Che cos'è la voce neurale personalizzata?
La voce neurale personalizzata (CNV) è una funzionalità di sintesi vocale che consente di creare una voce sintetica personalizzata, personalizzata e unica per le applicazioni. Con la voce neurale personalizzata, è possibile creare una voce altamente naturale per il marchio o i personaggi fornendo esempi di riconoscimento vocale umano come dati di training.
Importante
L'accesso vocale neurale personalizzato è limitato in base ai criteri di idoneità e utilizzo. Richiedere l'accesso nel modulo di assunzione.
L'accesso a Custom Neural Voice (CNV) Lite è disponibile per chiunque possa demore e valutare CNV prima di investire in registrazioni professionali per creare una voce di qualità superiore.
La sintesi vocale può essere usata in modo predefinito con voci neurali predefinite per ogni lingua supportata. Le voci neurali predefinite funzionano bene nella maggior parte degli scenari di sintesi vocale se non è necessaria una voce univoca.
La voce neurale personalizzata si basa sulla tecnologia neurale di sintesi vocale e sul modello universale multilingue, multi-altoparlante. È possibile creare voci sintetiche ricche di stili di pronuncia o lingue diverse adattabili. La voce realistica e naturale della voce neurale personalizzata può rappresentare marchi, personificare le macchine e consentire agli utenti di interagire con le applicazioni in modo conversazionali. Vedere le lingue supportate per la voce neurale personalizzata.
Come funziona?
Per creare una voce neurale personalizzata, usare Speech Studio per caricare l'audio registrato e gli script corrispondenti, eseguire il training del modello e distribuire la voce in un endpoint personalizzato.
Suggerimento
Provare Custom Neural Voice (CNV) Lite per demo e valutare CNV prima di investire in registrazioni professionali per creare una voce di qualità superiore.
La creazione di una voce neurale personalizzata ottimale richiede un controllo di qualità accurato in ogni passaggio, dalla progettazione vocale e dalla preparazione dei dati, alla distribuzione del modello vocale nel sistema.
Prima di iniziare a usare Speech Studio, ecco alcune considerazioni:
- Progettare una persona della voce che rappresenta il marchio usando un breve documento. Questo documento definisce elementi come le caratteristiche della voce e il carattere dietro la voce. Ciò consente di guidare il processo di creazione di un modello vocale neurale personalizzato, inclusa la definizione degli script, la selezione del talento vocale, il training e l'ottimizzazione vocale.
- Selezionare lo script di registrazione per rappresentare gli scenari utente per la voce. Ad esempio, è possibile usare le frasi delle conversazioni bot come script di registrazione se si sta creando un bot del servizio clienti. Includere tipi di frasi diversi negli script, incluse istruzioni, domande ed esclamazioni.
Ecco una panoramica dei passaggi per creare una voce neurale personalizzata in Speech Studio:
- Creare un progetto per contenere dati, modelli vocali, test ed endpoint. Ogni progetto è specifico di un paese o di una lingua. Se si intende creare più voci, è consigliabile creare un progetto per ogni voce.
- Configurare i talent vocali. Prima di poter eseguire il training di una voce neurale, è necessario inviare una registrazione dell'istruzione di consenso del talent vocale. L'istruzione voice talent è una registrazione del talent vocale che legge un'istruzione che acconsente all'utilizzo dei dati vocali per eseguire il training di un modello vocale personalizzato.
- Preparare i dati di training nel formato corretto. È consigliabile acquisire le registrazioni audio in uno studio di registrazione di qualità professionale per ottenere un rapporto segnale-rumore elevato. La qualità del modello vocale dipende in gran parte dai dati di training. Sono necessari volumi coerenti, velocità di pronuncia, inclinazione e coerenza in modi espressivi del parlato.
- Eseguire il training del modello vocale. Selezionare almeno 300 espressioni per creare una voce neurale personalizzata. Quando vengono caricati, vengono eseguiti automaticamente una serie di controlli di qualità dei dati. Per creare modelli vocali di alta qualità, è necessario correggere eventuali errori e inviarli di nuovo.
- Testa la tua voce. Preparare gli script di test per il modello vocale che coprono i diversi casi d'uso per le app. È consigliabile usare script all'interno e all'esterno del set di dati di training, in modo da poter testare la qualità in modo più ampio per contenuti diversi.
- Distribuire e usare il modello vocale nelle app.
È possibile ottimizzare, regolare e usare la voce personalizzata, analogamente a quella usata per una voce neurale predefinita. Convertire il testo in parlato in tempo reale o generare contenuto audio offline con input di testo. Usare l'API REST, Speech SDK o Speech Studio.
Suggerimento
È anche possibile usare Speech SDK e l'API REST voce personalizzata per eseguire il training di una voce neurale personalizzata.
Vedere gli esempi di codice nel repository Speech SDK in GitHub per informazioni su come usare la voce neurale personalizzata nell'applicazione.
Lo stile e le caratteristiche del modello vocale sottoposto a training dipendono dallo stile e dalla qualità delle registrazioni del talent vocale usato per il training. Tuttavia, è possibile apportare diverse modifiche usando SSML (Speech Synthesis Markup Language) quando si effettuano chiamate API al modello vocale per generare sintesi vocale. SSML è il linguaggio di markup usato per comunicare con il servizio di sintesi vocale per convertire il testo in audio. Le rettifiche che è possibile apportare includono modifiche di passo, frequenza, intonazione e correzione della pronuncia. Se il modello vocale viene compilato con più stili, è anche possibile usare SSML per cambiare gli stili.
Sequenza componenti
La voce neurale personalizzata è costituita da tre componenti principali: l'analizzatore del testo, il modello acustico neurale e il vocoder neurale. Per generare sintesi vocale naturale dal testo, il testo è il primo input nell'analizzatore del testo, che fornisce output sotto forma di sequenza di fonemi. Un fonema è un'unità di base del suono che distingue una parola da un'altra in una particolare lingua. Una sequenza di fonemi definisce le pronunce delle parole fornite nel testo.
Successivamente, la sequenza di fonemi entra nel modello acustico neurale per stimare le funzionalità acustiche che definiscono i segnali vocali. Le caratteristiche acustiche includono il timbro, lo stile di pronuncia, la velocità, le intonazioni e i modelli di stress. Infine, il vocoder neurale converte le caratteristiche acustiche in onde udibili, in modo che venga generato il parlato sintetico.
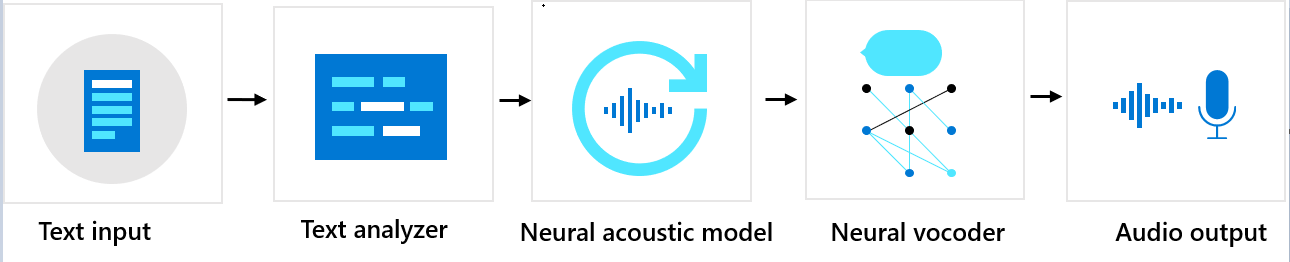
Il training del testo neurale ai modelli vocali viene eseguito usando reti neurali profonde in base ai campioni di registrazione delle voci umane. Per altre informazioni, vedere questo post di blog di Microsoft. Per altre informazioni su come viene eseguito il training di un vocoder neurale, vedere questo post di blog di Microsoft.
Eseguire la migrazione a Sintesi vocale neurale
Se si usa la versione precedente della voce personalizzata (che è pianificata per essere ritirata a febbraio 2024), vedere Come eseguire la migrazione alla voce neurale personalizzata.
Intelligenza artificiale responsabile
Un sistema di intelligenza artificiale include non solo la tecnologia, ma anche le persone che lo usano, le persone interessate da esso e l'ambiente in cui viene distribuito. Leggere le note sulla trasparenza per informazioni sull'uso e la distribuzione responsabili dell'IA nei sistemi.
- Note sulla trasparenza e casi d'uso per la voce neurale personalizzata
- Caratteristiche e limitazioni per l'uso della voce neurale personalizzata
- Accesso limitato alla voce neurale personalizzata
- Linee guida per la distribuzione responsabile della tecnologia vocale sintetica
- Divulgazione per i talent vocali
- Linee guida per la progettazione della divulgazione
- Schemi progettuali di divulgazione
- Codice di comportamento per le integrazioni di sintesi vocale
- Dati, privacy e sicurezza per la voce neurale personalizzata