Ottenere dati da Hub eventi di Azure
Questo articolo illustra come ottenere dati da Hub eventi nel database KQL in Microsoft Fabric. Hub eventi di Azure è una piattaforma di streaming di Big Data e un servizio di inserimento di eventi in grado di elaborare e indirizzare milioni di eventi al secondo.
Per trasmettere i dati da Hub eventi ad Analisi in tempo reale, è possibile eseguire due passaggi principali. Il primo passaggio viene eseguito nella portale di Azure, in cui si definiscono i criteri di accesso condiviso nell'istanza dell'hub eventi e si acquisiscono i dettagli necessari per connettersi successivamente tramite questo criterio.
Il secondo passaggio viene eseguito in Analisi in tempo reale in Fabric, in cui si connette un database KQL all'hub eventi e si configura lo schema per i dati in ingresso. Questo passaggio crea due connessioni. La prima connessione, denominata "connessione cloud", connette Microsoft Fabric all'istanza dell'hub eventi. La seconda connessione connette la "connessione cloud" al database KQL. Dopo aver configurato i dati e lo schema dell'evento, i dati trasmessi sono disponibili per l'esecuzione di query usando un set di query KQL.
Prerequisiti
- Una sottoscrizione di Azure. Creare un account Azure gratuito
- Un hub eventi
- Un'area di lavoro con capacità abilitata per Microsoft Fabric
- Un database KQL con autorizzazioni di modifica
Avviso
L'hub eventi non può essere protetto da un firewall.
Impostare criteri di accesso condiviso nell'hub eventi
Prima di poter creare una connessione ai dati di Hub eventi, è necessario impostare un criterio di accesso condiviso nell'hub eventi e raccogliere alcune informazioni da usare in un secondo momento per configurare la connessione. Per altre informazioni sull'autorizzazione dell'accesso alle risorse di Hub eventi, vedere Firme di accesso condiviso.
Nella portale di Azure passare all'istanza di Hub eventi che si vuole connettere.
In Impostazioni selezionare Criteri di accesso condiviso
Selezionare +Aggiungi per aggiungere un nuovo criterio di firma di accesso condiviso o selezionare un criterio esistente con Autorizzazioni di gestione .
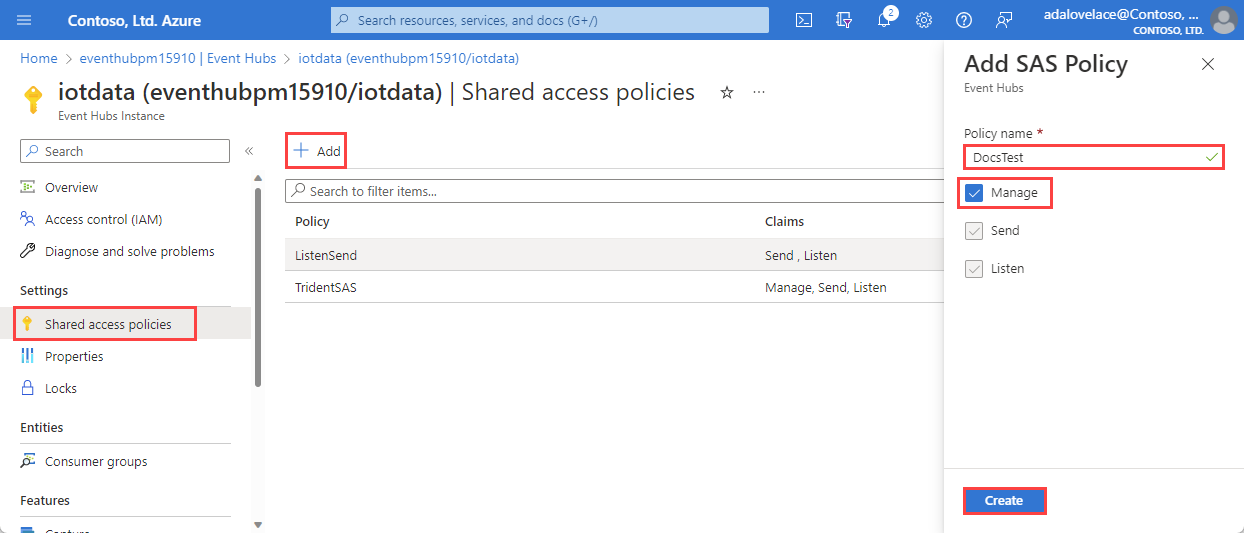
Immettere un nome per i criteri.
Selezionare Gestisci e quindi Crea.

Raccogliere informazioni per la connessione cloud
Nel riquadro dei criteri di firma di accesso condiviso prendere nota dei quattro campi seguenti. È possibile copiare questi campi e incollarli in un punto qualsiasi, ad esempio un Blocco note, da usare in un passaggio successivo.

| Informazioni di riferimento sul campo | Campo | Description | Esempio |
|---|---|---|---|
| a | Istanza di Hub eventi | Nome dell'istanza dell'hub eventi. | iotdata |
| b | Criteri di firma di accesso condiviso | Nome del criterio di firma di accesso condiviso creato nel passaggio precedente | DocsTest |
| c | Chiave primaria | Chiave associata ai criteri di firma di accesso condiviso | In questo esempio inizia con PGGIISb009... |
| d | chiave primaria stringa di Connessione ion | In questo campo si vuole copiare solo lo spazio dei nomi dell'hub eventi, disponibile come parte del stringa di connessione. | eventhubpm15910.servicebus.windows.net |
Origine
Nella barra multifunzione inferiore del database KQL selezionare Recupera dati.
Nella finestra Recupera dati è selezionata la scheda Origine .
Selezionare l'origine dati dall'elenco disponibile. In questo esempio si inseriscono dati da Hub eventi.
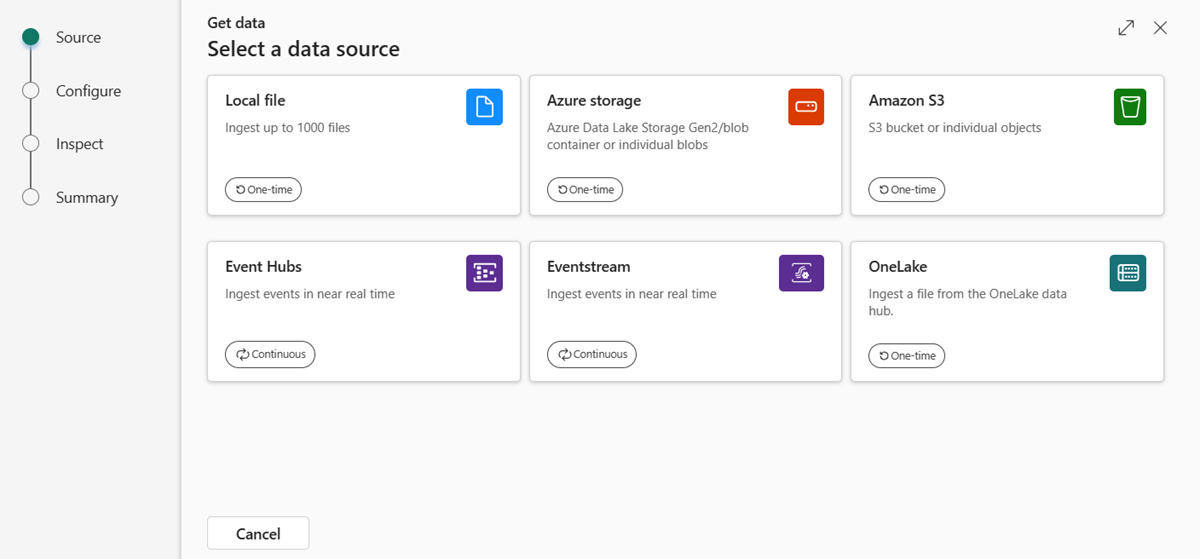

Configurazione
Selezionare una tabella di destinazione. Per inserire dati in una nuova tabella, selezionare + Nuova tabella e immettere un nome di tabella.
Nota
I nomi delle tabelle possono avere un massimo di 1024 caratteri, inclusi spazi, alfanumerici, trattini e caratteri di sottolineatura. I caratteri speciali non sono supportati.
Selezionare Crea nuova connessione oppure selezionare Connessione esistente e passare al passaggio successivo.
Create new connection
Compilare le impostazioni di Connessione ion in base alla tabella seguente:
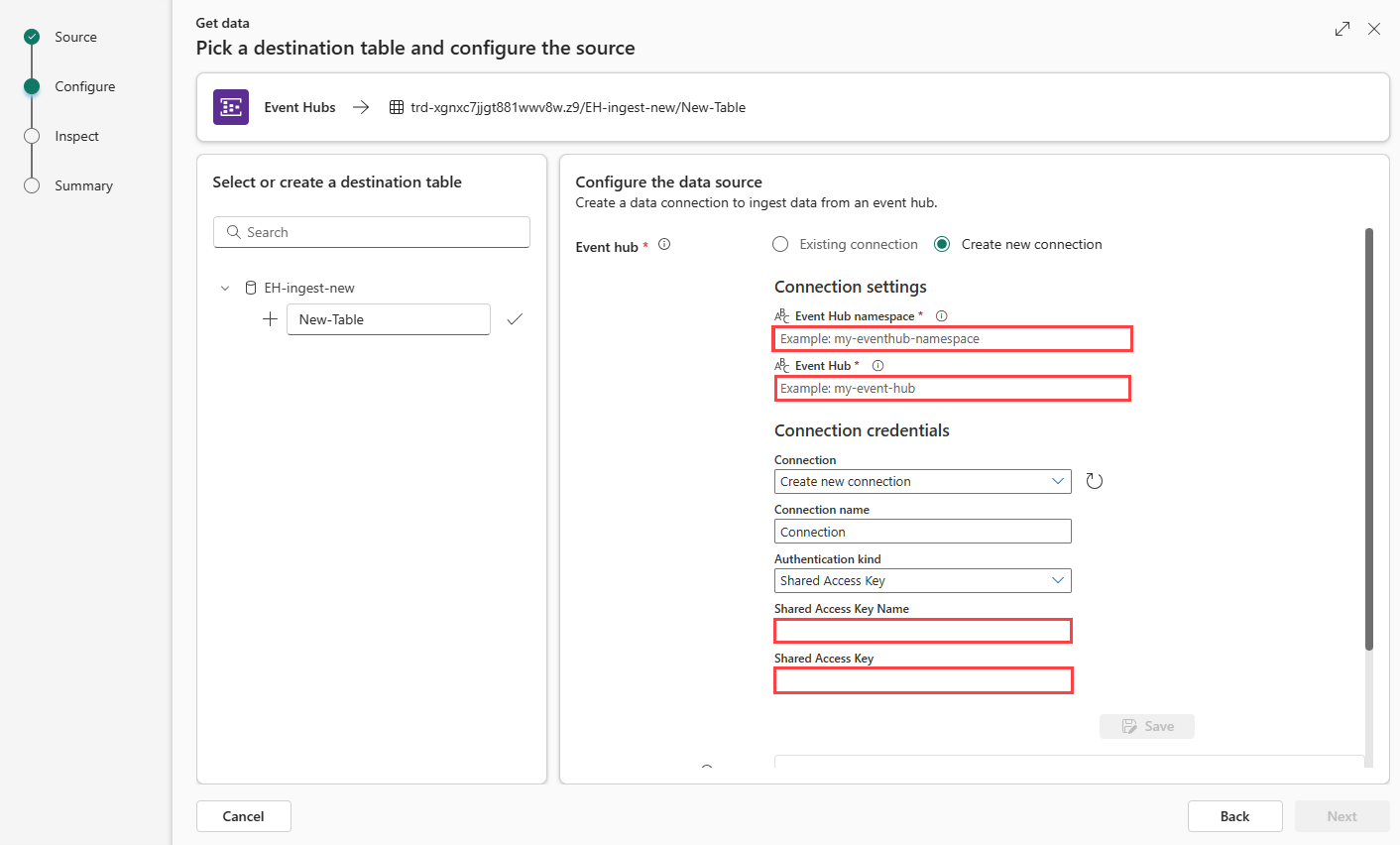
Impostazione Descrizione Valore di esempio Spazio dei nomi dell'hub eventi Campo d della tabella precedente. eventhubpm15910.servicebus.windows.net Hub eventi Campo dell'oggetto della tabella precedente. Nome dell'istanza dell'hub eventi. iotdata Connessione Per usare una connessione cloud esistente tra Fabric e Hub eventi, selezionare il nome di questa connessione. In caso contrario, selezionare Crea nuova connessione. Creare una nuova connessione Nome connessione Nome della nuova connessione cloud. Questo nome viene generato automaticamente, ma può essere sovrascritto. Deve essere univoco all'interno del tenant di Fabric. Connessione Tipo di autenticazione Ripopolato automaticamente. Attualmente è supportata solo la chiave di accesso condiviso. Chiave di accesso condiviso Nome chiave di accesso condiviso Campo b della tabella precedente. Nome assegnato ai criteri di accesso condiviso. DocsTest Chiave di accesso condiviso Campo c della tabella precedente. Chiave primaria dei criteri di firma di accesso condiviso. Seleziona Salva. Viene creata una nuova connessione dati cloud tra Fabric e Hub eventi.

Connessione la connessione cloud al database KQL
Indipendentemente dal fatto che sia stata creata una nuova connessione cloud o che si usi una connessione cloud esistente, è necessario definire il gruppo di consumer. Facoltativamente, è possibile impostare parametri che definiscono ulteriormente gli aspetti della connessione tra il database KQL e la connessione cloud.
Compilare i campi seguenti in base alla tabella:
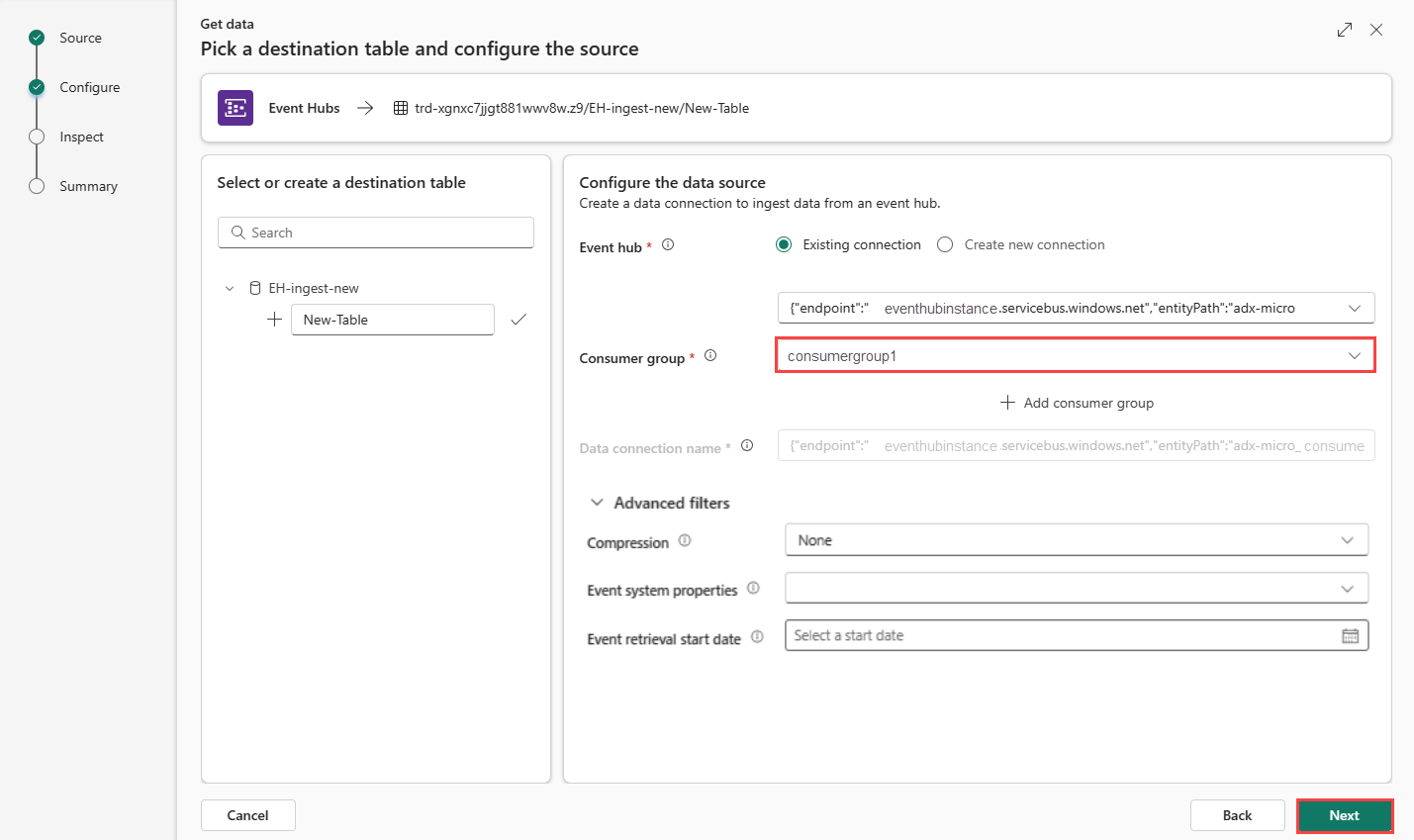
Impostazione Descrizione Valore di esempio Gruppo di consumer Gruppo di consumer pertinente definito nell'hub eventi. Per altre informazioni, vedere Gruppi di consumer. Dopo aver aggiunto un nuovo gruppo di consumer, sarà quindi necessario selezionare questo gruppo dall'elenco a discesa. NewConsumer Altri parametri Compressione Compressione dei dati degli eventi, come proveniente dall'hub eventi. Le opzioni sono Nessuna (impostazione predefinita) o Compressione Gzip. Nessuna Proprietà del sistema per gli eventi Per altre informazioni, vedere Proprietà del sistema dell'hub eventi. Se sono presenti più record per ogni messaggio di evento, le proprietà di sistema vengono aggiunte alla prima. Vedere le proprietà del sistema eventi. Data di inizio recupero eventi La connessione dati recupera gli eventi dell'hub eventi esistenti creati dalla data di inizio del recupero eventi. Può recuperare solo gli eventi conservati dall'hub eventi, in base al periodo di conservazione. Il fuso orario è UTC. Se non viene specificata alcuna ora, l'ora predefinita è l'ora in cui viene creata la connessione dati. Selezionare Avanti per continuare con la scheda Ispeziona.
Proprietà del sistema per gli eventi
Le proprietà di sistema archiviano le proprietà impostate dal servizio Hub eventi al momento dell'accodamento dell'evento. La connessione dati all'hub eventi può incorporare un set selezionato di proprietà di sistema nei dati inseriti in una tabella in base a un determinato mapping.
| Proprietà | Tipo di dati | Descrizione |
|---|---|---|
| x-opt-enqueued-time | data/ora | Ora UTC in cui l'evento è stato accodato. |
| x-opt-sequence-number | long | Numero di sequenza logica dell'evento all'interno del flusso di partizione dell'hub eventi. |
| x-opt-offset | stringa | Offset dell'evento dal flusso di partizione dell'hub eventi. L'identificatore di offset è univoco all'interno di una partizione del flusso dell'hub eventi. |
| x-opt-publisher | stringa | Nome del server di pubblicazione, se il messaggio è stato inviato a un endpoint del server di pubblicazione. |
| x-opt-partition-key | stringa | Chiave di partizione della partizione corrispondente che ha archiviato l'evento. |
Controllare
Per completare il processo di inserimento, selezionare Fine.

Facoltativamente:
Selezionare Visualizzatore comandi per visualizzare e copiare i comandi automatici generati dagli input.
Modificare il formato dei dati dedotto automaticamente selezionando il formato desiderato dall'elenco a discesa. I dati vengono letti dall'hub eventi sotto forma di oggetti EventData . I formati supportati sono CSV, JSON, PSV, SCsv, SOHsv TSV, TXT e TSVE.
Esplorare Le opzioni avanzate in base al tipo di dati.
Se i dati visualizzati nella finestra di anteprima non sono completi, potrebbero essere necessari altri dati per creare una tabella con tutti i campi dati necessari. Usare i comandi seguenti per recuperare nuovi dati dall'hub eventi:
- Ignora e recupera nuovi dati: elimina i dati presentati e cerca nuovi eventi.
- Recuperare altri dati: cerca altri eventi oltre agli eventi già trovati.
Modifica colonne
Nota
- Per i formati tabulari (CSV, TSV, PSV), non è possibile eseguire il mapping di una colonna due volte. Per eseguire il mapping a una colonna esistente, eliminare prima quella nuova.
- Non è possibile modificare un tipo di colonna esistente. Se si tenta di eseguire il mapping a una colonna con un formato diverso, è possibile che si verifichino colonne vuote.
Le modifiche che è possibile apportare in una tabella dipendono dai parametri seguenti:
- Il tipo di tabella è nuovo o esistente
- Il tipo di mapping è nuovo o esistente
| Tipo di tabella | Tipo di mapping | Modifiche disponibili |
|---|---|---|
| Nuova tabella | Nuovo mapping | Rinominare la colonna, modificare il tipo di dati, modificare l'origine dati, la trasformazione mapping, aggiungere una colonna, eliminare una colonna |
| Tabella esistente | Nuovo mapping | Aggiungi colonna (in cui è possibile modificare il tipo di dati, rinominare e aggiornare) |
| Tabella esistente | Mapping esistente | Nessuno |

Trasformazioni del mapping
Alcuni mapping del formato dati (Parquet, JSON e Avro) supportano semplici trasformazioni in fase di inserimento. Per applicare trasformazioni di mapping, creare o aggiornare una colonna nella finestra Modifica colonne .
Le trasformazioni di mapping possono essere eseguite su una colonna di tipo string o datetime, con l'origine con tipo di dati int o long. Le trasformazioni del mapping supportate sono:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Mapping dello schema per i file Avro di Acquisizione di Hub eventi
Un modo per usare i dati di Hub eventi consiste nell'acquisire eventi tramite Hub eventi di Azure in Archiviazione BLOB di Azure o azure Data Lake Archiviazione. È quindi possibile inserire i file di acquisizione mentre vengono scritti usando un Connessione dati di Griglia di eventi.
Lo schema dei file di acquisizione è diverso dallo schema dell'evento originale inviato a Hub eventi. È consigliabile progettare lo schema della tabella di destinazione tenendo presente questa differenza. In particolare, il payload dell'evento viene rappresentato nel file di acquisizione come matrice di byte e questa matrice non viene decodificata automaticamente dalla connessione dati di Griglia di eventi di Azure Esplora dati. Per informazioni più specifiche sullo schema di file per i dati di acquisizione avro di Hub eventi, vedere Esplorazione dei file Avro acquisiti in Hub eventi di Azure.
Per decodificare correttamente il payload dell'evento:
- Eseguire il mapping del
Bodycampo dell'evento acquisito a una colonna di tipodynamicnella tabella di destinazione. - Applicare un criterio di aggiornamento che converte la matrice di byte in una stringa leggibile usando la funzione unicode_codepoints_to_string().
Opzioni avanzate basate sul tipo di dati
Tabulare (CSV, TSV, PSV):
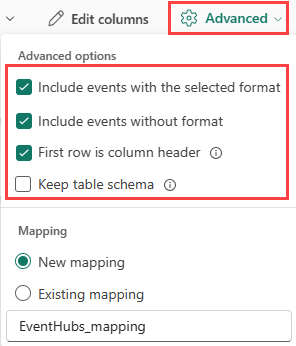
Se si inseriscono formati tabulari in una tabella esistente, è possibile selezionare Schema tabella Mantieni avanzato>. I dati tabulari non includono necessariamente i nomi di colonna usati per eseguire il mapping dei dati di origine alle colonne esistenti. Quando questa opzione è selezionata, il mapping viene eseguito in base all'ordine e lo schema della tabella rimane invariato. Se questa opzione è deselezionata, vengono create nuove colonne per i dati in ingresso, indipendentemente dalla struttura dei dati.
Per usare la prima riga come nomi di colonna, selezionare Avanzate>Prima riga è intestazione di colonna.
JSON:
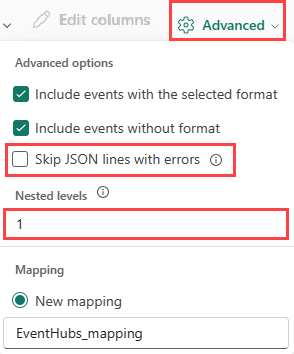
Per determinare la divisione delle colonne dei dati JSON, selezionare Livelli annidati avanzati>, da 1 a 100.
Se si seleziona Advanced Skip JSON lines with errors (Ignora righe JSON avanzate>con errori), i dati vengono inseriti in formato JSON. Se si lascia deselezionata questa casella di controllo, i dati vengono inseriti in formato multijson.
Riepilogo
Nella finestra Preparazione dati tutti e tre i passaggi vengono contrassegnati con segni di spunta verdi al termine dell'inserimento dati. È possibile selezionare una scheda per eseguire query, eliminare i dati inseriti o visualizzare un dashboard del riepilogo dell'inserimento.

Contenuto correlato
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per