Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Suggerimento
Questo contenuto è un estratto dell'eBook, Architettura di microservizi .NET per applicazioni .NET containerizzati, disponibile in documentazione .NET o come PDF scaricabile gratuitamente leggibile offline.

Sfida 1: Come definire i limiti di ogni microservizio
La definizione dei limiti dei microservizi è probabilmente la prima sfida che chiunque incontra. Ogni microservizio deve essere una parte dell'applicazione e ogni microservizio deve essere autonomo con tutti i vantaggi e le sfide che trasmette. Ma come si identificano questi limiti?
In primo luogo, è necessario concentrarsi sui modelli di dominio logici dell'applicazione e sui dati correlati. Provare a identificare isole disaccoppiate di dati e contesti diversi all'interno della stessa applicazione. Ogni contesto può avere un linguaggio aziendale diverso (termini aziendali diversi). I contesti devono essere definiti e gestiti in modo indipendente. I termini e le entità usati in questi contesti diversi potrebbero sembrare simili, ma si potrebbe scoprire che in un particolare contesto un concetto aziendale con uno viene usato per uno scopo diverso in un altro contesto e potrebbe anche avere un nome diverso. Ad esempio, un utente può essere definito utente nel contesto di identità o appartenenza, come cliente in un contesto CRM, come acquirente in un contesto di ordinamento e così via.
Il modo in cui si identificano i limiti tra più contesti dell'applicazione con un dominio diverso per ogni contesto è esattamente come è possibile identificare i limiti per ogni microservizio aziendale e i relativi dati e modello di dominio correlati. Si tenta sempre di ridurre al minimo l'accoppiamento tra questi microservizi. Questa guida illustra in modo più dettagliato questa progettazione di identificazione e modello di dominio nella sezione Identificazione dei limiti del modello di dominio per ogni microservizio in un secondo momento.
Sfida 2: Come creare query che recuperano dati da diversi microservizi
Una seconda sfida consiste nell'implementare query che recuperano i dati da diversi microservizi, evitando al tempo stesso la comunicazione chatty con i microservizi dalle app client remote. Un esempio può essere un'unica schermata di un'app per dispositivi mobili che deve mostrare le informazioni utente di proprietà del carrello, del catalogo e dei microservizi di identità utente. Un altro esempio è un report complesso che include molte tabelle che si trovano in più microservizi. La soluzione corretta dipende dalla complessità delle query. Tuttavia, in ogni caso, è necessario un modo per aggregare le informazioni se si vuole migliorare l'efficienza nelle comunicazioni del sistema. Di seguito sono riportate le soluzioni più diffuse.
Gateway API. Per un'aggregazione di dati semplice da più microservizi che possiedono database diversi, l'approccio consigliato è un microservizio di aggregazione denominato gateway API. Tuttavia, è necessario prestare attenzione all'implementazione di questo modello, perché può essere un punto di soffocamento nel sistema e può violare il principio dell'autonomia dei microservizi. Per attenuare questa possibilità, è possibile avere più gateway API con granularità fine, ognuno dei quali si concentra su una "sezione" verticale o su un'area aziendale del sistema. Il modello di gateway API è illustrato in modo più dettagliato nella sezione Gateway API più avanti.
Federazione graphQL Un'opzione da considerare se i microservizi usano già GraphQL è la federazione GraphQL. La federazione consente di definire "sottogrammi" da altri servizi e di componerli in un "supergrafo" aggregato che funge da schema autonomo.
CQRS con tabelle di query/lettura. Un'altra soluzione per l'aggregazione di dati da più microservizi è il modello di visualizzazione materializzata. In questo approccio, si generano in anticipo (preparare i dati denormalizzati prima dell'esecuzione delle query effettive), una tabella di sola lettura con i dati di proprietà di più microservizi. La tabella ha un formato adatto alle esigenze dell'app client.
Si consideri una schermata simile a quella di un'app per dispositivi mobili. Se si dispone di un database singolo, è possibile raggruppare i dati per tale schermata usando una query SQL che esegue un join complesso che coinvolge più tabelle. Tuttavia, quando si dispone di più database e ogni database è di proprietà di un microservizio diverso, non è possibile eseguire query su tali database e creare un join SQL. La tua richiesta complessa rappresenta una sfida. È possibile soddisfare il requisito usando un approccio CQRS: si crea una tabella denormalizzata in un database diverso usato solo per le query. La tabella può essere progettata specificamente per i dati necessari alla query complessa, con una corrispondenza uno-a-uno tra i campi necessari per la schermata dell'applicazione e le colonne nella tabella di query. Può anche servire a scopi di reporting.
Questo approccio non solo risolve il problema originale (come eseguire query e join tra microservizi), ma migliora anche notevolmente le prestazioni rispetto a un join complesso, perché sono già presenti i dati necessari per l'applicazione nella tabella di query. Naturalmente, l'uso di Command and Query Responsibility Segregation (CQRS) con le tabelle di query/letture implica un lavoro di sviluppo aggiuntivo e sarà necessario adottare la coerenza finale. Tuttavia, i requisiti per le prestazioni e la scalabilità elevata in scenari di collaborazione (o scenari competitivi, a seconda del punto di vista) sono la posizione in cui è necessario applicare CQRS con più database.
"Dati freddi" nei database centrali. Per report complessi e query che potrebbero non richiedere dati in tempo reale, un approccio comune consiste nell'esportare i "dati caldi" (dati transazionali dai microservizi) come "dati freddi" in database di grandi dimensioni usati solo per la reportistica. Questo sistema di database centrale può essere un sistema basato su Big Data, ad esempio Hadoop; un data warehouse come uno basato su Azure SQL Data Warehouse; o anche un singolo database SQL usato solo per i report (se le dimensioni non saranno un problema).
Tenere presente che questo database centralizzato verrà usato solo per query e report che non necessitano di dati in tempo reale. Gli aggiornamenti e le transazioni originali, come fonte di verità, devono trovarsi nei dati dei microservizi. La modalità di sincronizzazione dei dati consiste nell'usare la comunicazione guidata dagli eventi (illustrata nelle sezioni successive) o altri strumenti di importazione/esportazione dell'infrastruttura di database. Se si usa la comunicazione basata su eventi, tale processo di integrazione sarà simile al modo in cui si propagano i dati come descritto in precedenza per le tabelle di query CQRS.
Tuttavia, se la progettazione dell'applicazione comporta l'aggregazione costante di informazioni da più microservizi per query complesse, potrebbe essere un sintomo di una progettazione non valida -a microservizio deve essere il più isolato possibile da altri microservizi. Questo esclude report/analisi che devono sempre usare database centrali a dati ad accesso sporadico. La presenza di questo problema può spesso essere un motivo per unire i microservizi. È necessario bilanciare l'autonomia dell'evoluzione e della distribuzione di ogni microservizio con dipendenze complesse, coesione e aggregazione dei dati.
Sfida 3: Come ottenere la coerenza tra più microservizi
Come indicato in precedenza, i dati di proprietà di ogni microservizio sono privati per tale microservizio e possono essere accessibili solo usando l'API del microservizio. Pertanto, una sfida presentata è come implementare processi aziendali end-to-end mantenendo la coerenza tra più microservizi.
Per analizzare questo problema, si esaminerà un esempio dell'applicazione di riferimento eShopOnContainers. Il microservizio Catalog gestisce informazioni su tutti i prodotti, incluso il prezzo del prodotto. Il microservizio Basket gestisce i dati temporali sugli articoli di prodotto che gli utenti aggiungono ai carrello acquisti, che includono il prezzo degli articoli al momento dell'aggiunta al carrello. Quando il prezzo di un prodotto viene aggiornato nel catalogo, tale prezzo deve essere aggiornato anche nei cesti attivi che contengono lo stesso prodotto, più il sistema dovrebbe probabilmente avvisare l'utente che dice che il prezzo di un particolare articolo è cambiato da quando l'ha aggiunto al carrello.
In una versione ipotetica monolitica di questa applicazione, quando il prezzo cambia nella tabella products, il sottosistema del catalogo potrebbe semplicemente usare una transazione ACID per aggiornare il prezzo corrente nella tabella Basket.
Tuttavia, in un'applicazione basata su microservizi, le tabelle Product e Basket sono di proprietà dei rispettivi microservizi. Nessun microservizio deve mai includere tabelle/archiviazione di proprietà di un altro microservizio nelle proprie transazioni, non anche nelle query dirette, come illustrato nella figura 4-9.
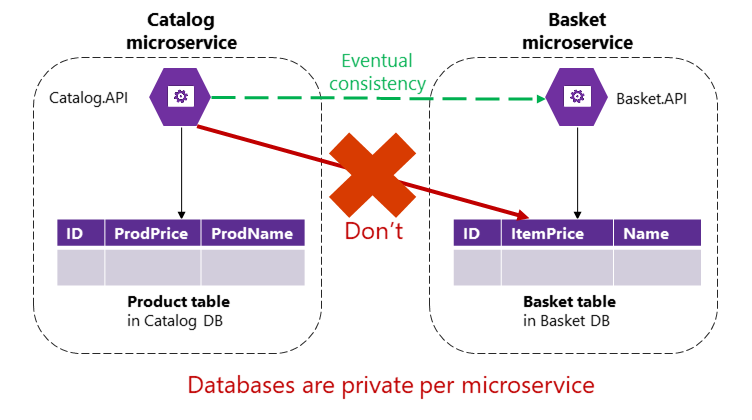
Figura 4-9. Un microservizio non può accedere direttamente a una tabella in un altro microservizio
Il microservizio Catalog non deve aggiornare direttamente la tabella Basket, perché la tabella Basket è di proprietà del microservizio Basket. Per eseguire un aggiornamento al microservizio Basket, il microservizio Catalog deve usare probabilmente la coerenza finale basata su comunicazioni asincrone, ad esempio eventi di integrazione (comunicazione basata su messaggi e eventi). Questo è il modo in cui l'applicazione di riferimento eShopOnContainers esegue questo tipo di coerenza tra microservizi.
È necessario scegliere tra disponibilità e forte coerenza ACID, come indicato dal teorema CAP. La maggior parte degli scenari basati su microservizi richiede disponibilità e scalabilità elevata anziché coerenza assoluta. Le applicazioni cruciali devono rimanere in esecuzione e gli sviluppatori possono aggirare la coerenza assoluta usando tecniche per lavorare con coerenza debole o finale. Questo è l'approccio adottato dalla maggior parte delle architetture basate su microservizi.
Inoltre, le transazioni di commit in stile ACID o a due fasi non sono solo contro i principi dei microservizi; la maggior parte dei database NoSQL (ad esempio Azure Cosmos DB, MongoDB e così via) non supporta transazioni di commit in due fasi, tipiche negli scenari di database distribuiti. Tuttavia, mantenere la coerenza dei dati tra servizi e database è essenziale. Questa sfida è correlata anche alla domanda su come propagare le modifiche tra più microservizi quando determinati dati devono essere ridondanti, ad esempio quando è necessario avere il nome o la descrizione del prodotto nel microservizio Catalog e nel microservizio Basket.
Una buona soluzione per questo problema consiste nell'usare la coerenza finale tra i microservizi articolati tramite comunicazioni guidate dagli eventi e un sistema di pubblicazione e sottoscrizione. Questi argomenti sono trattati nella sezione Comunicazione asincrona basata su eventi più avanti in questa guida.
Sfida 4: Come progettare la comunicazione tra i limiti dei microservizi
La comunicazione tra i limiti dei microservizi è una vera sfida. In questo contesto, la comunicazione non fa riferimento al protocollo da usare (HTTP e REST, AMQP, messaggistica e così via). Si tratta invece dello stile di comunicazione da usare e, in particolare, del modo in cui devono essere associati i microservizi. A seconda del livello di accoppiamento, quando si verifica un errore, l'impatto di tale errore nel sistema varia in modo significativo.
In un sistema distribuito come un'applicazione basata su microservizi, con così tanti artefatti che si spostano e con servizi distribuiti in molti server o host, i componenti alla fine avranno esito negativo. Si verificheranno errori parziali e interruzioni ancora più grandi, quindi è necessario progettare i microservizi e la comunicazione tra di essi considerando i rischi comuni in questo tipo di sistema distribuito.
Un approccio comune consiste nell'implementare microservizi basati su HTTP (REST), grazie alla loro semplicità. Un approccio basato su HTTP è perfettamente accettabile; il problema qui è correlato a come usarlo. Se si usano richieste e risposte HTTP solo per interagire con i microservizi dalle applicazioni client o dai gateway API, è corretto. Tuttavia, se si creano lunghe catene di chiamate HTTP sincrone tra microservizi, comunicando attraverso i relativi limiti come se i microservizi fossero oggetti in un'applicazione monolitica, l'applicazione alla fine si troverà in problemi.
Si supponga, ad esempio, che l'applicazione client effettui una chiamata API HTTP a un singolo microservizio, ad esempio il microservizio Ordering. Se il microservizio Ordinamento chiama a sua volta microservizi aggiuntivi usando HTTP nello stesso ciclo di richiesta/risposta, si sta creando una catena di chiamate HTTP. Inizialmente potrebbe sembrare ragionevole. Tuttavia, ci sono aspetti importanti da considerare quando si scende in questo percorso:
Blocco e prestazioni ridotte. A causa della natura sincrona di HTTP, la richiesta originale non riceve una risposta finché non vengono completate tutte le chiamate HTTP interne. Si supponga che il numero di queste chiamate aumenti significativamente e contemporaneamente venga bloccata una delle chiamate HTTP intermedie a un microservizio. Il risultato è che le prestazioni sono interessate e la scalabilità complessiva sarà influenzata in modo esponenziale man mano che aumentano le richieste HTTP aggiuntive.
Accoppiamento di microservizi con HTTP. I microservizi aziendali non devono essere associati ad altri microservizi aziendali. Idealmente, non dovrebbero "sapere" l'esistenza di altri microservizi. Se l'applicazione si basa sull'accoppiamento di microservizi come nell'esempio, il raggiungimento dell'autonomia per ogni microservizio sarà quasi impossibile.
Errore in un microservizio. Se è stata implementata una catena di microservizi collegati da chiamate HTTP, quando uno dei microservizi ha esito negativo (e alla fine avrà esito negativo) l'intera catena di microservizi avrà esito negativo. Un sistema basato su microservizi deve essere progettato per continuare a funzionare il più possibile durante gli errori parziali. Anche se si implementa la logica client che utilizza tentativi con meccanismi di backoff esponenziale o meccanismi di interruzione del circuito, più complesse sono le catene di chiamate HTTP, più complesso è implementare una strategia di gestione degli errori basata su HTTP.
Infatti, se i microservizi interni comunicano creando catene di richieste HTTP come descritto, si potrebbe sostenere di avere un'applicazione monolitica, ma una basata su HTTP tra processi anziché meccanismi di comunicazione intra-processo.
Pertanto, per applicare l'autonomia dei microservizi e avere una migliore resilienza, è consigliabile ridurre al minimo l'uso di catene di comunicazioni di richiesta/risposta tra microservizi. È consigliabile usare solo l'interazione asincrona per la comunicazione tra microservizi, usando la comunicazione asincrona basata su messaggi e eventi oppure usando il polling HTTP (asincrono) indipendentemente dal ciclo di richiesta/risposta HTTP originale.
L'uso della comunicazione asincrona viene illustrato con altri dettagli più avanti in questa guida nelle sezioni Integrazione asincrona di microservizio applica l'autonomia del microservizio e lacomunicazione asincrona basata su messaggi.
Risorse aggiuntive
Teorema CAP
https://en.wikipedia.org/wiki/CAP_theoremCoerenza finale
https://en.wikipedia.org/wiki/Eventual_consistencyIntroduzione alla coerenza dei dati
https://learn.microsoft.com/previous-versions/msp-n-p/dn589800(v=pandp.10)Martin Fowler. CQRS (Separazione delle Responsabilità di Comando e Interrogazione)
https://martinfowler.com/bliki/CQRS.htmlVista materializzata
https://learn.microsoft.com/azure/architecture/patterns/materialized-viewCharles Row. ACID vs BASE: Il pH mutevole nell'elaborazione delle transazioni di database
https://www.dataversity.net/acid-vs-base-the-shifting-ph-of-database-transaction-processing/Transazione di compensazione
https://learn.microsoft.com/azure/architecture/patterns/compensating-transactionUdi Dahan. Composizione orientata ai servizi
https://udidahan.com/2014/07/30/service-oriented-composition-with-video/
Collabora con noi su GitHub
L'origine di questo contenuto è disponibile in GitHub, in cui è anche possibile creare ed esaminare i problemi e le richieste pull. Per ulteriori informazioni, vedere la guida per i collaboratori.