この記事では、多層 IaaS (サービスとしてのインフラストラクチャ) アプリを Azure にデプロイする際の、高可用性 (HA) およびディザスター リカバリー (DR) のオプションのデシジョン ツリーと例を示します。
Architecture
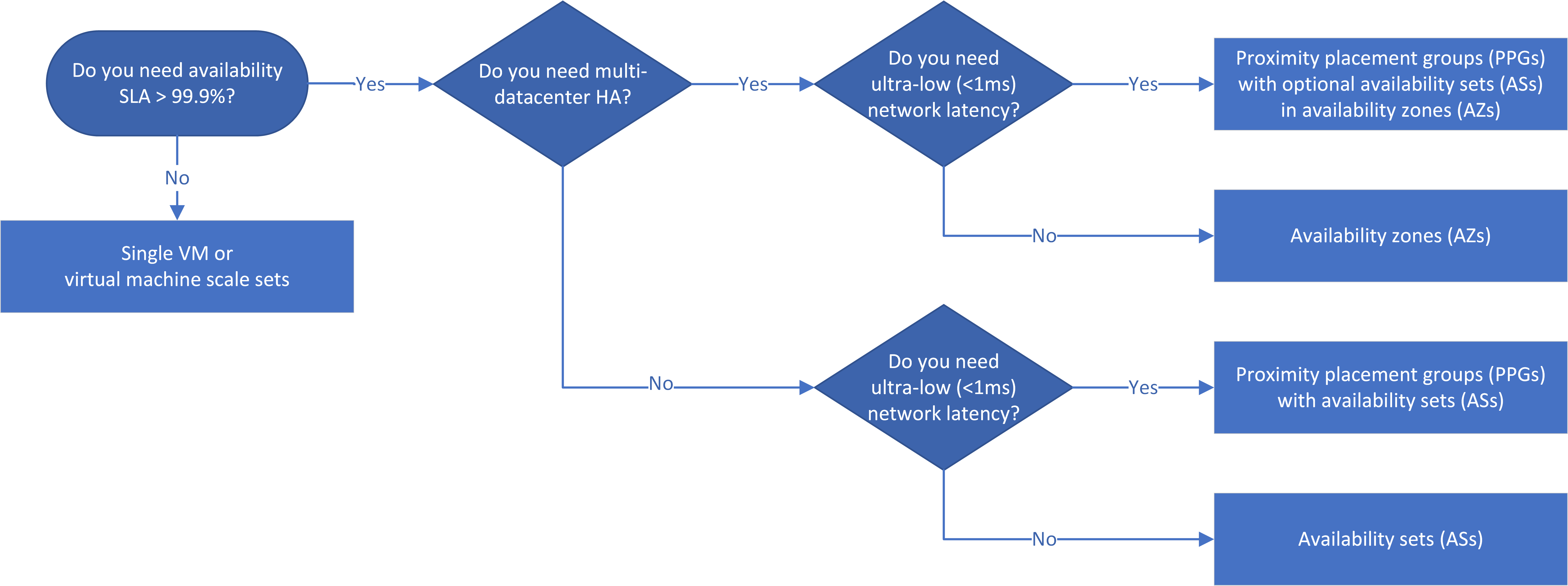
Workflow
可用性セット (AS) は、複数の分離されたハードウェア ノードに VM を分散することで、データセンター内で VM の冗長性と可用性を提供します。 計画的または計画外のダウンタイム中も VM のサブセットが稼働し続けるため、アプリ全体の可用性と動作が維持されます。
可用性ゾーン (AZ) は、Azure リージョン内の複数のデータセンターにまたがる一意の物理的な場所です。 各 AZ は、独立した電源、冷却手段、ネットワークを備えた 1 つ以上のデータセンターにアクセスします。AZ が有効な各 Azure リージョンには、最低 3 つの AZ があります。 リージョン内で AZ は物理的に分離されているため、デプロイされた VM はデータセンターの障害から保護されます。
この意思決定フローチャートは、可能であれば HA アプリで AZ を使用するという原則を反映しています。 データセンターの障害に対する回復力があるため、ゾーン間、つまりデータセンター間の HA は > 99.99% の SLA を提供します。
アプリのさまざまな層の AS と AZ は、同じデータセンター内に存在することが保証されているわけではありません。 アプリの待機時間が一番の懸念事項である場合は、AZ および AS と共に近接配置グループ (PPG) を使用して、1 つのデータセンターにサービスを併置する必要があります。
Components
代替
アプリがデータをネイティブにレプリケートできる場合は、Azure Site Recovery を使用したリージョンの DR の代わりに、DR 専用のストレッチ クラスターなど、ホット/コールド スタンバイ サーバーを使用した "マルチリージョン DR" を実装できます。 この代替方法は例で具体的に詳述されていませんが、どのソリューションにも追加できます。 リージョン間のレプリケーションは非同期であり、ある程度のデータ損失が予想されます。
代わりに、独自のデータ レプリケーション テクノロジがある場合は、それを使用して DR 用のセカンダリ リージョン内ゾーンを作成できます。 ワークロードのリージョンによっては、Azure Site Recovery を使用して項目を代替ゾーンにレプリケートできる場合もあります。リージョン別の提供状況とこの機能の詳細については、「Azure 仮想マシンのゾーン間ディザスター リカバリーを有効にする」をご覧ください。
マルチリージョンの HA も可能ですが、Front Door や Traffic Manager などのグローバル ロード バランサーが必要となります。 詳細については、「高可用性を得るために複数の Azure リージョンで N 層アプリケーションを実行する」をご覧ください。
シナリオの詳細
多層または n 層アーキテクチャは、従来のオンプレミス アプリで一般的であるため、オンプレミス アプリをクラウドに移行する場合や、オンプレミスとクラウドの両方のアプリを開発する場合に自然な選択となります。 通常、n 層アーキテクチャは論理層と物理層 (最上位の Web 層またはプレゼンテーション層、中間のビジネス層、データ層) に分かれた IaaS アプリとして実装されます。
n 層 IaaS アプリでは、各層が個別の VM セットで実行されます。 Web 層とビジネス層はステートレスです。つまり、層の任意の VM がその層に対する任意の要求を処理できます。 データ層は、レプリケートされたデータベース、オブジェクト ストレージ、またはファイル ストレージです。 各層の複数の VM によって、1 つの VM に障害が発生した場合の回復性が提供され、ロード バランサーによって VM 間で要求が分散されます。
プールに VM を追加して層をスケールアウトし、仮想マシン スケール セットを使用して同一の VM を自動的にスケールアウトできます。 ロード バランサーを使用しているため、アプリの稼働時間に影響を与えずに各層をスケールアウトできます。
IaaS アプリのサービス レベル アグリーメント (SLA) で > 99% の可用性が必要な場合は、VM を可用性セット、可用性ゾーン、 近接配置グループに配置して、アプリの高可用性を構成できます。 選択する HA および DR ソリューションは、必要な SLA、待機時間の考慮事項、リージョンの DR 要件によって異なります。
考えられるユース ケース
- n 層アプリをオンプレミスからクラウドに移行する。
- オンプレミスとクラウドの両方に n 層アプリをデプロイする。
- IaaS アプリの高可用性とディザスター リカバリーを構成する。
このソリューションは、次のようなシナリオを含め、あらゆる業界で使用できます。
- 公共部門のアプリケーション
- 銀行業 (金融業)
- 医療
考慮事項
AZ はすべての Azure リージョンで利用できるわけではありません。
ソリューションを構築する前に、使用するデプロイ オプションを決定します。 可能ではありますが、デプロイ後に別のオプションに移行するのは簡単なことではありません。 VM を削除し、基になるマネージド ディスクから再作成する必要があります。これは複雑なプロセスです。
選択したソリューションに対してアプリケーションをマップできることを確認します。 アプリ レイヤーの回復性の多数のパターンと設計は、このディシジョン ツリーの範囲外となります。
計画外のハードウェア メンテナンス、予期しないダウンタイム、計画メンテナンスの 3 つのシナリオでは、Azure VM が再起動される可能性があります。 これらのイベントと、その影響を軽減するための HA のベスト プラクティスの詳細については、「VM の再起動について - メンテナンスとダウンタイム」をご覧ください。
単一 VM
アプリに > 99.9% の可用性が必要でない場合は、アプリを HA 用に構成する必要はないので、単一 VM をデプロイできます。 仮想マシン スケール セットを使用して、同一の VM を自動的にスケールアウトできます。 ゾーンを指定せずに単一 VM をデプロイすると、リージョン全体に分散されます。 Azure Premium SSD ディスクを使用した場合、これらのアプリの SLA は 99.9% になります。
単一 VM では、すべての Azure データセンターに組み込まれている既定のサービス復旧機能を使用します。 予測可能な障害の場合、この機能ではライブ マイグレーションが通常使用されますが、予測できないイベントが発生すると、VM が再起動されたり、使用できなくなったりすることがあります。
高可用性
アプリに > 99.9% の SLA が必要な場合は、HA 用にアプリを設計します。 AZ はデータセンターのフォールト トレランスを提供するため、可能であればこれを使用します。 AZ の代わりに AS を使用することもできますが、AS はデータセンターの障害を許容できないため、AS を使用すると可用性が 99.99% から 99.95% に低下します。
AZ は、"アクティブ/アクティブ"、"アクティブ/パッシブ"、または高速フェールオーバーを使用する各層で両方の HA レベルの組み合わせを使用する、クラスター化されたアプリの多くのシナリオ (AlwaysOn SQL クラスターなど) に適しています。 ゾーン間ネットワークの待機時間が短いため、任意のデータベース管理システム (DBMS) ノード間で同期レプリケーションが可能です。 ゾーン間で "ストレッチ クラスター" 構成を実行することもできます。この構成では、待機時間が長くなり、非同期レプリケーションがサポートされます。
VM ベースの "クラスター アービター" ("ファイル共有監視" など) を使用する場合は、いずれかのゾーンで障害が発生した場合にクォーラムが失われないように、3 番目の AZ に配置します。 または、別のリージョンでクラウドベースの監視を使用できる場合もあります。
AZ 内のすべての VM は、単一の "障害ドメイン" (FD) と "更新ドメイン" (UD) にあります。つまり、これらは共通の電源とネットワーク スイッチを共有しているので、全 VM を同時に再起動できます。 異なる AZ に VM を作成すると、VM は異なる FD と UD に効果的に分散されるため、すべての VM で同時に障害が発生したり、同時に再起動されたりすることはありません。 冗長なゾーン内 VM とゾーン間 VM が必要な場合は、ゾーン内 VM を PPG の AS に配置して、一度にすべての VM が再起動されないようにする必要があります。 現在は冗長性のない単一インスタンス VM のワークロードであっても、必要に応じて PPG の AS を使用することで、将来の拡張と柔軟性に対応できます。
AZ に仮想マシン スケール セットをデプロイする場合は、FD と AZ を組み合わせることができるオーケストレーション モード (現在、パブリック プレビュー段階) を使用することを検討してください。
ゾーン内 PPG を含む AZ は、Azure で最も短いネットワーク待機時間と、マルチデータセンターの回復性による 99.99% 以上の SLA を実現します。 可能であれば、VM で高速ネットワークを使用します。
このソリューションは、あるゾーンの VM で実行されているサービスが別のゾーンのサービスとやり取りする必要があるシナリオを提示する場合があります。 たとえば、ゾーン間にアクティブ/アクティブの Web 層とアクティブ/パッシブのデータベース層が存在する場合があります。 一部の要求はゾーンをまたがるため、待機時間が発生します。 ゾーン間の待機時間が非常に短くても、待機時間をできるだけ短くする必要がある場合は、アプリの階層間のすべてのネットワーク通信を 1 つのゾーン内にとどめます。
待機時間に関する考慮事項
ネットワーク待機時間は、特に、デプロイされた VM 間の物理的な距離に左右されます。 アプリで階層間の待機時間を非常に短くする必要がある場合は、各層に AS を含む PPG を使用して、1 つのデータセンターにアプリをデプロイできます。 可能であれば、VM で高速ネットワークを使用します。 このシナリオでは、Azure で最も短いネットワーク待機時間と 99.95% の SLA を実現できます。
次のツールを使用すると、さまざまなシナリオの待機時間の状況についてより的確に把握できます。
- VM 間の待機時間をテストするには、「VM ネットワークの待ち時間のテスト」をご覧ください。
- ゾーン間の待機時間をテストするには、AvZone-Latency-Test を使用します。 このテストを使用すると、サブスクリプションの待機時間が最も短い論理ゾーンを特定できます。
- Azure リージョン間の待機時間をテストするには、http://www.azurespeed.com/ を使用します。 この定期的に更新されるツールは、リージョン間の非同期レプリケーションを検討する際に役立ちます。
障害復旧
DR に関する考慮事項として、"可用性"、正常な状態で稼働し続けるアプリの能力、"データの持続性" (災害が発生した場合のデータの保持) などがあります。
HA フェールオーバーは高速で、データ損失がなく、サービスへの影響が非常に限られています。 これに対して、従来の DR フェールオーバーには、長い目標復旧時間 (RTO) と目標復旧時点 (RPO) が関連付けられている場合があります。また、それは非同期であり、データ損失が発生する可能性があります。
DR ソリューションに別の AZ を使用することで、HA と DR の両方に AZ を利用できます。 ただし、別の AZ を使用しても、各 AZ のデータセンターが物理的に離れた場所に配置されることが保証されるわけではありません。
Azure Site Recovery では、VM を別の Azure リージョンにレプリケートして、リージョンのディザスター リカバリーとビジネス継続性を実現できます。 Azure Site Recovery を使用して、ソース リージョンが停止した場合にアプリを復旧したり、コンプライアンス要件を確実に満たすために定期的なディザスター リカバリー訓練を実施したりできます。
アプリで Azure Site Recovery がサポートされている場合は、アプリの重要度に応じて、リージョンの DR ソリューションを提供して保護を強化できます。 ただし、アプリがデータセンターの障害に対する完全な回復性を備えていれば、ダウンタイムやデータ損失は発生しないため、ゾーン間、データセンター間の HA だけで十分に保護できる場合もあります。
コストの最適化
AZ にデプロイされた VM に追加コストはかかりません。 AZ 間の VM 間データ転送の追加料金が発生する場合があります。 詳細については、帯域幅の料金に関するページをご覧ください。
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパル作成者:
- ショーン・クラウチャー | シニア コンサルタント