Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() SQL Server 2016 (13.x) e versioni
SQL Server 2016 (13.x) e versioni ![]() successive Azure SQL Database
successive Azure SQL Database![]() AzureSQL Managed Instance
AzureSQL Managed Instance![]() SQL database in Microsoft Fabric
SQL database in Microsoft Fabric
È possibile ottimizzare le query sui documenti JSON usando indici standard.
Note
In SQL Server 2025 (17.x) è possibile usare la funzionalità CREATE JSON INDEX (Transact-SQL).
Gli indici funzionano allo stesso modo nei dati JSON in varchar/nvarchar o nel tipo di dati nativo json.
Gli indici del database migliorano le prestazioni delle operazioni di filtro e ordinamento. Senza indici, SQL Server deve eseguire un'analisi completa della tabella ogni volta che viene eseguita una query sui dati.
Note
Tipo di dati JSON:
- è disponibile a livello generale per il database SQL di Azure e l'istanza gestita di SQL di Azure con SQL Server 2025 o Always-up-to-datecriteri di aggiornamento.
- è disponibile in anteprima per SQL Server 2025 (17.x) e il database SQL in Fabric.
Indicizzazione delle proprietà JSON mediante colonne calcolate
Quando si archiviano i dati JSON in SQL Server, di solito l'obiettivo è filtrare o ordinare i risultati delle query in base a una o più proprietà dei documenti JSON.
Example
In questo esempio si suppone che la tabella AdventureWorks.SalesOrderHeader includa una colonna Info che contiene varie informazioni in formato JSON sugli ordini di vendita. Contiene ad esempio dati non strutturati relativi al cliente, al venditore, agli indirizzi di spedizione e di fatturazione e così via. Si vogliono usare i valori della colonna Info per filtrare gli ordini di vendita per un cliente.
Per impostazione predefinita, la colonna Info usata non esiste, può essere creata nel AdventureWorks database con il codice seguente. Gli esempi seguenti non si applicano alla AdventureWorksLT serie di database di esempio.
IF NOT EXISTS (SELECT *
FROM sys.columns
WHERE object_id = OBJECT_ID('[Sales].[SalesOrderHeader]')
AND name = 'Info')
ALTER TABLE [Sales].[SalesOrderHeader]
ADD [Info] NVARCHAR (MAX) NULL;
GO
UPDATE h
SET [Info] =
(
SELECT [Customer.Name] = concat(p.FirstName, N' ', p.LastName),
[Customer.ID] = p.BusinessEntityID,
[Customer.Type] = p.[PersonType],
[Order.ID] = soh.SalesOrderID,
[Order.Number] = soh.SalesOrderNumber,
[Order.CreationData] = soh.OrderDate,
[Order.TotalDue] = soh.TotalDue
FROM [Sales].SalesOrderHeader AS soh
INNER JOIN [Sales].[Customer] AS c
ON c.CustomerID = soh.CustomerID
INNER JOIN [Person].[Person] AS p
ON p.BusinessEntityID = c.CustomerID
WHERE soh.SalesOrderID = h.SalesOrderID
FOR JSON PATH, WITHOUT_ARRAY_WRAPPER
)
FROM [Sales].SalesOrderHeader AS h;
Query da ottimizzare
Di seguito è riportato un esempio del tipo di query da ottimizzare usando un indice.
SELECT SalesOrderNumber,
OrderDate,
JSON_VALUE(Info, '$.Customer.Name') AS CustomerName
FROM Sales.SalesOrderHeader
WHERE JSON_VALUE(Info, '$.Customer.Name') = N'Aaron Campbell';
Indice di esempio
Per velocizzare i filtri o le clausole ORDER BY su una proprietà in un documento JSON, è possibile usare gli stessi indici già usati per altre colonne. Tuttavia, non è possibile fare direttamente riferimento alle proprietà nei documenti JSON.
- Per prima cosa, creare una "colonna virtuale" che restituisca i valori che verranno usati per il filtro.
- Successivamente, creare un indice su quella colonna virtuale.
Nell'esempio seguente viene creata una colonna calcolata che può essere usata per l'indicizzazione. Successivamente viene creato un indice per la nuova colonna calcolata. In questo esempio viene creata una colonna che espone il nome del cliente archiviato nel percorso $.Customer.Name nei dati JSON.
ALTER TABLE Sales.SalesOrderHeader
ADD vCustomerName AS JSON_VALUE(Info, '$.Customer.Name');
CREATE INDEX idx_soh_json_CustomerName
ON Sales.SalesOrderHeader(vCustomerName);
Questa istruzione restituisce l'avviso seguente:
Warning! The maximum key length for a nonclustered index is 1700 bytes.
The index 'vCustomerName' has maximum length of 8000 bytes.
For some combination of large values, the insert/update operation will fail.
La funzione JSON_VALUE potrebbe restituire valori di testo fino a 8.000 byte, ad esempio come il tipo nvarchar(4000). Tuttavia, non è possibile indicizzare i valori più lunghi di 1700 byte. Se si tenta di immettere il valore nella colonna calcolata indicizzata con lunghezza superiore a 1700 byte, l'operazione DML (Data Manipulation Language) ha esito negativo.
Per prestazioni migliori, provare a convertire il valore che esponi utilizzando la colonna calcolata nel più piccolo tipo di dati applicabile. Usare tipi int e datetime2 anziché tipi stringa.
Altre informazioni sulla colonna calcolata
Una colonna calcolata non è persistente. Una colonna calcolata viene calcolata solo quando l'indice deve essere reindicizzato. Non occupa spazio aggiuntivo nella tabella.
È importante creare la colonna calcolata con la stessa espressione che si prevede di usare nelle query, in questo esempio l'espressione è JSON_VALUE(Info, '$.Customer.Name').
Non è necessario riscrivere le query. Se si usano espressioni con la funzione JSON_VALUE come illustrato nella query di esempio precedente, SQL Server rileva la presenza di una colonna calcolata equivalente con la stessa espressione e, se possibile, applica un indice.
Piano di esecuzione per questo esempio
Di seguito viene riportato il piano di esecuzione per la query di questo esempio.
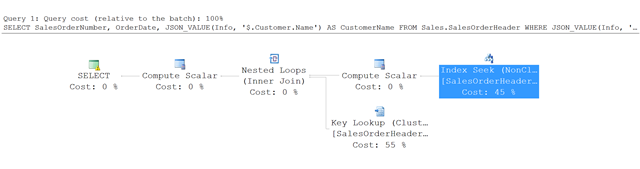
Invece di una scansione di tabella completa, SQL Server usa una ricerca nell'indice non cluster e individua le righe che soddisfano le condizioni specificate. Usa quindi una ricerca chiave nella tabella SalesOrderHeader per recuperare le altre colonne a cui si fa riferimento nella query, in questo esempio, SalesOrderNumber e OrderDate.
Ottimizzare ulteriormente l'indice includendo colonne
Se si aggiungono colonne necessarie nell'indice, è possibile evitare questa ricerca aggiuntiva nella tabella. È possibile aggiungere tali colonne come colonne incluse standard, come illustrato nell'esempio seguente che estende l'esempio CREATE INDEX precedente.
CREATE INDEX idx_soh_json_CustomerName
ON Sales.SalesOrderHeader(vCustomerName)
INCLUDE(SalesOrderNumber, OrderDate);
In questo caso, SQL Server non deve leggere altri dati dalla SalesOrderHeader tabella perché tutti gli elementi necessari sono inclusi nell'indice JSON non cluster. Questo tipo di indice è un buon metodo per combinare i dati JSON e di colonna nelle query e per creare indici ottimali per il carico di lavoro.
Gli indici JSON tengono conto delle regole di confronto
Una caratteristica importante degli indici rispetto ai dati JSON è che gli indici sono in grado di riconoscere le regole di confronto. Il risultato della funzione JSON_VALUE, che si usa quando si crea la colonna calcolata, è un valore di testo che eredita le regole di confronto dall'espressione di input. Di conseguenza, i valori dell'indice vengono ordinati usando le regole di confronto definite nelle colonne di origine.
Per dimostrare che gli indici sono sensibili al confronto, nell'esempio seguente viene creata una semplice tabella di raccolta con una chiave primaria e contenuto JSON.
CREATE TABLE JsonCollection
(
id INT IDENTITY CONSTRAINT PK_JSON_ID PRIMARY KEY,
[json] NVARCHAR (MAX) COLLATE SERBIAN_CYRILLIC_100_CI_AI
CONSTRAINT [Content should be formatted as JSON] CHECK (ISJSON(json) > 0)
);
Il comando precedente consente di specificare le regole di confronto per il serbo (cirillico) per la colonna json. Nell'esempio seguente la tabella viene popolata e viene creato un indice nella proprietà del nome.
INSERT INTO JsonCollection
VALUES
(N'{"name":"Иво","surname":"Андрић"}'),
(N'{"name":"Андрија","surname":"Герић"}'),
(N'{"name":"Владе","surname":"Дивац"}'),
(N'{"name":"Новак","surname":"Ђоковић"}'),
(N'{"name":"Предраг","surname":"Стојаковић"}'),
(N'{"name":"Михајло","surname":"Пупин"}'),
(N'{"name":"Борислав","surname":"Станковић"}'),
(N'{"name":"Владимир","surname":"Грбић"}'),
(N'{"name":"Жарко","surname":"Паспаљ"}'),
(N'{"name":"Дејан","surname":"Бодирога"}'),
(N'{"name":"Ђорђе","surname":"Вајферт"}'),
(N'{"name":"Горан","surname":"Бреговић"}'),
(N'{"name":"Милутин","surname":"Миланковић"}'),
(N'{"name":"Никола","surname":"Тесла"}');
GO
ALTER TABLE JsonCollection
ADD vName AS JSON_VALUE(json, '$.name');
CREATE INDEX idx_name
ON JsonCollection(vName);
I comandi precedenti creano un indice standard per la colonna calcolata vName, che rappresenta il valore della proprietà $.name JSON. Nella tabella codici per il serbo (alfabeto cirillico), l'ordine delle lettere è А, Б, В, Г, Д, Ђ, Е, ecc. L'ordine degli elementi nell'indice è conforme alle regole per il serbo (alfabeto cirillico) perché il risultato della funzione JSON_VALUE eredita le regole di confronto dalla colonna di origine. Nell'esempio seguente viene eseguita una query su questa raccolta e i risultati vengono ordinati in base al nome.
SELECT JSON_VALUE(json, '$.name'),
*
FROM JsonCollection
ORDER BY JSON_VALUE(json, '$.name');
Se si esamina il piano di esecuzione effettivo, si noterà che vengono usati valori ordinati dall'indice non clusterizzato.

Anche se la query include una clausola ORDER BY, il piano di esecuzione non usa un operatore di ordinamento. L'indice JSON è già ordinato secondo le regole dell'alfabeto cirillico serbo. SQL Server può quindi usare l'indice non cluster in cui risultati sono già ordinati.
Se tuttavia si modificano le regole di confronto dell'espressione ORDER BY, ad esempio inserendo COLLATE French_100_CI_AS_SC dopo la funzione JSON_VALUE, si ottiene un piano di esecuzione della query diverso.

Poiché l'ordine dei valori nell'indice non è conforme alle regole di confronto francese, SQL Server non può usare l'indice per ordinare i risultati. Pertanto, aggiunge un operatore di ordinamento che ordina i risultati usando le regole di confronto francesi.
Video Microsoft
Per un'introduzione visiva al supporto JSON predefinito, vedere il video seguente:
- JSON as a bridge between NoSQL and relational worlds (JSON come ponte tra NoSQL e gli ambienti relazionali)
Contenuti correlati
- Ottimizzare l'elaborazione JSON con OLTP in memoria
- Dati JSON in SQL Server
- Tipo di dati JSON