このアーキテクチャ例は、Basic Web アプリケーションのアーキテクチャ例に基づいており、次を示すために拡張されています。
- このアーキテクチャ例では、Azure App Service Web アプリケーションでスケーラビリティとパフォーマンスを改善するための実証済みの方法
- 複数のリージョンで Azure App Service アプリケーションを実行して高可用性を実現する方法
アーキテクチャ
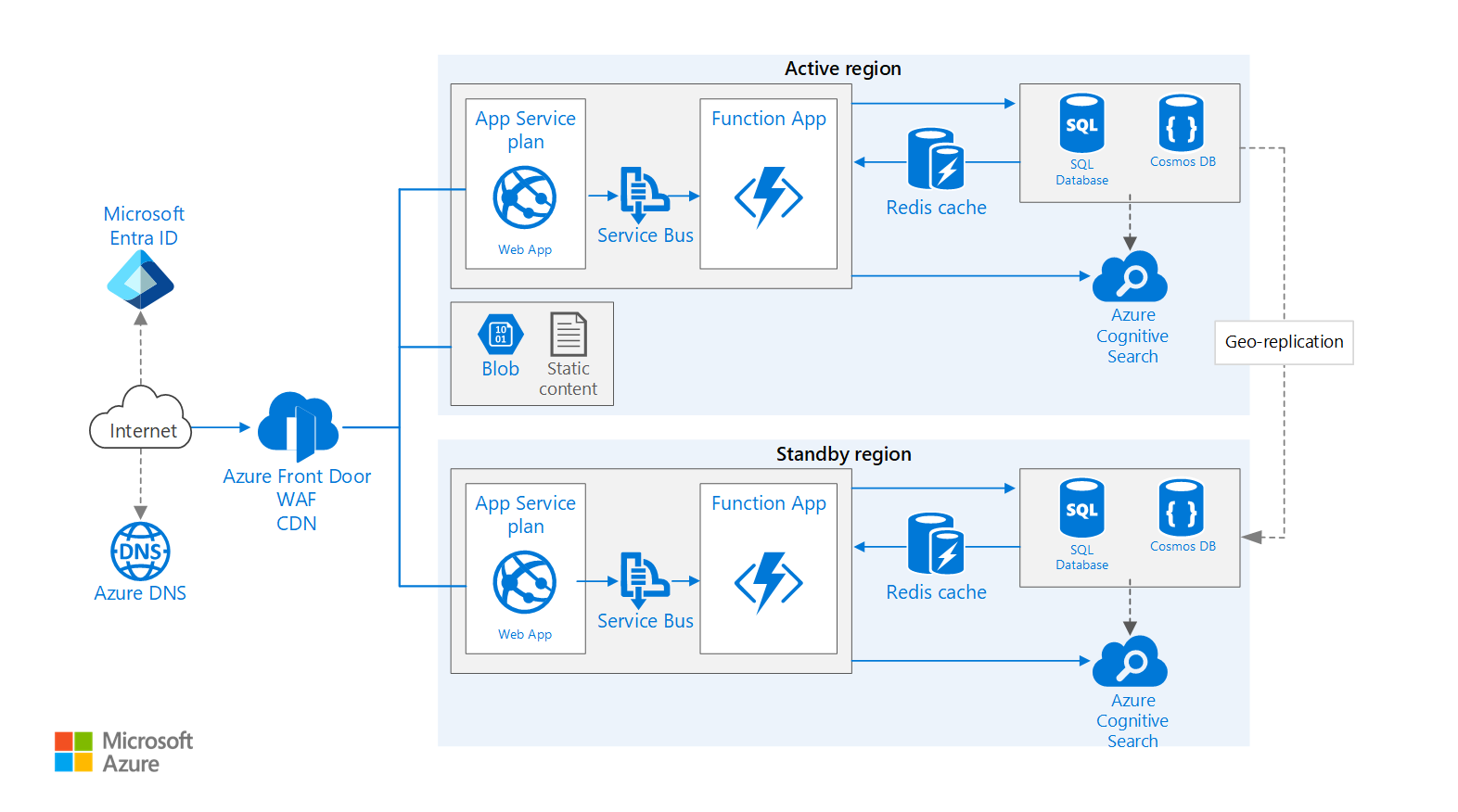
このアーキテクチャの Visio ファイルをダウンロードします。
ワークフロー
このワークフローは、アーキテクチャの複数リージョンの側面に焦点をあて、Basic Web アプリケーションに基づいています。
- プライマリ リージョンとセカンダリ リージョン。 このアーキテクチャでは、2 つのリージョンを使用して、高可用性を実現します。 アプリケーションは、各リージョンにデプロイされます。 通常の運用中は、ネットワーク トラフィックはプライマリ リージョンにルーティングされます。 プライマリ リージョンが使用できなくなった場合、トラフィックはセカンダリ リージョンにルーティングされます。
- Front Door。 Azure Front Door は、複数リージョンの実装に推奨されるロード バランサーです。 Web アプリケーション ファイアウォール (WAF) と統合して、一般的な悪用に対する防御を提供し、Front Door のネイティブ コンテンツ キャッシュ機能を使用します。 このアーキテクチャでは、Front Door は優先順位ルーティング用に構成され、使用できない場合を除き、すべてのトラフィックをプライマリ リージョンに送信します。 プライマリ リージョンが使用できなくなった場合、Front Door はすべてのトラフィックをセカンダリ リージョンにルーティングします。
- ストレージ アカウント、SQL Database、または Azure Cosmos DB の geo レプリケーション。
注意
ネットワーク保護の構成を含む、複数リージョン アーキテクチャ向けの Azure Front Door の使用の詳しい概要については、「ネットワーク セキュアなイングレスの実装」を参照してください。
コンポーネント
このアーキテクチャの実装に使用される主要テクノロジ:
- Microsoft Entra ID は、組織向けに開発されたクラウド アプリに従業員がアクセスできるようにするクラウドベースの ID およびアクセス管理サービスです。
- Azure DNS は、DNS ドメインのホスティング サービスであり、Microsoft Azure インフラストラクチャを使用した名前解決を提供します。 Azure でドメインをホストすることで、その他の Azure サービスと同じ資格情報、API、ツール、課金情報を使用して DNS レコードを管理できます。 カスタム ドメイン名 (
contoso.comなど) を使用するには、カスタム ドメイン名を IP アドレスにマップする DNS レコードを作成します。 詳細については、「 Azure App Service のカスタム ドメイン名の構成」を参照してください。 - Azure Content Delivery Network は、世界各地に戦略的に配置された物理ノードにコンテンツをキャッシュすることで、高帯域幅コンテンツを配信するためのグローバル ソリューションです。
- Azure Front Door はレイヤー 7 のロード バランサーです。 このアーキテクチャでは、これによって HTTP 要求が Web フロント エンドにルーティングされます。 Front Door には、一般的な脆弱性やその悪用からアプリケーションを保護する Web アプリケーション ファイアウォール (WAF) も用意されています。 この設計では、Front Door もコンテンツ配信ネットワーク (CDN) ソリューションに使用されます。
- Azure AppService は、クラウド アプリケーションを作成およびデプロイするためのフル マネージド プラットフォームです。 これにより、Web アプリが実行する一連のコンピューティング リソースを定義し、Web アプリをデプロイし、デプロイ スロットを構成できます。
- Azure Function Apps はバックグラウンド タスクを実行するために使用できます。 関数は、タイマー イベントや、キューに配置されているメッセージなどのトリガーによって呼び出されます。 実行時間の長いステートフル タスクについては、Durable Functions を使用します。
- Azure Storage は、現代的なデータ ストレージ シナリオ向けのクラウド ストレージ ソリューションであり、クラウド内のさまざまなデータ オブジェクトに対して可用性が高く、大規模なスケーリングが可能で、持続性があり、セキュリティで保護されたストレージを提供します。
- Azure Redis Cache は高パフォーマンスのキャッシュ サービスであり、オープンソース実装の Redis Cache に基づいて、データの高速取得のためのメモリ内データ ストアを提供します。
- Azure SQL Database は、クラウドのサービスとしてのリレーショナル データベースです。 SQL Database は、そのコード ベースを Microsoft SQL Server データベース エンジンと共有しています。
- Azure Cosmos DB は、大きなスケールでデータを管理するための、グローバル分散、フル マネージド、低待機時間、マルチモデル、マルチ クエリ API のデータベースです。
- Azure Cognitive Search は検索候補提案、あいまい検索、言語固有検索などの検索機能を追加するために使用できます。 通常、Azure Search は別のデータ ストアと組み合わせて使用されます。プライマリ データ ストアに厳密な一貫性が必要な場合は特にそうです。 この方法では、信頼できるデータを他のデータ ストアに格納し、検索インデックスは Azure Search に格納します。 また、Azure Search は、複数のデータ ストアから単一の検索インデックスに統合する場合にも使用できます。
シナリオの詳細
リージョン間で高可用性を実現する一般的な方法はいくつかあります。
アクティブ/パッシブ (ホット スタンバイ): トラフィックは 1 つのリージョンに送信され、もう一方はホット スタンバイで待機します。 "ホット スタンバイ" とは、セカンダリ リージョン内の App Service が割り当て済みであり、常に実行されていることを意味します。
アクティブ/パッシブ (コールド スタンバイ): トラフィックは 1 つのリージョンに送信され、もう一方はコールド スタンバイで待機します。 コールド スタンバイとは、セカンダリ リージョン内の App Service がフェールオーバーで必要になるまで割り当てられないことを意味します。 この方法のほうが実行コストは低くなりますが、ほとんどの場合、障害発生時にオンラインになるまでの時間が長くなります。
アクティブ/アクティブ: 両方のリージョンがアクティブであり、要求はそれらの間で負荷分散されます。 片方のリージョンが使用できなくなった場合は、ローテーションから外されます。
このリファレンスでは、ホット スタンバイによるアクティブ/パッシブに焦点を当てています。
考えられるユース ケース
これらのユースケースでは、複数リージョンのデプロイのメリットが得られる場合があります。
LoB アプリケーションの事業継続とディザスター リカバリー計画を設計する。
Windows または Linux で実行されるミッション クリティカルなアプリケーションをデプロイする。
アプリケーションを利用可能な状態に保つことで、ユーザー エクスペリエンスを向上させる。
Recommendations
実際の要件は、ここで説明するアーキテクチャとは異なる場合があります。 このセクションに記載されている推奨事項は原案として使用してください。
リージョンのペアリング
各 Azure リージョンは、同じ地区内の別のリージョンとペアリングされます。 通常は、同じリージョン ペアからリージョンを選択します (たとえば、米国東部 2 と米国中部)。 これには、次のような利点があります。
- 広範囲にわたる停止が発生した場合は、すべてのペアで、少なくとも 1 つのリージョンの復旧が優先的に実行されます。
- Azure システムの計画的更新は、起こり得るダウンタイムを最小限に抑えるために、ペアになっているリージョンに対して順にロールアウトされます。
- ほとんどの場合、リージョン ペアは、データの所在地要件を満たすために同じ地区内に所在します。
ただし、両方のリージョンでアプリケーションに必要なすべての Azure サービスがサポートされていることを確認してください。 リージョン別サービスに関する記事を参照してください。 リージョン ペアの詳細については、「ビジネス継続性とディザスター リカバリー (BCDR):Azure のペアになっているリージョン」をご覧ください。
リソース グループ
プライマリ リージョン、セカンダリ リージョン、Front Door を別々のリソース グループにデプロイすることを検討します。 この割り当てにより、各リージョンにデプロイされているリソースを単一のコレクションとして管理できます。
App Service アプリ
Web アプリケーションと Web API は、別の App Service アプリとして作成することをお勧めします。 この設計にすると、別の App Service プランで実行して個別にスケーリングできるようになります。 初期段階でこのレベルのスケーラビリティが不要な場合は、アプリを同じプランにデプロイし、後で必要に応じて別のプランに移行することができます。
注意
Basic、Standard、Premium、および Isolated プランの場合、アプリごとではなく、そのプランの VM インスタンスに対して課金されます。 「App Service の価格」をご覧ください
Front Door の構成
ルーティング。 Front Door では、複数のルーティング メカニズムがサポートされています。 この記事で説明するシナリオでは、"優先順位" によるルーティングを使用します。 この設定では、プライマリ リージョンのエンドポイントが到達不能にならない限り、Front Door ではプライマリ リージョンにすべての要求が送信されます。 到達不能になった時点で、セカンダリ リージョンに自動的にフェールオーバーします。 配信元プールに異なる優先順位の値を設定します。アクティブなリージョンは 1、スタンバイまたはパッシブ リージョンは 2 以上にします。
正常性プローブ。 Front Door は、HTTPS プローブを使って、各バックエンドが使用可能かどうかを監視します。 プローブでは、セカンダリ リージョンにフェールオーバーするための成功/失敗テストが Front Door に提供されます。 それは、特定の URL パスに要求を送信することによって機能します。 タイムアウト期間内に 200 以外の応答を取得した場合、プローブは失敗します。 正常性プローブの頻度、評価に必要なサンプルの数、配信元を正常とマークするために必要な成功サンプルの数を構成できます。 Front Door によって機能低下としてマークされた配信元は、他の配信元にフェールオーバーします。 詳細については、「正常性プローブ」を参照してください。
ベスト プラクティスとして、アプリケーションの全体的な正常性を報告するアプリケーション配信元に正常性プローブ パスを作成します。 この正常性プローブでは、App Service アプリ、ストレージ キュー、SQL Database などの重要な依存関係をチェックする必要があります。 これを行わなかった場合、プローブは、アプリケーションの重要な部分で実際には障害が発生しているにもかかわらず、配信元が正常であると報告する可能性があります。 その一方で、優先度の低いサービスをチェックするために正常性プローブを使用しないでください。 たとえば電子メール サービスがダウンした場合、アプリケーションは、2 つ目のプロバイダーに切り替えるか、後でメールを送信できます。 この設計パターンの詳細については、「正常性エンドポイント監視パターン」を参照してください。
インターネットからの配信元のセキュリティ保護は、パブリックにアクセス可能なアプリの実装の重要な部分です。 Front Door でアプリのイングレス通信をセキュリティ保護するための Microsoft が推奨する設計と実装のパターンについては、「ネットワーク セキュア イングレスの実装」をご覧ください。
CDN。 Front Door のネイティブ CDN 機能を使用して、静的コンテンツをキャッシュします。 CDN の主な利点は、ユーザーに地理的に近いエッジ サーバーにコンテンツがキャッシュされるため、ユーザーの待機時間が短くなることです。 また、トラフィックがアプリケーションで処理されないため、CDN でアプリケーションの負荷を減らすこともできます。 さらに、Front Door によって動的サイト アクセラレーションが提供されるため、静的コンテンツ キャッシュのみの場合より、Web アプリの全体的なユーザー エクスペリエンスを向上できます。
Note
Front Door の CDN は、認証を必要とするコンテンツを提供するように設計されていません。
SQL Database
アクティブ geo レプリケーションと自動フェールオーバー グループを使って、データベースの回復性を高めます。 アクティブ geo レプリケーションを使うと、プライマリ リージョンから 1 つ以上の (最大 4 つ) 他のリージョンにデータベースをレプリケートできます。 自動フェールオーバー グループは、アクティブ geo レプリケーションを基に構築されていて、アプリのコードを変更せずに、セカンダリ データベースにフェールオーバーできるようになります。 フェールオーバーは、ユーザーが作成するポリシー定義に従って、手動または自動で実行できます。 自動フェールオーバー グループを使うには、個々のデータベースの接続文字列ではなく、フェールオーバー グループに対して自動的に作成されるフェールオーバー接続文字列を使って、接続文字列を構成する必要があります。
Azure Cosmos DB
Azure Cosmos DB では、複数の書き込みリージョンを持つアクティブ/アクティブ パターンのリージョン間の geo レプリケーションがサポートされています。 また、あるリージョンを書き込み可能リージョンとして指定し、別のリージョンを読み取り専用レプリカとして指定することもできます。 地域的な停止が発生した場合は、書き込みリージョンにする別のリージョンを選択することで、フェールオーバーできます。 クライアント SDK が書き込み要求を現在の書き込みリージョンに自動的に送信するため、フェールオーバー後にクライアントの構成を更新する必要はありません。 詳細については、「Azure Cosmos DB でのグローバルなデータの分散」を参照してください。
ストレージ
Azure Storage では、読み取りアクセス geo 冗長ストレージ (RA-GRS) を使用します。 データは、RA-GRS を使用して、セカンダリ リージョンにレプリケートされます。 セカンダリ リージョンのデータには、別のエンドポイントを介して読み取り専用でアクセスできます。 geo レプリケートされるストレージ アカウントでは、セカンダリ リージョンへのユーザー開始フェールオーバーがサポートされています。 ストレージ アカウントのフェールオーバーを開始すると、DNS レコードが自動的に更新されて、セカンダリ ストレージ アカウントが新しいプライマリ ストレージ アカウントになります。 フェールオーバーは、必要と思われるときにのみ実行することが必要です。 この要件は組織のディザスター リカバリー計画によって定義されていて、以下の「考慮事項」セクションで説明されているように、その影響を考慮する必要があります。
地域的な停止や災害が発生した場合、Azure Storage チームがセカンダリ リージョンに geo フェールオーバーを実行することを決定する場合があります。 これらの種類のフェールオーバーでは、顧客の操作は必要ありません。 このような場合は、プライマリ リージョンへのフェールバックも Azure ストレージ チームによって管理されます。
場合によっては、ブロック BLOB のオブジェクト レプリケーションがワークロードに対して十分なレプリケーション ソリューションになります。 このレプリケーション機能を使うと、プライマリ ストレージ アカウントからセカンダリ リージョンのストレージ アカウントに、個々のブロック BLOB をコピーできます。 この方法の利点は、レプリケートされるデータを細かく制御できることです。 レプリケーション ポリシーを定義して、レプリケートされるブロック BLOB の種類をさらに細かく制御できます。 ポリシー定義の例を次に示しますが、これらに限定されません。
- ポリシーの作成後に追加されたブロック BLOB のみをレプリケートする
- 特定の日時より後に追加されたブロック BLOB のみをレプリケートする
- 特定のプレフィックスに一致するブロック BLOB のみをレプリケートする
キュー ストレージは、このシナリオで Azure Service Bus への代替メッセージング オプションとして参照されます。 ただし、メッセージング ソリューションにキュー ストレージを使用する場合、geo レプリケーションに関連する上記のガイダンスが、ここにあてはまります。キュー ストレージはストレージ アカウントに存在するためです。 ただし、メッセージはセカンダリ リージョンにレプリケートされず、その状態はリージョンから切り離せないことを理解しておくことが重要です。
Azure Service Bus
Azure Service Bus に提供される最高の回復性を利用するには、名前空間に Premium レベルを使います。 Premium レベルで使用される可用性ゾーンにより、名前空間はデータ センターの停止に対して回復性を持つようになります。 複数のデータ センターに影響を与える広範な障害が発生した場合、Premium レベルに含まれる geo ディザスター リカバリー機能が、復旧に役立つ可能性があります。 geo ディザスター リカバリー機能を使用すると、名前空間 (キュー、トピック、サブスクリプション、フィルター) の構成全体が、確実に、ペアリングされたプライマリ名前空間からセカンダリ名前空間に継続的にレプリケートされるようになります。 これにより、プライマリからセカンダリへの 1 回限りのフェールオーバー移動をいつでも開始できます。 フェールオーバー移動を行うと、名前空間の選択したエイリアス名がセカンダリ名前空間に再指定され、その後にペアリングが解除されます。 フェールオーバーは、開始されるとほぼ瞬時に完了します。
Azure Cognitive Search
Cognitive Search の可用性は、複数のレプリカによって実現されます。一方、事業継続とディザスター リカバリー (BCDR) は、複数の検索サービスによって実現されます。
Cognitive Search では、レプリカとはインデックスのコピーです。 Azure Cognitive Search で複数のレプリカを用意すれば、あるレプリカでコンピューターの再起動やメンテナンスを行い、同時に他のレプリカでクエリの実行を続けることが可能になります。 レプリカの追加については、「レプリカとパーティションの追加または削減」を参照してください。
検索サービスに 2 つ以上のレプリカを追加することで、Availability Zones を Azure Cognitive Search で利用できます。 各レプリカは、リージョン内の異なる可用性ゾーンに配置されます。
BCDR に関する考慮事項については、「個別の地理的リージョン内の複数のサービス」をご覧ください。
Azure Cache for Redis
Azure Cache for Redis のすべてのレベルでは高可用性のために Standard レプリケーションが提供されますが、さらに高いレベルの回復性と復旧可能性を実現するには Premium または Enterprise レベルをお勧めします。 これらのレベルでの回復性と復旧可能性のすべての機能とオプションの一覧については、「高可用性とディザスター リカバリー」をご覧ください。 どのレベルが実際のインフラストラクチャに最適かは、ビジネス要件によって決まります。
考慮事項
以降の考慮事項には、ワークロードの品質向上に使用できる一連の基本原則である Azure "Well-Architected Framework" の要素が組み込まれています。 詳細については、「Microsoft Azure Well-Architected Framework」を参照してください。
[信頼性]
信頼性により、顧客に確約したことをアプリケーションで確実に満たせるようにします。 詳細については、「信頼性の重要な要素の概要」を参照してください。 リージョン間で高可用性を実現するための設計時には、次の点を考慮してください。
Azure Front Door
Azure Front Door は、プライマリ リージョンが使用できなくなると自動的にフェールオーバーします。 Front Door によってフェールオーバーが実行されると、クライアントがアプリケーションに到達できない時間が発生します (通常は約 20 から 60 秒)。 この持続時間は、次の要因に影響されます。
- 正常性プローブの頻度。 正常性プローブの送信頻度が高いほど、Front Door によってダウンタイムを検出されたり、配信元が正常な状態に復元されるまでの時間が短縮されたりする可能性があります。
- サンプル サイズの構成。 この構成によって、プライマリ配信元が到達不能になったことを正常性プローブで検出するために必要なサンプル数を制御します。 この値が低すぎると、間欠的な問題から誤検知を受け取る可能性があります。
Front Door は、システムの障害ポイントになる可能性があります。 このサービスに障害が発生すると、クライアントは、ダウンタイム中はアプリケーションにアクセスできなくなります。 Front Door のサービス レベル アグリーメント (SLA) に関するページを確認し、Front Door の使用だけで高可用性のビジネス要件が満たされるかどうかを判断してください。 満たされない場合は、フォールバックとして別のトラフィック管理ソリューションを追加することを検討してください。 Front Door サービスで障害が発生した場合は、他のトラフィック管理サービスを参照するように、DNS の正規名 (CNAME) レコードを変更します。 この手順は手動で実行する必要があり、DNS の変更が反映されるまでアプリケーションを使用することはできません。
Azure Front Door Standard および Premium レベルは、Azure Front Door (クラシック)、Microsoft の Azure CDN Standard (クラシック)、Azure WAF の機能を 1 つのプラットフォームに統合したものです。 Azure Front Door Standard または Premium を使用すると、障害点が減り、制御、監視、セキュリティが強化されます。 詳細については、「Azure Front Door のレベルの概要」を参照してください。
SQL Database
「Azure SQL Database によるビジネス継続性の概要」に、SQL Database の目標復旧時点 (RPO) と推定目標復旧時間 (RTO) の説明があります。
アクティブ geo レプリケーションでは、レプリケートされる各データベースのコストが実質的に 2 倍になることに注意してください。 サンドボックス、テスト、開発の各データベースは、通常、レプリケーションには推奨されません。
Azure Cosmos DB
Azure Cosmos DB の RPO と目標復旧時間 (RTO) は、使用されている整合性レベルを通じて構成できます。これにより、可用性、データの持続性、スループットのトレードオフが発生します。 Azure Cosmos DB は、マルチマスターを使用した緩やかな整合性レベルの場合は最小 RTO 0 を、シングルマスターを使用した厳密な整合性の場合は RPO 0 を提供します。 Azure Cosmos DB の整合性レベルの詳細については、Azure Cosmos DB での整合性レベルとデータの持続性に関するページを参照してください。
ストレージ
RA-GRS ストレージは持続的なストレージを提供しますが、フェールオーバーの実行を検討するときは、次の要素を考慮することが重要です。
データ損失の可能性: セカンダリ リージョンへのデータのレプリケーションは非同期で実行されます。 そのため、geo フェールオーバーが実行された場合、プライマリ アカウントへの変更がセカンダリ アカウントに完全に同期されないと、データ損失が予想されます。 セカンダリ ストレージ アカウントの最終同期時刻プロパティを調べて、プライマリ リージョンのデータがセカンダリ リージョンに正常に書き込まれた最終時刻を確認できます。
目標復旧時間 (RTO) を適切に計画する: 通常、セカンダリ リージョンへのフェールオーバーには約 1 時間かかるため、DR 計画で RTO パラメーターを計算するときにこの情報を考慮する必要があります。
フェールバックを慎重に計画する: ストレージ アカウントがフェールオーバーするときに、元のプライマリ アカウントのデータが失われることを理解しておくことが重要です。 慎重な計画を行わずにプライマリ リージョンにフェールバックしようとすると、危険です。 フェールオーバーが完了すると、フェールオーバー リージョン内の新しいプライマリが、ローカル冗長ストレージ (LRS) 用に構成されます。 それをプライマリ リージョンへのレプリケーションを開始するための geo レプリケートされるストレージとして手動で再構成した後、アカウントが同期されるのに十分な時間を設ける必要があります。
ネットワークの停止などの一時的なエラーでは、ストレージのフェールオーバーはトリガーされません。 一時的な障害に対する回復力を持つようにアプリケーションを設計してください。 対応策のオプションには次のものがあります。
- セカンダリ リージョンから読み取ります。
- 新しい書き込み操作のために別のストレージ アカウントに (たとえばキュー メッセージに) 一時的に切り替えます。
- データをセカンダリ リージョンから別のストレージ アカウントにコピーします。
- システムが元の状態に戻るまで、機能を制限します。
詳細については、「Azure Storage の停止が発生した場合の対処方法」をご覧ください。
ブロック BLOB にオブジェクト レプリケーションを使用するときの考慮事項については、「オブジェクト レプリケーションの前提条件と注意事項」をご覧ください。
Azure Service Bus
Premium レベルの Azure Service Bus に含まれる geo ディザスター リカバリー機能を使うと、同じ構成で操作をすぐに継続できることを理解しておくことが重要です。 ただし、キューやトピック サブスクリプションまたは配信不能キューに保持されているメッセージはレプリケートされません。 そのため、セカンダリ リージョンへのスムーズなフェールオーバーのためには軽減戦略が必要です。 その他の考慮事項と軽減策について詳しくは、「考慮すべき重要な点」とディザスター リカバリーでの考慮事項に関する記事をご覧ください。
セキュリティ
セキュリティは、重要なデータやシステムの意図的な攻撃や悪用に対する保証を提供します。 詳細については、「セキュリティの重要な要素の概要」を参照してください。
受信トラフィックの制限 アプリケーションが Front Door からのトラフィックのみを受け入れるように構成します。 これにより、アプリに到達する前にすべてのトラフィックが WAF を経由するようになります。 詳細については、「バックエンドへのアクセスを Azure Front Door のみにロックダウンするにはどうしたらよいですか?」を参照してください。
クロスオリジン リソース共有 (CORS) Web サイトと Web API を別のアプリとして作成する場合、CORS を有効にしない限り、Web サイトは API に対してクライアント側 AJAX の呼び出しを行うことはできません。
注意
ブラウザーのセキュリティ機能により、Web ページでは AJAX 要求を別のドメインに送信することはできません。 この制限は、同一オリジン ポリシーと呼ばれ、悪意のあるサイトが、別のサイトから機密データを読み取れないようにします。 CORS は W3C 標準であり、サーバーによる同一オリジン ポリシーの緩和を許可し、一部のクロスオリジン要求を許可して他の要求を拒否することができます。
App Service には CORS のサポートが組み込まれているため、アプリケーション コードを作成する必要はありません。 CORS を使用して JavaScript から API アプリを使用する方法に関するページを参照してください。 API の許可されているオリジンの一覧に Web サイトを追加します。
SQL Database 暗号化 データベースの保存データを暗号化する必要がある場合は、Transparent Data Encryption を使用します。 この機能で、(バックアップとトランザクション ログ ファイルを含む) データベース全体のリアルタイムの暗号化と復号が実行されるので、アプリケーションを変更する必要はありません。 暗号化で、ある程度の待機時間が増えるので、セキュリティで保護する必要があるデータを独自のデータベースに分離し、そのデータベースについてのみ暗号化を有効にすることをお勧めします。
ID このアーキテクチャでコンポーネントの ID を定義するときは、可能な限りシステム マネージド ID を使用して、資格情報を管理する必要性と資格情報の管理に伴うリスクを軽減します。 システム マネージド ID を使用できない場合は、すべてのユーザー マネージド ID が 1 つのリージョン内にのみ存在し、リージョンの境界をまたいで共有されることがないようにします。
サービス ファイアウォール コンポーネントのサービス ファイアウォールを構成するときは、リージョン ローカルなサービスのみがそれらのサービスにアクセスできることと、それらのサービスが送信接続のみを許可していることの両方を確認します。これはレプリケーションとアプリケーションの機能のために必ず必要なことです。 制御とセグメント化をさらに強化するために、Azure Private Link の使用を検討してください。 Web アプリケーションのセキュリティ保護の詳細については、「ベースラインの高可用性ゾーン冗長 Web アプリケーション」を参照してください。
コストの最適化
コストの最適化とは、不要な費用を削減し、運用効率を向上させる方法を検討することです。 詳しくは、コスト最適化の柱の概要に関する記事をご覧ください。
キャッシュ キャッシュを使用して頻繁には変更されないコンテンツを処理するサーバーの負荷を削減します。 ページのレンダリング サイクルではすべてコンピューティング、メモリ、帯域幅が消費されるため、それがコストに影響する場合があります。 JavaScript シングルページ アプリやメディア ストリーミング コンテンツなどの静的コンテンツ サービスの場合は、キャッシュを使用すると、これらのコストを特に大幅に削減できます。
アプリに静的コンテンツが含まれている場合は、CDN を使用してフロント エンド サーバーの負荷を削減します。 頻繁には変更されないデータの場合は、Azure Cache for Redis を使用します。
状態 自動スケーリング用に構成されているステートレス アプリは、ステートフル アプリより費用効果が高くなります。 セッション状態を使用する ASP.NET アプリケーションの場合、Azure Cache for Redis でこれをメモリ内に格納します。 詳細については、「Azure Cache for Redis の ASP.NET セッション状態プロバイダー」を参照してください。 別のオプションとしては、セッション状態プロバイダー経由のバックエンド状態ストアとして Azure Cosmos DB を使用する方法があります。 「Azure Cosmos DB を ASP.NET セッション状態プロバイダーとキャッシュ プロバイダーとして使用する」を参照してください。
関数 バックグラウンド タスクが HTTP 要求を処理するのと同じインスタンス上で実行されないように、関数アプリを専用の App Service プランに配置することを検討します。 バックグラウンド タスクが断続的に実行される場合は、従量課金プランの使用を検討します。このプランでは、時間単位ではなく、実行数と使用されるリソースに基づいて課金されます。
詳細については、「Microsoft Azure Well-Architected Framework」のコストのセクションを参照してください。
コストを見積もるには、料金計算ツールを使用します。 このセクションの次の推奨事項がコストの削減に役立つことがあります。
Azure Front Door
Azure Front Door の課金には、送信データ転送、受信データ転送、ルーティング規則の 3 つの価格レベルがあります。 詳細については、Azure Front Door の価格に関するページを参照してください。 この価格のグラフには、配信元サービスからのデータへのアクセスや Front Door への転送のコストは含まれません。 これらのコストは、「帯域幅の料金詳細」で説明されているデータ転送の料金に基づいて課金されます。
Azure Cosmos DB
Azure Cosmos DB の価格を決定する要因として、次の 2 つがあります。
プロビジョニングされているスループットまたは要求ユニット/秒 (RU/秒)。
Azure Cosmos DB でプロビジョニングできるスループットは、標準と自動スケーリングの 2 種類があります。 標準スループットを使用すると、指定された RU/秒を保証するために必要なリソースが割り当てられます。 自動スケーリングの場合、最大スループットをプロビジョニングすると、Azure Cosmos DB は、最大自動スケーリング スループットの最小値 10% で、負荷に応じてすぐにスケール アップまたはスケール ダウンします。 標準スループットは、プロビジョニングされたスループットに対して 1 時間ごとに課金されます。 自動スケーリング スループットは、消費された最大スループットに対して 1 時間ごとに課金されます。
消費されたストレージ。 特定の 1 時間にデータおよびインデックスで消費されたストレージの合計量 (GB) に対して固定料金が請求されます。
詳細については、「Microsoft Azure Well-Architected Framework」のコストのセクションを参照してください。
パフォーマンス効率
Azure App Service の主な利点は、負荷に応じてアプリケーションをスケーリングできることです。 アプリケーションのスケーリングを計画する場合の考慮事項を次に示します。
App Service アプリ
ソリューションに複数の App Service アプリが含まれる場合は、別の App Service プランにデプロイすることを検討してください。 この方法にすると、別インスタンス上で実行されるので、個別にスケーリングすることができます。
SQL Database
データベースをシャード化することで、SQL Database のスケーラビリティを向上します。 シャード化とは、データベースを水平方向にパーティション分割することを指します。 シャード化すると、Elastic Database ツールを使用してデータベースを水平方向にスケール アウトできます。 シャード化には、次のような利点があります。
- トランザクション スループットの改善。
- データのサブセットに対するクエリの実行が高速になります。
Azure Front Door
Front Door で SSL のオフロードを実行し、バックエンド Web アプリとの TCP 接続の合計数を減らすこともできます。 これにより、Web アプリで管理される SSL ハンドシェイクと TCP 接続が少数になるので、スケーラビリティが向上します。 Web アプリに HTTPS として要求を転送した場合でも、接続の再利用率が高いため、このようにパフォーマンスが向上します。
Azure Search
Azure Search は、プライマリ データ ストアから複雑なデータ検索を実行するオーバーヘッドを取り除き、負荷を処理できるようにスケーリングできます。 Azure Search でクエリとインデックス作成のワークロードに応じたリソース レベルのスケーリングに関するページをご覧ください。
オペレーショナル エクセレンス
オペレーショナル エクセレンスとは、アプリケーションをデプロイし、運用環境でそれを動かし続ける運用プロセスのことであり、Well-Architected フレームワークの信頼性ガイダンスを拡張したものです。 このガイダンスでは、確実にワークロードを使用でき、あらゆる規模の障害から復旧できるようにするために、アプリケーション フレームワークに回復性を組み込む方法の詳細な概要を示します。 このアプローチの中心となる考え方は、アプリケーションのインフラストラクチャを高可用性になるように (最適なのは、この設計で示すように複数の地理的リージョンで) 設計することです。
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパル作成者:
- Arvind Boggaram Pandurangaiah Setty |シニア コンサルタント
パブリックでない LinkedIn プロファイルを表示するには、LinkedIn にサインインします。
次のステップ
エンドポイント監視パターンに基づいてアプリケーションの全体的な正常性を報告する正常性プローブを作成する
関連リソース
マルチリージョン N 層アプリケーションは同様のシナリオです。 複数の Azure リージョンで実行されている N 層アプリケーションを示しています