Configurare Pacemaker in Red Hat Enterprise Linux in Azure
Questo articolo descrive come configurare un cluster Pacemaker di base in Red Hat Enterprise Server (RHEL). Le istruzioni riguardano RHEL 7, RHEL 8 e RHEL 9.
Prerequisiti
Leggere prima di tutto i documenti e le note SAP seguenti:
- Nota SAP 1928533, che include:
- Elenco delle dimensioni delle macchine virtuali di Azure supportate per la distribuzione del software SAP.
- Informazioni importanti sulla capacità per le dimensioni delle macchine virtuali di Azure.
- Combinazioni di database e software SAP e sistema operativo supportati.
- Versione del kernel SAP richiesta per Windows e Linux in Microsoft Azure.
- La nota SAP 2015553 elenca i prerequisiti per le distribuzioni di software SAP supportate da SAP in Azure.
- Nota SAP 2002167 consiglia le impostazioni del sistema operativo per Red Hat Enterprise Linux.
- Nota SAP 3108316 consiglia le impostazioni del sistema operativo per Red Hat Enterprise Linux 9.x.
- Nota SAP 2009879 include le linee guida di SAP HANA per Red Hat Enterprise Linux.
- Nota SAP 3108302 include le linee guida di SAP HANA per Red Hat Enterprise Linux 9.x.
- La nota SAP 2178632 contiene informazioni dettagliate su tutte le metriche di monitoraggio segnalate per SAP in Azure.
- La nota SAP 2191498 contiene la versione dell'agente host SAP per Linux necessaria in Azure.
- La nota SAP 2243692 contiene informazioni sulle licenze SAP in Linux in Azure.
- Nota SAP 1999351 contiene altre informazioni sulla risoluzione dei problemi per l'estensione di monitoraggio avanzato di Azure per SAP.
- Community WIKI SAP contiene tutte le note su SAP necessarie per Linux.
- Pianificazione e implementazione di Macchine virtuali di Azure per SAP in Linux
- Distribuzione di Macchine virtuali di Microsoft Azure per SAP in Linux (questo articolo)
- Distribuzione DBMS di Macchine virtuali di Azure per SAP in Linux
- Replica di sistema SAP HANA nel cluster Pacemaker
- Documentazione generale di RHEL:
- Documentazione di RHEL specifica di Azure:
- Criteri di supporto per cluster RHEL a disponibilità elevata - Microsoft Azure Macchine virtuali come membri del cluster
- Installing and Configuring a Red Hat Enterprise Linux 7.4 (and later) High-Availability Cluster on Microsoft Azure (Installazione e configurazione di un cluster Red Hat Enterprise Linux 7.4 e versioni successive a disponibilità elevata in Microsoft Azure)
- Considerazioni sull'adozione di RHEL 8 - Disponibilità elevata e cluster
- Configurare SAP S/4HANA ASCS/ERS con il Server di accodamento autonomo 2 (ENSA2) in Pacemaker in RHEL 7.6
- RHEL per le offerte SAP in Azure
Installazione del cluster
Nota
Red Hat non supporta un watchdog emulato da software. Red Hat non supporta SBD sulle piattaforme cloud. Per altre informazioni, vedere Criteri di supporto per cluster RHEL a disponibilità elevata - sbd e fence_sbd.
L'unico meccanismo di isolamento supportato per i cluster Pacemaker RHEL in Azure è un agente di isolamento di Azure.
Gli elementi seguenti sono preceduti da:
- [A]: applicabile a tutti i nodi
- [1]: applicabile solo al nodo 1
- [2]: applicabile solo al nodo 2
Le differenze nei comandi o nella configurazione tra RHEL 7 e RHEL 8/RHEL 9 sono contrassegnate nel documento.
[A] Registra. Questo passaggio è facoltativo. Se si usano immagini abilitate per la disponibilità elevata di SAP RHEL, questo passaggio non è obbligatorio.
Ad esempio, se si esegue la distribuzione in RHEL 7, registrare la macchina virtuale e collegarla a un pool che contiene repository per RHEL 7.
sudo subscription-manager register # List the available pools sudo subscription-manager list --available --matches '*SAP*' sudo subscription-manager attach --pool=<pool id>Quando si collega un pool a un'immagine RHEL con pagamento in base al consumo di Azure Marketplace, l'utilizzo di RHEL viene effettivamente raddoppiato. L'immagine con pagamento in base al consumo viene fatturata una volta e una volta per il diritto RHEL nel pool collegato. Per attenuare questa situazione, Azure offre ora immagini RHEL bring-your-own-subscription. Per altre informazioni, vedere Immagini di Azure bring-your-own-subscription di Red Hat Enterprise Linux.
[A] Abilitare RHEL per i repository SAP. Questo passaggio è facoltativo. Se si usano immagini abilitate per la disponibilità elevata di SAP RHEL, questo passaggio non è obbligatorio.
Per installare i pacchetti necessari in RHEL 7, abilitare i repository seguenti:
sudo subscription-manager repos --disable "*" sudo subscription-manager repos --enable=rhel-7-server-rpms sudo subscription-manager repos --enable=rhel-ha-for-rhel-7-server-rpms sudo subscription-manager repos --enable=rhel-sap-for-rhel-7-server-rpms sudo subscription-manager repos --enable=rhel-ha-for-rhel-7-server-eus-rpms[A] Installare il componente aggiuntivo RHEL a disponibilità elevata.
sudo yum install -y pcs pacemaker fence-agents-azure-arm nmap-ncatImportante
È consigliabile usare le versioni seguenti dell'agente di isolamento di Azure (o versioni successive) per consentire ai clienti di trarre vantaggio da tempi di failover più rapidi, se un arresto della risorsa ha esito negativo o i nodi del cluster non possono più comunicare tra loro:
RHEL 7.7 o versione successiva usa la versione più recente disponibile del pacchetto di agenti di isolamento.
RHEL 7.6: fence-agents-4.2.1-11.el7_6.8
RHEL 7.5: fence-agents-4.0.11-86.el7_5.8
RHEL 7.4: fence-agents-4.0.11-66.el7_4.12
Per altre informazioni, vedere La macchina virtuale di Azure in esecuzione come membro del cluster RHEL a disponibilità elevata richiede molto tempo per essere delimitata o si verifica un errore o un timeout di isolamento prima dell'arresto della macchina virtuale.
Importante
È consigliabile usare le versioni seguenti dell'agente di isolamento di Azure (o versioni successive) per i clienti che vogliono usare le identità gestite per le risorse di Azure anziché i nomi delle entità servizio per l'agente di isolamento:
RHEL 8.4: fence-agents-4.2.1-54.el8.
RHEL 8.2: fence-agents-4.2.1-41.el8_2.4
RHEL 8.1: fence-agents-4.2.1-30.el8_1.4
RHEL 7.9: fence-agents-4.2.1-41.el7_9.4.
Importante
In RHEL 9 è consigliabile usare le versioni del pacchetto seguenti (o versioni successive) per evitare problemi con l'agente di isolamento di Azure:
fence-agents-4.10.0-20.el9_0.7
fence-agents-common-4.10.0-20.el9_0.6
ha-cloud-support-4.10.0-20.el9_0.6.x86_64.rpm
Controllare la versione dell'agente di isolamento di Azure. Se necessario, aggiornarlo alla versione minima richiesta o successiva.
# Check the version of the Azure Fence Agent sudo yum info fence-agents-azure-armImportante
Se è necessario aggiornare l'agente di isolamento di Azure e, se si usa un ruolo personalizzato, assicurarsi di aggiornare il ruolo personalizzato per includere l'azione powerOff. Per altre informazioni, vedere Creare un ruolo personalizzato per l'agente di isolamento.
Se si esegue la distribuzione in RHEL 9, installare anche gli agenti di risorse per la distribuzione cloud.
sudo yum install -y resource-agents-cloud[A] Configurare la risoluzione dei nomi host.
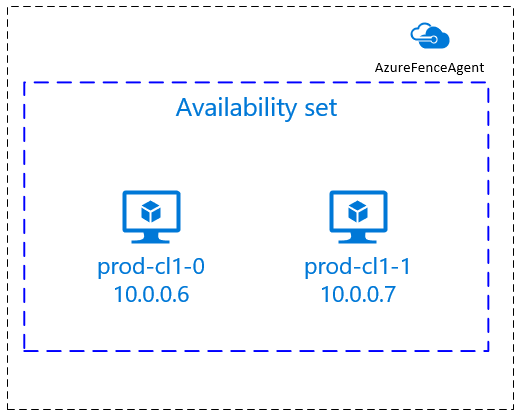
È possibile usare un server DNS o modificare il
/etc/hostsfile in tutti i nodi. In questo esempio viene illustrato come usare il/etc/hostsfile . Sostituire l'indirizzo IP e il nome host nei comandi seguenti.Importante
Se si usano nomi host nella configurazione del cluster, è fondamentale avere una risoluzione affidabile dei nomi host. La comunicazione del cluster ha esito negativo se i nomi non sono disponibili, il che può causare ritardi di failover del cluster.
Il vantaggio dell'uso
/etc/hostsè che il cluster diventa indipendente dal DNS, che potrebbe essere anche un singolo punto di errore.sudo vi /etc/hostsInserire le righe seguenti in
/etc/hosts. Modificare l'indirizzo IP e il nome host in modo che corrispondano all'ambiente.# IP address of the first cluster node 10.0.0.6 prod-cl1-0 # IP address of the second cluster node 10.0.0.7 prod-cl1-1[A] Modificare la
haclusterpassword con la stessa password.sudo passwd hacluster[A] Aggiungere regole del firewall per Pacemaker.
Aggiungere le seguenti regole del firewall per tutte le comunicazioni del cluster tra i nodi del cluster.
sudo firewall-cmd --add-service=high-availability --permanent sudo firewall-cmd --add-service=high-availability[A] Abilitare i servizi cluster di base.
Eseguire i comandi seguenti per abilitare il servizio Pacemaker e avviarlo.
sudo systemctl start pcsd.service sudo systemctl enable pcsd.service[1] Creare un cluster Pacemaker.
Eseguire i comandi seguenti per autenticare i nodi e creare il cluster. Impostare il token su 30000 per consentire la manutenzione della memoria. Per altre informazioni, vedere questo articolo per Linux.
Se si sta creando un cluster in RHEL 7.x, usare i comandi seguenti:
sudo pcs cluster auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup --name nw1-azr prod-cl1-0 prod-cl1-1 --token 30000 sudo pcs cluster start --allSe si sta creando un cluster in RHEL 8.x/RHEL 9.x, usare i comandi seguenti:
sudo pcs host auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup nw1-azr prod-cl1-0 prod-cl1-1 totem token=30000 sudo pcs cluster start --allVerificare lo stato del cluster eseguendo il comando seguente:
# Run the following command until the status of both nodes is online sudo pcs status # Cluster name: nw1-azr # WARNING: no stonith devices and stonith-enabled is not false # Stack: corosync # Current DC: prod-cl1-1 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum # Last updated: Fri Aug 17 09:18:24 2018 # Last change: Fri Aug 17 09:17:46 2018 by hacluster via crmd on prod-cl1-1 # # 2 nodes configured # 0 resources configured # # Online: [ prod-cl1-0 prod-cl1-1 ] # # No resources # # Daemon Status: # corosync: active/disabled # pacemaker: active/disabled # pcsd: active/enabled[A] Impostare i voti previsti.
# Check the quorum votes pcs quorum status # If the quorum votes are not set to 2, execute the next command sudo pcs quorum expected-votes 2Suggerimento
Se si sta creando un cluster multinodo, ovvero un cluster con più di due nodi, non impostare i voti su 2.
[1] Consenti azioni di isolamento simultanee.
sudo pcs property set concurrent-fencing=true
Creare un dispositivo di isolamento
Il dispositivo di isolamento usa un'identità gestita per la risorsa di Azure o un'entità servizio per l'autorizzazione in Azure.
Per creare un'identità gestita , creare un'identità gestita assegnata dal sistema per ogni macchina virtuale nel cluster. Se esiste già un'identità gestita assegnata dal sistema, viene usata. Al momento non usare identità gestite assegnate dall'utente con Pacemaker. Un dispositivo di isolamento, basato sull'identità gestita, è supportato in RHEL 7.9 e RHEL 8.x/RHEL 9.x.
[1] Creare un ruolo personalizzato per l'agente di isolamento
Sia l'identità gestita che l'entità servizio non dispongono delle autorizzazioni per accedere alle risorse di Azure per impostazione predefinita. È necessario concedere all'identità gestita o all'entità servizio le autorizzazioni per avviare e arrestare (spegnere) tutte le macchine virtuali del cluster. Se non è già stato creato il ruolo personalizzato, è possibile crearlo usando PowerShell o l'interfaccia della riga di comando di Azure.
Per il file di input usare il contenuto seguente. È necessario adattare il contenuto alle sottoscrizioni, ovvero sostituire xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx e yyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy con gli ID della sottoscrizione. Se si dispone di una sola sottoscrizione, rimuovere la seconda voce in AssignableScopes.
{
"Name": "Linux Fence Agent Role",
"description": "Allows to power-off and start virtual machines",
"assignableScopes": [
"/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"/subscriptions/yyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy"
],
"actions": [
"Microsoft.Compute/*/read",
"Microsoft.Compute/virtualMachines/powerOff/action",
"Microsoft.Compute/virtualMachines/start/action"
],
"notActions": [],
"dataActions": [],
"notDataActions": []
}
[A] Assegnare il ruolo personalizzato
Usare l'identità gestita o l'entità servizio.
Assegnare il ruolo Linux Fence Agent Role personalizzato creato nell'ultima sezione a ogni identità gestita delle macchine virtuali del cluster. Ogni identità gestita assegnata dal sistema della macchina virtuale richiede il ruolo assegnato per ogni risorsa della macchina virtuale del cluster. Per altre informazioni, vedere Assegnare un accesso all'identità gestita a una risorsa usando il portale di Azure. Verificare che l'assegnazione di ruolo dell'identità gestita di ogni macchina virtuale contenga tutte le macchine virtuali del cluster.
Importante
Tenere presente che l'assegnazione e la rimozione dell'autorizzazione con identità gestite possono essere posticipate fino a quando non sono effettive.
[1] Creare i dispositivi di isolamento
Dopo aver modificato le autorizzazioni per le macchine virtuali, è possibile configurare i dispositivi di isolamento nel cluster.
sudo pcs property set stonith-timeout=900
Nota
L'opzione pcmk_host_map è necessaria solo nel comando se i nomi host RHEL e i nomi delle macchine virtuali di Azure non sono identici. Specificare il mapping nel formato nome host:vm-name.
Vedere la sezione in grassetto nel comando. Per altre informazioni, vedere Quale formato usare per specificare i mapping dei nodi ai dispositivi di isolamento in pcmk_host_map?.
Per RHEL 7.x, usare il comando seguente per configurare il dispositivo di isolamento:
sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \
subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \
power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \
op monitor interval=3600
Per RHEL 8.x/9.x, usare il comando seguente per configurare il dispositivo di isolamento:
# Run following command if you are setting up fence agent on (two-node cluster and pacemaker version greater than 2.0.4-6.el8) OR (HANA scale out)
sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \
subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \
power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 \
op monitor interval=3600
# Run following command if you are setting up fence agent on (two-node cluster and pacemaker version less than 2.0.4-6.el8)
sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \
subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \
power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \
op monitor interval=3600
Se si usa un dispositivo di isolamento basato sulla configurazione dell'entità servizio, vedere Passare da SPN a MSI per cluster Pacemaker usando l'isolamento di Azure e informazioni su come eseguire la conversione alla configurazione dell'identità gestita.
Suggerimento
- Per evitare corse di isolamento all'interno di un cluster pacemaker a due nodi, è possibile configurare la proprietà del
priority-fencing-delaycluster. Questa proprietà introduce un ulteriore ritardo nell'isolamento di un nodo con priorità totale più elevata quando si verifica uno scenario split-brain. Per altre informazioni, vedere Can Pacemaker fence the cluster node with the fewest running resources?. - La proprietà
priority-fencing-delayè applicabile per Pacemaker versione 2.0.4-6.el8 o successiva e in un cluster a due nodi. Se si configura lapriority-fencing-delayproprietà del cluster, non è necessario impostare lapcmk_delay_maxproprietà . Tuttavia, se la versione di Pacemaker è minore di 2.0.4-6.el8, è necessario impostare lapcmk_delay_maxproprietà . - Per istruzioni su come impostare la proprietà del
priority-fencing-delaycluster, vedere i rispettivi documenti SAP ASCS/ERS e SAP HANA con scalabilità elevata.
Le operazioni di monitoraggio e isolamento vengono deserializzate. Di conseguenza, se è presente un'operazione di monitoraggio più lunga e un evento di isolamento simultaneo, non si verifica alcun ritardo per il failover del cluster perché l'operazione di monitoraggio è già in esecuzione.
[1] Abilitare l'uso di un dispositivo di isolamento
sudo pcs property set stonith-enabled=true
Suggerimento
L'agente di isolamento di Azure richiede la connettività in uscita agli endpoint pubblici. Per altre informazioni insieme alle possibili soluzioni, vedere Connettività degli endpoint pubblici per le macchine virtuali che usano il bilanciamento del carico interno standard.
Configurare Pacemaker per gli eventi pianificati di Azure
Azure offre eventi pianificati. Gli eventi pianificati vengono inviati tramite il servizio metadati e consentono all'applicazione di prepararsi per tali eventi.
L'agente azure-events-az di risorse Pacemaker monitora gli eventi di Azure pianificati. Se vengono rilevati eventi e l'agente risorse determina che è disponibile un altro nodo del cluster, imposta un attributo di integrità del cluster.
Quando l'attributo di integrità del cluster è impostato per un nodo, il vincolo di posizione viene attivato e tutte le risorse con nomi che non iniziano con health- vengono migrate dal nodo con l'evento pianificato. Dopo che il nodo del cluster interessato è libero di eseguire risorse del cluster, l'evento pianificato viene riconosciuto e può eseguirne l'azione, ad esempio un riavvio.
[A] Assicurarsi che il pacchetto per l'agente
azure-events-azsia già installato e aggiornato.RHEL 8.x: sudo dnf info resource-agents RHEL 9.x: sudo dnf info resource-agents-cloudRequisiti minimi per la versione:
- RHEL 8.4:
resource-agents-4.1.1-90.13 - RHEL 8.6:
resource-agents-4.9.0-16.9 - RHEL 8.8:
resource-agents-4.9.0-40.1 - RHEL 9.0:
resource-agents-cloud-4.10.0-9.6 - RHEL 9.2 e versioni successive:
resource-agents-cloud-4.10.0-34.1
- RHEL 8.4:
[1] Configurare le risorse in Pacemaker.
#Place the cluster in maintenance mode sudo pcs property set maintenance-mode=true[1] Impostare la strategia e il vincolo del nodo integrità del cluster Pacemaker.
sudo pcs property set node-health-strategy=custom sudo pcs constraint location 'regexp%!health-.*' \ rule score-attribute='#health-azure' \ defined '#uname'Importante
Non definire altre risorse nel cluster a partire dalle
health-risorse descritte nei passaggi successivi.[1] Impostare il valore iniziale degli attributi del cluster. Eseguire per ogni nodo del cluster e per ambienti con scalabilità orizzontale, inclusa la macchina virtuale di maggioranza.
sudo crm_attribute --node prod-cl1-0 --name '#health-azure' --update 0 sudo crm_attribute --node prod-cl1-1 --name '#health-azure' --update 0[1] Configurare le risorse in Pacemaker. Assicurarsi che le risorse inizino con
health-azure.sudo pcs resource create health-azure-events \ ocf:heartbeat:azure-events-az op monitor interval=10s sudo pcs resource clone health-azure-events allow-unhealthy-nodes=trueDisconnettere il cluster Pacemaker dalla modalità di manutenzione.
sudo pcs property set maintenance-mode=falseCancellare eventuali errori durante l'abilitazione e verificare che le
health-azure-eventsrisorse siano state avviate correttamente in tutti i nodi del cluster.sudo pcs resource cleanupL'esecuzione della prima query per gli eventi pianificati può richiedere fino a due minuti. I test pacemaker con eventi pianificati possono usare azioni di riavvio o ridistribuimento per le macchine virtuali del cluster. Per altre informazioni, vedere Eventi pianificati.
Configurazione facoltativa dell'isolamento
Suggerimento
Questa sezione è applicabile solo se si vuole configurare il dispositivo fence_kdumpspeciale di isolamento .
Se è necessario raccogliere informazioni di diagnostica all'interno della macchina virtuale, potrebbe essere utile configurare un altro dispositivo di isolamento in base all'agente fence_kdumpdi isolamento . L'agente fence_kdump può rilevare che un nodo ha immesso il ripristino anomalo del sistema kdump e può consentire il completamento del servizio di ripristino di arresto anomalo del sistema prima che vengano richiamati altri metodi di isolamento. Si noti che fence_kdump non è una sostituzione per i meccanismi di isolamento tradizionali, ad esempio l'agente di isolamento di Azure, quando si usano macchine virtuali di Azure.
Importante
Tenere presente che quando fence_kdump viene configurato come dispositivo di isolamento di primo livello, introduce ritardi nelle operazioni di isolamento e, rispettivamente, ritardi nel failover delle risorse dell'applicazione.
Se viene rilevato un dump di arresto anomalo del sistema, l'isolamento viene ritardato fino al completamento del servizio di ripristino di arresto anomalo del sistema. Se il nodo non riuscito non è raggiungibile o se non risponde, l'isolamento viene ritardato per tempo determinato, il numero configurato di iterazioni e il fence_kdump timeout. Per altre informazioni, vedere Ricerca per categorie configurare fence_kdump in un cluster Red Hat Pacemaker?.
Il timeout proposto fence_kdump potrebbe essere necessario adattarsi all'ambiente specifico.
È consigliabile configurare fence_kdump l'isolamento solo quando necessario per raccogliere la diagnostica all'interno della macchina virtuale e sempre in combinazione con i metodi di isolamento tradizionali, ad esempio l'agente di isolamento di Azure.
Gli articoli della Knowledge Base di Red Hat seguenti contengono informazioni importanti sulla configurazione dell'isolamento fence_kdump :
- Vedere Ricerca per categorie configurare fence_kdump in un cluster Red Hat Pacemaker?
- Vedere Come configurare/gestire i livelli di isolamento in un cluster RHEL con Pacemaker.
- Vedere fence_kdump ha esito negativo con "timeout dopo X secondi" in un cluster RHEL 6 o 7 a disponibilità elevata con kexec-tools precedenti alla 2.0.14.
- Per informazioni su come modificare il timeout predefinito, vedere Ricerca per categorie configurare kdump per l'uso con il componente aggiuntivo RHEL 6, 7, 8 HA?.
- Per informazioni su come ridurre il ritardo del failover quando si usa
fence_kdump, vedere È possibile ridurre il ritardo previsto del failover quando si aggiunge fence_kdump configurazione?
Eseguire i passaggi facoltativi seguenti per aggiungere fence_kdump come configurazione di isolamento di primo livello, oltre alla configurazione dell'agente di isolamento di Azure.
[A] Verificare che
kdumpsia attivo e configurato.systemctl is-active kdump # Expected result # active[A] Installare l'agente
fence_kdumpdi isolamento.yum install fence-agents-kdump[1] Creare un
fence_kdumpdispositivo di isolamento nel cluster.pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" timeout=30[1] Configurare i livelli di isolamento in modo che il
fence_kdumpmeccanismo di isolamento venga attivato per primo.pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" pcs stonith level add 1 prod-cl1-0 rsc_st_kdump pcs stonith level add 1 prod-cl1-1 rsc_st_kdump pcs stonith level add 2 prod-cl1-0 rsc_st_azure pcs stonith level add 2 prod-cl1-1 rsc_st_azure # Check the fencing level configuration pcs stonith level # Example output # Target: prod-cl1-0 # Level 1 - rsc_st_kdump # Level 2 - rsc_st_azure # Target: prod-cl1-1 # Level 1 - rsc_st_kdump # Level 2 - rsc_st_azure[A] Consentire le porte necessarie per
fence_kdumpattraverso il firewall.firewall-cmd --add-port=7410/udp firewall-cmd --add-port=7410/udp --permanent[A] Assicurarsi che il
initramfsfile di immagine contenga ifence_kdumpfile ehosts. Per altre informazioni, vedere Ricerca per categorie configurare fence_kdump in un cluster Red Hat Pacemaker?.lsinitrd /boot/initramfs-$(uname -r)kdump.img | egrep "fence|hosts" # Example output # -rw-r--r-- 1 root root 208 Jun 7 21:42 etc/hosts # -rwxr-xr-x 1 root root 15560 Jun 17 14:59 usr/libexec/fence_kdump_send[A] Eseguire la
fence_kdump_nodesconfigurazione in/etc/kdump.confper evitarefence_kdumperrori con un timeout per alcunekexec-toolsversioni. Per altre informazioni, vedere fence_kdump timeout quando fence_kdump_nodes non è specificato con kexec-tools versione 2.0.15 o successiva e fence_kdump ha esito negativo con "timeout dopo X secondi" in un cluster RHEL 6 o 7 a disponibilità elevata con versioni kexec-tools precedenti alla 2.0.14. Di seguito è illustrata la configurazione di esempio per un cluster a due nodi. Dopo aver apportato una modifica in/etc/kdump.conf, l'immagine kdump deve essere rigenerata. Per rigenerare, riavviare ilkdumpservizio.vi /etc/kdump.conf # On node prod-cl1-0 make sure the following line is added fence_kdump_nodes prod-cl1-1 # On node prod-cl1-1 make sure the following line is added fence_kdump_nodes prod-cl1-0 # Restart the service on each node systemctl restart kdumpTestare la configurazione arrestando un nodo in modo anomalo. Per altre informazioni, vedere Ricerca per categorie configurare fence_kdump in un cluster Red Hat Pacemaker?.
Importante
Se il cluster è già in uso produttivo, pianificare il test di conseguenza perché l'arresto anomalo di un nodo ha un impatto sull'applicazione.
echo c > /proc/sysrq-trigger
Passaggi successivi
- Vedere Pianificazione e implementazione di Azure Macchine virtuali per SAP.
- Vedere Distribuzione di macchine virtuali di Azure per SAP.
- Vedere Distribuzione DBMS di Azure Macchine virtuali per SAP.
- Per informazioni su come stabilire la disponibilità elevata e pianificare il ripristino di emergenza di SAP HANA nelle macchine virtuali di Azure, vedere Disponibilità elevata di SAP HANA in Azure Macchine virtuali.