余分なフェッチのアンチパターン
アンチパターンは、ストレス状況下でソフトウェアやアプリケーションを破壊する可能性があるため見落とさないようにする必要がある一般的な設計上の欠陥です。 "余分なフェッチのアンチパターン" では、業務のために必要以上のデータが取得されます。その結果、不要な I/O オーバーヘッドが発生し、応答性が低下することがよくあります。
余分なフェッチのアンチパターンの例
アプリケーションが I/O 要求数を最小限に抑えようと、必要になる "可能性のある" データをすべて取得した場合に、このアンチパターンに陥ることがあります。 これはえてして、頻度の高い I/O のアンチパターンを過度に意識したことによって生じます。 たとえば、データベースから製品ごとの詳しい情報をアプリケーションでフェッチすることがあります。 しかしユーザーが必要としているのは一部の情報だけで (顧客には関係のない情報が含まれている場合があります)、一度に "すべて" の製品を見る必要はないかもしれません。 ユーザーがカタログ全体を閲覧することになる場合でも、ページ単位で結果を表示すれば実用上は問題ないでしょう (20 件ずつ表示するなど)。
この問題の原因としてもう 1 つ考えられることは、実践している手法が、プログラミングまたはデザインの観点から好ましくない、ということです。 たとえば、次のコードは、Entity Framework を使用して製品ごとの詳しい情報をすべてフェッチします。 その後、その結果をフィルター処理して一部のフィールドだけを返し、残りは破棄されます。 完全なサンプルは、こちらでご覧いただけます。
public async Task<IHttpActionResult> GetAllFieldsAsync()
{
using (var context = new AdventureWorksContext())
{
// Execute the query. This happens at the database.
var products = await context.Products.ToListAsync();
// Project fields from the query results. This happens in application memory.
var result = products.Select(p => new ProductInfo { Id = p.ProductId, Name = p.Name });
return Ok(result);
}
}
次の例では、データベース側でも実行できる集計を、アプリケーション側でデータを取得して実行しています。 アプリケーションは、販売されたすべての注文のレコードを全件取得し、それらの合計を計算することによって、売上の合計を計算します。 完全なサンプルは、こちらでご覧いただけます。
public async Task<IHttpActionResult> AggregateOnClientAsync()
{
using (var context = new AdventureWorksContext())
{
// Fetch all order totals from the database.
var orderAmounts = await context.SalesOrderHeaders.Select(soh => soh.TotalDue).ToListAsync();
// Sum the order totals in memory.
var total = orderAmounts.Sum();
return Ok(total);
}
}
次に、少し気付きにくい問題の例を紹介します。Entity Framework の LINQ to Entities の振る舞いに起因するものです。
var query = from p in context.Products.AsEnumerable()
where p.SellStartDate < DateTime.Now.AddDays(-7) // AddDays cannot be mapped by LINQ to Entities
select ...;
List<Product> products = query.ToList();
このアプリケーションは、SellStartDate の日付から 1 週間以上経過している製品を探そうと試みます。 ほとんどの場合、where 句は、LINQ to Entities によって、データベース側で実行される SQL ステートメントに変換されます。 しかしこのケースでは、LINQ to Entities が AddDays メソッドを SQL にマッピングできません。 Product テーブルからすべての行が返され、その結果がメモリ内でフィルター処理されます。
問題は、AsEnumerable を呼び出す部分に潜んでいます。 このメソッドは、その結果を IEnumerable インターフェイスに変換します。 IEnumerable はフィルター処理をサポートしていますが、フィルター処理はデータベース側ではなく "クライアント" 側で実行されます。 LINQ to Entities でフィルター処理をデータ ソース側に引き渡すには既定の IQueryable を使用します。
余分なフェッチのアンチパターンを修正する方法
すぐに古くなったり破棄されたりするようなデータを大量にフェッチすることは避け、実行する処理に必要なデータだけをフェッチするようにしましょう。
テーブルからすべての列を取得してからフィルター処理するのではなく、必要な列だけをデータベースから選択します。
public async Task<IHttpActionResult> GetRequiredFieldsAsync()
{
using (var context = new AdventureWorksContext())
{
// Project fields as part of the query itself
var result = await context.Products
.Select(p => new ProductInfo {Id = p.ProductId, Name = p.Name})
.ToListAsync();
return Ok(result);
}
}
同様に、集計はデータベース内で実行し、アプリケーションのメモリ内で実行することは避けます。
public async Task<IHttpActionResult> AggregateOnDatabaseAsync()
{
using (var context = new AdventureWorksContext())
{
// Sum the order totals as part of the database query.
var total = await context.SalesOrderHeaders.SumAsync(soh => soh.TotalDue);
return Ok(total);
}
}
Entity Framework の使用時、LINQ クエリは IEnumerable ではなく、IQueryable インターフェイスを使って解決されます。 データ ソースにマッピング可能な関数だけを使用するように自分でクエリを調整することも、場合によっては必要となります。 前述の例は、クエリから AddDays メソッドを削除し、フィルター処理がデータベース側で実行されるようにすることでリファクタリングできます。
DateTime dateSince = DateTime.Now.AddDays(-7); // AddDays has been factored out.
var query = from p in context.Products
where p.SellStartDate < dateSince // This criterion can be passed to the database by LINQ to Entities
select ...;
List<Product> products = query.ToList();
考慮事項
一部のケースでは、データを行方向にパーティション分割することでパフォーマンスを高めることができます。 データが持つさまざまな属性に複数の異なる操作からアクセスする場合、行方向のパーティション分割によって競合を減らすことができます。 多くの場合ほとんどの操作は、データのごく一部分に対して実行すれば済みます。このように負荷を分散させることでパフォーマンスを向上できる場合があります。 データのパーティション分割に関するページを参照してください。
あえてクエリに特定の検索条件を設けず大量のデータが返される可能性を考慮しなければならない場合は、改ページ位置の自動修正を実装し、一度にフェッチするエンティティの件数を限定するようにします。 たとえばユーザーがブラウザーで製品カタログを閲覧する場合、1 ページずつ結果を表示することができます。
データ ストアに組み込まれている機能を可能な限り活用します。 たとえば SQL データベースには通常、集計関数が備わっています。
ご使用のデータ ストアが特定の関数 (集計など) をサポートしない場合、計算結果をどこか別の場所に保存しておき、レコードが追加されたり変更されたりしたときに値を更新することを検討してください。そうすれば値が必要になるたびにアプリケーション側で再計算する必要はありません。
要求によって取得されるフィールドの数が多いと感じる場合は、ソース コードをよく調べて、それらのフィールドが全部必要であるかどうかを確かめます。
SELECT *クエリの設計に改善の余地がある可能性があります。同様に、要求の結果として大量のエンティティが取得される場合、アプリケーション側でデータが正しくフィルター処理されていない可能性があります。 このようなエンティティが全部必要であるかどうかを確認します。 可能であれば、SQL の
WHERE句を使用するなど、データベース側のフィルター処理を使用します。処理の負荷をデータベース側に移すことが常に最善の方法とは限りません。 この手法を用いるのは、データベースがそのように設計されている、または最適化されている場合に限定してください。 ほとんどのデータベース システムは、特定の関数を想定して高度に最適化されていますが、汎用のアプリケーション エンジンの役割を果たすような設計にはなっていません。 詳細については、「ビジー状態のデータベースのアンチパターン」を参照してください。
余分なフェッチのアンチパターンを検出する方法
余分なフェッチは、待ち時間の長さやスループットの低さなどの症状となって現れます。 データ ストアからデータを取得する場合、競合の増加が関係している可能性もあります。 エンド ユーザーからは、応答時間の増加やサービスのタイムアウトに起因した障害が報告されることになります。こうした障害が発生した場合、HTTP 500 (内部サーバー) エラーまたは HTTP 503 (サービスを利用できません) エラーが返されます。 Web サーバーのイベント ログをよく調べてください。エラーの原因や状況についてさらに詳しい情報が記録されている可能性があります。
このアンチパターンの症状と収集されるテレメトリは、モノリシックな永続化のアンチパターンと酷似している場合があります。
原因を特定しやすくするために、次の手順を実行できます。
- ロード テストやプロセス監視など、インストルメンテーション データの収集手法を用いて、低速なワークロードまたはトランザクションを特定します。
- システムが示す動作パターンを観察します。 毎秒トランザクション数やユーザー数の観点で目立った制限はありますか。
- 低速なワークロードの事例と動作パターンとの相関関係を明らかにします。
- 使用中のデータ ストアを特定します。 データ ソースごとに、より深いレベルのテレメトリを実行し、処理の動作を観察します。
- そうしたデータ ソースを参照するクエリのうち、実行速度が遅いものがあれば特定します。
- 実行速度が遅いクエリについてリソースごとに分析し、データがどのように使用され、消費されているかを突き止めます。
次のような症状がないか調べます。
- 同じリソース (データ ストア) に対して大量の I/O 要求を頻繁に実行している。
- 共有リソース (データ ストア) で競合が生じている。
- 特定の操作がネットワーク経由で大量のデータを頻繁に受信している。
- アプリケーションやサービスが I/O の完了に費やす待ち時間が著しく長い。
診断の例
以降のセクションでは、上記の手順を前述の例に適用しています。
低速のワークロードを特定する
このグラフは、先ほど紹介した GetAllFieldsAsync メソッドを最大 400 人のユーザーが同時に実行するようすをシミュレートしたロード テストからのパフォーマンス測定結果を示したものです。 負荷が増えるにつれ少しずつスループットが低下しています。 ワークロードが増えるにつれて平均応答時間が上昇します。
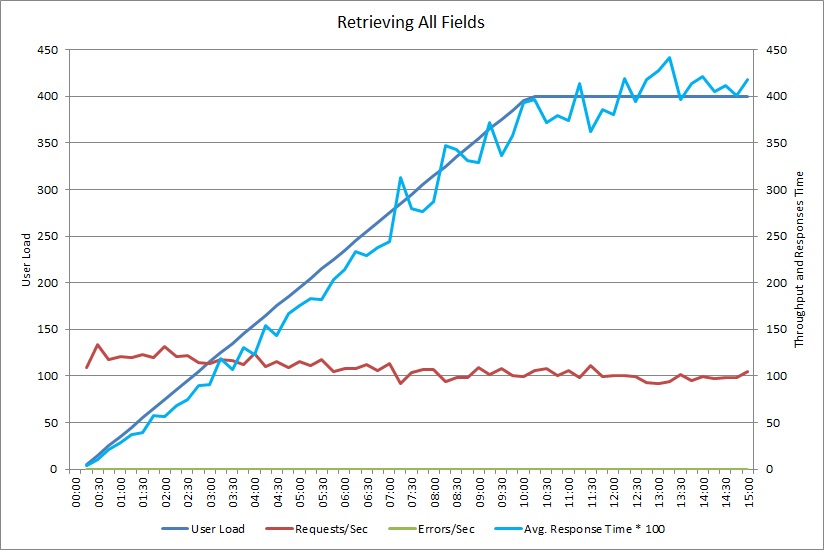
AggregateOnClientAsync 操作のロード テストも同様のパターンを示しています。 当然、要求のボリュームは不変です。 平均応答時間は、前のグラフと比べるとなだらかではありますが、ワークロードと共に上昇します。
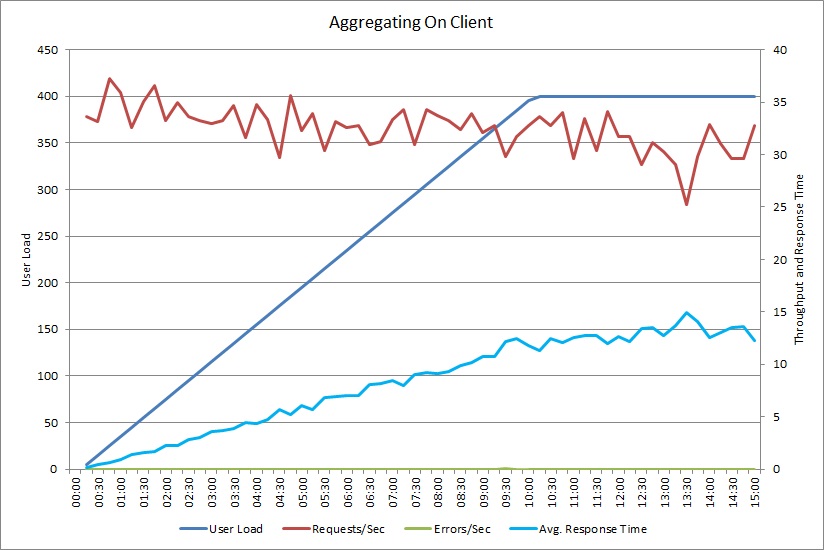
低速なワークロードと動作パターンとの相関関係を明らかにする
定期的に使用率が高くなる時間帯とパフォーマンス低下との相関関係から問題の領域が明らかになる場合があります。 実行速度低下が疑われる機能のパフォーマンス プロファイルを綿密に調査し、先ほど実行したロード テストと合致しているかどうかを確認してください。
同じ機能を対象に、ユーザー数を段階的に増やしていきながらロード テストを実施し、パフォーマンスが著しく低下したり、完全にエラーになったりするポイントを見極めます。 そのポイントが、皆さんの想定した実際の使用状況の範囲内で生じるのであれば、その機能がどのように実装されているかを詳しく調査してください。
システムに負荷のかかったタイミングで実行されることがない場合や急を要さない場合、他の重要な操作のパフォーマンスに悪影響を及ぼさない場合には、低速な処理が必ずしも問題となるわけではありません。 たとえば毎月の運用統計データの生成は、時間のかかる処理かもしれませんが、通常はバッチ処理として、低優先度のジョブとして実行されていることでしょう。 一方、顧客が製品カタログを問い合わせるために行うクエリは、重要度のきわめて高い業務です。 このような重要な操作から生成されるテレメトリに注目して、使用率が上昇する時間帯におけるパフォーマンスの変化を調べましょう。
低速なワークロードのデータ ソースを特定する
サービスのパフォーマンス低下の原因がデータの取得方法にあることが疑われる場合、アプリケーションとそのリポジトリとの対話を調査します。 ライブ システムを監視して、パフォーマンスの低い時間帯にどのソースがアクセスの対象になっているかを把握してください。
データ ソースごとに、次の情報を収集するようにシステムをインストルメント化します。
- それぞれのデータ ストアのアクセス頻度。
- データ ストアが送受するデータ量。
- 該当する操作の (特に要求の待ち時間が発生する) タイミング。
- 通常負荷の下で各データ ストアにアクセスしているときに発生するエラーの特性と割合。
この情報を、アプリケーションからクライアントに返されるデータの量と比較してみましょう。 データ ストアから返されるデータの量とクライアントに返されるデータの量の比率を追跡します。 その差が大きい場合、不要なデータをアプリケーションでフェッチしていないかどうかを調査します。
このデータは、ライブ システムを観察し、ユーザーの要求ごとのライフサイクルをトレースすることによって収集することができます。または、一連の人工的ワークロードをモデル化し、それをテスト システムに対して実行してもかまいません。
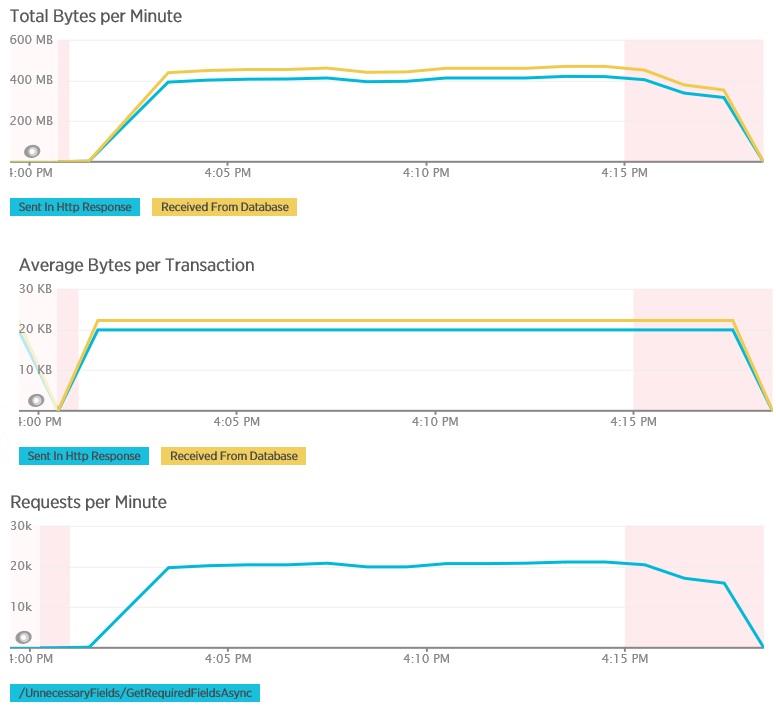
次のグラフは、GetAllFieldsAsync メソッドのロード テスト中に New Relic APM を使用して収集されたテレメトリを示したものです。 データベースから受信したデータの量と、それに対応する HTTP 応答の量の違いに注目してください。
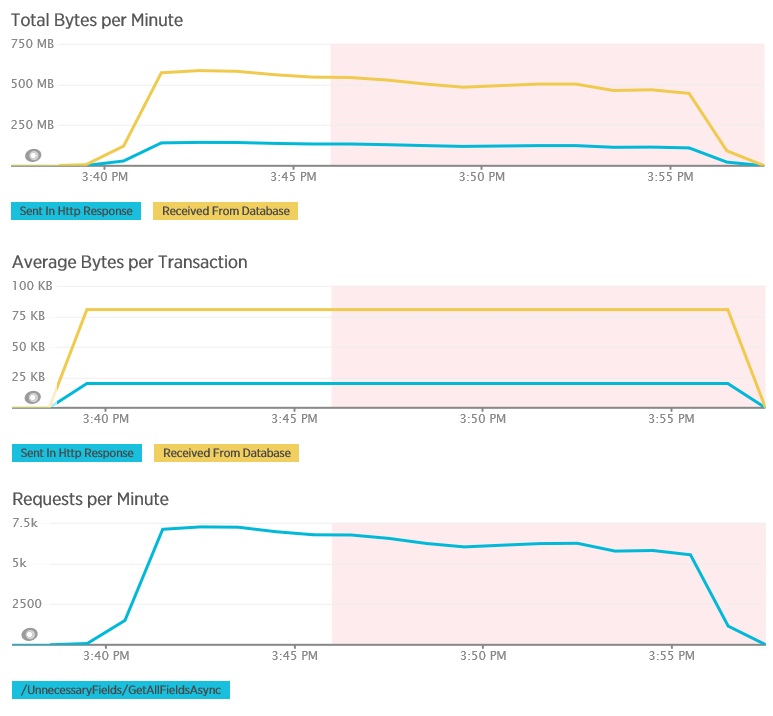
それぞれの要求でデータベースから返されたのは 80,503 バイトですが、そのうちクライアントへの応答に含まれていたのはたった 19,855 バイトでした。データベースの応答の約 25% です。 クライアントに返されるデータのサイズは、その形式によって変わることがあります。 このロード テストに関して言えば、クライアントが要求したのは JSON データです。 ここでは紹介していませんが、別途 XML を使用したテストでは応答サイズが 35,655 バイトと、データベースの応答の 44% のサイズになりました。
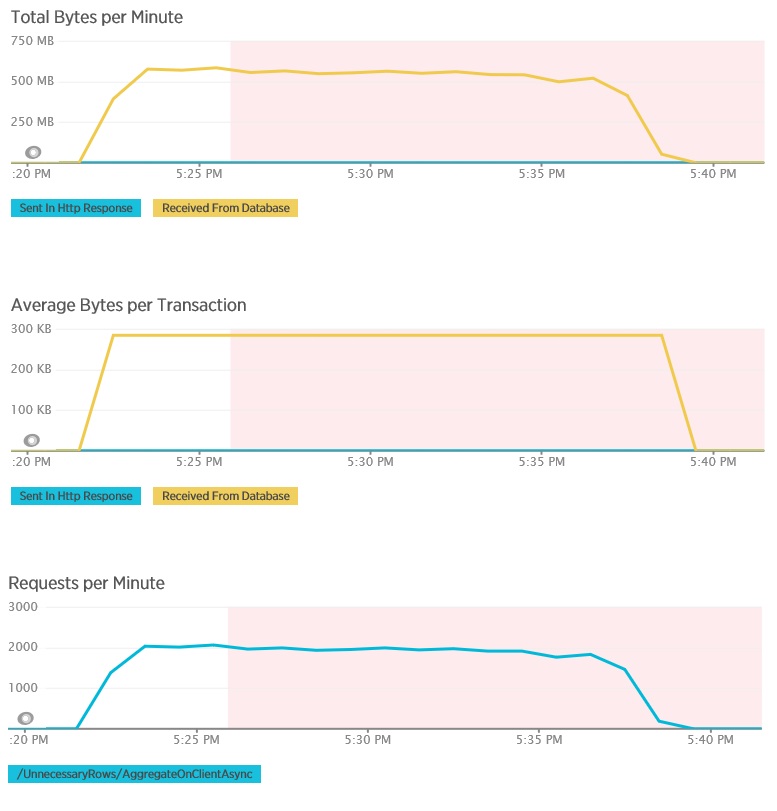
AggregateOnClientAsync メソッドのロード テストは、さらに極端な結果を示しています。 このケースの各テストで実行したクエリがデータベースから取得したデータは 280 Kb を超えましたが、JSON 形式の応答はわずか 14 バイトでした。 これほど大きな差があるのは、このメソッドが、集計結果を大量のデータから計算しているためです。
実行速度が遅いクエリを特定して分析する
リソース消費が最も激しく実行に著しい時間がかかるデータベース クエリを探します。 さまざまなデータベース操作の開始時刻と完了時刻は、インストルメンテーションを追加することで見極めることができます。 多くのデータ ストアは、クエリがどのように実行され、どのように最適化されるかについての詳細な情報を入手できるようになっています。 たとえば Azure SQL Database 管理ポータルの [クエリ パフォーマンス] ウィンドウでは、クエリを選択し、実行時の詳しいパフォーマンス情報を確認することができます。 以下に示したのは、GetAllFieldsAsync 操作によって生成されるクエリです。
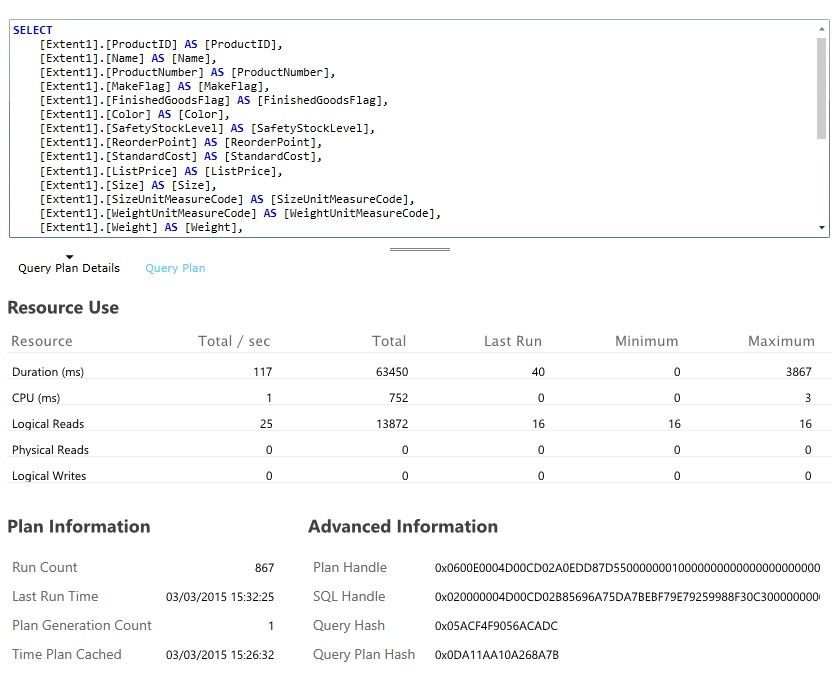
ソリューションを実装して結果を検証する
データベース側で SELECT ステートメントを使用するように GetRequiredFieldsAsync メソッドを変更した後、ロード テストでは、次の結果が示されました。
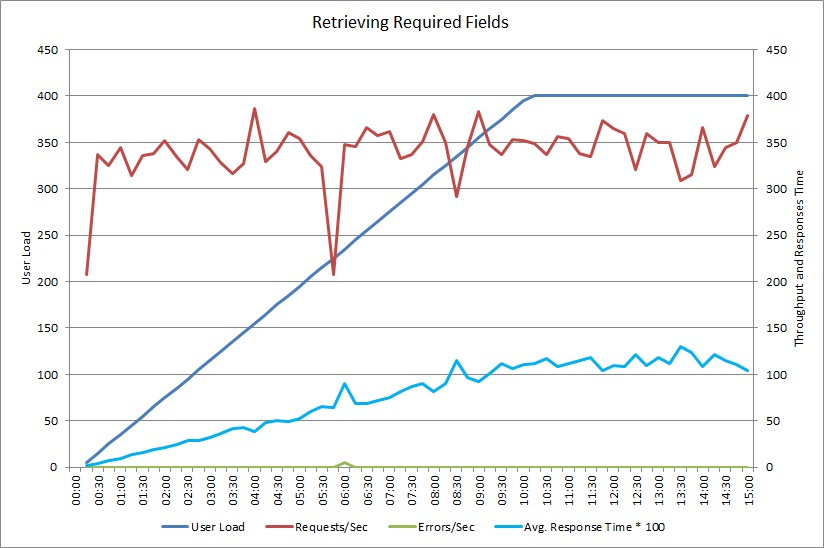
このロード テストで使用したデプロイは前回と同じです。また、ワークロードをシミュレートするために使用した同時ユーザー数も、前回と同じ 400 ユーザーです。 このグラフを見ると、待ち時間が大幅に短縮されていることが確認できます。 応答時間は負荷と共に上昇しますが、前回の 4 秒に比べて、最大でも 1.3 秒程度に留まっています。 スループットも向上し、毎秒要求数が前回の 100 に対し、350 にまで増加しています。 データベースから取得されたデータの量は、HTTP 応答メッセージのサイズとほぼ一致するようになりました。
AggregateOnDatabaseAsync メソッドのロード テストから生成された結果は次のとおりです。
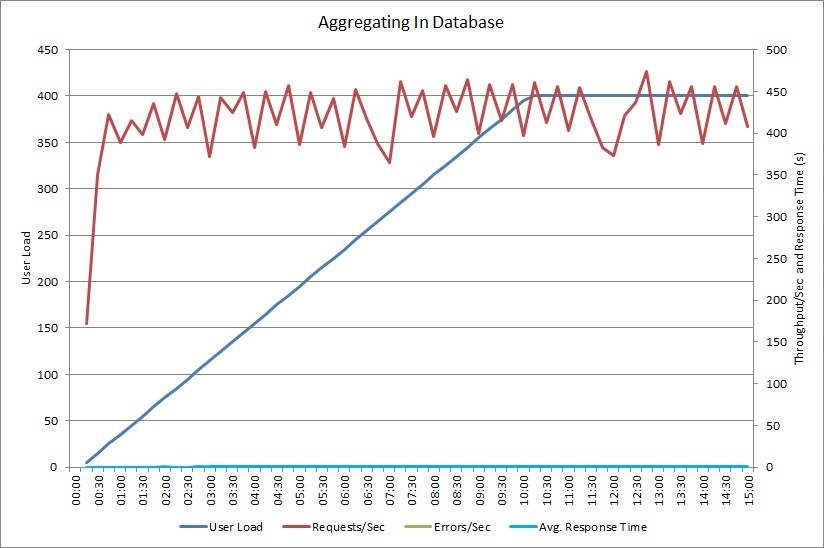
平均応答時間は最小限に抑えられています。 パフォーマンスが桁違いに向上しています。その主な要因は、データベースからの I/O が大幅に減ったことです。
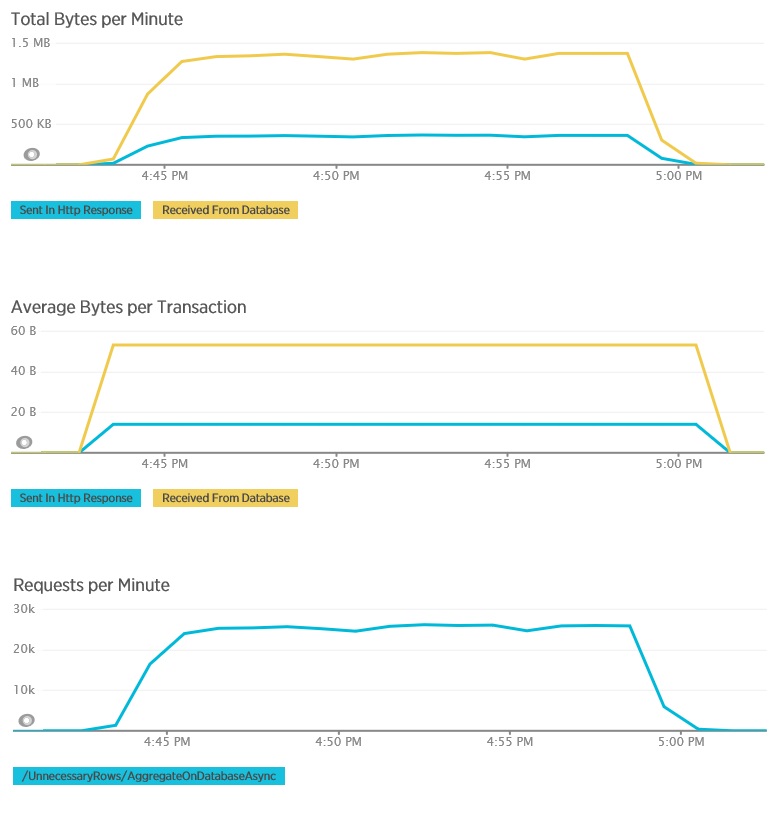
以下は、AggregateOnDatabaseAsync メソッドに関して対応するテレメトリを示したものです。 データベースから取得されるデータの量は、トランザクションあたり 280 Kb 超から 53 バイトへと大幅に削減されました。 その結果、1 分あたりの持続可能な最大要求数は、約 2,000 RPM から 25,000 RPM 超にまで増加しました。
関連リソース
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示