Disponibilità elevata del sistema sap HANA con scalabilità orizzontale in Red Hat Enterprise Linux
Questo articolo descrive come distribuire un sistema SAP HANA a disponibilità elevata in una configurazione con scalabilità orizzontale. In particolare, la configurazione usa la replica di sistema HANA (HSR) e Pacemaker in macchine virtuali Linux (VM) di Azure Red Hat Enterprise Linux. I file system condivisi nell'architettura presentata sono montati in NFS e vengono forniti da Azure NetApp Files o dalla condivisione NFS in File di Azure.
Nelle configurazioni di esempio e nei comandi di installazione, l'istanza di HANA è 03 e l'ID di sistema HANA è HN1.
Prerequisiti
Alcuni lettori trarranno vantaggio dalla consulenza di un'ampia gamma di note e risorse SAP prima di procedere con gli argomenti di questo articolo:
- La nota SAP 1928533 include:
- Elenco delle dimensioni delle macchine virtuali di Azure supportate per la distribuzione del software SAP.
- Informazioni importanti sulla capacità per le dimensioni delle macchine virtuali di Azure.
- Software SAP e combinazioni di database e del sistema operativo supportate.
- Versione del kernel SAP richiesta per Windows e Linux in Microsoft Azure.
- Nota SAP 2015553: elenca i prerequisiti per le distribuzioni di software SAP supportate da SAP in Azure.
- Nota SAP [2002167]: dispone delle impostazioni consigliate del sistema operativo per RHEL.
- Nota SAP 2009879: include linee guida per SAP HANA per RHEL.
- Nota SAP 3108302 include le linee guida di SAP HANA per Red Hat Enterprise Linux 9.x.
- Nota SAP 2178632: contiene informazioni dettagliate su tutte le metriche di monitoraggio segnalate per SAP in Azure.
- Nota SAP 2191498: contiene la versione richiesta dell'agente host SAP per Linux in Azure.
- Nota SAP 2243692: contiene informazioni sulle licenze SAP in Linux in Azure.
- Nota SAP 1999351: contiene informazioni aggiuntive sulla risoluzione dei problemi per l'estensione di monitoraggio avanzato di Azure per SAP.
- Nota SAP 1900823: contiene informazioni sui requisiti di archiviazione di SAP HANA.
- Wiki della community SAP: contiene tutte le note SAP necessarie per Linux.
- Pianificazione e implementazione di Azure Macchine virtuali per SAP in Linux.
- Distribuzione di Azure Macchine virtuali per SAP in Linux.
- Distribuzione DBMS Macchine virtuali di Azure per SAP in Linux.
- Requisiti di rete sap HANA.
- Documentazione generale di RHEL:
- Panoramica del componente aggiuntivo a disponibilità elevata.
- Amministrazione del componente aggiuntivo a disponibilità elevata.
- Informazioni di riferimento sui componenti aggiuntivi a disponibilità elevata.
- Guida alla rete di Red Hat Enterprise Linux.
- Ricerca per categorie configurare la replica del sistema con scalabilità orizzontale di SAP HANA in un cluster Pacemaker con file system HANA in condivisioni NFS.
- Attivo/Attivo (abilitato per la lettura): soluzione A DISPONIBILITÀ elevata RHEL per la scalabilità orizzontale e la replica di sistema di SAP HANA.
- Documentazione di RHEL specifica di Azure:
- Installare SAP HANA in Red Hat Enterprise Linux per l'uso in Microsoft Azure.
- Soluzione Red Hat Enterprise Linux per la replica di sistema e scalabilità orizzontale di SAP HANA.
- Documentazione di Azure NetApp Files.
- Volumi NFS v4.1 in Azure NetApp Files per SAP HANA.
- Documentazione su File di Azure
Panoramica
Per ottenere la disponibilità elevata di HANA per le installazioni con scalabilità orizzontale di HANA, è possibile configurare la replica di sistema HANA e proteggere la soluzione con un cluster Pacemaker per consentire il failover automatico. Quando un nodo attivo ha esito negativo, il cluster esegue il failover delle risorse HANA nell'altro sito.
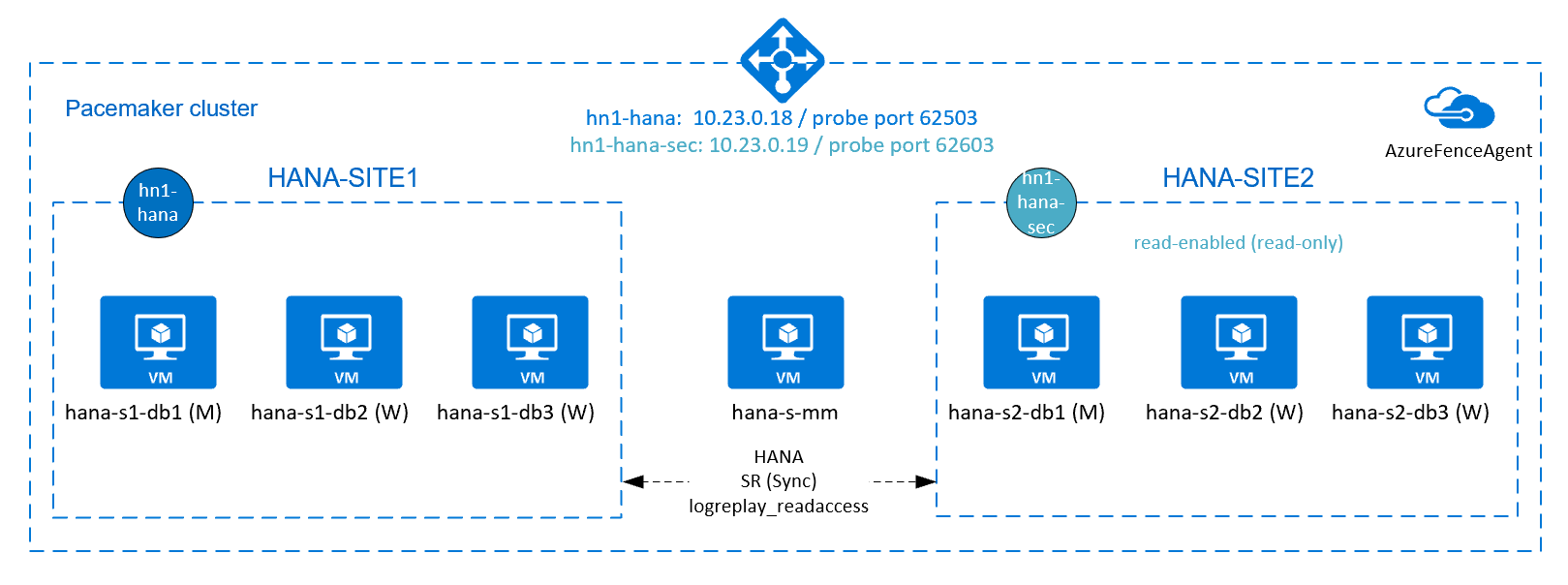
Nel diagramma seguente sono presenti tre nodi HANA in ogni sito e un nodo di maggioranza per evitare uno scenario "split-brain". Le istruzioni possono essere adattate per includere più macchine virtuali come nodi del database HANA.
Il file system /hana/shared condiviso HANA nell'architettura presentata può essere fornito da Azure NetApp Files o dalla condivisione NFS in File di Azure. Il file system condiviso HANA è montato su ogni nodo HANA nello stesso sito di replica di sistema HANA. I file system /hana/data e /hana/log sono file system locali e non vengono condivisi tra i nodi del database HANA. SAP HANA verrà installato in modalità non condivisa.
Per le configurazioni di archiviazione sap HANA consigliate, vedere Configurazioni di archiviazione delle macchine virtuali di Azure SAP HANA.
Importante
Se si distribuiscono tutti i file system HANA in Azure NetApp Files, per i sistemi di produzione, dove le prestazioni sono fondamentali, è consigliabile valutare e valutare l'uso del gruppo di volumi di applicazioni di Azure NetApp Files per SAP HANA.

Il diagramma precedente mostra tre subnet rappresentate all'interno di una rete virtuale di Azure, seguendo le raccomandazioni sulla rete SAP HANA:
- Per la comunicazione client:
client10.23.0.0/24 - Per la comunicazione interna di HANA internade:
inter10.23.1.128/26 - Per la replica di sistema HANA:
hsr10.23.1.192/26
Poiché /hana/data e /hana/log vengono distribuiti su dischi locali, non è necessario distribuire subnet separate e schede di rete virtuale separate per la comunicazione con l'archiviazione.
Se si usa Azure NetApp Files, i volumi NFS per /hana/sharedvengono distribuiti in una subnet separata, delegata ad Azure NetApp Files: anf 10.23.1.0/26.
Configurare l'infrastruttura
Nelle istruzioni seguenti si presuppone che il gruppo di risorse sia già stato creato, la rete virtuale di Azure con tre subnet di rete di Azure: cliente interhsr.
Distribuire macchine virtuali Linux tramite il portale di Azure
Distribuire le macchine virtuali di Azure. Per questa configurazione, distribuire sette macchine virtuali:
- Tre macchine virtuali da usare come nodi di database HANA per il sito di replica HANA 1: hana-s1-db1, hana-s1-db2 e hana-s1-db3.
- Tre macchine virtuali da usare come nodi di database HANA per il sito di replica HANA 2: hana-s2-db1, hana-s2-db2 e hana-s2-db3.
- Una piccola macchina virtuale da usare come produttore di maggioranza: hana-s-mm.
Le macchine virtuali distribuite come nodi SAP DB HANA devono essere certificate da SAP per HANA, come pubblicato nella directory hardware SAP HANA. Quando si distribuiscono i nodi del database HANA, assicurarsi di selezionare rete accelerata.
Per il nodo di maggioranza dei creatori, è possibile distribuire una macchina virtuale di piccole dimensioni, perché questa macchina virtuale non esegue alcuna delle risorse di SAP HANA. La macchina virtuale del produttore di maggioranza viene usata nella configurazione del cluster per ottenere e dispari il numero di nodi del cluster in uno scenario split-brain. In questo esempio la macchina virtuale di maggioranza necessita solo di un'interfaccia di rete virtuale nella
clientsubnet.Distribuire dischi gestiti locali per
/hana/datae/hana/log. La configurazione di archiviazione minima consigliata per/hana/dataed/hana/logè descritta in Configurazioni di archiviazione delle macchine virtuali di Azure SAP HANA.Distribuire l'interfaccia di rete primaria per ogni macchina virtuale nella subnet della
clientrete virtuale. Quando la macchina virtuale viene distribuita tramite portale di Azure, il nome dell'interfaccia di rete viene generato automaticamente. In questo articolo si farà riferimento alle interfacce di rete primarie generate automaticamente come hana-s1-db1-client, hana-s1-db2-client, hana-s1-db3-client e così via. Queste interfacce di rete sono collegate alla subnet dellaclientrete virtuale di Azure.Importante
Assicurarsi che il sistema operativo selezionato sia certificato SAP per SAP HANA nei tipi di macchina virtuale specifici in uso. Per un elenco dei tipi di MACCHINA virtuale certificati SAP HANA e delle versioni del sistema operativo per questi tipi, vedere Piattaforme IaaS certificate di SAP HANA. Esaminare i dettagli del tipo di macchina virtuale elencato per ottenere l'elenco completo delle versioni del sistema operativo supportate da SAP HANA per quel tipo.
Creare sei interfacce di rete, una per ogni macchina virtuale del database HANA, nella
intersubnet di rete virtuale (in questo esempio, hana-s1-db1-inter, hana-s1-db2-inter, hana-s1-db3-inter, hana-s2-db1-inter, hana-s2-db2-inter e hana-s2-db3-inter).Creare sei interfacce di rete, una per ogni macchina virtuale del database HANA, nella
hsrsubnet di rete virtuale (in questo esempio, hana-s1-db1-hsr, hana-s1-db2-hsr, hana-s1-db3-hsr, hana-s2-db1-hsr, hana-s2-db2-hsr e hana-s2-db3-hsr).Collegare le interfacce di rete virtuale appena create alle macchine virtuali corrispondenti:
- Passare alla macchina virtuale nel portale di Azure.
- Nel riquadro sinistro selezionare Macchine virtuali. Filtrare in base al nome della macchina virtuale (ad esempio, hana-s1-db1) e quindi selezionare la macchina virtuale.
- Nel riquadro Panoramica selezionare Arresta per deallocare la macchina virtuale.
- Selezionare Rete e quindi collegare l'interfaccia di rete. Nell'elenco a discesa Collega interfaccia di rete selezionare le interfacce di rete già create per le
intersubnet ehsr. - Seleziona Salva.
- Ripetere i passaggi b-e per le macchine virtuali rimanenti (in questo esempio, hana-s1-db2, hana-s1-db3, hana-s2-db1, hana-s2-db2 e hana-s2-db3)
- Lasciare invariate le macchine virtuali nello stato arrestato per il momento.
Abilitare la rete accelerata per le interfacce di rete aggiuntive per le
intersubnet ehsreseguendo le operazioni seguenti:Aprire Azure Cloud Shell nel portale di Azure.
Eseguire i comandi seguenti per abilitare la rete accelerata per le interfacce di rete aggiuntive collegate alle
intersubnet ehsr.az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db1-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db2-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db3-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db1-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db2-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db3-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db1-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db2-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db3-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db1-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db2-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db3-hsr --accelerated-networking true
Avviare le macchine virtuali del database HANA.
Configurare il servizio di bilanciamento del carico di Azure
Durante la configurazione della macchina virtuale, è possibile creare o selezionare l'uscita dal servizio di bilanciamento del carico nella sezione Rete. Seguire questa procedura per configurare il servizio di bilanciamento del carico standard per la configurazione a disponibilità elevata del database HANA.
Nota
- Per l'aumento del numero di istanze di HANA, selezionare la scheda di interfaccia di rete per la
clientsubnet quando si aggiungono le macchine virtuali nel pool back-end. - Il set completo di comandi nell'interfaccia della riga di comando di Azure e PowerShell aggiunge le macchine virtuali con scheda di interfaccia di rete primaria nel pool back-end.
Seguire la guida alla creazione del servizio di bilanciamento del carico per configurare un servizio di bilanciamento del carico standard per un sistema SAP a disponibilità elevata usando il portale di Azure. Durante la configurazione del servizio di bilanciamento del carico, prendere in considerazione i punti seguenti.
- Configurazione IP front-end: creare un indirizzo IP front-end. Selezionare la stessa rete virtuale e la stessa subnet delle macchine virtuali del database.
- Pool back-end: creare un pool back-end e aggiungere macchine virtuali del database.
- Regole in ingresso: creare una regola di bilanciamento del carico. Seguire la stessa procedura per entrambe le regole di bilanciamento del carico.
- Indirizzo IP front-end: selezionare ip front-end
- Pool back-end: selezionare il pool back-end
- Controllare "Porte a disponibilità elevata"
- Protocollo: TCP
- Probe di integrità: creare un probe di integrità con i dettagli seguenti
- Protocollo: TCP
- Porta: [ad esempio: 625<instance-no.>]
- Intervallo: 5
- Soglia probe: 2
- Timeout di inattività (minuti): 30
- Selezionare "Enable Floating IP" (Abilita IP mobile)
Nota
Il numero della proprietà di configurazione del probe di integritàOfProbes, altrimenti noto come "Soglia non integra" nel portale, non viene rispettato. Per controllare il numero di probe consecutivi riusciti o non riusciti, impostare la proprietà "probeThreshold" su 2. Attualmente non è possibile impostare questa proprietà usando portale di Azure, quindi usare l'interfaccia della riga di comando di Azure o il comando di PowerShell.
Importante
L'indirizzo IP mobile non è supportato in una configurazione IP secondaria della scheda di interfaccia di rete negli scenari di bilanciamento del carico. Per informazioni dettagliate, vedere Limitazioni di Azure Load Balancer. Se è necessario un indirizzo IP aggiuntivo per la macchina virtuale, distribuire una seconda scheda di interfaccia di rete.
Nota
Quando si usa il servizio di bilanciamento del carico standard, è necessario tenere presente la limitazione seguente. Quando si inserisce macchine virtuali senza indirizzi IP pubblici nel pool back-end di un servizio di bilanciamento del carico interno, non esiste connettività Internet in uscita. Per consentire il routing agli endpoint pubblici, è necessario eseguire una configurazione aggiuntiva. Per altre informazioni, vedere Connettività degli endpoint pubblici per Macchine virtuali usando Azure Load Balancer Standard in scenari a disponibilità elevata SAP.
Importante
Non abilitare i timestamp TCP nelle macchine virtuali di Azure posizionate dietro Azure Load Balancer. L'abilitazione dei timestamp TCP causa l'esito negativo dei probe di integrità. Impostare il parametro net.ipv4.tcp_timestamps su 0. Per informazioni dettagliate, vedere Probe di integrità di Load Balancer e note SAP 2382421.
Distribuire NFS
Sono disponibili due opzioni per la distribuzione di NFS nativo di Azure per /hana/shared. È possibile distribuire il volume NFS in Azure NetApp Files o nella condivisione NFS in File di Azure. I file di Azure supportano il protocollo NFSv4.1, NFS in Azure NetApp Files supporta sia NFSv4.1 che NFSv3.
Le sezioni successive descrivono i passaggi per distribuire NFS: è necessario selezionare solo una delle opzioni.
Suggerimento
Si è scelto di eseguire la distribuzione /hana/shared nella condivisione NFS in File di Azure o nel volume NFS in Azure NetApp Files.
Distribuire l'infrastruttura di Azure NetApp Files
Distribuire i volumi di Azure NetApp Files per il /hana/shared file system. È necessario un volume separato /hana/shared per ogni sito di replica di sistema HANA. Per altre informazioni, vedere Configurare l'infrastruttura di Azure NetApp Files.
In questo esempio si usano i volumi di Azure NetApp Files seguenti:
- volume HN1-shared-s1 (nfs://10.23.1.7/ HN1-shared-s1)
- volume HN1-shared-s2 (nfs://10.23.1.7/ HN1-shared-s2)
Distribuire NFS nell'infrastruttura File di Azure
Distribuire File di Azure condivisioni NFS per il /hana/shared file system. È necessaria una condivisione NFS File di Azure separata /hana/shared per ogni sito di replica di sistema HANA. Per altre informazioni, vedere Come creare una condivisione NFS.
In questo esempio sono state usate le File di Azure condivisioni NFS seguenti:
- share hn1-shared-s1 (sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1)
- share hn1-shared-s2 (sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2)
Configurazione e preparazione del sistema operativo
Le istruzioni nelle sezioni successive sono precedute da una delle abbreviazioni seguenti:
- [A]: applicabile a tutti i nodi
- [AH]: applicabile a tutti i nodi del database HANA
- [M]: applicabile al nodo di maggioranza
- [AH1]: applicabile a tutti i nodi del database HANA in SITE 1
- [AH2]: applicabile a tutti i nodi del database HANA in SITE 2
- [1]: applicabile solo al nodo 1 del database HANA, SITE 1
- [2]: applicabile solo al nodo 1 del database HANA, SITE 2
Configurare e preparare il sistema operativo eseguendo le operazioni seguenti:
[A] Gestire i file host nelle macchine virtuali. Includere voci per tutte le subnet. Per questo esempio vengono aggiunte
/etc/hostsle voci seguenti.# Client subnet 10.23.0.11 hana-s1-db1 10.23.0.12 hana-s1-db1 10.23.0.13 hana-s1-db2 10.23.0.14 hana-s2-db1 10.23.0.15 hana-s2-db2 10.23.0.16 hana-s2-db3 10.23.0.17 hana-s-mm # Internode subnet 10.23.1.138 hana-s1-db1-inter 10.23.1.139 hana-s1-db2-inter 10.23.1.140 hana-s1-db3-inter 10.23.1.141 hana-s2-db1-inter 10.23.1.142 hana-s2-db2-inter 10.23.1.143 hana-s2-db3-inter # HSR subnet 10.23.1.202 hana-s1-db1-hsr 10.23.1.203 hana-s1-db2-hsr 10.23.1.204 hana-s1-db3-hsr 10.23.1.205 hana-s2-db1-hsr 10.23.1.206 hana-s2-db2-hsr 10.23.1.207 hana-s2-db3-hsr[A] Creare il file di configurazione /etc/sysctl.d/ms-az.conf con le impostazioni di configurazione di Microsoft per Azure.
vi /etc/sysctl.d/ms-az.conf # Add the following entries in the configuration file net.ipv6.conf.all.disable_ipv6 = 1 net.ipv4.tcp_max_syn_backlog = 16348 net.ipv4.conf.all.rp_filter = 0 sunrpc.tcp_slot_table_entries = 128 vm.swappiness=10Suggerimento
Evitare di impostare
net.ipv4.ip_local_port_rangeenet.ipv4.ip_local_reserved_portsin modo esplicito neisysctlfile di configurazione, per consentire all'agente host SAP di gestire gli intervalli di porte. Per altri dettagli, vedere la nota SAP 2382421.[A] Installare il pacchetto client NFS.
yum install nfs-utils[AH] Configurazione di Red Hat per HANA.
Configurare RHEL, come descritto nel portale per i clienti di Red Hat e nelle note SAP seguenti:
- 2292690 - SAP HANA DB: Recommended OS settings for RHEL 7 (2292690 - SAP HANA DB: impostazioni del sistema operativo consigliate per RHEL 7)
- 2777782 - DATABASE SAP HANA: impostazioni del sistema operativo consigliate per RHEL 8
- 2455582 - Linux: Esecuzione di applicazioni SAP compilate con GCC 6.x
- 2593824 - Linux: Esecuzione di applicazioni SAP compilate con GCC 7.x
- 2886607 - Linux: Esecuzione di applicazioni SAP compilate con GCC 9.x
Preparare i file system
Le sezioni seguenti illustrano i passaggi per la preparazione dei file system. Si è scelto di distribuire /hana/shared' nella condivisione NFS in File di Azure o nel volume NFS in Azure NetApp Files.
Montare i file system condivisi (NFS di Azure NetApp Files)
In questo esempio i file system HANA condivisi vengono distribuiti in Azure NetApp Files e montati su NFSv4.1. Seguire i passaggi descritti in questa sezione, solo se si usa NFS in Azure NetApp Files.
[AH] Preparare il sistema operativo per l'esecuzione di SAP HANA in NetApp Systems con NFS, come descritto nella nota SAP 3024346 - Linux Kernel Impostazioni per NetApp NFS. Creare il file di configurazione /etc/sysctl.d/91-NetApp-HANA.conf per le impostazioni di configurazione di NetApp.
vi /etc/sysctl.d/91-NetApp-HANA.conf # Add the following entries in the configuration file net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_rmem = 4096 131072 16777216 net.ipv4.tcp_wmem = 4096 16384 16777216 net.core.netdev_max_backlog = 300000 net.ipv4.tcp_slow_start_after_idle=0 net.ipv4.tcp_no_metrics_save = 1 net.ipv4.tcp_moderate_rcvbuf = 1 net.ipv4.tcp_window_scaling = 1 net.ipv4.tcp_sack = 1[AH] Modificare le impostazioni sunrpc, come consigliato nella nota SAP 3024346 - Linux Kernel Impostazioni per NetApp NFS.
vi /etc/modprobe.d/sunrpc.conf # Insert the following line options sunrpc tcp_max_slot_table_entries=128[AH] Creare punti di montaggio per i volumi di database HANA.
mkdir -p /hana/shared[AH] Verificare l'impostazione del dominio NFS. Assicurarsi che il dominio sia configurato come dominio predefinito di Azure NetApp Files:
defaultv4iddomain.com. Assicurarsi che il mapping sia impostato sunobody.
Questo passaggio è necessario solo se si usa Azure NetAppFiles NFS v4.1.Importante
Verificare di impostare il dominio NFS in
/etc/idmapd.confsulla macchina virtuale in modo che corrisponda alla configurazione del dominio predefinito in Azure NetApp Files:defaultv4iddomain.com. Se si verifica una mancata corrispondenza tra la configurazione del dominio nel client NFS e il server NFS, le autorizzazioni per i file nei volumi Azure NetApp montati nelle macchine virtuali verranno visualizzate comenobody.sudo cat /etc/idmapd.conf # Example [General] Domain = defaultv4iddomain.com [Mapping] Nobody-User = nobody Nobody-Group = nobody[AH] Verificare
nfs4_disable_idmapping. Deve essere impostato suY. Per creare la struttura di directory in cuinfs4_disable_idmappingsi trova, eseguire il comando mount. Non sarà possibile creare manualmente la directory in /sys/modules, perché l'accesso è riservato per il kernel o i driver.
Questo passaggio è necessario solo se si usa Azure NetAppFiles NFSv4.1.# Check nfs4_disable_idmapping cat /sys/module/nfs/parameters/nfs4_disable_idmapping # If you need to set nfs4_disable_idmapping to Y mkdir /mnt/tmp mount 10.9.0.4:/HN1-shared /mnt/tmp umount /mnt/tmp echo "Y" > /sys/module/nfs/parameters/nfs4_disable_idmapping # Make the configuration permanent echo "options nfs nfs4_disable_idmapping=Y" >> /etc/modprobe.d/nfs.confPer altre informazioni su come modificare il
nfs4_disable_idmappingparametro, vedere il portale per i clienti di Red Hat.[AH1] Montare i volumi condivisi di Azure NetApp Files nelle macchine virtuali del database HANA SITE1.
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.23.1.7:/HN1-shared-s1 /hana/shared[AH2] Montare i volumi condivisi di Azure NetApp Files nelle macchine virtuali del database HANA SITE2.
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.23.1.7:/HN1-shared-s2 /hana/shared[AH] Verificare che i file system corrispondenti
/hana/shared/siano montati in tutte le macchine virtuali del database HANA, con la versione del protocollo NFS NFSv4.sudo nfsstat -m # Verify that flag vers is set to 4.1 # Example from SITE 1, hana-s1-db1 /hana/shared from 10.23.1.7:/HN1-shared-s1 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.11,local_lock=none,addr=10.23.1.7 # Example from SITE 2, hana-s2-db1 /hana/shared from 10.23.1.7:/HN1-shared-s2 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.14,local_lock=none,addr=10.23.1.7
Montare i file system condivisi (File di Azure NFS)
In questo esempio i file system HANA condivisi vengono distribuiti in NFS in File di Azure. Seguire la procedura descritta in questa sezione solo se si usa NFS in File di Azure.
[AH] Creare punti di montaggio per i volumi di database HANA.
mkdir -p /hana/shared[AH1] Montare i volumi condivisi di Azure NetApp Files nelle macchine virtuali del database HANA SITE1.
sudo vi /etc/fstab # Add the following entry sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 /hana/shared nfs nfsvers=4.1,sec=sys 0 0 # Mount all volumes sudo mount -a[AH2] Montare i volumi condivisi di Azure NetApp Files nelle macchine virtuali del database HANA SITE2.
sudo vi /etc/fstab # Add the following entries sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 /hana/shared nfs nfsvers=4.1,sec=sys 0 0 # Mount the volume sudo mount -a[AH] Verificare che i file system corrispondenti
/hana/shared/siano montati in tutte le macchine virtuali del database HANA con la versione del protocollo NFS NFSv4.1.sudo nfsstat -m # Example from SITE 1, hana-s1-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.19,local_lock=none,addr=10.23.0.35 # Example from SITE 2, hana-s2-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.22,local_lock=none,addr=10.23.0.35
Preparare i file system locali di dati e log
Nella configurazione presentata si distribuiscono file system /hana/data e /hana/log in un disco gestito e questi file system vengono collegati localmente a ogni macchina virtuale di database HANA. Eseguire la procedura seguente per creare i volumi di dati e log locali in ogni macchina virtuale del database HANA.
Configurare il layout del disco con Gestione volumi logici (LVM). Nell'esempio seguente si presuppone che ogni macchina virtuale HANA abbia tre dischi dati collegati e che questi dischi vengano usati per creare due volumi.
[AH] Elencare tutti i dischi disponibili:
ls /dev/disk/azure/scsi1/lun*Output di esempio:
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2[AH] Creare volumi fisici per tutti i dischi da usare:
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2[AH] Creare un gruppo di volumi per i file di dati. Usare un gruppo di volumi per i file di log e uno per la directory condivisa di SAP HANA:
sudo vgcreate vg_hana_data_HN1 /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_HN1 /dev/disk/azure/scsi1/lun2[AH] Creare i volumi logici. Quando si usa senza l'opzione
-i, viene creato un volume lineare.lvcreateÈ consigliabile creare un volume con striping per migliorare le prestazioni di I/O. Allineare le dimensioni di striping ai valori documentati nelle configurazioni di archiviazione delle macchine virtuali SAP HANA. L'argomento-ideve essere il numero dei volumi fisici sottostanti e l'argomento-Iè la dimensione della striscia. In questo articolo vengono usati due volumi fisici per il volume di dati, quindi l'argomento-iswitch viene impostato su2. Le dimensioni di striping per il volume di dati sono256 KiB. Un volume fisico viene usato per il volume di log, pertanto non è necessario usare opzioni esplicite-io-Iper i comandi del volume di log.Importante
Usare l'opzione
-ie impostarla sul numero del volume fisico sottostante, quando si usano più volumi fisici per ogni volume di dati o di log. Usare l'opzione-Iper specificare le dimensioni di striping quando si crea un volume con striping. Vedere Configurazioni di archiviazione della macchina virtuale SAP HANA per le configurazioni di archiviazione consigliate, incluse le dimensioni di striping e il numero di dischi.sudo lvcreate -i 2 -I 256 -l 100%FREE -n hana_data vg_hana_data_HN1 sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_HN1 sudo mkfs.xfs /dev/vg_hana_data_HN1/hana_data sudo mkfs.xfs /dev/vg_hana_log_HN1/hana_log[AH] Creare le directory di montaggio e copiare l'UUID di tutti i volumi logici:
sudo mkdir -p /hana/data/HN1 sudo mkdir -p /hana/log/HN1 # Write down the ID of /dev/vg_hana_data_HN1/hana_data and /dev/vg_hana_log_HN1/hana_log sudo blkid[AH] Creare
fstabvoci per i volumi logici e montare:sudo vi /etc/fstabInserire la riga seguente nel file
/etc/fstab:/dev/disk/by-uuid/UUID of /dev/mapper/vg_hana_data_HN1-hana_data /hana/data/HN1 xfs defaults,nofail 0 2 /dev/disk/by-uuid/UUID of /dev/mapper/vg_hana_log_HN1-hana_log /hana/log/HN1 xfs defaults,nofail 0 2Montare i nuovi volumi:
sudo mount -a
Installazione
In questo esempio per la distribuzione di SAP HANA in una configurazione con scalabilità orizzontale con HSR in macchine virtuali di Azure si usa HANA 2.0 SP4.
Preparare l'installazione di HANA
[AH] Prima dell'installazione di HANA, impostare la password radice. È possibile disabilitare la password radice dopo il completamento dell'installazione. Eseguire come
rootcomandopasswdper impostare la password.[1,2] Modificare le autorizzazioni per
/hana/shared.chmod 775 /hana/shared[1] Verificare di poter accedere a hana-s1-db2 e hana-s1-db3 tramite secure shell (SSH), senza che venga richiesta una password. In caso contrario, scambiare
sshle chiavi, come documentato in Uso dell'autenticazione basata su chiave.ssh root@hana-s1-db2 ssh root@hana-s1-db3[2] Verificare che sia possibile accedere a hana-s2-db2 e hana-s2-db3 tramite SSH, senza che venga richiesta una password. In caso contrario, scambiare
sshle chiavi, come documentato in Uso dell'autenticazione basata su chiave.ssh root@hana-s2-db2 ssh root@hana-s2-db3[AH] Installare pacchetti aggiuntivi, necessari per HANA 2.0 SP4. Per altre informazioni, vedere SAP Note 2593824 per RHEL 7.
# If using RHEL 7 yum install libgcc_s1 libstdc++6 compat-sap-c++-7 libatomic1 # If using RHEL 8 yum install libatomic libtool-ltdl.x86_64[A] Disabilitare temporaneamente il firewall, in modo che non interferisca con l'installazione di HANA. È possibile riabilitarlo al termine dell'installazione di HANA.
# Execute as root systemctl stop firewalld systemctl disable firewalld
Installazione di HANA nel primo nodo in ogni sito
[1] Installare SAP HANA seguendo le istruzioni riportate nella guida all'installazione e all'aggiornamento di SAP HANA 2.0. Le istruzioni seguenti illustrano l'installazione di SAP HANA nel primo nodo in SITE 1.
Avviare il
hdblcmprogramma dallarootdirectory del software di installazione di HANA. Usare ilinternal_networkparametro e passare lo spazio degli indirizzi per la subnet, che viene usato per la comunicazione interna di HANA internade internade../hdblcm --internal_network=10.23.1.128/26Al prompt immettere i valori seguenti:
- Per Scegliere un'azione immettere 1 (per l'installazione).
- Per Componenti aggiuntivi per l'installazione, immettere 2, 3.
- Per il percorso di installazione, premere INVIO (il valore predefinito è /hana/shared).
- Per Local Host Name (Nome host locale) premere INVIO per accettare l'impostazione predefinita.
- Per Aggiungere host al sistema?, immettere n.
- Per SAP HANA System ID (ID sistema SAP HANA) immettere HN1.
- Per Numero di istanza [00], immettere 03.
- Per Gruppo di lavoro host locale [impostazione predefinita], premere INVIO per accettare l'impostazione predefinita.
- Per Select System Usage /Enter index [4], enter 4 (for custom).
- Per Posizione dei volumi di dati [/hana/data/HN1], premere INVIO per accettare l'impostazione predefinita.
- Per Posizione dei volumi di log [/hana/log/HN1], premere INVIO per accettare il valore predefinito.
- Per Limita allocazione massima di memoria? [n], immettere n.
- Per Nome host certificato per Host hana-s1-db1 [hana-s1-db1], premere INVIO per accettare il valore predefinito.
- Per SAP Host Agent User (sapadm) Password immettere la password.
- Per Confermare la password dell'utente dell'agente host SAP (sapadm), immettere la password.
- Per System Amministrazione istrator (hn1adm) Password immettere la password.
- Per System Amministrazione istrator Home Directory [/usr/sap/HN1/home], premere INVIO per accettare il valore predefinito.
- Per System Amministrazione istrator Login Shell [/bin/sh], premere INVIO per accettare il valore predefinito.
- Per System Amministrazione istrator User ID [1001], premere INVIO per accettare il valore predefinito.
- Per ENTER ID of User Group (sapsys) [79], premere INVIO per accettare il valore predefinito.
- In System Database User (system) Password (Password utente database di sistema) immettere la password del sistema.
- Per Conferma password utente database di sistema (sistema) immettere la password del sistema.
- Per Riavvia sistema dopo il riavvio del computer? [n], immettere n.
- Per Continuare (y/n), convalidare il riepilogo e, se tutto è corretto, immettere y.
[2] Ripetere il passaggio precedente per installare SAP HANA nel primo nodo in SITE 2.
[1,2] Verificare global.ini.
Visualizzare global.ini e assicurarsi che la configurazione per la comunicazione interna interna di SAP HANA internade sia presente. Verificare la
communicationsezione . Deve avere lo spazio indirizzi per laintersubnet elisteninterfacedeve essere impostato su.internal. Verificare lainternal_hostname_resolutionsezione . Deve avere gli indirizzi IP per le macchine virtuali HANA che appartengono allaintersubnet.sudo cat /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini # Example from SITE1 [communication] internal_network = 10.23.1.128/26 listeninterface = .internal [internal_hostname_resolution] 10.23.1.138 = hana-s1-db1 10.23.1.139 = hana-s1-db2 10.23.1.140 = hana-s1-db3[1,2] Preparare global.ini per l'installazione in un ambiente non condiviso, come descritto nella nota SAP 2080991.
sudo vi /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini [persistence] basepath_shared = no[1,2] Riavviare SAP HANA per attivare le modifiche.
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StopSystem sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StartSystem[1,2] Verificare che l'interfaccia client usi gli indirizzi IP della subnet per la
clientcomunicazione.# Execute as hn1adm /usr/sap/HN1/HDB03/exe/hdbsql -u SYSTEM -p "password" -i 03 -d SYSTEMDB 'select * from SYS.M_HOST_INFORMATION'|grep net_publicname # Expected result - example from SITE 2 "hana-s2-db1","net_publicname","10.23.0.14"Per informazioni su come verificare la configurazione, vedere la nota SAP 2183363 - Configurazione della rete interna di SAP HANA.
[AH] Modificare le autorizzazioni per le directory di dati e log per evitare un errore di installazione di HANA.
sudo chmod o+w -R /hana/data /hana/log[1] Installare i nodi HANA secondari. Le istruzioni di esempio in questo passaggio sono relative a SITE 1.
Avviare il programma residente
hdblcmcomeroot.cd /hana/shared/HN1/hdblcm ./hdblcmAl prompt immettere i valori seguenti:
- Per Scegliere un'azione immettere 2 (per aggiungere host).
- Per Immettere nomi host separati da virgole da aggiungere, immettere hana-s1-db2, hana-s1-db3.
- Per Componenti aggiuntivi per l'installazione, immettere 2, 3.
- Per Immettere il nome utente radice [root], premere INVIO per accettare l'impostazione predefinita.
- Per Select roles for host 'hana-s1-db2' [1], select 1 (for worker).
- Per Enter Host Failover Group for host 'hana-s1-db2' [default], premere INVIO per accettare il valore predefinito.
- Per Enter Archiviazione Partition Number for host 'hana-s1-db2' [<<assign automatically>>], premere INVIO per accettare il valore predefinito.
- Per Enter Worker Group for host 'hana-s1-db2' [default], premere INVIO per accettare il valore predefinito.
- Per Select roles for host 'hana-s1-db3' [1], select 1 (for worker).
- Per Enter Host Failover Group for host 'hana-s1-db3' [default], premere INVIO per accettare il valore predefinito.
- Per Immettere Archiviazione numero di partizione per l'host 'hana-s1-db3' [<<assegna automaticamente>>], premere INVIO per accettare l'impostazione predefinita.
- Per Enter Worker Group for host 'hana-s1-db3' [default], premere INVIO per accettare il valore predefinito.
- Per System Amministrazione istrator (hn1adm) Password immettere la password.
- Per Immettere la password dell'utente dell'agente host SAP (sapadm) immettere la password.
- Per Confermare la password dell'utente dell'agente host SAP (sapadm), immettere la password.
- Per Nome host certificato per Host hana-s1-db2 [hana-s1-db2], premere INVIO per accettare l'impostazione predefinita.
- Per Nome host certificato per Host hana-s1-db3 [hana-s1-db3], premere INVIO per accettare l'impostazione predefinita.
- Per Continuare (y/n), convalidare il riepilogo e, se tutto è corretto, immettere y.
[2] Ripetere il passaggio precedente per installare i nodi SAP HANA secondari in SITE 2.
Configurare la replica di sistema SAP HANA 2.0
La procedura seguente consente di configurare la replica di sistema:
[1] Configurare la replica di sistema in SITE 1:
Eseguire il backup dei database come hn1adm:
hdbsql -d SYSTEMDB -u SYSTEM -p "passwd" -i 03 "BACKUP DATA USING FILE ('initialbackupSYS')" hdbsql -d HN1 -u SYSTEM -p "passwd" -i 03 "BACKUP DATA USING FILE ('initialbackupHN1')"Copiare i file PKI di sistema nel sito secondario:
scp /usr/sap/HN1/SYS/global/security/rsecssfs/data/SSFS_HN1.DAT hana-s2-db1:/usr/sap/HN1/SYS/global/security/rsecssfs/data/ scp /usr/sap/HN1/SYS/global/security/rsecssfs/key/SSFS_HN1.KEY hana-s2-db1:/usr/sap/HN1/SYS/global/security/rsecssfs/key/Creare il sito primario:
hdbnsutil -sr_enable --name=HANA_S1[2] Configurare la replica di sistema in SITE 2:
Registrare il secondo sito per avviare la replica di sistema. Eseguire il comando seguente come <hanasid>adm:
sapcontrol -nr 03 -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hana-s1-db1 --remoteInstance=03 --replicationMode=sync --name=HANA_S2 sapcontrol -nr 03 -function StartSystem[1] Controllare lo stato della replica e attendere che tutti i database siano sincronizzati.
sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py" # | Database | Host | Port | Service Name | Volume ID | Site ID | Site Name | Secondary | Secondary | Secondary | Secondary | Secondary | Replication | Replication | Replication | # | | | | | | | | Host | Port | Site ID | Site Name | Active Status | Mode | Status | Status Details | # | -------- | ------------- | ----- | ------------ | --------- | ------- | --------- | ------------- | --------- | --------- | --------- | ------------- | ----------- | ----------- | -------------- | # | HN1 | hana-s1-db3 | 30303 | indexserver | 5 | 1 | HANA_S1 | hana-s2-db3 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | SYSTEMDB | hana-s1-db1 | 30301 | nameserver | 1 | 1 | HANA_S1 | hana-s2-db1 | 30301 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db1 | 30307 | xsengine | 2 | 1 | HANA_S1 | hana-s2-db1 | 30307 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db1 | 30303 | indexserver | 3 | 1 | HANA_S1 | hana-s2-db1 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db2 | 30303 | indexserver | 4 | 1 | HANA_S1 | hana-s2-db2 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # # status system replication site "2": ACTIVE # overall system replication status: ACTIVE # # Local System Replication State # # mode: PRIMARY # site id: 1 # site name: HANA_S1[1,2] Modificare la configurazione HANA in modo che la comunicazione per la replica di sistema HANA venga indirizzata tramite le interfacce di rete virtuale di replica del sistema HANA.
Arrestare HANA in entrambi i siti.
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StopSystem HDBModificare global.ini per aggiungere il mapping host per la replica di sistema HANA. Usare gli indirizzi IP della
hsrsubnet.sudo vi /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini #Add the section [system_replication_hostname_resolution] 10.23.1.202 = hana-s1-db1 10.23.1.203 = hana-s1-db2 10.23.1.204 = hana-s1-db3 10.23.1.205 = hana-s2-db1 10.23.1.206 = hana-s2-db2 10.23.1.207 = hana-s2-db3Avviare HANA in entrambi i siti.
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StartSystem HDB
Per altre informazioni, vedere Risoluzione dei nomi host per la replica di sistema.
[AH] Riabilitare il firewall e aprire le porte necessarie.
Riabilitare il firewall.
# Execute as root systemctl start firewalld systemctl enable firewalldAprire le porte del firewall necessarie. Sarà necessario modificare le porte per il numero di istanza di HANA.
Importante
Creare regole del firewall per consentire la comunicazione internade HANA e il traffico client. Le porte necessarie sono elencate sulle porte TCP/IP di tutti i prodotti SAP. I comandi seguenti sono solo un esempio. In questo scenario si usa il numero di sistema 03.
# Execute as root sudo firewall-cmd --zone=public --add-port={30301,30303,30306,30307,30313,30315,30317,30340,30341,30342,1128,1129,40302,40301,40307,40303,40340,50313,50314,30310,30302}/tcp --permanent sudo firewall-cmd --zone=public --add-port={30301,30303,30306,30307,30313,30315,30317,30340,30341,30342,1128,1129,40302,40301,40307,40303,40340,50313,50314,30310,30302}/tcp
Creare un cluster Pacemaker
Per creare un cluster Pacemaker di base, seguire la procedura descritta in Configurazione di Pacemaker in Red Hat Enterprise Linux in Azure. Includere tutte le macchine virtuali, incluso il produttore di maggioranza nel cluster.
Importante
Non impostare su quorum expected-votes 2. Non si tratta di un cluster a due nodi. Assicurarsi che la proprietà concurrent-fencing del cluster sia abilitata, in modo che l'isolamento del nodo venga deserializzato.
Creare risorse del file system
Per la parte successiva di questo processo, è necessario creare risorse del file system. In tal caso, eseguire la procedura seguente:
[1,2] Arrestare SAP HANA in entrambi i siti di replica. Eseguire come <sid>adm.
sapcontrol -nr 03 -function StopSystem[AH] Smontare il file system
/hana/shared, che è stato montato temporaneamente per l'installazione in tutte le macchine virtuali del database HANA. Prima di smontarlo, è necessario arrestare tutti i processi e le sessioni che usano il file system.umount /hana/shared[1] Creare le risorse del cluster del file system per
/hana/sharednello stato disabilitato. È necessario definire--disabledi vincoli di posizione prima che i montaggi siano abilitati.
Si è scelto di distribuire /hana/shared' nella condivisione NFS in File di Azure o nel volume NFS in Azure NetApp Files.In questo esempio il file system '/hana/shared' viene distribuito in Azure NetApp Files e montato su NFSv4.1. Seguire i passaggi descritti in questa sezione, solo se si usa NFS in Azure NetApp Files.
# /hana/shared file system for site 1 pcs resource create fs_hana_shared_s1 --disabled ocf:heartbeat:Filesystem device=10.23.1.7:/HN1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,timeo=600,rsize=262144,wsize=262144,proto=tcp,noatime,sec=sys,nfsvers=4.1,lock,_netdev' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # /hana/shared file system for site 2 pcs resource create fs_hana_shared_s2 --disabled ocf:heartbeat:Filesystem device=10.23.1.7:/HN1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,timeo=600,rsize=262144,wsize=262144,proto=tcp,noatime,sec=sys,nfsvers=4.1,lock,_netdev' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # clone the /hana/shared file system resources for both site1 and site2 pcs resource clone fs_hana_shared_s1 meta clone-node-max=1 interleave=true pcs resource clone fs_hana_shared_s2 meta clone-node-max=1 interleave=true
I valori di timeout suggeriti consentono alle risorse del cluster di resistere alla pausa specifica del protocollo, correlata ai rinnovi del lease NFSv4.1 in Azure NetApp Files. Per altre informazioni, vedere Procedura consigliata per NFS in NetApp.
In questo esempio il file system '/hana/shared' viene distribuito in NFS in File di Azure. Seguire la procedura descritta in questa sezione solo se si usa NFS in File di Azure.
# /hana/shared file system for site 1 pcs resource create fs_hana_shared_s1 --disabled ocf:heartbeat:Filesystem device=sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,proto=tcp,noatime,nfsvers=4.1,lock' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # /hana/shared file system for site 2 pcs resource create fs_hana_shared_s2 --disabled ocf:heartbeat:Filesystem device=sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,proto=tcp,noatime,nfsvers=4.1,lock' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # clone the /hana/shared file system resources for both site1 and site2 pcs resource clone fs_hana_shared_s1 meta clone-node-max=1 interleave=true pcs resource clone fs_hana_shared_s2 meta clone-node-max=1 interleave=trueL'attributo
OCF_CHECK_LEVEL=20viene aggiunto all'operazione di monitoraggio, in modo che le operazioni di monitoraggio eseguano un test di lettura/scrittura nel file system. Senza questo attributo, l'operazione di monitoraggio verifica solo che il file system sia montato. Questo può essere un problema perché quando la connettività viene persa, il file system potrebbe rimanere montato, nonostante non sia accessibile.L'attributo
on-fail=fenceviene aggiunto anche all'operazione di monitoraggio. Con questa opzione, se l'operazione di monitoraggio non riesce in un nodo, tale nodo viene immediatamente delimitato. Senza questa opzione, il comportamento predefinito consiste nell'arrestare tutte le risorse che dipendono dalla risorsa non riuscita, quindi riavviare la risorsa non riuscita e quindi avviare tutte le risorse che dipendono dalla risorsa non riuscita. Non solo questo comportamento può richiedere molto tempo quando una risorsa SAP HANA dipende dalla risorsa non riuscita, ma può anche avere esito negativo. La risorsa SAP HANA non può essere interrotta correttamente, se la condivisione NFS che contiene i file binari HANA non è accessibile.I timeout nelle configurazioni precedenti potrebbero essere necessari per adattarsi alla configurazione SAP specifica.
[1] Configurare e verificare gli attributi del nodo. A tutti i nodi del database SAP HANA nel sito di replica 1 viene assegnato l'attributo
S1e a tutti i nodi del database SAP HANA nel sito di replica 2 viene assegnato l'attributoS2.# HANA replication site 1 pcs node attribute hana-s1-db1 NFS_SID_SITE=S1 pcs node attribute hana-s1-db2 NFS_SID_SITE=S1 pcs node attribute hana-s1-db3 NFS_SID_SITE=S1 # HANA replication site 2 pcs node attribute hana-s2-db1 NFS_SID_SITE=S2 pcs node attribute hana-s2-db2 NFS_SID_SITE=S2 pcs node attribute hana-s2-db3 NFS_SID_SITE=S2 # To verify the attribute assignment to nodes execute pcs node attribute[1] Configurare i vincoli che determinano dove verranno montati i file system NFS e abilitare le risorse del file system.
# Configure the constraints pcs constraint location fs_hana_shared_s1-clone rule resource-discovery=never score=-INFINITY NFS_SID_SITE ne S1 pcs constraint location fs_hana_shared_s2-clone rule resource-discovery=never score=-INFINITY NFS_SID_SITE ne S2 # Enable the file system resources pcs resource enable fs_hana_shared_s1 pcs resource enable fs_hana_shared_s2Quando si abilitano le risorse del file system, il cluster monta i
/hana/sharedfile system.[AH] Verificare che i volumi di Azure NetApp Files siano montati in
/hana/shared, in tutte le macchine virtuali del database HANA in entrambi i siti.Ad esempio, se si usa Azure NetApp Files:
sudo nfsstat -m # Verify that flag vers is set to 4.1 # Example from SITE 1, hana-s1-db1 /hana/shared from 10.23.1.7:/HN1-shared-s1 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.11,local_lock=none,addr=10.23.1.7 # Example from SITE 2, hana-s2-db1 /hana/shared from 10.23.1.7:/HN1-shared-s2 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.14,local_lock=none,addr=10.23.1.7Ad esempio, se si usa File di Azure NFS:
sudo nfsstat -m # Example from SITE 1, hana-s1-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.19,local_lock=none,addr=10.23.0.35 # Example from SITE 2, hana-s2-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.22,local_lock=none,addr=10.23.0.35
[1] Configurare e clonare le risorse dell'attributo e configurare i vincoli, come indicato di seguito:
# Configure the attribute resources pcs resource create hana_nfs_s1_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs_s1_active pcs resource create hana_nfs_s2_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs_s2_active # Clone the attribute resources pcs resource clone hana_nfs_s1_active meta clone-node-max=1 interleave=true pcs resource clone hana_nfs_s2_active meta clone-node-max=1 interleave=true # Configure the constraints, which will set the attribute values pcs constraint order fs_hana_shared_s1-clone then hana_nfs_s1_active-clone pcs constraint order fs_hana_shared_s2-clone then hana_nfs_s2_active-cloneSuggerimento
Se la configurazione include file system diversi da /
hana/sharede questi file system sono montati NFS, includere l'opzionesequential=false. Questa opzione garantisce che non vi siano dipendenze di ordinamento tra i file system. Tutti i file system montati NFS devono iniziare prima della risorsa attributo corrispondente, ma non devono iniziare in alcun ordine rispetto all'altro. Per altre informazioni, vedere Ricerca per categorie configurare HSR di SAP HANA con scalabilità orizzontale in un cluster Pacemaker quando i file system HANA sono condivisioni NFS.[1] Posizionare Pacemaker in modalità di manutenzione, in preparazione alla creazione delle risorse del cluster HANA.
pcs property set maintenance-mode=true
Creare le risorse cluster SAP HANA
A questo momento è possibile creare le risorse del cluster:
[A] Installare l'agente di risorse con scalabilità orizzontale HANA in tutti i nodi del cluster, incluso il produttore di maggioranza.
yum install -y resource-agents-sap-hana-scaleoutNota
Per la versione minima supportata del pacchetto
resource-agents-sap-hana-scaleoutper la versione del sistema operativo, vedere Criteri di supporto per i cluster RHEL HA - Gestione di SAP HANA in un cluster .[1,2] Installare l'hook di replica di sistema HANA in un nodo del database HANA in ogni sito di replica di sistema. SAP HANA dovrebbe essere ancora inattivo.
Preparare l'hook come
root.mkdir -p /hana/shared/myHooks cp /usr/share/SAPHanaSR-ScaleOut/SAPHanaSR.py /hana/shared/myHooks chown -R hn1adm:sapsys /hana/shared/myHooksRegolare
global.ini.# add to global.ini [ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /hana/shared/myHooks execution_order = 1 [trace] ha_dr_saphanasr = info
[AH] Il cluster richiede la configurazione sudoers nel nodo del cluster per <sid>adm. In questo esempio si ottiene questo risultato creando un nuovo file. Eseguire i comandi come
root.sudo visudo -f /etc/sudoers.d/20-saphana # Insert the following lines and then save Cmnd_Alias SOK = /usr/sbin/crm_attribute -n hana_hn1_glob_srHook -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL = /usr/sbin/crm_attribute -n hana_hn1_glob_srHook -v SFAIL -t crm_config -s SAPHanaSR hn1adm ALL=(ALL) NOPASSWD: SOK, SFAIL Defaults!SOK, SFAIL !requiretty[1,2] Avviare SAP HANA in entrambi i siti di replica. Eseguire come <sid>adm.
sapcontrol -nr 03 -function StartSystem[1] Verificare l'installazione dell'hook. Eseguire come <sid>adm nel sito di replica di sistema HANA attivo.
cdtrace awk '/ha_dr_SAPHanaSR.*crm_attribute/ \ { printf "%s %s %s %s\n",$2,$3,$5,$16 }' nameserver_* # Example entries # 2020-07-21 22:04:32.364379 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:04:46.905661 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:04:52.092016 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:04:52.782774 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:04:53.117492 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:06:35.599324 ha_dr_SAPHanaSR SOK[1] Creare le risorse del cluster HANA. Eseguire i comandi seguenti come
root.Assicurarsi che il cluster sia già in modalità di manutenzione.
Creare quindi la risorsa topologia HANA.
Se si sta creando un cluster RHEL 7.x , usare i comandi seguenti:pcs resource create SAPHanaTopology_HN1_HDB03 SAPHanaTopologyScaleOut \ SID=HN1 InstanceNumber=03 \ op start timeout=600 op stop timeout=300 op monitor interval=10 timeout=600 pcs resource clone SAPHanaTopology_HN1_HDB03 meta clone-node-max=1 interleave=trueSe si sta creando un cluster RHEL >= 8.x , usare i comandi seguenti:
pcs resource create SAPHanaTopology_HN1_HDB03 SAPHanaTopology \ SID=HN1 InstanceNumber=03 meta clone-node-max=1 interleave=true \ op methods interval=0s timeout=5 \ op start timeout=600 op stop timeout=300 op monitor interval=10 timeout=600 pcs resource clone SAPHanaTopology_HN1_HDB03 meta clone-node-max=1 interleave=trueCreare la risorsa dell'istanza di HANA.
Nota
Questo articolo contiene riferimenti a un termine che Microsoft non usa più. Quando il termine verrà rimosso dal software, verrà rimosso anche dall'articolo.
Se si sta creando un cluster RHEL 7.x , usare i comandi seguenti:
pcs resource create SAPHana_HN1_HDB03 SAPHanaController \ SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \ op start interval=0 timeout=3600 op stop interval=0 timeout=3600 op promote interval=0 timeout=3600 \ op monitor interval=60 role="Master" timeout=700 op monitor interval=61 role="Slave" timeout=700 pcs resource master msl_SAPHana_HN1_HDB03 SAPHana_HN1_HDB03 \ meta master-max="1" clone-node-max=1 interleave=trueSe si sta creando un cluster RHEL >= 8.x , usare i comandi seguenti:
pcs resource create SAPHana_HN1_HDB03 SAPHanaController \ SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \ op demote interval=0s timeout=320 op methods interval=0s timeout=5 \ op start interval=0 timeout=3600 op stop interval=0 timeout=3600 op promote interval=0 timeout=3600 \ op monitor interval=60 role="Master" timeout=700 op monitor interval=61 role="Slave" timeout=700 pcs resource promotable SAPHana_HN1_HDB03 \ meta master-max="1" clone-node-max=1 interleave=trueImportante
È consigliabile impostare su
AUTOMATED_REGISTERfalse, mentre si eseguono test di failover, per evitare che un'istanza primaria non riuscita venga registrata automaticamente come secondaria. Dopo il test, come procedura consigliata, impostare suAUTOMATED_REGISTERtrue, in modo che dopo l'acquisizione, la replica di sistema possa riprendere automaticamente.Creare l'INDIRIZZO IP virtuale e le risorse associate.
pcs resource create vip_HN1_03 ocf:heartbeat:IPaddr2 ip=10.23.0.18 op monitor interval="10s" timeout="20s" sudo pcs resource create nc_HN1_03 azure-lb port=62503 sudo pcs resource group add g_ip_HN1_03 nc_HN1_03 vip_HN1_03Creare i vincoli del cluster.
Se si sta creando un cluster RHEL 7.x , usare i comandi seguenti:
#Start HANA topology, before the HANA instance pcs constraint order SAPHanaTopology_HN1_HDB03-clone then msl_SAPHana_HN1_HDB03 pcs constraint colocation add g_ip_HN1_03 with master msl_SAPHana_HN1_HDB03 4000 #HANA resources are only allowed to run on a node, if the node's NFS file systems are mounted. The constraint also avoids the majority maker node pcs constraint location SAPHanaTopology_HN1_HDB03-clone rule resource-discovery=never score=-INFINITY hana_nfs_s1_active ne true and hana_nfs_s2_active ne trueSe si sta creando un cluster RHEL >= 8.x , usare i comandi seguenti:
#Start HANA topology, before the HANA instance pcs constraint order SAPHanaTopology_HN1_HDB03-clone then SAPHana_HN1_HDB03-clone pcs constraint colocation add g_ip_HN1_03 with master SAPHana_HN1_HDB03-clone 4000 #HANA resources are only allowed to run on a node, if the node's NFS file systems are mounted. The constraint also avoids the majority maker node pcs constraint location SAPHanaTopology_HN1_HDB03-clone rule resource-discovery=never score=-INFINITY hana_nfs_s1_active ne true and hana_nfs_s2_active ne true
[1] Posizionare il cluster fuori dalla modalità di manutenzione. Assicurarsi che lo stato del cluster sia
oke che tutte le risorse vengano avviate.sudo pcs property set maintenance-mode=false #If there are failed cluster resources, you may need to run the next command pcs resource cleanupNota
I timeout nella configurazione precedente sono solo esempi e potrebbero essere necessari per adattarsi all'installazione specifica di HANA. Ad esempio, potrebbe essere necessario aumentare il timeout di avvio, se l'avvio del database SAP HANA richiede più tempo.
Configurare la replica di sistema attiva/abilitata per la lettura di HANA
A partire da SAP HANA 2.0 SPS 01, SAP consente configurazioni attive/abilitate per la lettura per la replica di sistema SAP HANA. Con questa funzionalità, è possibile usare i sistemi secondari della replica di sistema SAP HANA attivamente per carichi di lavoro a elevato utilizzo di lettura. Per supportare tale configurazione in un cluster, è necessario un secondo indirizzo IP virtuale, che consente ai client di accedere al database SAP HANA abilitato per la lettura secondario. Per assicurarsi che il sito di replica secondario sia ancora accessibile dopo che si è verificato un'acquisizione, il cluster deve spostare l'indirizzo IP virtuale con il database secondario della risorsa SAP HANA.
Questa sezione descrive i passaggi aggiuntivi da eseguire per gestire questo tipo di replica di sistema in un cluster a disponibilità elevata di Red Hat, con un secondo indirizzo IP virtuale.
Prima di procedere, assicurarsi di avere completamente configurato un cluster red Hat a disponibilità elevata, gestendo un database SAP HANA, come descritto in precedenza in questo articolo.
Configurazione aggiuntiva in Azure Load Balancer per la configurazione attiva/abilitata per la lettura
Per procedere con il provisioning del secondo indirizzo IP virtuale, assicurarsi di aver configurato Azure Load Balancer come descritto in Configurare Azure Load Balancer.
Per il servizio di bilanciamento del carico standard , seguire questi passaggi aggiuntivi sullo stesso servizio di bilanciamento del carico creato nella sezione precedente.
Creare un secondo pool di indirizzi IP front-end:
- Aprire il servizio di bilanciamento del carico, selezionare Pool di indirizzi IP front-end e quindi Aggiungi.
- Immettere il nome del secondo pool di indirizzi IP front-end, ad esempio hana-secondaryIP.
- Impostare Assegnazione su Statico e immettere l'indirizzo IP, ad esempio 10.23.0.19.
- Seleziona OK.
- Dopo aver creato il nuovo pool di indirizzi IP front-end, annotare l'indirizzo IP del pool.
Creare quindi un probe di integrità:
- Aprire il servizio di bilanciamento del carico, selezionare Probe integrità e quindi Aggiungi.
- Immettere il nome del nuovo probe di integrità, ad esempio hana-secondaryhp.
- Selezionare TCP come protocollo e porta 62603. Lasciare il valore di Intervallo impostato su 5 e il valore di Soglia di non integrità impostato su 2.
- Seleziona OK.
Successivamente, creare le regole del servizio di bilanciamento del carico:
- Aprire il servizio di bilanciamento del carico, selezionare Regole di bilanciamento del carico e quindi Aggiungi.
- Immettere il nome della nuova regola di bilanciamento del carico, ad esempio hana-secondarylb.
- Selezionare l'indirizzo IP front-end, il pool back-end e il probe di integrità creato in precedenza, ad esempio hana-secondaryIP, hana-backend e hana-secondaryhp.
- Selezionare Porte a disponibilità elevata.
- Assicurarsi di selezionare Abilita l'indirizzo IP mobile.
- Seleziona OK.
Configurare la replica di sistema attiva/abilitata per la lettura di HANA
I passaggi per configurare la replica di sistema HANA sono descritti nella sezione Configurare la replica di sistema SAP HANA 2.0. Se si distribuisce uno scenario secondario abilitato per la lettura, durante la configurazione della replica di sistema nel secondo nodo, eseguire il comando seguente come hanasidadm:
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hana-s1-db1 --remoteInstance=03 --replicationMode=sync --name=HANA_S2 --operationMode=logreplay_readaccess
Aggiungere una risorsa indirizzo IP virtuale secondario per un'installazione attiva/abilitata per la lettura
È possibile configurare il secondo indirizzo IP virtuale e i vincoli aggiuntivi con i comandi seguenti. Se l'istanza secondaria è inattiva, l'INDIRIZZO IP virtuale secondario verrà impostato sul database primario.
pcs property set maintenance-mode=true
pcs resource create secvip_HN1_03 ocf:heartbeat:IPaddr2 ip="10.23.0.19"
pcs resource create secnc_HN1_03 ocf:heartbeat:azure-lb port=62603
pcs resource group add g_secip_HN1_03 secnc_HN1_03 secvip_HN1_03
# RHEL 8.x:
pcs constraint location g_ip_HN1_03 rule score=500 role=master hana_hn1_roles eq "master1:master:worker:master" and hana_hn1_clone_state eq PROMOTED
pcs constraint location g_secip_HN1_03 rule score=50 hana_hn1_roles eq 'master1:master:worker:master'
pcs constraint order promote SAPHana_HN1_HDB03-clone then start g_ip_HN1_03
pcs constraint order start g_ip_HN1_03 then start g_secip_HN1_03
pcs constraint colocation add g_secip_HN1_03 with Slave SAPHana_HN1_HDB03-clone 5
# RHEL 7.x:
pcs constraint location g_ip_HN1_03 rule score=500 role=master hana_hn1_roles eq "master1:master:worker:master" and hana_hn1_clone_state eq PROMOTED
pcs constraint location g_secip_HN1_03 rule score=50 hana_hn1_roles eq 'master1:master:worker:master'
pcs constraint order promote msl_SAPHana_HN1_HDB03 then start g_ip_HN1_03
pcs constraint order start g_ip_HN1_03 then start g_secip_HN1_03
pcs constraint colocation add g_secip_HN1_03 with Slave msl_SAPHana_HN1_HDB03 5
pcs property set maintenance-mode=false
Assicurarsi che lo stato del cluster sia oke che tutte le risorse vengano avviate. Il secondo indirizzo IP virtuale verrà eseguito nel sito secondario insieme alla risorsa secondaria di SAP HANA.
# Example output from crm_mon
#Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#
#Active resources:
#
#rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm
#Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1]
# Started: [ hana--s1-db1 hana-s1-db2 hana-s1-db3 ]
#Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2]
# Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active]
# Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ]
#Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active]
# Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03]
# Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03]
# Masters: [ hana-s1-db1 ]
# Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Resource Group: g_ip_HN1_03
# nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1
# vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1
#Resource Group: g_secip_HN1_03
# secnc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s2-db1
# secvip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s2-db1
Nella sezione successiva è possibile trovare il set tipico di test di failover da eseguire.
Quando si testa un cluster HANA configurato con un database secondario abilitato per la lettura, tenere presente il comportamento seguente del secondo indirizzo IP virtuale:
Quando la risorsa cluster SAPHana_HN1_HDB03 passa al sito secondario (S2), il secondo indirizzo IP virtuale verrà spostato nell'altro sito, hana-s1-db1. Se è stata configurata
AUTOMATED_REGISTER="false"e la replica di sistema HANA non viene registrata automaticamente, il secondo INDIRIZZO IP virtuale verrà eseguito in hana-s2-db1.Quando si esegue il test dell'arresto anomalo del server, le seconde risorse IP virtuali (secvip_HN1_03) e la risorsa porta di Azure Load Balancer (secnc_HN1_03) vengono eseguite nel server primario, insieme alle risorse IP virtuali primarie. Mentre il server secondario è inattivo, le applicazioni connesse al database HANA abilitato per la lettura si connetteranno al database HANA primario. Questo comportamento è previsto. Consente alle applicazioni connesse al database HANA abilitato per la lettura di funzionare mentre un server secondario non è disponibile.
Durante il failover e il fallback, le connessioni esistenti per le applicazioni che usano il secondo indirizzo IP virtuale per connettersi al database HANA potrebbero essere interrotte.
Testare il failover di SAP HANA
Prima di avviare un test, controllare lo stato di replica del cluster e del sistema SAP HANA.
Verificare che non siano presenti azioni cluster non riuscite.
#Verify that there are no failed cluster actions pcs status # Example #Stack: corosync #Current DC: hana-s-mm (version 1.1.19-8.el7_6.5-c3c624ea3d) - partition with quorum #Last updated: Thu Sep 24 06:00:20 2020 #Last change: Thu Sep 24 05:59:17 2020 by root via crm_attribute on hana-s1-db1 # #7 nodes configured #45 resources configured # #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # #Active resources: # #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm #Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana--s1-db1 hana-s1-db2 hana-s1-db3 ] #Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] #Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s1-db1 ] # Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1Verificare che la replica di sistema SAP HANA sia sincronizzata.
# Verify HANA HSR is in sync sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py" #| Database | Host | Port | Service Name | Volume ID | Site ID | Site Name | Secondary | Secondary| Secondary | Secondary | Secondary | Replication | Replication | Replication | #| | | | | | | | Host | Port | Site ID | Site Name | Active Status | Mode | Status | Status Details | #| -------- | ----------- | ----- | ------------ | --------- | ------- | --------- | ------------- | -------- | --------- | --------- | ------------- | ----------- | ----------- | -------------- | #| HN1 | hana-s1-db3 | 30303 | indexserver | 5 | 2 | HANA_S1 | hana-s2-db3 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db2 | 30303 | indexserver | 4 | 2 | HANA_S1 | hana-s2-db2 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| SYSTEMDB | hana-s1-db1 | 30301 | nameserver | 1 | 2 | HANA_S1 | hana-s2-db1 | 30301 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db1 | 30307 | xsengine | 2 | 2 | HANA_S1 | hana-s2-db1 | 30307 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db1 | 30303 | indexserver | 3 | 2 | HANA_S1 | hana-s2-db1 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #status system replication site "1": ACTIVE #overall system replication status: ACTIVE #Local System Replication State #~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ #mode: PRIMARY #site id: 1 #site name: HANA_S1
Verificare la configurazione del cluster per uno scenario di errore quando un nodo perde l'accesso alla condivisione NFS (
/hana/shared).Gli agenti di risorse SAP HANA dipendono dai file binari, archiviati in
/hana/shared, per eseguire operazioni durante il failover. Il file system/hana/sharedviene montato su NFS nella configurazione presentata. Un test che può essere eseguito consiste nel creare una regola del firewall temporanea per bloccare l'accesso/hana/sharedal file system montato NFS in una delle macchine virtuali del sito primario. Questo approccio convalida che il cluster eseguirà il failover, se l'accesso a/hana/sharedandrà perso nel sito di replica di sistema attivo.Risultato previsto: quando si blocca l'accesso al
/hana/sharedfile system montato NFS in una delle macchine virtuali del sito primario, l'operazione di monitoraggio che esegue operazioni di lettura/scrittura nel file system avrà esito negativo, perché non è in grado di accedere al file system e attiverà il failover delle risorse HANA. Lo stesso risultato è previsto quando il nodo HANA perde l'accesso alla condivisione NFS.È possibile controllare lo stato delle risorse del cluster eseguendo
crm_monopcs status. Stato delle risorse prima dell'avvio del test:# Output of crm_mon #7 nodes configured #45 resources configured #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # #Active resources: #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm # Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s1-db1 ] # Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1Per simulare un errore per
/hana/shared:- Se si usa NFS in ANF, verificare prima di tutto l'indirizzo IP per il
/hana/sharedvolume ANF nel sito primario. A tale scopo, eseguiredf -kh|grep /hana/shared. - Se si usa NFS in File di Azure, determinare prima di tutto l'indirizzo IP dell'endpoint privato per l'account di archiviazione.
Configurare quindi una regola del firewall temporanea per bloccare l'accesso all'indirizzo IP del
/hana/sharedfile system NFS eseguendo il comando seguente in una delle macchine virtuali del sito di replica del sistema HANA primario.In questo esempio il comando è stato eseguito su hana-s1-db1 per il volume
/hana/sharedANF .iptables -A INPUT -s 10.23.1.7 -j DROP; iptables -A OUTPUT -d 10.23.1.7 -j DROPLa macchina virtuale HANA che ha perso l'accesso a
/hana/shareddeve essere riavviata o interrotta, a seconda della configurazione del cluster. Le risorse del cluster vengono migrate nell'altro sito di replica di sistema HANA.Se il cluster non è stato avviato nella macchina virtuale riavviata, avviare il cluster eseguendo quanto segue:
# Start the cluster pcs cluster startAll'avvio del cluster, il file system
/hana/sharedviene montato automaticamente. Se si impostaAUTOMATED_REGISTER="false", sarà necessario configurare la replica di sistema SAP HANA nel sito secondario. In questo caso, è possibile eseguire questi comandi per riconfigurare SAP HANA come secondario.# Execute on the secondary su - hn1adm # Make sure HANA is not running on the secondary site. If it is started, stop HANA sapcontrol -nr 03 -function StopWait 600 10 # Register the HANA secondary site hdbnsutil -sr_register --name=HANA_S1 --remoteHost=hana-s2-db1 --remoteInstance=03 --replicationMode=sync # Switch back to root and clean up failed resources pcs resource cleanup SAPHana_HN1_HDB03Stato delle risorse, dopo il test:
# Output of crm_mon #7 nodes configured #45 resources configured #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Active resources: #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm # Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s2-db1 ] # Slaves: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db2 hana-s2-db3 ] # Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s2-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s2-db1- Se si usa NFS in ANF, verificare prima di tutto l'indirizzo IP per il
È consigliabile testare accuratamente la configurazione del cluster SAP HANA, eseguendo anche i test documentati in DISPONIBILITÀ elevata per SAP HANA nelle macchine virtuali di Azure in RHEL.
Passaggi successivi
- Pianificazione e implementazione di macchine virtuali di Azure per SAP
- Distribuzione di Macchine virtuali di Azure per SAP
- Distribuzione DBMS di macchine virtuali di Azure per SAP
- Volumi NFS v4.1 in Azure NetApp Files per SAP HANA
- Per informazioni su come stabilire la disponibilità elevata e pianificare il ripristino di emergenza di SAP HANA nelle macchine virtuali di Azure, vedere Disponibilità elevata di SAP HANA nelle macchine virtuali di Azure.