カスタム抽出モデルを構築してトレーニングする
このコンテンツの適用対象: ![]() v4.0 (プレビュー) | 以前のバージョン:
v4.0 (プレビュー) | 以前のバージョン: ![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1
v2.1
Document Intelligence モデルの使用を開始するのに必要なトレーニング ドキュメントはわずか 5 つです。 少なくとも 5 つのドキュメントがある場合には、カスタム モデルのトレーニングを開始できます。 カスタム テンプレート モデル (カスタム フォーム) またはカスタム ニューラル モデル(カスタム ドキュメント) のいずれかをトレーニングできます。 トレーニング プロセスは両方のモデルで同じです。このドキュメントでは、いずれかのモデルをトレーニングするプロセスについて説明します。
カスタム モデルの入力要件
まず、トレーニング データ セットが Document Intelligence の入力の要件に従っていることを確認します。
最適な結果を得るには、ドキュメントごとに 1 つの鮮明な写真または高品質のスキャンを提供してください。
サポートされているファイル形式:
モデル PDF 画像:
JPEG/JPG、PNG、BMP、TIFF、HEIFMicrosoft Office:
Word (DOCX)、Excel (XLS)、PowerPoint (PPT)、HTML既読 ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-02-29-preview、2023-10-31-preview) 一般的なドキュメント ✔ ✔ 事前構築済み ✔ ✔ カスタム抽出 ✔ ✔ カスタム分類 ✔ ✔ ✔ (2024-02-29-preview) PDF および TIFF の場合、最大 2000 ページを処理できます (Free レベルのサブスクリプションでは、最初の 2 ページのみが処理されます)。
ドキュメントを分析するためのファイル サイズは、有料 (S0) レベルでは 500 MB、無料 (F0) レベルでは 4 MB です。
画像のディメンションは、50 x 50 ピクセルから 10,000 x 10,000 ピクセルの間である必要があります。
PDF がパスワードでロックされている場合は、送信前にロックを解除する必要があります。
抽出するテキストの最小の高さは、1024 x 768 ピクセルのイメージの場合は 12 ピクセルです。 このディメンションは、150 DPI (1 インチあたりのドット数) で約
8ポイントのテキストに相当します。カスタム モデル トレーニングにおけるトレーニング データの最大ページ数は、カスタム テンプレート モデルの場合は 500、カスタム ニューラル モデルの場合は 50,000 です。
カスタム抽出モデル トレーニングにおけるトレーニング データの合計サイズは、テンプレート モデルの場合は 50 MB、ニューラル モデルの場合は 1GB です。
カスタム分類モデル トレーニングの場合、トレーニング データの合計サイズは
1GBで、最大 10,000 ページです。
トレーニング データのヒント
次のヒントを使って、トレーニングのためにデータ セットをさらに最適化してください。
- 画像ベースのドキュメントではなく、テキストベースの PDF ドキュメントを使用します。 スキャンした PDF は画像として扱われます。
- 入力フィールドを含むフォームの場合は、すべてのフィールドが入力された例を使用します。
- 各フィールドに異なる値が含まれたフォームを使用します。
- フォームの画像の品質が低い場合は、より大きなデータ セット (たとえば 10 から 15 の画像) を使用します。
トレーニング データをアップロードする
トレーニングに使用するフォームまたはドキュメントのセットを収集したら、それを Azure BLOB ストレージ コンテナーにアップロードする必要があります。 コンテナーを含む Azure Storage アカウントを作成する方法がわからない場合は、Azure portal の Azure Storage に関するクイックスタートに従ってください。 Free 価格レベル (F0) を使用してサービスを試用し、後から運用環境用の有料レベルにアップグレードすることができます。
動画: カスタム モデルをトレーニングする
- トレーニング データセットを収集してアップロードすると、カスタム モデルをトレーニングする準備ができます。 次の動画では、プロジェクトを作成し、モデルのラベル付けとトレーニングを成功させるための基礎をいくつか確認します。
Document Intelligence Studio でプロジェクトを作成する
Document Intelligence Studio を使用すると、データセットの完成とモデルのトレーニングに必要なすべての API 呼び出しを利用し、調整することができます。
まず、Document Intelligence Studio に移動します。 Studio を初めて使用するときは、サブスクリプション、リソース グループ、リソースを初期化する必要があります。 次に、カスタム プロジェクトの前提条件に従って、トレーニング データセットにアクセスする Studio を構成します。
Studio で [カスタム モデル] タイルを選択し、カスタム モデル ページで [プロジェクトの作成] ボタンを選択します。

[プロジェクトの作成] ダイアログで、プロジェクトの名前と必要に応じて説明を入力し、[続行] を選択します。
ワークフローの次の手順で、[続行] を選択する前に Document Intelligence リソースを選択または作成します。
重要
カスタム ニューラル モデルは、いくつかのリージョンでのみ使用できます。 ニューラル モデルのトレーニングを計画している場合は、これらのサポートされているリージョンの 1 つでリソースを選択または作成してください。
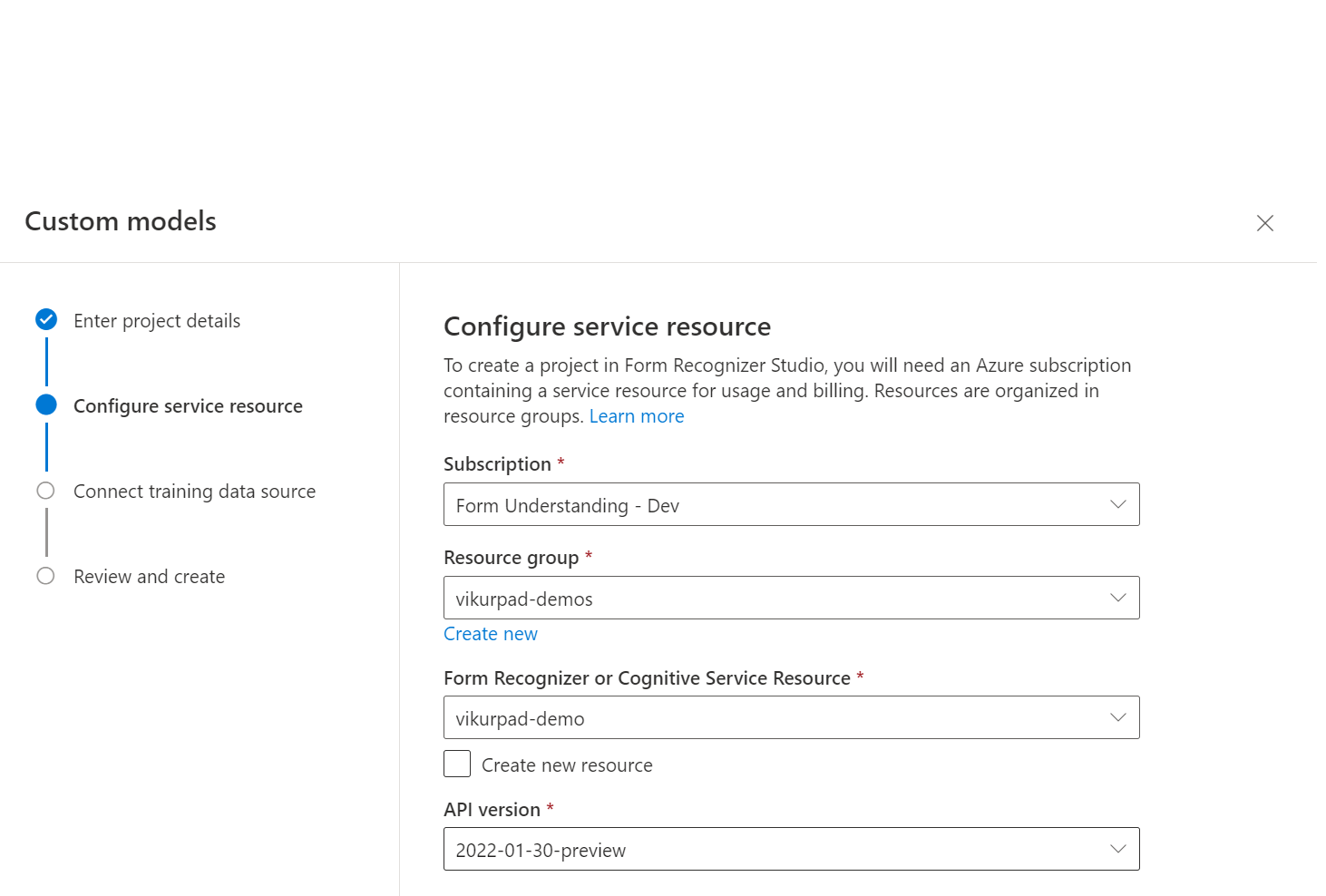
次に、カスタム モデルのトレーニング データセットをアップロードするために使用したストレージ アカウントを選択します。 トレーニング ドキュメントがコンテナーのルートにある場合は、フォルダー パスが空である必要があります。 ドキュメントがサブフォルダーにある場合は、[フォルダー パス] フィールドにコンテナー ルートからの相対パスを入力します。 ストレージ アカウントが構成された後、[続行] を選択します。
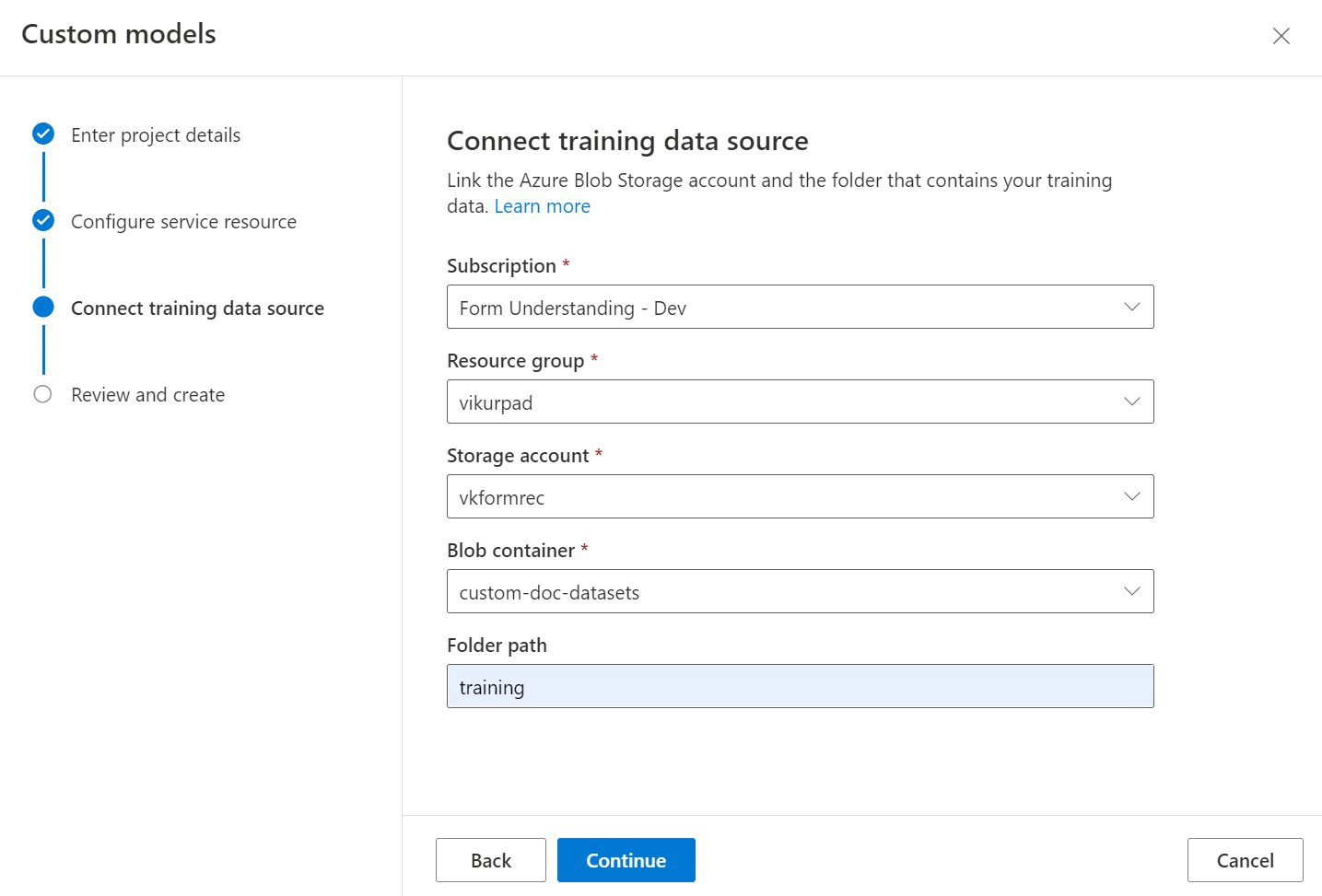
最後に、プロジェクトの設定を確認し、[プロジェクトの作成] を選択して新しいプロジェクトを作成します。 これで、ラベル付けウィンドウに表示され、データセット内のファイルが一覧表示されます。
データにラベルを付ける
プロジェクトでの最初のタスクは、抽出するフィールドをデータセットにラベル付けします。
ストレージにアップロードしたファイルが画面の左側に一覧表示され、最初のファイルにラベルを付ける準備が整っています。
画面の右上にあるプラス (➕) ボタンを選択して、データセットのラベル付けと最初のフィールドの作成を開始します。
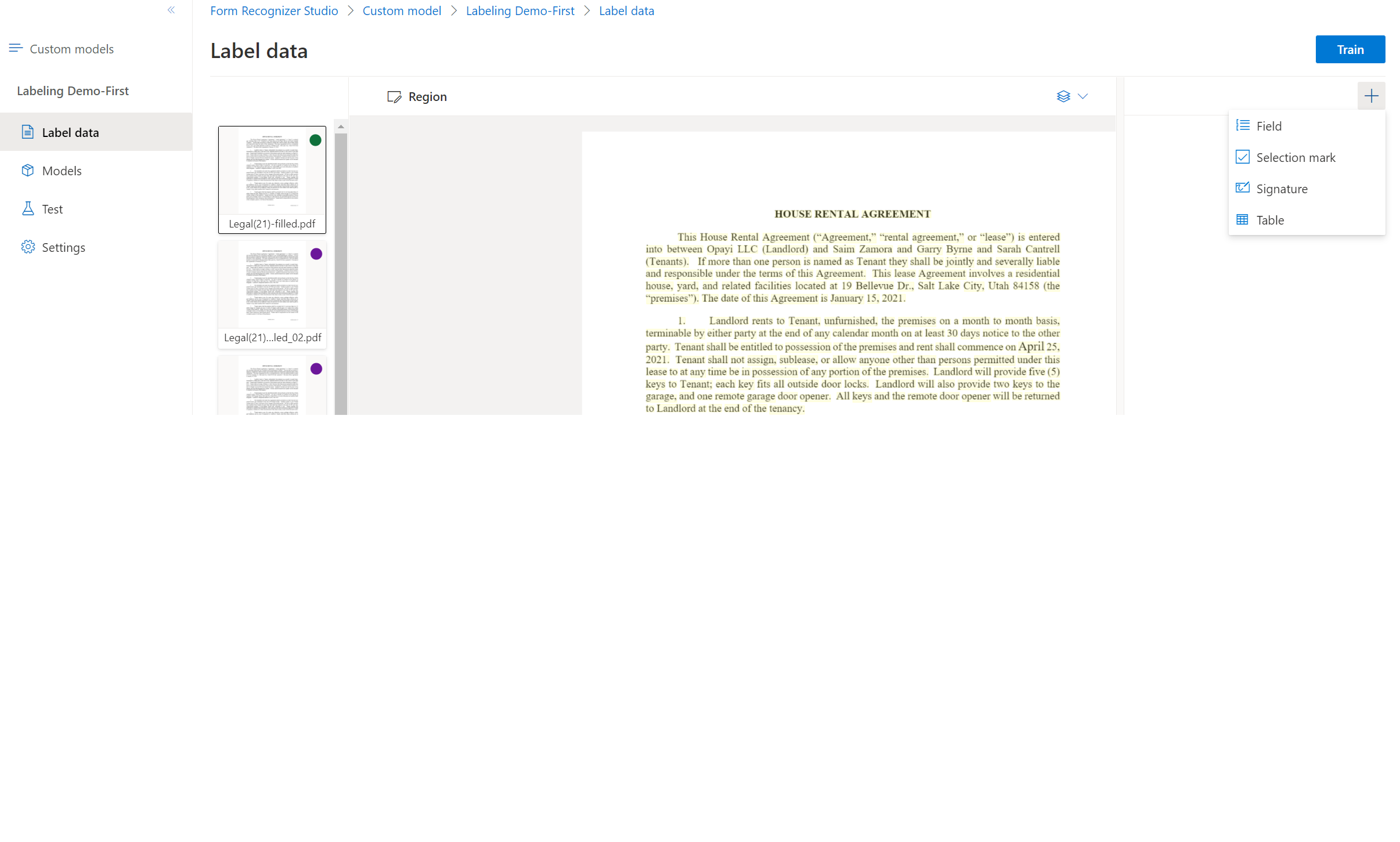
グループの名前を入力します。
ドキュメント内の単語を 1 つまたは複数選んで、フィールドに値を割り当てます。 ドロップダウンまたは右側のナビゲーション バーのフィールド リストでフィールドを選択します。 ラベル付けされた値は、フィールドの一覧の中のフィールド名の下に表示されます。
データセットにラベルを付けたいすべてのフィールドに対して、このプロセスを繰り返します。
各ドキュメントを選択し、ラベル付けするテキストを選択して、データセット内の残りのドキュメントにラベルを付けます。
これで、データセット内のすべてのドキュメントにラベルが付けられました。 .labels.json ファイルと .ocr.json ファイルはトレーニング データセット内の各ドキュメントと新しい fields.json ファイルに対応します。 このトレーニング データセットは、モデルをトレーニングするために送信されます。
モデルをトレーニングする
データセットにラベルが付いたので、モデルをトレーニングする準備が整いました。 右上隅にある [ツール] を選択します。
[モデルのトレーニング] ダイアログで、一意のモデル ID と、必要に応じて説明を指定します。 モデル ID は文字列データ型を受け取ります。
ビルド モードでは、トレーニングするモデルの種類を選択します。 モデルの種類と機能の詳細を確認してください。
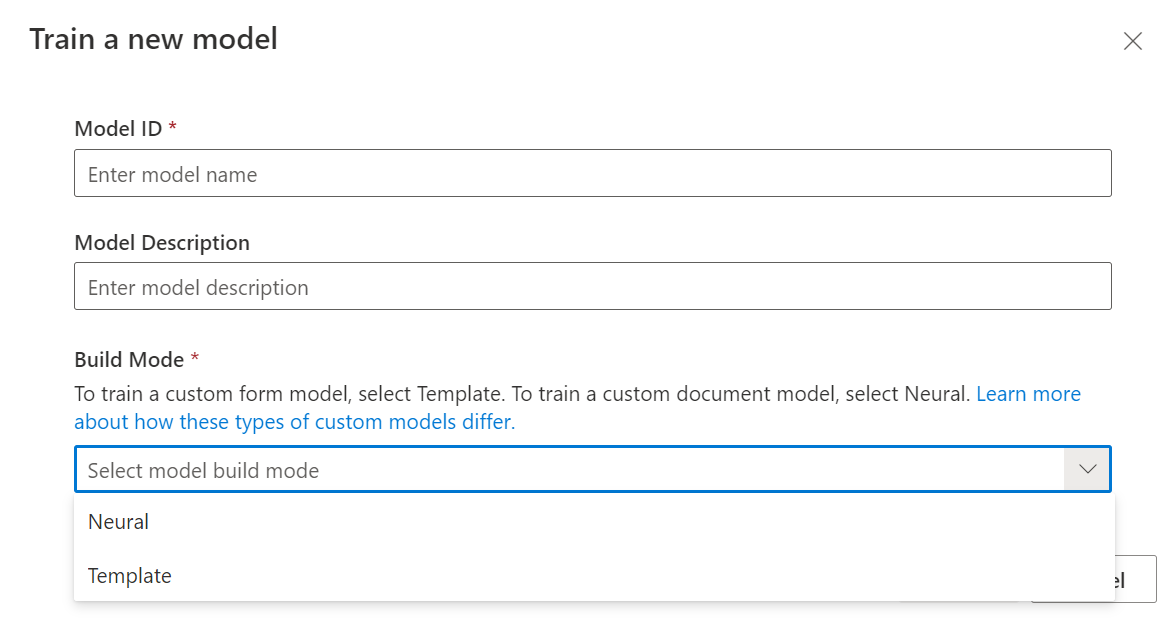
[トレーニング] を選択してトレーニング プロセスを開始します。
テンプレート モデルは数分でトレーニングされます。 ニューラル モデルのトレーニングには最大 30 分かかる場合があります。
[モデル] メニューに移動して、トレーニング操作の状態を表示します。
モデルのテスト
モデルのトレーニングが完了したら、モデルの一覧ページでモデルを選択して、モデルをテストできます。
モデルを選択し、[テスト] ボタンを選択します。
+ Addボタンを選択して、モデルをテストするファイルを選択します。ファイルを選択した後、[分析] ボタンを選択してモデルをテストします。
モデルの結果がメイン ウィンドウに表示され、抽出されたフィールドが右側のナビゲーション バーに一覧表示されます。
各フィールドの結果を評価して、モデルを検証します。
右側のナビゲーション バーには、モデルを呼び出すサンプル コードと、API からの JSON 結果もあります。
Document Intelligence Studio でカスタム モデルをトレーニングする方法を習得しました。 モデルは、ドキュメントを分析するために、REST API SDK で使用する準備ができています。
適用対象: ![]() v2.1。 その他のバージョン: v3.0
v2.1。 その他のバージョン: v3.0
Document Intelligence のカスタム モデルを使用する場合は、モデルを業界固有のフォームに合わせてトレーニングできるように、独自のトレーニング データを Train Custom Model 操作に提供します。 このガイドに従い、モデルを効果的にトレーニングするためにデータを収集し、準備する方法について学習してください。
同じ種類の完成したフォームが少なくとも 5 つ必要です。
手動でラベル付けされたトレーニング データを使用する場合は、同じ種類の少なくとも 5 つの完成したフォームから開始する必要があります。 必要なデータ セットに加え、ラベル付けされていないフォームを引き続き使用することもできます。
カスタム モデルの入力要件
まず、トレーニング データ セットが Document Intelligence の入力の要件に従っていることを確認します。
最適な結果を得るには、ドキュメントごとに 1 つの鮮明な写真または高品質のスキャンを提供してください。
サポートされているファイル形式:
モデル PDF 画像:
JPEG/JPG、PNG、BMP、TIFF、HEIFMicrosoft Office:
Word (DOCX)、Excel (XLS)、PowerPoint (PPT)、HTML既読 ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-02-29-preview、2023-10-31-preview) 一般的なドキュメント ✔ ✔ 事前構築済み ✔ ✔ カスタム抽出 ✔ ✔ カスタム分類 ✔ ✔ ✔ (2024-02-29-preview) PDF および TIFF の場合、最大 2000 ページを処理できます (Free レベルのサブスクリプションでは、最初の 2 ページのみが処理されます)。
ドキュメントを分析するためのファイル サイズは、有料 (S0) レベルでは 500 MB、無料 (F0) レベルでは 4 MB です。
画像のディメンションは、50 x 50 ピクセルから 10,000 x 10,000 ピクセルの間である必要があります。
PDF がパスワードでロックされている場合は、送信前にロックを解除する必要があります。
抽出するテキストの最小の高さは、1024 x 768 ピクセルのイメージの場合は 12 ピクセルです。 このディメンションは、150 DPI (1 インチあたりのドット数) で約
8ポイントのテキストに相当します。カスタム モデル トレーニングにおけるトレーニング データの最大ページ数は、カスタム テンプレート モデルの場合は 500、カスタム ニューラル モデルの場合は 50,000 です。
カスタム抽出モデル トレーニングにおけるトレーニング データの合計サイズは、テンプレート モデルの場合は 50 MB、ニューラル モデルの場合は 1GB です。
カスタム分類モデル トレーニングの場合、トレーニング データの合計サイズは
1GBで、最大 10,000 ページです。
トレーニング データのヒント
次のヒントを使って、トレーニングのためにデータ セットをさらに最適化してください。
- 画像ベースのドキュメントではなく、テキストベースの PDF ドキュメントを使用します。 スキャンした PDF は画像として扱われます。
- 完成したフォームでは、すべてのフィールドに入力されている例を使用します。
- 各フィールドに異なる値が含まれたフォームを使用します。
- 完成したフォームでは、より大きなデータ セット (10 から 15 の画像) を使用します。
トレーニング データをアップロードする
トレーニング用のドキュメントのセットを収集したら、それを Azure BLOB ストレージ コンテナーにアップロードする必要があります。 コンテナーを含む Azure Storage アカウントを作成する方法がわからない場合は、Azure portal の Azure Storage に関するクイックスタートに従ってください。 Standard パフォーマンス レベルを使用します。
手動でラベル付けされたデータを使用したい場合は、トレーニング ドキュメントに対応する .labels.json ファイルと .ocr.json ファイルをアップロードします。 サンプル ラベル付けツール (または独自の UI) を使用して、これらのファイルを生成できます。
データをサブフォルダーに整理する (オプション)
既定では、Train Custom Model API はストレージ コンテナーのルートにあるドキュメントのみを使用します。 ただし、API 呼び出しで指定した場合は、サブフォルダー内のデータを使用してトレーニングすることができます。 通常、カスタム モデルのトレーニング呼び出しの本文は次の形式になります。<SAS URL> は、コンテナーの Shared Access Signature URL です。
{
"source":"<SAS URL>"
}
次の内容を要求本文に追加すると、API はサブフォルダーにあるドキュメントでトレーニングを行います。 "prefix" フィールドはオプションであり、トレーニング データ セットを、指定された文字列で始まるパスのファイルに制限します。 そのため、たとえば、"Test" という値の場合、API は、Test という単語で始まるファイルまたはフォルダーのみを調べます。
{
"source": "<SAS URL>",
"sourceFilter": {
"prefix": "<prefix string>",
"includeSubFolders": true
},
"useLabelFile": false
}
次のステップ
トレーニング データ セットの作成方法を習得したので、クイックスタートに従って、カスタム Document Intelligence モデルをトレーニングし、お使いのフォームでの使用を開始してください。