Ripristino di emergenza per un'applicazione SaaS multi-tenant con la replica geografica del database
Si applica a:![]() database SQL di Azure
database SQL di Azure
In questa esercitazione si esamina uno scenario completo di ripristino di emergenza per un'applicazione SaaS multi-tenant la cui implementazione usa il modello di database per tenant. Per proteggere l'app in caso di interruzione, si usa la replica geografica per creare repliche per i database di catalogo e tenant in un'area di ripristino alternativa. In caso di interruzione, è possibile effettuare rapidamente il failover a tali repliche per riprendere le normali operazioni aziendali. In caso di failover, i database nell'area originale diventano le repliche secondarie dei database nell'area di ripristino. Quando queste repliche ritornano online, si aggiornano automaticamente allo stato dei database nell'area di ripristino. Dopo che l'interruzione è stata risolta, si esegue il failback ai database nell'area di produzione originale.
Questa esercitazione illustra il flusso di lavoro sia di failover che di failback. Nello specifico:
- Sincronizzare le informazioni di configurazione dei database e dei pool elastici nel catalogo del tenant
- Configurare un ambiente di ripristino in un'area alternativa, che include applicazione, server e pool
- Usare la replica geografica per replicare i database di catalogo e tenant nell'area di ripristino
- Effettuare il failover dell'applicazione e dei database di catalogo e tenant nell'area di ripristino
- Successivamente, effettuare il failover dell'applicazione e dei database di catalogo e tenant di nuovo nell'area originale, dopo che l'interruzione è stata risolta
- Aggiornare il catalogo man mano che viene effettuato il failover di ogni database tenant per tenere traccia della località primaria di ogni database tenant.
- Verificare che l'applicazione e il database tenant primario si trovino sempre nella stessa area di Azure, per ridurre la latenza
Prima di iniziare questa esercitazione, verificare che siano soddisfatti i prerequisiti seguenti:
- È stata distribuita l'app SaaS di database per tenant Wingtip Tickets. Per eseguire la distribuzione in meno di cinque minuti, vedere Deploy and explore the Wingtip Tickets SaaS Database Per Tenant application (Distribuire ed esplorare l'applicazione del database per tenant SaaS Wingtip Tickets)
- Azure PowerShell è installato. Per informazioni dettagliate, vedere Introduzione ad Azure PowerShell
Introduzione al modello di ripristino della replica geografica
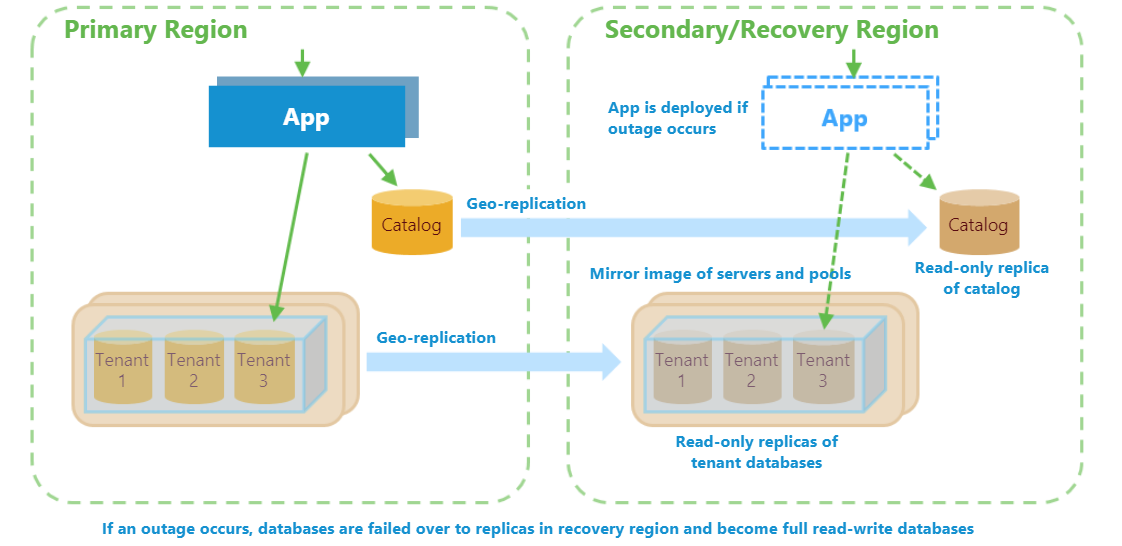
Il ripristino di emergenza è importante per molte applicazioni, per motivi di conformità o per garantire la continuità aziendale. In caso di interruzione prolungata del servizio, un piano di ripristino di emergenza adeguato può ridurre al minimo le interruzioni delle attività aziendali. L'uso della replica geografica offre i livelli più bassi per quanto riguarda obiettivo del punto di ripristino (RPO) e obiettivo del tempo di ripristino (RTO), perché le repliche dei database vengono mantenute in un'area in cui è possibile effettuare il failover con un breve preavviso.
Un piano di ripristino di emergenza basato sulla replica geografica è costituito da tre parti distinte:
- Configurazione: creazione e manutenzione dell'ambiente di ripristino
- Ripristino: failover dell'app e dei database nell'ambiente di ripristino se si verifica un'interruzione
- Ricollocamento: failover dell'app e dei database di nuovo nell'area originale dopo avere risolto il problema dell'applicazione
Tutte le parti devono essere considerate attentamente, in particolare se si opera su larga scala. Nel complesso, il piano deve soddisfare alcuni obiettivi:
- Configurazione
- Stabilire e mantenere un ambiente con un'immagine speculare nell'area di ripristino. Per creare pool elastici ed eseguire la replica di qualsiasi database in questo ambiente di ripristino è necessario riservare capacità nell'area di ripristino. La manutenzione di questo ambiente include la replica dei nuovi database tenant quando ne viene effettuato il provisioning.
- Recupero
- Nei casi in cui viene usato un ambiente di ripristino ridotto per ridurre al minimo i costi quotidiani, è necessario aumentare la capacità di pool e i database per consentire l'acquisizione della piena capacità operativa nell'area di ripristino
- Abilitare il provisioning dei nuovi tenant nell'area di ripristino non appena possibile.
- Essere ottimizzato per il ripristino dei tenant in ordine di priorità.
- Ottimizzare l'ambiente per portare i tenant online il più velocemente possibile eseguendo i passaggi in parallelo, dove possibile.
- Garantire resilienza agli errori, possibilità di riavvio e idempotenza.
- Consentire l'annullamento del processo mentre è in corso il trasferimento se l'area originale torna online.
- Ricollocamento
- Effettuare il failover dei database dall'area di ripristino alle repliche nell'area originale con un impatto minimo per i tenant: nessuna perdita di dati e un intervallo offline minimo per ogni tenant.
In questa esercitazione gli obiettivi appena elencati vengono soddisfatti usando le funzionalità del database SQL di Azure e della piattaforma Azure:
- Modelli di Azure Resource Manager, per riservare tutta la capacità necessaria il più rapidamente possibile. I modelli di Azure Resource Manager vengono usati per effettuare il provisioning di un'immagine speculare dei server di produzione e dei pool elastici nell'area di ripristino.
- Replica geografica, per creare repliche secondarie asincrone di sola lettura per tutti i database. Durante un'interruzione, effettuare il failover nelle repliche nell'area di ripristino. Dopo aver risolto l'interruzione, effettuare il failback nei database nell'area originale senza perdita di dati.
- Operazioni di failover asincrone inviate in ordine di priorità dei tenant, per ridurre al minimo il tempo di failover per un numero elevato di database.
- Funzionalità di ripristino della gestione delle partizioni, per modificare le voci di database nel catalogo durante il ripristino e il ricollocamento. Queste funzionalità consentono all'app di connettersi ai database tenant indipendentemente dalla posizione senza dover riconfigurare l'app.
- Alias DNS di SQL Server, per consentire un facile provisioning dei nuovi tenant indipendentemente dall'area in cui è in esecuzione l'app. Gli alias DNS vengono usati anche per consentire il processo di sincronizzazione del catalogo per la connessione al catalogo attivo indipendentemente dalla relativa posizione.
Ottenere gli script per il ripristino di emergenza
Importante
Come tutti gli script di gestione di Wingtip Tickets, gli script di ripristino di emergenza sono solo esempi e non devono essere usati nell'ambiente di produzione.
Gli script di ripristino usati in questa esercitazione e il codice sorgente dell'applicazione Wingtip sono disponibili nel repository GitHub della soluzione SaaS di database per tenant Wingtip Tickets. Leggere le linee guida generali per i passaggi da seguire per scaricare e sbloccare gli script di gestione di Wingtip Tickets.
Panoramica delle esercitazioni
In questa esercitazione si usa innanzitutto la replica geografica per creare repliche dell'applicazione Wingtip Tickets e dei relativi database in un'area diversa. Si effettua quindi il failover in quest'area per simulare il ripristino da un'interruzione. Al termine, l'applicazione è perfettamente funzionante nell'area di ripristino.
Successivamente, in un passaggio di ricollocamento distinto, si effettua il failover dei database di catalogo e tenant dall'area di ripristino all'area originale. L'applicazione e i database rimangono disponibili durante tutto il processo di ricollocamento. Al termine, l'applicazione è perfettamente funzionante nell'area originale.
Nota
L'applicazione viene ripristinata nell'area abbinata dell'area in cui l'applicazione è distribuita. Per altre informazioni, vedere Aree abbinate di Azure.
Esaminare lo stato di integrità dell'applicazione
Prima di iniziare il processo di ripristino, esaminare il normale stato di integrità dell'applicazione.
Nel Web browser aprire l'hub eventi di Wingtip Tickets all'indirizzo (http://events.wingtip-dpt.<utente>.trafficmanager.net. Sostituire <utente>) con il valore utente della distribuzione.
- Scorrere la pagina verso il basso e osservare il nome e la posizione del server di catalogo nella parte inferiore della pagina. La posizione corrisponde all'area in cui l'app è stata distribuita.
SUGGERIMENTO: passare il puntatore del mouse sulla posizione per ingrandire la visualizzazione.
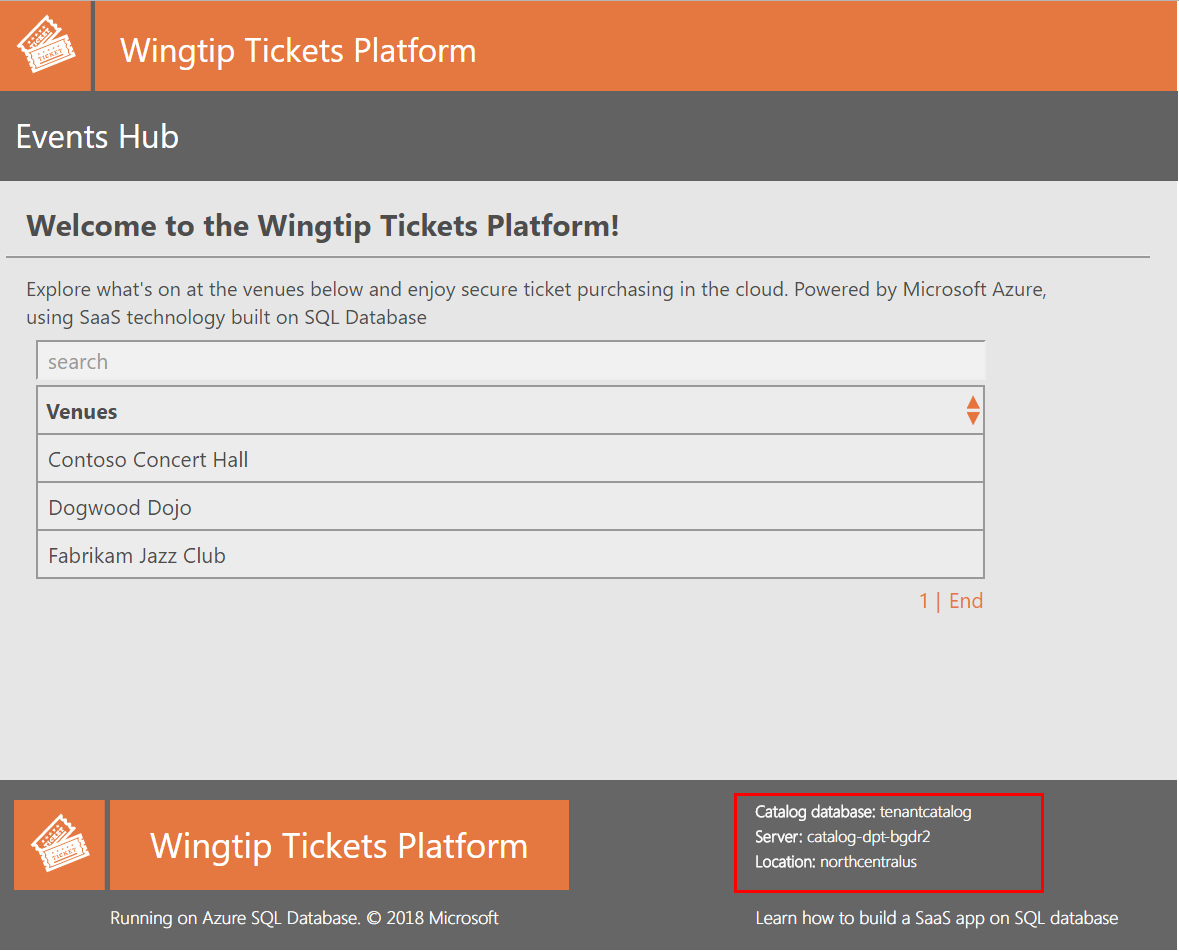
- Scorrere la pagina verso il basso e osservare il nome e la posizione del server di catalogo nella parte inferiore della pagina. La posizione corrisponde all'area in cui l'app è stata distribuita.
SUGGERIMENTO: passare il puntatore del mouse sulla posizione per ingrandire la visualizzazione.
Fare clic sul tenant Contoso Concert Hall e aprire la relativa pagina degli eventi.
- Nella parte inferiore della pagina osservare il nome del server tenant. La posizione corrisponderà a quella del server di catalogo.
Nel portale di Azure aprire il gruppo di risorse in cui è distribuita l'app
- Osservare l'area di distribuzione dei server.
Sincronizzare la configurazione dei tenant nel catalogo
In questa attività si avvia un processo che sincronizza la configurazione di server, pool elastici e database nel catalogo del tenant. Questo processo mantiene le informazioni aggiornate nel catalogo. Il processo funziona con il catalogo attivo, nell'area originale o nell'area di ripristino. Le informazioni di configurazione vengono usate nel processo di ripristino per garantire che l'ambiente di ripristino sia coerente con l'ambiente originale e quindi in un secondo momento durante il ricollocamento per garantire che l'area originale sia stata resa coerente con eventuali modifiche apportate nell'ambiente di ripristino. Il catalogo viene anche usato per tenere traccia dello stato di ripristino delle risorse del tenant
Importante
Per semplicità, il processo di sincronizzazione e gli altri processi di ripristino e ricollocamento a esecuzione prolungata vengono implementati in queste esercitazioni come processi di PowerShell locali o sessioni in esecuzione con l'account di accesso utente client. I token di autenticazione rilasciati al momento dell'accesso scadono dopo alcune ore e i processi avranno quindi esito negativo. In uno scenario di produzione i processi a esecuzione prolungata devono essere implementati come servizi di Azure affidabili di un determinato tipo, in esecuzione in un'entità servizio. Vedere Usare Azure PowerShell per creare un'entità servizio con un certificato.
In PowerShell ISE aprire il file ...\Learning Modules\UserConfig.psm1. Sostituire
<resourcegroup>e<user>alle righe 10 e 11 con il valore usato al momento della distribuzione dell'app. Salvare il file.In PowerShell ISE aprire lo script ...\Learning Modules\Business Continuity and Disaster Recovery\DR-FailoverToReplica\Demo-FailoverToReplica.ps1 e impostare:
- $DemoScenario = 1, per avviare un processo in background che esegue la sincronizzazione del server tenant e delle informazioni di configurazione dei pool nel catalogo.
Premere F5 per eseguire lo script di sincronizzazione. Viene aperta una nuova sessione di PowerShell per sincronizzare la configurazione delle risorse tenant.
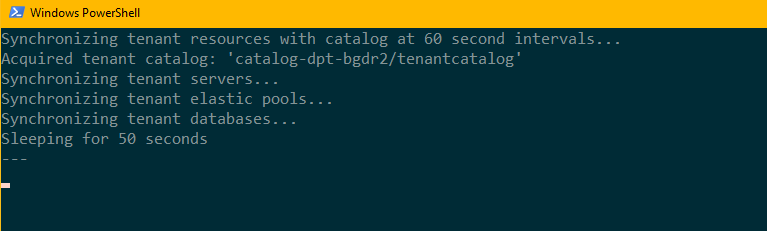
Lasciare la finestra di PowerShell in esecuzione in background e continuare con il resto dell'esercitazione.
Nota
Il processo di sincronizzazione si connette al catalogo tramite un alias DNS. Questo alias viene modificato durante il ripristino e il ricollocamento in modo da puntare al catalogo attivo. Il processo di sincronizzazione mantiene aggiornato il catalogo con le modifiche apportate alla configurazione dei database o dei pool nell'area di ripristino. Durante il ricollocamento, queste modifiche vengono applicate alle risorse equivalenti nell'area originale.
Creare repliche di database secondarie nell'area di ripristino
In questa attività si avvia un processo che consente di distribuire un'istanza di app duplicata e di replicare il catalogo e tutti i database tenant in un'area di ripristino.
Nota
Questa esercitazione aggiunge la protezione tramite replica geografica all'applicazione di esempio Wingtip Tickets. In uno scenario di produzione per un'applicazione che usa la replica geografica, per ogni tenant viene effettuato, fin dall'inizio, il provisioning di un database con replica geografica. Vedere Progettazione di servizi a disponibilità elevata con database SQL di Azure
In PowerShell ISE aprire lo script ...\Learning Modules\Business Continuity and Disaster Recovery\DR-FailoverToReplica\Demo-FailoverToReplica.ps1 e impostare i valori seguenti:
- $DemoScenario = 2, per creare un ambiente di ripristino con immagine speculare e replicare i database di catalogo e tenant
Premere F5 per eseguire lo script. Viene aperta una nuova sessione di PowerShell per creare le repliche.
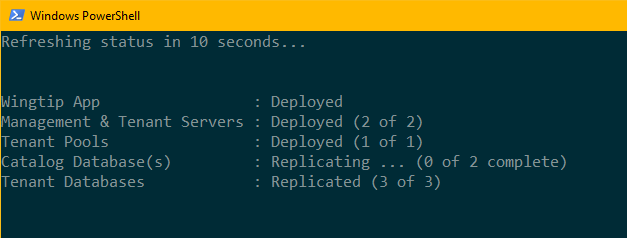
Esaminare il normale stato dell'applicazione
A questo punto, l'applicazione è in esecuzione normalmente nell'area originale ed è protetta tramite replica geografica. Nell'area di ripristino sono presenti repliche secondarie di sola lettura per tutti i database.
Nel portale di Azure esaminare i gruppi di risorse e osservare che è stato creato un gruppo di risorse con il suffisso -recovery nell'area di ripristino.
Esaminare le risorse nel gruppo di risorse di ripristino.
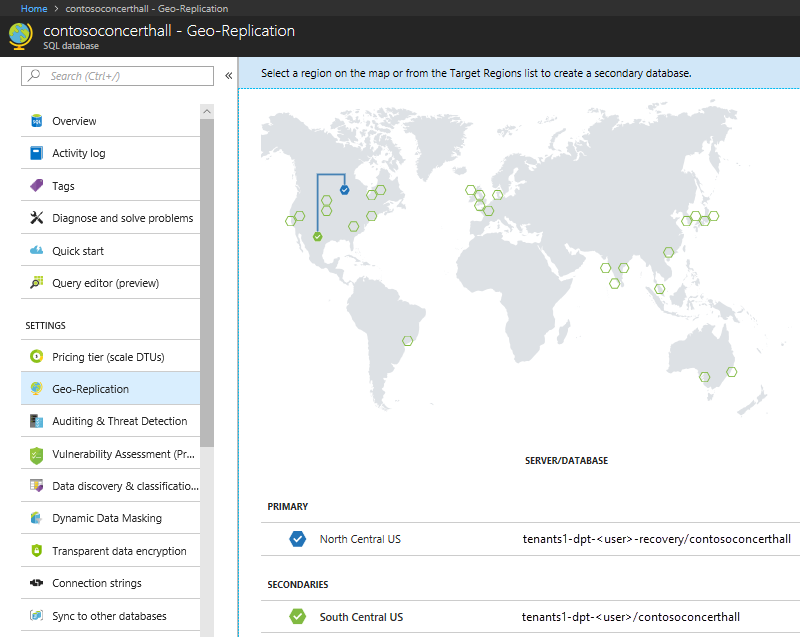
Fare clic sul database Contoso Concert Hall nel server tenants1-dpt-<utente>-recovery. Fare clic su Replica geografica a sinistra.
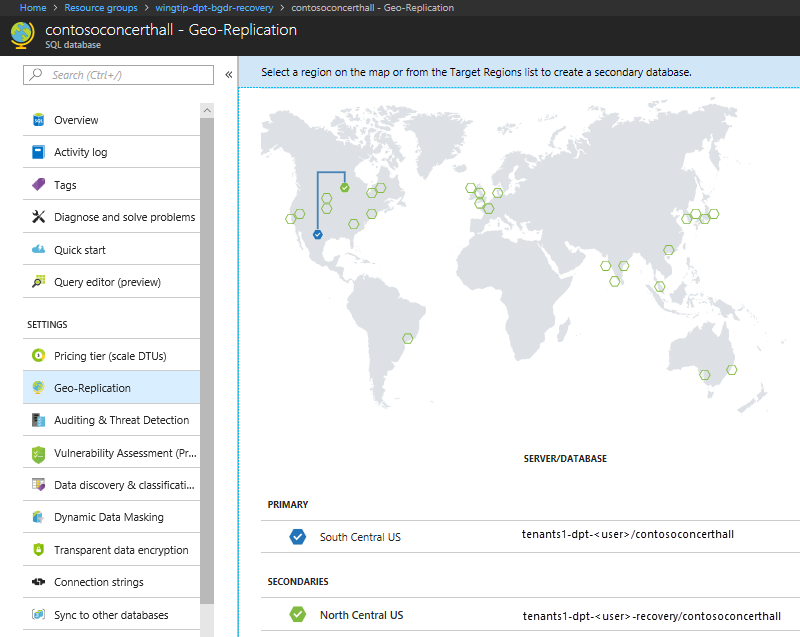
Nella mappa delle aree di Azure osservare il collegamento per la replica geografica tra il database primario nell'area originale e il database secondario nell'area di ripristino.
Effettuare il failover dell'applicazione nell'area di ripristino
Panoramica del processo di ripristino della replica geografica
Lo script di ripristino esegue le attività seguenti:
Disabilita l'endpoint di Gestione traffico per l'app Web nell'area di origine. La disabilitazione dell'endpoint impedisce agli utenti di connettersi all'app in uno stato non valido nel caso in cui l'area originale torni online durante il ripristino.
Usa un failover forzato del database di catalogo nell'area di ripristino per impostarlo come database primario e aggiorna l'alias activecatalog in modo che punti al server di catalogo di ripristino.
Aggiorna l'alias newtenant in modo che punti al server tenant nell'area di ripristino. Modificando questo alias si garantisce il provisioning dei database per i nuovi tenant nell'area di ripristino.
Contrassegna tutti i tenant esistenti nel catalogo di ripristino come offline per impedire l'accesso ai database tenant prima del failover.
Aggiorna la configurazione di tutti i pool elastici e i database singoli replicati nell'area di ripristino in modo da eseguire il mirroring della configurazione nell'area originale. Questa attività è necessaria solo se i pool o i database replicati nell'ambiente di ripristino sono stati ridotti durante il normale funzionamento per ridurre i costi.
Abilita l'endpoint Gestione traffico per l'app Web nell'area di ripristino. L'abilitazione di questo endpoint consente all'applicazione di effettuare il provisioning di nuovi tenant. In questa fase, i tenant esistenti sono ancora offline.
Invia batch di richieste per forzare il failover dei database in ordine di priorità.
- I batch sono organizzati in modo che il failover dei database venga eseguito in parallelo tra tutti i pool.
- Le richieste di failover vengono inviate usando operazioni asincrone, in modo che l'invio avvenga rapidamente e che più richieste possano essere elaborate simultaneamente.
Nota
In caso di interruzione, i database primari nell'area originale sono offline. Forzando il failover nel database secondario si interrompe la connessione al database primario senza tentativi di applicare eventuali transazioni in coda residue. In uno scenario di esercitazione sul ripristino di emergenza come questo, se sono in corso attività di aggiornamento al momento del failover potrebbe verificarsi una perdita di dati. In un secondo momento, durante il ricollocamento, quando si effettua il failover dei database dall'area di ripristino nuovamente nell'area originale, viene usato un failover normale per assicurarsi che non ci sia alcuna perdita di dati.
Monitora il servizio per determinare quando è stato eseguito il failover dei database. Dopo il failover di un database tenant, aggiorna il catalogo per registrare lo stato di ripristino del database tenant e contrassegnare il tenant come online.
- L'applicazione può accedere ai database tenant non appena vengono contrassegnati come online nel catalogo.
- Nel catalogo viene archiviata la somma dei valori rowversion per il database tenant. Questo valore funge da impronta digitale che consente al processo di ricollocamento di determinare se il database è stato aggiornato nell'area di ripristino.
Eseguire lo script per effettuare il failover nell'area di ripristino
Si supponga ora che si verifichi un'interruzione nell'area in cui l'applicazione è distribuita e che quindi si esegua lo script di ripristino:
In PowerShell ISE aprire lo script ...\Learning Modules\Business Continuity and Disaster Recovery\DR-FailoverToReplica\Demo-FailoverToReplica.ps1 e impostare i valori seguenti:
- $DemoScenario = 3, per ripristinare l'app in un'area di ripristino eseguendo il failover nelle repliche
Premere F5 per eseguire lo script.
- Lo script viene aperto in una nuova finestra di PowerShell e quindi avvia una serie di processi di PowerShell eseguiti in parallelo. Questi processi effettuano il failover dei database tenant nell'area di ripristino.
- L'area di ripristino è l'area abbinata all'area di Azure in cui è stata distribuita l'applicazione. Per altre informazioni, vedere Aree abbinate di Azure.
Monitorare lo stato del processo di ripristino nella finestra di PowerShell.
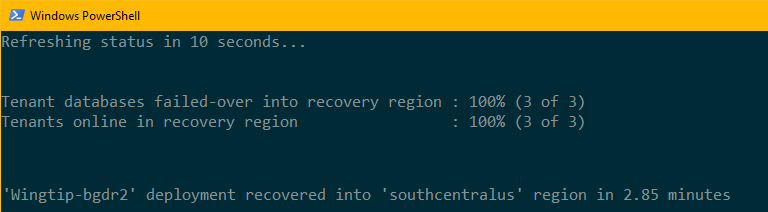
Nota
Per esplorare il codice per i processi di ripristino, esaminare gli script di PowerShell nella cartella ...\Learning Modules\Business Continuity and Disaster Recovery\DR-FailoverToReplica\RecoveryJobs.
Esaminare lo stato dell'applicazione durante il ripristino
Quando l'endpoint dell'applicazione è disabilitato in Gestione traffico, l'applicazione non è disponibile. Dopo il failover del catalogo nell'area del ripristino e dopo che tutti i tenant sono stati contrassegnati come offline, l'applicazione viene riportata online. Anche se l'applicazione è disponibile, ogni tenant appare offline nell'hub eventi fino a quando non viene effettuato il failover del relativo database. È importante progettare l'applicazione in modo da gestire i database tenant offline.
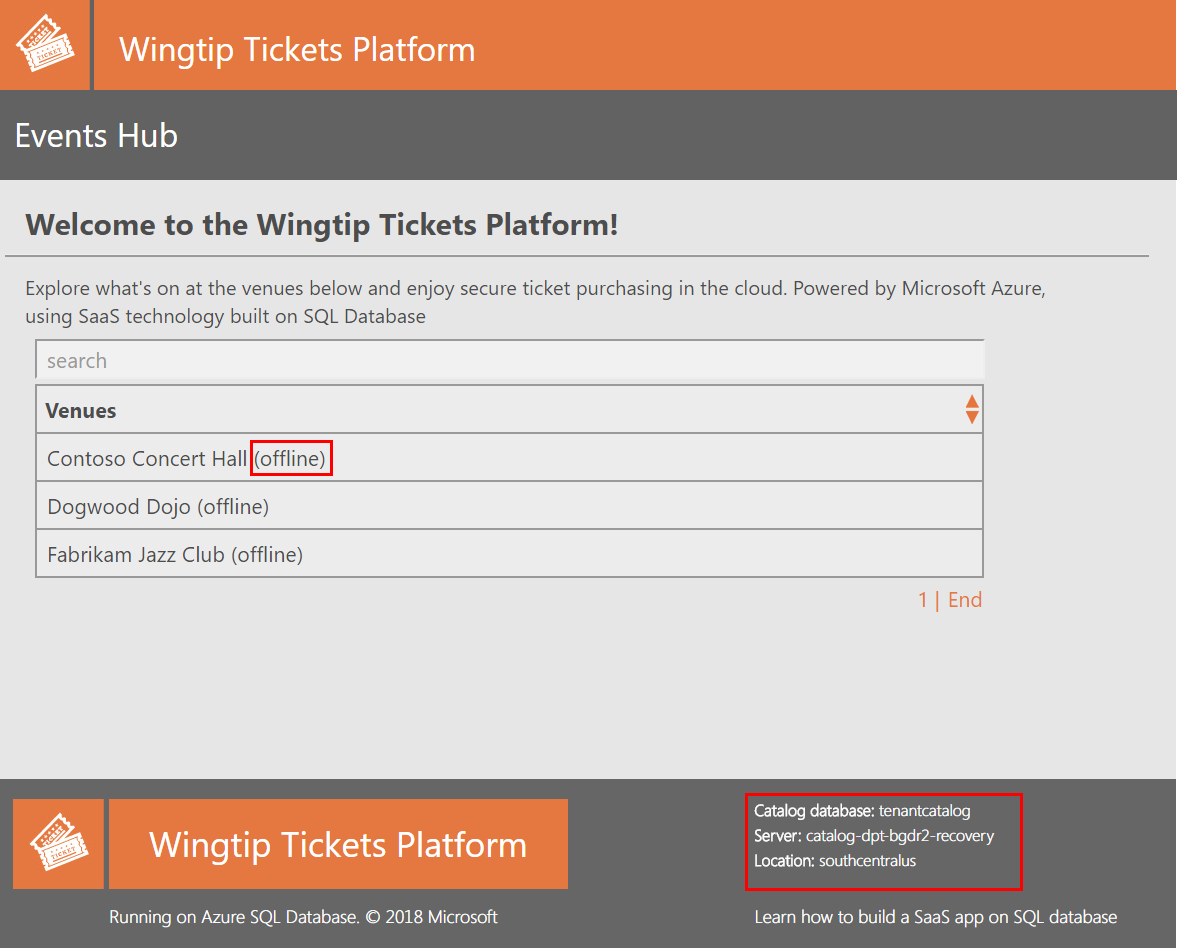
- Immediatamente dopo il ripristino del database di catalogo, aggiornare l'hub eventi di Wingtip Tickets nel Web browser.
Nella parte inferiore della pagina osservare che il nome del server di catalogo include ora un suffisso -recovery e si trova nell'area di ripristino.
Si noti che i tenant che non sono stati ancora ripristinati sono contrassegnati come offline e non sono selezionabili.
Nota
Se ci sono solo pochi database da ripristinare, potrebbe non essere possibile aggiornare il browser prima del completamento del ripristino e quindi si potrebbero non vedere i tenant mentre sono offline.
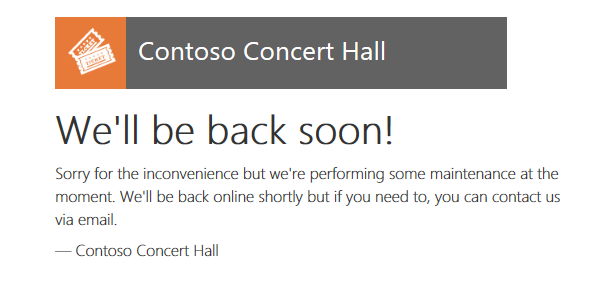
Se si apre direttamente la pagina degli eventi di un tenant offline, viene visualizza una notifica che indica che il tenant è offline. Se, ad esempio, Contoso Concert Hall è offline, provare ad aprire http://events.wingtip-dpt.<utente>.trafficmanager.net/contosoconcerthall
Effettuare il provisioning di un nuovo tenant nell'area di ripristino
Ancora prima del completamento del failover di tutti i database tenant esistenti, è possibile effettuare il provisioning di nuovi tenant nell'area di ripristino.
In PowerShell ISE aprire lo script ...\Learning Modules\Business Continuity and Disaster Recovery\DR-FailoverToReplica\Demo-FailoverToReplica.ps1 e impostare la proprietà seguente:
- $DemoScenario = 4, per effettuare il provisioning di un nuovo tenant nell'area di ripristino
Premere F5 per eseguire lo script ed effettuare il provisioning del nuovo tenant.
La pagina degli eventi di Hawthorn Hall viene aperta nel browser dopo il completamento. Osservare, nella parte inferiore della pagina, che è stato effettuato il ripristino del database Hawthorn Hall nell'area di ripristino.
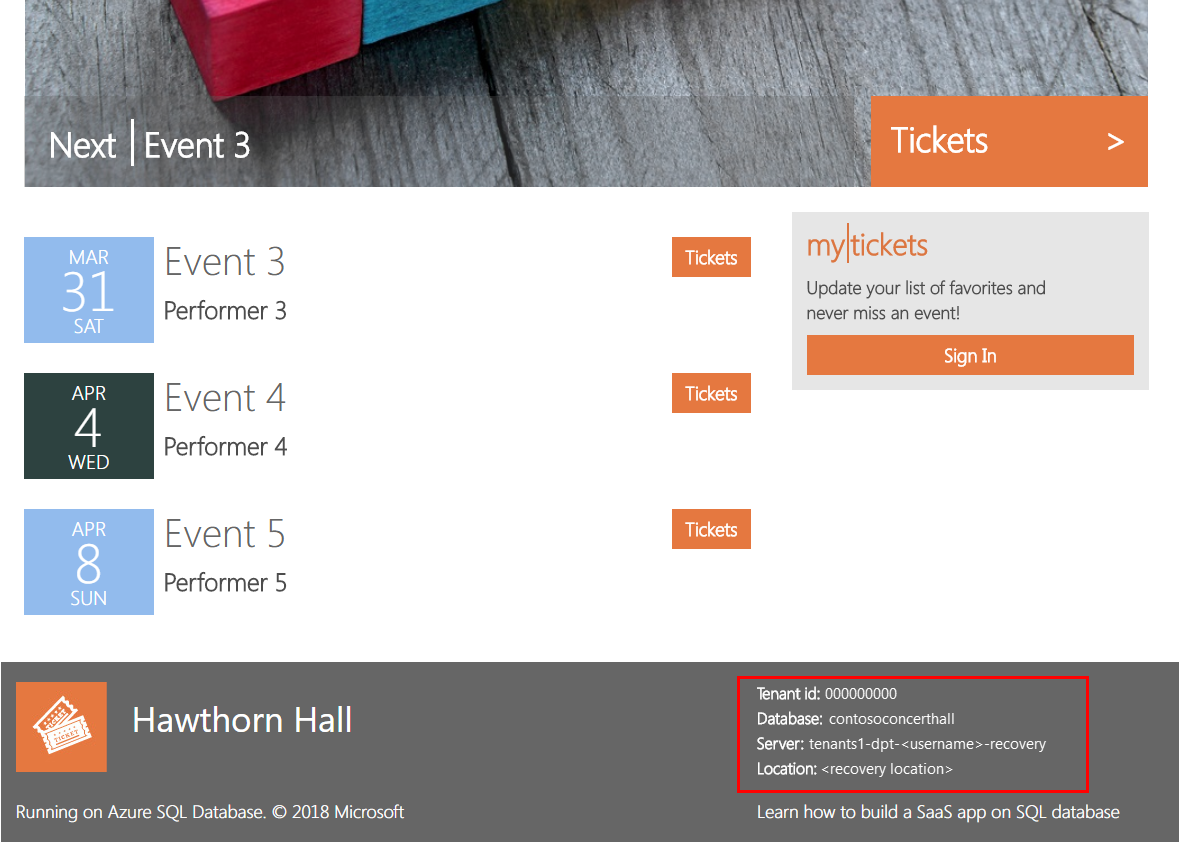
Nel browser aggiornare la pagina dell'hub eventi di Wingtip Tickets in modo da visualizzare anche Hawthorn Hall.
- Se è stato effettuato il provisioning di Hawthorn Hall senza attendere il ripristino degli altri tenant, è possibile che questi siano ancora offline.
Esaminare lo stato ripristinato dell'applicazione
Al termine del processo di ripristino, l'applicazione e tutti i tenant sono perfettamente funzionanti nell'area di ripristino.
Quando nella finestra della console di PowerShell viene indicato che tutti i tenant sono stati ripristinati, aggiornare l'hub eventi. Tutti i tenant risulteranno online, incluso il nuovo tenant Hawthorn Hall.
Nel portale di Azure aprire l'elenco dei gruppi di risorse.
- Osservare il gruppo di risorse distribuito, oltre al gruppo di risorse di ripristino, con il suffisso -recovery. Il gruppo di risorse di ripristino contiene tutte le risorse create durante il processo di ripristino, oltre alle nuove risorse create durante l'interruzione.
Aprire il gruppo di risorse di ripristino e osservare gli elementi seguenti:
Le versioni di ripristino dei server di catalogo e tenants1, con il suffisso -recovery. Tutti i database di catalogo e tenant ripristinati in questi server hanno i nomi usati nell'area di origine.
Il server SQL tenants2-dpt-<utente>-recovery. Questo server viene usato per il provisioning di nuovi tenant durante l'interruzione.
Il servizio app denominato events-wingtip-dpt-<recoveryregion>-<utente>;, che rappresenta l'istanza di ripristino dell'app Events.
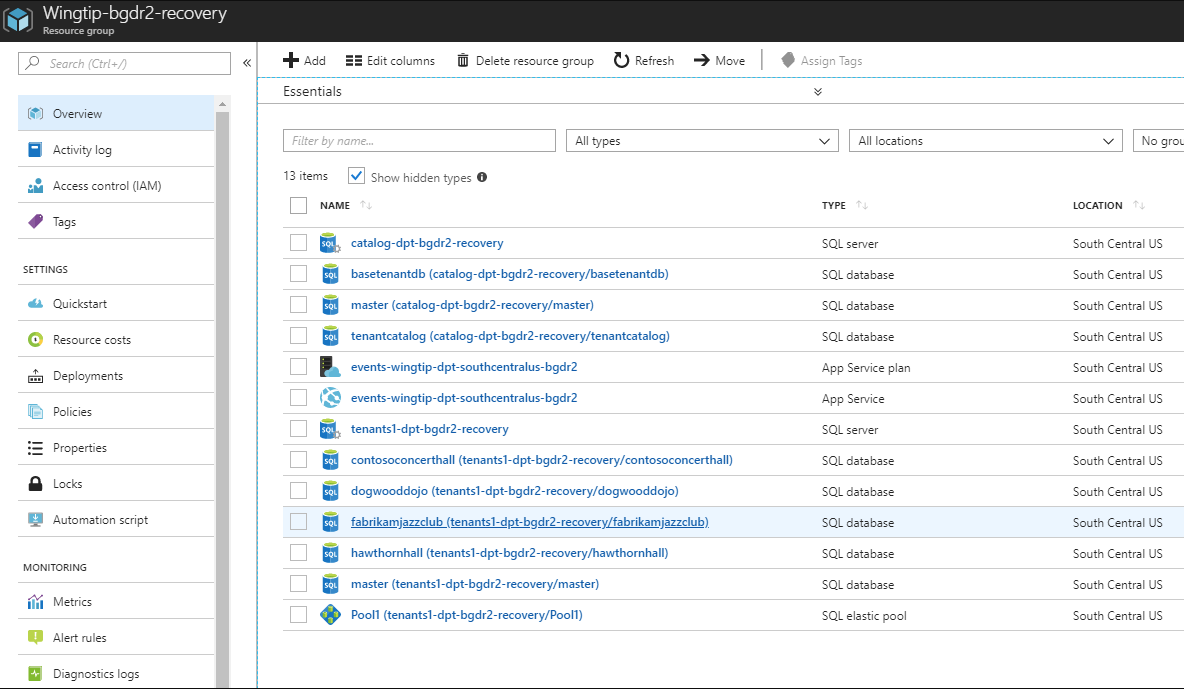
Aprire il server SQL tenants2-dpt-<utente>-recovery. Osservare che contiene il database hawthornhall e il pool elastico Pool1. Il database hawthornhall è configurato come database elastico nel pool elastico Pool1.
Tornare al gruppo di risorse e fare clic sul database Contoso Concert Hall nel server tenants1-dpt-<utente>-recovery. Fare clic su Replica geografica a sinistra.
Modificare i dati di un tenant
In questa attività si aggiorna uno dei database tenant.
- Nel browser trovare l'elenco di eventi per Contoso Concert Hall e osservare il nome dell'ultimo evento.
- In PowerShell ISE, nello script ...\Learning Modules\Business Continuity and Disaster Recovery\DR-FailoverToReplica\Demo-FailoverToReplica.ps1, impostare il valore seguente:
- $DemoScenario = 5, per eliminare un evento da un tenant nell'area di ripristino
- Premere F5 per eseguire lo script
- Aggiornare la pagina degli eventi di Contoso Concert Hall (http://events.wingtip-dpt.<utente>.trafficmanager.net/contosoconcerthall - sostituire <utente> con il valore utente della distribuzione) e osservare che l'ultimo evento è stato eliminato.
Ricollocare l'applicazione nell'area di produzione originale
Questa attività ricolloca l'applicazione nell'area originale. In uno scenario reale il processo di ricollocamento viene avviato dopo aver risolto l'interruzione.
Panoramica del processo di ricollocamento
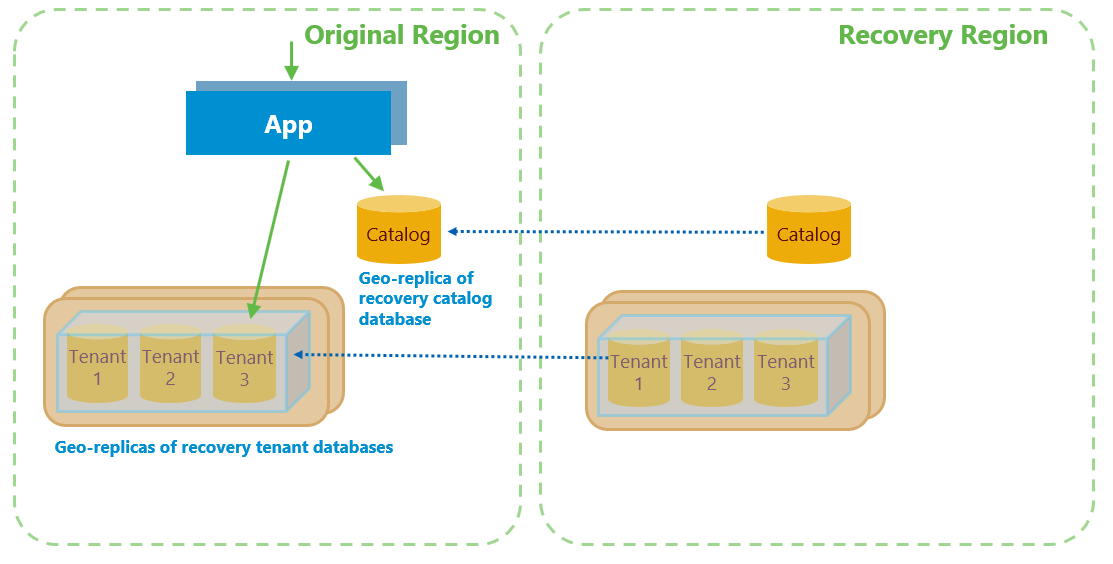
Il processo di ricollocamento:
- Annulla tutte le richieste di ripristino di database in corso o in attesa.
- Aggiorna l'alias newtenant in modo che punti al server tenant nell'area di origine. Modificando questo alias si garantisce il provisioning dei database per i nuovi tenant nell'area di origine.
- Inizializza i dati dei tenant modificati nell'area originale.
- Effettua il failover dei database tenant in ordine di priorità.
Il failover sposta in modo efficace il database nell'area originale. Dopo il failover del database, le connessioni aperte vengono eliminate e il database non è disponibile per alcuni secondi. È necessario scrivere le applicazioni con una logica di ripetizione dei tentativi, per garantire che si connettano di nuovo. Anche se questa breve disconnessione spesso non viene nemmeno notata, è possibile scegliere di ricollocare i database nella posizione originale al di fuori dell'orario lavorativo.
Eseguire lo script di ricollocamento
Si supponga ora che il problema di interruzione sia stato risolto e che quindi si esegua lo script di ricollocamento.
In PowerShell ISE usare lo script ...\Learning Modules\Business Continuity and Disaster Recovery\DR-FailoverToReplica\Demo-FailoverToReplica.ps1.
Verificare che il processo di sincronizzazione del catalogo sia ancora in esecuzione nell'istanza di PowerShell. Se necessario, riavviarlo impostando quanto segue:
- $DemoScenario = 1, per avviare la sincronizzazione delle informazioni di configurazione di server tenant, pool e database nel catalogo
- Premere F5 per eseguire lo script.
Avviare quindi il processo di ricollocamento impostando quanto segue:
- $DemoScenario = 6, per ricollocare l'app nell'area originale
- Premere F5 per eseguire lo script di ripristino in una nuova finestra di PowerShell. Il processo di ricollocamento richiede alcuni minuti e può essere monitorato nella finestra di PowerShell.
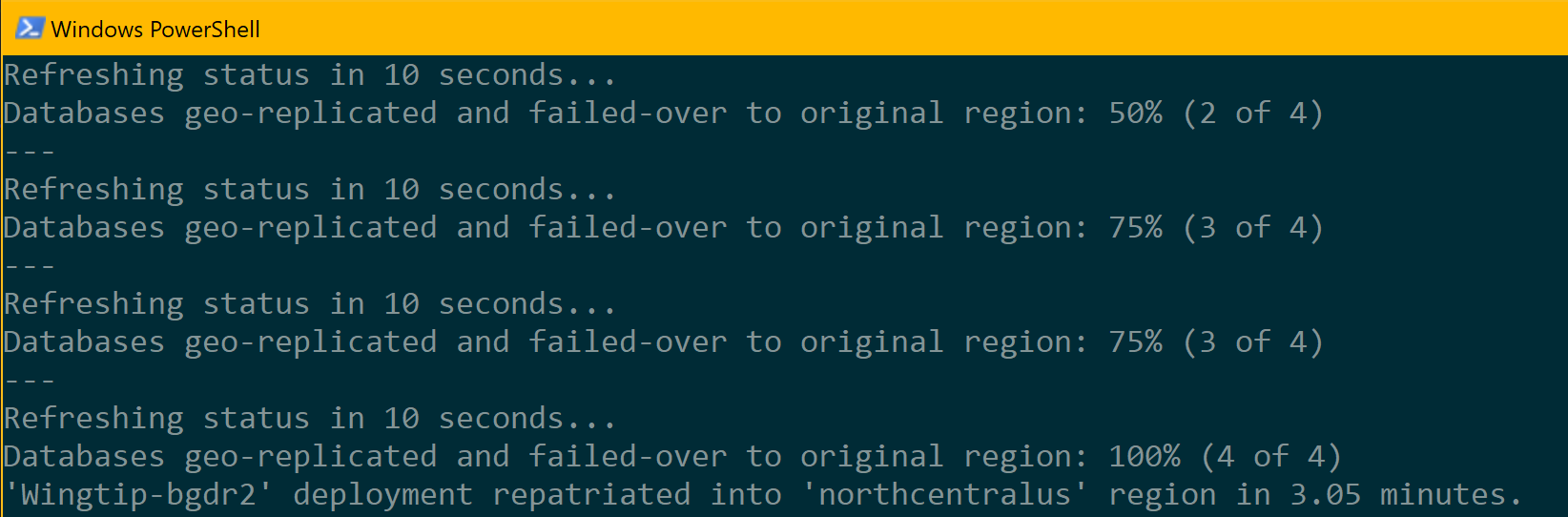
Mentre lo script è in esecuzione, aggiornare la pagina Hub eventi (http://events.wingtip-dpt.<utente>.trafficmanager.net).
- Si noti che tutti i tenant sono online e accessibili durante questo processo.
Al termine del ricollocamento, aggiornare l'hub eventi e aprire la pagina degli eventi per Hawthorn Hall. Si noti che il database è stato ricollocato nell'area originale.
Progettazione dell'applicazione in modo da mantenere l'app e il database nella stessa area
L'applicazione è progettata in modo da connettersi sempre da un'istanza nella stessa area del database tenant. Ciò consente di ridurre la latenza tra l'applicazione e il database. Questa ottimizzazione presuppone che l'interazione tra l'app e il database sia più frequente rispetto a quella tra l'utente e l'app.
Per un certo intervallo di tempo durante il ricollocamento, i database tenant possono essere distribuiti tra aree di origine e di ripristino. Per ogni database, l'app esegue una ricerca DNS nell'area in cui si trova il database in base al nome del server tenant. Nel database SQL il nome del server è un alias. in cui è incluso il nome dell'area. Se l'applicazione non si trova nella stessa area del database, viene eseguito il reindirizzamento all'istanza presente nella stessa area del server. In questo modo si riduce al minimo la latenza tra l'app e il database.
Passaggi successivi
In questa esercitazione si è appreso come:
- Sincronizzare le informazioni di configurazione dei database e dei pool elastici nel catalogo del tenant
- Configurare un ambiente di ripristino in un'area alternativa, che include applicazione, server e pool
- Usare la replica geografica per replicare i database di catalogo e tenant nell'area di ripristino
- Effettuare il failover dell'applicazione e dei database di catalogo e tenant nell'area di ripristino
- Effettuare il failback dell'applicazione e dei database di catalogo e tenant nell'area originale, dopo che l'interruzione è stata risolta
Per altre informazioni sulle tecnologie che il database SQL di Azure offre per consentire la continuità aziendale, vedere Panoramica della continuità aziendale.
Risorse aggiuntive
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per