Eventi
31 mar, 23 - 2 apr, 23
Il più grande evento di apprendimento di Fabric, Power BI e SQL. 31 marzo - 2 aprile. Usare il codice FABINSIDER per salvare $400.
Iscriviti oggi stessoQuesto browser non è più supportato.
Esegui l'aggiornamento a Microsoft Edge per sfruttare i vantaggi di funzionalità più recenti, aggiornamenti della sicurezza e supporto tecnico.
In Microsoft OneLake è possibile creare collegamenti alle tabelle Apache Iceberg, abilitandone l'uso in tutta l'ampia gamma di carichi di lavoro fabric. Questa funzionalità è resa possibile tramite una funzionalità denominata virtualizzazione dei metadati, che consente di interpretare le tabelle Iceberg come tabelle Delta Lake dal punto di vista del collegamento. Quando si crea un collegamento a una cartella di tabella Iceberg, OneLake genera automaticamente i metadati Delta Lake corrispondenti (log Delta) per tale tabella, rendendo i metadati Delta Lake accessibili tramite il collegamento.
Importante
Questa funzionalità si trova in anteprima.

Anche se questo articolo include indicazioni per la scrittura di tabelle Iceberg da Snowflake a OneLake, questa funzionalità è progettata per lavorare con qualsiasi tabella Iceberg con file di dati Parquet.
Se si dispone già di una tabella Iceberg in una posizione di archiviazione supportata dai collegamenti onelake, seguire questa procedura per creare un collegamento e visualizzare la tabella Iceberg con il formato Delta Lake.
Individuare la tabella Iceberg. Trovare la posizione in cui è archiviata la tabella Iceberg, che potrebbe trovarsi in Azure Data Lake Storage, OneLake, Amazon S3, Google Cloud Storage o in un servizio di archiviazione compatibile con S3.
Nota
Se si usa Snowflake e non si è certi della posizione in cui è archiviata la tabella Iceberg, è possibile eseguire l'istruzione seguente per visualizzare la posizione di archiviazione della tabella Iceberg.
SELECT SYSTEM$GET_ICEBERG_TABLE_INFORMATION('<table_name>');
L'esecuzione di questa istruzione restituisce un percorso al file di metadati per la tabella Iceberg. Questo percorso indica quale account di archiviazione contiene la tabella Iceberg. Ecco ad esempio le informazioni pertinenti per trovare il percorso di una tabella Iceberg archiviata in Azure Data Lake Storage:
{"metadataLocation":"azure://<storage_account_path>/<path_within_storage>/<table_name>/metadata/00001-389700a2-977f-47a2-9f5f-7fd80a0d41b2.metadata.json","status":"success"}
La cartella della tabella Iceberg deve contenere una metadata cartella, che contiene almeno un file che termina con .metadata.json.
In fabric lakehouse creare un nuovo collegamento nell'area Tabelle di una lakehouse non abilitata per lo schema.
Nota
Se vengono visualizzati schemi come dbo nella cartella Tabelle del lakehouse, la lakehouse è abilitata per lo schema e non è ancora compatibile con questa funzionalità.

Per il percorso di destinazione del collegamento, selezionare la cartella tabella Iceberg. La cartella della tabella Iceberg contiene le metadata cartelle e data .
Dopo aver creato il collegamento, questa tabella dovrebbe essere visualizzata automaticamente come tabella Delta Lake nella lakehouse, pronta per l'uso in tutta l'infrastruttura.

Se il nuovo collegamento alla tabella Iceberg non viene visualizzato come tabella utilizzabile, vedere la sezione Risoluzione dei problemi .
Se si usa Snowflake in Azure, è possibile scrivere tabelle Iceberg in OneLake seguendo questa procedura:
Assicurarsi che la capacità dell'infrastruttura si trova nella stessa posizione di Azure dell'istanza snowflake.
Identificare la posizione della capacità infrastruttura associata alla lakehouse di Fabric. Aprire le impostazioni dell'area di lavoro Infrastruttura che contiene il lakehouse.
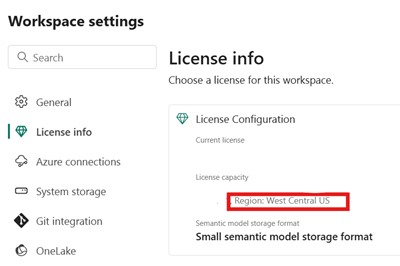
Nell'angolo inferiore sinistro dell'interfaccia dell'account Snowflake in Azure controllare l'area di Azure dell'account Snowflake.
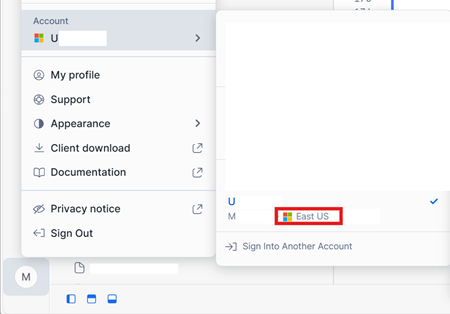
Se queste aree sono diverse, è necessario usare una capacità infrastruttura diversa nella stessa area dell'account Snowflake.
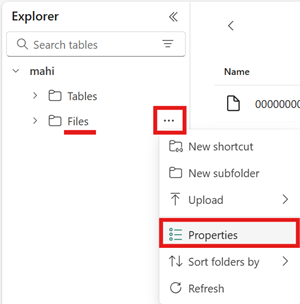
Aprire il menu per l'area File del lakehouse, selezionare Proprietà e copiare l'URL (percorso HTTPS) di tale cartella.
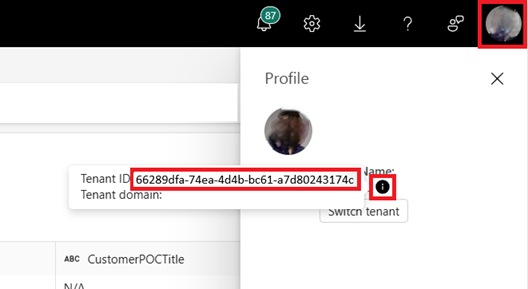
Identificare l'ID tenant di Fabric. Selezionare il profilo utente nell'angolo superiore destro dell'interfaccia utente di Fabric e passare il puntatore del mouse sulla bolla info accanto al nome del tenant. Copiare l'ID tenant.
In Snowflake configurare EXTERNAL VOLUME usando il percorso della cartella Files nella lakehouse.
Altre informazioni sulla configurazione di volumi esterni Snowflake sono disponibili qui.
Nota
Snowflake richiede che lo schema URL sia azure://, quindi assicurarsi di passare https:// a azure://.
CREATE OR REPLACE EXTERNAL VOLUME onelake_exvol
STORAGE_LOCATIONS =
(
(
NAME = 'onelake_exvol'
STORAGE_PROVIDER = 'AZURE'
STORAGE_BASE_URL = 'azure://<path_to_Files>/icebergtables'
AZURE_TENANT_ID = '<Tenant_ID>'
)
);
In questo esempio, tutte le tabelle create con questo volume esterno vengono archiviate nella lakehouse fabric all'interno della Files/icebergtables cartella .
Dopo aver creato il volume esterno, eseguire il comando seguente per recuperare l'URL di consenso e il nome dell'applicazione usata da Snowflake per scrivere in OneLake. Questa applicazione viene usata da qualsiasi altro volume esterno nell'account Snowflake.
DESC EXTERNAL VOLUME onelake_exvol;
L'output di questo comando restituisce le AZURE_CONSENT_URL proprietà e AZURE_MULTI_TENANT_APP_NAME . Prendere nota di entrambi i valori. Il nome dell'app Azure multi-tenant è simile <name>_<number>a , ma è sufficiente acquisire la <name> parte.
Aprire l'URL del consenso del passaggio precedente in una nuova scheda del browser. Se si vuole procedere, fornire il consenso alle autorizzazioni dell'applicazione necessarie, se richiesto.
Tornare in Infrastruttura, aprire l'area di lavoro e selezionare Gestisci accesso, quindi Aggiungi utenti o gruppi. Concedere all'applicazione usata dal volume esterno Snowflake le autorizzazioni necessarie per scrivere dati in lakehouse nell'area di lavoro. È consigliabile concedere il ruolo Collaboratore .
Tornare a Snowflake, usare il nuovo volume esterno per creare una tabella Iceberg.
CREATE OR REPLACE ICEBERG TABLE MYDATABASE.PUBLIC.Inventory (
InventoryId int,
ItemName STRING
)
EXTERNAL_VOLUME = 'onelake_exvol'
CATALOG = 'SNOWFLAKE'
BASE_LOCATION = 'Inventory/';
Con questa istruzione, viene creata una nuova cartella di tabella Iceberg denominata Inventory all'interno del percorso della cartella definito nel volume esterno.
Aggiungere alcuni dati alla tabella Iceberg.
INSERT INTO MYDATABASE.PUBLIC.Inventory
VALUES
(123456,'Amatriciana');
Infine, nell'area Tabelle della stessa lakehouse, è possibile creare un collegamento OneLake alla tabella Iceberg. Tramite questo collegamento, la tabella Iceberg viene visualizzata come tabella Delta Lake per l'utilizzo tra carichi di lavoro di Fabric.
I suggerimenti seguenti consentono di assicurarsi che le tabelle iceberg siano compatibili con questa funzionalità:
Aprire la cartella Iceberg nello strumento di esplorazione dello spazio di archiviazione preferito e controllare l'elenco della directory della cartella Iceberg nella posizione originale. Verrà visualizzata una struttura di cartelle simile all'esempio seguente.
../
|-- MyIcebergTable123/
|-- data/
|-- snow_A5WYPKGO_2o_APgwTeNOAxg_0_1_002.parquet
|-- snow_A5WYPKGO_2o_AAIBON_h9Rc_0_1_003.parquet
|-- metadata/
|-- 00000-1bdf7d4c-dc90-488e-9dd9-2e44de30a465.metadata.json
|-- 00001-08bf3227-b5d2-40e2-a8c7-2934ea97e6da.metadata.json
|-- 00002-0f6303de-382e-4ebc-b9ed-6195bd0fb0e7.metadata.json
|-- 1730313479898000000-Kws8nlgCX2QxoDHYHm4uMQ.avro
|-- 1730313479898000000-OdsKRrRogW_PVK9njHIqAA.avro
|-- snap-1730313479898000000-9029d7a2-b3cc-46af-96c1-ac92356e93e9.avro
|-- snap-1730313479898000000-913546ba-bb04-4c8e-81be-342b0cbc5b50.avro
Se la cartella dei metadati non viene visualizzata o se non vengono visualizzati i file con le estensioni mostrate in questo esempio, potrebbe non essere presente una tabella Iceberg generata correttamente.
Quando una tabella Iceberg viene virtualizzata come tabella Delta Lake, è possibile trovare una cartella denominata _delta_log/ all'interno della cartella di collegamento. Questa cartella contiene i metadati del formato Delta Lake (log Delta) dopo la conversione corretta.
Questa cartella include anche il latest_conversion_log.txt file, che contiene i dettagli sull'esito positivo o negativo della conversione tentata più recente.
Per visualizzare il contenuto di questo file dopo aver creato il collegamento, aprire il menu per il collegamento alla tabella Iceberg nell'area Tabelle del lakehouse e selezionare Visualizza file.

Verrà visualizzata una struttura simile all'esempio seguente:
Tables/
|-- MyIcebergTable123/
|-- data/
|-- <data files>
|-- metadata/
|-- <metadata files>
|-- _delta_log/ <-- Virtual folder. This folder doesn't exist in the original location.
|-- 00000000000000000000.json
|-- latest_conversion_log.txt <-- Conversion log with latest success/failure details.
Aprire il file di log della conversione per visualizzare i dettagli dell'ora di conversione o dell'errore più recenti. Se non viene visualizzato un file di log di conversione, la conversione non è stata tentata.
Se non viene visualizzato un file di log di conversione, la conversione non è stata tentata. Ecco due motivi comuni per cui la conversione non viene tentata:
Il collegamento non è stato creato nel posto giusto.
Affinché un collegamento a una tabella Iceberg venga convertito nel formato Delta Lake, il collegamento deve essere posizionato direttamente nella cartella Tables di una lakehouse non abilitata per lo schema. Non è consigliabile posizionare il collegamento nella sezione File o in un'altra cartella se si vuole che la tabella venga virtualizzata automaticamente come tabella Delta Lake.
Il percorso di destinazione del collegamento non è il percorso della cartella Iceberg.
Quando si crea il collegamento, il percorso della cartella selezionato nel percorso di archiviazione di destinazione deve essere solo la cartella della tabella Iceberg. Questa cartella contiene le metadata cartelle e data .

Tenere presenti le limitazioni temporanee seguenti quando si usa questa funzionalità:
Tipi di dati supportati
I tipi di dati della colonna Iceberg seguenti eseguono il mapping ai tipi Delta Lake corrispondenti usando questa funzionalità.
| Tipo di colonna Iceberg | Tipo di colonna Delta Lake | Commenti |
|---|---|---|
int |
integer |
|
long |
long |
Vedere Problema di larghezza dei tipi. |
float |
float |
|
double |
double |
Vedere Problema di larghezza dei tipi. |
decimal(P, S) |
decimal(P, S) |
Vedere Problema di larghezza dei tipi. |
boolean |
boolean |
|
date |
date |
|
timestamp |
timestamp_ntz |
Il timestamp tipo di dati Iceberg non contiene informazioni sul fuso orario. Il timestamp_ntz tipo Delta Lake non è completamente supportato nei carichi di lavoro di Infrastruttura. È consigliabile usare timestamp con fusi orari inclusi. |
timestamptz |
timestamp |
In Snowflake, per usare questo tipo, specificare timestamp_ltz come tipo di colonna durante la creazione della tabella Iceberg.
Altre informazioni sui tipi di dati Iceberg supportati in Snowflake sono disponibili qui. |
string |
string |
|
binary |
binary |
Problema di larghezza del tipo
Se si usa Snowflake per scrivere la tabella Iceberg e la tabella contiene tipi di INT64colonna , doubleo Decimal con precisione = 10, la tabella Delta Lake virtuale risultante >potrebbe non essere utilizzabile da tutti i motori fabric. È possibile che vengano visualizzati errori come:
Parquet column cannot be converted in file ... Column: [ColumnA], Expected: decimal(18,4), Found: INT32.
Microsoft sta lavorando a una correzione per questo problema.
Soluzione alternativa: se si usa l'interfaccia utente di anteprima della tabella Lakehouse e si verifica questo problema, è possibile risolvere questo errore passando alla visualizzazione Endpoint SQL (angolo superiore destro, selezionare vista Lakehouse, passare all'endpoint SQL) e visualizzare in anteprima la tabella da questa posizione. Se quindi si torna alla visualizzazione Lakehouse, l'anteprima della tabella dovrebbe essere visualizzata correttamente.
Se si esegue un notebook o un processo Spark e si verifica questo problema, è possibile risolvere questo errore impostando la spark.sql.parquet.enableVectorizedReader configurazione di Spark su false. Ecco un esempio di comando PySpark da eseguire in un notebook Spark:
spark.conf.set("spark.sql.parquet.enableVectorizedReader","false")
L'archiviazione dei metadati della tabella Iceberg non è portabile
I file di metadati di una tabella Iceberg si riferiscono l'uno all'altro usando riferimenti di percorso assoluti. Se si copia o si sposta il contenuto della cartella di una tabella Iceberg in un'altra posizione senza riscrivere i file di metadati iceberg, la tabella diventa illeggibile dai lettori di Iceberg, inclusa questa funzionalità di OneLake.
Soluzione alternativa:
Se è necessario spostare la tabella Iceberg in un'altra posizione per usare questa funzionalità, usare lo strumento che originariamente ha scritto la tabella Iceberg per scrivere una nuova tabella Iceberg nella posizione desiderata.
Le tabelle iceberg devono essere più profonde del livello radice
La cartella della tabella Iceberg nell'archiviazione deve trovarsi in una directory più profonda del livello di bucket o contenitore. Le tabelle iceberg archiviate direttamente nella directory radice di un bucket o di un contenitore potrebbero non essere virtualizzate nel formato Delta Lake.
Microsoft sta lavorando a un miglioramento per rimuovere questo requisito.
Soluzione alternativa:
Assicurarsi che tutte le tabelle Iceberg vengano archiviate in una directory più profonda rispetto alla directory radice di un bucket o di un contenitore.
Le cartelle delle tabelle iceberg devono contenere un solo set di file di metadati
Se si rilascia e si ricrea una tabella Iceberg in Snowflake, i file di metadati non vengono puliti. Questo comportamento è supportato dalla UNDROP funzionalità in Snowflake. Tuttavia, poiché il collegamento punta direttamente a una cartella e tale cartella include ora più set di file di metadati, non è possibile convertire la tabella finché non si rimuovono i file di metadati della tabella precedente.
Attualmente, la conversione viene tentata in questo scenario, che può comportare la visualizzazione di informazioni precedenti sul sommario e sullo schema nella tabella Delta Lake virtualizzata.
Si sta lavorando a una correzione in cui la conversione ha esito negativo se nella cartella dei metadati della tabella Iceberg si trovano più di un set di file di metadati.
Soluzione alternativa:
Per garantire che la tabella convertita rifletta la versione corretta della tabella:
Modifiche ai metadati non immediatamente riflesse
Se si apportano modifiche ai metadati alla tabella Iceberg, ad esempio l'aggiunta di una colonna, l'eliminazione di una colonna, la ridenominazione di una colonna o la modifica di un tipo di colonna, la tabella potrebbe non essere riconvertita fino a quando non viene apportata una modifica dei dati, ad esempio l'aggiunta di una riga di dati.
Si sta lavorando a una correzione che seleziona il file di metadati più recente corretto che include la modifica dei metadati più recente.
Soluzione alternativa:
Dopo aver apportato la modifica dello schema alla tabella Iceberg, aggiungere una riga di dati o apportare altre modifiche ai dati. Dopo questa modifica, dovrebbe essere possibile aggiornare e visualizzare la visualizzazione più recente della tabella in Fabric.
Aree di lavoro abilitate per lo schema non ancora supportate
Se si crea un collegamento Iceberg in una lakehouse abilitata per lo schema, la conversione non si verifica per tale collegamento.
Stiamo lavorando a un miglioramento per rimuovere questa limitazione.
Soluzione alternativa:
Usare una lakehouse non abilitata per lo schema con questa funzionalità. È possibile configurare questa impostazione durante la creazione di lakehouse.
Limitazione della disponibilità dell'area
La funzionalità non è ancora disponibile nelle aree seguenti:
Soluzione alternativa:
Le aree di lavoro collegate alle capacità di Infrastruttura in altre aree possono usare questa funzionalità. Vedere l'elenco completo delle aree in cui è disponibile Microsoft Fabric.
Collegamenti privati non supportati
Questa funzionalità non è attualmente supportata per tenant o aree di lavoro con collegamenti privati abilitati.
Stiamo lavorando a un miglioramento per rimuovere questa limitazione.
Limitazione delle dimensioni della tabella
È presente una limitazione temporanea delle dimensioni della tabella Iceberg supportata da questa funzionalità. Il numero massimo supportato di file di dati Parquet è di circa 5.000 file di dati o circa 1 miliardo di righe, a qualunque limite venga raggiunto per primo.
Stiamo lavorando a un miglioramento per rimuovere questa limitazione.
I tasti di scelta rapida oneLake devono essere della stessa area
Esiste una limitazione temporanea sull'uso di questa funzionalità con collegamenti che puntano alle posizioni di OneLake: la posizione di destinazione del collegamento deve trovarsi nella stessa area del collegamento stesso.
Microsoft sta lavorando a un miglioramento per rimuovere questo requisito.
Soluzione alternativa:
Se si dispone di un collegamento OneLake a un tavolo Iceberg in un'altra lakehouse, assicurarsi che l'altra lakehouse sia associata a una capacità nella stessa area.
opzione tenant che consente l'accesso esterno
È presente una limitazione temporanea che richiede l'impostazione del tenant "Gli utenti possono accedere ai dati archiviati in OneLake con app esterne a Fabric".
Se questa impostazione del tenant è disabilitata, la virtualizzazione delle tabelle Iceberg in formato Delta Lake non avrà esito positivo.
Soluzione alternativa:
Chiedere all'amministratore tenant di Fabric di abilitare l'impostazione "Gli utenti possono accedere ai dati archiviati in OneLake con app esterne a Fabric" impostazione del tenant, se possibile.
le tabelle Iceberg devono essere di copia su scrittura (non di tipo merge-on-read)
Attualmente, le tabelle Iceberg devono essere copy-on-write . Ciò significa che non possono contenere file di eliminazione o essere merge-on-read.
Snowflake attualmente produce tabelle copy-on-write Iceberg, ma altri scrittori Iceberg possono adottare un approccio diverso.
Microsoft sta lavorando al supporto per le tabelle Iceberg di tipo 'merge-on-read'.
Eventi
31 mar, 23 - 2 apr, 23
Il più grande evento di apprendimento di Fabric, Power BI e SQL. 31 marzo - 2 aprile. Usare il codice FABINSIDER per salvare $400.
Iscriviti oggi stessoFormazione
Modulo
Usare tabelle Delta Lake in Microsoft Fabric - Training
Le tabelle in un lakehouse di Microsoft Fabric si basano sulla tecnologia di Delta Lake comunemente usato in Apache Spark. Usando le funzionalità avanzate delle tabelle delta, è possibile creare soluzioni di analisi avanzate.
Documentazione
Creare un collegamento di Azure Data Lake Storage Gen2 - Microsoft Fabric
Informazioni su come creare un collegamento OneLake per Azure Data Lake Storage Gen2 all'interno di un lakehouse di Microsoft Fabric.
Unificare le origini dati con i collegamenti a OneLake - Microsoft Fabric
I collegamenti a OneLake consentono di connettersi ai dati esistenti senza doverli copiare direttamente. Informazioni su come usarli.
Creare collegamenti ai dati locali - Microsoft Fabric
Informazioni su come installare e usare un gateway dati locale di Fabric per creare collegamenti OneLake a origini dati locali o con restrizioni di rete.