Architettura del ripristino di emergenza da VMware ad Azure - Classico
Questo articolo descrive l'architettura e i processi usati per implementare il ripristino di emergenza con replica, failover e ripristino di macchine virtuali (VM) VMware tra un sito VMware locale e Azure usando il servizio Azure Site Recovery - Classico.
Per i dettagli sull'architettura modernizzata, consultare questo articolo
Componenti dell'architettura
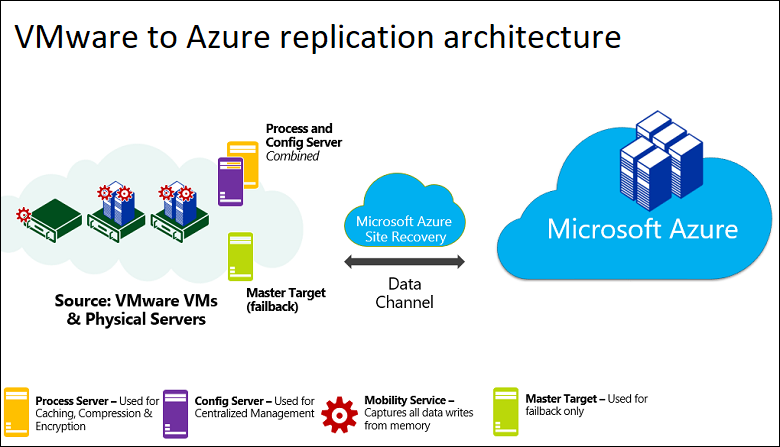
La tabella e l'immagine seguenti offrono una visualizzazione generale dei componenti usati per il ripristino di emergenza di macchine virtuali o fisiche da VMware ad Azure.
| Componente | Requisito | Dettagli |
|---|---|---|
| Azure | Una sottoscrizione di Azure, un account di Archiviazione di Azure per la cache, Managed Disks e rete di Azure. | I dati replicati da macchine virtuali locali vengono archiviati nell'archiviazione di Azure. Le macchine virtuali di Azure vengono create con i dati replicati durante l'esecuzione di un failover dal sito locale ad Azure. Le VM di Azure si connettono alla rete virtuale di Azure quando vengono create. |
| Computer server di configurazione | Un singolo computer locale. È consigliabile eseguirlo come macchina virtuale VMware che possa essere distribuita da un modello OVF scaricato. Il computer esegue tutti componenti di Site Recovery locali, tra cui il server di configurazione, il server di elaborazione e il server di destinazione master. |
Server di configurazione: coordina le comunicazioni tra i componenti locali e Azure e gestisce la replica dei dati. Server di elaborazione: installato per impostazione predefinita nel server di configurazione. Riceve i dati di replica, li ottimizza attraverso la memorizzazione nella cache, la compressione e la crittografia e li invia ad Archiviazione di Azure. Il server di elaborazione installa anche il servizio Mobility di Azure Site Recovery nelle macchine virtuali da replicare ed esegue l'individuazione automatica delle macchine virtuali locali. Con l'aumentare delle dimensioni della distribuzione, è possibile aggiungere altri server di elaborazione separati per gestire volumi più elevati di traffico di replica. Server di destinazione master: installato per impostazione predefinita nel server di configurazione. Gestisce i dati di replica durante il failback da Azure. Per distribuzioni di grandi dimensioni, è possibile aggiungere un altro server di destinazione master separato per il failback. |
| Server VMware | Le macchine virtuali VMware sono ospitate in server vSphere ESXi locali. È consigliabile usare un server vCenter per gestire gli host. | Durante la distribuzione di Site Recovery, aggiungere i server VMware all'insieme di credenziali di Servizi di ripristino. |
| Computer replicati | Il servizio Mobility viene installato in ogni macchina virtuale VMware da replicare. | È consigliabile consentire l'installazione automatica dal server di elaborazione. In alternativa, è possibile installare il servizio manualmente o usare un metodo di distribuzione automatizzato, ad esempio Configuration Manager. |
Configurare la connettività di rete in uscita
Affinché Site Recovery funzioni come previsto, è necessario modificare la connettività di rete in uscita per consentire all'ambiente di replicare.
Nota
Site Recovery di computer VMware/fisici che usano l'architettura classica non supporta l'uso di un proxy di autenticazione per controllare la connettività di rete. Quest'uso è invece supportato quando si usa l'architettura modernizzata.
Connettività in uscita per gli URL
Se si usa un proxy firewall basato su URL per controllare la connettività in uscita, consentire l'accesso a questi URL:
| Nome | Commerciale | Enti pubblici | Descrizione |
|---|---|---|---|
| Storage | *.blob.core.windows.net |
*.blob.core.usgovcloudapi.net |
Consente la scrittura di dati dalla macchina virtuale nell'account di archiviazione della cache all'area di origine. |
| Microsoft Entra ID | login.microsoftonline.com |
login.microsoftonline.us |
Fornisce l'autenticazione e l'autorizzazione per gli URL del servizio Site Recovery. |
| Replica | *.hypervrecoverymanager.windowsazure.com |
*.hypervrecoverymanager.windowsazure.us |
Consente alla macchina virtuale di comunicare con il servizio Site Recovery. |
| Bus di servizio | *.servicebus.windows.net |
*.servicebus.usgovcloudapi.net |
Consente alla macchina virtuale di scrivere i dati di diagnostica e monitoraggio di Site Recovery. |
Per un elenco completo degli URL da filtrare per la comunicazione tra l'infrastruttura di Azure Site Recovery locale e i servizi di Azure, vedere la sezione Requisiti di rete nell'articolo prerequisiti.
Processo di replica
Quando si abilita la replica per una macchina virtuale, viene avviata la replica iniziale nell'archiviazione di Azure con i criteri di replica specificati. Nota quanto segue:
- Per le macchine virtuali VMware, la replica è a livello di blocco, quasi continua, e usa l'agente del servizio Mobility in esecuzione nella macchina virtuale.
- Vengono applicate tutte le impostazioni dei criteri di replica:
- Soglia RPO. Questa impostazione non influisce sulla replica. È utile con il monitoraggio. Viene generato un evento e, facoltativamente, viene inviato un messaggio di posta elettronica, se l'obiettivo RPO corrente supera la soglia specificata.
- Conservazione del punto di ripristino. Questa impostazione specifica quanto indietro nel tempo si vuole andare quando si verifica un'interruzione. La conservazione massima è di 15 giorni nel disco gestito.
- Snapshot coerenti con l'app. È possibile acquisire snapshot coerenti con l'app a intervalli compresi tra 1 e 12 ore, a seconda delle esigenze dell'app. Si tratta di snapshot BLOB di Azure standard. L'agente di mobilità in esecuzione in una macchina virtuale richiede uno snapshot VSS conforme a questa impostazione e fa riferimento a quel momento come punto coerente con l'applicazione nel flusso di replica.
Nota
Un periodo di conservazione dei punti di ripristino elevato può influire sul costo di archiviazione perché potrebbe essere necessario salvare più punti di ripristino.
Il traffico viene replicato negli endpoint pubblici di archiviazione di Azure, tramite Internet. In alternativa, è possibile usare Azure ExpressRoute con il peering Microsoft. La replica del traffico tramite una VPN da sito a sito da un sito locale ad Azure non è supportata.
L'operazione di replica iniziale garantisce che interi dati nel computer al momento dell'abilitazione della replica vengano inviati ad Azure. Al termine della replica iniziale, viene avviata la replica differenziale in Azure. Le modifiche rilevate per un computer vengono inviate al server di elaborazione.
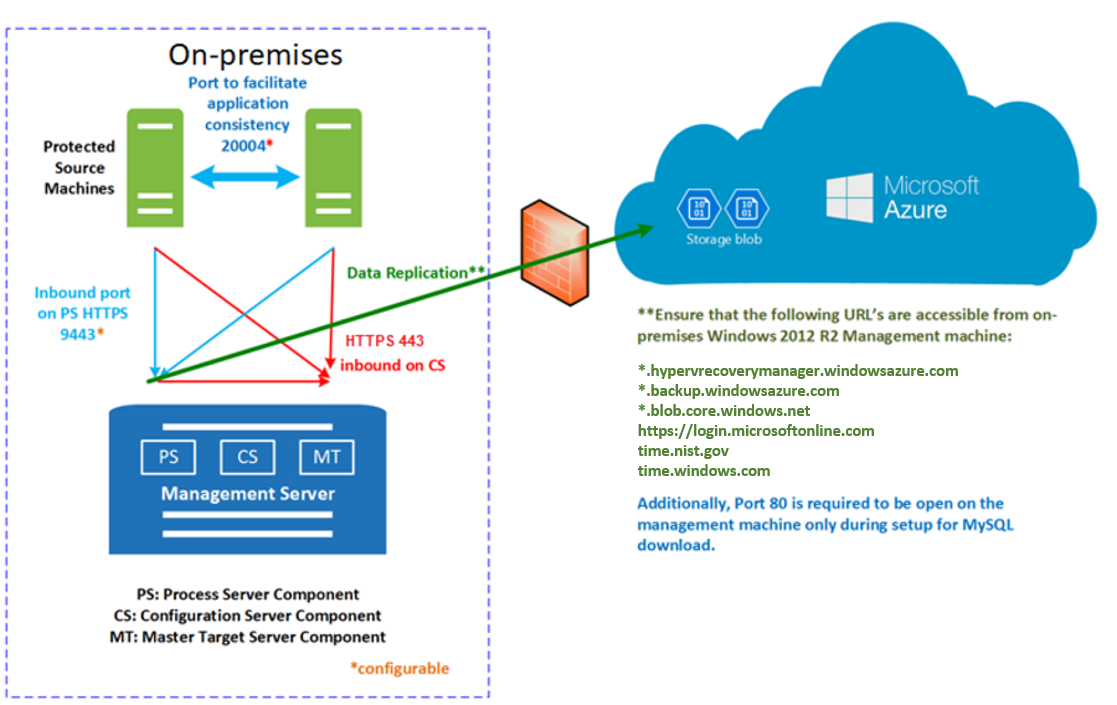
Le comunicazioni avvengono nel modo seguente:
- Le macchine virtuali comunicano con il server di configurazione locale sulla porta HTTPS 443 in ingresso, per la gestione della replica.
- Il server di configurazione orchestra la replica con Azure attraverso la porta HTTPS 443 in uscita.
- Le macchine virtuali inviano i dati della replica al server di elaborazione (in esecuzione sul computer del server di configurazione) sulla porta HTTPS 9443 in ingresso. La porta può essere modificata.
- Il server di elaborazione riceve i dati della replica, li ottimizza e li crittografa, quindi li invia ad Archiviazione di Azure attraverso la porta 443 in uscita.
I log dei dati di replica vengono prima inseriti in un account di archiviazione della cache in Azure. Questi log vengono elaborati e i dati vengono archiviati in un disco gestito di Azure (denominato disco di inizializzazione di Azure Site Recovery). I punti di ripristino vengono creati su questo disco.
Processo di risincronizzazione
- In alcuni casi, durante la replica iniziale o durante il trasferimento delle modifiche differenziali, possono verificarsi problemi di connettività di rete tra il computer di origine e il server di elaborazione o tra i server di elaborazione in Azure. Uno di questi può causare errori temporanei nel trasferimento dei dati in Azure.
- Per evitare problemi di integrità dei dati e ridurre al minimo i costi di trasferimento dei dati, Site Recovery contrassegna un computer per la risincronizzazione.
- Un computer può anche essere contrassegnato per la risincronizzazione in situazioni come le seguenti per mantenere la coerenza tra il computer di origine e i dati archiviati in Azure
- Se una macchina subisce l'arresto forzato
- Se un computer subisce modifiche di configurazione come il dimensionamento del disco (modifica delle dimensioni del disco da 2 TB a 4 TB)
- La risincronizzazione invia solo i dati differenziali ad Azure. Il trasferimento dei dati tra l'ambiente locale e Azure viene ridotto a icona calcolando i checksum dei dati tra il computer di origine e i dati archiviati in Azure.
- Per impostazione predefinita, la risincronizzazione è pianificata per l'esecuzione automatica al di fuori degli orari lavorativi. Se non si vuole attendere la risincronizzazione predefinita al di fuori degli orari di lavoro, è possibile risincronizzare una macchina virtuale manualmente, A questo scopo, nel portale di Azure selezionare la macchina virtuale >Risincronizza.
- Se la risincronizzazione predefinita ha esito negativo al di fuori dell'orario di ufficio e viene richiesto un intervento manuale, viene generato un errore nel computer specifico nel portale di Azure. È possibile risolvere l'errore e attivare manualmente la risincronizzazione.
- Al termine della risincronizzazione, la replica delle modifiche differenziali riprenderà.
Gestione dei criteri di replica
- È possibile personalizzare le impostazioni dei criteri di replica durante l'abilitazione della replica.
- È possibile creare criteri di replica in qualsiasi momento e quindi applicarli quando si abilita la replica.
Coerenza tra più macchine virtuali
Se si vuole che le macchine virtuali vengano replicate insieme e abbiano punti di ripristino condivisi coerenti con l'arresto anomalo del sistema e coerenti con l'app in caso di failover, è possibile raccoglierle in un gruppo di replica. La coerenza tra più macchine virtuali influisce sulle prestazioni dei carichi di lavoro e deve essere usata solo per le macchine virtuali che eseguono carichi di lavoro per cui la coerenza fra tutte le macchine è fondamentale.
Snapshot e punti di ripristino
I punti di ripristino vengono creati da snapshot dei dischi delle macchine virtuali acquisiti in un momento specifico. Quando si effettua il failover di una macchina virtuale, si usa un punto di ripristino per ripristinare la VM nella posizione di destinazione.
Prima di effettuare il failover è importante assicurarsi che la macchina virtuale venga avviata senza danneggiamenti o perdita di dati e che i dati della VM siano coerenti per il sistema operativo e per le app in esecuzione su di essa. Tutto questo dipende dal tipo di snapshot acquisiti.
Site Recovery acquisisce snapshot nel modo seguente:
- Site Recovery acquisisce snapshot dei dati coerenti con l'arresto anomalo del sistema per impostazione predefinita, oltre a snapshot coerenti con l'app se si specifica una frequenza.
- Dagli snapshot vengono creati punti di ripristino che vengono archiviati in base alle impostazioni di conservazione dei criteri di replica.
Coerenza
La tabella seguente illustra i vari tipi di coerenza.
Coerenza con l'arresto anomalo del sistema
| Descrizione | Dettagli | Consiglio |
|---|---|---|
| Uno snapshot coerente con l'arresto anomalo del sistema acquisisce i dati contenuti nel disco al momento dell'acquisizione dello snapshot. Non include alcun dato in memoria. Contiene l'equivalente dei dati su disco che sarebbero presenti se si verificasse un arresto anomalo della macchina virtuale o se il cavo di alimentazione del server venisse scollegato nell'istante esatto dell'acquisizione dello snapshot. Uno snapshot coerente con l'arresto anomalo del sistema non garantisce la coerenza dei dati per il sistema operativo o per le app in esecuzione nella macchina virtuale. |
Per impostazione predefinita, Site Recovery crea punti di ripristino coerenti con l'arresto anomalo del sistema ogni cinque minuti. Questa impostazione non può essere modificata. |
Attualmente, la maggior parte delle app può essere ripristinata correttamente da punti coerenti con l'arresto anomalo del sistema. I punti di ripristino coerenti con l'arresto anomalo del sistema sono in genere sufficienti per la replica di sistemi operativi e app come i server DHCP e i server di stampa. |
Coerenza con l'app
| Descrizione | Dettagli | Consiglio |
|---|---|---|
| I punti di ripristino coerenti con l'app vengono creati dagli snapshot coerenti con l'app. Uno snapshot coerente con l'app contiene tutte le informazioni contenute in uno snapshot coerente con l'arresto anomalo del sistema, oltre a tutti i dati in memoria e le transazioni in corso. |
Gli snapshot coerenti con l'app usano il servizio Copia Shadow del volume: 1) Azure Site Recovery usa il metodo di backup di sola copia (VSS_BT_COPY) che non modifica il tempo di backup del log delle transazioni di Microsoft SQL e il numero di sequenza 2) Quando viene avviato uno snapshot, VSS esegue un'operazione di copia su scrittura (COW) nel volume. 3) Prima di eseguire l'operazione di copia su scrittura, il servizio informa ogni app presente nella macchina virtuale che dovrà scaricare i dati residenti in memoria su disco. 4) Il servizio Copia Shadow del volume consente quindi all'app di backup/ripristino di emergenza (in questo caso Site Recovery) di leggere i dati dello snapshot e di procedere. |
Gli snapshot vengono acquisiti in base alla frequenza specificata. Questa frequenza deve essere sempre inferiore a quella impostata per la conservazione dei punti di ripristino. Ad esempio, se i punti di ripristino vengono conservati in base all'impostazione predefinita di 24 ore, la frequenza deve essere impostata su un periodo inferiore a 24 ore. Gli snapshot coerenti con l'app sono più complessi e il loro completamento richiede più tempo rispetto agli snapshot coerenti con l'arresto anomalo del sistema. Influiscono sulle prestazioni delle app in esecuzione su una macchina virtuale abilitata per la replica. |
Processo di failover e failback
Dopo aver configurato la replica e aver eseguito un'analisi di ripristino di emergenza (failover di test) per verificare che funzioni tutto come previsto, è possibile eseguire il failover e il failback in base alle esigenze.
È possibile eseguire il failover di una singola macchina virtuale o creare piani di ripristino per eseguire contemporaneamente il failover di più macchine virtuali. Rispetto al failover di una singola macchina virtuale, un piano di ripristino offre i vantaggi seguenti:
- È possibile modellare le dipendenze di un'app includendo tutte le macchine virtuali dell'app in un solo piano di ripristino.
- È possibile aggiungere script e runbook di Azure e sospendere il failover per eseguire operazioni manuali.
Dopo aver attivato il failover iniziale, è necessario eseguirne il commit per iniziare ad accedere al carico di lavoro dalla macchina virtuale di Azure.
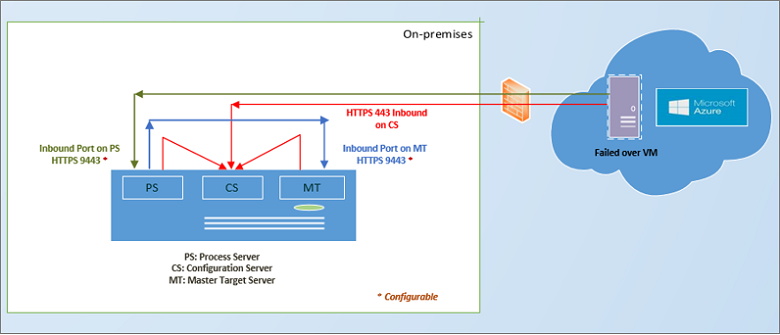
Quando il sito locale primario è di nuovo disponibile, è possibile eseguire le attività preliminari al failback. A tale scopo, è necessario configurare un'infrastruttura di failback con i componenti seguenti:
- Server di elaborazione temporaneo in Azure: per eseguire il failback da Azure, configurare una macchina virtuale di Azure perché funga da server di elaborazione per gestire la replica da Azure. Questa VM può essere eliminata al termine del failback.
- Connessione VPN: per eseguire il failback, è necessaria una connessione VPN (o ExpressRoute) dalla rete di Azure al sito locale.
- Server di destinazione master separato: per impostazione predefinita, il server di destinazione master installato con il server di configurazione nella macchina virtuale VMware locale gestisce il failback. Se è necessario eseguire il failback di grandi volumi di traffico, configurare un server di destinazione master locale separato a questo scopo.
- Criteri di failback: per eseguire la replica nel sito locale, è necessario un criterio di failback, che viene creato automaticamente quando si creano i criteri di replica dal sito locale ad Azure.
Una volta predisposti i componenti, il failback avviene in tre fasi:
- Fase 1: riproteggere le macchine virtuali di Azure in modo da eseguirne di nuovo la replica da Azure alle macchine virtuali VMware locali.
- Fase 2: eseguire un failover nel sito locale.
- Fase 3: al termine del failback dei carichi di lavoro, riabilitare la replica per le macchine virtuali locali.
Passaggi successivi
Seguire questa esercitazione per abilitare la replica da VMware ad Azure.