Avvio rapido: Iniziare a usare il servizio Azure Machine Learning
SI APPLICA A:  Python SDK azure-ai-ml v2 (corrente)
Python SDK azure-ai-ml v2 (corrente)
Questa esercitazione offre un'introduzione ad alcune delle funzionalità più usate del servizio Azure Machine Learning. Verrà creato, registrato e distribuito un modello. Questa esercitazione consentirà di acquisire familiarità con i concetti di base di Azure Machine Learning e il relativo utilizzo più comune.
Si apprenderà come eseguire un processo di training in una risorsa di calcolo scalabile, quindi distribuirlo e infine testare la distribuzione.
Si creerà uno script di training per gestire la preparazione dei dati, eseguire il training e registrare un modello. Dopo aver eseguito il training del modello, lo si distribuirà come endpoint, quindi chiamare l'endpoint per l'inferenza.
I passaggi da eseguire sono:
- Configurare un handle per l'area di lavoro di Azure Machine Learning
- Creare lo script di training
- Creare una risorsa di calcolo scalabile, un cluster di calcolo
- Creare ed eseguire un processo di comando che eseguirà lo script di training nel cluster di calcolo configurato con l'ambiente di processo appropriato
- Visualizzare l'output dello script di training
- Distribuire il modello appena sottoposto a training come endpoint
- Chiamare l'endpoint di Azure Machine Learning per l'inferenza
Guardare questo video per una panoramica dei passaggi descritti in questa guida introduttiva.
Prerequisiti
-
Per usare Azure Machine Learning, è prima necessaria un'area di lavoro. Se non è disponibile, completare Creare risorse necessarie per iniziare a creare un'area di lavoro e altre informazioni sull'uso.
-
Accedere allo studio e selezionare l'area di lavoro se non è già aperta.
-
Aprire o creare un notebook nell'area di lavoro:
- Creare un nuovo notebook, se si vuole copiare/incollare il codice nelle celle.
- In alternativa, aprire tutorials/get-started-notebooks/quickstart.ipynb dalla sezione Samples di Studio. Selezionare quindi Clona per aggiungere il notebook ai file. Vedere dove trovare esempi.
Impostare il kernel
Nella barra superiore sopra il notebook aperto creare un'istanza di calcolo se non ne è già disponibile una.

Se l'istanza di calcolo viene arrestata, selezionare Avvia calcolo e attendere fino a quando non è in esecuzione.

Assicurarsi che il kernel, trovato in alto a destra, sia
Python 3.10 - SDK v2. In caso contrario, usare l'elenco a discesa per selezionare questo kernel.
Se viene visualizzato un banner che indica che è necessario eseguire l'autenticazione, selezionare Autentica.



Importante
Il resto di questa esercitazione contiene celle del notebook dell'esercitazione. Copia/incollali nel nuovo notebook o passa ora al notebook se è stato clonato.
Creare un handle nell'area di lavoro
Prima di approfondire il codice, è necessario un modo per fare riferimento all'area di lavoro. L'area di lavoro è la risorsa di primo livello per Azure Machine Learning, che fornisce una posizione centralizzata da cui gestire tutti gli artefatti creati quando si usa Azure Machine Learning.
Si creerà ml_client un handle per l'area di lavoro. Si userà ml_client quindi per gestire risorse e processi.
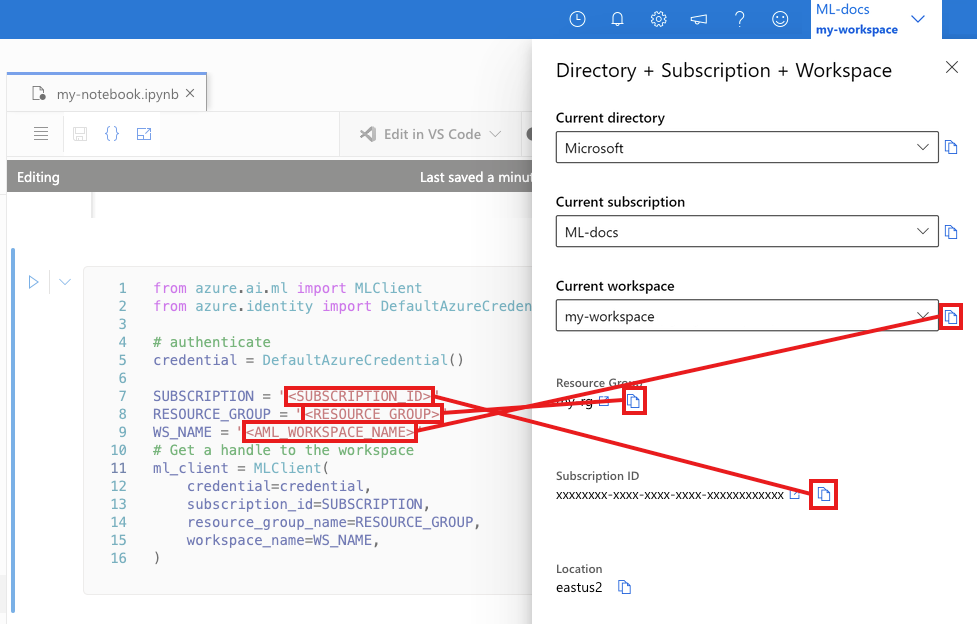
Nella cella successiva immettere l'ID sottoscrizione, il nome del gruppo di risorse e il nome dell'area di lavoro. Per trovare questi valori:
- Nella barra degli strumenti in alto a destra studio di Azure Machine Learning selezionare il nome dell'area di lavoro.
- Copiare il valore per l'area di lavoro, il gruppo di risorse e l'ID sottoscrizione nel codice.
- Sarà necessario copiare un valore, chiudere l'area e incollarlo, quindi tornare per quello successivo.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION="<SUBSCRIPTION_ID>"
RESOURCE_GROUP="<RESOURCE_GROUP>"
WS_NAME="<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Nota
La creazione di MLClient non si connetterà all'area di lavoro. L'inizializzazione del client è differita e attende per la prima volta che deve effettuare una chiamata (questa operazione verrà eseguita nella cella di codice successiva).
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location,":", ws.resource_group)
Creare uno script di training
Per iniziare, creare lo script di training, ovvero il file Python main.py .
Creare prima di tutto una cartella di origine per lo script:
import os
train_src_dir = "./src"
os.makedirs(train_src_dir, exist_ok=True)
Questo script gestisce la pre-elaborazione dei dati, suddividendoli in dati di test ed eseguirne il training. Usa quindi questi dati per eseguire il training di un modello basato su albero e restituire il modello di output.
MLFlow verrà usato per registrare i parametri e le metriche durante l'esecuzione della pipeline.
La cella seguente usa IPython magic per scrivere lo script di training nella directory appena creata.
%%writefile {train_src_dir}/main.py
import os
import argparse
import pandas as pd
import mlflow
import mlflow.sklearn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
###################
#<prepare the data>
###################
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
train_df, test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
####################
#</prepare the data>
####################
##################
#<train the model>
##################
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
###################
#</train the model>
###################
##########################
#<save and register model>
##########################
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.registered_model_name, "trained_model"),
)
###########################
#</save and register model>
###########################
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Come si può notare in questo script, una volta eseguito il training del modello, il file del modello viene salvato e registrato nell'area di lavoro. È ora possibile usare il modello registrato negli endpoint di inferenza.
Potrebbe essere necessario selezionare Aggiorna per visualizzare la nuova cartella e lo script nei file.
Configurare il comando
Ora che si dispone di uno script che può eseguire le attività desiderate e un cluster di calcolo per eseguire lo script, si userà un comando per utilizzo generico che può eseguire azioni della riga di comando. Questa azione della riga di comando può chiamare direttamente i comandi di sistema o eseguire uno script.
In questo caso si creeranno variabili di input per specificare i dati di input, il rapporto di divisione, la frequenza di apprendimento e il nome del modello registrato. Lo script di comando:
- Usare un ambiente che definisce le librerie software e di runtime necessarie per lo script di training. Azure Machine Learning offre molti ambienti curati o pronti, utili per scenari di training e inferenza comuni. In questo caso si userà uno di questi ambienti. In Esercitazione: Eseguire il training di un modello in Azure Machine Learning si apprenderà come creare un ambiente personalizzato.
- Configurare l'azione della riga di comando stessa
python main.py, in questo caso. Gli input/output sono accessibili nel comando tramite la${{ ... }}notazione . - In questo esempio si accede ai dati da un file su Internet.
- Poiché non è stata specificata una risorsa di calcolo, lo script verrà eseguito in un cluster di calcolo serverless creato automaticamente.
from azure.ai.ml import command
from azure.ai.ml import Input
registered_model_name = "credit_defaults_model"
job = command(
inputs=dict(
data=Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv",
),
test_train_ratio=0.2,
learning_rate=0.25,
registered_model_name=registered_model_name,
),
code="./src/", # location of source code
command="python main.py --data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} --learning_rate ${{inputs.learning_rate}} --registered_model_name ${{inputs.registered_model_name}}",
environment="AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest",
display_name="credit_default_prediction",
)
Inviare il processo
È ora possibile inviare il processo per l'esecuzione in Azure Machine Learning. Questa volta si userà create_or_update in ml_client.
ml_client.create_or_update(job)
Visualizzare l'output del processo e attendere il completamento del processo
Visualizzare il processo in studio di Azure Machine Learning selezionando il collegamento nell'output della cella precedente.
L'output di questo processo sarà simile al seguente nel studio di Azure Machine Learning. Esplorare le schede per vari dettagli, ad esempio metriche, output e così via. Al termine, il processo registrerà un modello nell'area di lavoro in seguito al training.
Importante
Attendere il completamento dello stato del processo prima di tornare a questo notebook per continuare. L'esecuzione del processo richiederà da 2 a 3 minuti. Potrebbero essere necessari più tempo (fino a 10 minuti) se il cluster di calcolo è stato ridotto a zero nodi e l'ambiente personalizzato è ancora in fase di compilazione.
Distribuire il modello come endpoint online
Distribuire ora il modello di Machine Learning come servizio Web nel cloud di Azure, un oggetto online endpoint.
Per distribuire un servizio di Machine Learning, si userà il modello registrato.
Creare un nuovo endpoint online
Ora che si dispone di un modello registrato, è possibile creare l'endpoint online. Il nome dell'endpoint deve essere univoco nell'intera area di Azure. Per questa esercitazione si creerà un nome univoco usando UUID.
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
Creare l'endpoint:
# Expect the endpoint creation to take a few minutes
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is an online endpoint",
auth_mode="key",
tags={
"training_dataset": "credit_defaults",
"model_type": "sklearn.GradientBoostingClassifier",
},
)
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
print(f"Endpoint {endpoint.name} provisioning state: {endpoint.provisioning_state}")
Nota
Si prevede che la creazione dell'endpoint richiederà alcuni minuti.
Dopo aver creato l'endpoint, è possibile recuperarlo come indicato di seguito:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpoint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)
Distribuire il modello nell'endpoint
Dopo aver creato l'endpoint, distribuire il modello con lo script di immissione. Ogni endpoint può avere più distribuzioni. È possibile specificare il traffico diretto a queste distribuzioni usando le regole. Verrà creata una singola distribuzione che gestisce il 100% del traffico in ingresso. È stato scelto un nome di colore per la distribuzione, ad esempio blu, verde, distribuzioni rosse, che è arbitrario.
È possibile controllare la pagina Modelli in studio di Azure Machine Learning per identificare la versione più recente del modello registrato. In alternativa, il codice seguente recupererà il numero di versione più recente da usare.
# Let's pick the latest version of the model
latest_model_version = max(
[int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(f'Latest model is version "{latest_model_version}" ')
Distribuire la versione più recente del modello.
# picking the model to deploy. Here we use the latest version of our registered model
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# Expect this deployment to take approximately 6 to 8 minutes.
# create an online deployment.
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.
# Learn more on https://azure.microsoft.com/pricing/details/machine-learning/.
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()
Nota
Si prevede che la distribuzione richiede circa 6-8 minuti.
Al termine della distribuzione, si è pronti per testarlo.
Eseguire test con una query di esempio
Dopo aver distribuito il modello nell'endpoint, è possibile eseguire l'inferenza con essa.
Creare un file di richiesta di esempio seguendo la progettazione prevista nel metodo run nello script del punteggio.
deploy_dir = "./deploy"
os.makedirs(deploy_dir, exist_ok=True)
%%writefile {deploy_dir}/sample-request.json
{
"input_data": {
"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],
"index": [0, 1],
"data": [
[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]
]
}
}
# test the blue deployment with some sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./deploy/sample-request.json",
deployment_name="blue",
)
Pulire le risorse
Se non si intende usare l'endpoint, eliminarlo per interrompere l'uso della risorsa. Assicurarsi che nessun'altra distribuzione usi un endpoint prima di eliminarla.
Nota
L'eliminazione completa richiede circa 20 minuti.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)
Arrestare l'istanza di calcolo
Se non si intende usarlo ora, arrestare l'istanza di calcolo:
- Nello studio, nell'area di spostamento a sinistra selezionare Calcolo.
- Nelle schede superiori selezionare Istanze di calcolo
- Selezionare l'istanza di calcolo nell'elenco.
- Sulla barra degli strumenti superiore selezionare Arresta.
Eliminare tutte le risorse
Importante
Le risorse create possono essere usate come prerequisiti per altre esercitazioni e procedure dettagliate per Azure Machine Learning.
Se non si prevede di usare alcuna delle risorse create, eliminarle in modo da non sostenere alcun addebito:
Nel portale di Azure fare clic su Gruppi di risorse all'estrema sinistra.
Nell'elenco selezionare il gruppo di risorse creato.
Selezionare Elimina gruppo di risorse.
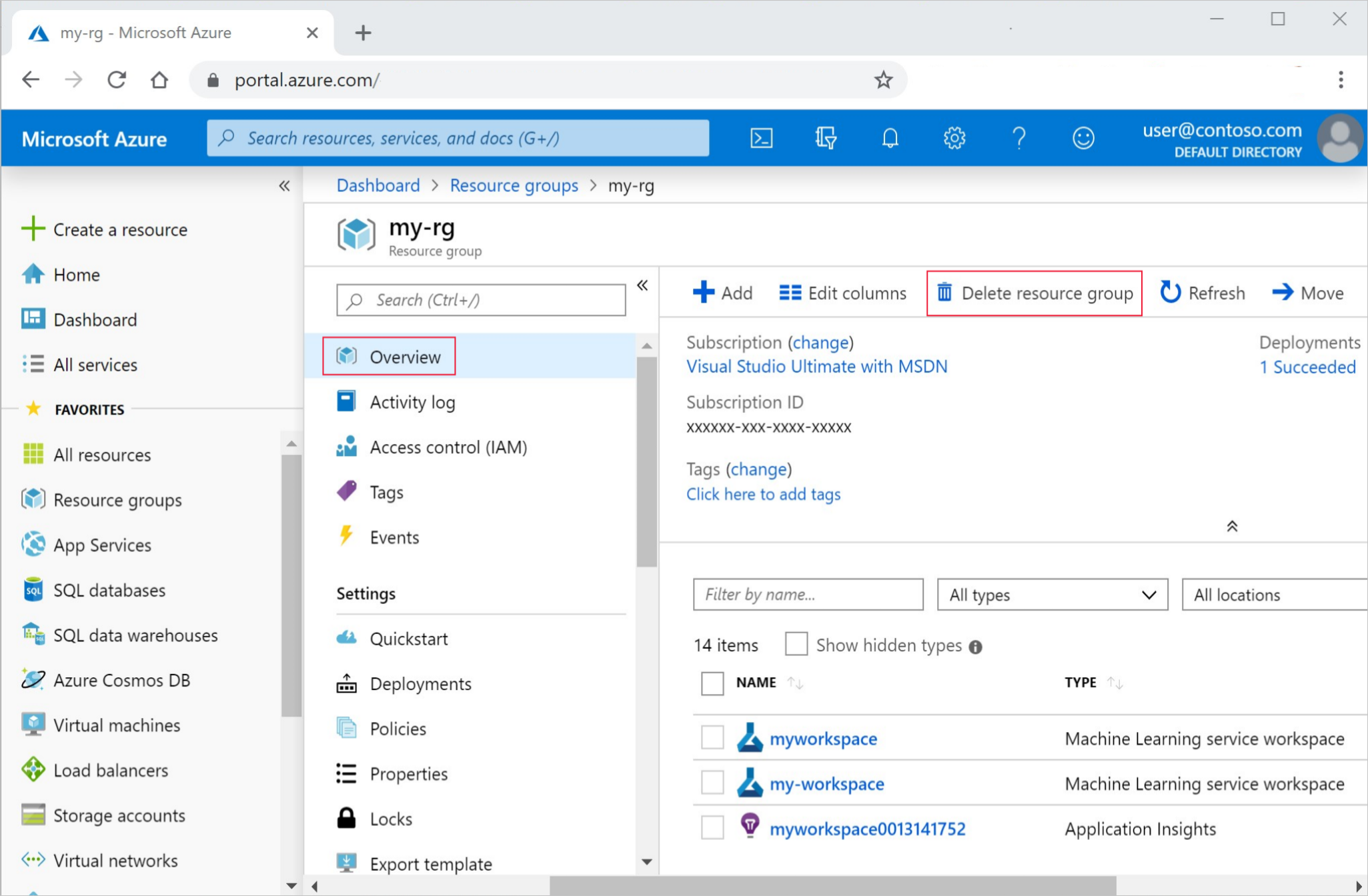
Immettere il nome del gruppo di risorse. Quindi seleziona Elimina.
Passaggi successivi
Ora che si ha un'idea di ciò che è coinvolto nel training e nella distribuzione di un modello, vedere altre informazioni sul processo in queste esercitazioni:
| Esercitazione | Descrizione |
|---|---|
| Caricare, accedere ed esplorare i dati in Azure Machine Learning | Archiviare dati di grandi dimensioni nel cloud e recuperarli da notebook e script |
| Sviluppo di modelli in una workstation cloud | Avviare la creazione di prototipi e sviluppare modelli di Machine Learning |
| Eseguire il training di un modello in Azure Machine Learning | Esaminare i dettagli del training di un modello |
| Distribuire un modello come endpoint online | Informazioni dettagliate sulla distribuzione di un modello |
| Creare pipeline di Machine Learning di produzione | Suddividere un'attività di Machine Learning completa in un flusso di lavoro a più passaggi. |