Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo illustra come creare cluster Apache Hadoop in HDInsight con il portale di Azure e quindi eseguire processi Apache Hive in HDInsight. La maggior parte dei processi Hadoop è costituita da processi batch. Viene creato un cluster, si eseguono alcuni processi e quindi si elimina il cluster. In questo articolo vengono eseguite tutte e tre le attività. Per una spiegazione approfondita delle configurazioni disponibili, vedere Configurare i cluster in HDInsight. Per altre informazioni sull'uso del portale per la creazione di cluster, vedere Creare cluster nel portale.
In questa guida di avvio rapido si userà il portale di Azure per creare un cluster Hadoop in HDInsight. È possibile creare un cluster usando il modello di Azure Resource Manager.
HDInsight attualmente viene fornito con sette diversi tipi di cluster. Ogni tipo di cluster supporta un set diverso di componenti. Tutti i tipi di cluster supportano Hive. Per un elenco dei componenti supportati in HDInsight, vedere Novità delle versioni cluster di Apache Hadoop incluse in HDInsight
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Creare un cluster Apache Hadoop
In questa sezione viene creato un cluster Hadoop in HDInsight usando il portale di Azure.
Accedere al portale di Azure.
Nel menu in alto selezionare + Crea una risorsa.
Selezionare Analytics>Azure HDInsight per passare alla pagina Crea cluster HDInsight.
Nella scheda Nozioni di base specificare le informazioni seguenti:
Proprietà Descrizione Subscription Nell'elenco a discesa selezionare la sottoscrizione di Azure che viene usata per il cluster. Gruppo di risorse Nell'elenco a discesa selezionare il gruppo di risorse esistente oppure selezionare Crea nuovo. Nome cluster Immettere un nome globalmente univoco. Il nome può includere al massimo 59 caratteri, tra cui lettere, numeri e trattini. Si noti che il primo e l'ultimo carattere del nome non possono essere trattini. Paese Nell'elenco a discesa selezionare un'area in cui viene creato il cluster. Scegliere una località vicina all'utente per ottenere prestazioni migliori. Tipo di cluster Scegliere Selezionare il tipo di cluster. Quindi selezionare Hadoop come tipo di cluster. Versione Nell'elenco a discesa selezionare una versione. Usare la versione predefinita, in caso di dubbi. Nome utente e password di accesso del cluster Il nome di accesso predefinito è admin. La password deve avere una lunghezza minima di 10 caratteri e contenere almeno una cifra, una lettera maiuscola, una lettera minuscola e un carattere non alfanumerico (ad eccezione di ' ` "). Assicurarsi di non fornire password comuni, ad esempio "Pass@word1".Nome utente Secure Shell (SSH) Il nome utente predefinito è sshuser. È possibile fornire un altro nome come nome utente SSH.Usare la password di accesso del cluster per SSH Selezionare questa casella di controllo se si desidera usare per l'utente SSH la stessa password fornita per l'utente di accesso del cluster. 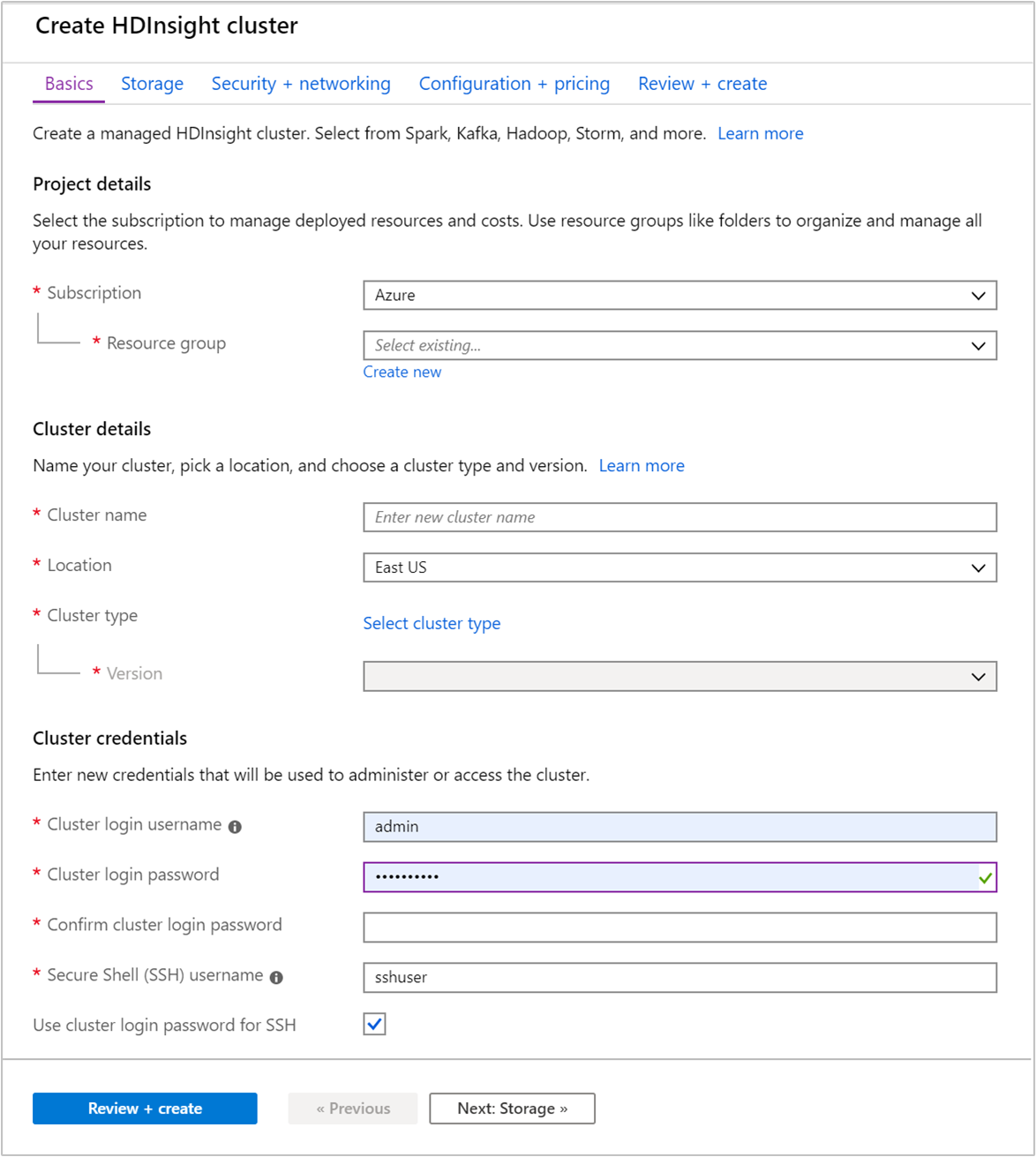
Selezionare Avanti: Archiviazione>> per andare alle impostazioni di archiviazione.
Nella scheda Archiviazione specificare i valori seguenti:
Proprietà Descrizione Tipo di archiviazione primario Usare il valore predefinito Archiviazione di Azure. Metodo di selezione Usare il valore predefinito Selezionare dall'elenco. Account di archiviazione primario Usare l'elenco a discesa per scegliere un account di archiviazione esistente oppure selezionare Crea nuovo. Se si crea un nuovo account, il nome deve avere una lunghezza compresa tra 3 e 24 caratteri e può contenere solo numeri e lettere minuscole Contenitore Usare il valore inserito automaticamente. 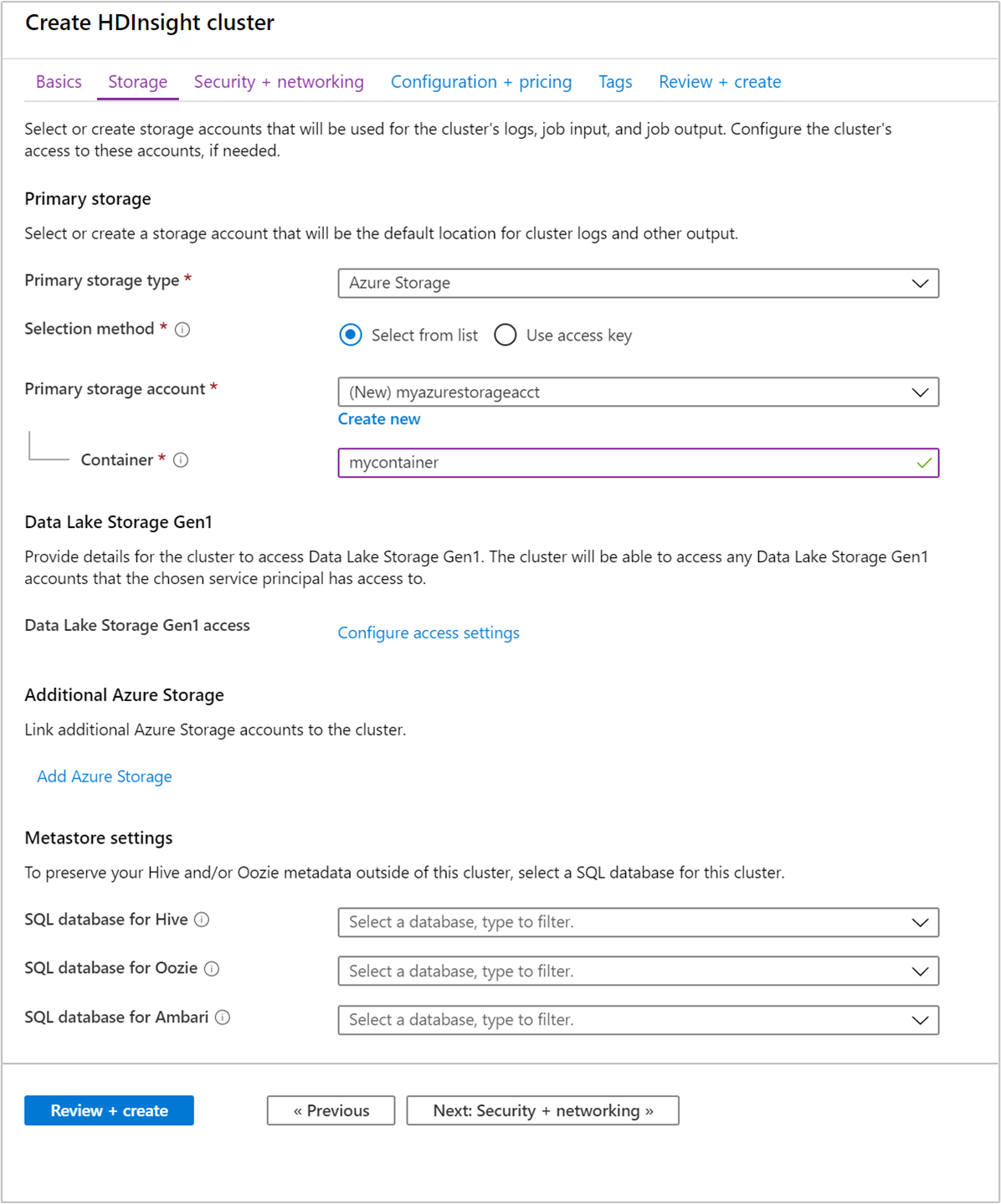
Ogni cluster ha una dipendenza dall'account di Archiviazione di Azure o da
Azure Data Lake Storage Gen2. Viene indicato come account di archiviazione predefinito. Il cluster HDInsight e l'account di archiviazione predefinito devono avere un percorso condiviso nella stessa area di Azure. L'eliminazione dei cluster non comporta l'eliminazione dell'account di archiviazione.Selezionare la scheda Rivedi e crea.
Nella scheda Rivedi e crea verificare i valori selezionati nei passaggi precedenti.
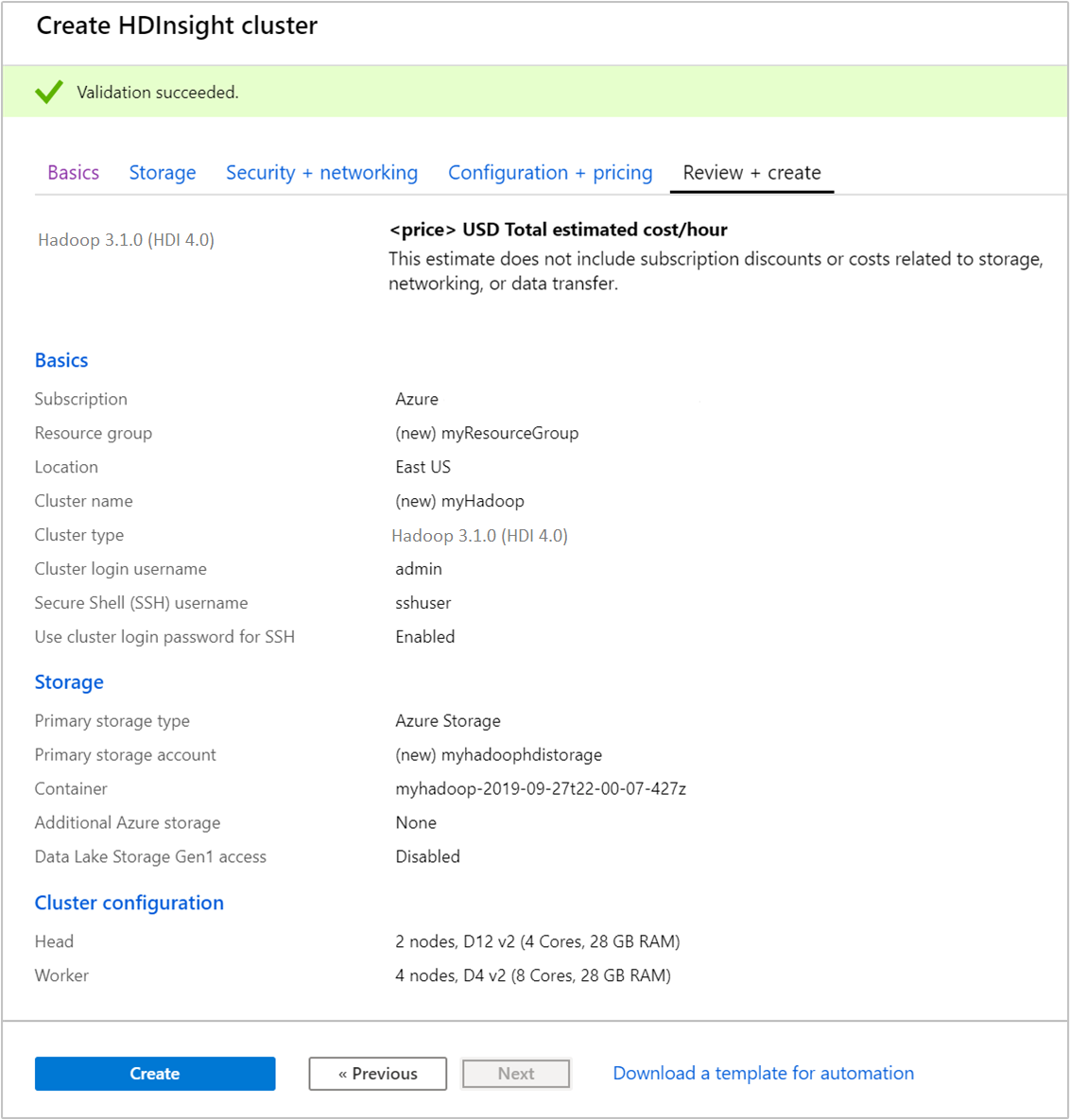
Seleziona Crea. La creazione di un cluster richiede circa 20 minuti.
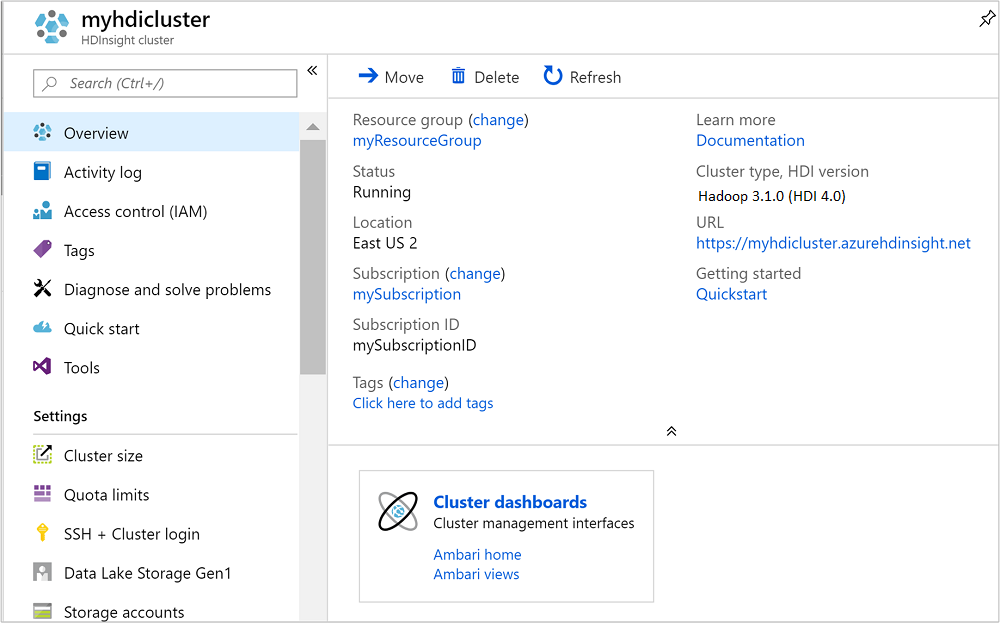
Dopo la creazione del cluster, compare la pagina di panoramica cluster nel portale di Azure.
Eseguire query Apache Hive
Apache Hive è il componente più diffuso usato in HDInsight. Esistono diversi modi per eseguire processi Hive in HDInsight. In questo argomento di avvio rapido si usa la visualizzazione Hive di Ambari dal portale. Per altri metodi di esecuzione di processi Hive, vedere Usare Hive in HDInsight.
Nota
La vista Apache Hive non è disponibile in HDInsight 4.0.
Per aprire Ambari, nello screenshot precedente selezionare Dashboard cluster. È anche possibile accedere a
https://ClusterName.azurehdinsight.net, doveClusterNameè il cluster creato nella sezione precedente.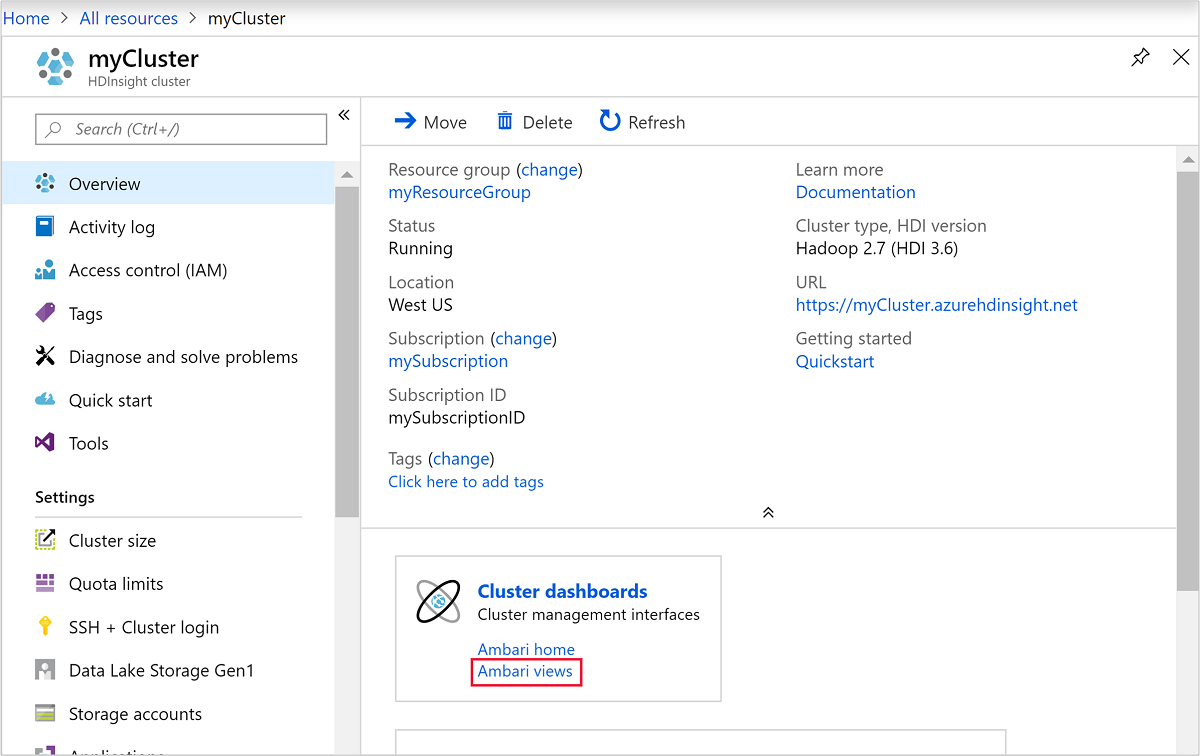
Immettere il nome utente e la password Hadoop specificati durante la creazione del cluster. Il nome utente predefinito è
admin.Aprire la visualizzazione Hive come illustrato nella schermata seguente:
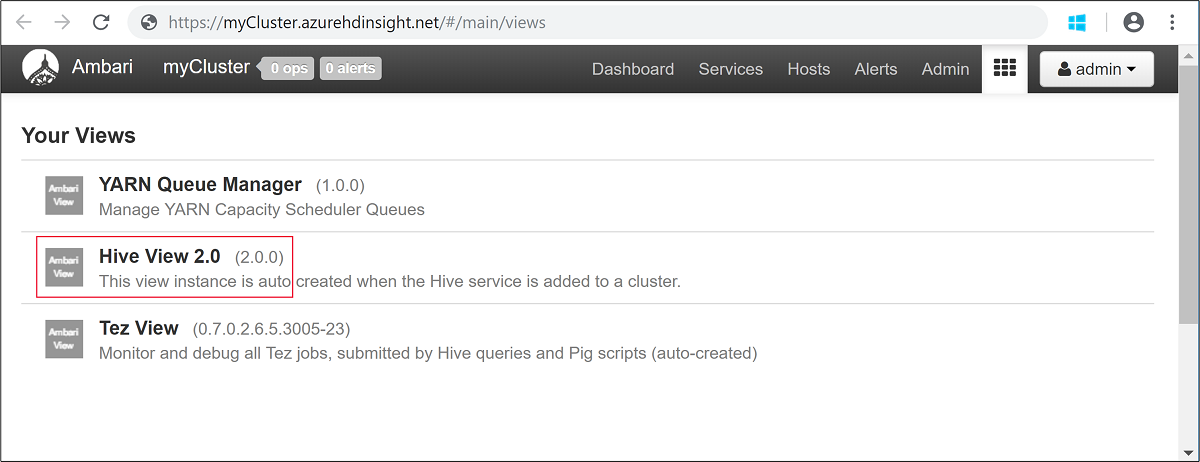
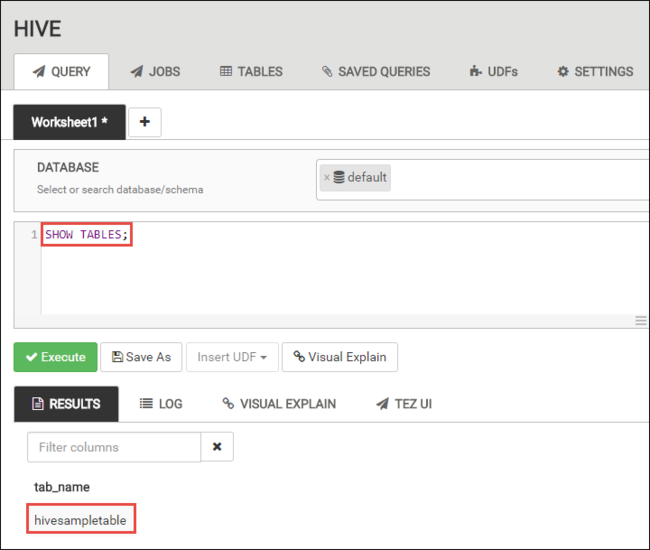
Nella scheda QUERY incollare le istruzioni HiveQL seguenti nel foglio di lavoro:
SHOW TABLES;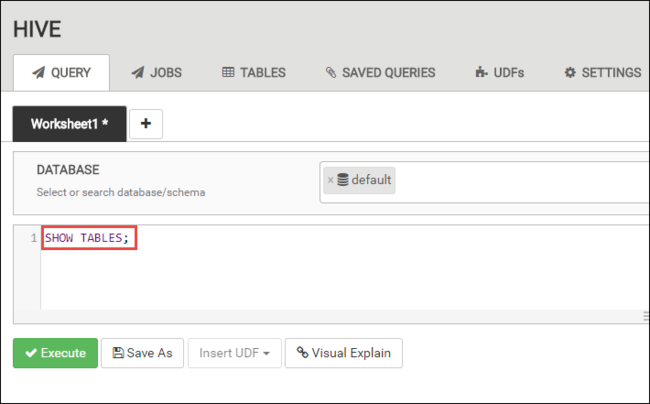
Seleziona Execute. Viene visualizzata una scheda RESULTS (RISULTATI) sotto la scheda QUERY e vengono visualizzate informazioni sul processo.
Al termine dell'elaborazione della query, nella scheda QUERY vengono visualizzati i risultati dell'operazione. Verrà visualizzata una tabella denominata hivesampletable. Questa tabella Hive di esempio è disponibile in tutti i cluster HDInsight.
Ripetere i passaggi 4 e 5 per eseguire questa query:
SELECT * FROM hivesampletable;È anche possibile salvare i risultati della query. Selezionare il pulsante del menu a destra e specificare se si vuole scaricare i risultati come file CSV o archiviarli nell'account di archiviazione associato al cluster.
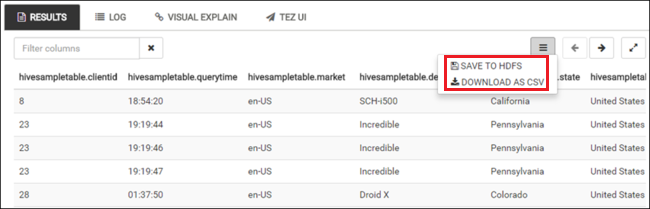
Dopo aver completato un processo Hive, è possibile esportare i risultati in un database SQL di Azure o in un database di SQL Server. È anche possibile visualizzare i risultati in Excel. Per altre informazioni sull'uso di Hive in HDInsight, vedere Usare Apache Hive e HiveQL con Apache Hadoop in HDInsight per analizzare un file Apache Log4j di esempio.
Pulire le risorse
Al termine dell'argomento di avvio rapido, può essere opportuno eliminare il cluster. Con HDInsight, i dati vengono archiviati in Archiviazione di Azure ed è possibile eliminare tranquillamente un cluster quando non è in uso. Vengono addebitati i costi anche per i cluster HDInsight che non sono in uso. Poiché i costi per il cluster sono decisamente superiori a quelli per l'archiviazione, eliminare i cluster quando non vengono usati è una scelta economicamente conveniente.
Nota
Se si procede subito con l'articolo successivo per imparare come eseguire le operazioni ETL mediante Hadoop in HDInsight, è possibile mantenere il cluster in esecuzione, poiché nell'esercitazione è necessario creare nuovamente un cluster Hadoop. Se invece non si prevede di passare subito all'articolo successivo, è necessario eliminare il cluster ora.
Per eliminare il cluster e/o l'account di archiviazione predefinito
Tornare alla scheda del browser in cui è visualizzato il portale di Azure. Occorre visualizzare la pagina di panoramica del cluster. Se si vuole solo eliminare il cluster ma conservare l'account di archiviazione predefinito, scegliere Elimina.
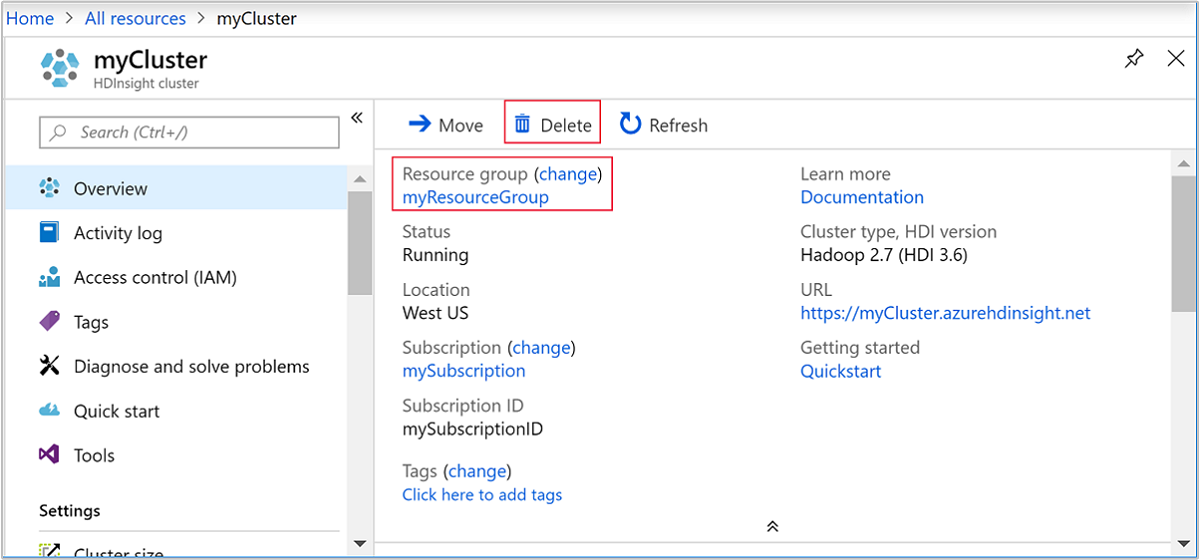
Se si intende eliminare il cluster, nonché l'account di archiviazione predefinito, selezionare il nome del gruppo di risorse (evidenziato nello screenshot precedente) per aprire la pagina di gruppo di risorse.
Selezionare Elimina gruppo di risorse per eliminare il gruppo di risorse che contiene il cluster e l'account di archiviazione predefinito. Si noti che l'eliminazione del gruppo di risorse comporta l'eliminazione dell'account di archiviazione. Se si vuole mantenere l'account di archiviazione, scegliere di eliminare solo il cluster.
Passaggi successivi
In questo argomento di avvio rapido si è appreso come creare un cluster HDInsight basato su Linux usando un modello di Resource Manager ed eseguire query Hive di base. Passare all'articolo successivo per informazioni su come eseguire un'operazione di estrazione, trasformazione e caricamento (ETL) usando Hadoop in HDInsight.