モノリシックな永続化のアンチパターン
アプリケーションのすべてのデータを単一のデータ ストアに配置すると、パフォーマンスが低下する可能性があります。その理由は、リソースが競合する可能性があること、あるいはデータ ストアが一部のデータに適していないことです。
問題の説明
歴史的に、アプリケーションでは、多くの場合、アプリケーションで格納することが必要になるデータの種類を問わずに単一のデータ ストアが使用されていました。 通常、その目的は、アプリケーションの設計を簡素化することや、開発チームの既存のスキル セットに合わせることにありました。
最新のクラウド ベースのシステムでは、多くの場合、追加の機能と非機能の要件があり、ドキュメント、画像、キャッシュ データ、キューに格納されたメッセージ、アプリケーション ログ、テレメトリなど、さまざまな種類のデータを保存する必要があります。 従来のアプローチに従ってこれらすべての情報を同じデータ ストアに格納すると、主に次の 2 つの理由から、パフォーマンスが低下する可能性があります。
- 関連性のない大量のデータを同じデータ ストアに格納および取得すると競合が発生し、応答時間が遅くなると共に、接続が失敗する可能性があります。
- どのデータ ストアを選択したとしても、そのデータ ストアは、各種データすべてにとって最適であるとは限らず、アプリケーションで実行する操作に最適化されていない可能性があります。
次の例は、新しいレコードをデータベースに追加し、その結果をログに記録する ASP.NET Web API コントローラーを示しています。 ログは、ビジネス データと同じデータベースに保持されます。 完全なサンプルは、こちらでご覧いただけます。
public class MonoController : ApiController
{
private static readonly string ProductionDb = ...;
public async Task<IHttpActionResult> PostAsync([FromBody]string value)
{
await DataAccess.InsertPurchaseOrderHeaderAsync(ProductionDb);
await DataAccess.LogAsync(ProductionDb, LogTableName);
return Ok();
}
}
ログ レコードの生成レートは、業務のパフォーマンスに影響するものと思われます。 また、アプリケーション プロセス モニターなどの別のコンポーネントが定期的にログ データを読み取って処理した結果、業務に影響が及ぶ可能性もあります。
問題の解決方法
用途に応じてデータを分けます。 データ セットごとに、そのデータ セットの使用方法に最も適合するデータ ストアを選択します。 前の例では、ビジネス データが保持されるデータベースとは別のストアにアプリケーションのログを保存する必要があります。
public class PolyController : ApiController
{
private static readonly string ProductionDb = ...;
private static readonly string LogDb = ...;
public async Task<IHttpActionResult> PostAsync([FromBody]string value)
{
await DataAccess.InsertPurchaseOrderHeaderAsync(ProductionDb);
// Log to a different data store.
await DataAccess.LogAsync(LogDb, LogTableName);
return Ok();
}
}
考慮事項
データの使用方法とアクセス方法によってデータを分けます。 たとえば、ログ情報とビジネス データを同じデータ ストアに格納しないようにします。 これらの種類のデータは、アクセスの要件とパターンが大きく異なります。 ログ レコードは、本質的にシーケンシャルです。これに対し、ビジネス データは、ランダム アクセスを必要とする可能性が高く、多くの場合リレーショナルです。
データの種類ごとのデータ アクセス パターンを検討します。 たとえば、書式設定されたレポートとドキュメントは Azure Cosmos DB などのドキュメント データベースに格納し、一時データをキャッシュするには Azure Cache for Redis を使用します。
このガイダンスに従ってもデータベースの限界に達する場合は、データベースのスケールアップが必要になる可能性があります。 また、水平方向にスケーリングし、複数のデータベース サーバー間で負荷を分けることも検討してください。 ただし、パーティション分割を行うにはアプリケーションの再設計が必要になる場合があります。 詳細については、「データのパーティション分割」を参照してください。
問題の検出方法
データベース接続などのシステム リソースが不足すると、システムは大幅に低速になり、最終的には動作しなくなります。
原因の識別に役立てるために、次の手順を実行できます。
- システムをインストルメント化して、主要なパフォーマンスの統計を記録します。 アプリケーションがデータを読み書きするポイントだけでなく、各操作のタイミング情報をキャプチャします。
- 可能であれば、運用環境でシステムの実行を数日間監視し、実際のシステムの使用状況を把握します。 これが不可能な場合は、典型的な一連の操作を実行する、現実的な数の仮想ユーザーを使用して、スクリプトによるロード テストを実行します。
- テレメトリ データを使用して、パフォーマンスが低下している期間を識別します。
- 対象の期間中にアクセスされていたデータ ストアを識別します。
- 競合が発生している可能性のあるデータ ストレージ リソースを識別します。
診断の例
以降のセクションでは、これらの手順を前述のサンプル アプリケーションに適用していきます。
システムをインストルメント化および監視する
次のグラフは、前述のサンプル アプリケーションのロード テストの結果を示しています。 テストでは、最大 1,000 人の同時実行ユーザーのステップ負荷を使用しました。
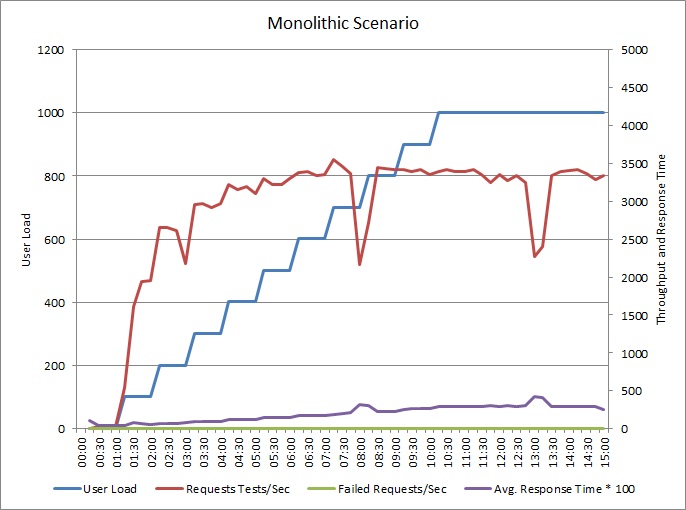
負荷が 700 ユーザーに増加するまでは、それに合わせてスループットも上がります。 しかし、その時点でスループットは横ばいになり、システムはその最大処理能力で動作しているように見えます。 ユーザーの負荷に応じて平均応答時間が徐々に上昇し、システムが需要に対応できないことがわかります。
パフォーマンスが低下している期間を識別する
運用システムを監視している場合、パターンに気付くかもしれません。 たとえば、毎日同じ時間に応答時間が大幅に低下しているとします。 このような状況は、通常のワークロードまたはスケジュールされたバッチ ジョブによって発生する可能性があるほか、単に特定の時間にシステムのユーザー数が増えるために発生する可能性があります。 こうしたイベントのテレメトリ データに注目する必要があります。
応答時間の増加と、データベース アクティビティまたは共有リソースへの I/O の増加との間の相関関係を見つけてください。 相関関係がある場合、データベースがボトルネックになる可能性を意味します。
対象の期間中にアクセスされていたデータ ストアを識別する
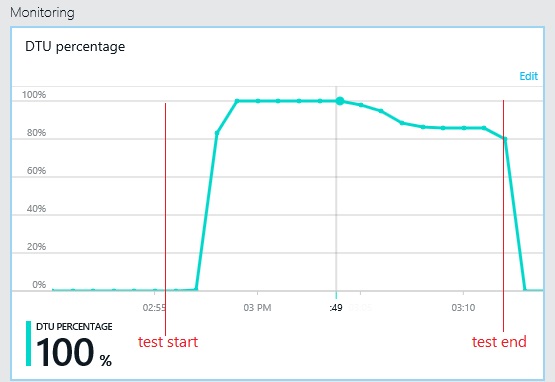
次のグラフは、ロード テスト中のデータベース スループット単位 (DTU) の使用率を示しています (DTU は使用可能な容量のメジャーであり、CPU 使用率、メモリ割り当て、I/O 率の組み合わせです)。DTU の使用率はすぐに 100% に達しています。 これは、前のグラフでスループットがピークに達したポイントとほぼ同じです。 データベースの使用率については、テストが終了するまで非常に高い値が維持されています。 最後の部分で若干の低下があります。これは、調整、データベース接続の競合、またはその他の要因が原因となっている可能性があります。
データ ストアのテレメトリを調べる
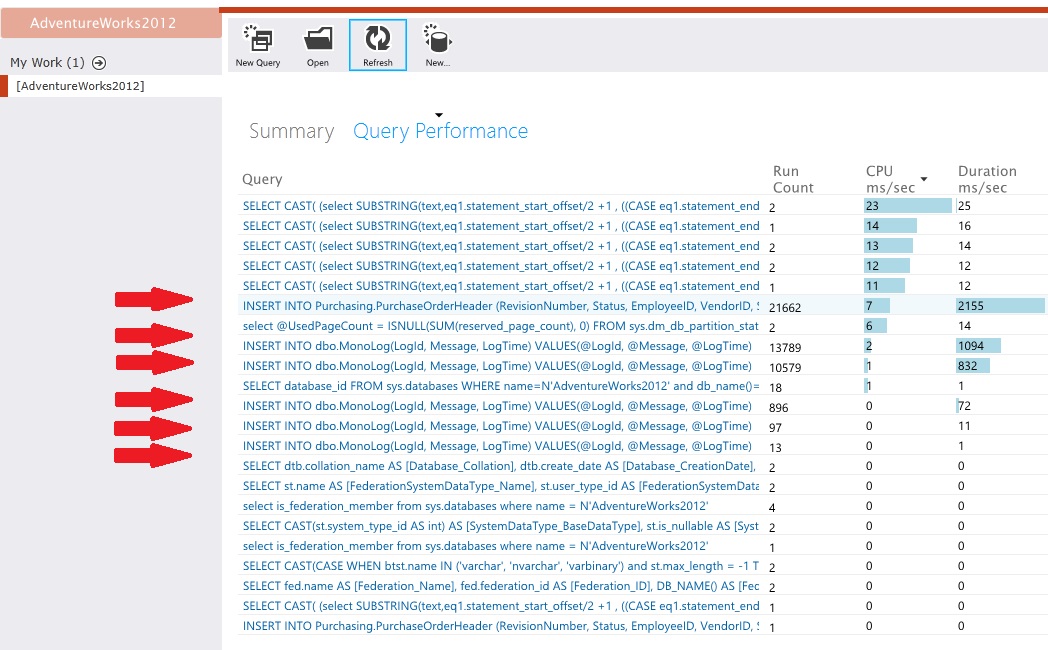
アクティビティの低レベルの詳細をキャプチャするためにデータ ストアをインストルメント化します。 データ アクセス統計から、サンプル アプリケーションでは PurchaseOrderHeader テーブルと MonoLog テーブルの両方に対して大量の挿入操作が実行されていることがわかります。
リソースの競合を識別する
この時点で、どのポイントでアプリケーションが競合するリソースにアクセスするかに注目して、ソース コードを確認することができます。 次のような状況を確認します。
- 論理的に区別されるデータが同じストアに書き込まれている。 ログ、レポート、およびキューに入れられたメッセージなどのデータをビジネス情報と同じデータベースに保持しないようにしてください。
- データ ストアの選択とデータの種類 (リレーショナル データベース内の大規模な BLOB または XML ドキュメントなど) のミスマッチ。
- 同じストアを共有しながら使用パターンが著しく異なるデータ (たとえば、書き込みが多く読み取りが少ないデータと書き込みが少なく読み取りが多いデータが一緒に格納されているケース)。
ソリューションを実装して結果を検証する
アプリケーションは、ログを別のデータ ストアに書き込むように変更されました。 ロード テストの結果を次に示します。
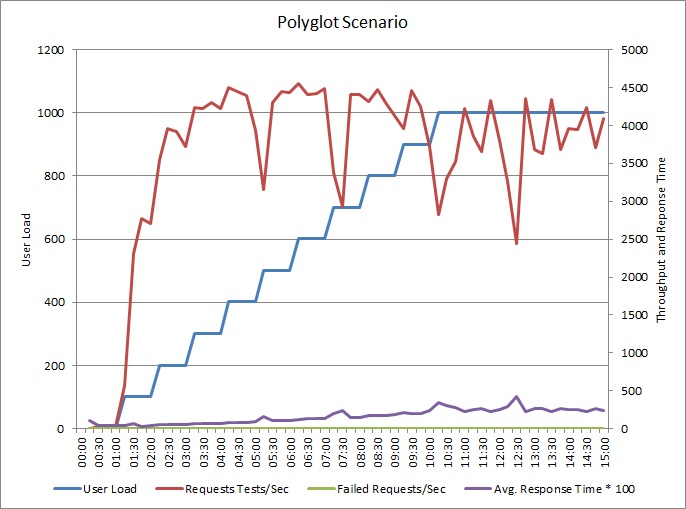
スループットのパターンは以前のグラフと似ていますが、パフォーマンスのピーク ポイントは、1 秒あたり約 500 要求高くなっています。 平均応答時間は少し低くなっています。 ただし、これらの統計は完全なストーリーを表していません。 ビジネス データベースのテレメトリでは、DTU の使用率は 100% ではなく約 75% でピークに達しています。
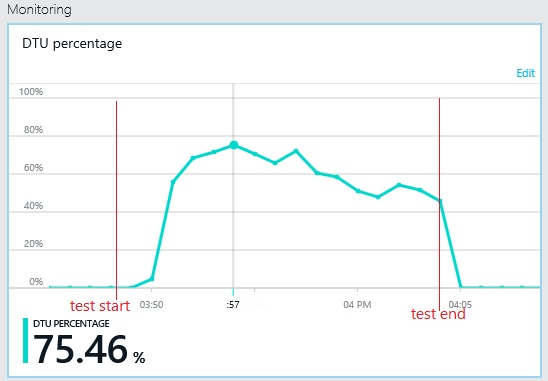
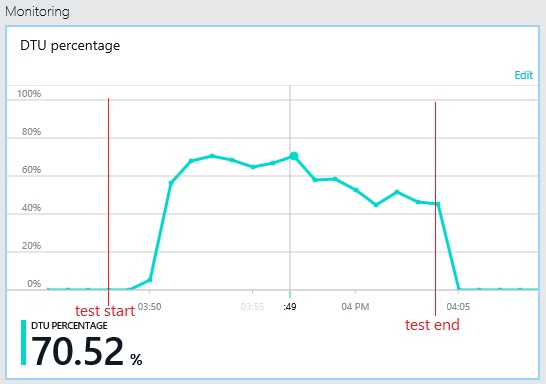
同様に、ログ データベースの最大 DTU 使用率は約 70% に留まります。 データベースは、システムのパフォーマンスを制限する要因ではなくなりました。
関連リソース
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示