Che cos'è l'analisi delle immagini?
Il servizio Analisi delle immagini di Visione di Azure AI può estrarre un'ampia gamma di caratteristiche visive da un'immagine. Il servizio, ad esempio, consente di determinare se il contenuto dell'immagine è per adulti, se contiene specifici marchi o oggetti o di individuare visi umani.
La versione più recente di Analisi immagini, 4.0, ora disponibile a livello generale, include nuove funzionalità come il rilevamento sincrono di OCR e persone. È consigliabile usare questa versione in futuro.
È possibile usare l'analisi delle immagini tramite un SDK della libreria client o chiamando direttamente l'API REST. Seguire la guida introduttiva per iniziare.
In alternativa, è possibile provare le funzionalità di Analisi immagini in modo rapido e semplice nel browser usando Vision Studio.
Questa documentazione contiene i tipi di articoli seguenti:
- Le guide introduttive sono istruzioni dettagliate che consentono di effettuare chiamate al servizio e ottenere risultati in un breve periodo di tempo.
- Le guide pratiche contengono istruzioni per l'uso del servizio in modi più specifici o personalizzati.
- Gli articoli concettuali forniscono spiegazioni approfondite delle funzionalità e delle funzionalità del servizio.
- Le esercitazioni sono guide più lunghe che illustrano come usare questo servizio come componente in soluzioni aziendali più ampie.
Per un approccio più strutturato, seguire un modulo Training per l'analisi delle immagini.
Versioni di Analisi immagini
Importante
Selezionare la versione dell'API Analisi immagini più adatta alle proprie esigenze.
| Versione | Funzionalità disponibili | Raccomandazione |
|---|---|---|
| versione 4.0 | Leggere testo, didascalie, didascalia dense, tag, rilevamento oggetti, classificazione di immagini personalizzate/rilevamento oggetti, Persone, ritaglio intelligente | Modelli migliori; usare la versione 4.0 se supporta il caso d'uso. |
| versione 3.2 | Tag, oggetti, descrizioni, marchi, visi, tipo di immagine, combinazione di colori, punti di riferimento, celebrità, contenuto per adulti, ritaglio intelligente | Gamma più ampia di funzionalità; usare la versione 3.2 se il caso d'uso non è ancora supportato nella versione 4.0 |
È consigliabile usare l'API Image Analysis 4.0 se supporta il caso d'uso. Usare la versione 3.2 se il caso d'uso non è ancora supportato dalla versione 4.0.
È anche necessario usare la versione 3.2 per eseguire l'immagine didascalia e la risorsa Visione si trova all'esterno di queste aree di Azure: Stati Uniti orientali, Francia centrale, Corea centrale, Europa settentrionale, Asia sud-orientale, Europa occidentale e Stati Uniti occidentali, Asia orientale. La funzionalità image didascalia ing in Image Analysis 4.0 è supportata solo in queste aree di Azure. Il didascalia di immagini nella versione 3.2 è disponibile in tutte le aree di Visione artificiale di Azure.
Analyze Image (Analisi dell'immagine)
È possibile analizzare le immagini per ricevere informazioni dettagliate sulle caratteristiche e gli aspetti visivi. Tutte le funzionalità di questo elenco sono fornite dall'API Analizza immagine. Per iniziare, seguire una guida di avvio rapido.
| Nome | Descrizione | Pagina Concetto |
|---|---|---|
| Personalizzazione del modello (solo anteprima v4.0) | È possibile creare ed eseguire il training di modelli personalizzati per eseguire la classificazione delle immagini o il rilevamento di oggetti. Usare immagini personalizzate, etichettarle con tag personalizzati e l'analisi delle immagini esegue il training di un modello personalizzato per il caso d'uso. | Personalizzazione del modello |
| Leggere il testo dalle immagini (solo v4.0) | La versione 4.0 di anteprima di Analisi immagini offre la possibilità di estrarre testo leggibile dalle immagini. Rispetto all'API di lettura asincrona Visione artificiale 3.2, la nuova versione offre il noto motore OCR di lettura in un'API sincrona ottimizzata per le prestazioni unificata che semplifica l'ocr insieme ad altre informazioni dettagliate in una singola chiamata API. | OCR per le immagini |
| Rilevare le persone nelle immagini (solo v4.0) | La versione 4.0 di Analisi immagini offre la possibilità di rilevare le persone visualizzate nelle immagini. Vengono restituite le coordinate del rettangolo di selezione di ogni persona rilevata, insieme a un punteggio di attendibilità. | rilevamento Persone |
| Generare didascalia di immagini | Generare una didascalia di un'immagine in linguaggio leggibile usando frasi complete. gli algoritmi di Visione artificiale generano didascalia in base agli oggetti identificati nell'immagine. Il modello di immagine 4.0 didascalia ing è un'implementazione più avanzata e funziona con una gamma più ampia di immagini di input. È disponibile solo nelle aree geografiche seguenti: Stati Uniti orientali, Francia centrale, Corea centrale, Europa settentrionale, Asia sud-orientale, Europa occidentale, Stati Uniti occidentali. La versione 4.0 consente anche di usare didascalia densi, che genera didascalia dettagliati per i singoli oggetti presenti nell'immagine. L'API restituisce le coordinate del rettangolo delimitatore (in pixel) di ogni oggetto trovato nell'immagine, più un didascalia. È possibile usare questa funzionalità per generare descrizioni di parti separate di un'immagine. 
|
Generare didascalia immagine (v3.2) (v4.0) |
| Rilevare gli oggetti | Il rilevamento di oggetti è simile all'assegnazione di tag, ma l'API restituisce le coordinate del rettangolo di selezione per ogni tag applicato. Ad esempio, se un'immagine contiene un cane, un gatto e una persona, l'operazione Rileva elenca tali oggetti insieme alle coordinate nell'immagine. È possibile usare questa funzionalità per elaborare ulteriormente le relazioni tra gli oggetti in un'immagine. Questa funzionalità consente anche di sapere quando sono presenti più istanze dello stesso tag in un'immagine. 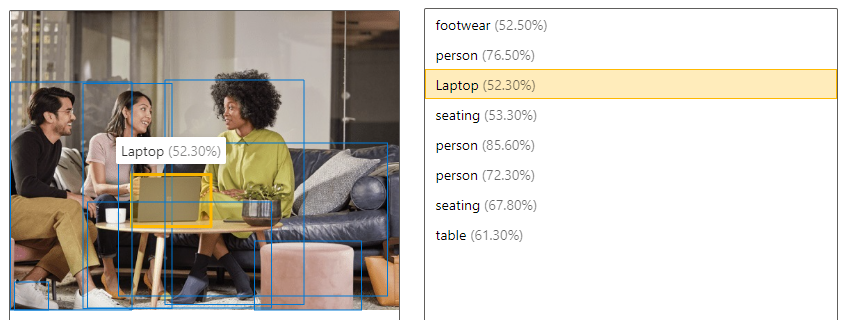
|
Rilevare gli oggetti (v3.2) (v4.0) |
| Assegnare tag agli elementi visivi | Identificare e assegnare tag agli elementi visivi di un'immagine in base a un set di migliaia di oggetti riconoscibili, esseri viventi, panorami e azioni. Quando i tag sono ambigui o non di conoscenza comune, la risposta dell'API fornisce suggerimenti per chiarire il contesto del tag. L'assegnazione di tag non è limitata al soggetto principale, ad esempio una persona in primo piano, ma include anche scenari (interni o esterni), arredamenti, strumenti, piante, animali, accessori, gadget e così via.
|
Funzionalità visive tag (v3.2) (v4.0) |
| Ottenere l'area di interesse/ritaglio intelligente | Analizzare il contenuto di un'immagine per restituire le coordinate dell'area di interesse che corrisponde a una proporzione specificata. Visione artificiale restituisce le coordinate del rettangolo delimitatore dell'area, in modo che l'applicazione chiamante possa modificare l'immagine originale in base alle esigenze. Il modello di ritaglio intelligente versione 4.0 è un'implementazione più avanzata e funziona con una gamma più ampia di immagini di input. È disponibile solo nelle aree geografiche seguenti: Stati Uniti orientali, Francia centrale, Corea centrale, Europa settentrionale, Asia sud-orientale, Europa occidentale, Stati Uniti occidentali. |
Generare un'anteprima (v3.2) (anteprima v4.0) |
| Rilevare i marchi (solo v3.2) | È possibile identificare i marchi commerciali in immagini o video da un database di migliaia di logo globali. È ad esempio possibile usare questa funzionalità per individuare i marchi più popolari sui social media o quelli più prevalenti nel posizionamento dei prodotti multimediali. | Rilevare i marchi |
| Classificare un'immagine (solo v3.2) | È possibile identificare e classificare un'intera immagine usando una tassonomia di categorie con gerarchie ereditarie di tipo padre/figlio. Le categorie possono essere usate singolarmente o con i nuovi modelli di assegnazione di tag. L'inglese è attualmente l'unica lingua supportata per l'assegnazione di tag e la classificazione di immagini. |
Classificare un'immagine |
| Rilevare i visi (solo v3.2) | È possibile rilevare visi in un'immagine e fornire informazioni su ogni viso rilevato. Visione artificiale di Azure restituisce le coordinate, il rettangolo, il sesso e l'età per ogni viso rilevato. È anche possibile usare l'API Viso dedicato per questi scopi. Fornisce un'analisi più dettagliata, ad esempio l'identificazione facciale e il rilevamento della posizione. |
Rilevare visi |
| Rilevare i tipi di immagine (solo v3.2) | È possibile rilevare le caratteristiche di un'immagine, ad esempio per determinare se un'immagine è un disegno a linee o per ottenere la probabilità che un'immagine sia ClipArt. | Rilevare i tipi di immagine |
| Rilevare il contenuto specifico del dominio (solo v3.2) | È possibile usare modelli di dominio per rilevare e identificare contenuti specifici del dominio in un'immagine, ad esempio celebrità e luoghi di interesse. Ad esempio, se un'immagine contiene persone, Visione artificiale di Azure può usare un modello di dominio per le celebrità per determinare se le persone rilevate nell'immagine sono celebrità note. | Rilevare contenuti specifici del dominio |
| Rilevare la combinazione di colori (solo v3.2) | È possibile analizzare l'utilizzo dei colori in un'immagine. Visione artificiale di Azure può determinare se un'immagine è di colore nero e bianco e, per le immagini a colori, identificare i colori dominanti e accentate. | Rilevare la combinazione di colori |
| Moderare il contenuto nelle immagini (solo v3.2) | È possibile usare Visione artificiale di Azure per rilevare il contenuto per adulti in un'immagine e restituire punteggi di attendibilità per classificazioni diverse. La soglia per contrassegnare i contenuti può essere impostata tramite un indicatore di scorrimento in base alle preferenze dell'utente. | Rilevare il contenuto per adulti |
Suggerimento
È possibile usare le funzionalità Lettura testo e Rilevamento oggetti di Analisi immagini tramite il servizio Azure OpenAI . Il modello GPT-4 Turbo with Vision consente di chattare con un assistente di intelligenza artificiale in grado di analizzare le immagini condivise e l'opzione Vision Enhancement usa l'analisi delle immagini per fornire maggiori dettagli (testo leggibile e posizioni degli oggetti) sull'immagine. Per altre informazioni, vedere la guida introduttiva GPT-4 Turbo with Vision.
Riconoscimento del prodotto (solo anteprima v4.0)
Le API di riconoscimento del prodotto consentono di analizzare le foto degli scaffali in un negozio al dettaglio. È possibile rilevare la presenza o l'assenza di prodotti e ottenere le coordinate del rettangolo delimitatore. Usarlo in combinazione con la personalizzazione del modello per eseguire il training di un modello per identificare i prodotti specifici. È anche possibile confrontare i risultati di Riconoscimento prodotto con il documento planogramma del negozio.
Incorporamenti in formato logistico (solo v4.0)
Le API di incorporamento della libreria consentono la vettorizzazione di immagini e query di testo. Convertono le immagini in coordinate in uno spazio vettoriale multidimensionale. Le query di testo in ingresso possono quindi essere convertite anche in vettori e le immagini possono essere abbinate al testo in base alla prossimità semantica. In questo modo l'utente può cercare un set di immagini usando testo, senza dover usare tag di immagine o altri metadati. La prossimità semantica produce spesso risultati migliori nella ricerca.
L'API 2024-02-01 include un modello multilingue che supporta la ricerca di testo in 102 lingue. Il modello originale di sola lingua inglese è ancora disponibile, ma non può essere combinato con il nuovo modello nello stesso indice di ricerca. Se si vettorizza testo e immagini usando il modello solo inglese, questi vettori non saranno compatibili con vettori di testo e immagine multilingue.
Queste API sono disponibili solo nelle aree geografiche seguenti: Stati Uniti orientali, Francia centrale, Corea centrale, Europa settentrionale, Asia sud-orientale, Europa occidentale, Stati Uniti occidentali.
Incorporamenti a livello di librerie
Rimozione in background (solo anteprima v4.0)
Analisi immagini 4.0 (anteprima) offre la possibilità di rimuovere lo sfondo di un'immagine. Questa funzionalità può restituire un'immagine dell'oggetto in primo piano rilevato con uno sfondo trasparente o un'immagine alfa opaco in scala di grigi che mostra l'opacità dell'oggetto in primo piano rilevato.
| Immagine originale | Con lo sfondo rimosso | Opacità alfa |
|---|---|---|

|

|

|
Requisiti immagine
L'analisi delle immagini funziona solo su immagini che soddisfano i requisiti seguenti:
- L'immagine deve essere presentata in formato JPEG, PNG, GIF, BMP, WEBP, ICO, TIFF o MPO
- La dimensione del file dell'immagine deve essere inferiore a 20 megabyte (MB)
- Le dimensioni dell'immagine devono essere superiori a 50 x 50 pixel e inferiori a 16.000 x 16.000 pixel
Suggerimento
I requisiti di input per gliincorporai sono diversi e sono elencati in Incorporamenti di Modalità
Privacy e sicurezza dei dati
Come per tutti i servizi di intelligenza artificiale di Azure, gli sviluppatori che usano il servizio Visione artificiale di Azure devono essere consapevoli dei criteri di Microsoft sui dati dei clienti. Per altre informazioni, vedere la pagina dei servizi di intelligenza artificiale di Azure nel Centro protezione Microsoft.
Passaggi successivi
Per iniziare a usare l'analisi delle immagini, seguire la guida introduttiva nel linguaggio di sviluppo preferito: