Azure SQL Database でデータベースのファイル領域を管理する
適用対象:![]() Azure SQL Database
Azure SQL Database
この記事では、Azure SQL Database のデータベースのさまざまな種類の記憶域スペースと、割り当てられたファイル領域を明示的に管理する必要がある場合に実行できる手順について説明します。
概要
Azure SQL Database では、データベースの基礎となるデータ ファイルの割り当てが使用データ ページ数よりも大きくなるようなワークロード パターンがあります。 この状況は、使用領域が増えた後にデータが削除された場合に発生する可能性があります。 これは、データの削除時に割り当てられていたファイル領域が自動的に再利用されないためです。
次のシナリオでは、ファイル領域の使用率の監視とデータ ファイルの圧縮が必要になる場合があります。
- データベースに割り当てられたファイル領域がプールのサイズ上限に達した場合に、エラスティック プール内のデータの増大を許可する。
- 単一データベースまたはエラスティック プールの最大サイズの縮小を許可する。
- 単一データベースまたはエラスティック プールを、よりサイズ上限の低い異なるサービス レベルまたはパフォーマンス レベルに変更することを許可する。
Note
圧縮操作は、通常のメンテナンス操作と見なすことはできません。 通常の定期的なビジネス操作のために増加するデータ ファイルとログ ファイルには、圧縮操作は必要ではありません。
ファイル領域の使用状況の監視
次の API に表示されるほとんどのストレージ領域メトリックでは、使用されているデータ ページのサイズだけが測定されます。
- PowerShell get-metrics などの Azure Resource Manager ベースのメトリック API
ただし、次の API は、データベースとエラスティック プールに割り当てられている領域のサイズを測ることもできます。
- T-SQL: sys.resource_stats
- T-SQL: sys.elastic_pool_resource_stats
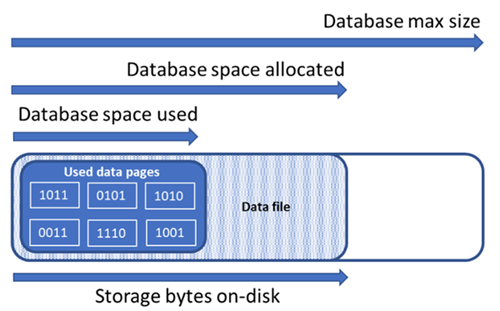
データベースの記憶域スペースの種類を理解する
データベースのファイル領域を管理するには、以下に示す記憶域スペースの量について理解することが重要です。
| データベースの量 | 定義 | 説明 |
|---|---|---|
| 使用済みのデータ領域 | データベース データを格納するために使用された領域の量。 | 一般的に、使用済みの領域は挿入 (削除) で増加 (減少) します。 操作に関連するデータの量とパターン、および断片化によっては、挿入または削除時に使用される領域が変わらない場合があります。 たとえば、各データ ページから 1 行を削除しても、使用される領域が減らない場合があります。 |
| 割り当て済みのデータ領域 | データベース データの格納に使用できるフォーマット済みファイル領域の量。 | 割り当て済みの領域の量は自動的に増えますが、削除後に自動的に減ることはありません。 このような動作で領域を再フォーマットする必要がないため、以降の挿入はより高速になります。 |
| 割り当て済みで未使用のデータ領域 | 割り当て済みのデータ領域と使用済みのデータ領域の差。 | この量は、データベースのデータ ファイルを縮小して再利用できる空き領域の上限を表します。 |
| データの最大サイズ | データベース データの格納に使用できる領域の最大量。 | データの最大サイズを超えて割り当て済みのデータ領域を拡大することはできません。 |
次の図は、データベースの異なる種類の記憶域スペース間の関係を示しています。
ファイル スペースの情報について単一データベースのクエリを実行する
sys.database_files に次のクエリを使用して、割り当て済みデータベース ファイル領域と未使用の割り当て済み領域を返します。 クエリ結果の単位は MB です。
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
エラスティック プールの記憶域スペースの種類を理解する
エラスティック プールのファイル領域を管理するには、以下に示す記憶域スペースの量について理解することが重要です。
| エラスティック プールの量 | 定義 | 説明 |
|---|---|---|
| 使用済みのデータ領域 | エラスティック プール内のすべてのデータベースで使用されるデータ領域の合計。 | |
| 割り当て済みのデータ領域 | エラスティック プール内のすべてのデータベースで割り当て済みのデータ領域の合計。 | |
| 割り当て済みで未使用のデータ領域 | エラスティック プール内のすべてのデータベースで割り当て済みのデータ領域と使用済みのデータ領域の差。 | この量は、データベースのデータ ファイルを縮小して再利用できる、エラスティック プールに割り当てられた領域の上限を表します。 |
| データの最大サイズ | エラスティック プールのすべてのデータベースに使用できるデータ領域の最大量。 | エラスティック プールに割り当てられた領域は、エラスティック プールの最大サイズを超えないようにする必要があります。 最大サイズを超えた場合は、割り当て済みで未使用の領域を、データベースのデータ ファイルを縮小して再利用できます。 |
Note
"エラスティック プールの記憶域が上限に達しました" というエラー メッセージは、データベース オブジェクトがエラスティック プールの記憶域の上限に達するほどの領域を割り当てられていることを示していますが、データ領域の割り当てに未使用の領域が存在する場合があります。 エラスティック プールの記憶域の上限を引き上げるか、短期的な解決策として、「未使用の割り当て済み領域を再利用する」に記載された例を使用してデータ領域を解放することを検討してください。 また、データベース ファイルの圧縮によってパフォーマンスが悪影響を受けるおそれがあることにも注意する必要があります。「圧縮後のインデックスのメンテナンス」を参照してください。
記憶域スペースの情報についてエラスティック プールのクエリを実行する
次のクエリを使用して、エラスティック プールの記憶域スペースの量を確認できます。
使用済みのエラスティック プールのデータ領域
使用済みのエラスティック プールのデータ領域の量を返すように次のクエリを変更します。 クエリ結果の単位は MB です。
-- Connect to master
-- Elastic pool data space used in MB
SELECT TOP 1 avg_storage_percent / 100.0 * elastic_pool_storage_limit_mb AS ElasticPoolDataSpaceUsedInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
割り当て済みのエラスティック プールのデータ領域と未使用の割り当て済み領域
次の例を変更して、エラスティック プール内の各データベースの割り当て済み領域と未使用の割り当て済み領域の一覧表を返すようにします。 この表では、未使用の割り当て済み領域があるデータベースが、最大サイズのデータベースから順に並んでいます。 クエリ結果の単位は MB です。
エラスティック プールに割り当てられた領域の合計を確認するために、プール内の各データベースに割り当てられた領域を確認するためのクエリ結果も追加することができます。 割り当て済みエラスティック プール領域は、エラスティック プールの最大サイズを超えないようにする必要があります。
重要
PowerShell Azure Resource Manager モジュールは Azure SQL Database で引き続きサポートされますが、今後の開発はすべて Az.Sql モジュールを対象に行われます。 AzureRM モジュールのバグ修正は、少なくとも 2020 年 12 月までは引き続き受け取ることができます。 Az モジュールと AzureRm モジュールのコマンドの引数は実質的に同じです。 その互換性の詳細については、「新しい Azure PowerShell Az モジュールの概要」を参照してください。
PowerShell スクリプトには SQL Server PowerShell モジュールが必要です。インストール方法については、PowerShell モジュールのダウンロードに関するページを参照してください。
$resourceGroupName = "<resourceGroupName>"
$serverName = "<serverName>"
$poolName = "<poolName>"
$userName = "<userName>"
$password = "<password>"
# get list of databases in elastic pool
$databasesInPool = Get-AzSqlElasticPoolDatabase -ResourceGroupName $resourceGroupName `
-ServerName $serverName -ElasticPoolName $poolName
$databaseStorageMetrics = @()
# for each database in the elastic pool, get space allocated in MB and space allocated unused in MB
foreach ($database in $databasesInPool) {
$sqlCommand = "SELECT DB_NAME() as DatabaseName, `
SUM(size/128.0) AS DatabaseDataSpaceAllocatedInMB, `
SUM(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0) AS DatabaseDataSpaceAllocatedUnusedInMB `
FROM sys.database_files `
GROUP BY type_desc `
HAVING type_desc = 'ROWS'"
$serverFqdn = "tcp:" + $serverName + ".database.windows.net,1433"
$databaseStorageMetrics = $databaseStorageMetrics +
(Invoke-Sqlcmd -ServerInstance $serverFqdn -Database $database.DatabaseName `
-Username $userName -Password $password -Query $sqlCommand)
}
# display databases in descending order of space allocated unused
Write-Output "`n" "ElasticPoolName: $poolName"
Write-Output $databaseStorageMetrics | Sort -Property DatabaseDataSpaceAllocatedUnusedInMB -Descending | Format-Table
以下のスクリーンショットは、スクリプトの出力例です。

エラスティック プール データの最大サイズ
最後に記録されたエラスティック プール データ最大サイズを返すように、次の T-SQL クエリを変更します。 クエリ結果の単位は MB です。
-- Connect to master
-- Elastic pools max size in MB
SELECT TOP 1 elastic_pool_storage_limit_mb AS ElasticPoolMaxSizeInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
未使用の割り当て済み領域を再利用する
重要
縮小コマンドは、実行中のデータベース パフォーマンスに影響を及ぼすため、可能であれば、使用率が低い期間中に実行してください。
データ ファイルを圧縮する
データベースのパフォーマンスに影響を与える可能性があるため、Azure SQL Database ではデータ ファイルは自動的には圧縮されません。 ただし、顧客は、任意の時点で、セルフサービスによってデータ ファイルを圧縮できます。 これは定期的にスケジュールされた操作ではなく、データ ファイルの使用領域の消費量が大幅に減少した場合の 1 回きりのイベントである必要があります。
ヒント
通常のアプリケーション ワークロードによってファイルが同じ割り当て済みサイズまで再度増える場合は、データ ファイルを圧縮することはお勧めしません。
Azure SQL Database では、DBCC SHRINKDATABASE または DBCC SHRINKFILE コマンドのいずれかを使用してファイルを圧縮できます。
DBCC SHRINKDATABASEでは、単一のコマンドを使用して、データベース内のすべてのデータとログ ファイルを圧縮します。 このコマンドによって、一度に 1 つのデータ ファイルが圧縮されます。より大規模なデータベースでは時間がかかる場合があります。 また、ログ ファイルも縮小されます。Azure SQL Database によって必要に応じてログ ファイルが自動的に圧縮されるため、これは通常は不要です。DBCC SHRINKFILEコマンドでは、より高度なシナリオがサポートされます。- データベース内のすべてのファイルを圧縮するのではなく、必要に応じて個々のファイルを対象にすることができます。
- 各
DBCC SHRINKFILEコマンドを他のDBCC SHRINKFILEコマンドと並列して実行することで、複数のファイルを同時に圧縮して、圧縮の合計時間を短縮できます。ただし、リソースの使用率が高くなり、圧縮中に実行されるユーザー クエリがブロックされる可能性が高くなります。 - ファイルの末尾にデータが含まれていない場合は、
TRUNCATEONLY引数を指定することで、割り当てられたファイル サイズをはるかに高速に縮小できます。 この場合、ファイル内でのデータ移動は必要ありません。
- これらの圧縮コマンドの詳細については、「DBCC SHRINKDATABASE」と「DBCC SHRINKFILE」を参照してください。
次の例は、master データベースではなく、ターゲット ユーザー データベースに接続しているときに実行する必要があります。
DBCC SHRINKDATABASE を使用して、特定のデータベースのすべてのデータ ファイルとログ ファイルを圧縮するには、次のようにします。
-- Shrink database data space allocated.
DBCC SHRINKDATABASE (N'database_name');
Azure SQL Database のデータベースには、データの増加に合わせて自動的に作成されるデータ ファイルが 1 つ以上含まれている場合があります。 各ファイルの使用済みサイズと割り当てサイズなど、データベースのファイル レイアウトを決定するには、次のサンプル スクリプトを使用して sys.database_files カタログ ビューのクエリを実行します。
-- Review file properties, including file_id and name values to reference in shrink commands
SELECT file_id,
name,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_file_size_mb
FROM sys.database_files
WHERE type_desc IN ('ROWS','LOG');
次の例のように、DBCC SHRINKFILE コマンドを使用して 1 つのファイルだけに対して圧縮を実行できます。
-- Shrink database data file named 'data_0` by removing all unused at the end of the file, if any.
DBCC SHRINKFILE ('data_0', TRUNCATEONLY);
GO
データベース ファイルの圧縮によってパフォーマンスが悪影響を受けるおそれがあることに注意してください。「圧縮後のインデックスのメンテナンス」を参照してください。
トランザクション ログ ファイルの圧縮
データ ファイルとは異なり、Azure SQL Database では、領域不足エラーが発生する可能性のある領域の過剰使用を防ぐために、トランザクション ログ ファイルが自動的に圧縮されます。 通常は、お客様がトランザクション ログ ファイルを圧縮する必要はありません。
Premium および Business Critical サービス レベルでは、トランザクション ログのサイズが大きくなると、ローカル ストレージの使用量が最大ローカル ストレージの制限に近づく大きな一因となる可能性があります。 ローカル ストレージの使用量が上限に近づいている場合は、次の例に示すように、DBCC SHRINKFILE コマンドを使用してトランザクション ログを圧縮できます。 これにより、定期的な自動圧縮操作を待たずに、コマンドが完了するとすぐにローカル ストレージが解放されます。
次の例は、master データベースではなく、ターゲット ユーザー データベースに接続しているときに実行する必要があります。
-- Shrink the database log file (always file_id 2), by removing all unused space at the end of the file, if any.
DBCC SHRINKFILE (2, TRUNCATEONLY);
自動圧縮
データ ファイルを手動で圧縮する代わりに、データベースに対して自動圧縮を有効にすることができます。 ただし、自動圧縮は、DBCC SHRINKDATABASE および DBCC SHRINKFILE よりもファイル領域の解放の効果が低くなる可能性があります。
既定では、自動圧縮は無効になっています。これは、ほとんどのデータベースで推奨されます。 自動圧縮を有効にすることが必要になった場合は、永続的に有効にしておくのではなく、領域管理の目標を達成したら無効にすることをお勧めします。 詳細については、「AUTO_SHRINK に関する考慮事項」を参照してください。
たとえば、自動圧縮は、エラスティック プールに多くのデータベースが含まれており、使用されているデータ ファイル領域が大幅に増減したことが原因で、プールでその最大サイズの制限に近づくような特定のシナリオで役立ちます。 これは一般的なシナリオではありません。
自動圧縮を有効にするには、(master データベースではなく) 対象のデータベースに接続しているときに次のコマンドを実行します。
-- Enable auto-shrink for the current database.
ALTER DATABASE CURRENT SET AUTO_SHRINK ON;
このコマンドの詳細については、DATABASE SET オプションをご覧ください。
圧縮後のインデックスのメンテナンス
データ ファイルに対する圧縮操作が完了すると、インデックスが断片化される可能性があります。 これにより、大規模なスキャンを使用したクエリなど、特定のワークロードではパフォーマンス最適化の有効性が低下します。 圧縮操作の完了後にパフォーマンスが低下する場合は、インデックスを再構築するためのインデックスのメンテナンスを検討してください。 インデックスの再構築にはデータベースの空き領域が必要であるため、割り当てられた領域が増えて、圧縮の効果を弱める可能性があることを覚えておいてください。
インデックスのメンテナンスの詳細については、「クエリのパフォーマンスを向上させてリソースの消費を削減するためにインデックスのメンテナンスを最適化する」を参照してください。
大規模なデータベースを圧縮する
データベースに割り当てられた領域が数百ギガバイト以上の場合、圧縮の完了にかなりの時間 (多くの場合、数テラバイトのデータベースでは数時間または数日単位) が必要になることがあります。 このプロセスの効率を高め、アプリケーション ワークロードへの影響を軽減するために使用できるプロセスの最適化とベスト プラクティスがあります。
領域の使用状況のベースラインをキャプチャする
圧縮を開始する前に、次の領域の使用状況クエリを実行して、各データベース ファイルで現在使用されている領域と割り当てられた領域をキャプチャします。
SELECT file_id,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
圧縮が完了したら、このクエリを再度実行し、結果を最初のベースラインと比較できます。
データ ファイルを切り詰める
最初に TRUNCATEONLY パラメーターを使用してデータ ファイルごとに圧縮を実行することをお勧めします。 この方法では、ファイルの末尾に割り当てられているが未使用の領域がある場合、データ移動なしですばやく削除されます。 次のサンプル コマンドでは、file_id が 4 のデータ ファイルが切り詰められます。
DBCC SHRINKFILE (4, TRUNCATEONLY);
すべてのデータ ファイルに対してこのコマンドが実行されると、領域の使用状況クエリを再実行して、割り当て済みの領域が減少した場合はそれを確認できます。 また、Azure portal でデータベースの割り当て済み領域を表示することもできます。
インデックス ページの密度を評価する
データ ファイルを切り詰めても、割り当て済みの領域が十分に減らなかった場合は、データ ファイルを圧縮する必要があります。 ただし、省略可能ですがお勧めの手順として、最初にデータベース内のインデックスの平均ページ密度を判別する必要があります。 同じ量のデータの場合、ページの密度が高い場合は、ページの移動が少なくなるので圧縮の完了がより速くなります。 一部のインデックスでページの密度が低い場合は、データ ファイルを圧縮する前に、これらのインデックスのメンテナンスを実行してページ密度を増やすことを検討してください。 これにより、圧縮で割り当て済みのストレージ領域のより大幅な削減を実現できます。
データベース内のすべてのインデックスのページ密度を判別するには、次のクエリを使用します。 ページ密度は avg_page_space_used_in_percent 列で報告されます。
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
ページ密度が 60 から 70% 未満のページ数が多いインデックスがある場合は、データ ファイルを圧縮する前に、これらのインデックスを再構築または再編成することを検討してください。
Note
大規模なデータベースでは、ページ密度を判別するためのクエリの完了には、長時間 (数時間) かかる場合があります。 さらに、大規模なインデックスを再構築または再編成するには、かなりの時間とリソース使用量も必要です。 ページ密度を増やすことに追加の時間をかけることと、圧縮期間を短縮して高い省スペースを実現することとの間には、トレードオフがあります。
ページ密度が低いインデックスが複数ある場合は、複数のデータベース セッションで並行して再構築してプロセスを高速化できることがあります。 ただし、そうすることでデータベース リソースの制限に近づかないようにして、実行されている可能性があるアプリケーション ワークロードに十分なリソース ヘッドルームを残してください。 Azure portal 内で、またはsys.dm_db_resource_stats ビューを使用して、リソース使用量 (CPU、データ IO、ログ IO) を監視し、これらの各ディメンションのリソース使用率が 100% を大幅に下回ったままの場合にのみ、追加の並列再構築を開始します。 CPU、データ IO、またはログ IO の使用率が 100% の場合は、データベースをスケールアップして CPU コアを増やし、IO スループットを向上させることができます。 これにより、追加の並列再構築でプロセスを迅速に完了できる場合があります。
インデックス再構築コマンドのサンプル
ALTER INDEX ステートメントを使用して、インデックスを再構築してページ密度を高めるためのサンプル コマンドを次に示します。
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
このコマンドによって、オンラインの再開可能なインデックスの再構築が開始されます。 これで、再構築の進行中に同時実行ワークロードでテーブルの使用を続行でき、何らかの理由で中断された場合に再構築を再開できます。 ただし、この種類の再構築は、テーブルへのアクセスをブロックするオフラインの再構築よりも低速です。 再構築中に他のワークロードからテーブルにアクセスする必要がない場合は、ONLINE および RESUMABLE オプションを OFF に設定し、WAIT_AT_LOW_PRIORITY 句を削除します。
インデックスのメンテナンスの詳細について学習するには、「クエリのパフォーマンスを向上させてリソースの消費を削減するためにインデックスのメンテナンスを最適化する」を参照してください。
複数のデータ ファイルを圧縮する
前に説明したように、データ移動での圧縮は長期のプロセスです。 データベースに複数のデータ ファイルがある場合は、複数のデータ ファイルを並行して圧縮することで、プロセスを高速化できます。 これを行うには、複数のデータベース セッションを開き、各セッションで異なる file_id 値とともに DBCC SHRINKFILE を使用します。 上記のインデックスの再構築と同様に、新しいそれぞれの並列圧縮コマンドを開始する前に、十分なリソース ヘッドルーム (CPU、データ IO、ログ IO) を確保してください。
次のサンプル コマンドでは、file_id が 4 のデータ ファイルを圧縮し、ファイル内でページを移動して、割り当てサイズを 52,000 MB に減らします。
DBCC SHRINKFILE (4, 52000);
ファイルの割り当て済み領域を最小限まで減らしたい場合は、ターゲット サイズを指定せずにステートメントを実行します。
DBCC SHRINKFILE (4);
ワークロードが圧縮と同時に実行されている場合、圧縮が完了し、ファイルが切り詰められる前に、圧縮によって解放されたストレージ領域の使用が開始される可能性があります。 この場合、圧縮しても、指定したターゲットに割り当てられた領域を減らすことはできません。
これを回避するには、各ファイルを小さなステップに分割して圧縮します。 つまり、DBCC SHRINKFILE コマンドでは、ベースライン領域の使用状況クエリの結果に示されている、ファイルに現在割り当てられている領域よりも少し小さいターゲットを設定します。 たとえば、file_id が 4 のファイルに割り当てられた領域が 200,000 MB の場合に、100,000 MB に圧縮するには、最初にターゲットを 170,000 MB に設定できます。
DBCC SHRINKFILE (4, 170000);
このコマンドが完了すると、ファイルが切り詰められ、割り当てられたサイズが 170,000 MB に減ります。 その後、ファイルが目的のサイズに圧縮されるまで、最初にターゲットを 140,000 MB に設定し、次に 110,000 MB などに設定して、このコマンドを繰り返すことができます。 コマンドが完了したがファイルが切り詰められていない場合は、30,000 MB ではなく 15,000 MB など、より小さなステップを使用します。
同時に実行されているすべての圧縮セッションの圧縮の進行状況を監視するには、次のクエリを使用できます。
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
Note
圧縮の進行状況は非線形になる可能性があります。また、圧縮がまだ進行中でも、percent_complete 列の値は長時間実質的に変更されないままになることがあります。
すべてのデータ ファイルの圧縮が完了したら、領域の使用状況クエリを再実行 (または Azure portal で確認) して、割り当てられたストレージ サイズの削減結果を判断します。 使用済みの領域と割り当て済みの領域の間にまだ大きな差がある場合は、前述のようにインデックスを再構築します。 これにより、割り当て済みの領域がさらに一時的に増加する可能性があります。ただし、インデックスの再構築後にデータ ファイルを再び圧縮すると、割り当て済みの領域が大幅に減るはずです。
圧縮中の一時的なエラー
圧縮コマンドは、場合によってはタイムアウトやデッドロックなどのさまざまなエラーで失敗することがあります。 一般に、これらのエラーは一時的であり、同じコマンドが繰り返された場合は再び発生しません。 圧縮がエラーで失敗した場合、データ ページの移動におけるこれまでの進行は保持され、同じ圧縮コマンドを再度実行してファイルの圧縮を続行できます。
次のサンプル スクリプトは、再試行ループで圧縮を実行して、タイムアウト エラーまたはデッドロック エラーが発生したときに構成可能な回数まで自動的に再試行する方法を示しています。 この再試行方法は、圧縮中に発生する可能性がある他の多くのエラーに適用できます。
DECLARE @RetryCount int = 3; -- adjust to configure desired number of retries
DECLARE @Delay char(12);
-- Retry loop
WHILE @RetryCount >= 0
BEGIN
BEGIN TRY
DBCC SHRINKFILE (1); -- adjust file_id and other shrink parameters
-- Exit retry loop on successful execution
SELECT @RetryCount = -1;
END TRY
BEGIN CATCH
-- Retry for the declared number of times without raising an error if deadlocked or timed out waiting for a lock
IF ERROR_NUMBER() IN (1205, 49516) AND @RetryCount > 0
BEGIN
SELECT @RetryCount -= 1;
PRINT CONCAT('Retry at ', SYSUTCDATETIME());
-- Wait for a random period of time between 1 and 10 seconds before retrying
SELECT @Delay = '00:00:0' + CAST(CAST(1 + RAND() * 8.999 AS decimal(5,3)) AS varchar(5));
WAITFOR DELAY @Delay;
END
ELSE -- Raise error and exit loop
BEGIN
SELECT @RetryCount = -1;
THROW;
END
END CATCH
END;
タイムアウトとデッドロックに加えて、特定の既知の問題が原因で、圧縮でエラーが発生する可能性があります。
返されるエラーと軽減策の手順は次のとおりです。
- エラー番号: 49503、エラー メッセージ: %.*ls: ページ %d:%d は、行外の永続的なバージョン ストア ページなので移動できませんでした。ページ ホールドアップの理由: %ls。ページ ホールドアップのタイムスタンプ: %I64d。
このエラーは、永続的なバージョン ストア (PVS) で行バージョンを生成した、長期のアクティブなトランザクションがある場合に発生します。 これらの行バージョンを含むページは圧縮しても移動できません。そのため、進行できず、このエラーで失敗します。
回避するには、これらの長期のトランザクションが完了するまで待つ必要があります。 または、これらの長期のトランザクションを特定して終了することができます。ただし、トランザクション エラーを正常に処理しないとアプリケーションが影響を受ける可能性があります。 長期のトランザクションを見つける方法の 1 つは、圧縮コマンドを実行したデータベースで次のクエリを実行することです。
-- Transactions sorted by duration
SELECT st.session_id,
dt.database_transaction_begin_time,
DATEDIFF(second, dt.database_transaction_begin_time, CURRENT_TIMESTAMP) AS transaction_duration_seconds,
dt.database_transaction_log_bytes_used,
dt.database_transaction_log_bytes_reserved,
st.is_user_transaction,
st.open_transaction_count,
ib.event_type,
ib.parameters,
ib.event_info
FROM sys.dm_tran_database_transactions AS dt
INNER JOIN sys.dm_tran_session_transactions AS st
ON dt.transaction_id = st.transaction_id
OUTER APPLY sys.dm_exec_input_buffer(st.session_id, default) AS ib
WHERE dt.database_id = DB_ID()
ORDER BY transaction_duration_seconds DESC;
KILL コマンドを使用し、クエリ結果から関連付けられた session_id 値を指定すると、トランザクションを終了できます。
KILL 4242; -- replace 4242 with the session_id value from query results
注意
トランザクションを終了すると、ワークロードに悪影響を及ぼす可能性があります。
長期のトランザクションが終了または完了すると、内部バックグラウンド タスクでは、しばらくすると不要になった行バージョンがクリーンアップされます。 PVS サイズを監視して、次のクエリを使用してクリーンアップの進行状況を測定できます。 圧縮コマンドを実行したデータベースでクエリを実行します。
SELECT pvss.persistent_version_store_size_kb / 1024. / 1024 AS persistent_version_store_size_gb,
pvss.online_index_version_store_size_kb / 1024. / 1024 AS online_index_version_store_size_gb,
pvss.current_aborted_transaction_count,
pvss.aborted_version_cleaner_start_time,
pvss.aborted_version_cleaner_end_time,
dt.database_transaction_begin_time AS oldest_transaction_begin_time,
asdt.session_id AS active_transaction_session_id,
asdt.elapsed_time_seconds AS active_transaction_elapsed_time_seconds
FROM sys.dm_tran_persistent_version_store_stats AS pvss
LEFT JOIN sys.dm_tran_database_transactions AS dt
ON pvss.oldest_active_transaction_id = dt.transaction_id
AND
pvss.database_id = dt.database_id
LEFT JOIN sys.dm_tran_active_snapshot_database_transactions AS asdt
ON pvss.min_transaction_timestamp = asdt.transaction_sequence_num
OR
pvss.online_index_min_transaction_timestamp = asdt.transaction_sequence_num
WHERE pvss.database_id = DB_ID();
persistent_version_store_size_gb 列で報告された PVS サイズが元のサイズと比較して大幅に縮小されたら、圧縮の再実行は成功するはずです。
- エラー番号: 5223、エラー メッセージ: %.*ls: 空のページ %d:%d の割り当てを解除することができませんでした。
このエラーは、ALTER INDEX などの進行中のインデックス メンテナンス操作がある場合に発生する可能性があります。 これらの操作が完了したら、圧縮コマンドを再度試します。
このエラーが解決しない場合は、関連付けられているインデックスの再構築が必要な可能性があります。 再構築するインデックスを見つけるには、圧縮コマンドを実行したのと同じデータベースで次のクエリを実行します。
SELECT OBJECT_SCHEMA_NAME(pg.object_id) AS schema_name,
OBJECT_NAME(pg.object_id) AS object_name,
i.name AS index_name,
p.partition_number
FROM sys.dm_db_page_info(DB_ID(), <file_id>, <page_id>, default) AS pg
INNER JOIN sys.indexes AS i
ON pg.object_id = i.object_id
AND
pg.index_id = i.index_id
INNER JOIN sys.partitions AS p
ON pg.partition_id = p.partition_id;
このクエリを実行する前に、<file_id> および <page_id> プレースホルダーを、表示されたエラー メッセージの実際の値に置き換えます。 たとえば、メッセージが "空のページ 1:62669 の割り当てを解除することができませんでした。" の場合は、<file_id> は 1 で、<page_id> は 62669 です。
クエリで識別されたインデックスを再構築し、圧縮コマンドを再度試します。
- エラー番号: 5201、エラー メッセージ: DBCC SHRINKDATABASE: ファイル ID %d (データベース ID %d) がスキップされました。ファイルに再利用する空き領域が不足しています。
このエラーは、データ ファイルをさらに圧縮できないことを意味します。 次のデータ ファイルに移動できます。
次のステップ
データベースの最大サイズについては、以下を参照してください。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示