再試行ストームのアンチパターン
サービスが利用できないかビジー状態である場合、クライアントによる接続の再試行が頻繁すぎると、サービスの復旧が難航して、問題が悪化する可能性があります。 また、要求は通常、定義された期間だけ有効なので、無期限の再試行には意味がありません。
問題の説明
クラウドでは、サービスに問題が発生し、クライアントから使用できなくなったり、クライアントのスロットルやレート制限が必要になったりすることがあります。 クライアントがサービスへの接続に失敗した場合に再試行するのは適切なプラクティスですが、再試行が頻繁すぎたり、長期にわたりすぎたりしないようにすることが重要です。 短期間内の再試行は、サービスが復旧されていない可能性が高いため、成功する可能性が低くなります。 また、復旧の試行中に多数の接続が試行されるとサービスにさらにストレスがかかり、反復的な接続試行によってサービスが過負荷になって根本的な問題が悪化する可能性もあります。
次の例は、クライアントがサーバーベースの API に接続するシナリオを示しています。 要求が成功しなかった場合、クライアントは直ちに再試行し、再試行が無期限に行われます。 多くの場合、このような動作はこの例ほど明らかではありませんが、同じ原則が適用されます。
public async Task<string> GetDataFromServer()
{
while(true)
{
var result = await httpClient.GetAsync(string.Format("http://{0}:8080/api/...", hostName));
if (result.IsSuccessStatusCode) break;
}
// ... Process result.
}
問題の解決方法
クライアント アプリケーションは、再試行ストームの発生を回避するために、いくつかのベスト プラクティスに従う必要があります。
- 再試行回数に上限を設定し、再試行が長期にわたらないようにします。
while(true)ループの記述は簡単に思えるかもしれませんが、ほとんどの場合、要求の開始につながった状況は変化した可能性が高いため、実際には長期にわたる再試行は望ましくありません。 ほとんどのアプリケーションでは、数秒または数分の再試行で十分です。 - 再試行間に一時停止します。 サービスが利用できない場合、即時の再試行が成功する可能性は低くなります。 たとえば、エクスポネンシャル バックオフ戦略を使用して、試行間の待機時間を徐々に長くします。
- エラーを適切に処理します。 サービスが応答していない場合は、試行を中止し、コンポーネントのユーザーまたは呼び出し元にエラーを返すのが妥当かどうかを検討してください。 アプリケーションを設計するときは、これらの障害シナリオを考慮してください。
- サーキット ブレーカー パターンの使用を検討します。これは、再試行ストームを避けるために設計されています。
- サーバーが
retry-after応答ヘッダーを提供する場合は、指定された期間が経過するまで再試行しないようにしてください。 - Azure サービスとの通信には、公式の SDK を使用します。 一般に、これらの SDK には、再試行ストームの原因や関与に対する再試行ポリシーと保護が組み込まれています。 通信しているサービスに SDK がないか、SDK では再試行ロジックが正しく処理されない場合は、Polly (.NET の場合) や retry (JavaScript の場合) などのライブラリを使用して再試行ロジックを正しく処理することを検討し、コードを自身で記述することは避けてください。
- それをサポートする環境で実行している場合は、サービス メッシュ (または別の抽象化レイヤー) を使用して、送信呼び出しを送信してください。 通常、これらのツール (Dapr など) では、再試行ポリシーがサポートされ、繰り返しの試行された後のバックオフなどのベスト プラクティスに自動的に従います。 このアプローチにより、再試行コードを自身で記述する必要がなくなります。
- 要求をバッチ処理し、使用可能な場合は要求プーリングを使用することを検討します。 多くの SDK では、要求のバッチ処理と接続プーリングが処理されます。これにより、アプリケーションが行う送信接続試行の合計回数が少なくなりますが、これらの接続を頻繁に再試行しすぎないように注意する必要は依然としてあります。
サービスを再試行ストームから保護する必要もあります。
- インシデント中に接続を停止できるように、ゲートウェイ レイヤーを追加します。 これは、バルクヘッド パターンの例です。 Azure では、Front Door、Application Gateway、API Management など、さまざまな種類のソリューションに対してさまざまなゲートウェイ サービスを提供しています。
- ゲートウェイで要求を調整します。これにより、バックエンド コンポーネントによって操作を続行できない多数の要求が受け入れられなくなります。
- 調整している場合は、接続を再試行するタイミングをクライアントが理解できるように、
retry-afterヘッダーを返送します。
考慮事項
- クライアントでは、返されるエラーの種類を考慮する必要があります。 一部のエラーの種類は、サービスの障害を示すのではなく、クライアントにより無効な要求が送信されたことを示します。 たとえば、クライアント アプリケーションが
400 Bad Requestエラー応答を受信した場合は、要求が無効であることがサーバーから通知されるので、同じ要求の再試行はおそらく役に立ちません。 - クライアントでは、接続を再試行する意味がある時間の長さを考慮する必要があります。 再試行する時間の長さは、ビジネス要件と、エラーをユーザーまたは呼び出し元に適切に伝達できるかどうかによって決まります。 ほとんどのアプリケーションでは、数秒または数分の再試行で十分です。
問題の検出方法
クライアントの観点から見ると、この問題の現象には、非常に長い応答や処理時間と、接続の再試行が繰り返し試行されることを示すテレメトリが含まれる場合があります。
サービスの観点から見ると、この問題の現象には、1 つのクライアントからの短期間に多数の要求や、障害からの復旧中の 1 つのクライアントからの多数の要求が含まれる場合があります。 現象には、サービスを復旧するときの問題や、障害の修復直後のサービスの継続的な連鎖的失敗が含まれることもあります。
診断の例
次のセクションでは、クライアント側とサービス側の両方で、再試行ストームの可能性を検出する方法の 1 つを示します。
クライアント テレメトリからの識別
Azure Application Insights はアプリケーションからテレメトリを記録し、データをクエリと視覚化に使用できるようにします。 送信接続は依存関係として追跡されます。それらに関する情報にアクセスしてグラフ化し、クライアントが同じサービスに対して大量の送信要求を行っていることを識別することができます。
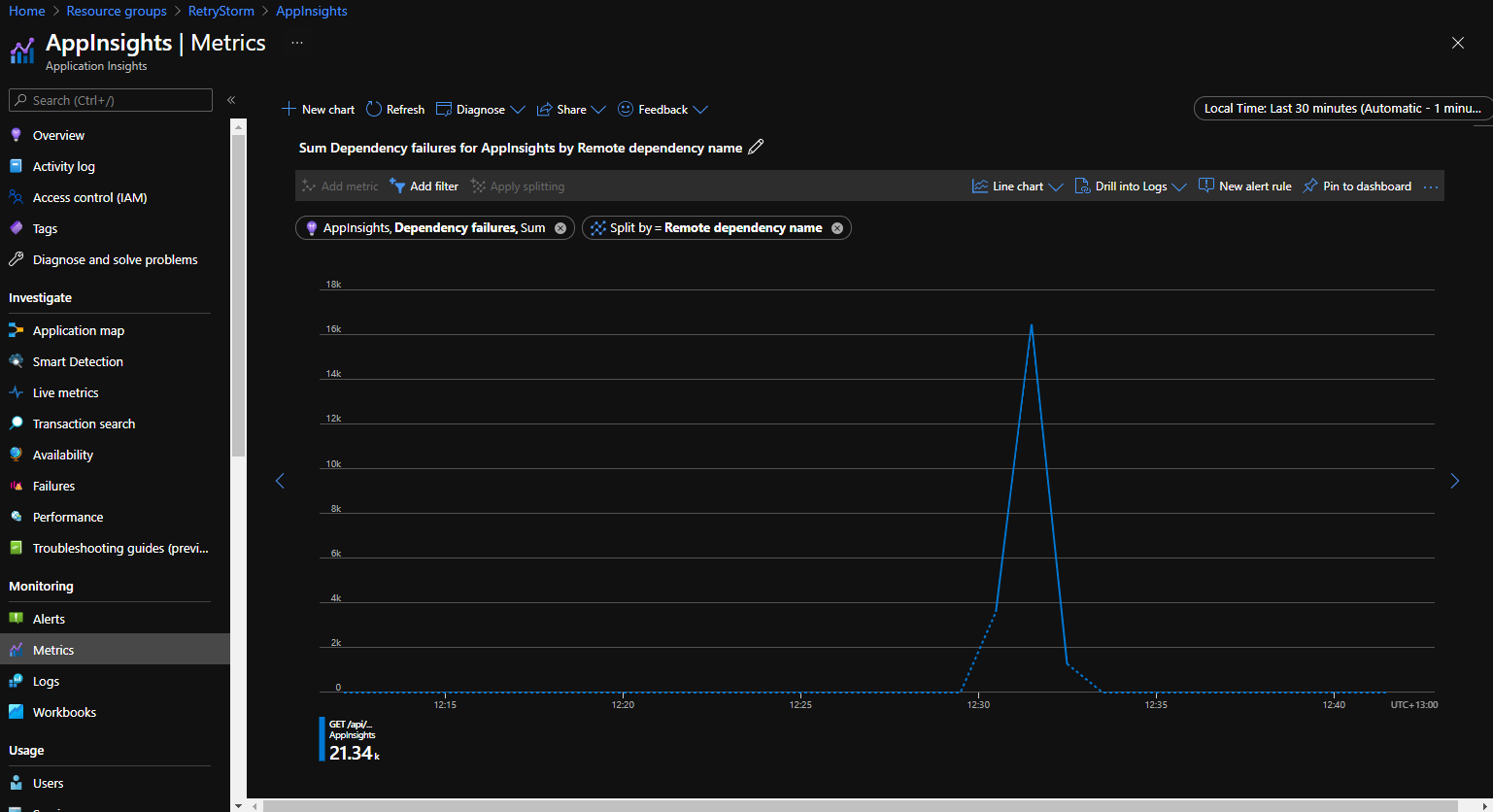
次のグラフは、Application Insights ポータル内の [メトリック] タブから取得され、"依存関係エラー" メトリックが "リモート依存関係名" で分割されて表示されています。 これは、短い時間内に依存関係への失敗した接続試行の数が多い (21,000 を超える) シナリオを示しています。
サーバー テレメトリからの識別
サーバー アプリケーションでは、1 つのクライアントからの多数の接続を検出できます。 次の例では、Azure Front Door はアプリケーションのゲートウェイとして機能し、Log Analytics ワークスペースにすべての要求を記録するように構成されています。
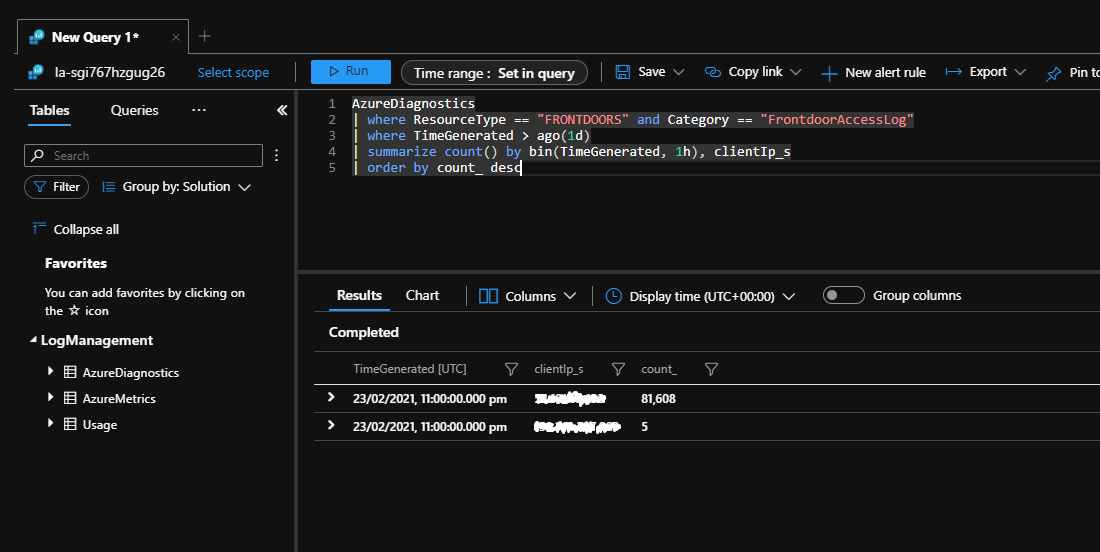
次の Kusto クエリを Log Analytics に対して実行できます。 これにより、前日に多数の要求をアプリケーションに送信したクライアント IP アドレスが識別されます。
AzureDiagnostics
| where ResourceType == "FRONTDOORS" and Category == "FrontdoorAccessLog"
| where TimeGenerated > ago(1d)
| summarize count() by bin(TimeGenerated, 1h), clientIp_s
| order by count_ desc
再試行ストーム中にこのクエリを実行すると、1 つの IP アドレスからの多数の接続試行が示されます。
関連リソース
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示