Inviare processi Spark in Azure Machine Learning
SI APPLICA A: Estensione Ml dell'interfaccia della riga di comando di Azure v2 (current)Python SDK azure-ai-ml v2 (current)
Estensione Ml dell'interfaccia della riga di comando di Azure v2 (current)Python SDK azure-ai-ml v2 (current)
Azure Machine Learning supporta l'invio di processi di Machine Learning autonomi e la creazione di pipeline di Machine Learning che coinvolgono più passaggi del flusso di lavoro di Machine Learning. Azure Machine Learning gestisce sia la creazione di processi Spark autonomi che la creazione di componenti Spark riutilizzabili che le pipeline di Azure Machine Learning possono usare. In questo articolo si apprenderà come inviare processi Spark usando:
- interfaccia utente di studio di Azure Machine Learning
- Interfaccia della riga di comando di Azure Machine Learning
- SDK di Azure Machine Learning
Per altre informazioni sui concetti relativi ad Apache Spark in Azure Machine Learning , vedere questa risorsa.
Prerequisiti
SI APPLICA A:Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
- Una sottoscrizione di Azure; se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
- Un'area di lavoro di Azure Machine Learning. Vedere Creare risorse dell'area di lavoro.
- Creare un'istanza di calcolo di Azure Machine Learning.
- Installare l'interfaccia della riga di comando di Azure Machine Learning.
- (Facoltativo): pool di Spark synapse collegato nell'area di lavoro di Azure Machine Learning.
Nota
- Per altre informazioni sull'accesso alle risorse durante l'uso dell'ambiente di calcolo Spark serverless di Azure Machine Learning e sul pool di Spark collegato, vedere Garantire l'accesso alle risorse per i processi Spark.
- Azure Machine Learning offre un pool di quote condivise da cui tutti gli utenti possono accedere alla quota di calcolo per eseguire test per un periodo di tempo limitato. Quando si usa il calcolo Spark serverless, Azure Machine Learning consente di accedere a questa quota condivisa per un breve periodo di tempo.
Collegare un'identità gestita assegnata dall'utente tramite l'interfaccia della riga di comando v2
- Creare un file YAML che definisce l'identità gestita assegnata dall'utente che deve essere collegata all'area di lavoro:
identity: type: system_assigned,user_assigned tenant_id: <TENANT_ID> user_assigned_identities: '/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>': {} - Con il
--fileparametro usare il file YAML nelaz ml workspace updatecomando per allegare l'identità gestita assegnata dall'utente:az ml workspace update --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --name <AML_WORKSPACE_NAME> --file <YAML_FILE_NAME>.yaml
Collegare un'identità gestita assegnata dall'utente usando ARMClient
- Installare
ARMClient, un semplice strumento da riga di comando che richiama l'API di Azure Resource Manager. - Creare un file JSON che definisce l'identità gestita assegnata dall'utente che deve essere collegata all'area di lavoro:
{ "properties":{ }, "location": "<AZURE_REGION>", "identity":{ "type":"SystemAssigned,UserAssigned", "userAssignedIdentities":{ "/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>": { } } } } - Per collegare l'identità gestita assegnata dall'utente all'area di lavoro, eseguire il comando seguente nel prompt di PowerShell o nel prompt dei comandi.
armclient PATCH https://management.azure.com/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>?api-version=2022-05-01 '@<JSON_FILE_NAME>.json'
Nota
- Per garantire la corretta esecuzione del processo Spark, assegnare i ruoli Collaboratore e Collaboratore dati BLOB Archiviazione, nell'account di archiviazione di Azure usato per l'input e l'output dei dati, all'identità usata dal processo Spark
- L'accesso alla rete pubblica deve essere abilitato nell'area di lavoro di Azure Synapse per garantire la corretta esecuzione del processo Spark usando un pool di Spark synapse collegato.
- Se un pool di Spark synapse collegato punta a un pool di Synapse Spark, in un'area di lavoro di Azure Synapse a cui è associata una rete virtuale gestita, è necessario configurare un endpoint privato gestito per l'account di archiviazione per garantire l'accesso ai dati.
- L'ambiente di calcolo Spark serverless supporta la rete virtuale gestita di Azure Machine Learning. Se viene effettuato il provisioning di una rete gestita per il calcolo Spark serverless, è necessario effettuare il provisioning degli endpoint privati corrispondenti per l'account di archiviazione per garantire l'accesso ai dati.
Inviare un processo Spark autonomo
Dopo aver apportato le modifiche necessarie per la parametrizzazione degli script Python, è possibile usare uno script Python sviluppato da data wrangling interattivo per inviare un processo batch per elaborare un volume di dati più grande. Un processo batch di data wrangling semplice può essere inviato come processo Spark autonomo.
Un processo Spark richiede uno script Python che accetta argomenti, che può essere sviluppato con la modifica del codice Python sviluppato da data wrangling interattivo. Di seguito è riportato uno script Python di esempio.
# titanic.py
import argparse
from operator import add
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
parser = argparse.ArgumentParser()
parser.add_argument("--titanic_data")
parser.add_argument("--wrangled_data")
args = parser.parse_args()
print(args.wrangled_data)
print(args.titanic_data)
df = pd.read_csv(args.titanic_data, index_col="PassengerId")
imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy(
"mean"
) # Replace missing values in Age column with the mean value
df.fillna(
value={"Cabin": "None"}, inplace=True
) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
df.to_csv(args.wrangled_data, index_col="PassengerId")
Nota
Questo esempio di codice Python usa pyspark.pandas. Questo supporto è supportato solo dal runtime spark versione 3.2 o successiva.
Lo script precedente accetta due argomenti --titanic_data e --wrangled_data, che passano rispettivamente il percorso dei dati di input e della cartella di output.
SI APPLICA A:Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
Per creare un processo, è possibile definire un processo Spark autonomo come file di specifica YAML, che può essere usato nel az ml job create comando con il --file parametro . Definire queste proprietà nel file YAML:
Proprietà YAML nella specifica del processo Spark
type- impostato suspark.code: definisce il percorso della cartella che contiene il codice sorgente e gli script per questo processo.entry: definisce il punto di ingresso per il processo. Deve coprire una di queste proprietà:file: definisce il nome dello script Python che funge da punto di ingresso per il processo.
py_files: definisce un elenco di.zipfile ,.eggo.pyda inserire in per l'esecuzionePYTHONPATHcorretta del processo. Questa proprietà è facoltativa.jars: definisce un elenco di.jarfile da includere nel driver Spark e nell'executorCLASSPATHper l'esecuzione corretta del processo. Questa proprietà è facoltativa.files: definisce un elenco di file che devono essere copiati nella directory di lavoro di ogni executor, per un'esecuzione corretta del processo. Questa proprietà è facoltativa.archives: definisce un elenco di archivi che devono essere estratti nella directory di lavoro di ogni executor, per un'esecuzione corretta del processo. Questa proprietà è facoltativa.conf: definisce queste proprietà del driver Spark e dell'executor:spark.driver.cores: numero di core per il driver Spark.spark.driver.memory: memoria allocata per il driver Spark, in gigabyte (GB).spark.executor.cores: numero di core per l'executor Spark.spark.executor.memory: allocazione di memoria per l'executor Spark, in gigabyte (GB).spark.dynamicAllocation.enabled- indica se gli executor devono essere allocati in modo dinamico, comeTruevalore oFalse.- Se l'allocazione dinamica degli executor è abilitata, definire queste proprietà:
spark.dynamicAllocation.minExecutors: numero minimo di istanze di executor Spark per l'allocazione dinamica.spark.dynamicAllocation.maxExecutors: numero massimo di istanze di executor Spark per l'allocazione dinamica.
- Se l'allocazione dinamica degli executor è disabilitata, definire questa proprietà:
spark.executor.instances: numero di istanze dell'executor Spark.
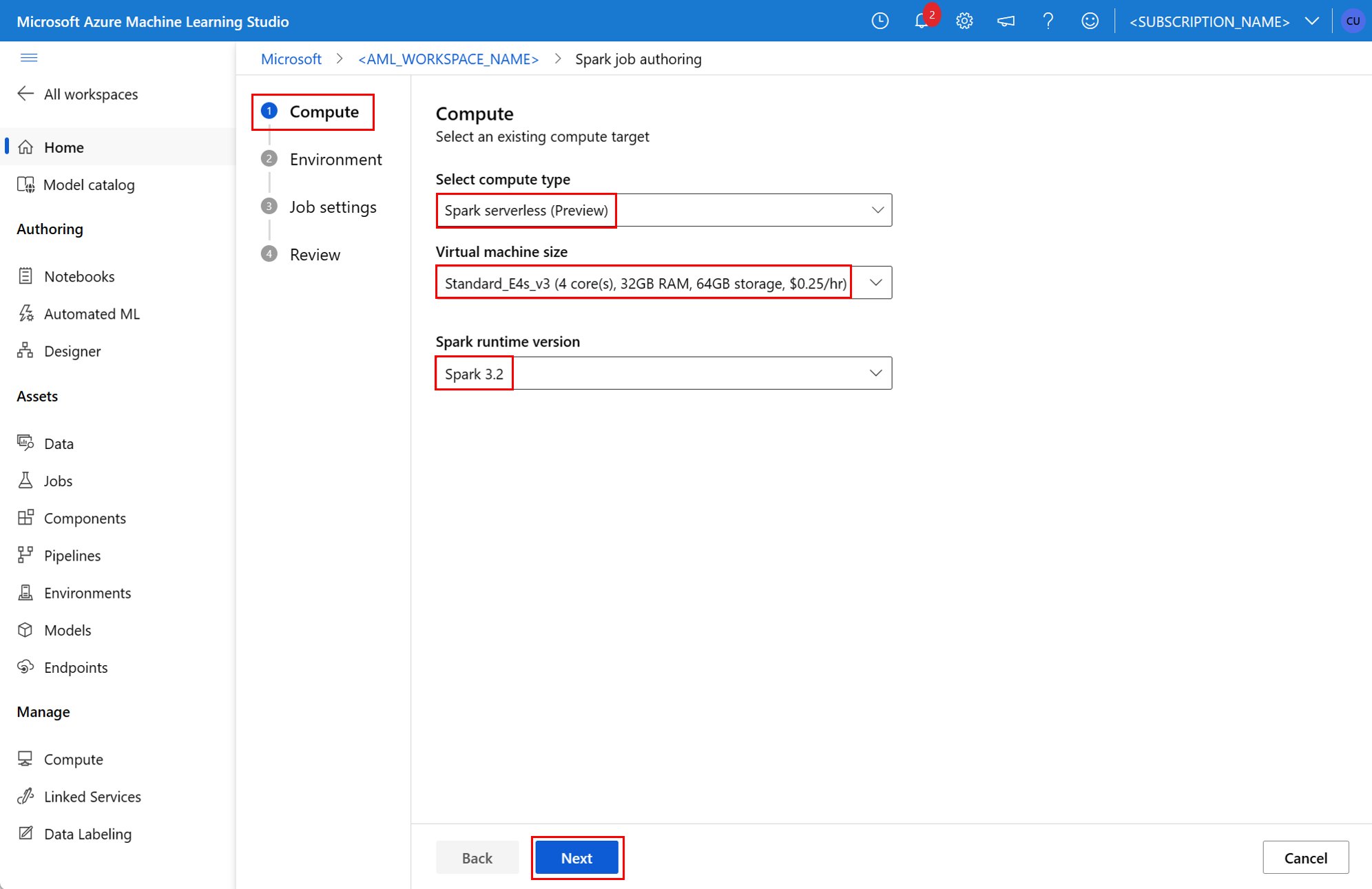
environment: un ambiente di Azure Machine Learning per eseguire il processo.args: gli argomenti della riga di comando che devono essere passati allo script Python del punto di ingresso del processo. Per un esempio, vedere il file di specifica YAML fornito qui.resources: questa proprietà definisce le risorse da usare da un ambiente di calcolo Spark serverless di Azure Machine Learning. Usa le proprietà seguenti:instance_type: tipo di istanza di calcolo da usare per il pool di Spark. Sono attualmente supportati i tipi di istanza seguenti:standard_e4s_v3standard_e8s_v3standard_e16s_v3standard_e32s_v3standard_e64s_v3
runtime_version: definisce la versione del runtime di Spark. Sono attualmente supportate le versioni di runtime spark seguenti:3.23.3Importante
Runtime di Azure Synapse per Apache Spark: annunci
- Runtime di Azure Synapse per Apache Spark 3.2:
- Data annuncio EOLA: 8 luglio 2023
- Data di fine del supporto: 8 luglio 2024. Dopo questa data, il runtime verrà disabilitato.
- Per un supporto continuo e prestazioni ottimali, è consigliabile eseguire la migrazione ad Apache Spark 3.3.
- Runtime di Azure Synapse per Apache Spark 3.2:
Questo è un esempio:
resources: instance_type: standard_e8s_v3 runtime_version: "3.3"compute: questa proprietà definisce il nome di un pool di Spark Synapse collegato, come illustrato in questo esempio:compute: mysparkpoolinputs: questa proprietà definisce gli input per il processo Spark. Gli input per un processo Spark possono essere un valore letterale o dati archiviati in un file o in una cartella.- Un valore letterale può essere un numero, un valore booleano o una stringa. Ecco alcuni esempi:
inputs: sampling_rate: 0.02 # a number hello_number: 42 # an integer hello_string: "Hello world" # a string hello_boolean: True # a boolean value - I dati archiviati in un file o in una cartella devono essere definiti usando queste proprietà:
type: impostare questa proprietàuri_filesu ouri_folder, rispettivamente per i dati di input contenuti in un file o in una cartella.path- URI dei dati di input, ad esempioazureml://,abfss://owasbs://.mode: impostare questa proprietà sudirect. Questo esempio mostra la definizione di un input di processo, che può essere definito :$${inputs.titanic_data}}inputs: titanic_data: type: uri_file path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv mode: direct
- Un valore letterale può essere un numero, un valore booleano o una stringa. Ecco alcuni esempi:
outputs: questa proprietà definisce gli output del processo Spark. Gli output per un processo Spark possono essere scritti in un file o in un percorso di cartella, definito usando le tre proprietà seguenti:type: questa proprietà può essere impostata rispettivamente suuri_fileouri_folderper la scrittura di dati di output in un file o in una cartella.path: questa proprietà definisce l'URI del percorso di output, ad esempioazureml://,abfss://owasbs://.mode: impostare questa proprietà sudirect. Questo esempio mostra la definizione di un output del processo, che può essere definito :${{outputs.wrangled_data}}outputs: wrangled_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/data/wrangled/ mode: direct
identity: questa proprietà facoltativa definisce l'identità usata per inviare questo processo. Può avereuser_identityvalori emanaged. Se la specifica YAML non definisce un'identità, il processo Spark usa l'identità predefinita.
Processo Spark autonomo
Questa specifica YAML di esempio mostra un processo Spark autonomo. Usa un ambiente di calcolo Spark serverless di Azure Machine Learning:
$schema: http://azureml/sdk-2-0/SparkJob.json
type: spark
code: ./
entry:
file: titanic.py
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.executor.instances: 2
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
identity:
type: user_identity
resources:
instance_type: standard_e4s_v3
runtime_version: "3.3"
Nota
Per usare un pool di Spark Synapse collegato, definire la compute proprietà nel file di specifica YAML di esempio illustrato in precedenza, anziché nella resources proprietà .
I file YAML mostrati in precedenza possono essere usati nel az ml job create comando , con il --file parametro , per creare un processo Spark autonomo, come illustrato di seguito:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
È possibile eseguire il comando precedente da:
- terminale di un'istanza di calcolo di Azure Machine Learning.
- terminale di Visual Studio Code connesso a un'istanza di calcolo di Azure Machine Learning.
- nel computer locale in cui è installata l'interfaccia della riga di comando di Azure Machine Learning.
Componente Spark in un processo della pipeline
Un componente Spark offre la flessibilità di usare lo stesso componente in più pipeline di Azure Machine Learning, come passaggio della pipeline.
SI APPLICA A:Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
La sintassi YAML per un componente Spark è simile alla sintassi YAML per la specifica del processo Spark nella maggior parte dei modi. Queste proprietà sono definite in modo diverso nella specifica YAML del componente Spark:
name: nome del componente Spark.version: versione del componente Spark.display_name: nome del componente Spark da visualizzare nell'interfaccia utente e altrove.description: la descrizione del componente Spark.inputs: questa proprietà è simile allainputsproprietà descritta nella sintassi YAML per la specifica del processo Spark, ad eccezione del fatto che non definisce lapathproprietà . Questo frammento di codice mostra un esempio della proprietà del componenteinputsSpark:inputs: titanic_data: type: uri_file mode: directoutputs: questa proprietà è simile allaoutputsproprietà descritta nella sintassi YAML per la specifica del processo Spark, ad eccezione del fatto che non definisce lapathproprietà . Questo frammento di codice mostra un esempio della proprietà del componenteoutputsSpark:outputs: wrangled_data: type: uri_folder mode: direct
Nota
Un componente Spark non definisce identityle proprietà o resourcescompute . Il file di specifica YAML della pipeline definisce queste proprietà.
Questo file di specifica YAML fornisce un esempio di componente Spark:
$schema: http://azureml/sdk-2-0/SparkComponent.json
name: titanic_spark_component
type: spark
version: 1
display_name: Titanic-Spark-Component
description: Spark component for Titanic data
code: ./src
entry:
file: titanic.py
inputs:
titanic_data:
type: uri_file
mode: direct
outputs:
wrangled_data:
type: uri_folder
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.dynamicAllocation.enabled: True
spark.dynamicAllocation.minExecutors: 1
spark.dynamicAllocation.maxExecutors: 4
Il componente Spark definito nel file di specifica YAML precedente può essere usato in un processo della pipeline di Azure Machine Learning. Per altre informazioni sulla sintassi YAML che definisce un processo della pipeline, vedere Schema YAML del processo della pipeline. Questo esempio mostra un file di specifica YAML per un processo della pipeline, con un componente Spark e un ambiente di calcolo Spark serverless di Azure Machine Learning:
$schema: http://azureml/sdk-2-0/PipelineJob.json
type: pipeline
display_name: Titanic-Spark-CLI-Pipeline
description: Spark component for Titanic data in Pipeline
jobs:
spark_job:
type: spark
component: ./spark-job-component.yaml
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
identity:
type: managed
resources:
instance_type: standard_e8s_v3
runtime_version: "3.3"
Nota
Per usare un pool di Spark Synapse collegato, definire la compute proprietà nel file di specifica YAML di esempio illustrato in precedenza, anziché resources la proprietà .
Il file di specifica YAML precedente può essere usato nel az ml job create comando , usando il --file parametro , per creare un processo della pipeline come illustrato di seguito:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
È possibile eseguire il comando precedente da:
- terminale di un'istanza di calcolo di Azure Machine Learning.
- terminale di Visual Studio Code connesso a un'istanza di calcolo di Azure Machine Learning.
- nel computer locale in cui è installata l'interfaccia della riga di comando di Azure Machine Learning.
Risoluzione dei problemi relativi ai processi Spark
Per risolvere i problemi relativi a un processo Spark, è possibile accedere ai log generati per tale processo in studio di Azure Machine Learning. Per visualizzare i log per un processo Spark:
- Passare a Processi dal pannello sinistro nell'interfaccia utente di studio di Azure Machine Learning
- Selezionare la scheda Tutti i processi
- Selezionare il valore Nome visualizzato per il processo
- Nella pagina dei dettagli del processo selezionare la scheda Output e log
- In Esplora file espandere la cartella logs e quindi espandere la cartella azureml
- Accedere ai log dei processi Spark all'interno delle cartelle driver e gestione librerie
Nota
Per risolvere i problemi relativi ai processi Spark creati durante il wrangling dei dati interattivi in una sessione del notebook, selezionare Dettagli processo nell'angolo superiore destro dell'interfaccia utente del notebook. I processi Spark di una sessione interattiva del notebook vengono creati con il nome dell'esperimento notebook-runs.