data Lake Archiviazione è la base di archiviazione per la creazione di data lake convenienti in Azure. Fornisce l'archiviazione BLOB con una struttura gerarchica di cartelle e prestazioni, gestione e sicurezza migliorate. Offre più petabyte di informazioni, sostenendo centinaia di gigabit di velocità effettiva.
- Azure Synapse Analytics è un servizio di analisi che riunisce le migliori tecnologie SQL e Spark e un'esperienza utente unificata per Azure Synapse Esplora dati e pipeline. Si integra con Power BI, Azure Cosmos DB e Azure Machine Learning. Il servizio supporta modelli di risorse dedicati e serverless e la possibilità di passare da un modello all'altro.
- database SQL di Azure è un database relazionale completamente aggiornato e completamente gestito creato per il cloud.
- Azure Machine Learning è un servizio cloud per la gestione dei cicli di vita dei progetti di Machine Learning . Offre un ambiente integrato per l'esplorazione dei dati, la creazione e la gestione dei modelli e la distribuzione e supporta approcci code-first e low-code/no-code all'apprendimento automatico.
- Power BI è uno strumento di visualizzazione che offre un'integrazione semplice con le risorse di Azure.
- app Azure Servizio consente di compilare e ospitare app Web, back-end per dispositivi mobili e API RESTful senza gestire l'infrastruttura. I linguaggi supportati includono .NET, .NET Core, Java, Ruby, Node.js, PHP e Python.
Alternative
È possibile usare Azure Databricksper sviluppare, distribuire e gestire modelli di Machine Learning e carichi di lavoro di analisi. Il servizio fornisce un ambiente unificato per lo sviluppo di modelli.
Dettagli dello scenario
Le organizzazioni del settore finanziario devono prevedere il rischio di credito di individui o aziende che richiedono credito. Questo modello valuta la delinquenza e le probabilità predefinite dei richiedenti prestiti.
La stima del rischio di credito implica un'analisi approfondita del comportamento della popolazione e la classificazione della base clienti in segmenti basati sulla responsabilità fiscale. Altre variabili includono fattori di mercato e condizioni economiche, che hanno un impatto significativo sui risultati.
Sfide. I dati di input includono decine di milioni di profili cliente e dati relativi al comportamento del credito dei clienti e alle abitudini di spesa basate su miliardi di record provenienti da sistemi diversi, ad esempio sistemi di attività interni dei clienti. I dati di terze parti sulle condizioni economiche e l'analisi del mercato del paese/area geografica possono provenire da snapshot mensili o trimestrali che richiedono il caricamento e la manutenzione di centinaia di GB di file. Sono necessarie informazioni sul richiedente o sulle righe semistrutturate dei dati dei clienti e sui cross join tra questi set di dati e controlli di qualità per convalidare l'integrità dei dati.
I dati sono in genere costituiti da tabelle a colonne estese di informazioni sui clienti provenienti da uffici di credito insieme all'analisi del mercato. L'attività del cliente è costituita da record con layout dinamico che potrebbero non essere strutturati. I dati sono disponibili anche in formato libero nelle note del servizio clienti e nei moduli di interazione dei candidati.
L'elaborazione di questi grandi volumi di dati e la garanzia che i risultati siano correnti richiedono un'elaborazione semplificata. È necessario un processo di archiviazione e recupero a bassa latenza. L'infrastruttura dati deve essere in grado di ridimensionare per supportare origini dati diverse e fornire la possibilità di gestire e proteggere il perimetro dei dati. La piattaforma di Machine Learning deve supportare l'analisi complessa dei numerosi modelli sottoposti a training, test e convalidati in molti segmenti di popolazione.
Riservatezza e privacy dei dati. L'elaborazione dei dati per questo modello implica dati personali e dettagli demografici. È necessario evitare la profilatura delle popolazioni. È necessario limitare la visibilità diretta a tutti i dati personali. Esempi di dati personali includono numeri di conto, dettagli della carta di credito, numeri di previdenza sociale, nomi, indirizzi e codici postali.
I numeri di carta di credito e conto corrente bancario devono essere sempre offuscati. Alcuni elementi di dati devono essere mascherati e sempre crittografati, senza accedere alle informazioni sottostanti, ma disponibili per l'analisi.
I dati devono essere crittografati inattivi, in transito e durante l'elaborazione tramite enclave sicuri. L'accesso agli elementi di dati viene registrato in una soluzione di monitoraggio. Il sistema di produzione deve essere configurato con pipeline CI/CD appropriate con approvazioni che attivano distribuzioni e processi del modello. Il controllo dei log e del flusso di lavoro deve fornire le interazioni con i dati per qualsiasi esigenza di conformità.
In elaborazione. Questo modello richiede una potenza di calcolo elevata per l'analisi, la contestualizzazione e il training e la distribuzione del modello. L'assegnazione dei punteggi del modello viene convalidata in base a campioni casuali per garantire che le decisioni di credito non includano alcuna razza, sesso, etnia o distorsione della posizione geografica. Il modello decisionale deve essere documentato e archiviato per riferimento futuro. Ogni fattore coinvolto nei risultati delle decisioni viene archiviato.
L'elaborazione dei dati richiede un utilizzo elevato della CPU. Include l'elaborazione SQL di dati strutturati in formato DB e JSON, l'elaborazione spark dei frame di dati o l'analisi di Big Data su terabyte di informazioni in diversi formati di documento. I processi ELT/ETL dei dati vengono pianificati o attivati a intervalli regolari o in tempo reale, a seconda del valore dei dati più recenti.
Framework di conformità e normative. Ogni dettaglio dell'elaborazione dei prestiti deve essere documentato, tra cui l'applicazione inviata, le funzionalità usate nell'assegnazione dei punteggi del modello e il set di risultati del modello. Le informazioni di training del modello, i dati usati per il training e i risultati di training devono essere registrati per le future richieste di riferimento e controllo e conformità.
Batch rispetto all'assegnazione dei punteggi in tempo reale. Alcune attività sono proattive e possono essere elaborate come processi batch, ad esempio trasferimenti di saldo pre-approvati. Alcune richieste, ad esempio l'aumento della riga di credito online, richiedono l'approvazione in tempo reale.
L'accesso in tempo reale allo stato delle richieste di prestito online deve essere disponibile per il richiedente. L'istituto finanziario emittente di prestiti monitora continuamente le prestazioni del modello di credito e necessita di informazioni dettagliate sulle metriche come lo stato di approvazione dei prestiti, il numero di prestiti approvati, gli importi in dollari emessi e la qualità delle nuove origini dei prestiti.
IA responsabile
Il dashboard Di intelligenza artificiale responsabile offre un'unica interfaccia per più strumenti che consentono di implementare l'intelligenza artificiale responsabile. Lo standard di intelligenza artificiale responsabile si basa su sei principi:
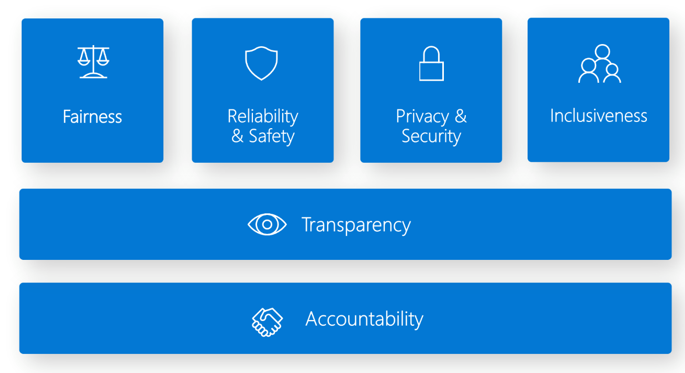
Equità e inclusività in Azure Machine Learning. Questo componente del dashboard dell'intelligenza artificiale responsabile consente di valutare comportamenti ingiusti evitando danni all'allocazione e ai danni della qualità del servizio. È possibile usarlo per valutare l'equità tra gruppi sensibili definiti in termini di sesso, età, etnia e altre caratteristiche. Durante la valutazione, l'equità viene quantificata tramite metriche di disparità. È necessario implementare gli algoritmi di mitigazione nel pacchetto open source Fairlearn , che usano vincoli di parità.
Affidabilità e sicurezza in Azure Machine Learning. Il componente di analisi degli errori dell'intelligenza artificiale responsabile consente di:
- Acquisire una conoscenza approfondita del modo in cui viene distribuito l'errore per un modello.
- Identificare le coorti di dati con una frequenza di errore superiore rispetto al benchmark complessivo.
Trasparenza in Azure Machine Learning. Una parte fondamentale della trasparenza è comprendere in che modo le funzionalità influiscono sul modello di Machine Learning.
- L'interpretazione del modello consente di comprendere cosa influisce sul comportamento del modello. Genera descrizioni comprensibili delle stime del modello. Questa comprensione consente di garantire che sia possibile considerare attendibile il modello e consente di eseguire il debug e migliorarlo. InterpretML consente di comprendere la struttura dei modelli in scatola di vetro o la relazione tra le caratteristiche nei modelli di rete neurale profonda black box.
- Simulazione controfactuale consente di comprendere ed eseguire il debug di un modello di Machine Learning in termini di reazione alle modifiche e alle perturbazioni delle funzionalità.
Privacy e sicurezza in Azure Machine Learning. Gli amministratori di Machine Learning devono creare una configurazione sicura per sviluppare e gestire la distribuzione dei modelli. Le funzionalità di sicurezza e governance consentono di rispettare i criteri di sicurezza dell'organizzazione. Altri strumenti consentono di valutare e proteggere i modelli.
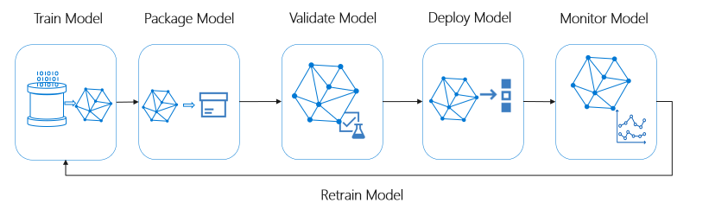
Responsabilità in Azure Machine Learning. Le operazioni di Machine Learning (MLOps) si basano su principi e procedure DevOps che aumentano l'efficienza dei flussi di lavoro di intelligenza artificiale. Azure Machine Learning consente di implementare le funzionalità MLOps:
- Registrare, creare pacchetti e distribuire modelli
- Ottenere notifiche e avvisi per le modifiche nei modelli
- Acquisire i dati di governance per il ciclo di vita end-to-end
- Monitorare le applicazioni per i problemi operativi
Questo diagramma illustra le funzionalità MLOps di Azure Machine Learning:
Potenziali casi d'uso
È possibile applicare questa soluzione agli scenari seguenti:
- Finanza: ottenere l'analisi finanziaria dei clienti o l'analisi cross-sales dei clienti per campagne di marketing mirate.
- Assistenza sanitaria: usare le informazioni sui pazienti come input per suggerire offerte di trattamento.
- Ospitalità: creare un profilo cliente per suggerire offerte per alberghi, voli, pacchetti di crociera e appartenenze.
Considerazioni
Queste considerazioni implementano i pilastri di Azure Well-Architected Framework, che è un set di set di principi guida che è possibile usare per migliorare la qualità di un carico di lavoro. Per altre informazioni, vedere Framework ben progettato di Microsoft Azure.
Sicurezza
La sicurezza offre garanzie contro attacchi intenzionali e l'abuso di dati e sistemi preziosi. Per altre informazioni, vedere Panoramica del pilastro della sicurezza.
Le soluzioni di Azure offrono una difesa approfondita e un approccio Zero Trust.
Prendere in considerazione l'implementazione delle funzionalità di sicurezza seguenti in questa architettura:
- Distribuire servizi di Azure dedicati in reti virtuali
- database SQL di Azure funzionalità di sicurezza
- Proteggere le credenziali nella data factory usando Key Vault
- Sicurezza e governance aziendale per Azure Machine Learning
- Baseline di sicurezza di Azure per l'area di lavoro Synapse Analytics
Ottimizzazione dei costi
L'ottimizzazione dei costi riguarda la riduzione delle spese non necessarie e il miglioramento dell'efficienza operativa. Per altre informazioni, vedere Panoramica del pilastro di ottimizzazione dei costi.
Per stimare il costo di implementazione di questa soluzione, usare il calcolatore dei prezzi di Azure.
Considerare anche queste risorse:
- Pianificare e gestire i costi per Azure Synapse Analytics
- Pianificare e gestire i costi per Azure Machine Learning
Eccellenza operativa
L'eccellenza operativa copre i processi operativi che distribuiscono un'applicazione e la mantengono in esecuzione nell'ambiente di produzione. Per altre informazioni, vedere Panoramica del pilastro dell'eccellenza operativa.
Le soluzioni di Machine Learning devono essere scalabili e standardizzate per semplificare la gestione e la manutenzione. Assicurarsi che la soluzione supporti l'inferenza continua con cicli di ripetizione del training e ridistribuzioni automatizzate dei modelli.
Per altre informazioni, vedere Acceleratore di soluzioni Azure MLOps (v2).
Efficienza prestazionale
L'efficienza delle prestazioni è la capacità di dimensionare il carico di lavoro per soddisfare in modo efficiente le richieste poste dagli utenti. Per altre informazioni, vedere Panoramica dell'efficienza delle prestazioni.
- Per altre informazioni sulla progettazione di soluzioni scalabili, vedere Elenco di controllo per l'efficienza delle prestazioni.
- Per informazioni sui settori regolamentati, vedere Ridimensionare l'intelligenza artificiale e le iniziative di Machine Learning nei settori regolamentati.
- Gestire l'ambiente di Azure Synapse Analytics con pool SQL, Spark o SQL serverless.
Contributori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autore principale:
- Charitha Basani | Senior Cloud Solution Architect
Altro collaboratore:
- Mick Alberts | Writer tecnico
Per visualizzare i profili LinkedIn non pubblici, accedere a LinkedIn.
Passaggi successivi
- Baseline di sicurezza di Azure per Azure Machine Learning
- Azure Synapse Analytics
- Distribuire modelli di Machine Learning in Azure
- Che cos'è l'IA responsabile?