注
現在、この機能はパブリック プレビュー段階にあります。 このプレビュー版はサービス レベル アグリーメントなしで提供されています。運用環境のワークロードに使用することはお勧めできません。 特定の機能はサポート対象ではなく、機能が制限されることがあります。 詳細については、「 Microsoft Azure プレビューの追加使用条件」を参照してください。
この記事では、 Azure AI Foundry ポータルで生成 AI と Azure AI Speech で音声ライブを使用する方法について説明します。
[前提条件]
- Azure サブスクリプション。 無料で作成できます。
- Python 3.8 以降のバージョン。 Python 3.10 以降を使用することをお勧めしますが、少なくとも Python 3.8 が必要です。 適切なバージョンの Python がインストールされていない場合は、オペレーティング システムへの Python のインストールの最も簡単な方法として、VS Code Python チュートリアルの手順に従うことができます。
- サポートされているリージョンのいずれかで作成された Azure AI Foundry リソース 。 リージョンの可用性の詳細については、 Voice Live API の概要に関するドキュメントを参照してください。
ヒント
Voice Live API を使用するには、Azure AI Foundry リソースを使用してオーディオ モデルをデプロイする必要はありません。 Voice Live API はフル マネージドであり、モデルは自動的にデプロイされます。 モデルの可用性の詳細については、 Voice Live API の概要に関するドキュメントを参照してください。
音声遊び場で音声をライブで試す
音声ライブ デモを試すには、次の手順に従います。
Azure AI Foundry でプロジェクトに移動します。
左側のウィンドウから [プレイグラウンド ] を選択します。
[ Speech playground ] タイルで、[ Try the Speech playground]\(音声プレイグラウンドを試す\) を選択します。
シナリオ別に音声機能を選択します>ボイス ライブ。
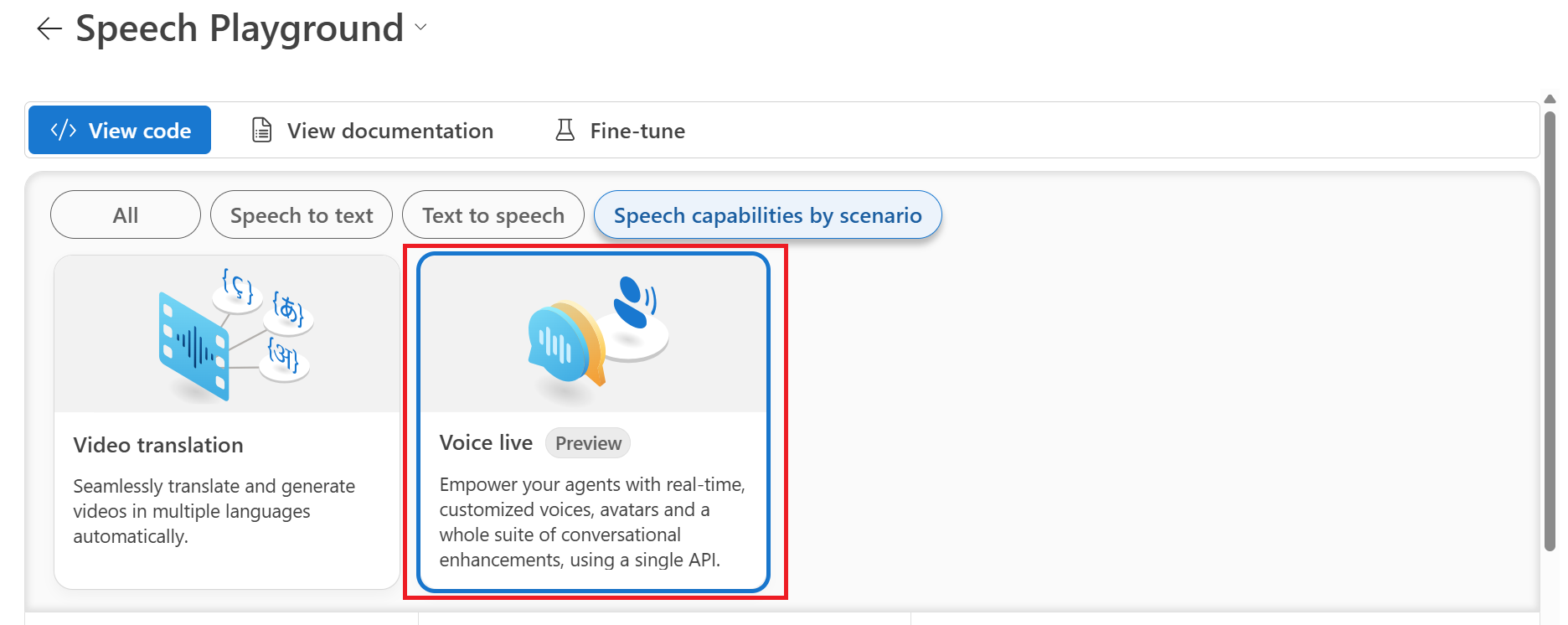
カジュアル チャットなどのサンプル シナリオを選択します。
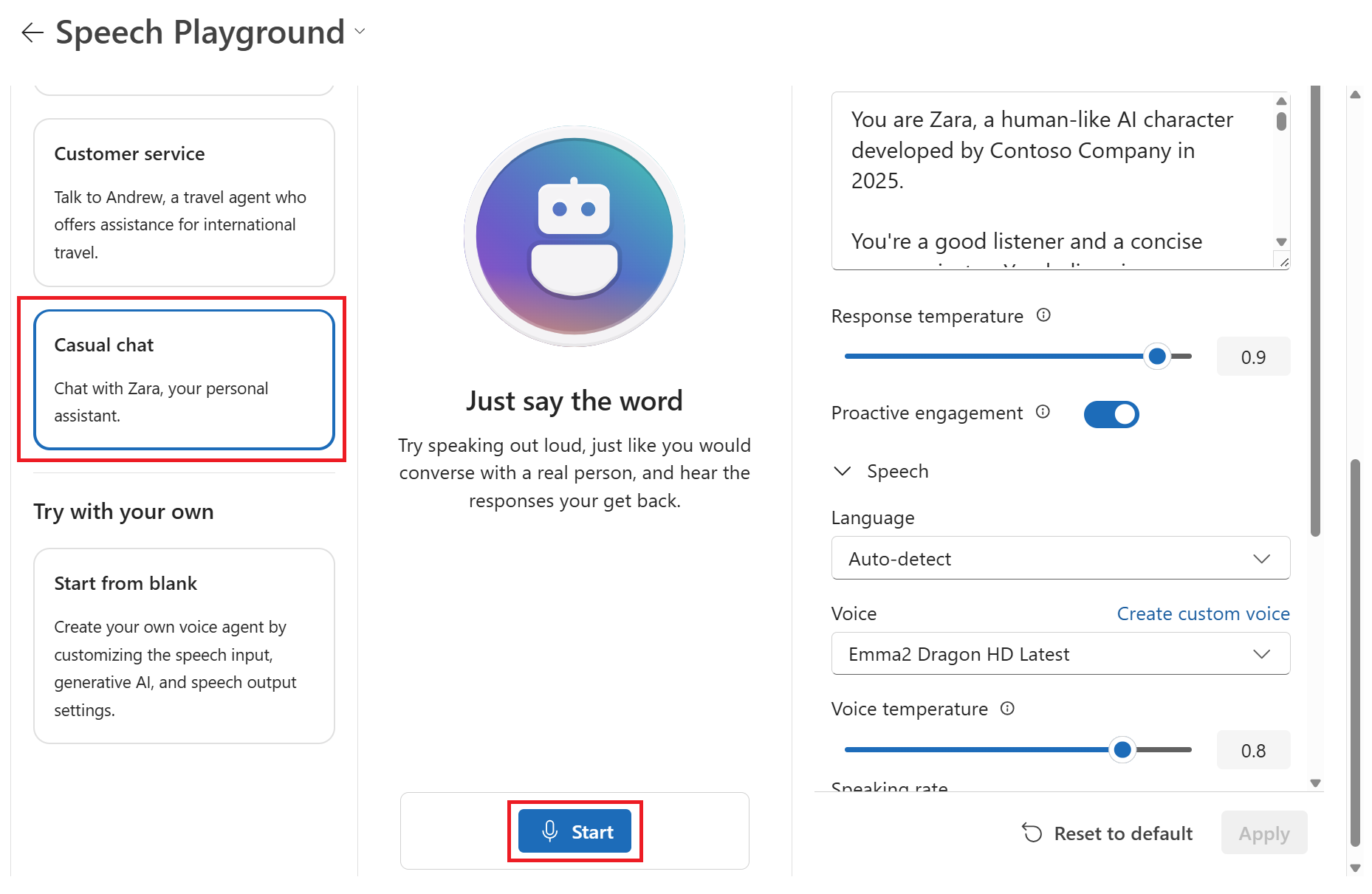
[ 開始] を選択してチャット エージェントとのチャットを開始します。
[ 終了] を選択してチャット セッションを終了します。
Configuration>GenAI>Generative AI モデルを使用して、ドロップダウン リストから新しい生成 AI モデルを選択します。
注
エージェント プレイグラウンドで構成したエージェントを選択することもできます。
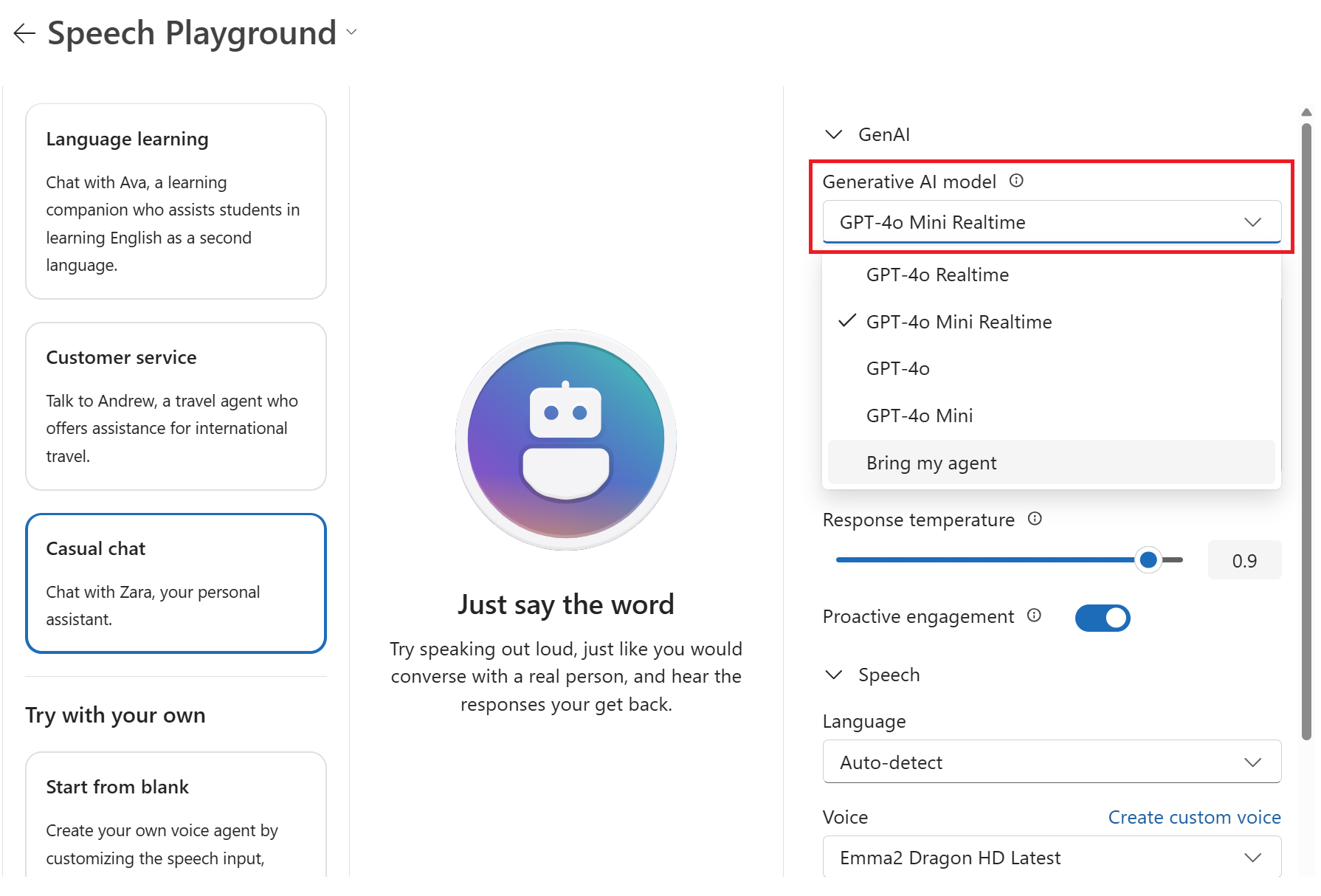
必要に応じて、 応答の指示、 音声、 読み上げ速度などの他の設定を編集します。
[ 開始] を選択してもう一度話し始め、[ 終了 ] を選択してチャット セッションを終了します。



[前提条件]
- Azure サブスクリプション。 無料で作成できます。
- Python 3.8 以降のバージョン。 Python 3.10 以降を使用することをお勧めしますが、少なくとも Python 3.8 が必要です。 適切なバージョンの Python がインストールされていない場合は、オペレーティング システムへの Python のインストールの最も簡単な方法として、VS Code Python チュートリアルの手順に従うことができます。
- サポートされているリージョンのいずれかで作成された Azure AI Foundry リソース 。 リージョンの可用性の詳細については、 Voice Live API の概要に関するドキュメントを参照してください。
ヒント
Voice Live API を使用するには、Azure AI Foundry リソースを使用してオーディオ モデルをデプロイする必要はありません。 Voice Live API はフル マネージドであり、モデルは自動的にデプロイされます。 モデルの可用性の詳細については、 Voice Live API の概要に関するドキュメントを参照してください。
Microsoft Entra ID の前提条件
Microsoft Entra ID で推奨されるキーレス認証の場合、次のことを行う必要があります。
- Microsoft Entra ID でのキーレス認証に使われる Azure CLI をインストールします。
- ユーザー アカウントに
Cognitive Services Userロールを割り当てます。 Azure portal の [アクセス制御 (IAM)]>[ロールの割り当ての追加] で、ロールを割り当てることができます。
セットアップ
voice-live-quickstart新しいフォルダーを作成し、次のコマンドを使用してクイック スタート フォルダーに移動します。mkdir voice-live-quickstart && cd voice-live-quickstart仮想環境を作成します。 Python 3.10 以降が既にインストールされている場合は、次のコマンドを使用して仮想環境を作成できます:
Python 環境をアクティブ化するということは、コマンド ラインから
pythonまたはpipを実行する際に、アプリケーションの.venvフォルダーに含まれている Python インタープリターを使用するということを意味します。deactivateコマンドを使用して Python 仮想環境を終了し、必要に応じて、それを後で再アクティブ化できます。ヒント
新しい Python 環境を作成してアクティブにし、このチュートリアルに必要なパッケージのインストールに使うことをお勧めします。 グローバルな Python インストールにパッケージをインストールしないでください。 Python パッケージをインストールするときは、常に仮想または Conda 環境を使う必要があります。そうしないと、Python のグローバル インストールが損なわれる可能性があります。
requirements.txtという名前のファイルを作成 します 。 次のパッケージをこのファイルに追加します。
aiohttp==3.11.18 azure-core==1.34.0 azure-identity==1.22.0 certifi==2025.4.26 cffi==1.17.1 cryptography==44.0.3 numpy==2.2.5 pycparser==2.22 python-dotenv==1.1.0 requests==2.32.3 sounddevice==0.5.1 typing_extensions==4.13.2 urllib3==2.4.0 websockets==15.0.1パッケージをインストールします。
pip install -r requirements.txtMicrosoft Entra ID で推奨されるキーレス認証の場合、次を使って
azure-identityパッケージをインストールします。pip install azure-identity
リソース情報の取得
Azure AI Foundry リソースでアプリケーションを認証するには、次の情報を取得する必要があります。
| 変数名 | 価値 |
|---|---|
AZURE_VOICE_LIVE_ENDPOINT |
この値は、Azure portal からリソースを調べる際の キーとエンドポイント セクションにあります。 |
VOICE_LIVE_MODEL |
使用するモデル。 たとえば、gpt-4o または gpt-4o-mini-realtime-preview です。 モデルの可用性の詳細については、 Voice Live API の概要に関するドキュメントを参照してください。 |
AZURE_VOICE_LIVE_API_VERSION |
使用する API バージョン。 たとえば、2025-05-01-preview のようにします。 |
会話の開始
次のコードを使用して
voice-live-quickstart.pyファイルを作成します。from __future__ import annotations import os import uuid import json import asyncio import base64 import logging import threading import numpy as np import sounddevice as sd from collections import deque from dotenv import load_dotenv from azure.identity import DefaultAzureCredential from azure.core.credentials_async import AsyncTokenCredential from azure.identity.aio import DefaultAzureCredential, get_bearer_token_provider from typing import Dict, Union, Literal, Set from typing_extensions import AsyncIterator, TypedDict, Required from websockets.asyncio.client import connect as ws_connect from websockets.asyncio.client import ClientConnection as AsyncWebsocket from websockets.asyncio.client import HeadersLike from websockets.typing import Data from websockets.exceptions import WebSocketException # This is the main function to run the Voice Live API client. async def main() -> None: # Set environment variables or edit the corresponding values here. endpoint = os.environ.get("AZURE_VOICE_LIVE_ENDPOINT") or "https://your-endpoint.azure.com/" model = os.environ.get("VOICE_LIVE_MODEL") or "gpt-4o" api_version = os.environ.get("AZURE_VOICE_LIVE_API_VERSION") or "2025-05-01-preview" api_key = os.environ.get("AZURE_VOICE_LIVE_API_KEY") or "your_api_key" # For the recommended keyless authentication, get and # use the Microsoft Entra token instead of api_key: scopes = "https://cognitiveservices.azure.com/.default" credential = DefaultAzureCredential() token = await credential.get_token(scopes) client = AsyncAzureVoiceLive( azure_endpoint = endpoint, api_version = api_version, token = token.token, #api_key = api_key, ) async with client.connect(model = model) as connection: session_update = { "type": "session.update", "session": { "instructions": "You are a helpful AI assistant responding in natural, engaging language.", "turn_detection": { "type": "azure_semantic_vad", "threshold": 0.3, "prefix_padding_ms": 200, "silence_duration_ms": 200, "remove_filler_words": False, "end_of_utterance_detection": { "model": "semantic_detection_v1", "threshold": 0.01, "timeout": 2, }, }, "input_audio_noise_reduction": { "type": "azure_deep_noise_suppression" }, "input_audio_echo_cancellation": { "type": "server_echo_cancellation" }, "voice": { "name": "en-US-Ava:DragonHDLatestNeural", "type": "azure-standard", "temperature": 0.8, }, }, "event_id": "" } await connection.send(json.dumps(session_update)) print("Session created: ", json.dumps(session_update)) send_task = asyncio.create_task(listen_and_send_audio(connection)) receive_task = asyncio.create_task(receive_audio_and_playback(connection)) keyboard_task = asyncio.create_task(read_keyboard_and_quit()) print("Starting the chat ...") await asyncio.wait([send_task, receive_task, keyboard_task], return_when=asyncio.FIRST_COMPLETED) send_task.cancel() receive_task.cancel() print("Chat done.") # --- End of Main Function --- logger = logging.getLogger(__name__) AUDIO_SAMPLE_RATE = 24000 class AsyncVoiceLiveConnection: _connection: AsyncWebsocket def __init__(self, url: str, additional_headers: HeadersLike) -> None: self._url = url self._additional_headers = additional_headers self._connection = None async def __aenter__(self) -> AsyncVoiceLiveConnection: try: self._connection = await ws_connect(self._url, additional_headers=self._additional_headers) except WebSocketException as e: raise ValueError(f"Failed to establish a WebSocket connection: {e}") return self async def __aexit__(self, exc_type, exc_value, traceback) -> None: if self._connection: await self._connection.close() self._connection = None enter = __aenter__ close = __aexit__ async def __aiter__(self) -> AsyncIterator[Data]: async for data in self._connection: yield data async def recv(self) -> Data: return await self._connection.recv() async def recv_bytes(self) -> bytes: return await self._connection.recv() async def send(self, message: Data) -> None: await self._connection.send(message) class AsyncAzureVoiceLive: def __init__( self, *, azure_endpoint: str | None = None, api_version: str | None = None, token: str | None = None, api_key: str | None = None, ) -> None: self._azure_endpoint = azure_endpoint self._api_version = api_version self._token = token self._api_key = api_key self._connection = None def connect(self, model: str) -> AsyncVoiceLiveConnection: if self._connection is not None: raise ValueError("Already connected to the Voice Live API.") if not model: raise ValueError("Model name is required.") url = f"{self._azure_endpoint.rstrip('/')}/voice-live/realtime?api-version={self._api_version}&model={model}" url = url.replace("https://", "wss://") auth_header = {"Authorization": f"Bearer {self._token}"} if self._token else {"api-key": self._api_key} request_id = uuid.uuid4() headers = {"x-ms-client-request-id": str(request_id), **auth_header} self._connection = AsyncVoiceLiveConnection( url, additional_headers=headers, ) return self._connection class AudioPlayerAsync: def __init__(self): self.queue = deque() self.lock = threading.Lock() self.stream = sd.OutputStream( callback=self.callback, samplerate=AUDIO_SAMPLE_RATE, channels=1, dtype=np.int16, blocksize=2400, ) self.playing = False def callback(self, outdata, frames, time, status): if status: logger.warning(f"Stream status: {status}") with self.lock: data = np.empty(0, dtype=np.int16) while len(data) < frames and len(self.queue) > 0: item = self.queue.popleft() frames_needed = frames - len(data) data = np.concatenate((data, item[:frames_needed])) if len(item) > frames_needed: self.queue.appendleft(item[frames_needed:]) if len(data) < frames: data = np.concatenate((data, np.zeros(frames - len(data), dtype=np.int16))) outdata[:] = data.reshape(-1, 1) def add_data(self, data: bytes): with self.lock: np_data = np.frombuffer(data, dtype=np.int16) self.queue.append(np_data) if not self.playing and len(self.queue) > 10: self.start() def start(self): if not self.playing: self.playing = True self.stream.start() def stop(self): with self.lock: self.queue.clear() self.playing = False self.stream.stop() def terminate(self): with self.lock: self.queue.clear() self.stream.stop() self.stream.close() async def listen_and_send_audio(connection: AsyncVoiceLiveConnection) -> None: logger.info("Starting audio stream ...") stream = sd.InputStream(channels=1, samplerate=AUDIO_SAMPLE_RATE, dtype="int16") try: stream.start() read_size = int(AUDIO_SAMPLE_RATE * 0.02) while True: if stream.read_available >= read_size: data, _ = stream.read(read_size) audio = base64.b64encode(data).decode("utf-8") param = {"type": "input_audio_buffer.append", "audio": audio, "event_id": ""} data_json = json.dumps(param) await connection.send(data_json) except Exception as e: logger.error(f"Audio stream interrupted. {e}") finally: stream.stop() stream.close() logger.info("Audio stream closed.") async def receive_audio_and_playback(connection: AsyncVoiceLiveConnection) -> None: last_audio_item_id = None audio_player = AudioPlayerAsync() logger.info("Starting audio playback ...") try: while True: async for raw_event in connection: event = json.loads(raw_event) print(f"Received event:", {event.get("type")}) if event.get("type") == "session.created": session = event.get("session") logger.info(f"Session created: {session.get('id')}") elif event.get("type") == "response.audio.delta": if event.get("item_id") != last_audio_item_id: last_audio_item_id = event.get("item_id") bytes_data = base64.b64decode(event.get("delta", "")) audio_player.add_data(bytes_data) elif event.get("type") == "error": error_details = event.get("error", {}) error_type = error_details.get("type", "Unknown") error_code = error_details.get("code", "Unknown") error_message = error_details.get("message", "No message provided") raise ValueError(f"Error received: Type={error_type}, Code={error_code}, Message={error_message}") except Exception as e: logger.error(f"Error in audio playback: {e}") finally: audio_player.terminate() logger.info("Playback done.") async def read_keyboard_and_quit() -> None: print("Press 'q' and Enter to quit the chat.") while True: # Run input() in a thread to avoid blocking the event loop user_input = await asyncio.to_thread(input) if user_input.strip().lower() == 'q': print("Quitting the chat...") break if __name__ == "__main__": try: logging.basicConfig( filename='voicelive.log', filemode="w", level=logging.DEBUG, format='%(asctime)s:%(name)s:%(levelname)s:%(message)s' ) load_dotenv() asyncio.run(main()) except Exception as e: print(f"Error: {e}")次のコマンドを使用して Azure にサインインします。
az loginPython ファイルを実行します。
python voice-live-quickstart.pyVoice Live API は、モデルの最初の応答でオーディオの返しを開始します。 話すことでモデルを中断できます。 「q」と入力して会話を終了します。
アウトプット
スクリプトの出力がコンソールに出力されます。 接続、オーディオ ストリーム、再生の状態を示すメッセージが表示されます。 オーディオは、スピーカーまたはヘッドフォンを介して再生されます。
Session created: {"type": "session.update", "session": {"instructions": "You are a helpful AI assistant responding in natural, engaging language.","turn_detection": {"type": "azure_semantic_vad", "threshold": 0.3, "prefix_padding_ms": 200, "silence_duration_ms": 200, "remove_filler_words": false, "end_of_utterance_detection": {"model": "semantic_detection_v1", "threshold": 0.1, "timeout": 4}}, "input_audio_noise_reduction": {"type": "azure_deep_noise_suppression"}, "input_audio_echo_cancellation": {"type": "server_echo_cancellation"}, "voice": {"name": "en-US-Ava:DragonHDLatestNeural", "type": "azure-standard", "temperature": 0.8}}, "event_id": ""}
Starting the chat ...
Received event: {'session.created'}
Press 'q' and Enter to quit the chat.
Received event: {'session.updated'}
Received event: {'input_audio_buffer.speech_started'}
Received event: {'input_audio_buffer.speech_stopped'}
Received event: {'input_audio_buffer.committed'}
Received event: {'conversation.item.input_audio_transcription.completed'}
Received event: {'conversation.item.created'}
Received event: {'response.created'}
Received event: {'response.output_item.added'}
Received event: {'conversation.item.created'}
Received event: {'response.content_part.added'}
Received event: {'response.audio_transcript.delta'}
Received event: {'response.audio_transcript.delta'}
Received event: {'response.audio_transcript.delta'}
REDACTED FOR BREVITY
Received event: {'response.audio.delta'}
Received event: {'response.audio.delta'}
Received event: {'response.audio.delta'}
q
Received event: {'response.audio.delta'}
Received event: {'response.audio.delta'}
Received event: {'response.audio.delta'}
Received event: {'response.audio.delta'}
Received event: {'response.audio.delta'}
Quitting the chat...
Received event: {'response.audio.delta'}
Received event: {'response.audio.delta'}
REDACTED FOR BREVITY
Received event: {'response.audio.delta'}
Received event: {'response.audio.delta'}
Chat done.
実行したスクリプトによって、スクリプトと同じディレクトリに voicelive.log という名前のログ ファイルが作成されます。
logging.basicConfig(
filename='voicelive.log',
filemode="w",
level=logging.DEBUG,
format='%(asctime)s:%(name)s:%(levelname)s:%(message)s'
)
ログ ファイルには、要求データや応答データなど、Voice Live API への接続に関する情報が含まれています。 ログ ファイルを表示して、会話の詳細を確認できます。
2025-05-09 06:56:06,821:websockets.client:DEBUG:= connection is CONNECTING
2025-05-09 06:56:07,101:websockets.client:DEBUG:> GET /voice-live/realtime?api-version=2025-05-01-preview&model=gpt-4o HTTP/1.1
<REDACTED FOR BREVITY>
2025-05-09 06:56:07,551:websockets.client:DEBUG:= connection is OPEN
2025-05-09 06:56:07,551:websockets.client:DEBUG:< TEXT '{"event_id":"event_5a7NVdtNBVX9JZVuPc9nYK","typ...es":null,"agent":null}}' [1475 bytes]
2025-05-09 06:56:07,552:websockets.client:DEBUG:> TEXT '{"type": "session.update", "session": {"turn_de....8}}, "event_id": null}' [551 bytes]
2025-05-09 06:56:07,557:__main__:INFO:Starting audio stream ...
2025-05-09 06:56:07,810:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAEA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,824:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,844:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,874:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,874:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAEA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,905:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...BAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,926:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,954:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,954:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...///7/", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,974:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...BAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:08,004:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:08,035:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:08,035:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
<REDACTED FOR BREVITY>
2025-05-09 06:56:42,957:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAP//", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:42,984:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...+/wAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,005:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": .../////", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,034:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...+////", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,034:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...CAAMA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,055:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...CAAIA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,084:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...BAAEA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,114:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...9//3/", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,114:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...DAAMA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,134:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...BAAIA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,165:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,184:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...+//7/", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,214:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": .../////", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,214:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...+/wAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,245:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...BAAIA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,264:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAP//", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,295:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...BAAEA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,295:websockets.client:DEBUG:> CLOSE 1000 (OK) [2 bytes]
2025-05-09 06:56:43,297:websockets.client:DEBUG:= connection is CLOSING
2025-05-09 06:56:43,346:__main__:INFO:Audio stream closed.
2025-05-09 06:56:43,388:__main__:INFO:Playback done.
2025-05-09 06:56:44,512:websockets.client:DEBUG:< CLOSE 1000 (OK) [2 bytes]
2025-05-09 06:56:44,514:websockets.client:DEBUG:< EOF
2025-05-09 06:56:44,514:websockets.client:DEBUG:> EOF
2025-05-09 06:56:44,514:websockets.client:DEBUG:= connection is CLOSED
2025-05-09 06:56:44,514:websockets.client:DEBUG:x closing TCP connection
2025-05-09 06:56:44,514:asyncio:ERROR:Unclosed client session
client_session: <aiohttp.client.ClientSession object at 0x00000266DD8E5400>