Descrivere un cluster di Service Fabric usando Cluster Resource Manager
La funzionalità Cluster Resource Manager di Azure Service Fabric offre diversi meccanismi per descrivere un cluster:
- Domini di errore
- Domini di aggiornamento
- Proprietà del nodo
- Capacità del nodo
Durante il runtime Cluster Resource Manager usa queste informazioni per garantire la disponibilità elevata dei servizi in esecuzione nel cluster. Applicando queste regole importanti, tenta anche di ottimizzare l'utilizzo delle risorse all'interno del cluster.
Domini di errore
Un dominio di errore (FD, Fault Domain) è un'area di errore coordinato. Un singolo computer è un dominio di errore. Può non riuscire autonomamente per vari motivi, dagli errori di alimentazione agli errori di unità al firmware NIC non valido.
I computer connessi allo stesso commutatore Ethernet si trovano nello stesso dominio di errore. Si tratta quindi di computer che condividono una singola fonte di alimentazione o in un'unica posizione.
Poiché è naturale che gli errori hardware si sovrappongano, i domini di errore sono intrinsecamente gerarchici. Sono rappresentati come URI in Service Fabric.
È importante che i domini di errore siano configurati correttamente perché Service Fabric usa queste informazioni per posizionare i servizi in modo sicuro. Service Fabric non vuole inserire servizi in modo che la perdita di un dominio di errore (causato dall'errore di un componente) causi un arresto di un servizio.
Nell'ambiente di Azure Service Fabric usa le informazioni sul dominio di errore fornite dall'ambiente per configurare correttamente i nodi nel cluster per conto dell'utente. Per le istanze autonome di Service Fabric, i domini di errore vengono definiti al momento della configurazione del cluster.
Avviso
È importante che le informazioni sul dominio di errore fornite a Service Fabric siano accurate. Si supponga, ad esempio, che i nodi del cluster di Service Fabric siano in esecuzione all'interno di 10 macchine virtuali, in esecuzione in 5 host fisici. In questo caso, anche se sono presenti 10 macchine virtuali, sono presenti solo 5 domini di errore diversi (livello superiore). La condivisione dello stesso host fisico fa sì che le macchine virtuali condividano lo stesso dominio di errore radice, perché le macchine virtuali riscontrano un errore coordinato se l'host fisico non riesce.
Service Fabric prevede che il dominio di errore di un nodo non venga modificato. Altri meccanismi per garantire la disponibilità elevata delle macchine virtuali, ad esempio le macchine virtuali a disponibilità elevata, potrebbero causare conflitti con Service Fabric. Questi meccanismi usano la migrazione trasparente delle macchine virtuali da un host a un altro. Non riconfigurano o notificano il codice in esecuzione all'interno della macchina virtuale. Di conseguenza, non sono supportati come ambienti per l'esecuzione di cluster di Service Fabric.
Service Fabric deve essere l'unica tecnologia di disponibilità elevata in uso. Non sono necessari meccanismi come la migrazione di macchine virtuali in tempo reale e le reti SAN. Se questi meccanismi vengono usati insieme a Service Fabric, riducono la disponibilità e l'affidabilità delle applicazioni. Il motivo è che introducono complessità aggiuntive, aggiungono origini centralizzate di errore e usano strategie di affidabilità e disponibilità in conflitto con quelle in Service Fabric.
Nell'immagine seguente vengono colorare tutte le entità che contribuiscono ai domini di errore ed elencare tutti i diversi domini di errore risultanti. In questo esempio sono presenti data center ("DC"), rack ("R") e pannelli ("B"). Se ogni pannello contiene più di una macchina virtuale, potrebbe essere presente un altro livello nella gerarchia del dominio di errore.
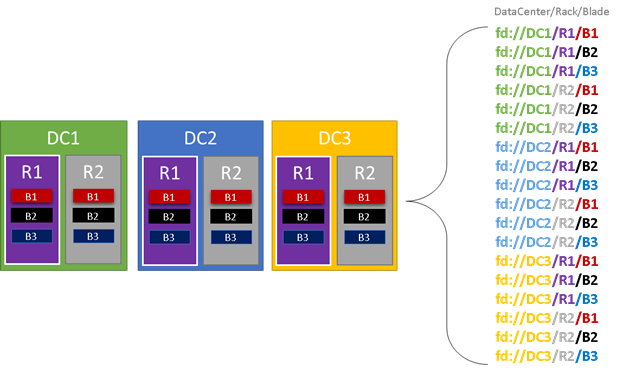
Durante il runtime, Cluster Resource Manager di Service Fabric considera i domini di errore nei layout del cluster e dei piani. Le repliche con stato o le istanze senza stato per un servizio vengono distribuite in modo che si trovino in domini di errore separati. La distribuzione del servizio tra domini di errore garantisce che la disponibilità del servizio non sia compromessa quando un dominio di errore non riesce a qualsiasi livello della gerarchia.
Cluster Resource Manager non interessa il numero di livelli presenti nella gerarchia del dominio di errore. Tenta di assicurarsi che la perdita di una parte della gerarchia non influisca sui servizi in esecuzione.
È preferibile se lo stesso numero di nodi è a ogni livello di profondità nella gerarchia del dominio di errore. Se l'albero dei domini di errore è sbilanciato nel cluster, è più difficile per Cluster Resource Manager determinare l'allocazione ottimale dei servizi. Layout di dominio di errore sbilanciati indicano che la perdita di alcuni domini influisce sulla disponibilità dei servizi più di altri domini. Di conseguenza, Cluster Resource Manager è diviso tra due obiettivi:
- Vuole usare i computer in quel dominio "pesante" posizionando i servizi su di essi.
- Vuole inserire servizi in altri domini in modo che la perdita di un dominio non causi problemi.
Come appaiono i domini sbilanciati? Il diagramma seguente illustra due diversi layout del cluster. Nel primo esempio i nodi vengono distribuiti uniformemente tra i domini di errore. Nel secondo esempio, un dominio di errore ha molti più nodi rispetto agli altri domini di errore.
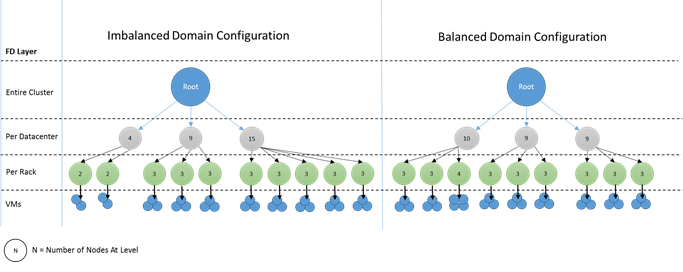
In Azure la scelta del dominio di errore che contiene un nodo viene gestita. Tuttavia, a seconda del numero di nodi di cui si effettua il provisioning, è comunque possibile finire con domini di errore con più nodi in essi contenuti rispetto ad altri.
Si supponga, ad esempio, di avere cinque domini di errore nel cluster, ma effettuare il provisioning di sette nodi per un tipo di nodo (NodeType). In questo caso, i primi due domini di errore finiscono con più nodi. Se si continua a distribuire più istanze NodeType con solo un paio di istanze, il problema peggiora. Per questo motivo, è consigliabile che il numero di nodi in ogni tipo di nodo sia un multiplo del numero di domini di errore.
Domini di aggiornamento
I domini di aggiornamento sono un'altra funzionalità che consente a Cluster Resource Manager di Service Fabric di comprendere il layout del cluster. I domini di aggiornamento definiscono set di nodi aggiornati contemporaneamente. I domini di aggiornamento consentono a Cluster Resource Manager di comprendere e orchestrare operazioni di gestione come gli aggiornamenti.
I domini di aggiornamento sono molto simili ai domini di errore, ma con un paio di differenze chiave. Prima di tutto, le aree di errori hardware coordinati definiscono i domini di errore. I domini di aggiornamento, d'altra parte, sono definiti dai criteri. È possibile decidere il numero desiderato, invece di lasciare che l'ambiente determini il numero. È possibile avere un numero di domini di aggiornamento quanti sono i nodi. Un'altra differenza tra domini di errore e domini di aggiornamento è che i domini di aggiornamento non sono gerarchici. Sono invece più simili a un semplice tag.
Il diagramma seguente mostra tre domini di aggiornamento con striping in tre domini di errore. Mostra anche un posizionamento possibile per tre repliche diverse di un servizio con stato, in cui ognuno si trova in domini di errore e di aggiornamento diversi. Questo posizionamento consente la perdita di un dominio di errore durante l'aggiornamento di un servizio e ha ancora una copia del codice e dei dati.
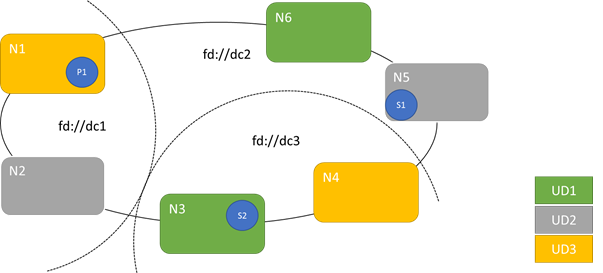
Esistono vantaggi e svantaggi per avere un numero elevato di domini di aggiornamento. Più domini di aggiornamento indicano che ogni passaggio dell'aggiornamento è più granulare e influisce su un numero minore di nodi o servizi. Meno servizi devono spostarsi alla volta, introducendo meno varianza nel sistema. Ciò tende a migliorare l'affidabilità, perché meno del servizio è interessato da qualsiasi problema introdotto durante l'aggiornamento. Altri domini di aggiornamento indicano anche che è necessario un buffer meno disponibile in altri nodi per gestire l'impatto dell'aggiornamento.
Ad esempio, se sono presenti cinque domini di aggiornamento, i nodi in ognuno gestiscono circa il 20% del traffico. Se è necessario arrestare il dominio di aggiornamento per un aggiornamento, il carico deve in genere andare da qualche parte. Poiché sono presenti quattro domini di aggiornamento rimanenti, ognuno deve avere spazio per circa il 25% del traffico totale. Più domini di aggiornamento indicano che è necessario meno buffer nei nodi del cluster.
Si consideri invece se si dispone di 10 domini di aggiornamento. In tal caso, ogni dominio di aggiornamento gestirà solo il 10% del traffico totale. Quando un aggiornamento passa attraverso il cluster, ogni dominio deve avere spazio solo per circa il 11% del traffico totale. Più domini di aggiornamento consentono in genere di eseguire i nodi a un utilizzo più elevato, perché è necessaria una capacità meno riservata. Lo stesso vale per i domini di errore.
Lo svantaggio di avere molti domini di aggiornamento è che gli aggiornamenti tendono a richiedere più tempo. Service Fabric attende un breve periodo dopo il completamento di un dominio di aggiornamento ed esegue i controlli prima di iniziare a aggiornare quello successivo. Questi ritardi consentono di rilevare i problemi introdotti in seguito all'aggiornamento prima che l'aggiornamento continui. Questo compromesso è accettabile perché evita che modifiche non valide abbiano un impatto eccessivo sul servizio in un determinato momento.
La presenza di troppi domini di aggiornamento ha molti effetti collaterali negativi. Mentre ogni dominio di aggiornamento è inattivo e viene aggiornato, una grande parte della capacità complessiva non è disponibile. Se, ad esempio, si hanno solo tre domini di aggiornamento, si arresta circa un terzo della capacità complessiva del servizio o del cluster alla volta. Non è consigliabile avere così tanta parte del servizio inattivo in una sola volta perché è necessaria una capacità sufficiente nel resto del cluster per gestire il carico di lavoro. La gestione del buffer significa che durante il normale funzionamento, tali nodi sono meno caricati di quanto altrimenti. Questo approccio implica un aumento del costo di esecuzione del servizio.
Non è previsto alcun limite effettivo per il numero totale di domini di errore o di aggiornamento in un ambiente e non sono previsti vincoli per le relative sovrapposizioni. Esistono tuttavia modelli comuni:
- Domini di errore e domini di aggiornamento mappati 1:1
- Un dominio di aggiornamento per nodo (istanza fisica o virtuale del sistema operativo)
- Modello "con striping" o "matrice" in cui i domini di errore e i domini di aggiornamento formano una matrice con i computer che in genere eseguono le diagonali
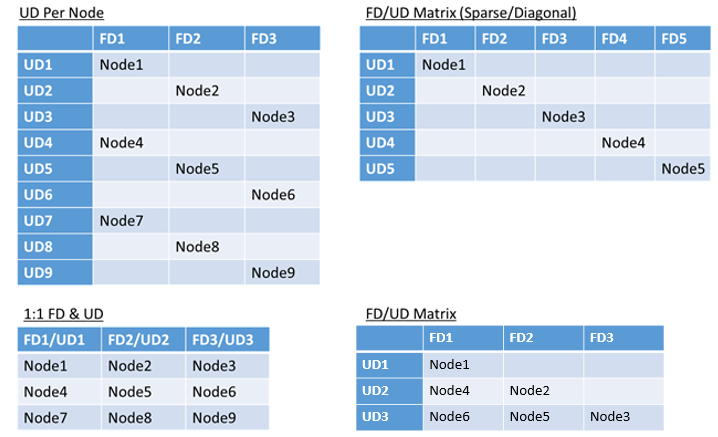
Non c'è una risposta migliore per quale layout scegliere. Ognuna presenta vantaggi e svantaggi. Ad esempio, il modello di tipo 1FD:1UD è semplice da configurare. Il modello di un dominio di aggiornamento per ogni modello di nodo è più simile a quello usato dagli utenti. Durante gli aggiornamenti, ogni nodo viene aggiornato in modo indipendente. È simile alla modalità con la quale un piccolo gruppo di computer veniva aggiornato manualmente in passato.
Il modello più comune è la matrice FD/UD, in cui i domini di errore e i domini di aggiornamento formano una tabella e i nodi vengono posizionati a partire dalla diagonale. È il modello usato per impostazione predefinita nei cluster di Service Fabric in Azure. Per i cluster con molti nodi, tutto sembra simile a un modello di matrice densa.
Nota
I cluster di Service Fabric ospitati in Azure non supportano la modifica della strategia predefinita. Solo i cluster autonomi offrono tale personalizzazione.
Vincoli del dominio di errore e di aggiornamento e comportamento risultante
Approccio predefinito
Per impostazione predefinita, Cluster Resource Manager mantiene bilanciati i servizi tra domini di errore e di aggiornamento. Tale equilibrio è modellato come un vincolo. Il vincolo per i domini di errore e di aggiornamento indica: "Per una determinata partizione del servizio, non deve mai esserci una differenza maggiore di uno nel numero di oggetti servizio (istanze del servizio senza stato o repliche del servizio con stato) tra due domini nello stesso livello di gerarchia".
Si supponga che questo vincolo fornisca una garanzia di "differenza massima". Il vincolo per i domini di errore e di aggiornamento impedisce determinati spostamenti o disposizioni che violano la regola.
Si supponga, ad esempio, di avere un cluster con sei nodi, configurato con cinque domini di errore e cinque domini di aggiornamento.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | ||||
| UD1 | N6 | N2 | |||
| UD2 | N3 | ||||
| UD3 | N4 | ||||
| UD4 | N5 |
Si supponga ora di creare un servizio con un valore TargetReplicaSetSize (o, per un servizio senza stato, InstanceCount) di cinque. Le repliche avvengono in N1 N5. N6 non verrà mai usato indipendentemente dal numero di servizi simili creati. Ma perché? Esaminiamo la differenza tra il layout corrente e ciò che accadrebbe se si scegliesse N6.
Ecco il layout ottenuto e il numero totale di repliche per dominio di errore e aggiornamento:
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R2 | 1 | ||||
| UD2 | R3 | 1 | ||||
| UD3 | R4 | 1 | ||||
| UD4 | R5 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Questo layout è bilanciato in termini di nodi per dominio di errore e dominio di aggiornamento. È anche bilanciato in termini di numero di repliche per ogni dominio di errore e aggiornamento. Ogni dominio ha lo stesso numero di nodi e lo stesso numero di repliche.
A questo punto vediamo cosa accadrebbe se usassimo N6 invece di N2. Come sarebbero state distribuite le repliche?
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R5 | 1 | ||||
| UD2 | R2 | 1 | ||||
| UD3 | R3 | 1 | ||||
| UD4 | R4 | 1 | ||||
| FDTotal | 2 | 0 | 1 | 1 | 1 | - |
Questo layout viola la definizione della garanzia "differenza massima" per il vincolo di dominio di errore. FD0 ha due repliche, mentre FD1 ha zero. La differenza tra FD0 e FD1 è un totale di due, che è maggiore della differenza massima di uno. Poiché il vincolo viene violato, Cluster Resource Manager non consente questa disposizione.
Analogamente, se abbiamo scelto N2 e N6 (invece di N1 e N2), otterremo:
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | 0 | |||||
| UD1 | R5 | R1 | 2 | |||
| UD2 | R2 | 1 | ||||
| UD3 | R3 | 1 | ||||
| UD4 | R4 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Questo layout è bilanciato in termini di domini di errore. Ma ora viola il vincolo di dominio di aggiornamento, perché UD0 ha zero repliche e UD1 ha due. Questo layout non è valido e non verrà selezionato da Cluster Resource Manager.
Questo approccio alla distribuzione delle repliche con stato o delle istanze senza stato offre la migliore tolleranza di errore possibile. Se un dominio diventa inattivo, viene perso il numero minimo di repliche/istanze.
D'altro canto, questo approccio può essere troppo limitato e non consentire al cluster di usare tutte le risorse. Per determinate configurazioni del cluster non è possibile usare alcuni nodi. In questo modo Service Fabric non inserisce i servizi, generando messaggi di avviso. Nell'esempio precedente alcuni nodi del cluster non possono essere usati (N6 nell'esempio). Anche se sono stati aggiunti nodi a tale cluster (N7-N10), le repliche/istanze vengono posizionate solo su N1-N5 a causa di vincoli sui domini di errore e di aggiornamento.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | N10 | |||
| UD1 | N6 | N2 | |||
| UD2 | N7 | N3 | |||
| UD3 | N8 | N4 | |||
| UD4 | N9 | N5 |
Approccio alternativo
Cluster Resource Manager supporta un'altra versione del vincolo per i domini di errore e di aggiornamento. Consente il posizionamento garantendo comunque un livello minimo di sicurezza. Il vincolo alternativo può essere indicato come segue: "Per una determinata partizione del servizio, la distribuzione della replica tra domini deve garantire che la partizione non subisca una perdita di quorum". Si supponga che questo vincolo fornisca una garanzia "quorum sicura".
Nota
In un servizio con stato si parla di perdita del quorum in una situazione in cui la maggioranza delle repliche di partizione è contemporaneamente inattiva. Ad esempio, se TargetReplicaSetSize è cinque, un set di tre repliche rappresenta il quorum. Analogamente, se TargetReplicaSetSize è sei, per il quorum sono necessarie quattro repliche. In entrambi i casi, non più di due repliche possono essere disattivate contemporaneamente se la partizione vuole continuare a funzionare normalmente.
Per un servizio senza stato, non esiste alcuna perdita di quorum. I servizi senza stato continuano a funzionare normalmente anche se la maggior parte delle istanze si arresta contemporaneamente. Quindi, ci concentreremo sui servizi con stato nel resto di questo articolo.
Tornare all'esempio precedente. Con la versione "quorum safe" del vincolo, tutti e tre i layout sarebbero validi. Anche se FD0 non è riuscito nel secondo layout o UD1 non è riuscito nel terzo layout, la partizione avrebbe comunque un quorum. La maggior parte delle repliche è ancora in funzione. Con questa versione del vincolo, N6 può quasi sempre essere utilizzato.
L'approccio "quorum safe" offre maggiore flessibilità rispetto all'approccio "differenza massima". Il motivo è che è più facile trovare le distribuzioni di replica valide in quasi tutte le topologie del cluster. Tuttavia, questo approccio non garantisce le caratteristiche di tolleranza di errore migliori perché alcuni errori sono più gravi di altri.
Nello scenario peggiore, la maggior parte delle repliche può essere persa con l'errore di un dominio e una replica aggiuntiva. Ad esempio, invece di tre errori necessari per perdere il quorum con cinque repliche o istanze, è ora possibile perdere una maggioranza con soli due errori.
Approccio adattivo
Poiché entrambi gli approcci hanno punti di forza e punti deboli, è stato introdotto un approccio adattivo che combina queste due strategie.
Nota
Questo è il comportamento predefinito a partire da Service Fabric versione 6.2.
L'approccio adattivo usa la logica della "differenza massima" per impostazione predefinita, per passare alla logica di "sicurezza del quorum" solo quando necessario. Cluster Resource Manager determina automaticamente quale strategia è necessaria esaminando il modo in cui vengono configurati i servizi e il cluster.
Cluster Resource Manager deve usare la logica "basata su quorum" per un servizio, entrambe queste condizioni sono vere:
- TargetReplicaSetSize per il servizio è divisibile in modo uniforme in base al numero di domini di errore e al numero di domini di aggiornamento.
- Il numero di nodi è minore o uguale al numero di domini di errore moltiplicati per il numero di domini di aggiornamento.
Tenere presente che Cluster Resource Manager userà questo approccio sia per i servizi senza stato che per i servizi con stato, anche se la perdita del quorum non è rilevante per i servizi senza stato.
Tornare all'esempio precedente e presupporre che un cluster abbia ora otto nodi. Il cluster è ancora configurato con cinque domini di errore e cinque domini di aggiornamento e il valore TargetReplicaSetSize di un servizio ospitato in tale cluster rimane cinque.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | ||||
| UD1 | N6 | N2 | |||
| UD2 | N7 | N3 | |||
| UD3 | N8 | N4 | |||
| UD4 | N5 |
Poiché tutte le condizioni necessarie sono soddisfatte, Cluster Resource Manager userà la logica "basata sul quorum" per distribuire il servizio. Ciò consente l'utilizzo di N6-N8. Una possibile distribuzione del servizio in questo caso potrebbe essere simile alla seguente:
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R2 | 1 | ||||
| UD2 | R3 | R4 | 2 | |||
| UD3 | 0 | |||||
| UD4 | R5 | 1 | ||||
| FDTotal | 2 | 1 | 1 | 0 | 1 | - |
Se il valore TargetReplicaSetSize del servizio viene ridotto a quattro (ad esempio), Cluster Resource Manager noterà che cambia. Riprenderà a usare la logica "differenza massima" perché TargetReplicaSetSize non è più diviso per il numero di domini di errore e domini di aggiornamento. Di conseguenza, alcuni spostamenti di replica si verificheranno per distribuire le quattro repliche rimanenti nei nodi N1-N5. In questo modo, la versione "differenza massima" del dominio di errore e la logica del dominio di aggiornamento non viene violata.
Nel layout precedente, se il valore TargetReplicaSetSize è cinque e N1 viene rimosso dal cluster, il numero di domini di aggiornamento diventa uguale a quattro. Anche in questo caso, Cluster Resource Manager inizia a usare la logica "differenza massima" perché il numero di domini di aggiornamento non divide più il valore TargetReplicaSetSize del servizio. Di conseguenza, replica R1, quando viene compilata di nuovo, deve atterrare su N4 in modo che il vincolo per il dominio di errore e di aggiornamento non venga violato.
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | N/D | N/D | N/D | N/D | N/D | N/D |
| UD1 | R2 | 1 | ||||
| UD2 | R3 | R4 | 2 | |||
| UD3 | R1 | 1 | ||||
| UD4 | R5 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Configurazione di domini di errore e di aggiornamento
Nelle distribuzioni di Service Fabric ospitate in Azure, i domini di errore e i domini di aggiornamento vengono definiti automaticamente. Service Fabric recupera semplicemente le informazioni sull'ambiente da Azure e le usa.
Se si sta creando un cluster personalizzato (o si vuole eseguire una particolare topologia in fase di sviluppo), è possibile fornire manualmente le informazioni sul dominio di errore e sull'aggiornamento del dominio. In questo esempio viene definito un cluster di sviluppo locale a nove nodi che si estende su tre data center (ognuno con tre rack). Questo cluster include anche tre domini di aggiornamento con striping tra questi tre data center. Ecco un esempio della configurazione in ClusterManifest.xml:
<Infrastructure>
<!-- IsScaleMin indicates that this cluster runs on one box/one single server -->
<WindowsServer IsScaleMin="true">
<NodeList>
<Node NodeName="Node01" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType01" FaultDomain="fd:/DC01/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node02" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType02" FaultDomain="fd:/DC01/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node03" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType03" FaultDomain="fd:/DC01/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
<Node NodeName="Node04" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType04" FaultDomain="fd:/DC02/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node05" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType05" FaultDomain="fd:/DC02/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node06" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType06" FaultDomain="fd:/DC02/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
<Node NodeName="Node07" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType07" FaultDomain="fd:/DC03/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node08" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType08" FaultDomain="fd:/DC03/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node09" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType09" FaultDomain="fd:/DC03/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
</NodeList>
</WindowsServer>
</Infrastructure>
Questo esempio usa ClusterConfig.json per le distribuzioni autonome:
"nodes": [
{
"nodeName": "vm1",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm2",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm3",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD3"
},
{
"nodeName": "vm4",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm5",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm6",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD3"
},
{
"nodeName": "vm7",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm8",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm9",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD3"
}
],
Nota
Quando si definiscono i cluster tramite Azure Resource Manager, Azure assegna domini di errore e domini di aggiornamento. La definizione dei tipi di nodo e dei set di scalabilità di macchine virtuali nel modello di Azure Resource Manager non include quindi informazioni sul dominio di errore o sul dominio di aggiornamento.
Proprietà dei nodi e vincoli di posizionamento
In alcuni casi, infatti, nella maggior parte dei casi, è consigliabile assicurarsi che determinati carichi di lavoro vengano eseguiti solo in determinati tipi di nodi del cluster. Ad esempio, alcuni carichi di lavoro potrebbero richiedere GPU o UNITÀ SSD e altri potrebbero non essere disponibili.
Un ottimo esempio di destinazione dell'hardware a carichi di lavoro specifici è quasi ogni architettura a più livelli. Alcuni computer fungono da lato front-end o api dell'applicazione e vengono esposti ai client o a Internet. Altri computer, spesso con risorse hardware diverse, gestiscono il lavoro dei livelli di calcolo o archiviazione. In genere non sono esposti direttamente a Internet o ai client.
Service Fabric prevede che in alcuni casi potrebbero essere necessari carichi di lavoro specifici per l'esecuzione in configurazioni hardware specifiche. Ad esempio:
- Un'applicazione a più livelli esistente è stata "rimossa e spostata" in un ambiente di Service Fabric.
- Un carico di lavoro deve essere eseguito su hardware specifico per motivi di prestazioni, scalabilità o isolamento della sicurezza.
- Un carico di lavoro deve essere isolato da altri carichi di lavoro per motivi di utilizzo di criteri o risorse.
Per supportare questi tipi di configurazioni, Service Fabric include tag che è possibile applicare ai nodi. Questi tag vengono chiamati proprietà del nodo. I vincoli di posizionamento sono le istruzioni associate ai singoli servizi selezionati per una o più proprietà del nodo. Definiscono la posizione in cui i servizi devono essere eseguiti. Il set di vincoli è estendibile. Qualsiasi coppia chiave/valore può funzionare.
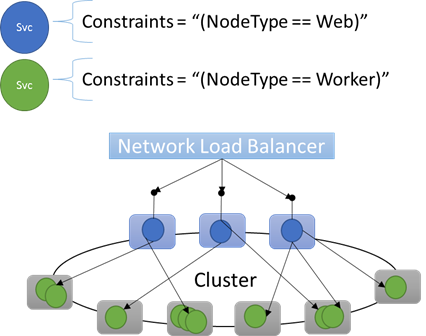
Proprietà predefinite dei nodi
Service Fabric definisce alcune proprietà predefinite del nodo che possono essere usate automaticamente, quindi non è necessario definirle. Le proprietà predefinite definite in ogni nodo sono NodeType e NodeName.
Ad esempio, è possibile scrivere un vincolo di posizionamento come "(NodeType == NodeType03)". NodeType è una proprietà di uso comune. È utile perché corrisponde a 1:1 con un tipo di computer. Ogni tipo di computer corrisponde a un tipo di carico di lavoro in un'applicazione tradizionale a più livelli.
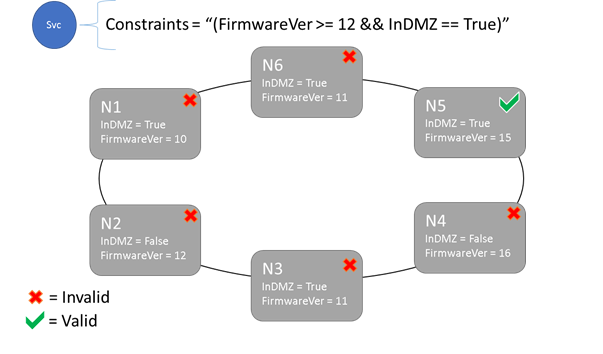
Vincoli di posizionamento e sintassi delle proprietà del nodo
Il valore specificato nella proprietà node può essere una stringa, un valore booleano o un valore long con segno. L'istruzione nel servizio è denominata vincolo di posizionamento perché vincola la posizione in cui il servizio può essere eseguito nel cluster. Il vincolo può essere qualsiasi istruzione booleana che opera sulle proprietà del nodo nel cluster. I selettori validi in queste istruzioni booleane sono:
Controlli condizionali per la creazione di istruzioni specifiche:
Istruzione Sintassi "uguale a" "==" "diverso da" "!=" "maggiore di" ">" "maggiore o uguale a" ">=" "minore di" "<" "minore o uguale a" "<=" Istruzioni booleane per operazioni logiche e di raggruppamento:
Istruzione Sintassi "and" "&&" "or" "||" "not" "!" "raggruppamento come singola istruzione" "()"
Ecco alcuni esempi di istruzioni di vincolo di base:
"Value >= 5""NodeColor != green""((OneProperty < 100) || ((AnotherProperty == false) && (OneProperty >= 100)))"
È possibile posizionare il servizio solo sui nodi in cui l'istruzione del vincolo di posizionamento generale restituisce "True". I nodi che non dispongono di una proprietà definita non corrispondono ad alcun vincolo di posizionamento che contiene la proprietà .
Si supponga che le proprietà del nodo seguenti siano state definite per un tipo di nodo in ClusterManifest.xml:
<NodeType Name="NodeType01">
<PlacementProperties>
<Property Name="HasSSD" Value="true"/>
<Property Name="NodeColor" Value="green"/>
<Property Name="SomeProperty" Value="5"/>
</PlacementProperties>
</NodeType>
L'esempio seguente mostra le proprietà del nodo definite tramite ClusterConfig.json per le distribuzioni autonome o Template.json per i cluster ospitati in Azure.
Nota
Nel modello di Azure Resource Manager il tipo di nodo viene in genere parametrizzato. Sembra "[parameters('vmNodeType1Name')]" piuttosto che NodeType01.
"nodeTypes": [
{
"name": "NodeType01",
"placementProperties": {
"HasSSD": "true",
"NodeColor": "green",
"SomeProperty": "5"
},
}
],
È possibile creare vincoli di posizionamento del servizio per un servizio come indicato di seguito:
FabricClient fabricClient = new FabricClient();
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
serviceDescription.PlacementConstraints = "(HasSSD == true && SomeProperty >= 4)";
// Add other required ServiceDescription fields
//...
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceType -Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton -PlacementConstraint "HasSSD == true && SomeProperty >= 4"
Se tutti i nodi di NodeType01 sono validi, è anche possibile selezionare il tipo di nodo con il vincolo "(NodeType == NodeType01)".
I vincoli di posizionamento di un servizio possono essere aggiornati dinamicamente durante il runtime. Se è necessario, è possibile spostare un servizio nel cluster, aggiungere e rimuovere i requisiti e così via. Service Fabric garantisce che il servizio rimanga attivo e disponibile anche quando vengono apportate queste modifiche.
StatefulServiceUpdateDescription updateDescription = new StatefulServiceUpdateDescription();
updateDescription.PlacementConstraints = "NodeType == NodeType01";
await fabricClient.ServiceManager.UpdateServiceAsync(new Uri("fabric:/app/service"), updateDescription);
Update-ServiceFabricService -Stateful -ServiceName $serviceName -PlacementConstraints "NodeType == NodeType01"
I vincoli di posizionamento vengono specificati per ogni istanza del servizio denominata. Gli aggiornamenti sostituiscono (sovrascrivono) sempre quanto specificato in precedenza.
La definizione del cluster definisce le proprietà in un nodo. La modifica delle proprietà di un nodo richiede un aggiornamento alla configurazione del cluster. L'aggiornamento delle proprietà di un nodo richiede che ogni nodo in questione venga riavviato per segnalare le nuove proprietà. Service Fabric gestisce questi aggiornamenti in sequenza.
Descrizione e gestione delle risorse del cluster
Uno dei processi più importanti di un agente di orchestrazione consiste nel semplificare la gestione dell'utilizzo delle risorse del cluster. Gestione delle risorse del cluster può avere significati diversi.
Innanzitutto, è necessario verificare che i computer non siano sovraccarichi, ovvero che non eseguano più servizi di quanti ne possano gestire.
In secondo luogo, c'è bilanciamento e ottimizzazione, che sono fondamentali per l'esecuzione efficiente dei servizi. Le offerte di servizi convenienti o sensibili alle prestazioni non possono consentire l'accesso frequente ad alcuni nodi, mentre altri sono a freddo. I nodi ad accesso frequente comportano conflitti di risorse e prestazioni scarse. I nodi ad accesso sporadico rappresentano risorse sprecate e costi maggiori.
Service Fabric rappresenta le risorse come metriche. Per metrica si intende qualsiasi risorsa logica o fisica che deve essere descritta per Service Fabric, Esempi di metriche sono "WorkQueueDepth" o "MemoryInMb". Per informazioni sulle risorse fisiche che Service Fabric può gestire nei nodi, vedere Governance delle risorse. Per informazioni sulle metriche predefinite usate da Cluster Resource Manager e su come configurare le metriche personalizzate, vedere questo articolo.
Le metriche sono diverse dai vincoli di posizionamento e dalle proprietà dei nodi. Le proprietà dei nodi sono descrittori statici dei nodi stessi. Le metriche descrivono le risorse che i nodi hanno e che i servizi usano quando vengono eseguiti in un nodo. Una proprietà del nodo potrebbe essere HasSSD e potrebbe essere impostata su true o false. La quantità di spazio disponibile in tale unità SSD e la quantità di utilizzo da parte dei servizi sarebbe una metrica come "DriveSpaceInMb".
Proprio come per i vincoli di posizionamento e le proprietà dei nodi, Cluster Resource Manager di Service Fabric non comprende i nomi delle metriche. I nomi delle metriche sono semplicemente stringhe. È consigliabile dichiarare le unità come parte dei nomi delle metriche creati quando potrebbero essere ambigue.
Capacità
Se è stato disattivato tutto il bilanciamento delle risorse, Cluster Resource Manager di Service Fabric garantisce comunque che nessun nodo esegua la capacità. Gestire i sovraccarichi di capacità è possibile, a meno che il cluster non sia pieno o il carico di lavoro sia maggiore rispetto a qualsiasi altro nodo. La capacità è un altro vincolo usato da Cluster Resource Manager per comprendere la quantità di una risorsa di un nodo. La capacità rimanente verrà registrata anche per il cluster nel suo complesso.
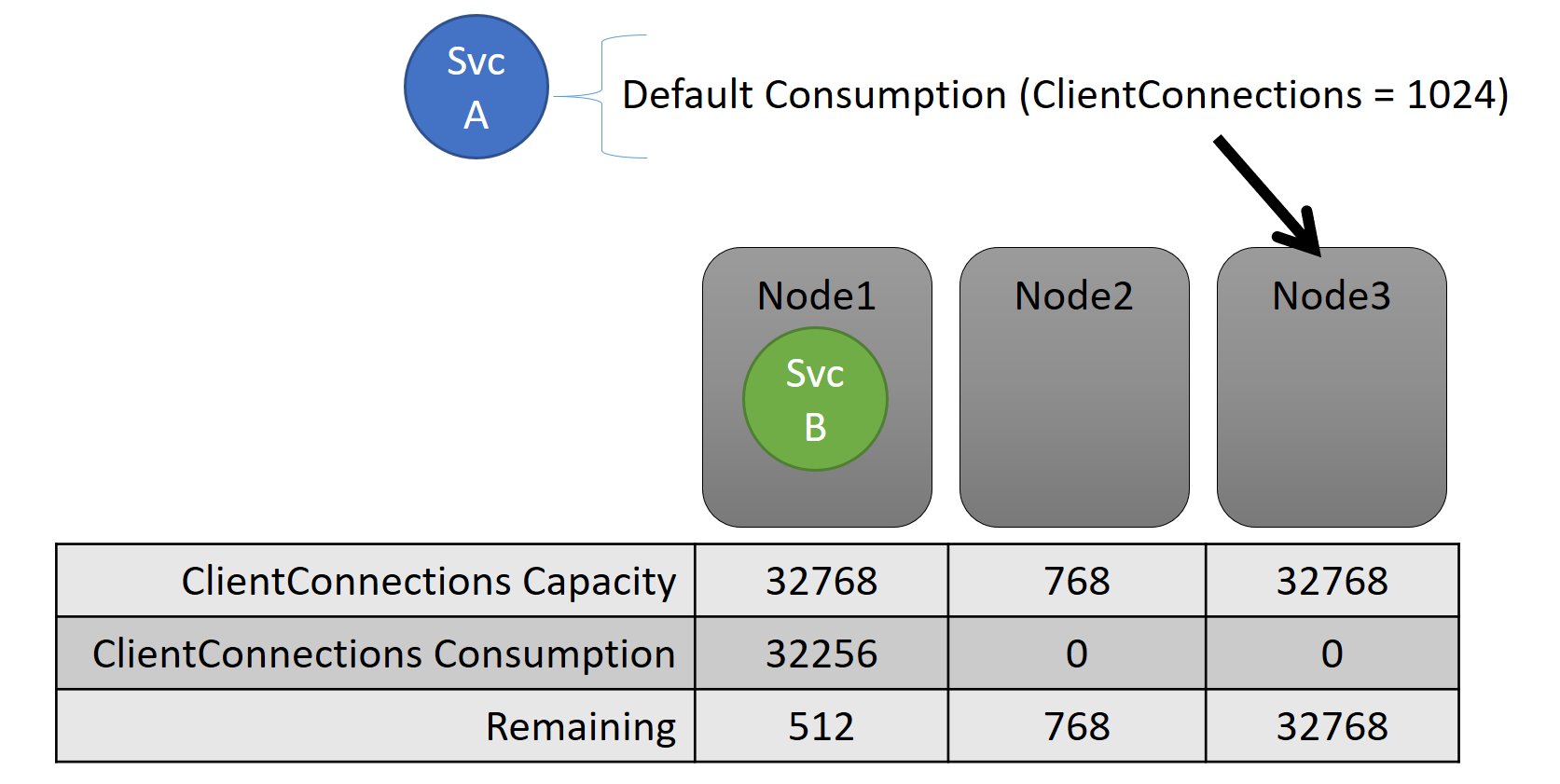
Sia la capacità che l'utilizzo a livello di servizio sono espressi in termini di metriche. Ad esempio, la metrica potrebbe essere "Client Connessione ions" e un nodo potrebbe avere una capacità per "Client Connessione ions" di 32.768. Altri nodi possono avere altri limiti. Un servizio in esecuzione su tale nodo può dire che attualmente sta usando 32.256 della metrica "Client Connessione ions".
Durante il runtime Cluster Resource Manager tiene traccia della capacità rimanente nel cluster e nei nodi. Per tenere traccia della capacità, Cluster Resource Manager sottrae l'utilizzo di ogni servizio dalla capacità di un nodo in cui viene eseguito il servizio. Con queste informazioni, Cluster Resource Manager può determinare dove posizionare o spostare le repliche in modo che i nodi non superano la capacità.
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
ServiceLoadMetricDescription metric = new ServiceLoadMetricDescription();
metric.Name = "ClientConnections";
metric.PrimaryDefaultLoad = 1024;
metric.SecondaryDefaultLoad = 0;
metric.Weight = ServiceLoadMetricWeight.High;
serviceDescription.Metrics.Add(metric);
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("ClientConnections,High,1024,0)
È possibile visualizzare le capacità definite nel manifesto del cluster. Ecco un esempio per ClusterManifest.xml:
<NodeType Name="NodeType03">
<Capacities>
<Capacity Name="ClientConnections" Value="65536"/>
</Capacities>
</NodeType>
Ecco un esempio di capacità definite tramite ClusterConfig.json per le distribuzioni autonome o Template.json per i cluster ospitati in Azure:
"nodeTypes": [
{
"name": "NodeType03",
"capacities": {
"ClientConnections": "65536",
}
}
],
Il carico di un servizio cambia spesso in modo dinamico. Si supponga che il carico di una replica di "Client Connessione ions" sia cambiato da 1.024 a 2.048. Il nodo in cui era in esecuzione aveva quindi una capacità di soli 512 rimanenti per tale metrica. Ora che il posizionamento della replica o dell'istanza non è valido, perché non c'è spazio sufficiente su tale nodo. Cluster Resource Manager deve riportare il nodo sotto la capacità. Riduce il carico sul nodo che supera la capacità spostando una o più repliche o istanze da tale nodo ad altri nodi.
Cluster Resource Manager tenta di ridurre al minimo il costo delle repliche in movimento. Altre informazioni sui costi di spostamento e sul ribilanciamento di strategie e regole.
Capacità del cluster
In che modo Cluster Resource Manager di Service Fabric impedisce che il cluster complessivo sia troppo pieno? Con il carico dinamico, non c'è molto da fare. I servizi possono avere un picco di carico indipendentemente da azioni eseguite da Cluster Resource Manager. Di conseguenza, il cluster con un sacco di sala head oggi potrebbe essere sottopo se c'è un picco domani.
I controlli in Cluster Resource Manager consentono di evitare problemi. La prima cosa che è possibile fare è impedire la creazione di nuovi carichi di lavoro che causerebbero il pieno del cluster.
Si supponga di creare un servizio senza stato e che sia associato un carico. Il servizio si occupa della metrica "DiskSpaceInMb". Il servizio utilizzerà cinque unità di "DiskSpaceInMb" per ogni istanza del servizio. Si vogliono creare tre istanze del servizio. Ciò significa che nel cluster sono necessarie 15 unità di "DiskSpaceInMb" per poter creare anche queste istanze del servizio.
Cluster Resource Manager calcola continuamente la capacità e il consumo di ogni metrica in modo che possa determinare la capacità rimanente nel cluster. Se lo spazio non è sufficiente, Cluster Resource Manager rifiuta la chiamata per creare un servizio.
Poiché il requisito è solo che saranno disponibili 15 unità, è possibile allocare questo spazio in molti modi diversi. Ad esempio, potrebbe essere presente un'unità di capacità rimanente su 15 nodi diversi o tre unità di capacità rimanenti in cinque nodi diversi. Se Cluster Resource Manager può riorganizzare gli elementi in modo che siano disponibili cinque unità in tre nodi, inserisce il servizio. In genere la riorganizzazione del cluster è possibile, a meno che il cluster non sia quasi pieno o che, per qualsiasi motivo, non sia possibile consolidare i servizi esistenti.
Capacità di buffer dei nodi e overbooking
Se si specifica una capacità del nodo per una metrica, Cluster Resource Manager non inserisce mai o sposta le repliche in un nodo se il carico totale supera la capacità del nodo specificata. Ciò può talvolta impedire il posizionamento di nuove repliche o la sostituzione di repliche non riuscite se il cluster è quasi pieno e una replica con un carico di grandi dimensioni deve essere inserita, sostituita o spostata.
Per offrire maggiore flessibilità, è possibile specificare la capacità di buffer dei nodi o overbooking. Quando si specifica la capacità di buffer del nodo o overbooking per una metrica, Cluster Resource Manager tenterà di posizionare o spostare le repliche in modo tale che la capacità buffer o overbooking rimanga inutilizzata, ma consente di usare la capacità di buffer o overbooking, se necessario per azioni che aumentano la disponibilità del servizio, ad esempio:
- Posizionamento di una nuova replica o sostituzione di repliche non riuscite
- Posizionamento durante gli aggiornamenti
- Correzione di violazioni di vincoli soft e hard
- Deframmentazione
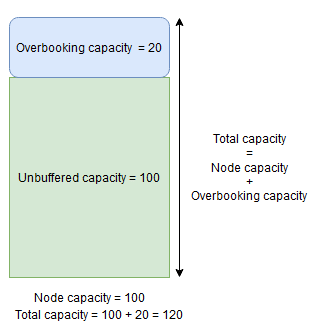
La capacità del buffer del nodo rappresenta una parte riservata della capacità del nodo al di sotto della capacità del nodo specificata e la capacità di overbooking rappresenta una parte della capacità aggiuntiva sopra la capacità del nodo specificata. In entrambi i casi Cluster Resource Manager tenterà di mantenere libera questa capacità.
Ad esempio, se un nodo ha una capacità specificata per la metrica CpuUtilization pari a 100 e la percentuale di buffer dei nodi per tale metrica è impostata su 20%, le capacità totali e non memorizzate nel buffer saranno rispettivamente 100 e 80 e Cluster Resource Manager non insedierà più di 80 unità di carico nel nodo in circostanze normali.

Il buffer del nodo deve essere usato quando si vuole riservare una parte della capacità del nodo che verrà usata solo per le azioni che aumentano la disponibilità del servizio indicate in precedenza.
D'altra parte, se viene usata la percentuale di overbooking dei nodi e impostata sul 20%, le capacità totali e non memorizzate nel buffer saranno rispettivamente 120 e 100.
La capacità di overbooking deve essere usata quando si vuole consentire a Cluster Resource Manager di posizionare le repliche in un nodo anche se l'utilizzo totale delle risorse supera la capacità. Questo può essere usato per fornire disponibilità aggiuntiva per i servizi a scapito delle prestazioni. Se si usa l'overbooking, la logica dell'applicazione utente deve essere in grado di funzionare con meno risorse fisiche di quelle necessarie.
Se si specificano capacità di buffer dei nodi o overbooking, Cluster Resource Manager non sposta o posiziona le repliche se il carico totale nel nodo di destinazione supera la capacità totale (capacità del nodo in caso di buffer del nodo e capacità del nodo e capacità del nodo + overbooking in caso di overbooking).
La capacità di overbooking può essere specificata anche per essere infinita. In questo caso, Cluster Resource Manager tenterà di mantenere il carico totale nel nodo al di sotto della capacità del nodo specificata, ma può potenzialmente posizionare un carico molto maggiore sul nodo che potrebbe causare una grave riduzione delle prestazioni.
Una metrica non può avere sia il buffer del nodo che la capacità di overbooking specificati contemporaneamente.
Ecco un esempio di come specificare le capacità di buffer dei nodi o overbooking in ClusterManifest.xml:
<Section Name="NodeBufferPercentage">
<Parameter Name="SomeMetric" Value="0.15" />
</Section>
<Section Name="NodeOverbookingPercentage">
<Parameter Name="SomeOtherMetric" Value="0.2" />
<Parameter Name=”MetricWithInfiniteOverbooking” Value=”-1.0” />
</Section>
Di seguito è riportato un esempio di come specificare capacità di buffer del nodo o overbooking tramite ClusterConfig.json per distribuzioni autonome o Template.json per i cluster ospitati in Azure:
"fabricSettings": [
{
"name": "NodeBufferPercentage",
"parameters": [
{
"name": "SomeMetric",
"value": "0.15"
}
]
},
{
"name": "NodeOverbookingPercentage",
"parameters": [
{
"name": "SomeOtherMetric",
"value": "0.20"
},
{
"name": "MetricWithInfiniteOverbooking",
"value": "-1.0"
}
]
}
]
Passaggi successivi
- Per informazioni sull'architettura e sul flusso di informazioni in Cluster Resource Manager, vedere Panoramica dell'architettura di Cluster Resource Manager.
- La definizione delle metriche di deframmentazione è un modo per consolidare il carico sui nodi anziché distribuirlo. Per informazioni su come configurare la deframmentazione, vedere Deframmentazione delle metriche e del carico in Service Fabric.
- Iniziare dall'inizio e ottenere un'introduzione a Cluster Resource Manager di Service Fabric.
- Per informazioni su come Cluster Resource Manager gestisce e bilancia il carico nel cluster, vedere Bilanciamento del cluster di Service Fabric.