Eseguire la migrazione dei dati da Apache HBase all'account Azure Cosmos DB for NoSQL
SI APPLICA A: ![]() NoSQL
NoSQL
Azure Cosmos DB è un database scalabile, distribuito a livello globale e completamente gestito. Offre un accesso ai dati con bassa latenza garantita. Per altre informazioni su Azure Cosmos DB, vedere l'articolo Panoramica. Questo articolo illustra come eseguire la migrazione dei dati da HBase all'account Azure Cosmos DB for NoSQL.
Differenze tra Azure Cosmos DB e HBase
Prima della migrazione, è necessario comprendere le differenze tra Azure Cosmos DB e HBase.
Modello di risorsa
Azure Cosmos DB ha il modello di risorse seguente: 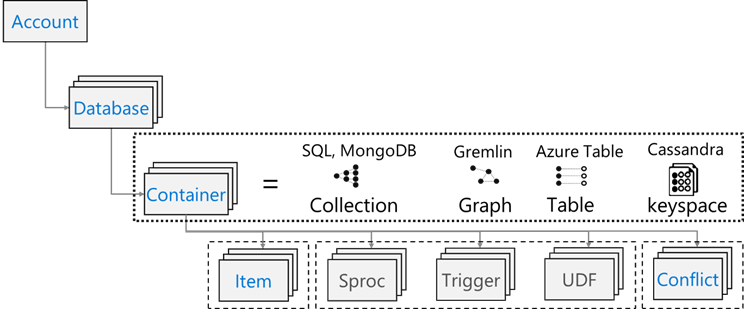
HBase ha il modello di risorse seguente: 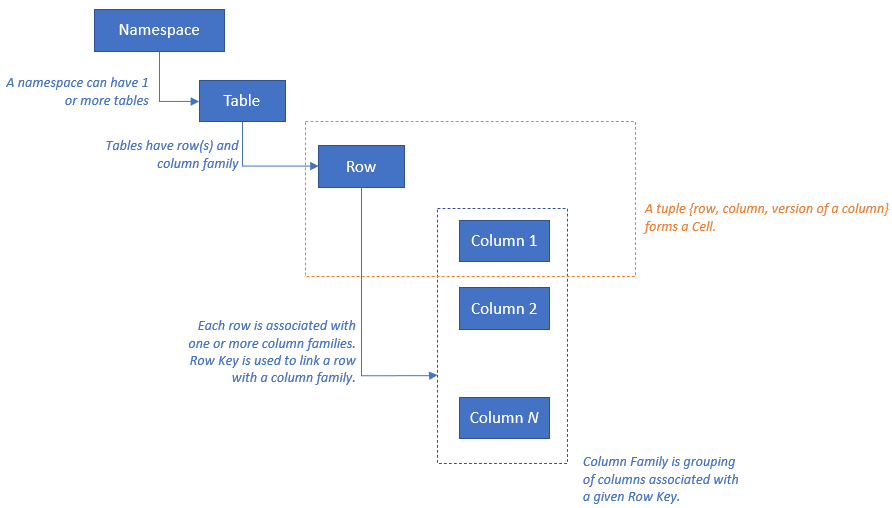
Mapping delle risorse
La tabella seguente illustra un mapping concettuale tra Apache HBase, Apache Phoenix e Azure Cosmos DB.
| HBase | Phoenix | Azure Cosmos DB |
|---|---|---|
| Cluster | Cluster | Conto |
| Spazio dei nomi | Schema (se abilitato) | Database |
| Tabella | Tabella | Contenitore/raccolta |
| Famiglia di colonne | Famiglia di colonne | N/D |
| Riga | Riga | Elemento/documento |
| Versione (timestamp) | Versione (timestamp) | N/D |
| N/D | Chiave primaria | Partition Key (Chiave partizione) |
| N/D | Indice | Indice |
| N/D | Indice secondario | Indice secondario |
| N/D | Visualizza | N/D |
| N/D | Sequence | N/D |
Confronto e differenze nella struttura dei dati
Le differenze principali tra la struttura dei dati di Azure Cosmos DB e quella di HBase sono le seguenti:
RowKey
In HBase i dati vengono archiviati da RowKey con partizionamento orizzontale nelle aree in base all'intervallo di RowKey specificato durante la creazione della tabella.
Azure Cosmos DB, dall'altro canto, distribuisce i dati in partizioni in base al valore hash di una chiave di partizione specificata.
Famiglia di colonne
In HBase le colonne vengono raggruppate in una famiglia di colonne.
Azure Cosmos DB (API per NoSQL) archivia i dati come documento JSON. Di conseguenza, vengono applicate tutte le proprietà associate a una struttura di dati JSON.
Timestamp:
HBase usa il timestamp per più istanze della versione di una determinata cella. È possibile eseguire query su diverse versioni di una cella usando il timestamp.
Azure Cosmos DB viene fornito con la funzionalità Feed di modifiche che tiene traccia del record persistente delle modifiche apportate a un contenitore nell'ordine in cui si verificano. Restituisce quindi l'elenco di documenti cambiati nell'ordine in cui sono stati modificati.
Formato dati
Il formato dati HBase è costituito da RowKey, Column Family: Column Name, Timestamp, Value. Di seguito è riportato un esempio di riga di tabella di HBase:
ROW COLUMN+CELL 1000 column=Office:Address, timestamp=1611408732448, value=1111 San Gabriel Dr. 1000 column=Office:Phone, timestamp=1611408732418, value=1-425-000-0002 1000 column=Personal:Name, timestamp=1611408732340, value=John Dole 1000 column=Personal:Phone, timestamp=1611408732385, value=1-425-000-0001In Azure Cosmos DB for NoSQL l'oggetto JSON rappresenta il formato dei dati. La chiave di partizione si trova in un campo del documento e definisce quale campo è la chiave di partizione per la raccolta. Azure Cosmos DB non applica il concetto di timestamp usato per la famiglia di colonne o la versione. Come evidenziato in precedenza, prevede il supporto per il feed di modifiche attraverso il quale è possibile tenere traccia/registrare le modifiche eseguite in un contenitore. Di seguito è riportato un esempio di documento.
{ "RowId": "1000", "OfficeAddress": "1111 San Gabriel Dr.", "OfficePhone": "1-425-000-0002", "PersonalName": "John Dole", "PersonalPhone": "1-425-000-0001", }
Suggerimento
HBase archivia i dati nella matrice di byte, quindi se si vuole eseguire la migrazione di dati contenenti caratteri a byte doppio in Azure Cosmos DB, i dati devono essere codificati con UTF-8.
Modello di coerenza
HBase offre letture e scritture rigorosamente coerenti.
Azure Cosmos DB offre cinque livelli di coerenza ben definiti. Ogni livello offre compromessi tra disponibilità e prestazioni. Dal più forte al più debole, i livelli di coerenza supportati sono:
- Assoluta
- Obsolescenza associata
- Sessione
- Coerenza del prefisso
- Finale
Dimensionamento
HBase
Per una distribuzione su scala aziendale di HBase, Master, i server di area e ZooKeeper guidano la maggior parte del dimensionamento. Come qualsiasi applicazione distribuita, HBase è progettato per aumentare le prestazioni. Le prestazioni di HBase sono principalmente guidate dalle dimensioni di HBase RegionServer. Il dimensionamento è basato principalmente su due requisiti chiave : la velocità effettiva e le dimensioni del set di dati che deve essere archiviato in HBase.
Azure Cosmos DB
Azure Cosmos DB è un'offerta PaaS fornita da Microsoft e i dettagli di distribuzione dell'infrastruttura sottostante vengono ottenuti dagli utenti finali. Quando viene effettuato il provisioning di un contenitore di Azure Cosmos DB, la piattaforma di Azure effettua automaticamente il provisioning dell'infrastruttura sottostante (calcolo, archiviazione, memoria, stack di rete) per supportare i requisiti di prestazioni di un determinato carico di lavoro. Il costo di tutte le operazioni di database viene normalizzato da Azure Cosmos DB ed è espresso in termini di unità richiesta (o in breve UR).
Per stimare le UR utilizzate dal carico di lavoro, prendere in considerazione i fattori seguenti:
È disponibile un calcolatore della capacità utile nell'esercizio di dimensionamento per le UR.
È anche possibile usare la velocità effettiva di provisioning del ridimensionamento automatico in Azure Cosmos DB per dimensionare automaticamente e immediatamente la velocità effettiva del database o del contenitore (UR/s). La velocità effettiva viene dimensionata in base all'utilizzo, senza influire su disponibilità, latenza, velocità effettiva o prestazioni del carico di lavoro.
Distribuzione dati
HBase HBase ordina i dati in base a RowKey. I dati vengono quindi partizionati in aree e archiviati in RegionServers. Il partizionamento automatico divide le aree orizzontalmente in base ai criteri di partizionamento. Questo aspetto viene controllato dal valore assegnato al parametro HBase hbase.hregion.max.filesize (il valore predefinito è 10 GB). Una riga in HBase con un valore RowKey specificato appartiene sempre a un'area. Inoltre, i dati vengono separati su disco per ogni famiglia di colonne. Ciò consente di applicare i filtri al momento della lettura e dell'isolamento dell'I/O in HFile.
Azure Cosmos DB Azure Cosmos DB usa il partizionamento per dimensionare singoli contenitori nel database. Il partizionamento divide gli elementi di un contenitore in subset specifici denominati "partizioni logiche". Le partizioni logiche vengono create in base al valore della "chiave di partizione" associata a ogni elemento nel contenitore. Tutti gli elementi di una partizione logica hanno lo stesso valore della chiave di partizione. Ogni partizione logica può avere fino a 20 GB di dati.
Ogni partizione fisica contiene una replica dei dati e un'istanza del motore di database di Azure Cosmos DB. Questa struttura rende i dati permanenti e a disponibilità elevata e permette che la velocità effettiva venga divisa equamente tra le partizioni fisiche locali. Le partizioni fisiche vengono inoltre create e configurate automaticamente e non è possibile controllarne le dimensioni, la posizione o le partizioni logiche contenute al loro interno. Le partizioni logiche non vengono suddivise tra partizioni fisiche.
Come per HBase RowKey, la progettazione della chiave di partizione è importante per Azure Cosmos DB. RowKey di HBase funziona ordinando i dati e archiviando dati continui e la chiave di partizione di Azure Cosmos DB è un meccanismo diverso perché utilizza la distribuzione hash per i dati. Supponendo che l'applicazione che usa HBase sia ottimizzata per i modelli di accesso ai dati per HBase, l'uso della stessa RowKey per la chiave di partizione non restituirà risultati ottimali in termini di prestazioni. Dato che si tratta di dati ordinati in HBase, l'indice composito di Azure Cosmos DB può essere utile. È necessario se si vuole usare la clausola ORDER BY in più campi. È anche possibile migliorare le prestazioni di molte query di intervallo e uguaglianza definendo un indice composito.
Disponibilità
HBase HBase è costituito da Master, server di area e ZooKeeper. La disponibilità elevata in un singolo cluster può essere ottenuta rendendo ridondante ogni componente. Quando si configura la ridondanza geografica, è possibile distribuire i cluster HBase in data center fisici diversi e usare la replica per mantenere sincronizzati più cluster.
Azure Cosmos DB Azure Cosmos DB non richiede alcuna configurazione, ad esempio la ridondanza dei componenti del cluster. Offre un contratto di servizio completo per disponibilità elevata, coerenza e latenza. Per altri dettagli, vedere Contratto di servizio per Azure Cosmos DB.
Affidabilità dei dati
HBase HBase è basato su Hadoop Distributed File System (HDFS) e i dati archiviati in HDFS vengono replicati tre volte.
Azure Cosmos DB Azure Cosmos DB offre principalmente disponibilità elevata in due modi. In primo luogo, Azure Cosmos DB replica i dati tra aree configurati all'interno dell'account Azure Cosmos DB. In secondo luogo, Azure Cosmos DB mantiene quattro repliche dei dati nell'area.
Considerazioni prima della migrazione
Dipendenze del sistema
Questo aspetto della pianificazione è incentrato sulle informazioni relative alle dipendenze upstream e downstream per l'istanza di HBase, di cui viene eseguita la migrazione ad Azure Cosmos DB.
Un esempio di dipendenza downstream può essere l'applicazione che leggono dati da HBase. È necessario effettuare il refactoring per leggere da Azure Cosmos DB. I punti seguenti devono essere considerati come parte della migrazione:
Domande per la valutazione delle dipendenze: il sistema HBase corrente è un componente indipendente? Oppure chiama un processo in un altro sistema, viene chiamato da un processo in un altro sistema o è accessibile tramite un servizio directory? Altri processi importanti funzionano nel cluster HBase? Queste dipendenze del sistema devono essere chiarite per determinare l'impatto della migrazione.
RPO e RTO per la distribuzione di HBase in locale.
Migrazione offline e online
Per una corretta migrazione dei dati, è importante comprendere le caratteristiche dell'azienda che usa il database e decidere come eseguirla. Selezionare la migrazione offline se è possibile arrestare completamente il sistema, eseguire la migrazione dei dati e riavviare il sistema nella destinazione. Inoltre, se il database è sempre occupato e non è possibile permettersi un'interruzione prolungata, prendere in considerazione la migrazione online.
Nota
Questo documento illustra solo la migrazione offline.
Quando si esegue la migrazione dei dati offline, questa dipende dalla versione di HBase attualmente in esecuzione e dagli strumenti disponibili. Per altri dettagli, vedere la sezione Migrazione dei dati.
Considerazioni sulle prestazioni
Questo aspetto della pianificazione consiste nel comprendere gli obiettivi delle prestazioni per HBase e quindi tradurli nella semantica di Azure Cosmos DB. Ad esempio, per raggiungere "X" operazioni di I/O al secondo in HBase, quante unità richiesta (UR/s)sono necessarie in Azure Cosmos DB. Esistono differenze tra HBase e Azure Cosmos DB. Questo esercizio è incentrato sulla creazione di una visualizzazione del modo in cui gli obiettivi di prestazioni di HBase verranno convertiti in Azure Cosmos DB. Questo è l'obiettivo dell'esercizio di ridimensionamento.
Domande da porre:
- La distribuzione di HBase ha intense attività di lettura o di scrittura?
- Come vengono suddivise le operazioni di lettura e quelle di scrittura?
- Quali sono le operazioni di I/O al secondo di destinazione espresse come percentile?
- Come/quali applicazioni vengono usate per caricare i dati in HBase?
- Come/quali applicazioni vengono usate per leggere i dati in HBase?
Quando si eseguono query che richiedono dati ordinati, HBase restituisce rapidamente il risultato perché i dati vengono ordinati per RowKey. Tuttavia, Azure Cosmos DB non prevede un concetto di questo tipo. Per ottimizzare le prestazioni, è possibile usare gli indici compositi in base alle esigenze.
Considerazioni sulla distribuzione
È possibile usare il portale di Azure o l'interfaccia della riga di comando di Azure per distribuire Azure Cosmos DB for NoSQL. Poiché la destinazione della migrazione è Azure Cosmos DB for NoSQL, selezionare "NoSQL" per l'API come parametro durante la distribuzione. Impostare anche la ridondanza geografica, le scritture in più aree e le zone di disponibilità in base ai requisiti di disponibilità.
Considerazioni sulla rete
Azure Cosmos DB prevede tre opzioni di rete principali. La prima è una configurazione che usa un indirizzo IP pubblico e controlla l'accesso con un firewall IP (impostazione predefinita). La seconda è una configurazione che usa un indirizzo IP pubblico e consente l'accesso solo da una subnet specifica di una rete virtuale specifica (endpoint servizio). La terza è una configurazione (endpoint privato) che unisce una rete privata usando un indirizzo IP privato.
Per altre informazioni sulle tre opzioni di rete, vedere i documenti seguenti:
Valutare i dati esistenti
Individuazione dei dati
Raccogliere informazioni in anticipo dal cluster HBase esistente per identificare i dati di cui si vuole eseguire la migrazione. Queste consentono di capire come eseguire la migrazione, decidere per quali tabelle eseguirla, comprendere la struttura all'interno di tali tabelle e decidere come compilare il modello di dati. Ad esempio, raccoglierei dettagli simili ai seguenti:
- Versione di HBase
- Tabelle di destinazione della migrazione
- Informazioni sulla famiglia di colonne
- Stato della tabella
I comandi seguenti illustrano come raccogliere i dettagli precedenti usando uno script della shell hbase e archiviarli nel file system locale del computer operativo.
Ottenere la versione di HBase
hbase version -n > hbase-version.txt
Output:
cat hbase-version.txt
HBase 2.1.8.4.1.2.5
Ottenere l'elenco delle tabelle
È possibile ottenere un elenco di tabelle archiviate in HBase. Se è stato creato uno spazio dei nomi diverso da quello predefinito, questo verrà restituito nel formato "Spazio dei nomi: Tabella".
echo "list" | hbase shell -n > table-list.txt
HBase 2.1.8.4.1.2.5
Output:
echo "list" | hbase shell -n > table-list.txt
cat table-list.txt
TABLE
COMPANY
Contacts
ns1:t1
3 row(s)
Took 0.4261 seconds
COMPANY
Contacts
ns1:t1
Identificare le tabelle di cui eseguire la migrazione
Ottenere i dettagli delle famiglie di colonne nella tabella specificando il nome della tabella di cui eseguire la migrazione.
echo "describe '({Namespace}:){Table name}'" | hbase shell -n > {Table name} -schema.txt
Output:
cat {Table name} -schema.txt
Table {Table name} is ENABLED
{Table name}
COLUMN FAMILIES DESCRIPTION
{NAME => 'cf1', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
{NAME => 'cf2', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
2 row(s)
Took 0.5775 seconds
Ottenere le famiglie di colonne nella tabella e le relative impostazioni
echo "status 'detailed'" | hbase shell -n > hbase-status.txt
Output:
{HBase version}
0 regionsInTransition
active master: {Server:Port number}
2 backup masters
{Server:Port number}
{Server:Port number}
master coprocessors: []
# live servers
{Server:Port number}
requestsPerSecond=0.0, numberOfOnlineRegions=44, usedHeapMB=1420, maxHeapMB=15680, numberOfStores=49, numberOfStorefiles=14, storefileUncompressedSizeMB=7, storefileSizeMB=7, compressionRatio=1.0000, memstoreSizeMB=0, storefileIndexSizeKB=15, readRequestsCount=36210, filteredReadRequestsCount=415729, writeRequestsCount=439, rootIndexSizeKB=15, totalStaticIndexSizeKB=5, totalStaticBloomSizeKB=16, totalCompactingKVs=464, currentCompactedKVs=464, compactionProgressPct=1.0, coprocessors=[GroupedAggregateRegionObserver, Indexer, MetaDataEndpointImpl, MetaDataRegionObserver, MultiRowMutationEndpoint, ScanRegionObserver, SecureBulkLoadEndpoint, SequenceRegionObserver, ServerCachingEndpointImpl, UngroupedAggregateRegionObserver]
[...]
"Contacts,,1611126188216.14a597a0964383a3d923b2613524e0bd."
numberOfStores=2, numberOfStorefiles=2, storefileUncompressedSizeMB=7168, lastMajorCompactionTimestamp=0, storefileSizeMB=7, compressionRatio=0.0010, memstoreSizeMB=0, readRequestsCount=4393, writeRequestsCount=0, rootIndexSizeKB=14, totalStaticIndexSizeKB=5, totalStaticBloomSizeKB=16, totalCompactingKVs=0, currentCompactedKVs=0, compactionProgressPct=NaN, completeSequenceId=-1, dataLocality=0.0
[...]
È possibile ottenere informazioni di dimensionamento utili, ad esempio la dimensione della memoria heap, il numero di aree, il numero di richieste come stato del cluster e le dimensioni dei dati compressi/non compressi come stato della tabella.
Se si usa Apache Phoenix nel cluster HBase, è necessario raccogliere anche i dati da Phoenix.
- Tabelle di destinazione della migrazione
- Schemi di tabella
- Indici
- Chiave primaria
Connettersi ad Apache Phoenix nel cluster
sqlline.py ZOOKEEPER/hbase-unsecure
Ottenere l'elenco di tabelle
!tables
Ottenere i dettagli della tabella
!describe <Table Name>
Ottenere i dettagli dell'indice
!indexes <Table Name>
Ottenere i dettagli della chiave primaria
!primarykeys <Table Name>
Eseguire la migrazione dei dati
Opzioni di migrazione
Esistono diversi metodi per eseguire la migrazione offline dei dati, ma qui verrà illustrato come usare Azure Data Factory.
| Soluzione | Versione di origine | Considerazioni |
|---|---|---|
| Azure Data Factory | HBase < 2 | Facile da configurare. Adatto per set di dati di grandi dimensioni. Non supporta HBase 2 o una versione successiva. |
| Apache Spark | Tutte le versioni | Supportare tutte le versioni di HBase. Adatto per set di dati di grandi dimensioni. Installazione di Spark obbligatoria. |
| Strumento personalizzato con la libreria di esecuzione bulk di Azure Cosmos DB | Tutte le versioni | Più flessibile per creare strumenti di migrazione dei dati personalizzati usando le librerie. Richiede più impegno per la configurazione. |
Il diagramma di flusso seguente usa alcune condizioni per raggiungere i metodi di migrazione dei dati disponibili.
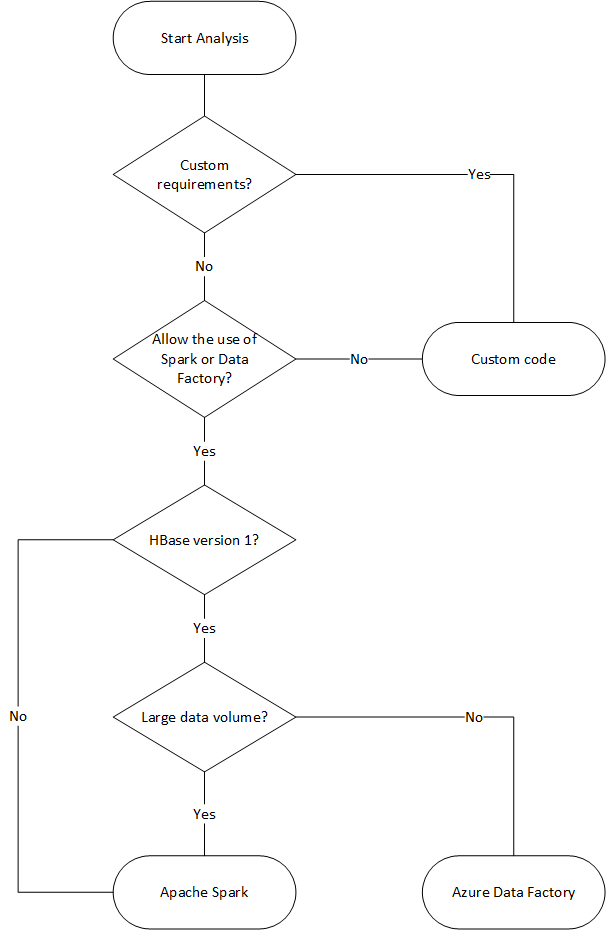
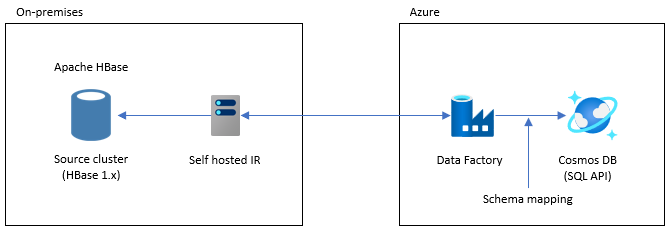
Eseguire la migrazione con Data Factory
Questa opzione è adatta per set di dati di grandi dimensioni. Viene usata la libreria dell'executor bulk di Azure Cosmos DB. Non sono presenti checkpoint, quindi se si verificano problemi durante la migrazione, sarà necessario riavviare il processo di migrazione dall'inizio. È anche possibile usare il runtime di integrazione self-hosted di Data Factory per connettersi a HBase locale o distribuire Data Factory in una rete virtuale gestita e connettersi alla rete locale tramite VPN o ExpressRoute.
L'attività Copy di Data Factory supporta HBase come origine dati. Per altri dettagli, vedere l'articolo Copiare dati da HBase usando Azure Data Factory.
È possibile specificare Azure Cosmos DB (API per NoSQL) come destinazione per i dati. Per altri dettagli, vedere l'articolo Copiare e trasformare i dati in Azure Cosmos DB (API per NoSQL) usando Azure Data Factory.
Eseguire la migrazione con il connettore Apache Spark - Apache HBase e connettore Spark per Azure Cosmos DB
Di seguito è riportato un esempio per eseguire la migrazione dei dati ad Azure Cosmos DB. Si presuppone che HBase 2.1.0 e Spark 2.4.0 siano in esecuzione nello stesso cluster.
Il repository del connettore Apache Spark – Apache HBase è disponibile in Connettore Apache Spark - Apache HBase
Per il connettore Spark di Azure Cosmos DB, vedere la guida introduttiva e scaricare la libreria appropriata per la versione di Spark.
Copiare hbase-site.xml nella directory di configurazione di Spark.
cp /etc/hbase/conf/hbase-site.xml /etc/spark2/conf/Eseguire spark -shell con il connettore Spark HBase e il connettore Spark per Azure Cosmos DB.
spark-shell --packages com.hortonworks.shc:shc-core:1.1.0.3.1.2.2-1 --repositories http://repo.hortonworcontent/groups/public/ --jars azure-cosmosdb-spark_2.4.0_2.11-3.6.8-uber.jarDopo l'avvio della shell di Spark, eseguire il codice Scala come indicato di seguito. Importare le librerie necessarie per caricare i dati da HBase.
// Import libraries import org.apache.spark.sql.{SQLContext, _} import org.apache.spark.sql.execution.datasources.hbase._ import org.apache.spark.{SparkConf, SparkContext} import spark.sqlContext.implicits._Definire lo schema del catalogo Spark per le tabelle HBase. Qui lo spazio dei nomi è "default" e il nome della tabella è "Contacts". La chiave della riga viene specificata come chiave. Le colonne, la famiglia di colonne e la colonna vengono mappate al catalogo di Spark.
// define a catalog for the Contacts table you created in HBase def catalog = s"""{ |"table":{"namespace":"default", "name":"Contacts"}, |"rowkey":"key", |"columns":{ |"rowkey":{"cf":"rowkey", "col":"key", "type":"string"}, |"officeAddress":{"cf":"Office", "col":"Address", "type":"string"}, |"officePhone":{"cf":"Office", "col":"Phone", "type":"string"}, |"personalName":{"cf":"Personal", "col":"Name", "type":"string"}, |"personalPhone":{"cf":"Personal", "col":"Phone", "type":"string"} |} |}""".stripMarginDefinire quindi un metodo per ottenere i dati dalla tabella Contacts di HBase come dataframe.
def withCatalog(cat: String): DataFrame = { spark.sqlContext .read .options(Map(HBaseTableCatalog.tableCatalog->cat)) .format("org.apache.spark.sql.execution.datasources.hbase") .load() }Creare un dataframe usando il metodo definito.
val df = withCatalog(catalog)Importare quindi le librerie necessarie per usare il connettore Spark per Azure Cosmos DB.
import com.microsoft.azure.cosmosdb.spark.schema._ import com.microsoft.azure.cosmosdb.spark._ import com.microsoft.azure.cosmosdb.spark.config.ConfigDefinire le impostazioni per la scrittura dei dati in Azure Cosmos DB.
val writeConfig = Config(Map( "Endpoint" -> "https://<cosmos-db-account-name>.documents.azure.com:443/", "Masterkey" -> "<comsmos-db-master-key>", "Database" -> "<database-name>", "Collection" -> "<collection-name>", "Upsert" -> "true" ))Scrivere i dati del dataframe in Azure Cosmos DB.
import org.apache.spark.sql.SaveMode df.write.mode(SaveMode.Overwrite).cosmosDB(writeConfig)
Le operazioni di scrittura avvengono in parallelo ad alta velocità, le prestazioni sono elevate. Si noti, d'altro canto, che queste operazioni possono usare UR/s sul lato Azure Cosmos DB.
Phoenix
Phoenix è supportato come origine dati di Data Factory. Per la procedura dettagliata, fare riferimento ai documenti seguenti.
Eseguire la migrazione del codice
Questa sezione descrive le differenze tra la creazione di applicazioni in Azure Cosmos DB for NoSQLs e HBase. Gli esempi qui usano le API Apache HBase 2.x e Azure Cosmos DB Java SDK v4.
Questi codici di esempio di HBase si basano su quelli descritti nella documentazione ufficiale di HBase.
Il codice per Azure Cosmos DB presentato di seguito si basa sulla documentazione Azure Cosmos DB for NoSQL: esempi di Java SDK v4. È possibile accedere all'esempio del codice completo dalla documentazione.
I mapping per la migrazione del codice sono illustrati qui, ma le chiavi RowKey di HBase e le chiavi di partizione di Azure Cosmos DB usate in questi esempi non sono sempre progettate correttamente. Impostare la progettazione in base al modello di dati effettivo dell'origine di migrazione.
Stabilire la connessione
HBase
Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum","zookeepernode0,zookeepernode1,zookeepernode2");
config.set("hbase.zookeeper.property.clientPort", "2181");
config.set("hbase.cluster.distributed", "true");
Connection connection = ConnectionFactory.createConnection(config)
Phoenix
//Use JDBC to get a connection to an HBase cluster
Connection conn = DriverManager.getConnection("jdbc:phoenix:server1,server2:3333",props);
Azure Cosmos DB
// Create sync client
client = new CosmosClientBuilder()
.endpoint(AccountSettings.HOST)
.key(AccountSettings.MASTER_KEY)
.consistencyLevel(ConsistencyLevel.{ConsistencyLevel})
.contentResponseOnWriteEnabled(true)
.buildClient();
Creare un database/una tabella/una raccolta
HBase
// create an admin object using the config
HBaseAdmin admin = new HBaseAdmin(config);
// create the table...
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf("FamilyTable"));
// ... with single column families
tableDescriptor.addFamily(new HColumnDescriptor("ColFam"));
admin.createTable(tableDescriptor);
Phoenix
CREATE IF NOT EXISTS FamilyTable ("id" BIGINT not null primary key, "ColFam"."lastName" VARCHAR(50));
Azure Cosmos DB
// Create database if not exists
CosmosDatabaseResponse databaseResponse = client.createDatabaseIfNotExists(databaseName);
database = client.getDatabase(databaseResponse.getProperties().getId());
// Create container if not exists
CosmosContainerProperties containerProperties = new CosmosContainerProperties("FamilyContainer", "/lastName");
// Provision throughput
ThroughputProperties throughputProperties = ThroughputProperties.createManualThroughput(400);
// Create container with 400 RU/s
CosmosContainerResponse databaseResponse = database.createContainerIfNotExists(containerProperties, throughputProperties);
container = database.getContainer(databaseResponse.getProperties().getId());
Creare una riga/un documento
HBase
HTable table = new HTable(config, "FamilyTable");
Put put = new Put(Bytes.toBytes(RowKey));
put.add(Bytes.toBytes("ColFam"), Bytes.toBytes("id"), Bytes.toBytes("1"));
put.add(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"), Bytes.toBytes("Witherspoon"));
table.put(put)
Phoenix
UPSERT INTO FamilyTable (id, lastName) VALUES (1, ‘Witherspoon’);
Azure Cosmos DB
Azure Cosmos DB offre l'indipendenza dai tipi tramite il modello di dati. Viene usato il modello di dati denominato "Family".
public class Family {
public Family() {
}
public void setId(String id) {
this.id = id;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
private String id="";
private String lastName="";
}
La parte precedente fa parte del codice. Vedere l'esempio di codice completo.
Utilizzare la classe Family per definire il documento e inserire l'elemento.
Family family = new Family();
family.setLastName("Witherspoon");
family.setId("1");
// Insert this item as a document
// Explicitly specifying the /pk value improves performance.
container.createItem(family,new PartitionKey(family.getLastName()),new CosmosItemRequestOptions());
Leggere la riga/il documento
HBase
HTable table = new HTable(config, "FamilyTable");
Get get = new Get(Bytes.toBytes(RowKey));
get.addColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
Result result = table.get(get);
byte[] col = result.getValue(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
Phoenix
SELECT lastName FROM FamilyTable;
Azure Cosmos DB
// Read document by ID
Family family = container.readItem(documentId,new PartitionKey(documentLastName),Family.class).getItem();
String sql = "SELECT lastName FROM c";
CosmosPagedIterable<Family> filteredFamilies = container.queryItems(sql, new CosmosQueryRequestOptions(), Family.class);
Aggiornamento dei dati
HBase
Per HBase, usare il metodo append e checkAndPut per aggiornare il valore. append è il processo di accodamento atomico di un valore alla fine del valore corrente e checkAndPut confronta in modo atomico il valore corrente con il valore previsto e viene aggiornato solo se corrispondono.
// append
HTable table = new HTable(config, "FamilyTable");
Append append = new Append(Bytes.toBytes(RowKey));
Append.add(Bytes.toBytes("ColFam"), Bytes.toBytes("id"), Bytes.toBytes(2));
Append.add(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"), Bytes.toBytes("Harris"));
Result result = table.append(append)
// checkAndPut
byte[] row = Bytes.toBytes(RowKey);
byte[] colfam = Bytes.toBytes("ColFam");
byte[] col = Bytes.toBytes("lastName");
Put put = new Put(row);
put.add(colfam, col, Bytes.toBytes("Patrick"));
boolearn result = table.checkAndPut(row, colfam, col, Bytes.toBytes("Witherspoon"), put);
Phoenix
UPSERT INTO FamilyTable (id, lastName) VALUES (1, ‘Brown’)
ON DUPLICATE KEY UPDATE id = "1", lastName = "Whiterspoon";
Azure Cosmos DB
In Azure Cosmos DB gli aggiornamenti vengono considerati operazioni upsert. Ovvero, se il documento non esiste, viene inserito.
// Replace existing document with new modified document (contingent on modification).
Family family = new Family();
family.setLastName("Brown");
family.setId("1");
CosmosItemResponse<Family> famResp = container.upsertItem(family, new CosmosItemRequestOptions());
Eliminare una riga/un documento
HBase
In Hbase non esiste un modo diretto per selezionare la riga in base al valore. È possibile che sia stato implementato il processo di eliminazione in combinazione con ValueFilter e così via. In questo esempio la riga da eliminare viene specificata da RowKey.
HTable table = new HTable(config, "FamilyTable");
Delete delete = new Delete(Bytes.toBytes(RowKey));
delete.deleteColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("id"));
delete.deleteColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
table.dalate(delete)
Phoenix
DELETE FROM TableName WHERE id = "xxx";
Azure Cosmos DB
Di seguito è riportato il metodo di eliminazione in base all'ID documento.
container.deleteItem(documentId, new PartitionKey(documentLastName), new CosmosItemRequestOptions());
Eseguire query su righe/documenti
HBase HBase consente di recuperare più righe usando l'analisi. È possibile usare i filtri per specificare condizioni di analisi dettagliate. Vedere Client Request Filters per i tipi di filtro predefiniti di HBase.
HTable table = new HTable(config, "FamilyTable");
Scan scan = new Scan();
SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes("ColFam"),
Bytes.toBytes("lastName"), CompareOp.EQUAL, New BinaryComparator(Bytes.toBytes("Witherspoon")));
filter.setFilterIfMissing(true);
filter.setLatestVersionOnly(true);
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
Phoenix
SELECT * FROM FamilyTable WHERE lastName = "Witherspoon"
Azure Cosmos DB
Operazione del filtro
String sql = "SELECT * FROM c WHERE c.lastName = 'Witherspoon'";
CosmosPagedIterable<Family> filteredFamilies = container.queryItems(sql, new CosmosQueryRequestOptions(), Family.class);
Eliminare una tabella/raccolta
HBase
HBaseAdmin admin = new HBaseAdmin(config);
admin.deleteTable("FamilyTable")
Phoenix
DROP TABLE IF EXISTS FamilyTable;
Azure Cosmos DB
CosmosContainerResponse containerResp = database.getContainer("FamilyContainer").delete(new CosmosContainerRequestOptions());
Altre considerazioni
I cluster HBase possono essere usati con carichi di lavoro HBase e MapReduce, Hive, Spark e altro ancora. Se si dispone di altri carichi di lavoro con HBase corrente, è necessario eseguire la migrazione anche di questi. Per informazioni dettagliate, vedere la relativa guida alla migrazione.
- MapReduce
- hbase
- Spark
Programmazione lato server
HBase offre diverse funzionalità di programmazione lato server. Se si usano queste funzionalità, sarà necessario eseguire la migrazione anche dell'elaborazione.
HBase
-
Diversi filtri sono disponibili come predefiniti in HBase, ma è anche possibile implementare filtri personalizzati. I filtri personalizzati possono essere implementati se i filtri disponibili come predefiniti in HBase non soddisfano i requisiti.
-
Il coprocessore è un framework che consente di eseguire il proprio codice nel server di area. Usando il coprocessore, è possibile eseguire l'elaborazione eseguita sul lato client sul lato server e, a seconda dell'elaborazione, può essere resa più efficiente. Esistono due tipi di coprocessore, Observer ed Endpoint.
Observer
- Observer associa operazioni ed eventi specifici. Si tratta di una funzione per l'aggiunta di un'elaborazione arbitraria. È una funzionalità simile ai trigger RDBMS.
Endpoint
- Endpoint è una funzionalità per l'estensione di HBase RPC. Si tratta di una funzione simile a una stored procedure RDBMS.
Azure Cosmos DB
-
- Le stored procedure di Azure Cosmos DB vengono scritte in JavaScript e possono eseguire operazioni quali la creazione, l'aggiornamento, la lettura, l'esecuzione di query e l'eliminazione di elementi nei contenitori di Azure Cosmos DB.
-
- I trigger possono essere specificati per le operazioni nel database. Sono disponibili due metodi: un pre-trigger che viene eseguito prima che l'elemento del database venga modificato e un post-trigger eseguito dopo la modifica dell'elemento del database.
-
- Azure Cosmos DB consente di definire le funzioni definite dall'utente. Le funzioni definite dall'utente possono essere scritte anche in JavaScript.
Le stored procedure e i trigger utilizzano le UR in base alla complessità delle operazioni eseguite. Quando si sviluppa l'elaborazione lato server, controllare l'utilizzo necessario per ottenere maggiori informazioni sulla quantità di UR utilizzate da ogni operazione. Per informazioni dettagliate, vedere Unità richiesta in Azure Cosmos DB e Ottimizzare il costo delle richieste in Azure Cosmos DB.
Mapping di programmazione lato server
| hbase | Azure Cosmos DB | Descrizione |
|---|---|---|
| Filtri personalizzati | Clausola WHERE | Se l'elaborazione implementata dal filtro personalizzato non può essere ottenuta con la clausola WHERE in Azure Cosmos DB, usare la funzione definita dall'utente in combinazione. |
| Coprocessore (Observer) | Trigger | Observer è un trigger che viene eseguito prima e dopo un determinato evento. Proprio come Observer supporta le pre-e le post-chiamate, il trigger di Azure Cosmos DB supporta anche i pre-trigger e i post-trigger. |
| Coprocessore (Endpoint) | Stored procedure | Endpoint è un meccanismo di elaborazione dati lato server eseguito per ogni area. È simile a una stored procedure RDBMS. Le stored procedure di Azure Cosmos DB vengono scritte in JavaScript. Fornisce l'accesso a tutte le operazioni che è possibile eseguire in Azure Cosmos DB tramite stored procedure. |
Nota
In Azure Cosmos DB possono essere necessari mapping e implementazioni diversi a seconda dell'elaborazione implementata in HBase.
Sicurezza
La sicurezza dei dati è una responsabilità condivisa tra il cliente e il provider di database. Per le soluzioni locali, i clienti devono fornire tutti gli elementi, dalla protezione degli endpoint alla sicurezza hardware fisica, che non è un'attività semplice. Se si sceglie un provider di database cloud PaaS, ad esempio Azure Cosmos DB, il coinvolgimento del cliente verrà ridotto. Azure Cosmos DB viene eseguito sulla piattaforma Azure, quindi può essere migliorato in modo diverso rispetto a HBase. Azure Cosmos DB non richiede l'installazione di componenti aggiuntivi per la sicurezza. È consigliabile eseguire la migrazione dell'implementazione della sicurezza del sistema di database usando l'elenco di controllo seguente:
| Controllo di sicurezza | HBase | Azure Cosmos DB |
|---|---|---|
| Sicurezza di rete e impostazioni del firewall | Controllare il traffico usando funzioni di sicurezza come i dispositivi di rete. | Supporta il controllo degli accessi basato su IP e su criteri nel firewall in ingresso. |
| Autenticazione utente e controlli utente con granularità fine | Controllo di accesso con granularità fine tramite la combinazione di LDAP con i componenti di sicurezza come Apache Ranger. | È possibile usare la chiave primaria dell'account per creare risorse utente e autorizzazioni per ogni database. I token di risorsa sono associati alle autorizzazioni nel database per determinare in che modo gli utenti possono accedere alle risorse dell'applicazione nel database (lettura/scrittura, sola lettura o nessun accesso). È anche possibile usare Microsoft Entra ID per autenticare le richieste di dati. In questo modo è possibile autorizzare le richieste di dati usando un modello di controllo degli accessi in base al ruolo con granularità fine. |
| Possibilità di replicare i dati a livello globale per gli errori locali | Creare una replica di database in un data center remoto usando la replica di HBase. | Azure Cosmos DB esegue una distribuzione globale senza configurazione e consente di replicare i dati nei data center in tutto il mondo in Azure con la selezione di un pulsante. In termini di sicurezza, la replica globale garantisce che i dati siano protetti da errori locali. |
| Possibilità di effettuare il failover da un data center a un altro | È necessario implementare personalmente il failover. | Se si esegue la replica dei dati in più data center e il data center dell'area diventa offline, Azure Cosmos DB esegue automaticamente il roll over dell'operazione. |
| Replica di dati locali all'interno di un data center | Il meccanismo HDFS consente di avere più repliche nei nodi all'interno di un singolo file system. | Azure Cosmos DB replica automaticamente i dati per mantenere la disponibilità elevata, anche all'interno di un singolo data center. È possibile scegliere personalmente il livello di coerenza. |
| Backup automatici dei dati | Non esiste alcuna funzione di backup automatico. È necessario implementare personalmente il backup dei dati. | Il backup di Azure Cosmos DB viene eseguito regolarmente e archiviato nell'archiviazione con ridondanza geografica. |
| Proteggere e isolare i dati sensibili | Ad esempio, se si usa Apache Ranger, è possibile usare i criteri Ranger per applicarli alla tabella. | È possibile separare dati personali e altri dati sensibili in contenitori specifici e in lettura/scrittura oppure limitare l'accesso in sola lettura a utenti specifici. |
| Monitoraggio per identificare gli attacchi | Deve essere implementata usando prodotti di terze parti. | Usando la registrazione di controllo e i log attività, è possibile monitorare l'account per identificare attività normali e anomale. |
| Risposta agli attacchi | Deve essere implementata usando prodotti di terze parti. | Quando si contatta il supporto tecnico di Azure per segnalare un potenziale attacco, viene avviato un processo di risposta all'evento imprevisto in 5 fasi. |
| Possibilità per i dati di seguire le restrizioni di governance dei dati in base al geo-fencing | È necessario controllare le restrizioni di ogni paese/area geografica e implementarlo personalmente. | Garantisce la governance dei dati per le aree sovrane (Germania, Cina, US Gov e così via). |
| Protezione fisica dei server in data center protetti | Dipende dal data center in cui si trova il sistema. | Per un elenco delle certificazioni più recenti, vedere il sito globale per la conformità di Azure. |
| Certificazioni | Dipende dalla distribuzione di Hadoop. | Vedere la documentazione sulla conformità in Azure. |
Per altre informazioni sulla sicurezza, vedere Panoramica sulla sicurezza in Azure Cosmos DB
Monitoraggio
HBase esegue in genere il monitoraggio del cluster usando l'interfaccia utente Web delle metriche del cluster o con Ambari, Cloudera Manager o altri strumenti di monitoraggio. Azure Cosmos DB consente di usare il meccanismo di monitoraggio integrato nella piattaforma Azure. Per altre informazioni sul monitoraggio di Azure Cosmos DB, vedere Monitorare Azure Cosmos DB.
Se l'ambiente implementa il monitoraggio del sistema di HBase per inviare avvisi, ad esempio tramite posta elettronica, potrebbe essere possibile sostituirlo con gli avvisi di Monitoraggio di Azure. È possibile ricevere avvisi in base alle metriche o agli eventi del log attività per l'account Azure Cosmos DB.
Per altre informazioni sugli avvisi in Monitoraggio di Azure, vedere Creare avvisi per Azure Cosmos DB usando Monitoraggio di Azure
Vedere anche le metriche e i tipi di log di Azure Cosmos DB che possono essere raccolti da Monitoraggio di Azure.
Backup e ripristino di emergenza
Backup
Esistono diversi modi per ottenere un backup di HBase. Ad esempio, Snapshot, Export, CopyTable, Backup offline dei dati HDFS e altri backup personalizzati.
Azure Cosmos DB esegue automaticamente il backup dei dati a intervalli periodici, il che non influisce sulle prestazioni o sulla disponibilità delle operazioni del database. I backup vengono archiviati in Archiviazione di Azure e possono essere usati per ripristinare i dati, se necessario. Esistono due tipi di backup di Azure Cosmos DB:
Ripristino di emergenza
HBase è un sistema distribuito a tolleranza di errore, ma è necessario implementare il ripristino di emergenza usando snapshot, repliche e così via quando il failover è necessario nel percorso di backup in caso di errore a livello di data center. La replica di HBase può essere configurata con tre modelli di replica: Leader-Follower, Leader-Leader e Cyclic. Se HBase di origine implementa il ripristino di emergenza, è necessario comprendere come configurarlo in Azure Cosmos DB e soddisfare i requisiti del sistema.
Azure Cosmos DB è un database distribuito a livello globale con funzionalità di ripristino di emergenza predefinite. È possibile replicare i dati del database in qualsiasi area di Azure. Azure Cosmos DB mantiene il database a disponibilità elevata nel caso improbabile di errore in alcune aree.
L'account Azure Cosmos DB che usa solo una singola area può perdere la disponibilità in caso di errore dell'area. È consigliabile configurare almeno due aree per garantire sempre la disponibilità elevata. È anche possibile garantire la disponibilità elevata sia per le operazioni di scrittura che di lettura configurando l'account Azure Cosmos DB per estendere almeno due aree con più aree di scrittura per garantire la disponibilità elevata per le operazioni di scrittura e lettura. Per gli account in più aree costituite da più aree di scrittura, il failover tra aree viene rilevato e gestito dal client di Azure Cosmos DB. Si tratta di eventi momentanei che non richiedono modifiche dall'applicazione. In questo modo, è possibile ottenere una configurazione di disponibilità che include il ripristino di emergenza per Azure Cosmos DB. Come accennato in precedenza, la replica di HBase può essere configurata con tre modelli, ma Azure Cosmos DB può essere configurato con la disponibilità basata su contratto di servizio configurando aree a scrittura singola e multi-scrittura.
Per altre informazioni sulla disponibilità elevata, vedere In che modo Azure Cosmos DB offre disponibilità elevata
Domande frequenti
Perché eseguire la migrazione all'API per NoSQL anziché ad altre API in Azure Cosmos DB?
L'API per NoSQL offre la migliore esperienza end-to-end in termini di interfaccia, libreria client dell'SDK del servizio. Le nuove funzionalità implementate in Azure Cosmos DB saranno disponibili per la prima volta nell'account API per NoSQL. Inoltre, l'API per NoSQL supporta l'analisi e offre la separazione delle prestazioni tra carichi di lavoro di produzione e analisi. Se si vogliono usare le tecnologie modernizzate per compilare le app, API per NoSQL è l'opzione consigliata.
È possibile assegnare HBase RowKey alla chiave di partizione di Azure Cosmos DB?
Potrebbe non essere ottimizzato così come è. In HBase i dati vengono ordinati in base alla RowKey specificata, archiviati nell'area e suddivisi in dimensioni fisse. Questo comportamento è diverso rispetto al partizionamento in Azure Cosmos DB. Di conseguenza, le chiavi devono essere riprogettate per distribuire meglio i dati in base alle caratteristiche del carico di lavoro. Per altri dettagli, vedere la sezione Distribuzione.
I dati vengono ordinati in base a RowKey in HBase, ma il partizionamento avviene in base alla chiave in Azure Cosmos DB. In che modo Azure Cosmos DB può ottenere l'ordinamento e la collocazione?
In Azure Cosmos DB è possibile aggiungere un indice composito per ordinare i dati in ordine crescente o decrescente e migliorare le prestazioni delle query di uguaglianza e intervallo. Vedere la sezione Distribuzione e Indice composto nella documentazione del prodotto.
L'elaborazione analitica viene eseguita sui dati HBase con Hive o Spark. Come è possibile modernizzarli in Azure Cosmos DB?
È possibile usare l'archivio analitico di Azure Cosmos DB per sincronizzare automaticamente i dati operativi in un altro archivio a colonne. Il formato di archivio a colonne è adatto per query analitiche di grandi dimensioni eseguite in modo ottimizzato, il che migliora la latenza per tali query. Collegamento ad Azure Synapse consente di creare una soluzione HTAP senza ETL eseguendo un collegamento diretto da Azure Synapse Analytics all'archivio analitico di Azure Cosmos DB. In questo modo è possibile eseguire analisi su larga scala quasi in tempo reale dei dati operativi. Synapse Analytics supporta i pool SQL di Apache Spark e serverless nell'archivio di analisi di Azure Cosmos DB. È possibile sfruttare questa funzionalità per eseguire la migrazione dell'elaborazione analitica. Per altre informazioni, vedere Archivio analitico.
In che modo gli utenti possono usare una query timestamp in HBase su Azure Cosmos DB?
Azure Cosmos DB non ha esattamente la stessa funzionalità di controllo delle versioni del timestamp di HBase. Azure Cosmos DB offre tuttavia la possibilità di accedere al feed di modifiche che può essere usato per il controllo delle versioni.
Archiviare ogni versione/modifica come elemento separato.
Leggere il feed di modifiche per unire/consolidare le modifiche e attivare le azioni appropriate downstream filtrando con il campo "_ts". Inoltre, per la versione precedente dei dati, è possibile far scadere le versioni precedenti usando TTL.
Passaggi successivi
Per un esempio, vedere Test delle prestazioni e della scalabilità con Azure Cosmos DB.
Per ottimizzare il codice, vedere l'articolo Suggerimenti sulle prestazioni per Azure Cosmos DB.
Esplorare il repository di GitHub riferimenti SDK per l'SDK asincrono per Java V3.