Trasmettere dati in database SQL di Azure usando l'integrazione di Analisi di flusso di Azure (anteprima)
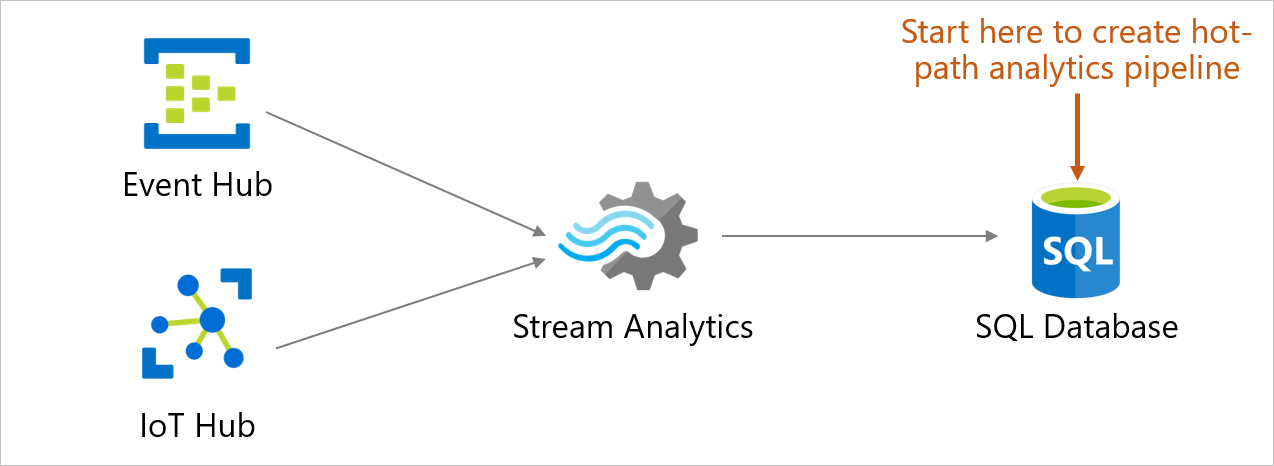
Gli utenti possono ora inserire, elaborare, visualizzare e analizzare i dati di streaming in tempo reale in una tabella direttamente da un database in database SQL di Azure. A tale scopo, nel portale di Azure usando Analisi di flusso di Azure. Questa esperienza consente una vasta gamma di scenari, tra cui auto connesse, monitoraggio remoto, rilevamento di illeciti e molto altro ancora. Nel portale di Azure, è possibile selezionare un'origine evento (hub eventi/hub IoT), visualizzare gli eventi in ingresso in tempo reale e selezionare una tabella per l'archiviazione degli eventi. È anche possibile scrivere query nel linguaggio di query di Analisi di flusso di Azure nel portale per trasformare gli eventi in ingresso e archiviarli nella tabella selezionata. Questo nuovo punto di ingresso viene aggiunto alle esperienze di creazione e configurazione già esistenti in Analisi di flusso. L'esperienza parte dal contesto del tuo database, permettendoti di configurare rapidamente un processo di Analisi di flusso e di spostarti facilmente tra le esperienze del database in database SQL di Azure e di Analisi di flusso.
Vantaggi chiave
- Cambio di contesto minimo: è possibile iniziare da un database in database SQL di Azure nel portale e avviare l'inserimento di dati in tempo reale in una tabella senza passare a un altro servizio.
- Numero ridotto di passaggi: il contesto del database e della tabella viene usato per preconfigurare un processo di Analisi di flusso.
- Maggiore facilità d'uso con i dati di anteprima: visualizzare in anteprima i dati in ingresso dall'origine eventi (Hub eventi/hub IoT) nel contesto della tabella selezionata
Importante
Un processo di Analisi di flusso di Azure può restituire database SQL di Azure, Istanza gestita di SQL di Azure o Azure Synapse Analytics. Per altre informazioni, vedere Output.
Prerequisiti
Per seguire la procedura descritta in questo articolo, sono necessarie le risorse seguenti:
- Una sottoscrizione di Azure. Se non hai una sottoscrizione di Azure, crea un account gratuito.
- Database nel database SQL di Azure. Per informazioni dettagliate, vedere Creare un database singolo in database SQL di Azure.
- Una regola del firewall che consente al computer di connettersi al server. Per la procedura dettagliata, vedere Creare una regola del firewall a livello di server.
Configurare l'integrazione di Analisi di flusso
Accedere al portale di Azure.
Passare al database in cui si desidera inserire i dati di streaming. Selezionare Analisi di flusso (anteprima).
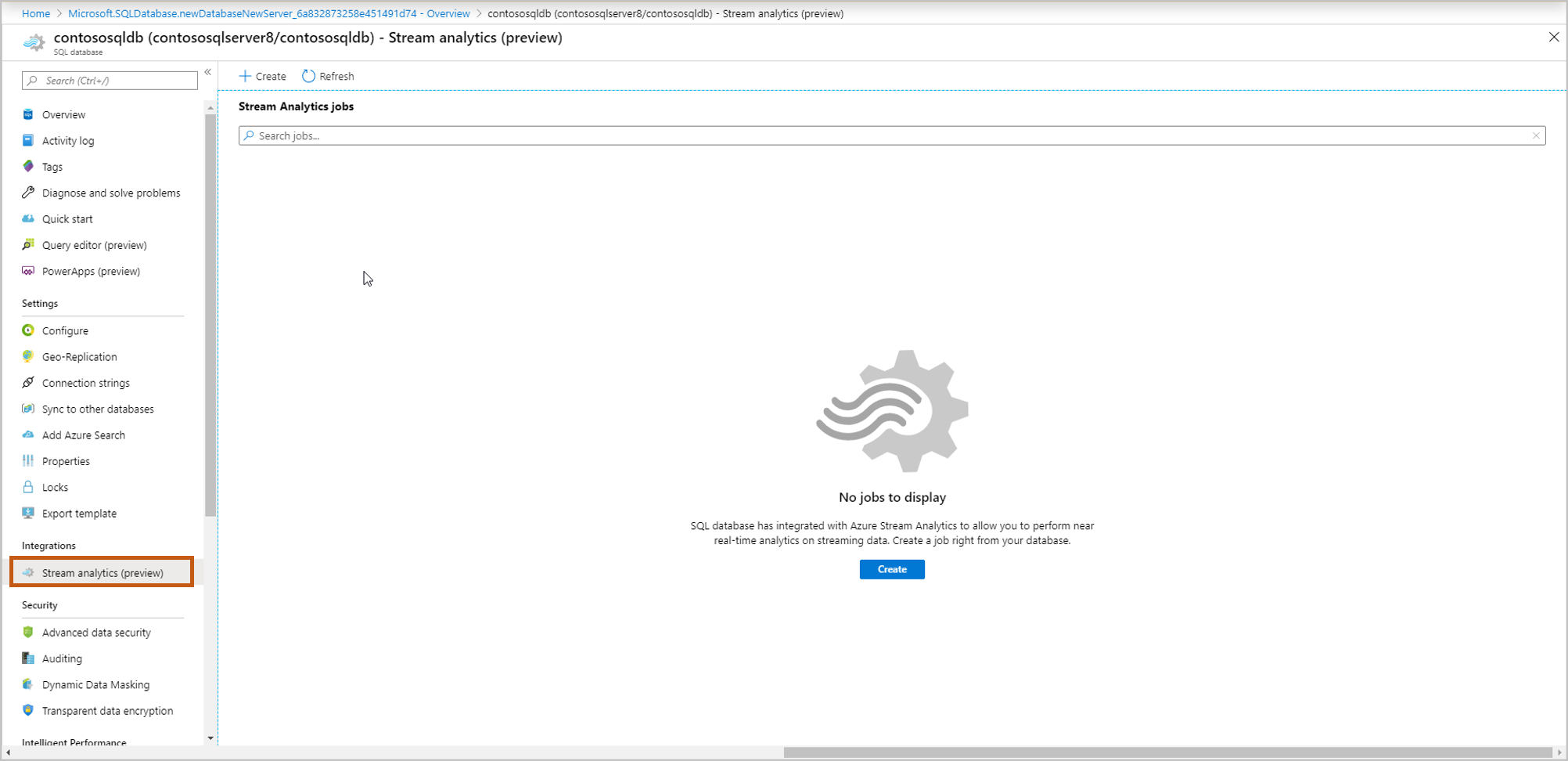
Per iniziare a inserire i dati di streaming in questo database, selezionare Crea e assegnare un nome al processo di streaming e quindi selezionare Avanti: Input.
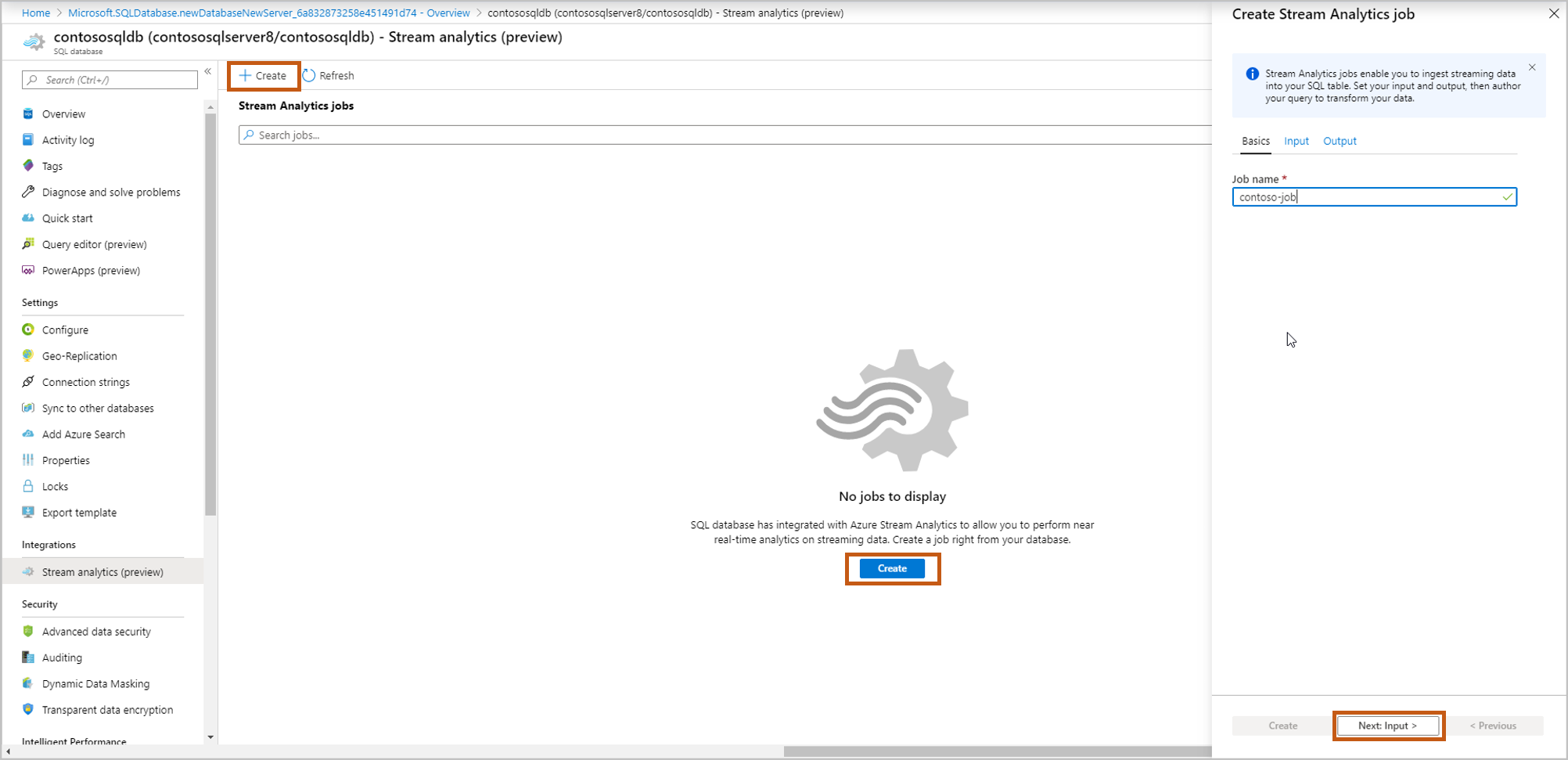
Immettere i dettagli dell'origine eventi e quindi selezionare Avanti: Output.
Tipo di input: Hub eventi/hub IoT
Alias input: immettere un nome per identificare l'origine eventi
Sottoscrizione: uguale a database SQL di Azure sottoscrizione
Spazio dei nomi dell’hub eventi: Nome per lo spazio dei nomi
Nome hub eventi: nome dell'hub eventi all'interno dello spazio dei nomi selezionato
Nome criterio hub eventi (impostazione predefinita per la creazione): assegnare un nome ai criteri
Gruppo di consumer dell'hub eventi (impostazione predefinita per la creazione): assegnare un nome a un gruppo di consumer
È consigliabile creare un gruppo di consumer e un criterio per ogni nuovo processo di Analisi di flusso di Azure creato da qui. I gruppi di consumer consentono solo cinque lettori simultanei, quindi fornire un gruppo di consumer dedicato per ogni processo eviterà eventuali errori che potrebbero verificarsi al superamento di tale limite. Un criterio dedicato consente di ruotare la chiave o revocare le autorizzazioni senza influire sulle altre risorse.
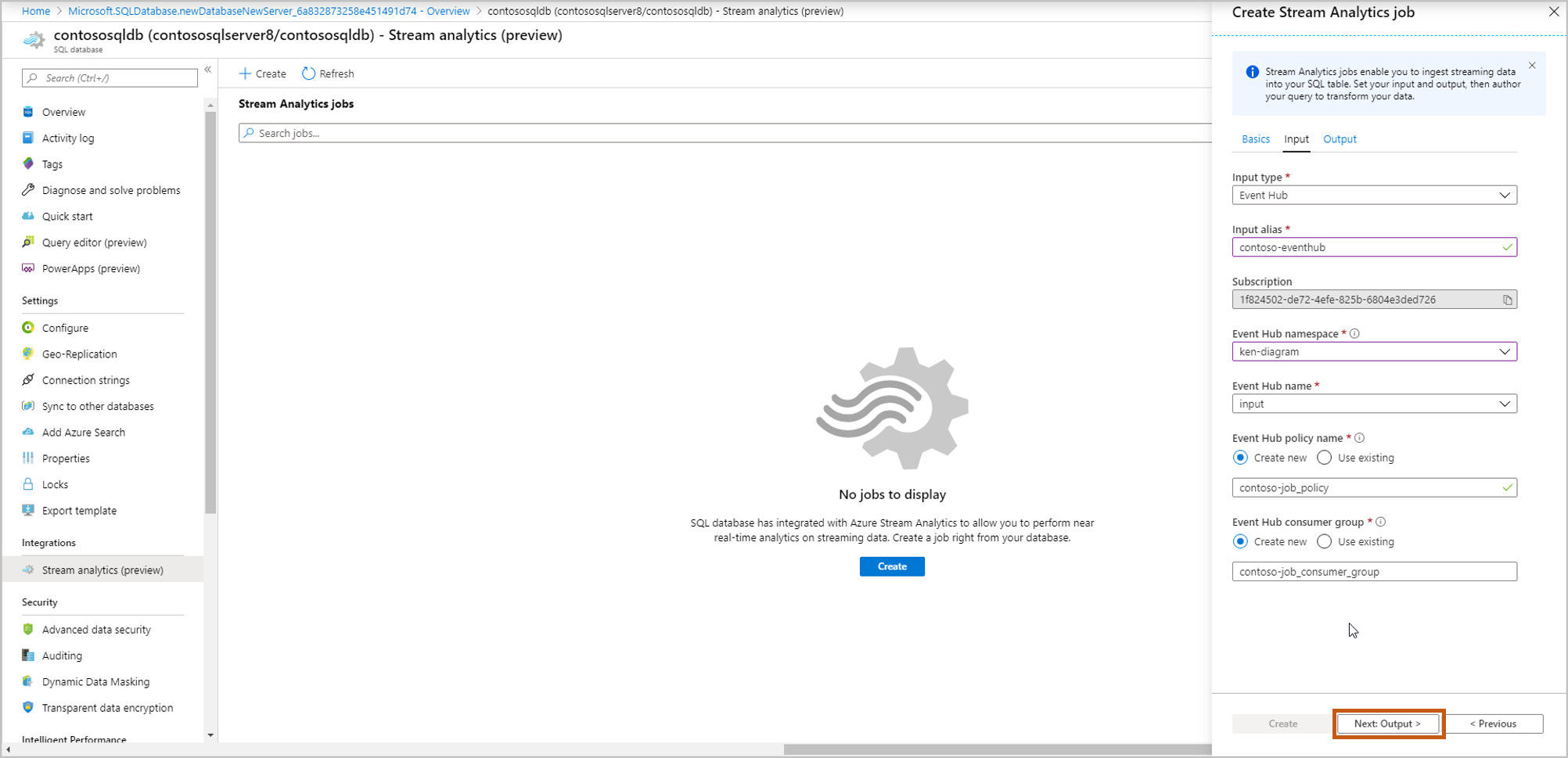
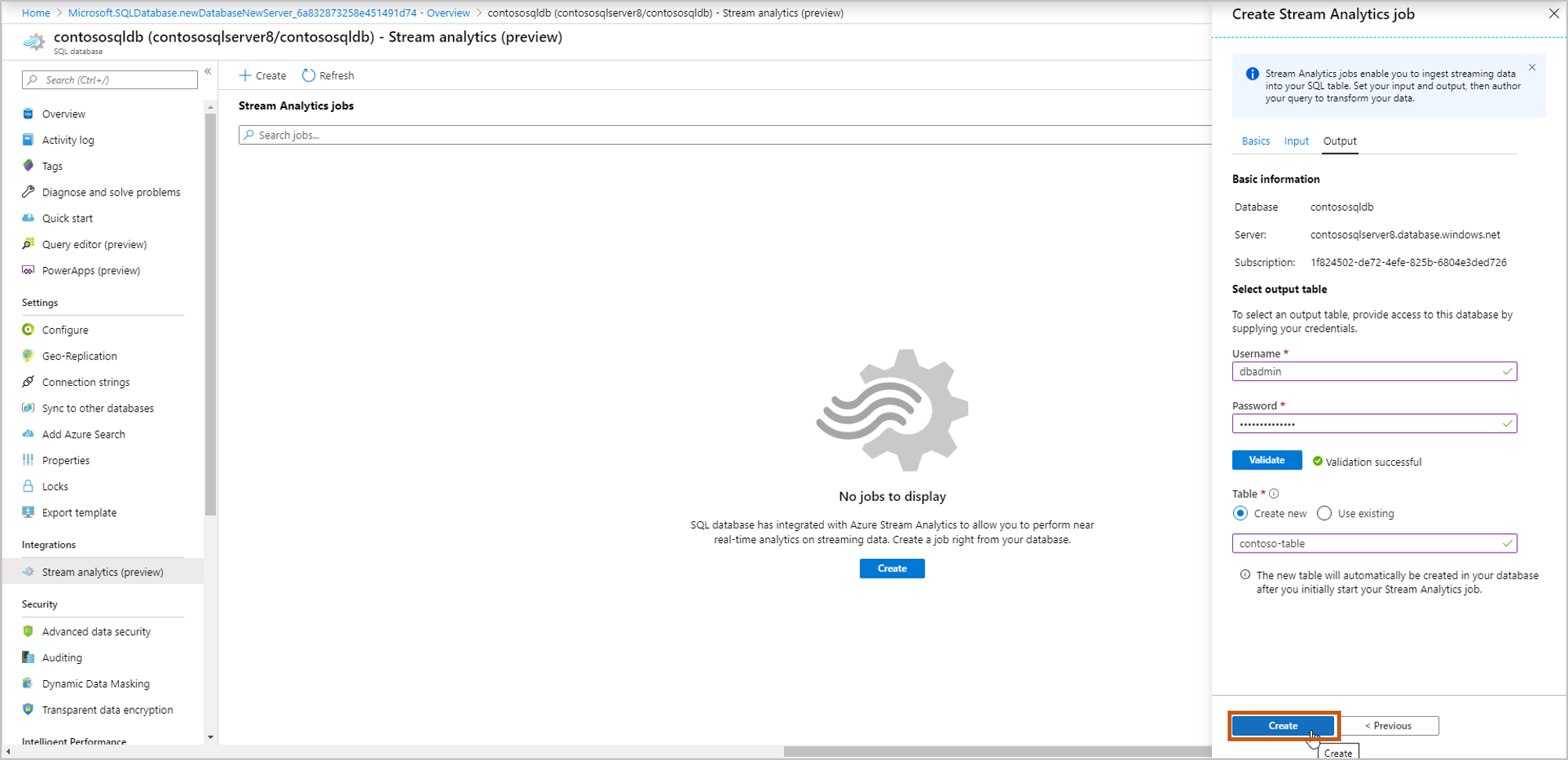
Selezionare la tabella verso cui indirizzare il flusso di dati. Al termine, selezionare Crea.
Nome utente, Password: immettere le credenziali per l'autenticazione di SQL Server. Selezionare Convalida.
Tabella: Seleziona Crea nuova o Usa esistente. In questo flusso, selezionare Crea. Verrà creata una nuova tabella quando si avvia il processo di Analisi di flusso.
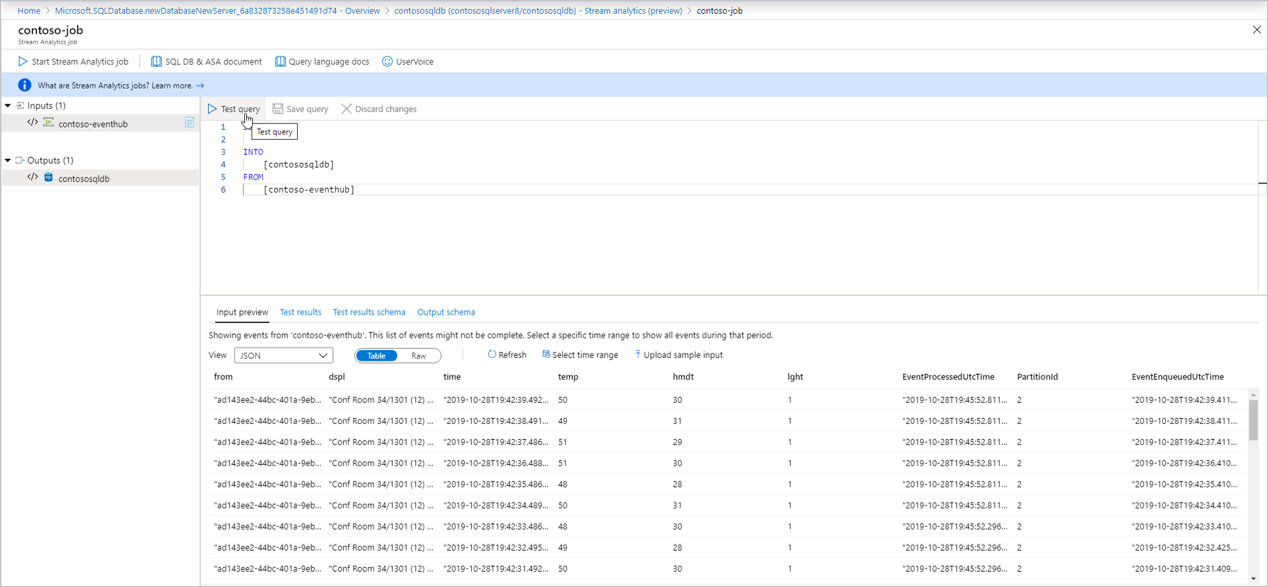
Viene visualizzata una pagina di query con i dettagli seguenti:
Input (origine eventi di input) da cui inserire i dati
Output (tabella di output) che archivierà i dati trasformati
Query SAQL di esempio con istruzione edizione SELECT.
Anteprima input: mostra lo snapshot dei dati in ingresso più recenti dall'origine degli eventi di input.
- Il tipo di serializzazione nei dati viene rilevato automaticamente (JSON/CSV). È possibile modificarlo manualmente anche in JSON/CSV/AVRO.
- È possibile visualizzare in anteprima i dati in ingresso nel formato Tabella o In formato non elaborato.
- Se i dati visualizzati non sono aggiornati, selezionare Aggiorna per visualizzare gli eventi più recenti.
- Selezionare Seleziona intervallo di tempo per testare la query su un intervallo di tempo specifico di eventi in ingresso.
- Selezionare Carica input di esempio per testare la query caricando un file JSON/CSV di esempio. Per altre informazioni sul test di una query SAQL, vedere Testare un processo di Analisi di flusso di Azure con dati di esempio.
Risultati dei test: selezionare Query di test ed è possibile visualizzare i risultati della query di streaming

Schema dei risultati del test: mostra lo schema dei risultati della query di streaming dopo il test. Assicurarsi che lo schema dei risultati del test corrisponda allo schema di output.
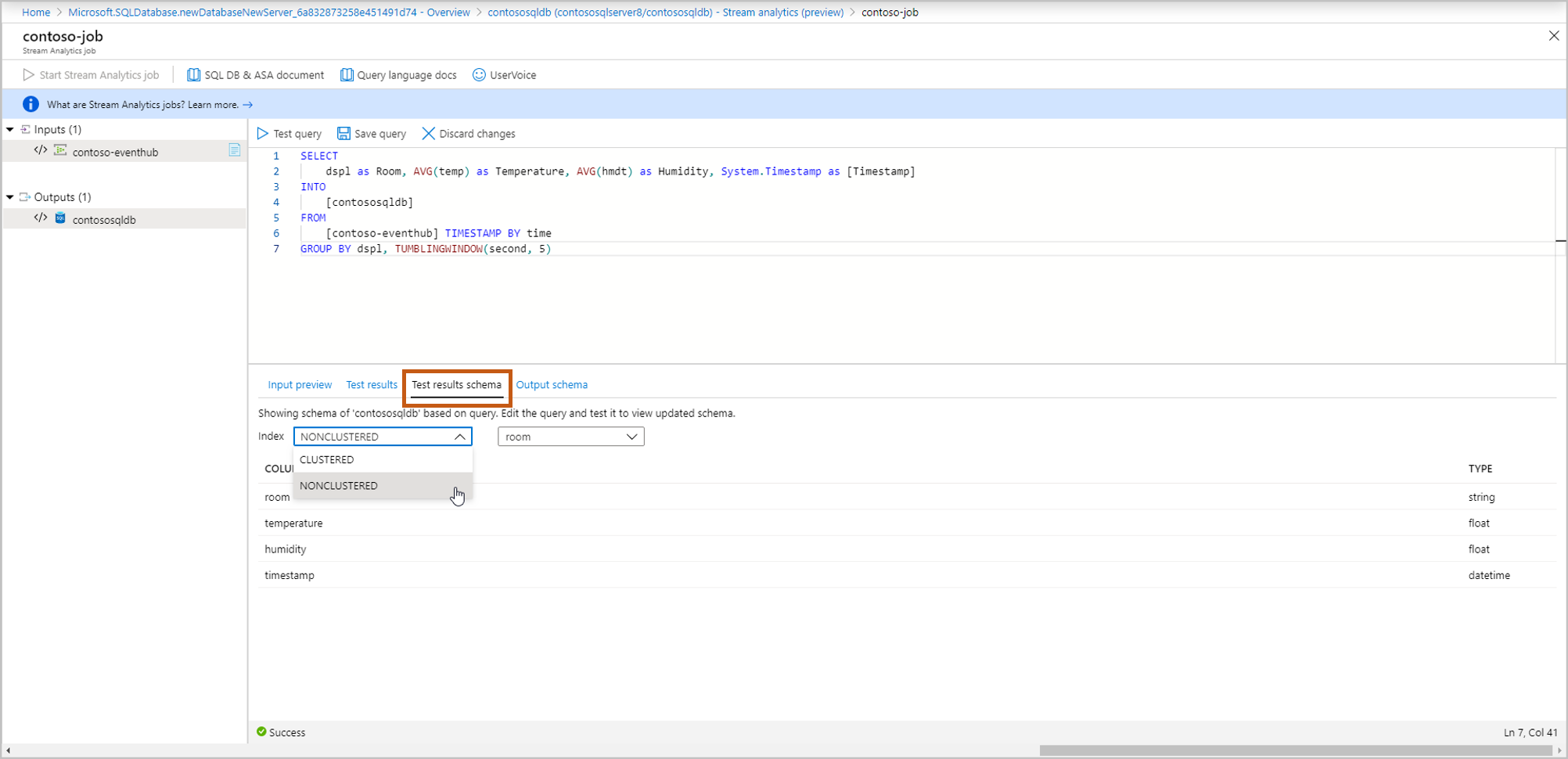
Schema di output: contiene lo schema della tabella selezionata nel passaggio 5 (nuovo o esistente).
- Crea nuovo: se questa opzione è stata selezionata nel passaggio 5, lo schema non verrà ancora visualizzato finché non si avvia il processo di streaming. Quando si crea una nuova tabella, selezionare l'indice di tabella appropriato. Per altre informazioni sull’indicizzazione della tabella, vedere Descrizione di indici cluster e non cluster.
- Usa esistente: se questa opzione è stata selezionata nel passaggio 5, verrà visualizzato lo schema della tabella selezionata.
Dopo aver completato la creazione e il test della query, selezionare Salva query. Selezionare Avvia processo di Analisi di flusso per avviare l'inserimento di dati trasformati nella tabella SQL. Dopo aver completato i campi seguenti, avviare il processo.
Ora di inizio dell'output: definisce l'ora del primo output del processo.
- Adesso: il processo verrà avviato ed elaborato nuovi dati in ingresso.
- Personalizzata: il processo verrà avviato ora, ma eseguirà l'elaborazione dei dati da un punto specifico nel tempo (che può trovarsi nel passato o nel futuro). Per ulteriori informazioni, vedere: Come avviare un processo di Analisi di flusso di Azure.
Unità di streaming: i prezzi di Analisi di flusso di Azure dipendono dal numero di unità di streaming necessarie per elaborare i dati nel servizio. Per altre informazioni, vedere Prezzi di Analisi di flusso di Azure.
Gestione degli errori di output:
- Riprova: quando si verifica un errore, Analisi di flusso di Azure prova a scrivere l'evento a tempo indeterminato fino a quando la scrittura non ha esito positivo. Non è impostato alcun timeout per i tentativi. Alla fine, l'elaborazione di tutti gli eventi successivi viene bloccata dall'evento in fase di esecuzione. Questa opzione è il criterio di gestione degli errori di output predefinito.
- Escludi: analisi di flusso di Azure escluderà qualsiasi evento di output che restituisca un errore di conversione dei dati. Gli eventi rimossi non possono essere recuperati per essere rielaborati in seguito. Tutti gli errori temporanei (ad esempio, gli errori di rete) vengono ritentati indipendentemente dalla configurazione dei criteri di gestione degli errori di output.
Impostazioni output database SQL: opzione che consente di ereditare lo schema di partizionamento del passaggio di query precedente, per abilitare la topologia perfettamente parallela con più writer nella tabella. Per altre informazioni, consultare Output di Analisi di flusso di Azure in Database SQL di Azure.
Limite massimo batch: limite massimo consigliato rispetto al numero di record inviati con ogni transazione di inserimento bulk.
Per altre informazioni sulla gestione degli errori di output, vedere Criteri di errore di output in Analisi di flusso di Azure.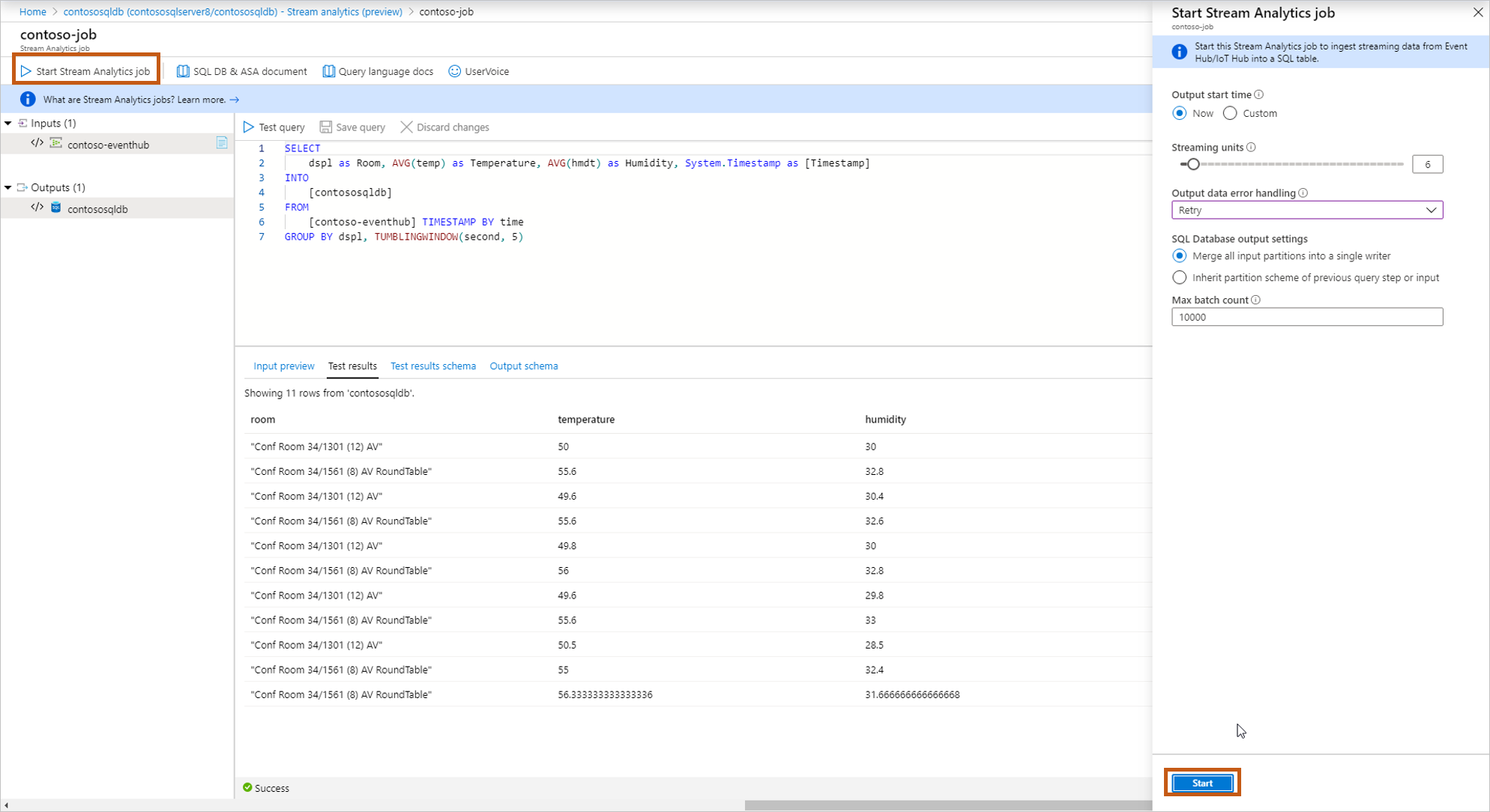
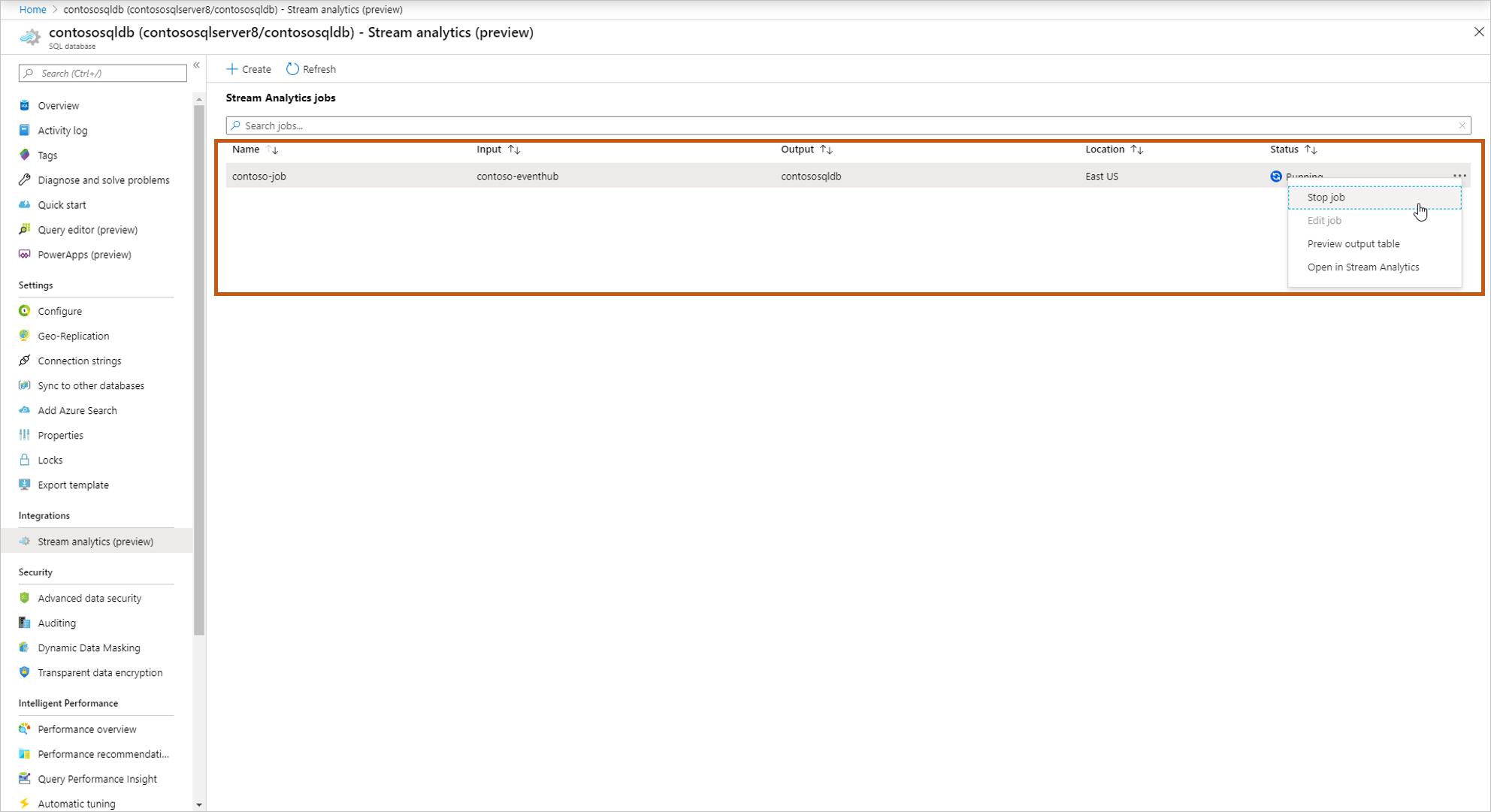
Dopo aver avviato il processo, verrà visualizzato il processo In esecuzione nell'elenco ed è possibile eseguire le azioni seguenti:
Avviare/arrestare il processo: se il processo è in esecuzione, è possibile arrestare il processo. Se il processo viene arrestato, è possibile avviare il processo.
Modifica processo: è possibile modificare la query. Se si vogliono apportare altre modifiche al processo, ad esempio aggiungere altri input/output, quindi aprire il processo in Analisi di flusso. L'opzione di modifica è disabilitata quando il processo è in esecuzione.
Anteprima tabella di output: è possibile visualizzare in anteprima la tabella nell'editor di query SQL.
Aprire in Analisi di flusso: aprire il processo in Analisi di flusso per visualizzare il monitoraggio e i dettagli del debug del processo.
Passaggi successivi
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per