Esercitazione: Documentare l’intelligenza con i Servizi di Azure AI
Informazioni sui documenti di Azure AI è un Servizio Azure per intelligenza artificiale che consente di creare un’applicazione di elaborazione dati automatica tramite la tecnologia di apprendimento automatico. Questa esercitazione descrive come arricchire facilmente i dati in Azure Synapse Analytics. Si userà Informazioni sui documenti per analizzare moduli e documenti, estrarre testo e dati e restituire un output JSON strutturato. È possibile ottenere rapidamente risultati accurati e personalizzati in base al contenuto specifico, senza bisogno di interventi manuali impegnativi o competenze approfondite di data science.
Questa esercitazione illustra l'uso di Informazioni sui documenti con SynapseML per:
- Estrarre testo e layout da un determinato documento
- Rilevare ed estrarre dati dalle ricevute
- Rilevare ed estrarre dati dai biglietti da visita
- Rilevare ed estrarre dati dalle fatture
- Rilevare ed estrarre dati dai documenti di identificazione
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Prerequisiti
- Area di lavoro di Azure Synapse Analytics con un account di archiviazione di Azure Data Lake Storage Gen2 configurato come risorsa archiviazione predefinita. È necessario essere il Collaboratore ai dati dei BLOB della risorsa di archiviazione del file system di Data Lake Storage Gen2 con cui si lavora.
- Pool di Spark nell'area di lavoro di Azure Synapse Analytics. Per i dettagli, vedere Creare un pool di Spark in Azure Synapse.
- Passaggi di preconfigurazione nell'esercitazione Configurare i servizi di Azure AI in Azure Synapse.
Operazioni preliminari
Aprire Synapse Studio e creare un nuovo notebook. Per iniziare, importare SynapseML.
import synapse.ml
from synapse.ml.cognitive import *
Configurare l'intelligenza sui documenti
Usare l’intelligenza sui documenti collegata configurata nei passaggi di preconfigurazione.
ai_service_name = "<Your linked service for Document Intelligence>"
Analyze Layout
Estrarre informazioni di testo e layout da un documento specificato. Il documento di input deve essere di uno dei tipi di contenuto supportati: 'applicazione/pdf', 'immagine/jpeg', 'immagine/png' o 'immagine/tiff'.
Input di esempio

from pyspark.sql.functions import col, flatten, regexp_replace, explode, create_map, lit
imageDf = spark.createDataFrame([
("<replace with your file path>/layout.jpg",)
], ["source",])
analyzeLayout = (AnalyzeLayout()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("layout")
.setConcurrency(5))
display(analyzeLayout
.transform(imageDf)
.withColumn("lines", flatten(col("layout.analyzeResult.readResults.lines")))
.withColumn("readLayout", col("lines.text"))
.withColumn("tables", flatten(col("layout.analyzeResult.pageResults.tables")))
.withColumn("cells", flatten(col("tables.cells")))
.withColumn("pageLayout", col("cells.text"))
.select("source", "readLayout", "pageLayout"))
Risultati previsti
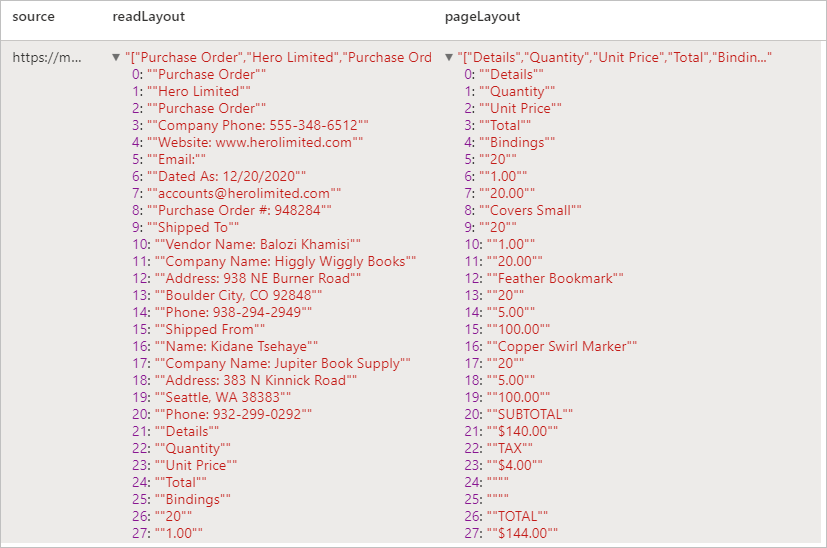
Analizzare ricevute
Rileva ed estrae dati dalle ricevute usando il riconoscimento ottico dei caratteri (OCR) e il nostro modello di ricevuta, consentendo di estrarre facilmente dati strutturati dalle ricevute, ad esempio il nome del fornitore, il numero di telefono del fornitore, la data della transazione, il totale delle transazioni e altro ancora.
Input di esempio

imageDf2 = spark.createDataFrame([
("<replace with your file path>/receipt1.png",)
], ["image",])
analyzeReceipts = (AnalyzeReceipts()
.setLinkedService(ai_service_name)
.setImageUrlCol("image")
.setOutputCol("parsed_document")
.setConcurrency(5))
results = analyzeReceipts.transform(imageDf2).cache()
display(results.select("image", "parsed_document"))
Risultati previsti
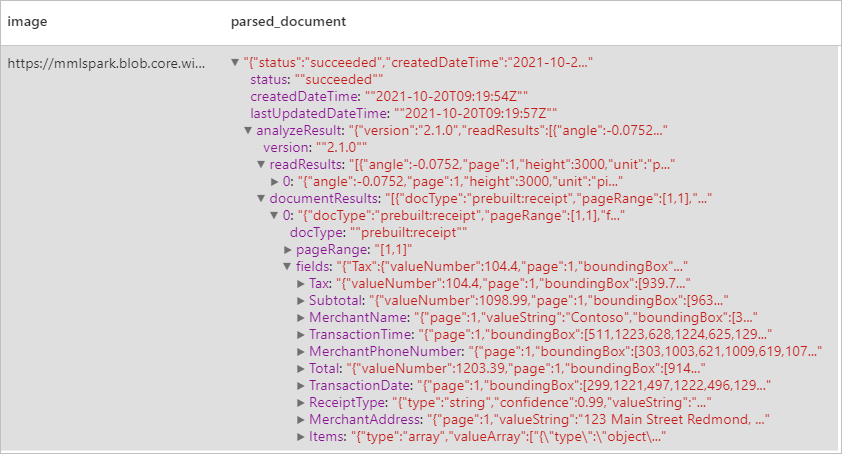
Analizzare biglietti da visita
Rileva ed estrae dati da biglietti da visita usando il riconoscimento ottico dei caratteri (OCR) e il nostro modello di biglietti da visita, consentendo di estrarre facilmente dati strutturati da biglietti da visita, ad esempio nomi di contatto, nomi di società, numeri di telefono, e-mail e altro ancora.
Input di esempio

imageDf3 = spark.createDataFrame([
("<replace with your file path>/business_card.jpg",)
], ["source",])
analyzeBusinessCards = (AnalyzeBusinessCards()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("businessCards")
.setConcurrency(5))
display(analyzeBusinessCards
.transform(imageDf3)
.withColumn("documents", explode(col("businessCards.analyzeResult.documentResults.fields")))
.select("source", "documents"))
Risultati previsti
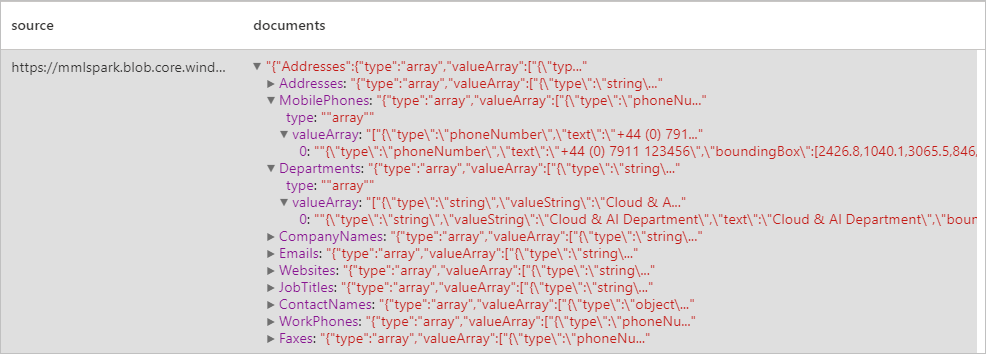
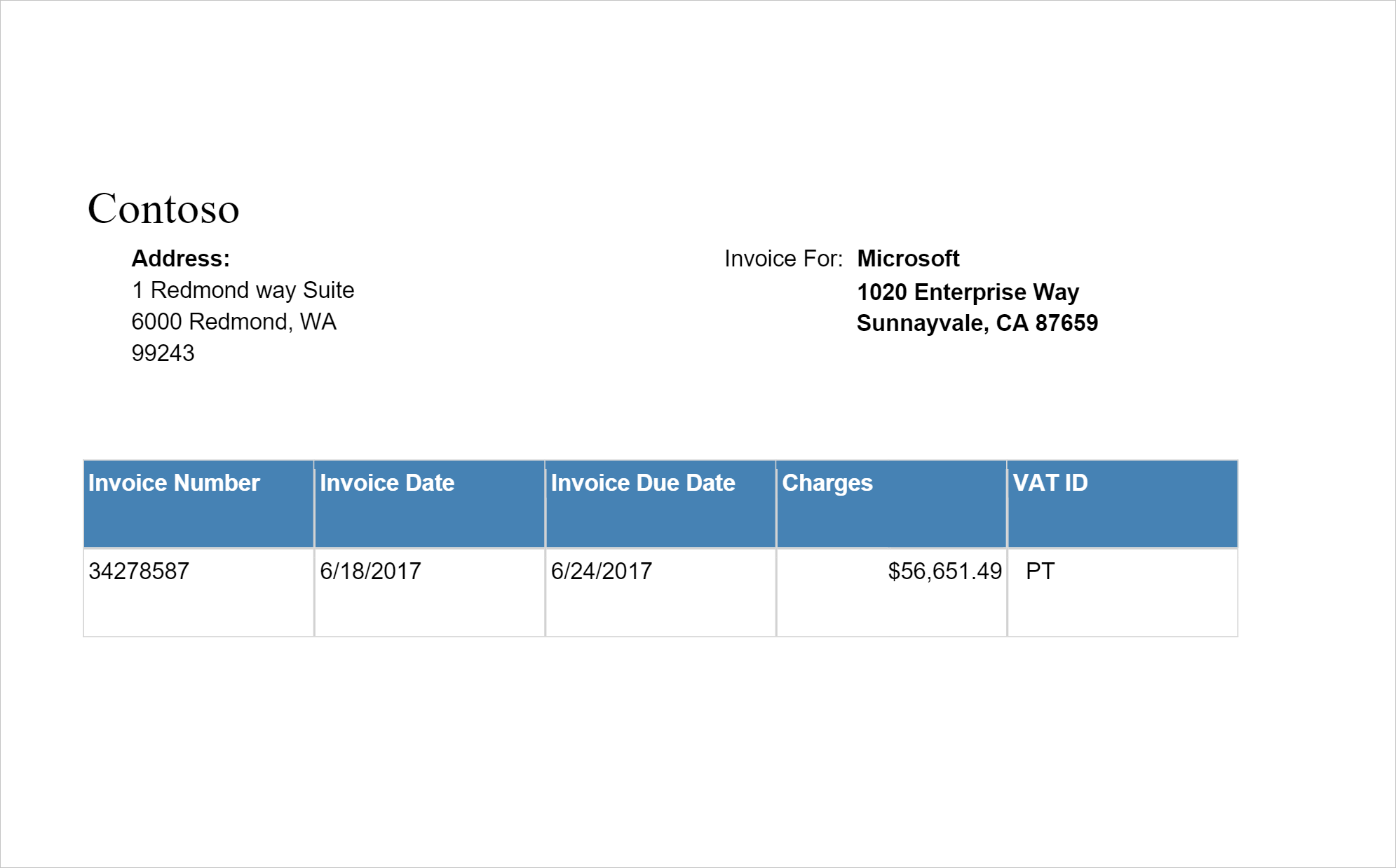
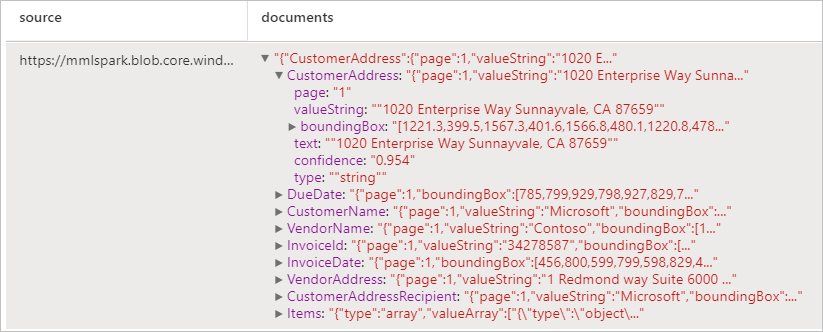
Analizzare fatture
Rileva ed estrae dati dalle fatture usando il riconoscimento ottico dei caratteri (OCR) e i modelli di Deep Learning per la comprensione delle fatture, consentendo di estrarre facilmente dati strutturati dalle fatture, ad esempio cliente, fornitore, ID fattura, data di scadenza fattura, totale, importo della fattura dovuto, importo iva, importo fiscale, spedizione, fatturazione, voci e altro ancora.
Input di esempio
imageDf4 = spark.createDataFrame([
("<replace with your file path>/invoice.png",)
], ["source",])
analyzeInvoices = (AnalyzeInvoices()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("invoices")
.setConcurrency(5))
display(analyzeInvoices
.transform(imageDf4)
.withColumn("documents", explode(col("invoices.analyzeResult.documentResults.fields")))
.select("source", "documents"))
Risultati previsti
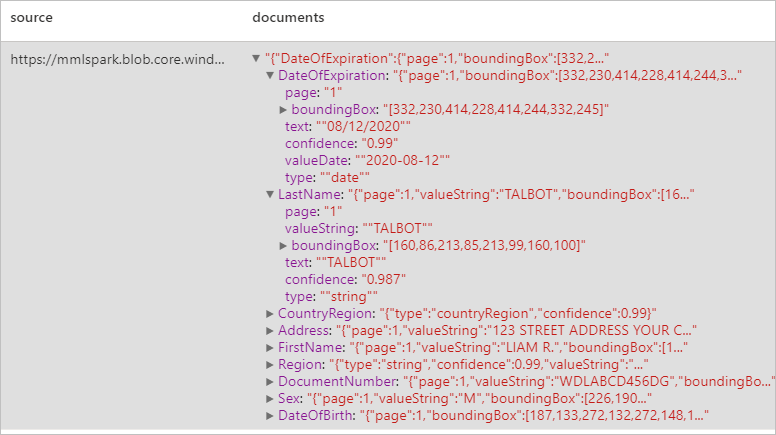
Analizzare documenti di identità
Rileva ed estrae dati dai documenti di identificazione usando il riconoscimento ottico dei caratteri (OCR) e il modello di documento di identità, consentendo di estrarre facilmente dati strutturati da documenti ID, ad esempio nome, cognome, data di nascita, numero di documento e altro ancora.
Input di esempio

imageDf5 = spark.createDataFrame([
("<replace with your file path>/id.jpg",)
], ["source",])
analyzeIDDocuments = (AnalyzeIDDocuments()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("ids")
.setConcurrency(5))
display(analyzeIDDocuments
.transform(imageDf5)
.withColumn("documents", explode(col("ids.analyzeResult.documentResults.fields")))
.select("source", "documents"))
Risultati previsti
Pulire le risorse
Per assicurarsi che l'istanza di Spark venga arrestata, terminare tutte le sessioni connesse (notebook). Il pool si arresta quando viene raggiunto il tempo di inattività specificato nel pool di Apache Spark. Si può anche selezionare Termina sessione sulla barra di stato nella parte destra superiore del notebook.
