Monitoraggio degli endpoint di Gestione traffico
Gestione traffico di Azure include il monitoraggio degli endpoint e il failover automatico degli endpoint. Questa funzionalità consente di distribuire applicazioni a disponibilità elevata resilienti agli errori di endpoint, inclusi gli errori di area di Azure. Il monitoraggio degli endpoint è abilitato per impostazione predefinita. Per disabilitare il monitoraggio, vedere Abilitare o disabilitare i controlli di integrità.
Configurare il monitoraggio degli endpoint
Per configurare il monitoraggio degli endpoint è necessario specificare le seguenti impostazioni nel profilo di Gestione traffico:
- Protocollo. Scegliere HTTP, HTTPS o TCP come protocollo che Gestione traffico usa quando esegue il sondaggio dell'endpoint per verificarne l'integrità. Il monitoraggio HTTPS non verifica se il certificato TLS/SSL è valido, verifica solo che il certificato sia presente.
- Porta. scegliere la porta usata per la richiesta.
- Path. Questa impostazione di configurazione è valida solo per i protocolli HTTP e HTTPS, per i quali è necessario specificare l'impostazione del percorso. Se si specifica questa impostazione per il protocollo di monitoraggio TCP, viene generato un errore. Per i protocolli HTTP e HTTPS specificare il percorso relativo e il nome della pagina Web o il file a cui accede il monitoraggio. Una barra
/in avanti è una voce valida per il percorso relativo. Questo valore implica che il file sia nella directory radice (impostazione predefinita). - Impostazioni di intestazione personalizzate. Questa impostazione di configurazione consente di aggiungere intestazioni HTTP specifiche ai controlli di integrità che Gestione traffico agli endpoint in un profilo. Le intestazioni personalizzate possono essere specificate a livello di profilo da applicare per tutti gli endpoint di tale profilo e/o a livello di endpoint applicabili solo a tale endpoint. È possibile usare le intestazioni personalizzate per i controlli di integrità degli endpoint in ambienti multi-tenant. In questo modo, può essere instradato correttamente alla destinazione specificando un'intestazione host. È anche possibile usare questa impostazione mediante l'aggiunta di intestazioni univoche che possono essere usate per identificare le richieste HTTP(S) originate da Gestione traffico ed elaborarle in modo diverso. È possibile specificare fino a otto
header:valuecoppie separate da una virgola. Ad esempio,header1:value1, header2:value2.
Nota
L'uso di caratteri asterischi (*) nelle intestazioni personalizzate Host non è supportato.
Intervalli di codice di stato previsti. Questa impostazione consente di specificare più intervalli di codici di esito positivo nel formato 200-299, 301-301. Se questi codici di stato vengono ricevuti come risposta da un endpoint quando viene avviato un controllo di integrità, Gestione traffico contrassegna tale endpoint come integro. È possibile specificare un massimo di otto intervalli di codici di stato. Questa impostazione è applicabile solo al protocollo HTTP e HTTPS e a tutti gli endpoint. Questa impostazione è a livello di profilo di Gestione traffico e per impostazione predefinita è definito il valore 200 come il codice di stato di riuscita.
Intervallo di probing. Questo valore specifica la frequenza con cui viene controllata l'integrità di un endpoint dall'agente di sondaggio di Gestione traffico. È possibile specificare due valori qui: 30 secondi (sondaggio normale) e 10 secondi (sondaggio veloce). Se non viene specificato alcun valore, il profilo imposta un valore predefinito di 30 secondi. Visitare la pagina dei prezzi di Gestione traffico per altre informazioni sui prezzi di probing rapido.
Numero tollerato di errori. Questo valore specifica il numero di errori tollerati da un agente di sondaggio di Gestione traffico prima di contrassegnare l'endpoint come non integro. Il valore può essere compreso tra 0 e 9. Un valore pari a 0 indica che un singolo errore di monitoraggio può far sì che l'endpoint venga contrassegnato come non integro. Se non si specifica alcun valore, viene usato il valore predefinito di 3.
Timeout probe. Questa proprietà specifica il tempo di attesa dell'agente di sondaggio di Gestione traffico prima che un controllo del probe di integrità su un endpoint venga considerato un errore. Se l'intervallo sondaggio è impostato su 30 secondi, è possibile impostare il valore di timeout tra 5 e 10 secondi. Se non si specifica alcun valore, viene usato il valore predefinito di 10 secondi. Se l'intervallo sondaggio è impostato su 10 secondi, è possibile impostare il valore di timeout tra 5 e 9 secondi. Se non si specifica alcun valore di timeout, viene usato il valore predefinito di 9 secondi.
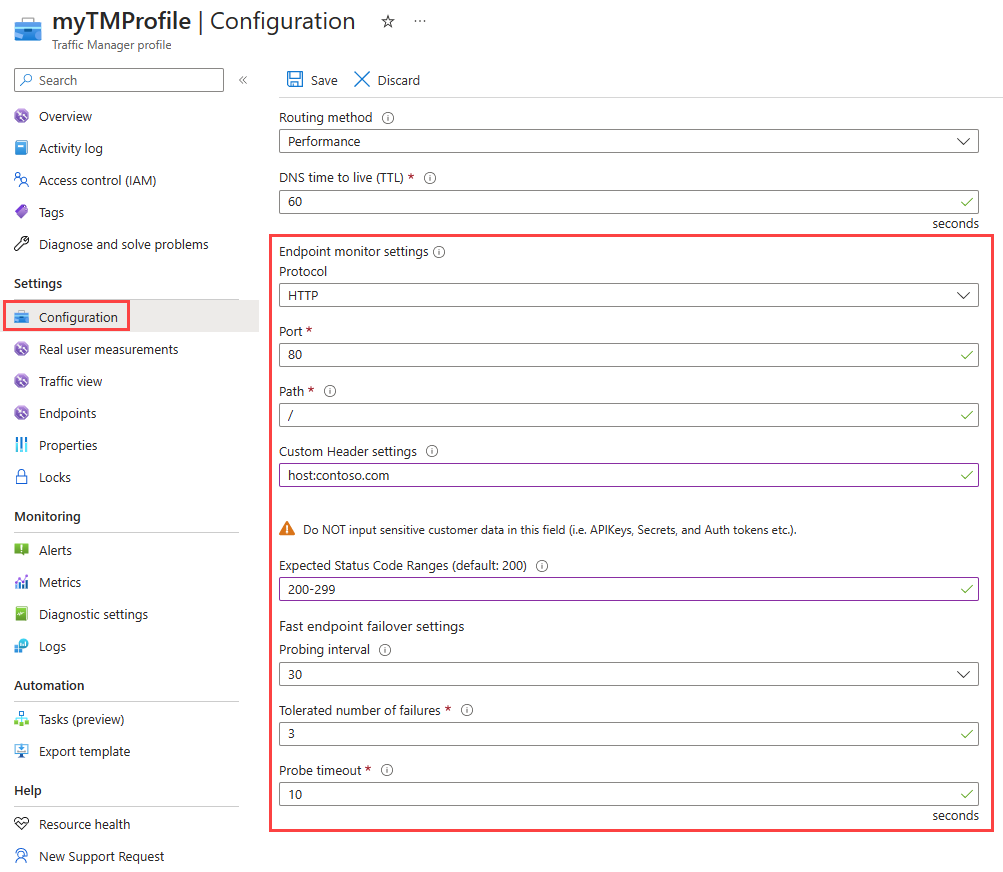
Figura: Monitoraggio degli endpoint di Gestione traffico

Funzionamento del monitoraggio degli endpoint
Se il protocollo di monitoraggio è impostato su HTTP o HTTPS, l'agente di sondaggio di Gestione traffico esegue una richiesta GET all'endpoint usando il protocollo, la porta e il percorso relativo specificati. Un endpoint viene considerato integro se l'agente di prova riceve una risposta da 200-OK o una delle risposte configurate negli intervalli di codice di stato previsti. Se la risposta è un valore diverso o non viene ricevuta alcuna risposta entro il periodo di timeout, l'agente di sondaggio di Gestione traffico riprova in base all'impostazione del numero di errori tollerati. Se questa impostazione è 0, non vengono eseguiti nuovi tentativi. L'endpoint è contrassegnato come non integro se il numero di errori consecutivi è superiore al numero di errori tollerati .
Se il protocollo di monitoraggio è TCP, l'agente di sondaggio di Gestione traffico crea una richiesta di connessione TCP usando la porta specificata. Se l'endpoint risponde alla richiesta con una risposta per stabilire la connessione, tale controllo di integrità viene contrassegnato come esito positivo. L'agente di sondaggio di Gestione traffico reimposta la connessione TCP. Nei casi in cui la risposta è un valore diverso o nessuna risposta viene ricevuta entro il periodo di timeout, l'agente di verifica del traffico esegue nuovamente il ripristino in base al numero tollerato di errori . Se questa impostazione è 0, non vengono eseguiti nuovi tentativi. Se il numero di errori consecutivi è superiore al numero tollerabile di impostazione degli errori , tale endpoint è contrassegnato come non integro.
In tutti i casi, Gestione traffico esegue il sondaggio da più posizioni. L'errore consecutivo determina cosa succede all'interno di ogni area. Per questo motivo gli endpoint ricevono probe di integrità da Gestione traffico con una frequenza maggiore rispetto all'impostazione usata per Intervallo sondaggio.
Nota
Per il protocollo di monitoraggio HTTP o HTTPS, una pratica comune sul lato endpoint consiste nell'implementare una pagina personalizzata all'interno dell'applicazione, ad esempio /health.aspx. Usando questo percorso per il monitoraggio, è possibile eseguire controlli specifici dell'applicazione, ad esempio il controllo dei contatori delle prestazioni o la verifica della disponibilità del database. In base a questi controlli personalizzati, la pagina restituisce un codice di stato HTTP appropriato.
Tutti gli endpoint in un profilo di Gestione traffico condividono le impostazioni di monitoraggio. Se è necessario usare impostazioni di monitoraggio diverse per i vari endpoint, è possibile creare i profili nidificati di Gestione traffico.
Stato di endpoint e profili
Gli endpoint e i profili di Gestione traffico possono essere abilitati e disabilitati. Tuttavia, una modifica dello stato dell'endpoint potrebbe verificarsi anche a causa delle impostazioni e dei processi automatizzati di Gestione traffico.
Stato endpoint
È possibile abilitare o disabilitare un endpoint specifico. Il servizio sottostante, che potrebbe essere ancora integro, non è interessato. La modifica dello stato dell'endpoint controlla la disponibilità dell'endpoint nel profilo di Gestione traffico. Quando uno stato dell'endpoint è disabilitato, Gestione traffico non controlla l'integrità e l'endpoint non è incluso in una risposta DNS.
Stato profilo
Usando l'impostazione dello stato del profilo è possibile abilitare o disabilitare un profilo specifico. Mentre lo stato dell'endpoint interessa un solo endpoint, lo stato del profilo interessa l'intero profilo, che include tutti gli endpoint. Quando si disabilita un profilo, gli endpoint non vengono controllati per l'integrità e non sono inclusi endpoint in una risposta DNS. Viene restituito un codice di risposta NXDOMAIN per la query DNS.
Endpoint monitor status (Stato monitoraggio endpoint)
Il valore relativo allo stato di monitoraggio dell'endpoint viene generato da Gestione traffico per indicare lo stato corrente dell'endpoint. Non è possibile modificare questa impostazione manualmente. Lo stato del monitoraggio dell'endpoint è una combinazione dei risultati del monitoraggio dell'endpoint e dello stato dell'endpoint configurato. La tabella seguente indica i valori possibili dello stato di monitoraggio degli endpoint:
| Stato profilo | Stato endpoint | Endpoint monitor status (Stato monitoraggio endpoint) | Note |
|---|---|---|---|
| Disabled | Attivato | Inactive | Il profilo è stato disabilitato. Anche se lo stato dell'endpoint è Enabled, se lo stato del profilo è Disabled, quest'ultimo avrà la precedenza. Gli endpoint nei profili disabilitati non vengono monitorati. Per la query DNS viene restituito un codice di risposta NXDOMAIN. |
| <qualsiasi> | Disabled | Disabled | L'endpoint è stato disabilitato. Gli endpoint disabilitati non vengono monitorati. L'endpoint non è incluso nelle risposte DNS, come ad esempio non riceve il traffico. |
| Attivato | Attivato | Online | L'endpoint è monitorato e integro. È incluso nelle risposte DNS e può ricevere il traffico. |
| Attivato | Attivato | Degraded | I controlli di integrità del monitoraggio dell'endpoint hanno esito negativo. L'endpoint non è incluso nelle risposte DNS e non riceve il traffico. Un'eccezione è se tutti gli endpoint sono degradati. In caso contrario, tutti vengono considerati restituiti nella risposta alla query. |
| Attivato | Attivato | CheckingEndpoint | L'endpoint viene monitorato, ma i risultati del primo probe non sono ancora stati ricevuti. CheckingEndpoint è un stato temporaneo che in genere si verifica immediatamente dopo l'aggiunta o l'abilitazione di un endpoint nel profilo. Un endpoint con questo stato viene incluso nelle risposte DNS e può ricevere traffico. |
| Attivato | Attivato | Arrestato | L'app Web a cui punta l'endpoint non è in esecuzione. Controllare le impostazioni dell'app Web. Questo stato può verificarsi anche se l'endpoint è di tipo endpoint annidato e il profilo figlio viene disabilitato o inattivo. Un endpoint con stato arrestato non viene monitorato. Non è incluso nelle risposte DNS e non riceve il traffico. Un'eccezione è se tutti gli endpoint sono degradati. In caso contrario, tutti vengono considerati restituiti nella risposta alla query. |
| Attivato | Attivato | Non monitorato | L'endpoint è configurato per gestire sempre il traffico. I controlli di integrità non sono abilitati. |
Per informazioni dettagliate sul modo in cui viene calcolato lo stato del monitoraggio degli endpoint per gli endpoint annidati, vedere Profili di Gestione traffico annidati.
Nota
Uno stato di monitoraggio dell'endpoint di tipo Interrotto può verificarsi nel servizio app se l'applicazione Web non è in esecuzione nel livello Standard o superiore. Per altre informazioni, vedere Integrazione di Gestione traffico con il servizio app.
Stato monitoraggio profilo
Lo stato di monitoraggio del profilo è una combinazione dei valori relativi allo stato del profilo configurato e allo stato di monitoraggio di tutti gli endpoint. I valori possibili sono illustrati nella tabella seguente:
| Stato profilo (come configurato) | Endpoint monitor status (Stato monitoraggio endpoint) | Stato monitoraggio profilo | Note |
|---|---|---|---|
| Disabled | <qualsiasi> o un profilo senza endpoint definiti. | Disabled | Il profilo è stato disabilitato. |
| Attivato | Almeno un endpoint è associato allo stato Degraded. | Degraded | Esaminare i valori di stato dei singoli endpoint per determinare quali endpoint richiedono attenzione. |
| Attivato | Almeno un endpoint è associato allo stato Online. Nessun endpoint presenta lo stato Degraded. | Online | Il servizio sta accettando il traffico. Non è richiesta alcuna azione ulteriore. |
| Attivato | Almeno un endpoint è associato allo stato CheckingEndpoint. Nessun endpoint presenta lo stato Online o Degraded. | CheckingEndpoints | Questo stato di transizione si verifica quando un profilo viene creato o abilitato. Viene verificata l'integrità dell'endpoint per la prima volta. |
| Attivato | Tutti gli endpoint del profilo presentano lo stato Disabled o Stopped oppure nel profilo non sono definiti endpoint. | Inactive | Non ci sono endpoint attivi, ma il profilo presenta lo stato Enabled. |
Failover e ripristino degli endpoint
Gestione traffico verifica periodicamente l'integrità di ogni endpoint, inclusi gli endpoint non integri. Rileva quando un endpoint diventa integro e lo reinserisce nella rotazione.
Un endpoint non è integro quando si verifica uno degli eventi seguenti:
- Se il protocollo di monitoraggio è HTTP o HTTPS:
- Risposta non 200 o risposta che non include l'intervallo di stato specificato nell'impostazione Intervalli di codice di stato previsti ricevuti . (Incluso un codice 2xx diverso o un reindirizzamento 301/302).
- Se il protocollo di monitoraggio è TCP:
- Una risposta diversa da ACK o SYN-ACK viene ricevuta in risposta alla richiesta SYN inviata da Gestione traffico per tentare una connessione.
- Timeout.
- Qualsiasi altro problema di connessione che determina l'irraggiungibilità dell'endpoint.
Per altre informazioni sulla risoluzione dei problemi relativi ai controlli non riusciti, vedere Risoluzione dei problemi relativi allo stato danneggiato in Gestione traffico di Azure.
La sequenza temporale nella figura seguente è una descrizione dettagliata del processo di monitoraggio dell'endpoint di Gestione traffico con le impostazioni seguenti:
- Il protocollo di monitoraggio è HTTP.
- L'intervallo di probing è di 30 secondi.
- Il numero di errori tollerati è 3.
- Il valore di timeout è di 10 secondi.
- IL TTL DNS è di 30 secondi.
 Figura: Failover dell'endpoint di Gestione traffico e sequenza di ripristino
Figura: Failover dell'endpoint di Gestione traffico e sequenza di ripristino
GET. Per ogni endpoint, il sistema di monitoraggio di Gestione traffico esegue una richiesta GET nel percorso specificato nelle impostazioni di monitoraggio.
200 OK o intervallo di codice personalizzato specificato impostazioni di monitoraggio del profilo di Gestione traffico. Il sistema di monitoraggio prevede la restituzione di un codice di stato HTTP 200 OK o di un codice di stato nell'intervallo specificato nelle impostazioni di monitoraggio entro 10 secondi. Alla ricezione della risposta, il sistema riconosce la disponibilità del servizio.
30 secondi tra i controlli. Il controllo di integrità dell'endpoint viene ripetuto ogni 30 secondi.
Servizio non disponibile. il servizio diventa non disponibile. Gestione traffico non saprà fino alla successiva verifica dell'integrità.
Tenta di accedere al percorso di monitoraggio. Il sistema di monitoraggio esegue una richiesta GET, ma non riceve una risposta entro il periodo di timeout di 10 secondi. Il sistema esegue quindi altri tre tentativi a intervalli di 30 secondi. Se uno dei tentativi ha esito positivo, il conteggio viene azzerato.
Stato impostato su Degraded. al quarto errore consecutivo, il sistema di monitoraggio contrassegna lo stato dell'endpoint non disponibile come Degraded.
Traffico deviato ad altri endpoint. vengono aggiornati i server dei nomi DNS di Gestione traffico, che non restituisce più l'endpoint in risposta alle query DNS. Le nuove connessioni vengono indirizzate ad altri endpoint disponibili. Tuttavia, le risposte DNS precedenti che includono questo endpoint potrebbero comunque essere memorizzate nella cache da server DNS ricorsivi e client DNS. I client continuano a usare l'endpoint fino alla scadenza della cache DNS. Quando la cache DNS scade i client eseguono nuove query DNS, indirizzate a endpoint diversi. La durata della cache è determinata dall'impostazione TTL definita nel profilo di Gestione traffico, ad esempio 30 secondi.
I controlli di integrità proseguono. Gestione traffico continua a controllare l'integrità dell'endpoint finché si trova nello stato Degraded. Gestione traffico rileva quando l'endpoint ritorna integro.
Il servizio ritorna online. il servizio diventa disponibile. L'endpoint mantiene lo stato degradato in Gestione traffico fino a quando il sistema di monitoraggio esegue il controllo integrità successivo.
Ripresa del traffico al servizio. Gestione traffico invia una richiesta GET e riceve una risposta di stato 200 OK, Il servizio è tornato a uno stato integro. I server dei nomi di Gestione traffico vengono aggiornati di nuovo e iniziano a distribuire il nome DNS del servizio nelle risposte DNS. Il traffico restituisce all'endpoint come risposte DNS memorizzate nella cache che restituiscono altri endpoint scade e, quando le connessioni esistenti ad altri endpoint terminano.
Importante
Gestione traffico distribuisce più probe da più posizioni per ogni endpoint. Più probe aumentano la resilienza per il monitoraggio degli endpoint. Gestione traffico aggrega l'integrità media dei probe anziché basarsi su un'istanza di probe singolare. La ridondanza del sistema di ricerca è in base alla progettazione. I valori degli endpoint devono essere esaminati in modo olistico e non per probe. Il numero visualizzato per l'integrità del probe è una media. Lo stato deve essere un problema solo se meno del 50% (0,5) dei probe pubblicano uno stato superiore .
Nota
Poiché lavora a livello di DNS, Gestione traffico non può influenzare le connessioni esistenti verso qualsiasi endpoint. Quando indirizza il traffico tra gli endpoint, modificando le impostazioni del profilo oppure durante il failover o il failback, Gestione traffico indirizza le nuove connessioni agli endpoint disponibili. Altri endpoint potrebbero continuare a ricevere il traffico tramite connessioni esistenti fino alla chiusura di tali sessioni. Per consentire lo smaltimento del traffico dalle connessioni esistenti, le applicazioni devono limitare la durata della sessione usata con ogni endpoint.
Metodi di routing del traffico
Quando un endpoint ha uno stato degradato, non viene più restituito in risposta alle query DNS. Viene invece scelto e restituito un endpoint alternativo. Il metodo di routing del traffico configurato nel profilo determina il modo in cui viene scelto l'endpoint alternativo.
- Priorità. Gli endpoint stabiliscono un elenco con priorità. Viene sempre restituito il primo endpoint disponibile nell'elenco. Se lo stato di un endpoint è Degraded, viene restituito il successivo endpoint disponibile.
- Ponderato. Tutti gli endpoint disponibili vengono scelti in modo casuale in base ai pesi assegnati e ai pesi degli altri endpoint disponibili.
- Prestazioni. Viene restituito l'endpoint più vicino all'utente finale. Se l'endpoint non è disponibile, Gestione traffico sposta il traffico sugli endpoint dell'area di Azure più vicina. È possibile configurare piani di failover alternativi per il routing del traffico con il metodo Prestazioni usando profili di Gestione traffico nidificati.
- Geografico. L'endpoint mappato per gestire la posizione geografica (in base agli indirizzi IP della richiesta di query) viene restituito. Se tale endpoint non è disponibile, un altro endpoint non è selezionato per eseguire il failover, poiché una posizione geografica può essere mappata solo a un endpoint in un profilo. Altre informazioni sono disponibili nelle domande frequenti. Come procedura consigliata, quando si usa il routing geografico, si consiglia ai clienti di usare profili di Gestione traffico annidati con più di un endpoint come endpoint del profilo.
- MultiValue. Vengono restituiti più endpoint associati agli indirizzi IPv4 e IPv6. Quando viene ricevuta una query per questo profilo, gli endpoint integri vengono restituiti in base al numero massimo di record nel valore di risposta specificato. Il numero predefinito di risposte è due endpoint.
- Subnet. Viene restituito l'endpoint mappato a un set di intervalli di indirizzi IP. Quando viene ricevuta una richiesta dall'indirizzo IP, l'endpoint restituito è quello mappato per tale indirizzo IP.
Per altre informazioni, vedere Metodi di routing del traffico di Gestione traffico.
Nota
Un'eccezione al normale comportamento del routing del traffico si verifica quando lo stato di tutti gli endpoint idonei risulta Degraded. Gestione traffico effettua un tentativo e risponde come se tutti gli endpoint con stato Degraded fossero in realtà Online, una condizione preferibile all'alternativa di non restituire endpoint nella risposta DNS. Gli endpoint disabilitati o arrestati non vengono monitorati, di conseguenza non sono considerati idonei per il traffico.
Questa condizione è in genere causata da una configurazione non corretta del servizio, ad esempio:
- Un elenco di controllo di accesso [ACL] che blocca i controlli di integrità di Gestione traffico.
- Una configurazione non corretta del protocollo o della porta di monitoraggio nel profilo di Gestione traffico.
La conseguenza di questo comportamento è che se i controlli di integrità di Gestione traffico non sono configurati in modo appropriato, dal routing del traffico potrebbe sembrare che Gestione traffico funzioni correttamente. In questo caso il failover degli endpoint non viene tuttavia eseguito, con ripercussioni sulla disponibilità complessiva dell'applicazione. È importante verificare che il profilo indichi lo stato Online e non Degraded. Lo stato Online indica che i controlli di integrità di Gestione traffico funzionano come previsto.
Per altre informazioni sulla risoluzione dei problemi relativi ai controlli di integrità non riusciti, vedere Risoluzione dei problemi relativi allo stato danneggiato in Gestione traffico di Azure.
Abilitare o disabilitare i controlli di integrità
Gestione traffico di Azure consente anche di configurare i controlli di integrità degli endpoint da abilitare o disabilitare. Per disabilitare il monitoraggio, scegliere l'opzione per gestire sempre il traffico.
Esistono due impostazioni disponibili per i controlli di integrità:
- Abilitare (controlli di integrità). Il traffico viene servito all'endpoint in base all'integrità. Questa è l'impostazione predefinita.
- Servire sempre il traffico. Questa impostazione disabilita i controlli di integrità.
Sempre serve
Quando viene selezionato Sempre il traffico di servizio , il monitoraggio viene ignorato e il traffico viene sempre inviato a un endpoint. Lo stato del monitoraggio dell'endpoint visualizzato è Unmonitored.
Per abilitare Always Serve:
- Selezionare Endpoint nella sezione Impostazioni del pannello Profilo di Gestione traffico.
- Selezionare l'endpoint da configurare.
- In Controlli di integrità scegliere Sempre servire il traffico.
- Selezionare Salva.
Vedere l'esempio seguente:

Nota
- I controlli di integrità non possono essere disabilitati nei profili annidati di Gestione traffico.
- Per configurare i controlli di integrità, è necessario abilitare un endpoint.
- L'abilitazione e la disabilitazione di un endpoint non reimpostano la configurazione dei controlli di integrità.
- Gli endpoint configurati per gestire sempre il traffico vengono fatturati per i controlli di integrità di base.
Domande frequenti
- Gestione traffico è resiliente rispetto agli errori di area di Azure?
- In che modo la scelta della posizione del gruppo di risorse si ripercuote su Gestione traffico?
- Come si determina lo stato di integrità corrente di ogni endpoint?
- È possibile monitorare gli endpoint HTTPS?
- Si usa un indirizzo IP o un nome DNS quando si aggiunge un endpoint?
- Quali tipi di indirizzi IP è possibile usare quando si aggiunge un endpoint?
- È possibile usare tipi di indirizzamento diversi per gli endpoint all'interno di un singolo profilo?
- Cosa accade quando il tipo di record di una query in ingresso è diverso dal tipo di record associato al tipo di indirizzamento degli endpoint?
- È possibile usare un profilo con endpoint con indirizzi IPv4 o IPv6 in un profilo annidato?
- È stato arrestato un endpoint dell'applicazione Web nel profilo di Gestione traffico, ma non si riceve alcun traffico anche dopo il riavvio. Come è possibile risolvere questo problema?
- È possibile usare Gestione traffico anche se l'applicazione non dispone del supporto per HTTP o HTTPS?
- Quali sono le risposte specifiche richieste dall'endpoint quando si usa il monitoraggio TCP?
- Con quale velocità Gestione traffico sposta gli utenti da un endpoint considerato non integro?
- Come specificare diverse impostazioni di monitoraggio per i diversi endpoint in un profilo?
- Come si assegnano le intestazioni HTTP ai controlli di integrità di Gestione traffico per gli endpoint?
- Quali intestazione host viene usata per i controlli di integrità degli endpoint?
- Quali sono gli indirizzi IP da cui si originano i controlli di integrità?
- Qual è il numero di controlli di integrità previsto per un endpoint da parte di Gestione traffico?
- Come si possono ricevere notifiche se uno degli endpoint risulta inattivo?
Passaggi successivi
- Informazioni sul funzionamento di Gestione traffico
- Ulteriori informazioni sui metodi di routing del traffico supportati da Gestione traffico
- Informazioni su come creare un profilo di Gestione traffico
- Risoluzione dei problemi relativi allo stato Degraded di un endpoint di Gestione traffico