結合 (SQL Server)
適用対象:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)
SQL Server では、インメモリの並べ替えとハッシュ結合テクノロジを使用して、並べ替え、積集合、和集合、および差集合の各演算が実行されます。 この種のクエリ プランを使用すると、SQL Server によってテーブルの列分割がサポートされます。
SQL Server では、Transact-SQL 構文によって決定される論理結合操作が実装されます。
- 内部結合
- 左外部結合
- 右外部結合
- 完全外部結合
- クロス結合
Note
結合構文の詳細については、「FROM 句と JOIN、APPLY、PIVOT (Transact-SQL)」を参照してください。
SQL Server には、論理結合操作を実行するために、次の 4 種類の物理結合操作が採用されています。
- ネステッド ループ結合
- マージ結合
- ハッシュ結合
- アダプティブ結合 (SQL Server 2017 (14.x) 以降)
結合の基礎
結合を使用すると、テーブル間の論理リレーションシップに基づいて、複数のテーブルからデータを取得できます。 結合では、SQL Server が 1 つのテーブルのデータを使用して別のテーブルの行を選択する方法を指定します。
結合条件は、クエリ内の 2 つのテーブルの関係を定義します。
- テーブルごとに結合に使用する列を指定します。 一般的な結合条件では、1 つのテーブルから外部キーを指定し、他のテーブルでそれに対応したキーを指定します。
- 列の値の比較に使用する論理演算子 (= や <> など) を指定します。
結合は、次の Transact-SQL 構文を使用して論理的に表現されます。
- INNER JOIN
- LEFT [ OUTER ] JOIN
- RIGHT [ OUTER ] JOIN
- FULL [ OUTER ] JOIN
- CROSS JOIN
内部結合は、FROM 句または WHERE 句のどちらを使用しても指定できます。 外部結合とクロス結合は、FROM 句でのみ指定できます。 結合条件は、検索条件 WHERE と HAVING を使用して、FROM 句で参照されたベース テーブルからどの行を選択するかを指定します。
FROM 句で結合条件を指定すると、WHERE 句で他の検索条件が指定された場合に区別しやすくなります。結合を指定する場合、FROM 句で指定することをお勧めします。 簡略化された ISO FROM 句の結合構文は次のとおりです。
FROM first_table < join_type > second_table [ ON ( join_condition ) ]
join_type は、実行する結合の種類 (内部、外部、クロス結合) を指定します。 join_condition は、結合された各行を評価するための述語を定義します。 以下に FROM 句での結合指定の例を示します。
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON ( ProductVendor.BusinessEntityID = Vendor.BusinessEntityID )
次の例は、この結合を使用したシンプルな SELECT ステートメントを示します。
SELECT ProductID, Purchasing.Vendor.BusinessEntityID, Name
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON (Purchasing.ProductVendor.BusinessEntityID = Purchasing.Vendor.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
GO
この SELECT ステートメントからは、企業名が F で始まる企業が提供する製品のうち価格が 10 ドルを超えている部品について、製品と納入業者の情報が返されます。
1 つのクエリで複数のテーブルを参照する場合、どの列参照も明確である必要があります。 上記の例では、ProductVendor および Vendor テーブルの両方に、BusinessEntityID という名前の列があります。 複数のテーブル間で重複している列名をクエリで参照する場合は、列名をテーブル名で修飾する必要があります。 この例では Vendor 列への参照はすべて修飾されています。
クエリで使用する複数のテーブルで列名が重複していない場合、参照する列名にテーブル名を付けて修飾する必要はありません。 上記の例を参照してください。 このような SELECT 句は、どのテーブルの列か示されていないので、わかりにくいことがあります。 すべての列をテーブル名で修飾すれば、クエリは読みやすくなります。 テーブル別名を使用すればもっと読みやすくなります。特にテーブル名をデータベース名または所有者名で修飾する必要がある場合は、別名を使用すると読みやすくなります。 次の例は、上記の例と同じですが、テーブル別名が割り当てられており、列はテーブル別名で修飾されているので読みやすくなっています。
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv
INNER JOIN Purchasing.Vendor AS v
ON (pv.BusinessEntityID = v.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
上記の例では、FROM 句 (推奨の方法) で結合条件を指定していました。 次の例に示すように、これと同じ結合条件を持つクエリを WHERE 句でも指定できます。
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv, Purchasing.Vendor AS v
WHERE pv.BusinessEntityID=v.BusinessEntityID
AND StandardPrice > $10
AND Name LIKE N'F%';
結合の SELECT リストは、結合されたテーブル内のすべての列を参照することも、一部の列だけを参照することもできます。 SELECT リストには、結合したすべてのテーブルの列を含める必要はありません。 たとえば、3 つのテーブルを結合した場合、1 つのテーブルだけを使用して残りの 2 つのテーブルの一方から 3 番目のテーブルにブリッジできます。中央のテーブルの列を選択リストで参照する必要はありません。 これは、反準結合とも呼ばれます。
結合条件では、通常は等値比較演算子 (=) を使用します。ただし、他の述語と同様に他の比較演算子や関係演算子も指定できます。 詳しくは、「比較演算子 (Transact-SQL)」および「WHERE (Transact-SQL)」をご覧ください。
つまり、SQL Server で結合を処理する場合、クエリ オプティマイザーは、複数の候補の中から最も効率的な結合の処理方法を選択します。 これには、最も効率的な物理結合の種類、テーブルが結合される順序をそれぞれ選択することや、Transact-SQL 構文で直接表現できない論理結合操作の種類 (準結合 や 反準結合など) を使用することも含まれます。 各結合の物理的実行には何種類もの最適化を使用できるので、その実行を確実に予測することはできません。 準結合と反準結合の詳細については、「プラン表示の論理操作と物理操作のリファレンス」を参照してください。
結合条件で使用する複数の列間で名前やデータ型が同じである必要はありません。 ただし、データ型が同じでない場合、互換性があるか SQL Server が暗黙的に変換できるデータ型である必要があります。 データ型を暗黙的に変換できない場合、結合条件は CAST 関数を使用してデータ型を明示的に変換する必要があります。 明示的な変換と暗黙的な変換について詳しくは、「データ型の変換 (データベース エンジン)」をご覧ください。
結合を使用するクエリは、ほとんどの場合サブクエリ、つまりクエリ内で入れ子になった別のクエリを使用して書き換えることができます。またほとんどのサブクエリは結合として書き換えることができます。 サブクエリについて詳しくは、「サブクエリ」をご覧ください。
Note
ntext 列、text 列、または image 列を使用してテーブルを直接結合することはできません。 ただし、SUBSTRING を使用すれば、ntext 列、text 列、または image 列でテーブルを間接的に結合できます。
たとえば、 SELECT * FROM t1 JOIN t2 ON SUBSTRING(t1.textcolumn, 1, 20) = SUBSTRING(t2.textcolumn, 1, 20) は t1 と t2 のt1 テーブルと t2 テーブルの各テキスト列の先頭の 20 文字について 2 つのテーブル内部結合を実行します。
WHERE 句を使用して列の長さを比較して、2 つのテーブルの ntext 列または text 列を比較することもできます。例: WHERE DATALENGTH(p1.pr_info) = DATALENGTH(p2.pr_info)。
入れ子になっているループ結合についての解釈
一方の結合入力が少なく (たとえば 10 行未満)、他方の結合入力が多く、その結合列にインデックスが設定されている場合、インデックスの入れ子になったループが最も高速な結合演算です。入れ子になったループは I/O が最も少なく、比較が最も少なくなるためです。
入れ子になっているループ結合は "入れ子化反復処理" とも呼ばれ、一方の結合入力を外部入力テーブル (グラフィカルな実行プランでは上部入力として表示) として使用し、もう一方を内部 (下部) 入力テーブルとして使用します。 外部ループでは、外部入力テーブルを 1 行ずつ使用します。 内部ループは、外部行の 1 行ごとに実行され、内部入力テーブルで一致行を検索します。
最も単純な場合、テーブルまたはインデックス全体が検索されます。これは、"単純入れ子化ループ結合" と呼ばれます。 検索でインデックスが使用される場合、"インデックス入れ子化ループ結合" と呼ばれます。 インデックスがクエリ プランの一部として作成される (クエリの完了後破棄される) 場合、"一時インデックス入れ子化ループ結合" と呼ばれます。 これらすべての派生形は、クエリ オプティマイザーによって検討されます。
特に、外部入力が少なく、内部入力があらかじめインデックスを持ち、その数が多い場合に、入れ子になっているループ結合は効果的です。 少数の行にだけ影響を与えるトランザクションなど、多くの小規模なトランザクションでは、インデックス入れ子化ループ結合はマージ結合およびハッシュ結合より優れています。 ただし、大規模なクエリでは、多くの場合入れ子になっているループ結合は最適ではありません。
ネステッド ループ結合演算子の OPTIMIZED 属性が True に設定されている場合は、内部テーブルが大きいときに、それが並列化されているかどうかに関係なく、最適化されたネステッド ループ (またはバッチ並べ替え) を使用して I/O を最小化することを意味します。 指定された計画にこの最適化が含まれていることは、並べ替え自体が非表示操作であることを考えると、実行プランを分析する際にはわかりにくいかもしれません。 しかし、OPTIMIZED 属性の XML プランを見ると、ネステッド ループ結合では I/O パフォーマンスを向上させるために入力行の並べ替えが試行される場合があることがわかります。
マージ結合
2 つの結合入力が少なくない場合でも、結合列に基づいて並べ替えられている場合 (並べ替えられたインデックスのスキャンにより取得された場合など)、マージ結合が最も高速な結合演算です。 両方の結合入力が多く、2 つの入力が同じようなサイズの場合、あらかじめ並べ替えられたマージ結合とハッシュ結合は同じようなパフォーマンスになります。 ただし、2 つの入力サイズが大きく異なる場合、ハッシュ結合演算の方がはるかに高速になることが多くなります。
マージ結合では、両方の入力がマージ列を基準に並べ替えられていることが必要です。マージ列は、結合述語の等値 (ON) 句によって定義されます。 通常、インデックスが対応する 1 組の列に対して存在する場合、クエリ オプティマイザーはインデックスをスキャンします。または、マージ結合の下に並べ替え操作が配置されます。 まれに、複数の等値句が存在することもありますが、マージ列は利用できる等値句の一部からしか取られません。
各入力が並べ替えられるので、Merge Join 操作は各入力から 1 行ずつ取得して、それらを比較します。 たとえば、Inner Join 操作では、行が等しい場合、それらの行が返されます。 行が等しくない場合は、小さい方の値が含まれる行が破棄され、その入力から別の行が取得されます。 すべての行が処理されるまで、この処理は続きます。
Merge Join 操作は、標準の操作または多対多操作のいずれかになります。 多対多のマージ結合では、行を格納するために一時テーブルが使用されます。 各入力に重複する値がある場合、一方の入力の各重複値が処理されるとき、他方の入力は重複値の先頭に戻る必要があります。
残余述語がある場合、マージ述語に適合するすべての行は残余述語を評価し、残余述語に適合する行だけが返されます。
マージ結合自体は非常に高速ですが、並べ替え操作が必要な場合、時間がかかることがあります。 ただし、データ量が多く、必要なデータを既存の B ツリー インデックスからあらかじめ並べ替えられた形で取得できる場合、多くの場合、利用可能な結合アルゴリズムの中でマージ結合が最も高速になります。
ハッシュ結合
ハッシュ結合は、並べ替えられておらず、インデックスが設定されていない大量の入力を効率的に処理できます。 次のような理由から、ハッシュ結合は、複雑なクエリでの中間結果を得るのに役立ちます。
- 中間結果にはインデックスが設定されず (ディスクに明示的に保存した後インデックスを設定しない限り)、多くの場合、クエリ プランでの次の演算に合わせて並べ替えられることがありません。
- クエリ オプティマイザーは、中間結果のサイズだけを予想します。 複雑なクエリではこの予想が非常に不正確になる場合があります。そのため、中間結果を処理するアルゴリズムは効率的なだけでなく、中間結果が予想をはるかに上回る場合でも、パフォーマンスをあまり低下させないようにする必要があります。
ハッシュ結合では、非正規化の使用を減らすことができます。 通常、非正規化は、結合演算を減らすことにより、パフォーマンスを向上させるときに使用します。ただし、不整合な更新など、データの冗長性が発生するおそれがあります。 ハッシュ結合では、非正規化の必要性が減少します。 ハッシュ結合では、列方向のパーティション分割 (単一テーブルの列グループを異なるファイルまたはインデックスに格納することを表します) を物理データベース デザインに利用できます。
ハッシュ結合には、ビルド入力とプローブ入力という 2 つの入力があります。 クエリ オプティマイザーでは、2 つの入力のうち小さい方がビルド入力になるように、ロールを割り当てます。
ハッシュ結合は多種多様な集合の照合操作に使用されます。ハッシュ結合を使用できるのは、Inner Join、Left Outer Join、Right Outer Join、Full Outer Join、Left Semi Join、Right Semi Join、Intersect、Union、Diff です。 また、ハッシュ結合の派生形では、重複の削除やグループ化を行うことができます (SUM(salary) GROUP BY department など)。 このような変更では、ビルドとプローブの両方のロールに 1 つの入力しか使用しません。
ここでは、インメモリ ハッシュ結合、猶予ハッシュ結合、再帰的ハッシュ結合など、さまざまなハッシュ結合について説明します。
インメモリ ハッシュ結合
このハッシュ結合では、まずビルド入力全体がスキャンまたは計算され、メモリ内にハッシュ テーブルが作成されます。 各行はハッシュ キー用に計算されたハッシュ値に従ってハッシュ バケットに挿入されます。 ビルド入力全体が使用可能なメモリを超えない場合、すべての行をハッシュ テーブルに挿入できます。 このビルド フェーズの後、プローブ フェーズになります。 プローブ入力全体が 1 回に 1 行ずつスキャンまたは計算されます。プローブ行ごとにハッシュ キーの値が計算され、対応するハッシュ バケットがスキャンされて、照合が行われます。
猶予ハッシュ結合
ビルド入力がメモリに入りきらない場合、ハッシュ結合が複数のステップで進められます。 これを、猶予ハッシュ結合と呼びます。 各ステップにはビルド フェーズとプローブ フェーズがあります。 まず、ビルド入力とプローブ入力全体が使用され、複数のファイルにパーティション分割されます (ハッシュ キーにハッシュ関数を使用)。 ハッシュ キーにハッシュ関数を使用すると、2 つの結合レコードが同じファイルの組に含まれることが保証されます。 したがって、2 つの大規模な入力を結合する作業は、小規模な同一作業の複数のインスタンスになります。 その後、ハッシュ結合がパーティション分割されたファイルの組それぞれに適用されます。
再帰的ハッシュ結合
ビルド入力が大規模なので、標準の外部マージの入力に複数のマージ レベルが必要な場合、複数のパーティション分割ステップと複数のパーティション分割レベルが必要です。 パーティションの一部だけが大規模な場合、その特定のパーティションだけに使用するパーティション分割ステップが追加されます。 すべてのパーティション分割ステップをできるだけ高速にするには、大規模な非同期 I/O 操作を使用し、1 つのスレッドで複数のディスク ドライブを集中的に使用できるようにします。
Note
ビルド入力がわずかに使用可能なメモリを超える場合は、インメモリ ハッシュ結合と猶予ハッシュ結合の要素が 1 つのステップに組み合わされ、ハイブリッド ハッシュ結合が作成されます。
最適化時にどのハッシュ結合を使用するかを、常に決定できるわけではありません。 このため SQL Server では、始めにインメモリ ハッシュ結合が使用され、ビルド入力のサイズに従って、徐々に猶予ハッシュ結合と再帰的ハッシュ結合に移行します。
クエリ オプティマイザーが、2 つの入力のうち、ビルド入力になるべき小さい方を誤って予想した場合、ビルド ロールとプローブ ロールは動的に逆転されます。 ハッシュ結合では、必ず小さい方のオーバーフロー ファイルをビルド入力として使用します。 この技法はロール逆転と呼ばれます。 ロール逆転は、ディスクへの書き込みが少なくとも 1 回行われた後にハッシュ結合の内部で行われます。
Note
ロール逆転は、クエリ ヒントやクエリの構造とは無関係に行われます。 ロール逆転はクエリ プランには示されません。ロール逆転が行われてもユーザーには認識されません。
ハッシュの保留
猶予ハッシュ結合または再帰的ハッシュ結合を説明するために、ハッシュの保留という用語が使用されることがあります。
Note
再帰的ハッシュ結合またはハッシュの保留により、サーバーのパフォーマンスが低下します。 トレース内に多数の Hash Warning イベントを確認した場合は、結合対象の列の統計を更新します。
ハッシュの保留について詳しくは、「Hash Warning イベント クラス」をご覧ください。
適応型結合
バッチ モード アダプティブ結合機能を使用すると、最初の入力のスキャンが終わるまで、ハッシュ結合方法またはネステッド ループ結合方法のどちらを選ぶかを、遅延することができます。 アダプティブ結合演算子は、入れ子になったループ プランに切り替えるタイミングを決定するために使われるしきい値を定義します。 したがって、クエリ プランでは、再コンパイルを行わなくても、実行中により適切な結合方法に動的に切り替えることができます。
ヒント
大小の結合入力スキャンが頻繁に切り替わるワークロードの場合、この機能から最もメリットがあります。
ランタイムの決定は、次の手順に基づいて行います。
- ビルド結合入力の行数が十分に小さくて、ネステッド ループ結合の方がハッシュ結合より適している場合、プランはネステッド ループ アルゴリズムに切り替わります。
- ビルド結合入力が特定の行数しきい値を超えている場合、切り替えは行われず、プランはハッシュ結合を使い続けます。
アダプティブ結合の例として次のようなクエリを考えます。
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 360;
このクエリは 336 行を返します。 ライブ クエリ統計を有効にすると次のようなプランが表示されます。
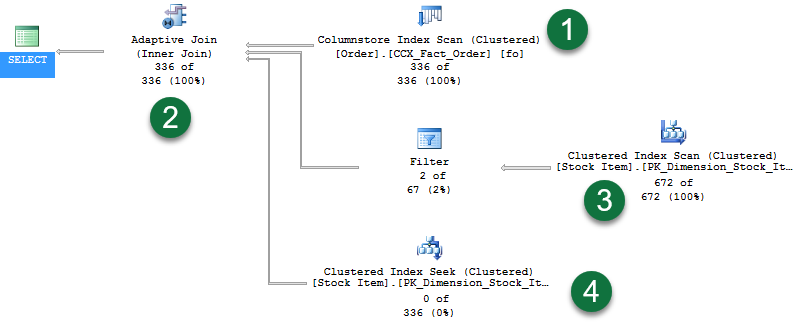
このプランでは、次のことがわかります。
- ハッシュ結合ビルド フェーズ用の行を提供するために、列ストア インデックス スキャンが使われています。
- 新しいアダプティブ結合演算子があります。 この演算子は、入れ子になったループ プランに切り替えるタイミングを決定するために使われるしきい値を定義します。 この例では、しきい値は 78 行です。 行数が >= 78 の場合はいずれでも、ハッシュ結合が使われます。 しきい値より小さい場合は、ネステッド ループ結合が使用されます。
- クエリからは 336 行が返されるため、これはしきい値を超えており、2 番目の分岐は標準的なハッシュ結合操作のプローブ フェーズを表します。 ライブ クエリ統計は演算子を通過する行数を示すことに注意してください (この場合は "672 of 672")。
- そして、最後の分岐は、しきい値を超えていないネステッド ループ結合で使用するためのクラスター化インデックス シークです。 "0 of 336" 行と表示されます (分岐は使われません)。
次は、同じクエリでプランを比較します。ただし、この場合、Quantity 値にはテーブル内の行が 1 つ含まれるだけです。
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 361;
クエリでは 1 行が返されます。 ライブ クエリ統計を有効にすると次のようなプランが表示されます。
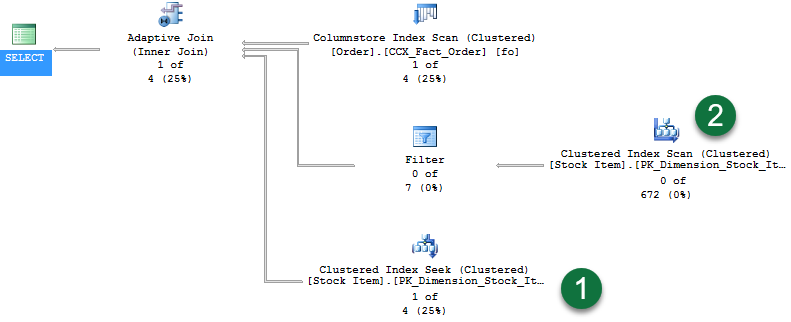
このプランでは、次のことがわかります。
- 返されるのが 1 行なので、クラスター化インデックス シークを行が通過します。
- また、ハッシュ結合ビルド フェーズは続行しなかったので、2 番目の分岐を通る行はありません。
アダプティブ結合の注釈
アダプティブ結合では、同等のインデックスが入れ子になったループ結合プランより多くのメモリが必要です。 追加のメモリは、入れ子になったループがハッシュ結合であるかのように要求されます。 ストップ アンド ゴー操作と、同等の入れ子になったループ ストリーミング結合の違いのため、ビルド フェーズにもオーバーヘッドがあります。 その追加コストにより、ビルド入力で行数が変動するシナリオに対して柔軟性があります。
バッチ モード アダプティブ結合は、ステートメントの最初の実行に対して作用し、コンパイル後は、コンパイルされたアダプティブ結合しきい値と、外部入力のビルド フェーズを通過するランタイム行に基づいて、連続する実行がアダプティブのままになります。
アダプティブ結合は、入れ子になったループ操作に切り替えた場合、ハッシュ結合ビルドによって既に読み取られた行を使います。 演算子が外部参照行をもう一度読み込むことは "ありません"。
アダプティブ結合アクティビティのトラック
アダプティブ結合演算子には次のプラン演算子属性があります。
| プラン属性 | 説明 |
|---|---|
| AdaptiveThresholdRows | ハッシュ結合から入れ子になったループ結合への切り替えに使われるしきい値を示します。 |
| EstimatedJoinType | 予想される結合の種類を示します。 |
| ActualJoinType | 実際のプランで、しきい値に基づいて最終的に選ばれた結合アルゴリズムを示します。 |
予想されるプランは、アダプティブ結合プランの概要と、定義されているアダプティブ結合しきい値および予想される結合の種類を示します。
ヒント
クエリ ストアは、バッチ モード アダプティブ結合プランをキャプチャし、強制できます。
アダプティブ結合を使えるステートメント
論理結合をバッチ モード アダプティブ結合で使うにはいくつかの条件があります。
- データベース互換性レベルが 140 以上である。
- クエリが
SELECTステートメントである (現在、データ変更ステートメントは使えません)。 - 結合が、インデックス付きのネステッド ループ結合またはハッシュ結合の両方の物理アルゴリズムで実行できる。
- クエリ全体に列ストア インデックスが存在すること、列ストア インデックス テーブルを結合で直接参照すること、または行ストアでバッチ モードを使用することにより、有効化されたバッチ モードをハッシュ結合が使っている。
- ネステッド ループ結合とハッシュ結合の生成された代替ソリューションが、同じ最初の子 (外部参照) を持っている。
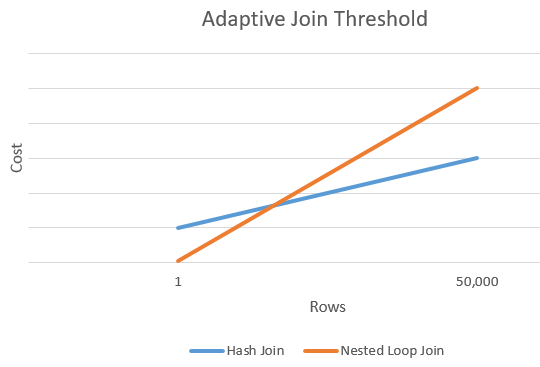
アダプティブしきい値行
次のグラフは、ハッシュ結合のコストとネステッド ループ結合のコストの交点の例を示します。 この交点で、しきい値が決定され、それによって結合操作に実際に使われるアルゴリズムが決まります。
互換性レベルを変更せず、アダプティブ結合を無効にする
アダプティブ結合は、データベース互換レベル 140 以上を維持しながら、データベースまたはステートメント範囲で無効にできます。
データベースを発生源とするすべてのクエリ実行に対してアダプティブ結合を無効にするには、該当するデータベースとの関連で次を実行します。
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = ON;
-- Azure SQL Database, SQL Server 2019 and later versions
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = OFF;
有効になっているとき、この設定は sys.database_scoped_configurations で有効として表示されます。
データベースを発生源とするすべてのクエリ実行に対して適応型結合を再有効化するには、該当するデータベースとの関連で次を実行します。
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = OFF;
-- Azure SQL Database, SQL Server 2019 and later versions
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = ON;
DISABLE_BATCH_MODE_ADAPTIVE_JOINSUSE HINT クエリ ヒントとして を指定することで、特定のクエリでアダプティブ結合を無効にすることもできます。 次に例を示します。
SELECT s.CustomerID,
s.CustomerName,
sc.CustomerCategoryName
FROM Sales.Customers AS s
LEFT OUTER JOIN Sales.CustomerCategories AS sc
ON s.CustomerCategoryID = sc.CustomerCategoryID
OPTION (USE HINT('DISABLE_BATCH_MODE_ADAPTIVE_JOINS'));
Note
USE HINT クエリ ヒントは、 データベース スコープ構成 またはトレース フラグ設定に優先します。
NULL 値と結合
結合されるテーブルの列に NULL 値がある場合、双方の NULL 値が互いに一致することはありません。 結合されるいずれかのテーブルの列に複数の NULL 値がある場合にそれを返すのは、外部結合を使用した場合だけです。ただし WHERE 句によって NULL 値が除外される場合を除きます。
次に 2 つのテーブルを示しています。どちらのテーブルでも、結合に使われる列に NULL 値が含まれています。
table1 table2
a b c d
------- ------ ------- ------
1 one NULL two
NULL three 4 four
4 join4
列の値と列 a の値を比較する結合の場合、NULL の値を含む列 c は一致しません。
SELECT *
FROM table1 t1 JOIN table2 t2
ON t1.a = t2.c
ORDER BY t1.a;
GO
列 4 と列 a で返されるのは、値が c の行 1 つだけです。
a b c d
----------- ------ ----------- ------
4 join4 4 four
(1 row(s) affected)
ベース テーブルから返される NULL 値と外部結合から返される NULL 値を区別することは困難です。 たとえば、次の SELECT ステートメントは、2 つのテーブルの左外部結合を行います。
SELECT *
FROM table1 t1 LEFT OUTER JOIN table2 t2
ON t1.a = t2.c
ORDER BY t1.a;
GO
結果セットは次のようになります。
a b c d
----------- ------ ----------- ------
NULL three NULL NULL
1 one NULL NULL
4 join4 4 four
(3 row(s) affected)
この結果では、データ内の NULL を、結合の失敗を表す NULL と区別するのが簡単ではありません。 結合されるデータ内に NULL 値がある場合、通常は、普通の結合を使ってこれらの NULL 値を結果から除外することをおすすめします。
次のステップ
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示