Azure 全体で、信頼性とはサービスの停止や劣化が発生した場合の回復性と可用性を意味します。 Azure AI Search では、信頼性は、1 つのサービス内で、または別のリージョンの複数の検索サービスを通じて達成できます。
1 つの検索サービスをデプロイし、高可用性を実現するためにスケールアップします。 複数のレプリカを追加して、より高度なインデックス付けとクエリのワークロードを処理できます。 検索サービスで可用性ゾーンがサポートされている場合、レプリカは、さらなる回復性のために別の物理データ センターに自動的にプロビジョニングされます。
異なる地理的リージョンに複数の検索サービスをデプロイします。 すべての検索ワークロードは、1 つの地理的リージョンで実行される 1 つのサービス内に完全に収まっていますが、マルチサービス シナリオでは、コンテンツを同期して、すべてのサービスで同じになるようにするオプションがあります。 また、負荷分散ソリューションを設定して、サービスが停止した場合に要求を再配信したり、フェールオーバーしたりすることもできます。
リージョン レベルでの事業継続性と災害からの復旧のために、同じ構成とコンテンツを持つ複数の検索サービスで構成されたリージョン間トポロジを計画します。 カスタム スクリプトまたはコードは、代替検索サービスが突然使用できなくなった場合に フェールオーバー メカニズムを提供します。
高可用性
Azure AI Search では、レプリカはインデックスのコピーです。 検索サービスは、少なくとも 1 つのレプリカで委託され、最大 12 個のレプリカを保有することができます。 レプリカを追加すると、Azure AI Search は 1 つのレプリカに対してマシンの再起動とメンテナンスを実行し、クエリの実行は他のレプリカで続行できます。
Microsoft は、個々の検索サービスについて、次の条件を満たす構成に対して 99.9% 以上の可用性を保証します。
"読み取り専用" ワークロード (クエリ) の高可用性のための 2 個のレプリカ
"読み取り/書き込み" ワークロード (クエリとインデックス作成) の高可用性のための 3 個以上のレプリカ
システムには、レプリカの正常性とパーティションの整合性を監視するための内部メカニズムがあります。 レプリカとパーティションの特定の組み合わせをプロビジョニングすると、システムによってサービスの容量レベルが保証されます。
Free レベルでは、サービス レベル アグリーメント (SLA) は提供されません。 詳細については、「Azure AI 検索の SLA」を参照してください。
可用性ゾーンのサポート
Availability Zones は、リージョンのデータ センターを個別の物理的な場所のグループに分割することで、同一リージョン内での高可用性を実現する Azure プラットフォーム機能です。 Azure AI Search では、個々のレプリカがゾーン割り当ての単位です。 検索サービスは、1 つのリージョン内で実行されます。そのレプリカは、そのリージョン内の別の物理データ センター (またはゾーン) で実行されます。
可用性ゾーンは、2 つ以上のレプリカを検索サービスに追加するときに使用されます。 各レプリカは、リージョン内の異なる可用性ゾーンに配置されます。 検索サービス リージョンで使用可能なゾーンよりもレプリカが多い場合、レプリカはできるだけ均等に複数のゾーンに分散されます。 可用性ゾーンを提供するリージョンに検索サービスを作成し、複数のレプリカを使用するようにサービスを構成する以外に、ユーザー側で特定の操作は必要ありません。
前提条件
- サービス レベルは Standard 以上である必要があります
- サービス リージョンは、(次のセクションに記載された) 可用性ゾーンがあるリージョンにする必要があります
- 構成には、複数のレプリカ (読み取り専用クエリ ワークロードの場合は 2 個、インデックス作成を含む読み取り/書き込みワークロードの場合は 3 個) を含める必要があります
サポートされているリージョン
Availability Zones のサポートは、インフラストラクチャとストレージによって異なります。 現在、以下のゾーンには十分なストレージがないため、Azure AI Search の可用性ゾーンは提供されていません。
- 西日本
Azure AI Search 用の Availability Zones は、次のリージョンでサポートされています。
| リージョン | ロールアウト日 |
|---|---|
| オーストラリア東部 | 2021年1月30日以降 |
| ブラジル南部 | 2021年5月2日以降 |
| カナダ中部 | 2021年1月30日以降 |
| インド中部 | 2022年1月20日以降 |
| 米国中部 | 2020年12月4日以降 |
| 中国北部3 | 2022 年 9 月 7 日以降 |
| 東アジア | 2022年1月13日以降 |
| 米国東部 | 2021年1月27日以降 |
| 米国東部 2 | 2021年1月30日以降 |
| フランス中部 | 2020年10月23日以降 |
| ドイツ中西部 | 2021 年 5 月 3 日以降 |
| イスラエル中部 | 2024 年 4 月 1 日以降 |
| イタリア北部 | 2024 年 4 月 1 日以降 |
| 東日本 | 2021年1月30日以降 |
| 韓国中部 | 2022年1月20日以降 |
| 北ヨーロッパ | 2021年1月28日以降 |
| ノルウェー東部 | 2022年1月20日以降 |
| カタール中部 | 2022 年 8 月 25 日以降 |
| 南アフリカ北部 | 2022 年 9 月 7 日以降 |
| 米国中南部 | 2021年4月30日以降 |
| 東南アジア | 2021年1月31日以降 |
| スウェーデン中部 | 2022年1月21日以降 |
| スイス北部 | 2022 年 9 月 7 日以降 |
| アラブ首長国連邦北部 | 2022 年 9 月 9 日以降 |
| 英国南部 | 2021年1月30日以降 |
| アメリカ合衆国政府 バージニア州 | 2021年4月30日以降 |
| 西ヨーロッパ | 2021年1月29日以降 |
| 米国西部 2 | 2021年1月30日以降 |
| 米国西部 3 | 2021 年 6 月 2 日以降 |
注
可用性ゾーンでは、SLA の条件は変化しません。 クエリの高可用性を実現するには、3 つ以上のレプリカが必要です。
個別の地理的リージョン内の複数のサービス
運用要件に次が含まれる場合は、サービスの冗長性が必要です。
ビジネス継続性とディザスター リカバリー (BCDR) の要件。 Azure AI Search では、停止が発生した場合に即時フェールオーバーは提供されません。
グローバル分散型アプリケーションの高速パフォーマンス。 クエリおよびインデックス付けの要求が世界中から行われた場合、ホスト データセンターに近いユーザーほどパフォーマンスが速くなります。 このユーザーに近接しているリージョンにさらにサービスを作成すると、全ユーザーのパフォーマンスを均等化できます。
2 つ以上の検索サービスが必要な場合は、それらを異なるリージョンに作成することで、継続性と復旧のためのアプリケーション要件を満たし、グローバル ユーザー ベースの応答時間を短縮できます。
Azure AI Search では、地理的リージョン間で検索インデックスのレプリケートする自動化された方法を提供していませんが、このプロセスを簡素化して実装および管理できる手法がいくつかあります。 以下のセクションでは、これらの手法の概要を説明します。
地理的に分散した一連の検索サービスの目的は、2 つ以上のリージョンで 2 つ以上のインデックスを使用できるようにすることです。このリージョンでは、ユーザーは待機時間が最も短い Azure AI Search サービスにルーティングされます。
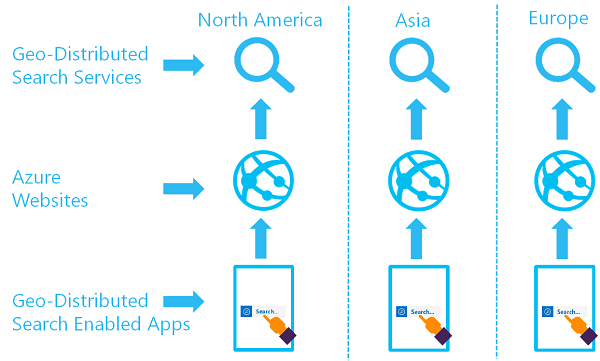
このアーキテクチャを実装するには、複数のサービスを作成し、データ同期の戦略を設計します。 必要に応じて、ルート指定要求のための Azure Traffic Manager などのリソースを含めることができます。
ヒント
複数のリージョンに複数の検索サービスをデプロイする方法については、完全に構成された複数リージョンの検索ソリューションをデプロイする GitHub のこの Bicep サンプル を参照してください。 このサンプルでは、インデックスの同期と Traffic Manager を使用した要求リダイレクトの 2 つの方法ができます。
複数のサービス間でデータを同期する
2 つ以上の異なる検索サービスの同期を維持するには、次の 2 つの方法があります。
- インデクサーを使用して、コンテンツの更新を検索インデックスにプルする。
- ドキュメントの追加または更新 (REST) API または Azure SDK と同等の API を使用して、コンテンツをインデックスにプッシュする。
どちらかで構成するには、azure-search-multiple-region リポジトリでサンプル Bicep スクリプトを使用し、リージョンとインデックス付け戦略を変更することをお勧めします。
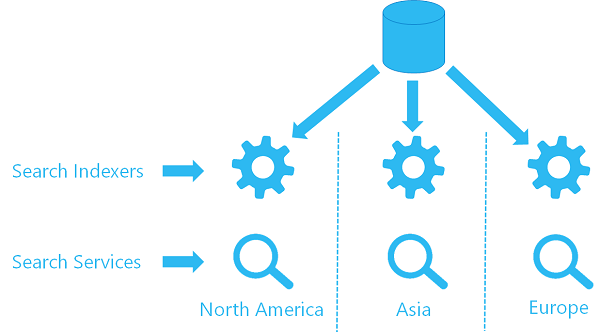
オプション 1: 複数のサービス上のコンテンツ更新のためのインデクサーの使用
あるサービスで既にインデクサーを使用している場合は、2 つ目のサービスに 2 つ目のインデクサーを構成し、同じデータ ソース オブジェクトを使用して同じ場所からデータをプルすることができます。 各リージョンの各サービスには、独自のインデクサーとターゲット インデックスがあります (検索インデックスは共有されていません。つまり、各インデックスにはデータの独自のコピーが入っています) が、各インデクサーは同じデータ ソースを参照します。
このアーキテクチャの概要の高度な図を次に示します。
オプション 2: 複数のサービスでコンテンツの更新をプッシュするための REST API を使用する
Azure AI Search REST API を使用してコンテンツを検索インデックスにプッシュする場合は、更新が必要になるたびにすべての検索サービスに変更をプッシュすることで、さまざまな検索サービスの同期を保てます。 コードでは、ある Search サービスの更新が失敗した場合でも、他のサービスでの成功は必ず処理してください。
クエリ要求のフェールオーバーまたはリダイレクト
要求レベルで冗長性が必要な場合、Azure にはいくつかの負荷分散オプションがあります。
- Azure Traffic Manager、複数の地理的にに配置された Web サイトに要求をルーティングするために使用され、その要求は複数の検索サービスによってサポートされます。
- Application Gateway、アプリケーション レイヤーのリージョン内のサーバー間の負荷分散に使用されます。
- Azure Front Door、Web トラフィックのグローバル ルーティングを最適化し、グローバル フェールオーバーを提供するために使用されます。
- Azure Load Balancer。バックエンド プール内のサービス間の負荷分散に使用されます。
負荷分散オプションを評価する際に注意すること:
検索は、クライアントからのクエリ要求とインデックス付け要求を受け入れるバックエンド サービスです。
クライアントから検索サービスへの要求を認証する必要があります。 検索操作にアクセスするには、呼び出し元がロールベースのアクセス許可を持っているか、要求に対して API キーを指定する必要があります。
サービス エンドポイントには、既定でパブリック インターネット接続を介して到達します。 仮想ネットワーク内が元であるクライアント接続のプライベート エンドポイントを設定する場合は、Application Gateway を使用します。
Azure AI Search は、
<your-search-service-name>.search.windows.netエンドポイント宛ての要求を受け入れます。 ホスト ヘッダー内の別の DNS 名 (CNAME など) を使用して同じエンドポイントに到達した場合、要求は拒否されます。
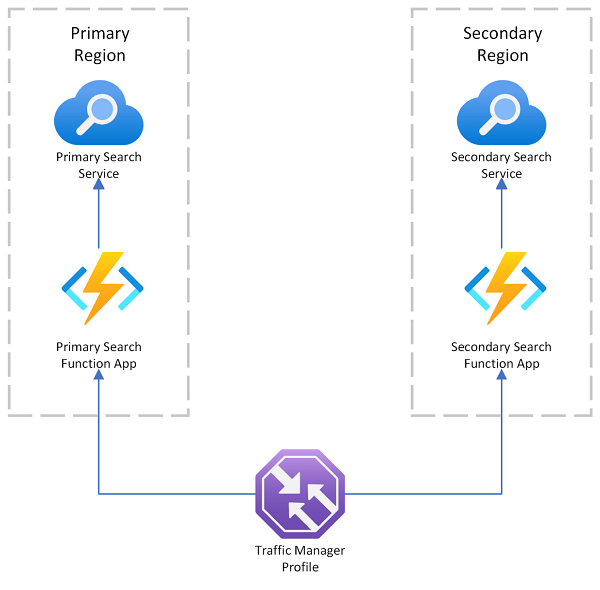
Azure AI Search には、プライマリ エンドポイントで障害が発生した場合の要求リダイレクトに Azure Traffic Manager を使用する、マルチリージョン デプロイ サンプルがあります。 このソリューションは、同じリージョン内の検索サービスのみを呼び出す、検索が有効なクライアントにルーティングする場合に便利です。
Azure Traffic Manager は主に、特定のルーティング方法 (優先順位、パフォーマンス、地理的な場所など) に基づいて、異なるエンドポイント間でネットワーク トラフィックをルーティングするのに使用されます。 DNS レベルで機能し、受信した要求を適切なエンドポイントに転送します。 Traffic Manager がサービスを提供しているエンドポイントが要求を拒否し始めると、トラフィックは別のエンドポイントにルーティングされます。
Traffic Manager では、Azure AI Search に直接接続するためのエンドポイントは提供されません。つまり、Traffic Manager の背後に検索サービスを直接配置することはできません。 それどころか、要求が Traffic Manager、次に検索が有効な Web クライアント、最後にバックエンド上の検索サービスに流れることが前提です。 クライアントとサービスは同じリージョンにあります。 1 つの検索サービスがダウンした場合、検索クライアントで障害が起き始めると、Traffic Manager は残りのクライアントにリダイレクトします。
注
検索サービスで Azure Load Balancer 正常性プローブ を使用している場合は、パスとして /ping を持つ HTTPS プローブを使用する必要があります。
複数リージョン デプロイでのデータ所在地
さまざまな地理的リージョンに複数の検索サービスをデプロイすると、コンテンツは検索サービスごとに選択したリージョンに格納されます。
Azure AI 検索が、利用者の認可なしに指定されたリージョン外にデータを保存することはありません。 Azure Storage リソースに書き込む機能 (エンリッチメント キャッシュ、デバッグ セッション、ナレッジ ストア) を使用する場合、認可は暗黙的です。 いずれの場合も、ストレージ アカウントは、選択したリージョンでユーザーが指定するものになります。
注記
ストレージ アカウントと検索サービスの両方が同じリージョンにある場合、検索とストレージ間のネットワーク トラフィックはプライベート IP アドレスを使用し、Microsoft バックボーン ネットワーク経由で発生します。 プライベート IP アドレスが使用されるため、ネットワーク セキュリティ用に IP ファイアウォールまたはプライベート エンドポイントを構成することはできません。 代わりに、両方のサービスが同じリージョンにある場合は、信頼されたサービス例外を代替として使用してください。
サービスの停止と致命的なイベントについて
SLA で説明されているように、Microsoft は、Azure AI 検索サービス インスタンスが 2 個以上のレプリカで構成されている場合はインデックス クエリ要求の可用性を、Azure AI 検索サービス インスタンスが 3 個以上のレプリカで構成されている場合はインデックス更新要求の可用性を、高レベルで保証しています。 ただし、ディザスター リカバリーのための組み込みのメカニズムはありません。 Microsoft の管理が及ばない外部の壊滅的災害の際にサービスを継続する必要がある場合は、異なるリージョンに 2 番目のサービスをプロビジョニングし、geo レプリケーション戦略を導入して、インデックスがすべてのサービスで完全に冗長になるようにすることをお勧めします。
インデクサーを使用してインデックスの設定と更新を行うお客様は、同じデータ ソースからデータを取得する地域固有のインデクサーによりディザスター リカバリーを処理できます。 異なるリージョンにある 2 つのサービスそれぞれでインデクサーを実行し、同じデータ ソースのインデックスを作成すると、geo 冗長性を実現できます。 地域冗長性も備えたデータ ソースからインデックス付けを行う場合、Azure AI Search インデクサーはプライマリ レプリカからの増分インデックス付け (新しいドキュメント、変更されたドキュメント、または削除されたドキュメントからの更新のマージ) しか実行できないことに注意してください。 フェールオーバー イベントでは、必ずインデクサーを新しいプライマリ レプリカにリダイレクトするようにしてください。
インデクサーを使用しない場合は、アプリケーションのコードを使ってオブジェクトとデータを異なる検索サービスに並列にプッシュします。 詳細については、「複数のサービス間でのデータの同期」を参照してください。
バックアップと復元の代替手段
通常、データ レイヤーのビジネス継続性戦略には、バックアップからの復元手順が含まれます。 Azure AI Search は主要なデータ ストレージ ソリューションではないため、Microsoft ではセルフサービスのバックアップおよび復元のための正式なメカニズムは提供していません。 ただし、この Azure AI Search .NET サンプル リポジトリまたはこの Python サンプル リポジトリのインデックスバックアップ/復元サンプル コードを使用して、インデックス定義とスナップショットを一連の JSON ファイルにバックアップし、必要に応じてこれらのファイルを使用してインデックスを復元できます。 このツールを使用して、サービス レベル間でインデックスを移動することもできます。
そうしない場合は、インデックスの作成と設定に使われるアプリケーション コードが、誤ってインデックスを削除した場合の事実上の復元オプションです。 インデックスを再構築するには、インデックスを削除し (存在する場合)、サービスでインデックスを再作成して、プライマリ データ ストアからデータを取得することによって再読み込みします。
関連するコンテンツ
- それぞれの価格レベルとサービスの制限の詳細については、「サービスの制限」を参照してください。
- パーティションとレプリカの組み合わせの詳細については、「容量の計画」を確認してください。
- 構成に関するその他のガイダンスについては、「ケース スタディ: Cognitive Search を使用して複雑な AI シナリオをサポート」を確認してください。