Valutare i sistemi di intelligenza artificiale usando il dashboard di Intelligenza artificiale responsabile
L'implementazione dell'Intelligenza artificiale responsabile in pratica richiede una progettazione rigorosa. Ma una progettazione rigorosa può essere un'attività monotona, manuale e dispendiosa in termini di tempo senza gli strumenti e l'infrastruttura corretti.
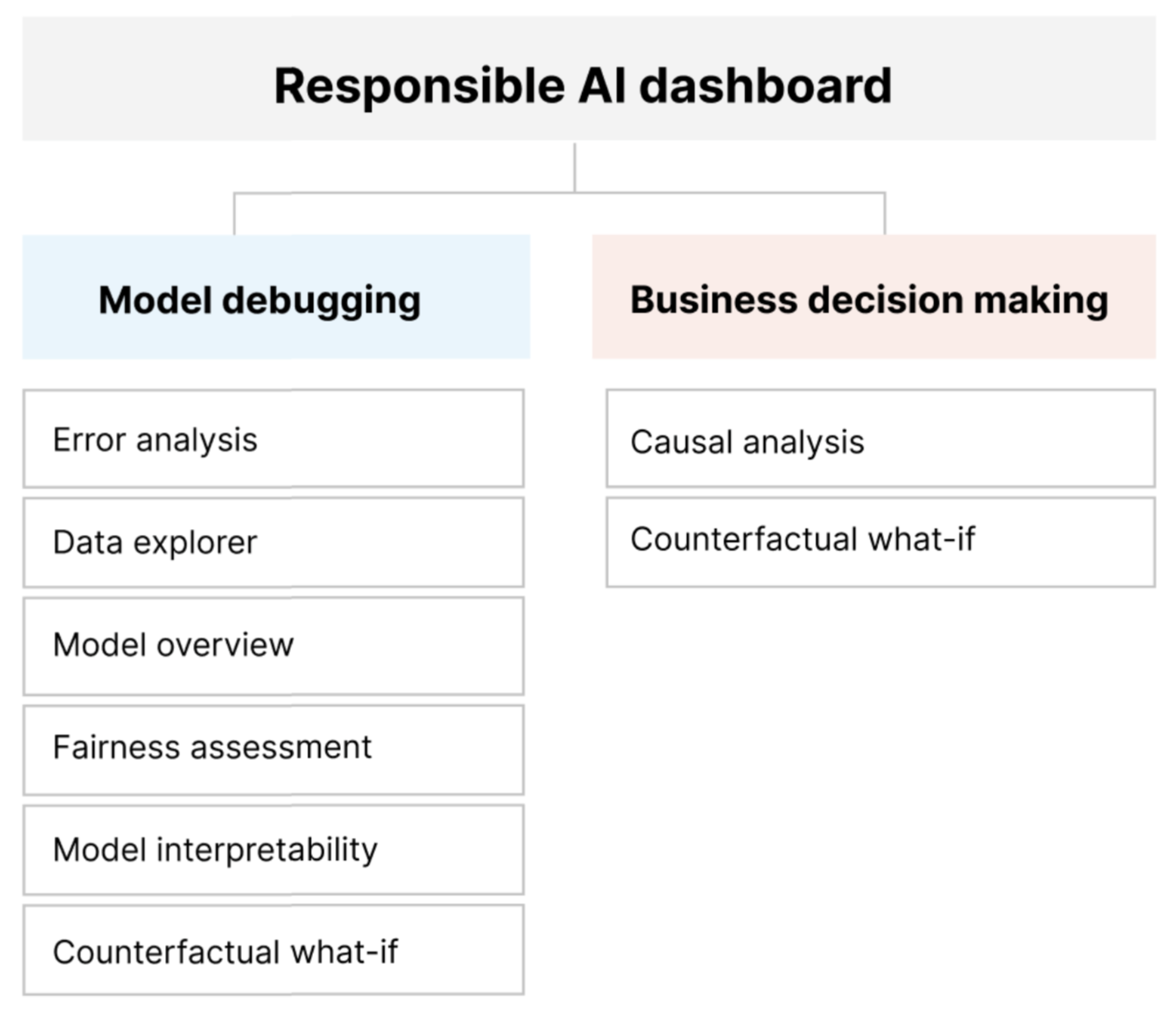
Il dashboard di Intelligenza artificiale responsabile offre un'unica interfaccia che consente di implementare l'intelligenza artificiale responsabile in pratica in modo efficace ed efficiente. Riunisce diversi strumenti di Intelligenza artificiale responsabile avanzati nelle aree di:
- Valutazione delle prestazioni e dell'equità del modello
- esplorazione dei dati
- Interpretabilità del Machine Learning
- Analisi degli errori
- Analisi controfattuale e perturbazioni
- Inferenza causale
Il dashboard offre una valutazione olistica e il debug dei modelli in modo da poter prendere decisioni informate basate sui dati. L'accesso a tutti questi strumenti in un'unica interfaccia consente di:
Valutare ed eseguire il debug dei modelli di Machine Learning identificando gli errori del modello e i problemi di equità, diagnosticare il motivo per cui si verificano tali errori e dare informazioni sui passaggi di mitigazione.
Aumentare le capacità decisionali basate sui dati rispondendo a domande come:
"Qual è la modifica minima che gli utenti possono applicare alle proprie funzionalità per ottenere un risultato diverso dal modello?"
"Qual è l'effetto causale della riduzione o dell'aumento di una caratteristica (ad esempio, consumo di carne rossa) su un risultato reale (ad esempio, progressione del diabete)?"
È possibile personalizzare il dashboard in modo da includere solo il subset di strumenti rilevanti per il caso d'uso.
Il dashboard di Intelligenza artificiale responsabile è accompagnato da una scorecard in PDF. La scorecard consente di esportare metadati e informazioni dettagliate sull'Intelligenza artificiale responsabile nei dati e nei modelli. È quindi possibile condividerli offline con gli stakeholder del prodotto e della conformità.
Componenti del dashboard di Intelligenza artificiale responsabile
Il dashboard di Intelligenza artificiale responsabile riunisce, in una visualizzazione completa, vari strumenti nuovi e preesistenti. Il dashboard integra questi strumenti con l'interfaccia della riga di comando di Azure Machine Learning v2, Azure Machine Learning Python SDK v2 e studio di Azure Machine Learning. Gli strumenti comprendono:
- Analisi dei dati, per comprendere ed esplorare le distribuzioni e le statistiche dei set di dati.
- Panoramica del modello e valutazione dell'equità, per valutare le prestazioni del modello e valutare i problemi di equità del gruppo del modello (in che modo le stime del modello influiscono su gruppi di persone diverse).
- Analisi degli errori, per visualizzare e comprendere come vengono distribuiti gli errori nel set di dati.
- Interpretabilità del modello (valori di importanza per le funzionalità di aggregazione e singole), per comprendere le stime del modello e il modo in cui vengono eseguite queste stime complessive e singole.
- Simulazione controfattuale, per osservare in che modo le perturbazioni delle funzionalità influiscono sulle stime del modello fornendo al tempo stesso i punti dati più vicini con stime del modello opposte o diverse.
- Analisi causale, per usare dati cronologici per visualizzare gli effetti causali delle caratteristiche di trattamento sui risultati reali.
Insieme, questi strumenti consentono di eseguire il debug di modelli di Machine Learning, informando al contempo le decisioni aziendali basate sui dati e basate su modelli. Il diagramma seguente illustra come incorporarli nel ciclo di vita dell'intelligenza artificiale per migliorare i modelli e ottenere informazioni approfondite sui dati.
Debug del modello
La valutazione e il debug dei modelli di Machine Learning è fondamentale per l'affidabilità del modello, l'interpretazione, l'equità e la conformità. Consente di determinare come e perché i sistemi di intelligenza artificiale si comportano nel modo in cui si comportano. È quindi possibile usare queste informazioni per migliorare le prestazioni del modello. Concettualmente, il debug del modello è costituito da tre fasi:
Identificare, per comprendere e riconoscere gli errori del modello e/o i problemi di equità rispondendo alle domande seguenti:
"Quali tipi di errori presenta il modello?"
"In quali aree si verificano gli errori più diffusi?"
Diagnosticare, per esplorare i motivi alla base degli errori identificati rispondendo a:
"Quali sono le cause di questi errori?"
"Dove è necessario concentrare le risorse per migliorare il modello?"
Attenuare, per usare le informazioni dettagliate sull'identificazione e la diagnosi delle fasi precedenti per adottare misure di attenuazione mirate e rispondere a domande come:
"Come è possibile migliorare il modello?"
"Quali soluzioni sociali o tecniche esistono per questi problemi?"

La tabella seguente descrive quando usare i componenti del dashboard di Intelligenza artificiale responsabile per supportare il debug del modello:
| Fase | Componente | Descrizione |
|---|---|---|
| Identificazione | Analisi degli errori | Il componente di analisi degli errori consente di ottenere una comprensione più approfondita della distribuzione degli errori del modello e di identificare rapidamente coorti errate (sottogruppi) di dati. Le funzionalità di questo componente nel dashboard provengono dal pacchetto di analisi degli errori. |
| Identificazione | Analisi dell'equità | Il componente di equità definisce i gruppi in termini di attributi sensibili, ad esempio sesso, razza ed età. Valuta quindi il modo in cui le stime del modello influiscono su questi gruppi e su come ridurre le disparità. Valutare le prestazioni del modello esplorando la distribuzione dei valori di previsione e i valori delle metriche delle prestazioni del modello tra i gruppi. Le funzionalità di questo componente nel dashboard provengono dal pacchetto Fairlearn. |
| Identificazione | Panoramica dei modelli | Il componente di panoramica del modello aggrega le metriche di valutazione del modello in una vista generale della distribuzione delle stime del modello per una migliore analisi delle prestazioni. Questo componente consente anche la valutazione dell'equità dei gruppi evidenziando la suddivisione delle prestazioni del modello tra gruppi sensibili. |
| Diagnosi | Analisi dei dati | L'analisi dei dati visualizza i set di dati in base a risultati stimati ed effettivi, gruppi di errori e funzionalità specifiche. È quindi possibile identificare i problemi di sovrapresentazione e sottopresentazione, oltre a vedere in che modo i dati vengono raggruppati nel set di dati. |
| Diagnosi | Interpretabilità dei modelli | Il componente di interpretabilità genera spiegazioni comprensibili per le stime di un modello di Machine Learning. Fornisce più viste del comportamento di un modello: - Spiegazioni globali (ad esempio, quali funzionalità influiscono sul comportamento complessivo di un modello di allocazione dei prestiti) - Spiegazioni locali (ad esempio, perché la richiesta di prestito di un richiedente è stata approvata o rifiutata) Le funzionalità di questo componente nel dashboard provengono dal pacchetto InterpretML. |
| Diagnosi | Analisi controfattuale e simulazione | Questo componente è costituito da due funzionalità per una migliore diagnosi degli errori: - Generazione di un set di esempi in cui le modifiche minime apportate a un determinato punto modificano la stima del modello. Ovvero, gli esempi mostrano i punti dati più vicini con previsioni del modello opposte. - Abilitazione di perturbazioni di simulazione interattive e personalizzate per i singoli punti dati per comprendere in che modo il modello reagisce alle modifiche delle funzionalità. Le funzionalità di questo componente nel dashboard provengono dal pacchetto DiCE. |
I passaggi di mitigazione sono disponibili tramite strumenti autonomi, ad esempio Fairlearn. Per altre informazioni, vedere gli algoritmi di mitigazione dell'iniquità.
Processo decisionale responsabile
Il processo decisionale è una delle promesse più grandi del Machine Learning. Il dashboard di Intelligenza artificiale responsabile consente di prendere decisioni aziendali informate tramite:
Informazioni dettagliate basate sui dati, per ulteriormente comprendere gli effetti causali del trattamento su un risultato, usando solo i dati cronologici. Ad esempio:
"In che modo una medicina influisce sulla pressione sanguigna di un paziente?"
"In che modo fornire valori promozionali a determinati clienti influisce sui ricavi?"
Queste informazioni dettagliate vengono fornite tramite il componente inferenza causale del dashboard.
Informazioni dettagliate basate su modello, per rispondere alle domande degli utenti, ad esempio "Cosa posso fare per ottenere un risultato diverso dall'intelligenza artificiale la prossima volta?", in modo da poter intervenire. Queste informazioni vengono fornite ai data scientist tramite il componente di simulazione controfattuale.

L'analisi esplorativa dei dati, l'inferenza causale e le funzionalità di analisi controfattuale consentono di prendere decisioni informate basate su modelli e basate sui dati in modo responsabile.
Questi componenti del dashboard di Intelligenza artificiale responsabile supportano il processo decisionale responsabile:
Analisi dei dati: è possibile riutilizzare il componente di analisi dei dati nel presente documento per comprendere le distribuzioni dei dati e identificare la sovrapresentazione e la sottopresentazione. L'esplorazione dei dati è una parte fondamentale del processo decisionale, perché non è possibile prendere decisioni informate su una coorte sottorappresentata nei dati.
Inferenza causale: il componente di inferenza causale stima il modo in cui un risultato reale cambia in presenza di un intervento. Aiuta anche a costruire interventi promettenti simulando risposte di caratteristiche a vari interventi e creando regole per determinare quali coorti della popolazione trarrebbero vantaggio da un particolare intervento. Collettivamente, queste funzionalità consentono di applicare nuovi criteri e applicare cambiamenti reali.
Le funzionalità di questo componente provengono dal pacchetto EconML, che stima effetti di trattamento eterogenei dai dati osservazionali tramite Machine Learning.
Analisi controfattuale: è possibile riutilizzare il componente di analisi controfattuale nel presente documento per generare modifiche minime applicate alle funzionalità di un punto dati che portano a stime del modello opposte. Ad esempio: Taylor avrebbe ottenuto l'approvazione del prestito dall'intelligenza artificiale se avesse guadagnato 10.000 dollari in più di reddito annuo e avesse due carte di credito aperte in meno.
Fornire queste informazioni agli utenti per informare la propria prospettiva. Li informa su come intervenire per ottenere il risultato desiderato dall'intelligenza artificiale in futuro.
Le funzionalità di questo componente provengono dal pacchetto DiCE.
Motivi per l'uso del dashboard di Intelligenza artificiale responsabile
Anche se sono stati compiuti progressi sui singoli strumenti per aree specifiche dell'Intelligenza artificiale responsabile, i data scientist spesso devono usare vari strumenti per valutare in modo olistico i modelli e i dati. Ad esempio, potrebbe essere necessario usare insieme la valutazione dell'interpretazione del modello e l'equità.
Se i data scientist individuano un problema di equità con uno strumento, è necessario passare a uno strumento diverso per comprendere quali dati o fattori del modello si trovano alla radice del problema prima di eseguire qualsiasi procedura di mitigazione. I fattori seguenti complicano ulteriormente questo processo complesso:
- Non è prevista una posizione centrale per scoprire e conoscere gli strumenti, estendendo il tempo necessario per la ricerca e apprendere nuove tecniche.
- I diversi strumenti non comunicano tra loro. I data scientist devono creare set di dati, modelli e altri metadati man mano che li passano tra gli strumenti.
- Le metriche e le visualizzazioni non sono facilmente confrontabili e i risultati sono difficili da condividere.
Il dashboard di Intelligenza artificiale responsabile sfida questo status quo. Si tratta di uno strumento completo e personalizzabile che riunisce esperienze frammentate in un'unica posizione. Consente di eseguire facilmente l'onboarding in un unico framework personalizzabile per il debug dei modelli e il processo decisionale basato sui dati.
Usando il dashboard di Intelligenza artificiale responsabile, è possibile creare coorti di set di dati, passarli a tutti i componenti supportati e osservare l'integrità del modello per le coorti identificate. È possibile confrontare ulteriormente le informazioni dettagliate di tutti i componenti supportati in un'ampia gamma di coorti predefinite per eseguire analisi disaggregate e trovare i punti ciechi del modello.
Quando si è pronti a condividere queste informazioni dettagliate con altri stakeholder, è possibile estrarle facilmente usando la scorecard PDF di Intelligenza artificiale responsabile. Allegare il report PDF ai report di conformità o condividerlo con i colleghi per creare fiducia e ottenere l'approvazione.
Modi per personalizzare il dashboard di Intelligenza artificiale responsabile
La forza del dashboard di Intelligenza artificiale responsabile risiede nella sua personalizzazione. Consente agli utenti di progettare flussi di lavoro personalizzati ed end-to-end del modello che rispondono alle loro esigenze specifiche.
Hai bisogno di ispirazione? Ecco alcuni esempi di come i componenti del dashboard possono essere combinati per analizzare gli scenari in modi diversi:
| Flusso del dashboard di Intelligenza artificiale responsabile | Caso d'uso |
|---|---|
| Panoramica del modello > analisi degli errori > analisi dei dati | Per identificare gli errori del modello e diagnosticarli comprendendo la distribuzione dei dati sottostante |
| Panoramica del modello > valutazione dell'equità > analisi dei dati | Per identificare i problemi di equità del modello e diagnosticarli comprendendo la distribuzione dei dati sottostante |
| Panoramica del modello > analisi degli errori > analisi controfattuale e simulazione | Per diagnosticare gli errori nelle singole istanze con l'analisi controfattuale (modifica minima per generare una stima del modello diversa) |
| Panoramica del modello > analisi dei dati | Per comprendere la causa radice di errori e problemi di equità introdotti tramite squilibri di dati o mancanza di rappresentazione di una particolare coorte di dati |
| Panoramica del modello > interpretabilità | Per diagnosticare gli errori del modello tramite la comprensione del modo in cui il modello ha eseguito le stime |
| Analisi dei dati > inferenza causale | Per distinguere tra correlazioni e cause nei dati o decidere i trattamenti migliori da applicare per ottenere un risultato positivo |
| Interpretabilità > inferenza causale | Per sapere se i fattori usati dal modello per la previsione hanno effetti causali sul risultato reale |
| Analisi dei dati > analisi controfattuale e simulazione | Per rispondere alle domande dei clienti su cosa possono fare la prossima volta per ottenere un risultato diverso da un sistema di intelligenza artificiale |
Persone che devono usare il dashboard di Intelligenza artificiale responsabile
Le persone seguenti possono usare il dashboard di Intelligenza artificiale responsabile e la corrispondente scorecard di Intelligenza artificiale responsabile per costruire fiducia con i sistemi di intelligenza artificiale:
- Professionisti di Machine Learning e data scientist interessati al debug e al miglioramento dei modelli di Machine Learning prima della distribuzione
- Professionisti e data scientist di Machine Learning interessati a condividere i propri record di integrità del modello con responsabili di prodotto e stakeholder aziendali per creare fiducia e ricevere autorizzazioni di distribuzione
- Responsabili di prodotto e stakeholder aziendali che esaminano i modelli di Machine Learning prima della distribuzione
- Responsabili dei rischi che esaminano i modelli di Machine Learning per comprendere l'equità e i problemi di affidabilità
- Provider di soluzioni di intelligenza artificiale che vogliono spiegare le decisioni del modello agli utenti o aiutarli a migliorare il risultato
- Professionisti in spazi fortemente regolamentati che devono esaminare i modelli di Machine Learning con autorità di regolamentazione e revisori
Scenari supportati e limitazioni
- Il dashboard di Intelligenza artificiale responsabile supporta attualmente modelli di regressione e classificazione (binario e multi-classe) sottoposti a training su dati strutturati tabulari.
- Il dashboard di intelligenza artificiale responsabile supporta attualmente i modelli MLflow registrati in Azure Machine Learning solo con una versione sklearn (scikit-learn). I modelli scikit-learn devono implementare metodi
predict()/predict_proba()oppure il modello deve essere sottoposto a wrapping all'interno di una classe che implementa i metodipredict()/predict_proba(). I modelli devono essere caricabili nell'ambiente dei componenti e devono essere selezionabili. - Il dashboard di Intelligenza artificiale responsabile visualizza attualmente fino a 5.000 punti dati nell'interfaccia utente del dashboard. È consigliabile sottocampionare il set di dati a 5.000 o meno prima di passarlo al dashboard.
- Gli input del set di dati nel dashboard di Intelligenza artificiale responsabile devono essere dataframe Pandas in formato Parquet. I dati di tipo sparse NumPy e SciPy non sono attualmente supportati.
- Il dashboard di Intelligenza artificiale responsabile supporta attualmente funzionalità numeriche o categoriche. Per le funzionalità categoriche, l'utente deve specificare in modo esplicito i nomi delle funzionalità.
- Il dashboard di Intelligenza artificiale responsabile attualmente non supporta i set di dati con più di 10.000 colonne.
- Il dashboard di Intelligenza artificiale responsabile attualmente non supporta il modello AutoML MLFlow.
Passaggi successivi
- Informazioni su come generare il dashboard di intelligenza artificiale responsabile tramite l'interfaccia della riga di comando e l'SDK o l'interfaccia utente dello studio di Azure Machine Learning.
- Informazioni su come generare una scorecard di intelligenza artificiale responsabile in base alle informazioni dettagliate osservate nel dashboard di intelligenza artificiale responsabile.