Esercitazione: Configurare i gruppi di disponibilità per SQL Server nelle macchine virtuali RHEL in Azure
Si applica a:![]() SQL Server su VM di Azure
SQL Server su VM di Azure
Nota
In questa esercitazione viene usato SQL Server 2017 (14.x) con RHEL 7.6, ma è possibile usare SQL Server 2019 (15.x) in RHEL 7 o RHEL 8 per configurare la disponibilità elevata. I comandi per configurare le risorse del gruppo di disponibilità e il cluster Pacemaker sono cambiati in RHEL 8 ed è quindi opportuno vedere l'articolo Creare risorse del gruppo di disponibilità e le risorse di RHEL 8 per altre informazioni sui comandi corretti.
In questa esercitazione apprenderai a:
- Creare un nuovo gruppo di risorse, un set di disponibilità e le macchine virtuali Linux
- Abilitare la disponibilità elevata
- Creare un cluster Pacemaker
- Configurare un agente di isolamento mediante la creazione di un dispositivo STONITH
- Installare SQL Server e mssql-tools in RHEL
- Configurare il gruppo di disponibilità Always On di SQL Server
- Configurare le risorse del gruppo di disponibilità nel cluster Pacemaker
- Testare un failover e l'agente di isolamento
Questa esercitazione usa l'interfaccia della riga di comando di Azure per distribuire le risorse in Azure.
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Prerequisiti
Usare l'ambiente Bash in Azure Cloud Shell. Per altre informazioni, vedere Avvio rapido per Bash in Azure Cloud Shell.

Se si preferisce eseguire i comandi di riferimento dell'interfaccia della riga di comando in locale, installare l'interfaccia della riga di comando di Azure. Per l'esecuzione in Windows o macOS, è consigliabile eseguire l'interfaccia della riga di comando di Azure in un contenitore Docker. Per altre informazioni, vedere Come eseguire l'interfaccia della riga di comando di Azure in un contenitore Docker.
Se si usa un'installazione locale, accedere all'interfaccia della riga di comando di Azure con il comando az login. Per completare il processo di autenticazione, seguire la procedura visualizzata nel terminale. Per altre opzioni di accesso, vedere Accedere tramite l'interfaccia della riga di comando di Azure.
Quando richiesto, installare l'estensione dell'interfaccia della riga di comando di Azure al primo utilizzo. Per altre informazioni sulle estensioni, vedere Usare le estensioni con l'interfaccia della riga di comando di Azure.
Eseguire az version per trovare la versione e le librerie dipendenti installate. Per eseguire l'aggiornamento alla versione più recente, eseguire az upgrade.
- Questo articolo richiede l'interfaccia della riga di comando di Azure versione 2.0.30 o successiva. Se si usa Azure Cloud Shell, la versione più recente è già installata.
Creare un gruppo di risorse
Se sono presenti più sottoscrizioni, selezionare la sottoscrizione in cui dovranno essere distribuite le risorse.
Usare il comando seguente per creare un gruppo di risorse <resourceGroupName> in un'area. Sostituire <resourceGroupName> con il nome desiderato. Per questa esercitazione verrà usata l'area East US 2. Per altre informazioni, vedere la guida di Avvio rapido seguente.
az group create --name <resourceGroupName> --location eastus2
Creare un set di disponibilità
Il passaggio successivo prevede la creazione di un set di disponibilità. Eseguire il comando seguente in Azure Cloud Shell e sostituire <resourceGroupName> con il nome del gruppo di risorse. Scegliere un nome per <availabilitySetName>.
az vm availability-set create \
--resource-group <resourceGroupName> \
--name <availabilitySetName> \
--platform-fault-domain-count 2 \
--platform-update-domain-count 2
Al termine del comando, verranno restituiti i risultati seguenti:
{
"id": "/subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.Compute/availabilitySets/<availabilitySetName>",
"location": "eastus2",
"name": "<availabilitySetName>",
"platformFaultDomainCount": 2,
"platformUpdateDomainCount": 2,
"proximityPlacementGroup": null,
"resourceGroup": "<resourceGroupName>",
"sku": {
"capacity": null,
"name": "Aligned",
"tier": null
},
"statuses": null,
"tags": {},
"type": "Microsoft.Compute/availabilitySets",
"virtualMachines": []
}
Creare macchine virtuali RHEL all'interno del set di disponibilità
Avviso
Se si sceglie un'immagine di RHEL con pagamento in base al consumo (PAYG) e si configura la disponibilità elevata (HA), potrebbe essere necessario registrare la sottoscrizione. Ciò potrebbe comportare il pagamento doppio del prezzo, in quanto verranno addebitate la sottoscrizione di Microsoft Azure RHEL per la macchina virtuale e la sottoscrizione per Red Hat. Per ulteriori informazioni, vedere https://access.redhat.com/solutions/2458541.
Per evitare questa "doppia fatturazione", quando si crea la macchina virtuale di Azure usare un'immagine di RHEL con disponibilità elevata. Le immagini offerte come immagini di RHEL con disponibilità elevata sono immagini con pagamento in base al consumo e con il repository a disponibilità elevata preabilitato.
Ottenere un elenco di immagini di macchine virtuali che offrono RHEL con la disponibilità elevata:
az vm image list --all --offer "RHEL-HA"Dovresti vedere i seguenti risultati:
[ { "offer": "RHEL-HA", "publisher": "RedHat", "sku": "7.4", "urn": "RedHat:RHEL-HA:7.4:7.4.2019062021", "version": "7.4.2019062021" }, { "offer": "RHEL-HA", "publisher": "RedHat", "sku": "7.5", "urn": "RedHat:RHEL-HA:7.5:7.5.2019062021", "version": "7.5.2019062021" }, { "offer": "RHEL-HA", "publisher": "RedHat", "sku": "7.6", "urn": "RedHat:RHEL-HA:7.6:7.6.2019062019", "version": "7.6.2019062019" }, { "offer": "RHEL-HA", "publisher": "RedHat", "sku": "8.0", "urn": "RedHat:RHEL-HA:8.0:8.0.2020021914", "version": "8.0.2020021914" }, { "offer": "RHEL-HA", "publisher": "RedHat", "sku": "8.1", "urn": "RedHat:RHEL-HA:8.1:8.1.2020021914", "version": "8.1.2020021914" }, { "offer": "RHEL-HA", "publisher": "RedHat", "sku": "80-gen2", "urn": "RedHat:RHEL-HA:80-gen2:8.0.2020021915", "version": "8.0.2020021915" }, { "offer": "RHEL-HA", "publisher": "RedHat", "sku": "81_gen2", "urn": "RedHat:RHEL-HA:81_gen2:8.1.2020021915", "version": "8.1.2020021915" } ]Per questa esercitazione, verrà scelta l'immagine
RedHat:RHEL-HA:7.6:7.6.2019062019per l'esempio relativo a RHEL 7 eRedHat:RHEL-HA:8.1:8.1.2020021914per l'esempio relativo a RHEL 8.È anche possibile scegliere SQL Server 2019 (15.x) preinstallato nelle immagini RHEL8-HA. Per ottenere l'elenco di queste immagini, eseguire il comando seguente:
az vm image list --all --offer "sql2019-rhel8"Dovresti vedere i seguenti risultati:
[ { "offer": "sql2019-rhel8", "publisher": "MicrosoftSQLServer", "sku": "enterprise", "urn": "MicrosoftSQLServer:sql2019-rhel8:enterprise:15.0.200317", "version": "15.0.200317" }, { "offer": "sql2019-rhel8", "publisher": "MicrosoftSQLServer", "sku": "enterprise", "urn": "MicrosoftSQLServer:sql2019-rhel8:enterprise:15.0.200512", "version": "15.0.200512" }, { "offer": "sql2019-rhel8", "publisher": "MicrosoftSQLServer", "sku": "sqldev", "urn": "MicrosoftSQLServer:sql2019-rhel8:sqldev:15.0.200317", "version": "15.0.200317" }, { "offer": "sql2019-rhel8", "publisher": "MicrosoftSQLServer", "sku": "sqldev", "urn": "MicrosoftSQLServer:sql2019-rhel8:sqldev:15.0.200512", "version": "15.0.200512" }, { "offer": "sql2019-rhel8", "publisher": "MicrosoftSQLServer", "sku": "standard", "urn": "MicrosoftSQLServer:sql2019-rhel8:standard:15.0.200317", "version": "15.0.200317" }, { "offer": "sql2019-rhel8", "publisher": "MicrosoftSQLServer", "sku": "standard", "urn": "MicrosoftSQLServer:sql2019-rhel8:standard:15.0.200512", "version": "15.0.200512" } ]Se si usa una delle immagini precedenti per creare le macchine virtuali, SQL Server 2019 (15.x) è preinstallato. Ignorare la sezione Installare SQL Server e mssql-tools come descritto in questo articolo.
Importante
Per configurare il gruppo di disponibilità, i nomi delle macchine virtuali devono contenere meno di 15 caratteri. Il nome utente non può contenere caratteri maiuscoli e le password devono contenere più di 12 caratteri.
Nel set di disponibilità verranno create 3 macchine virtuali. Sostituire questi valori nel comando seguente:
<resourceGroupName><VM-basename><availabilitySetName><VM-Size>, ad esempio "Standard_D16_v3"<username><adminPassword>
for i in `seq 1 3`; do az vm create \ --resource-group <resourceGroupName> \ --name <VM-basename>$i \ --availability-set <availabilitySetName> \ --size "<VM-Size>" \ --image "RedHat:RHEL-HA:7.6:7.6.2019062019" \ --admin-username "<username>" \ --admin-password "<adminPassword>" \ --authentication-type all \ --generate-ssh-keys done
Il comando precedente crea le macchine virtuali e crea una rete virtuale predefinita per tali macchine virtuali. Per altre informazioni sulle diverse configurazioni, vedere l'articolo con le informazioni di riferimento su az vm create.
Al termine del comando per ogni macchina virtuale, si otterrà un risultato simile al seguente:
{
"fqdns": "",
"id": "/subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.Compute/virtualMachines/<VM1>",
"location": "eastus2",
"macAddress": "<Some MAC address>",
"powerState": "VM running",
"privateIpAddress": "<IP1>",
"publicIpAddress": "",
"resourceGroup": "<resourceGroupName>",
"zones": ""
}
Importante
L'immagine predefinita creata con il comando precedente crea un disco del sistema operativo da 32 GB per impostazione predefinita. Con questa installazione predefinita, è tuttavia possibile esaurire lo spazio disponibile. Usare quindi il parametro seguente aggiunto al comando az vm create precedente per creare un disco del sistema operativo ad esempio da 128 GB: --os-disk-size-gb 128.
Successivamente, configurare Logical Volume Manager (LVM) se è necessario espandere i volumi delle cartelle appropriati per l'installazione.
Testare la connessione alle macchine virtuali create
Connettersi a VM1 o alle altre macchine virtuali usando il comando seguente in Azure Cloud Shell. Se non si riesce a trovare gli indirizzi IP della macchina virtuale, seguire questa guida di Avvio rapido in Azure Cloud Shell.
ssh <username>@publicipaddress
Se la connessione viene stabilita, verrà visualizzato l'output seguente che rappresenta il terminale Linux:
[<username>@<VM1> ~]$
Digitare exit per uscire dalla sessione SSH.
Abilitare la disponibilità elevata
Importante
Per completare questa parte dell'esercitazione, è necessario disporre di una sottoscrizione di RHEL e del componente aggiuntivo per la disponibilità elevata. Se si usa un'immagine consigliata nella sezione precedente, non è necessario registrare un'altra sottoscrizione.
Connettersi a ogni nodo della macchina virtuale e seguire la guida riportata sotto per abilitare la disponibilità elevata. Per altre informazioni, vedere Abilitare la sottoscrizione a disponibilità elevata per RHEL.
Suggerimento
Sarà più semplice se si apre una sessione SSH contemporaneamente per ogni macchina virtuale, perché i comandi illustrati nell'articolo dovranno essere eseguiti in ogni macchina virtuale.
Se si copiano e incollano più comandi sudo e viene richiesta una password, i comandi aggiuntivi non verranno eseguiti. Eseguire ogni comando separatamente.
Eseguire i comandi seguenti in ogni macchina virtuale per aprire le porte del firewall Pacemaker:
sudo firewall-cmd --permanent --add-service=high-availability sudo firewall-cmd --reloadAggiornare e installare i pacchetti Pacemaker in tutti i nodi usando i comandi seguenti:
Nota
nmap è uno strumento che viene installato come parte di questo blocco di comandi per trovare gli indirizzi IP disponibili nella rete. Non è necessario installare nmap, ma sarà utile più avanti in questa esercitazione.
sudo yum update -y sudo yum install -y pacemaker pcs fence-agents-all resource-agents fence-agents-azure-arm nmap sudo rebootImpostare la password per l'utente predefinito creato durante l'installazione dei pacchetti Pacemaker. Usare la stessa password in tutti i nodi.
sudo passwd haclusterUsare il comando seguente per aprire il file hosts e impostare la risoluzione dei nomi host. Per altre informazioni su come configurare il file hosts, vedere Configurare il gruppo di disponibilità.
sudo vi /etc/hostsNell'editor vi immettere
iper inserire il testo e, in una riga vuota, aggiungere l'indirizzo IP privato della macchina virtuale corrispondente. Aggiungere quindi il nome della macchina virtuale dopo uno spazio accanto all'indirizzo IP. Ogni riga deve contenere una voce separata.<IP1> <VM1> <IP2> <VM2> <IP3> <VM3>Importante
È consigliabile usare l'indirizzo IP privato nell'esempio precedente. Se in questa configurazione si usa l'indirizzo IP pubblico, l'installazione avrà esito negativo e non è consigliabile esporre la macchina virtuale alle reti esterne.
Per uscire dall'editor vi, premere prima il tasto ESC e quindi immettere il comando
:wqper eseguire la scrittura del file e uscire.
Creare il cluster Pacemaker
In questa sezione verrà abilitato e avviato il servizio pcsd e quindi verrà configurato il cluster. Per SQL Server in Linux, le risorse del cluster non vengono create automaticamente. È necessario abilitare e creare manualmente le risorse Pacemaker. Per ulteriori altre, vedere l'articolo sulla configurazione di un'istanza del cluster di failover per RHEL.
Abilitare e avviare il servizio pcsd e Pacemaker
Eseguire i comandi in tutti i nodi. In questo modo, i nodi potranno essere aggiunti nuovamente al cluster dopo il riavvio.
sudo systemctl enable pcsd sudo systemctl start pcsd sudo systemctl enable pacemakerRimuovere eventuali configurazioni cluster esistenti da tutti i nodi. Esegui questo comando:
sudo pcs cluster destroy sudo systemctl enable pacemakerNel nodo primario eseguire i comandi seguenti per configurare il cluster.
- Quando si esegue il comando
pcs cluster authper autenticare i nodi del cluster, verrà richiesta una password. Immettere la password per l'utente hacluster creato in precedenza.
RHEL7
sudo pcs cluster auth <VM1> <VM2> <VM3> -u hacluster sudo pcs cluster setup --name az-hacluster <VM1> <VM2> <VM3> --token 30000 sudo pcs cluster start --all sudo pcs cluster enable --allRHEL 8
Per RHEL 8, sarà necessario autenticare i nodi separatamente. Immettere manualmente il nome utente e la password per hacluster, quando richiesto.
sudo pcs host auth <node1> <node2> <node3> sudo pcs cluster setup <clusterName> <node1> <node2> <node3> sudo pcs cluster start --all sudo pcs cluster enable --all- Quando si esegue il comando
Eseguire il comando seguente per verificare che tutti i nodi siano online.
sudo pcs statusRHEL 7
Se tutti i nodi sono online, l'output visualizzato sarà simile al seguente:
Cluster name: az-hacluster WARNINGS: No stonith devices and stonith-enabled is not false Stack: corosync Current DC: <VM2> (version 1.1.19-8.el7_6.5-c3c624ea3d) - partition with quorum Last updated: Fri Aug 23 18:27:57 2019 Last change: Fri Aug 23 18:27:56 2019 by hacluster via crmd on <VM2> 3 nodes configured 0 resources configured Online: [ <VM1> <VM2> <VM3> ] No resources Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabledRHEL 8
Cluster name: az-hacluster WARNINGS: No stonith devices and stonith-enabled is not false Cluster Summary: * Stack: corosync * Current DC: <VM2> (version 1.1.19-8.el7_6.5-c3c624ea3d) - partition with quorum * Last updated: Fri Aug 23 18:27:57 2019 * Last change: Fri Aug 23 18:27:56 2019 by hacluster via crmd on <VM2> * 3 nodes configured * 0 resource instances configured Node List: * Online: [ <VM1> <VM2> <VM3> ] Full List of Resources: * No resources Daemon Status: * corosync: active/enabled * pacemaker: active/enabled * pcsd: active/enabledImpostare i voti previsti nel cluster attivo su 3. Questo comando influisce solo sul cluster attivo e non modifica i file di configurazione.
In tutti i nodi impostare i voti previsti con il comando seguente:
sudo pcs quorum expected-votes 3
Configurare l'agente di isolamento
Per configurare un agente di isolamento, per questa esercitazione vengono modificate le istruzioni seguenti. Per altre informazioni, vedere Creare un dispositivo STONITH.
Controllare la versione dell'agente di isolamento di Azure per assicurarsi che sia aggiornata. Utilizza il seguente comando:
sudo yum info fence-agents-azure-arm
Verrà visualizzato un output simile all'esempio seguente.
Loaded plugins: langpacks, product-id, search-disabled-repos, subscription-manager
Installed Packages
Name : fence-agents-azure-arm
Arch : x86_64
Version : 4.2.1
Release : 11.el7_6.8
Size : 28 k
Repo : installed
From repo : rhel-ha-for-rhel-7-server-eus-rhui-rpms
Summary : Fence agent for Azure Resource Manager
URL : https://github.com/ClusterLabs/fence-agents
License : GPLv2+ and LGPLv2+
Description : The fence-agents-azure-arm package contains a fence agent for Azure instances.
Registrare una nuova applicazione in Microsoft Entra ID
Per registrare una nuova applicazione in Microsoft Entra ID (in precedenza Azure Active Directory), seguire questa procedura:
- Vai a https://portal.azure.com.
- Aprire il riquadro Proprietà ID Microsoft Entra e annotare
Tenant ID. - Selezionare Registrazioni app.
- Seleziona Nuova registrazione.
- Immettere un Nome, ad esempio
<resourceGroupName>-app. Per tipi di account supportati, selezionare Account solo in questa directory dell'organizzazione (solo Microsoft - Tenant singolo). - Selezionare Web per URI di reindirizzamento e immettere un URL, ad esempio
http://localhost, e selezionare Aggiungi. L'URL di accesso può essere qualsiasi URL valido. Al termine dell'operazione, selezionare Registra. - Selezionare Certificati e segreti per la nuova registrazione app e quindi fare clic su Nuovo segreto client.
- Immettere una descrizione per una nuova chiave (segreto client), quindi selezionare Aggiungi.
- Prendere nota del valore del segreto. Verrà usato come password per l'entità servizio.
- Selezionare Panoramica. Prendere nota dell'ID applicazione. Viene usato come nome utente (ID di accesso nelle azioni seguenti) dell'entità servizio.
Creare un ruolo personalizzato per l'agente di isolamento
Seguire l'esercitazione Creare un ruolo personalizzato di Azure tramite l'interfaccia della riga di comando di Azure.
Il file JSON dovrebbe avere un aspetto simile all'esempio seguente:
- Sostituire
<username>con il nome desiderato. In questo modo sarà possibile evitare eventuali duplicati durante la creazione di questa definizione del ruolo. - Sostituire
<subscriptionId>con l'ID della sottoscrizione di Azure.
{
"Name": "Linux Fence Agent Role-<username>",
"Id": null,
"IsCustom": true,
"Description": "Allows to power-off and start virtual machines",
"Actions": [
"Microsoft.Compute/*/read",
"Microsoft.Compute/virtualMachines/powerOff/action",
"Microsoft.Compute/virtualMachines/start/action"
],
"NotActions": [
],
"AssignableScopes": [
"/subscriptions/<subscriptionId>"
]
}
Per aggiungere il ruolo, eseguire il comando seguente:
- Sostituire
<filename>con il nome file. - Se si esegue il comando da un percorso diverso dalla cartella in cui è stato salvato il file, includere il percorso della cartella del file nel comando.
az role definition create --role-definition "<filename>.json"
Verrà visualizzato l'output seguente:
{
"assignableScopes": [
"/subscriptions/<subscriptionId>"
],
"description": "Allows to power-off and start virtual machines",
"id": "/subscriptions/<subscriptionId>/providers/Microsoft.Authorization/roleDefinitions/<roleNameId>",
"name": "<roleNameId>",
"permissions": [
{
"actions": [
"Microsoft.Compute/*/read",
"Microsoft.Compute/virtualMachines/powerOff/action",
"Microsoft.Compute/virtualMachines/start/action"
],
"dataActions": [],
"notActions": [],
"notDataActions": []
}
],
"roleName": "Linux Fence Agent Role-<username>",
"roleType": "CustomRole",
"type": "Microsoft.Authorization/roleDefinitions"
}
Assegnare il ruolo personalizzato all'entità servizio
Assegnare all'entità servizio il ruolo personalizzato Linux Fence Agent Role-<username> creato nel passaggio precedente. Non usare più il ruolo Proprietario.
- Passare a https://portal.azure.com
- Aprire il riquadro Tutte le risorse
- Selezionare la macchina virtuale del primo nodo del cluster.
- Selezionare Controllo di accesso (IAM) .
- Selezionare Aggiungi un'assegnazione di ruolo
- Selezionare il ruolo
Linux Fence Agent Role-<username>dall'elenco Ruolo - Nell'elenco Seleziona immettere il nome dell'applicazione creata sopra,
<resourceGroupName>-app - Seleziona Salva
- Ripetere questi passaggi in tutti i nodi del cluster.
Creare i dispositivi STONITH
Eseguire questo comando nel nodo 1:
- Sostituire
<ApplicationID>con il valore dell'ID della registrazione dell'applicazione. - Sostituire
<servicePrincipalPassword>con il valore del segreto client. - Sostituire
<resourceGroupName>con il gruppo di risorse della sottoscrizione usata per questa esercitazione. - Sostituire
<tenantID>e<subscriptionId>con i valori della sottoscrizione di Azure.
sudo pcs property set stonith-timeout=900
sudo pcs stonith create rsc_st_azure fence_azure_arm login="<ApplicationID>" passwd="<servicePrincipalPassword>" resourceGroup="<resourceGroupName>" tenantId="<tenantID>" subscriptionId="<subscriptionId>" power_timeout=240 pcmk_reboot_timeout=900
Poiché al firewall è già stata aggiunta una regola per consentire il servizio a disponibilità elevata (--add-service=high-availability), non è necessario aprire le seguenti porte del firewall in tutti i nodi: 2224, 3121, 21064, 5405. Tuttavia, se si verificano problemi di connessione con la disponibilità elevata, usare il comando seguente per aprire le porte associate alla disponibilità elevata.
Suggerimento
È facoltativamente possibile aggiungere contemporaneamente tutte le porte indicate in questa esercitazione per risparmiare tempo. Le porte che devono essere aperte sono illustrate sotto nelle sezioni corrispondenti. Per aggiungere ora tutte le porte, aggiungere le porte aggiuntive: 1433 e 5022.
sudo firewall-cmd --zone=public --add-port=2224/tcp --add-port=3121/tcp --add-port=21064/tcp --add-port=5405/tcp --permanent
sudo firewall-cmd --reload
Installare SQL Server e mssql-tools
Nota
Se le macchine virtuali sono state create con SQL Server 2019 (15.x) preinstallato in RHEL8-HA, è possibile ignorare i passaggi seguenti per installare SQL Server e mssql-tools e avviare la sezione Configura un gruppo di disponibilità dopo aver configurato la password dell'amministratore di sistema in tutte le macchine virtuali usando il comando sudo /opt/mssql/bin/mssql-conf set-sa-password in tutte le macchine virtuali.
Vedere la sezione seguente per installare SQL Server e mssql-tools nelle macchine virtuali. È possibile scegliere uno degli esempi seguenti per installare SQL Server 2017 (14.x) in RHEL 7 o SQL Server 2019 (15.x) in RHEL 8. Eseguire ogni azione in tutti i nodi. Per altre informazioni, vedere Installare SQL Server in una macchina virtuale Red Hat.
Installazione di SQL Server nelle macchine virtuali
Per installare SQL Server verranno usati i comandi seguenti:
RHEL 7 con SQL Server 2017
sudo curl -o /etc/yum.repos.d/mssql-server.repo https://packages.microsoft.com/config/rhel/7/mssql-server-2017.repo
sudo yum install -y mssql-server
sudo /opt/mssql/bin/mssql-conf setup
sudo yum install mssql-server-ha
RHEL 8 con SQL Server 2019
sudo curl -o /etc/yum.repos.d/mssql-server.repo https://packages.microsoft.com/config/rhel/8/mssql-server-2019.repo
sudo yum install -y mssql-server
sudo /opt/mssql/bin/mssql-conf setup
sudo yum install mssql-server-ha
Aprire la porta del firewall 1433 per le connessioni remote
Per connettersi in modalità remota, è necessario aprire la porta 1433 nella macchina virtuale. Usare i comandi seguenti per aprire la porta 1433 nel firewall di ogni macchina virtuale:
sudo firewall-cmd --zone=public --add-port=1433/tcp --permanent
sudo firewall-cmd --reload
Installare gli strumenti da riga di comando di SQL Server
Per installare gli strumenti da riga di comando di SQL Server verranno usati i comandi seguenti. Per altre informazioni, vedere Installare gli strumenti da riga di comando di SQL Server.
RHEL 7
sudo curl -o /etc/yum.repos.d/msprod.repo https://packages.microsoft.com/config/rhel/7/prod.repo
sudo yum install -y mssql-tools unixODBC-devel
RHEL 8
sudo curl -o /etc/yum.repos.d/msprod.repo https://packages.microsoft.com/config/rhel/8/prod.repo
sudo yum install -y mssql-tools unixODBC-devel
Nota
Per praticità, aggiungere /opt/mssql-tools/bin/ alla variabile di ambiente PATH. In questo modo è possibile eseguire gli strumenti senza specificare il percorso completo. Eseguire i comandi seguenti per modificare la variabile PATHecho 'export PATH="$PATH:/opt/mssql-tools/bin"' >> ~/.bash_profileecho 'export PATH="$PATH:/opt/mssql-tools/bin"' >> ~/.bashrcsource ~/.bashrc sia per le sessioni di accesso che per le sessioni interattive/non di accesso:
Verificare lo stato di SQL Server
Al termine della configurazione, è possibile controllare lo stato di SQL Server e verificare che sia in esecuzione:
systemctl status mssql-server --no-pager
Verrà visualizzato l'output seguente:
● mssql-server.service - Microsoft SQL Server Database Engine
Loaded: loaded (/usr/lib/systemd/system/mssql-server.service; enabled; vendor preset: disabled)
Active: active (running) since Thu 2019-12-05 17:30:55 UTC; 20min ago
Docs: https://learn.microsoft.com/sql/linux
Main PID: 11612 (sqlservr)
CGroup: /system.slice/mssql-server.service
├─11612 /opt/mssql/bin/sqlservr
└─11640 /opt/mssql/bin/sqlservr
Configurare un gruppo di disponibilità
Per configurare un gruppo di disponibilità Always On di SQL Server per le macchine virtuali, seguire questa procedura. Per altre informazioni, vedere Configurare gruppi di disponibilità Always On di SQL Server per la disponibilità elevata in Linux.
Abilitare la funzionalità Gruppi di disponibilità Always On e riavviare mssql-server
Abilitare i gruppi di disponibilità Always On in ogni nodo che ospita un'istanza di SQL Server. Riavviare quindi mssql-server. Eseguire lo script seguente:
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
sudo systemctl restart mssql-server
Creare un certificato
L'autenticazione di Active Directory per l'endpoint del gruppo di disponibilità non è attualmente supportata. È quindi necessario usare un certificato per la crittografia dell'endpoint del gruppo di disponibilità.
Connettersi a tutti i nodi usando SQL Server Management Studio (SSMS) o sqlcmd. Eseguire i comandi seguenti per abilitare la sessione AlwaysOn_health e creare una chiave master:
Importante
Se ci si connette all'istanza di SQL Server in modalità remota, sarà necessario aprire la porta 1433 sul firewall. Sarà inoltre necessario consentire le connessioni in ingresso alla porta 1433 nel gruppo di sicurezza di rete per ogni macchina virtuale. Per altre informazioni, vedere Creare una regola di sicurezza per la creazione di una regola di sicurezza in ingresso.
- Sostituire
<Master_Key_Password>con la propria password.
ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE=ON); GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<Master_Key_Password>';- Sostituire
Connettersi alla replica primaria usando SSMS o sqlcmd. I comandi seguenti creeranno un certificato in
/var/opt/mssql/data/dbm_certificate.cere una chiave privata invar/opt/mssql/data/dbm_certificate.pvknella replica primaria di SQL Server:- Sostituire
<Private_Key_Password>con la propria password.
CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; GO BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '<Private_Key_Password>' ); GO- Sostituire
Per uscire dalla sessione sqlcmd eseguire il comando exit e tornare alla sessione SSH.
Copiare il certificato nelle repliche secondarie e creare i certificati nel server
Copiare i due file creati nello stesso percorso in tutti i server che ospiteranno le repliche di disponibilità.
Nel server primario eseguire il comando
scpper copiare il certificato nei server di destinazione:- Sostituire
<username>e<VM2>con il nome utente e il nome della macchina virtuale di destinazione in uso. - Eseguire questo comando per tutte le repliche secondarie.
Nota
Non è necessario eseguire
sudo -i, che restituisce l'ambiente radice. È semplicemente possibile eseguire il comandosudoprima di ogni comando come già fatto in precedenza in questa esercitazione.# The below command allows you to run commands in the root environment sudo -iscp /var/opt/mssql/data/dbm_certificate.* <username>@<VM2>:/home/<username>- Sostituire
Nel server di destinazione eseguire questo comando:
- Sostituire
<username>con il nome utente. - Il comando
mvsposta i file o la directory da una posizione a un'altra. - Il comando
chownviene usato per modificare il proprietario e il gruppo di file, directory o collegamenti. - Eseguire questi comandi per tutte le repliche secondarie.
sudo -i mv /home/<username>/dbm_certificate.* /var/opt/mssql/data/ cd /var/opt/mssql/data chown mssql:mssql dbm_certificate.*- Sostituire
Lo script Transact-SQL seguente crea un certificato dal backup creato nella replica primaria di SQL Server. Aggiornare lo script con password complesse. La password di decrittografia è la stessa password usata per creare il file PVK nel passaggio precedente. Per creare il certificato, eseguire lo script seguente in tutti i server secondari usando sqlcmd o SSMS:
CREATE CERTIFICATE dbm_certificate FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '<Private_Key_Password>' ); GO
Creare endpoint di mirroring del database in tutte le repliche
Eseguire lo script seguente in tutte le istanze di SQL Server usando sqlcmd o SSMS:
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
GO
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
GO
Creare il gruppo di disponibilità
Connettersi all'istanza di SQL Server che ospita la replica primaria usando sqlcmd o SSMS. Per creare il gruppo di disponibilità, eseguire questo comando:
- Sostituire
ag1con il nome del gruppo di disponibilità desiderato. - Sostituire i valori di
<VM1>,<VM2>e<VM3>con i nomi delle istanze di SQL Server che ospitano le repliche.
CREATE AVAILABILITY GROUP [ag1]
WITH (DB_FAILOVER = ON, CLUSTER_TYPE = EXTERNAL)
FOR REPLICA ON
N'<VM1>'
WITH (
ENDPOINT_URL = N'tcp://<VM1>:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'<VM2>'
WITH (
ENDPOINT_URL = N'tcp://<VM2>:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'<VM3>'
WITH(
ENDPOINT_URL = N'tcp://<VM3>:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
);
GO
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE;
GO
Creare un account di accesso di SQL Server per Pacemaker
In tutte le istanze di SQL Server creare un account di accesso di SQL Server per Pacemaker. Il codice Transact-SQL seguente crea un account di accesso.
- Sostituire
<password>con una password complessa personale.
USE [master]
GO
CREATE LOGIN [pacemakerLogin] with PASSWORD= N'<password>';
GO
ALTER SERVER ROLE [sysadmin] ADD MEMBER [pacemakerLogin];
GO
In tutte le istanze di SQL Server salvare le credenziali usate per l'account di accesso di SQL Server.
Creare il file :
sudo vi /var/opt/mssql/secrets/passwdAggiungere le righe seguenti al file:
pacemakerLogin <password>Per uscire dall'editor vi, premere prima il tasto ESC e quindi immettere il comando
:wqper eseguire la scrittura del file e uscire.Impostare il file come leggibile solo dall'utente ROOT:
sudo chown root:root /var/opt/mssql/secrets/passwd sudo chmod 400 /var/opt/mssql/secrets/passwd
Aggiungere le repliche secondarie al gruppo di disponibilità
Per aggiungere le repliche secondarie al gruppo di disponibilità, è necessario aprire la porta 5022 sul firewall per tutti i server. Nella sessione SSH eseguire questo comando:
sudo firewall-cmd --zone=public --add-port=5022/tcp --permanent sudo firewall-cmd --reloadNelle repliche secondarie eseguire i comandi seguenti per aggiungerle al gruppo di disponibilità:
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE; GONella replica primaria e in ogni replica secondaria eseguire lo script Transact-SQL seguente:
GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::ag1 TO pacemakerLogin; GO GRANT VIEW SERVER STATE TO pacemakerLogin; GODopo aver aggiunto le repliche secondarie, sarà possibile visualizzarle in Esplora oggetti di SSMS espandendo il nodo Disponibilità elevata Always On:
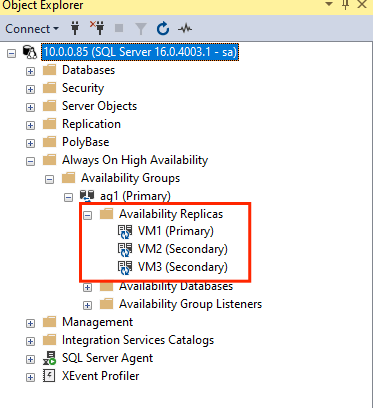
Aggiungere un database al gruppo di disponibilità
Si seguiranno le procedure illustrate nell'articolo sulla configurazione del gruppo di disponibilità per aggiungere un database.
In questo passaggio verranno usati i comandi Transact-SQL seguenti. Eseguire questi comandi nella replica primaria:
CREATE DATABASE [db1]; -- creates a database named db1
GO
ALTER DATABASE [db1] SET RECOVERY FULL; -- set the database in full recovery model
GO
BACKUP DATABASE [db1] -- backs up the database to disk
TO DISK = N'/var/opt/mssql/data/db1.bak';
GO
ALTER AVAILABILITY GROUP [ag1] ADD DATABASE [db1]; -- adds the database db1 to the AG
GO
Verificare che il database sia creato nei server secondari
In ogni replica secondaria di SQL Server eseguire la query seguente per verificare che il database db1 sia stato creato e che si trovi nello stato SINCRONIZZATO:
SELECT * FROM sys.databases WHERE name = 'db1';
GO
SELECT DB_NAME(database_id) AS 'database', synchronization_state_desc FROM sys.dm_hadr_database_replica_states;
Se l'elenco synchronization_state_desc restituisce SINCRONIZZATO per db1, significa che le repliche sono sincronizzate. I server secondari mostrano db1 nella replica primaria.
Creare le risorse del gruppo di disponibilità nel cluster Pacemaker
Verranno seguite le istruzioni fornite nella guida Creare le risorse dei gruppi di disponibilità nel cluster Pacemaker.
Nota
Comunicazione senza distorsione
Questo articolo contiene riferimenti al termine slave, un termine che Microsoft considera offensivo se usato in questo contesto. Il termine viene visualizzato in questo articolo perché è attualmente incluso nel software. Quando il termine verrà rimosso dal software, verrà rimosso dall'articolo.
Creare la risorsa cluster del gruppo di disponibilità
Usare uno dei comandi seguenti in base all'ambiente scelto in precedenza per creare la risorsa
ag_clusternel gruppo di disponibilitàag1.RHEL 7
sudo pcs resource create ag_cluster ocf:mssql:ag ag_name=ag1 meta failure-timeout=30s master notify=trueRHEL 8
sudo pcs resource create ag_cluster ocf:mssql:ag ag_name=ag1 meta failure-timeout=30s promotable notify=trueControllare la risorsa e verificare che sia online prima di procedere con il comando seguente:
sudo pcs resourceVerrà visualizzato l'output seguente:
RHEL 7
[<username>@VM1 ~]$ sudo pcs resource Master/Slave Set: ag_cluster-master [ag_cluster] Masters: [ <VM1> ] Slaves: [ <VM2> <VM3> ]RHEL 8
[<username>@VM1 ~]$ sudo pcs resource * Clone Set: ag_cluster-clone [ag_cluster] (promotable): * ag_cluster (ocf::mssql:ag) : Slave VMrhel3 (Monitoring) * ag_cluster (ocf::mssql:ag) : Master VMrhel1 (Monitoring) * ag_cluster (ocf::mssql:ag) : Slave VMrhel2 (Monitoring)
Creare una risorsa indirizzo IP virtuale
Usare un indirizzo IP statico disponibile della rete per creare una risorsa indirizzo IP virtuale. È possibile trovarne uno usando lo strumento di comando
nmap.nmap -sP <IPRange> # For example: nmap -sP 10.0.0.* # The above will scan for all IP addresses that are already occupied in the 10.0.0.x space.Impostare la proprietà stonith-enabled su false:
sudo pcs property set stonith-enabled=falsePer creare la risorsa indirizzo IP virtuale, usare il comando seguente: Sostituire il valore per
<availableIP>con un indirizzo IP inutilizzato.sudo pcs resource create virtualip ocf:heartbeat:IPaddr2 ip=<availableIP>
Aggiungere i vincoli
Per fare in modo che la risorsa indirizzo IP e la risorsa gruppo di disponibilità siano in esecuzione nello stesso nodo, è necessario configurare un vincolo di condivisione del percorso. Esegui questo comando:
RHEL 7
sudo pcs constraint colocation add virtualip ag_cluster-master INFINITY with-rsc-role=MasterRHEL 8
sudo pcs constraint colocation add virtualip with master ag_cluster-clone INFINITY with-rsc-role=MasterCreare un vincolo di ordinamento per fare in modo che la risorsa del gruppo di disponibilità sia attiva e in esecuzione prima dell'indirizzo IP. Mentre il vincolo di condivisione del percorso implica un vincolo di ordinamento, questo lo applica.
RHEL 7
sudo pcs constraint order promote ag_cluster-master then start virtualipRHEL 8
sudo pcs constraint order promote ag_cluster-clone then start virtualipPer verificare i vincoli, eseguire questo comando:
sudo pcs constraint list --fullVerrà visualizzato l'output seguente:
RHEL 7
Location Constraints: Ordering Constraints: promote ag_cluster-master then start virtualip (kind:Mandatory) (id:order-ag_cluster-master-virtualip-mandatory) Colocation Constraints: virtualip with ag_cluster-master (score:INFINITY) (with-rsc-role:Master) (id:colocation-virtualip-ag_cluster-master-INFINITY) Ticket Constraints:RHEL 8
Location Constraints: Ordering Constraints: promote ag_cluster-clone then start virtualip (kind:Mandatory) (id:order-ag_cluster-clone-virtualip-mandatory) Colocation Constraints: virtualip with ag_cluster-clone (score:INFINITY) (with-rsc-role:Master) (id:colocation-virtualip-ag_cluster-clone-INFINITY) Ticket Constraints:
Riabilitare STONITH
A questo punto, è possibile procedere al test. Per riabilitare STONITH nel cluster eseguire questo comando nel nodo 1:
sudo pcs property set stonith-enabled=true
Controllare lo stato del cluster
È possibile controllare lo stato delle risorse cluster con il comando seguente:
[<username>@VM1 ~]$ sudo pcs status
Cluster name: az-hacluster
Stack: corosync
Current DC: <VM3> (version 1.1.19-8.el7_6.5-c3c624ea3d) - partition with quorum
Last updated: Sat Dec 7 00:18:38 2019
Last change: Sat Dec 7 00:18:02 2019 by root via cibadmin on VM1
3 nodes configured
5 resources configured
Online: [ <VM1> <VM2> <VM3> ]
Full list of resources:
Master/Slave Set: ag_cluster-master [ag_cluster]
Masters: [ <VM2> ]
Slaves: [ <VM1> <VM3> ]
virtualip (ocf::heartbeat:IPaddr2): Started <VM2>
rsc_st_azure (stonith:fence_azure_arm): Started <VM1>
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Failover di test
Per assicurarsi che la configurazione abbia avuto esito positivo fino a questo momento, si testerà un failover. Per altre informazioni, vedere Failover di un gruppo di disponibilità Always On in Linux.
Eseguire il comando seguente per procedere al failover manuale della replica primaria in
<VM2>. Sostituire<VM2>con il valore del nome del server.RHEL 7
sudo pcs resource move ag_cluster-master <VM2> --masterRHEL 8
sudo pcs resource move ag_cluster-clone <VM2> --masterÈ anche possibile specificare un'opzione aggiuntiva in modo che il vincolo temporaneo creato per spostare la risorsa in un nodo desiderato venga disabilitato automaticamente, senza la necessità di eseguire i passaggi 2 e 3 seguenti.
RHEL 7
sudo pcs resource move ag_cluster-master <VM2> --master lifetime=30SRHEL 8
sudo pcs resource move ag_cluster-clone <VM2> --master lifetime=30SUn'altra alternativa consiste nell'automatizzare i passaggi 2 e 3 seguenti che cancellano il vincolo temporaneo nel comando stesso di spostamento della risorsa combinando più comandi in una singola riga.
RHEL 7
sudo pcs resource move ag_cluster-master <VM2> --master && sleep 30 && pcs resource clear ag_cluster-masterRHEL 8
sudo pcs resource move ag_cluster-clone <VM2> --master && sleep 30 && pcs resource clear ag_cluster-cloneSe si controllano di nuovo i vincoli, si noterà che è stato aggiunto un altro vincolo a seguito del failover manuale:
RHEL 7
[<username>@VM1 ~]$ sudo pcs constraint list --full Location Constraints: Resource: ag_cluster-master Enabled on: VM2 (score:INFINITY) (role: Master) (id:cli-prefer-ag_cluster-master) Ordering Constraints: promote ag_cluster-master then start virtualip (kind:Mandatory) (id:order-ag_cluster-master-virtualip-mandatory) Colocation Constraints: virtualip with ag_cluster-master (score:INFINITY) (with-rsc-role:Master) (id:colocation-virtualip-ag_cluster-master-INFINITY) Ticket Constraints:RHEL 8
[<username>@VM1 ~]$ sudo pcs constraint list --full Location Constraints: Resource: ag_cluster-master Enabled on: VM2 (score:INFINITY) (role: Master) (id:cli-prefer-ag_cluster-clone) Ordering Constraints: promote ag_cluster-clone then start virtualip (kind:Mandatory) (id:order-ag_cluster-clone-virtualip-mandatory) Colocation Constraints: virtualip with ag_cluster-clone (score:INFINITY) (with-rsc-role:Master) (id:colocation-virtualip-ag_cluster-clone-INFINITY) Ticket Constraints:Rimuovere il vincolo con l'ID
cli-prefer-ag_cluster-masterusando il comando seguente:RHEL 7
sudo pcs constraint remove cli-prefer-ag_cluster-masterRHEL 8
sudo pcs constraint remove cli-prefer-ag_cluster-cloneControllare le risorse cluster usando il comando
sudo pcs resource. Si noterà che l'istanza primaria è ora<VM2>.[<username>@<VM1> ~]$ sudo pcs resource Master/Slave Set: ag_cluster-master [ag_cluster] ag_cluster (ocf::mssql:ag): FAILED <VM1> (Monitoring) Masters: [ <VM2> ] Slaves: [ <VM3> ] virtualip (ocf::heartbeat:IPaddr2): Started <VM2> [<username>@<VM1> ~]$ sudo pcs resource Master/Slave Set: ag_cluster-master [ag_cluster] Masters: [ <VM2> ] Slaves: [ <VM1> <VM3> ] virtualip (ocf::heartbeat:IPaddr2): Started <VM2>
Testare l'isolamento
Per testare l'isolamento, eseguire il comando seguente. Provare a eseguire il comando seguente da <VM1> per <VM3>.
sudo pcs stonith fence <VM3> --debug
Nota
Per impostazione predefinita, l'azione di isolamento porta il nodo offline e quindi di nuovo online. Se si vuole solo portare offline il nodo, usare l'opzione --off nel comando.
Dovrebbe essere visualizzato l'output seguente:
[<username>@<VM1> ~]$ sudo pcs stonith fence <VM3> --debug
Running: stonith_admin -B <VM3>
Return Value: 0
--Debug Output Start--
--Debug Output End--
Node: <VM3> fenced
Per altre informazioni sul test di un dispositivo di isolamento, vedere l'articolo di Red Hat seguente.
Passaggio successivo
Commenti e suggerimenti
Presto disponibile: nel corso del 2024 verranno dismessi i problemi di GitHub come meccanismo di feedback per il contenuto e verranno sostituiti con un nuovo sistema di feedback. Per altre informazioni, vedere: https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per