Azure Monitor での Prometheus メトリックの収集のトラブルシューティング
Azure Monitor で Prometheus メトリックが期待どおりに収集されない原因を特定するには、この記事の手順のようにします。
Replica ポッドでは、kube-state-metrics からのメトリックと、ama-metrics-prometheus-config configmap のカスタム スクレイピング ターゲットをスクレイピングします。 DaemonSet ポッドでは、それぞれのノード上のターゲット kubelet、cAdvisor、node-exporter からのメトリック、および ama-metrics-prometheus-config-node configmap のカスタム スクレイピング ターゲットをスクレイピングします。 どのポッドについてログと Prometheus UI を表示するかは、調べるスクレイピング ターゲットによって異なります。
PowerShell スクリプトを使用したトラブルシューティング
AKS クラスターの監視を有効にしようとしたときにエラーが発生した場合は、こちらの手順に従ってトラブルシューティング スクリプトを実行してください。 このスクリプトは、クラスターの構成の問題に対して基本的な診断を行うように設計されており、生成されたファイルを ch しながら、サポート ケースの迅速な解決のためのサポート リクエストを作成できます。
メトリックの調整
Azure portal で Azure Monitor ワークスペースに移動します。 Metrics に移動し、メトリック Active Time Series % Utilization と Events Per Minute Ingested % Utilization が 100% を下回っていることを確認します。

いずれかが 100% を超える場合は、このワークスペースへのインジェストが調整されます。 同じワークスペースで、New Support Request に移動して、制限を引き上げる要求を作成します。 イシューの種類を Service and subscription limits (quotas) として選択し、クォータの種類を Managed Prometheus として選択します。
メトリック データ収集の断続的なギャップ
ノードの更新中に、クラスター レベルのコレクターから収集されたメトリックのメトリック データに 1 分から 2 分のギャップが表示される場合があります。 このギャップは、実行されているノードが通常の更新プロセスの一環として更新されているために発生します。 指定された kube-state-metrics やカスタム アプリケーション ターゲットなどのクラスター全体のターゲットが影響を受けます。 これは、クラスターが手動または自動更新によって更新されるときに発生します。 この動作は想定されているものであり、実行されているノードが更新されるために発生します。 推奨されるアラート ルールは、いずれもこの動作の影響を受けません。
ポッドの状態
次のコマンドでポッドの状態を調べます。
kubectl get pods -n kube-system | grep ama-metrics
- クラスター上の各ノードに、1 つの
ama-metrics-xxxxxxxxxx-xxxxxレプリカ ポッド、1 つのama-metrics-ksm-*ポッド、ama-metrics-node-*ポッドが存在する必要があります。 - 各ポッドの状態が
Runningになっていて、適用された ConfigMap の変更の数と同じ数の再起動が行われている必要があります。

各ポッドの状態が Running であるにも関わらず、1 つ以上のポッドに再起動がある場合は、次のコマンドを実行します。
kubectl describe pod <ama-metrics pod name> -n kube-system
- このコマンドにより、再起動の理由が示されます。 ConfigMap の変更が行われた場合、ポッドの再起動が予想されます。 再起動の理由が
OOMKilledである場合、ポッドはメトリックの量に追いつくことができません。 メトリックの量に関するスケールの推奨事項を参照してください。
ポッドが想定どおりに実行されている場合、次に調べる場所はコンテナー ログです。
コンテナー ログ
次のコマンドを使ってコンテナー ログを表示します。
kubectl logs <ama-metrics pod name> -n kube-system -c prometheus-collector
起動時の初期エラーは赤で表示され、警告は黄色で表示されます。 (色付きのログを表示するには、少なくとも PowerShell バージョン 7 または Linux ディストリビューションが必要です)。
- 認証トークンの取得に問題があるかどうかを確認します。
- "AKS リソースの構成が存在しない" というメッセージは、5 分ごとにログされます。
- ポッドは 15 分ごとに再起動し、"AKS リソースの構成が存在しない" というエラーがあるともう一度試します。
- その場合は、データ収集ルールとデータ収集エンドポイントがリソース グループに存在することをチェックします。
- また、Azure Monitor ワークスペースが存在することも確認します。
- プライベート AKS クラスターがなく、他のサービスの Azure Monitor のプライベート リンク スコープにリンクされていないことを確認します。 このシナリオは現在サポートされていません。
- Prometheus 構成の解析、有効になっている既定のスクレイピング ターゲットとのマージ、完全な構成の検証に関するエラーがないことを確認します。
- カスタム Prometheus 構成を含めた場合は、ログで認識されていることを確認します。 等しくない場合は、次の作業を行います。
- configmap の
kube-system名前空間に正しい名前ama-metrics-prometheus-configがあることを確認します。 - configmap で、Prometheus の構成が次のように
dataの下のprometheus-configというセクションの下にあることを確認します。kind: ConfigMap apiVersion: v1 metadata: name: ama-metrics-prometheus-config namespace: kube-system data: prometheus-config: |- scrape_configs: - job_name: <your scrape job here>
- configmap の
- Azure Monitor ワークスペースでの認証に関する
MetricsExtensionからのエラーがないことを確認します。 - ターゲットのスクレイピングに関する
OpenTelemetry collectorからのエラーがないことを確認します。
次のコマンドを実行します。
kubectl logs <ama-metrics pod name> -n kube-system -c addon-token-adapter
- このコマンドにより、Azure Monitor ワークスペースでの認証に問題がある場合は、エラーが示されます。 次の例は、問題がない場合のログを示しています。
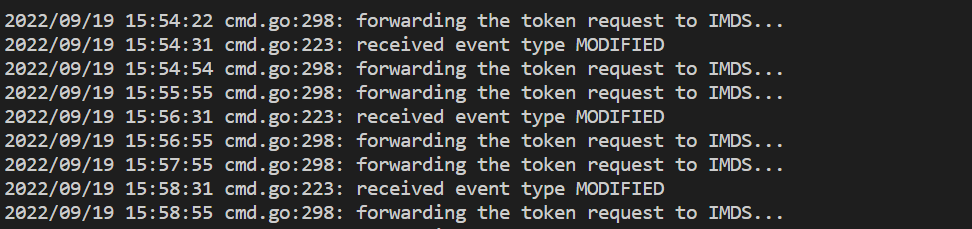

ログにエラーがない場合、Prometheus インターフェイスを使ってデバッグを行い、想定される構成とターゲットがスクレイピングされていることを確認できます。
Prometheus インターフェイス
すべての ama-metrics-* ポッドには、ポート 9090 で使用可能な Prometheus エージェント モードのユーザー インターフェイスがあります。 レプリカ ポッドまたはデーモン セット ポッドのいずれかにポートフォワードして、説明されているように構成、サービス検出、ターゲット エンドポイントをチェックし、カスタム構成が正しいこと、目的のターゲットがジョブごとに検出されていること、特定のターゲットをスクレイピングするエラーがないことを確認します。
コマンド kubectl port-forward <ama-metrics pod> -n kube-system 9090 を実行します。
ブラウザーを開いてアドレス
127.0.0.1:9090/configにアクセスします。 このユーザー インターフェイスには、完全なスクレイピング構成があります。 すべてのジョブが構成に含まれていることを確認します。
127.0.0.1:9090/service-discoveryにアクセスし、指定されたサービス検出オブジェクトによって検出されたターゲットと、ターゲットをフィルター処理した relabel_configs を確認します。 たとえば、特定のポッドからのメトリックがないときは、そのポッドが検出されたかどうか、およびその URI が何であるかを確認できます。 その後、ターゲットを参照するときにこの URI を使って、スクレイピング エラーがあるかどうかを確認できます。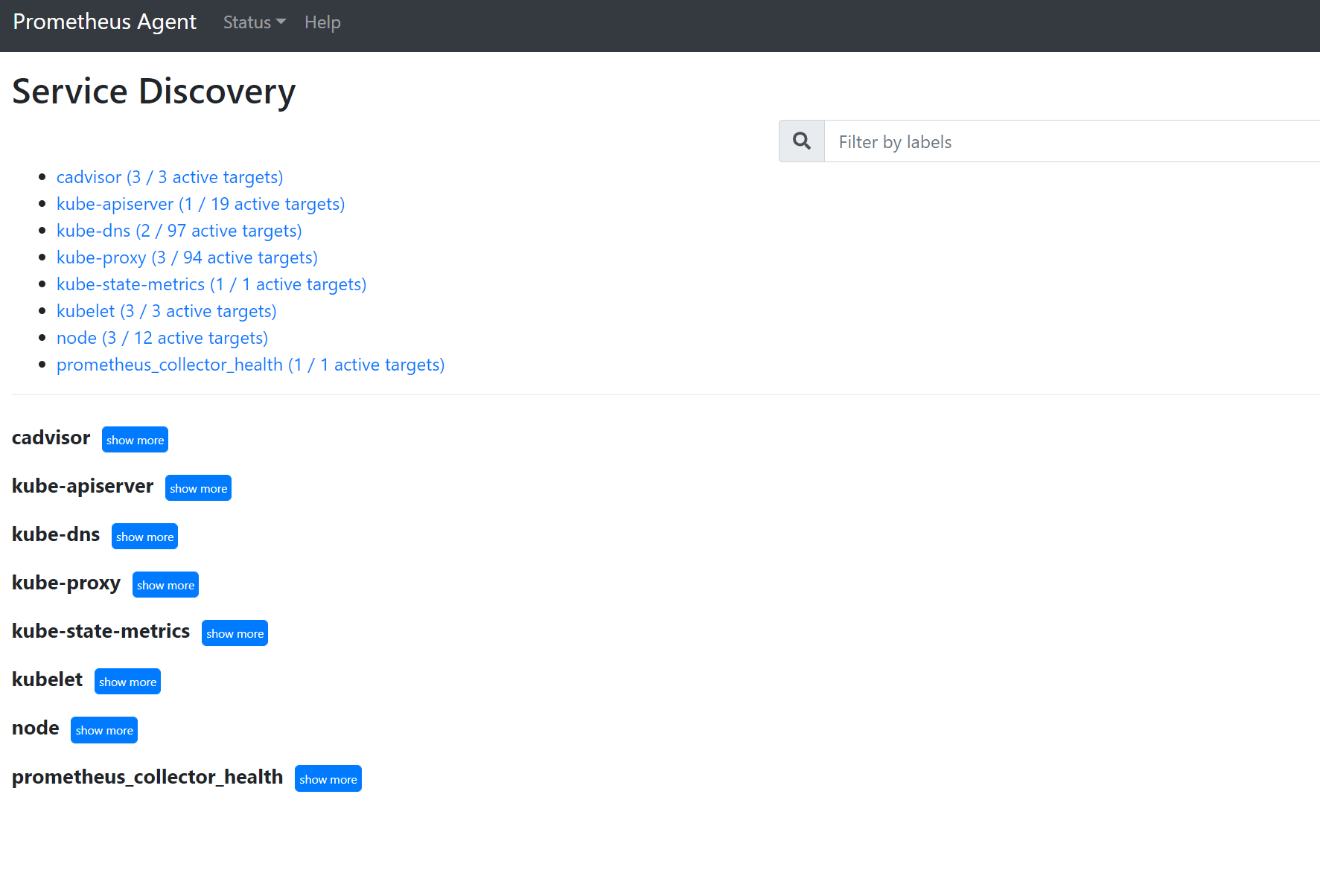
127.0.0.1:9090/targetsにアクセスして、すべてのジョブ、そのジョブのエンドポイントが最後にスクレイピングされた日時、およびエラーを確認します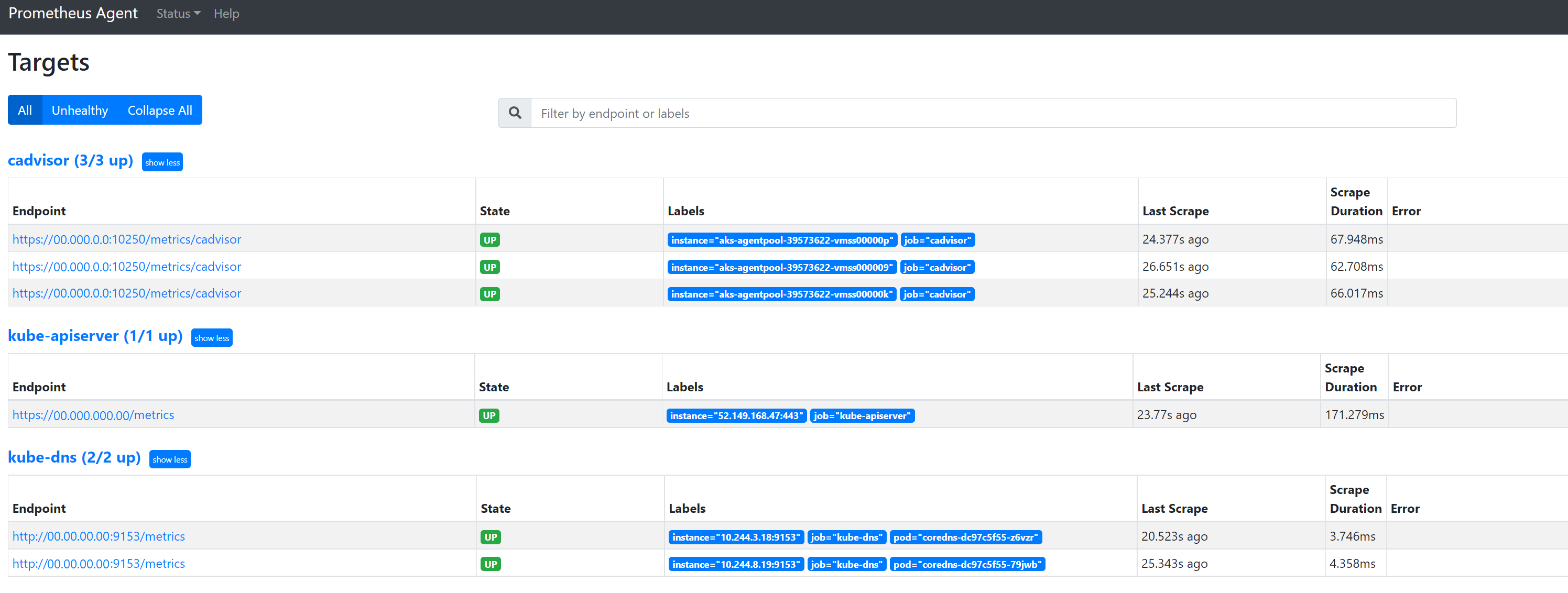



問題がなく、目的のターゲットがスクレイピングされている場合は、デバッグ モードを有効にすることで、スクレイピングされている正確なメトリックを確認できます。
デバッグ モード
警告
このモードはパフォーマンスに影響を与える可能性があり、デバッグのために短時間だけ有効にする必要があります。
こちらの手順に従って debug-mode の下にある ConfigMap の設定 enabled を true に変更することで、デバッグ モードで実行するようにメトリック アドオンを構成できます。
有効にすると、スクレイピングされたすべての Prometheus メトリックがポート 9091 でホストされます。 次のコマンドを実行します。
kubectl port-forward <ama-metrics pod name> -n kube-system 9091
ブラウザーで 127.0.0.1:9091/metrics にアクセスし、メトリックが OpenTelemetry コレクターによってスクレイピングされたかどうかを確認します。 すべての ama-metrics-* ポッドで、このユーザー インターフェイスにアクセスできます。 メトリックがない場合は、メトリックまたはラベル名の長さ、またはラベルの数に関する問題がある可能性があります。 また、この記事で示されているように、Prometheus メトリックのインジェスト クォータの超過についてもチェックします。
メトリック名、ラベル名、ラベルの値
現在、エージェント ベースのスクレイピングには、次の表の制限があります。
| プロパティ | 制限 |
|---|---|
| ラベル名の長さ | 511 文字以下。 ジョブのいずれかの時系列でこの制限を超えると、スクレイピング ジョブ全体が失敗し、インジェストの前にそのジョブからメトリックが削除されます。 そのようなジョブには up=0 と表示され、ターゲットの Ux には up=0 の理由が表示されます。 |
| ラベル値の長さ | 1023 文字以下。 ジョブのいずれかの時系列でこの制限を超えると、スクレイピング全体が失敗し、インジェストの前にそのジョブからメトリックが削除されます。 そのようなジョブには up=0 と表示され、ターゲットの Ux には up=0 の理由が表示されます。 |
| 時系列ごとのラベルの数 | 63 以下。 ジョブのいずれかの時系列でこの制限を超えると、スクレイピング ジョブ全体が失敗し、インジェストの前にそのジョブからメトリックが削除されます。 そのようなジョブには up=0 と表示され、ターゲットの Ux には up=0 の理由が表示されます。 |
| メトリック名の長さ | 511 文字以下。 ジョブのいずれかの時系列でこの制限を超えると、その特定の系列のみが削除されます。 MetricextensionConsoleDebugLog には、削除されたメトリックのトレースがあります。 |
| 大文字と小文字が異なるラベル名 | 大文字と小文字が異なる同じメトリック サンプル内の 2 つのラベルは、重複するラベルを持つものとして扱われ、取り込まれると削除されます。 たとえば、ExampleLabel と examplelabel は同じラベル名と見なされるため、重複するラベルが原因で時系列 my_metric{ExampleLabel="label_value_0", examplelabel="label_value_1} が削除されます。 |
Azure Monitor ワークスペースのインジェスト クォータを確認する
メトリックが見つからない場合は、まず、Azure Monitor ワークスペースのインジェスト制限を超えているかチェックできます。 Azure portal では、Azure Monitor ワークスペースの現在の使用状況をチェックできます。 現在の使用状況メトリックは、Azure Monitor ワークスペースの Metrics メニューで確認できます。 次の使用率メトリックは、各 Azure Monitor ワークスペースの標準メトリックとして使用できます。
- アクティブな時系列 - 過去 12 時間にワークスペースに最近取り込まれた一意の時系列の数
- アクティブな時系列の制限 - ワークスペースにアクティブに取り込むことができる一意の時系列の数の制限
- アクティブな時系列の使用率 - 現在のアクティブな時系列の使用率
- 取り込まれた 1 分あたりのイベント数 - 最近受信した 1 分あたりのイベント (サンプル) 数
- 1 分あたりのイベントの取り込み制限 - 調整される前に取り込むことができる 1 分あたりのイベントの最大数
- 1 分あたりのイベントの取り込み使用率 - 現在のメトリック インジェスト率制限の使用率
既定のクォータについては、サービスのクォータと制限に関するページを参照してください。また、使用量に基づいて何を増やすことができるかを理解してください。 Azure Monitor ワークスペースの Support Request メニューを使用して、Azure Monitor ワークスペースのクォータの引き上げを要求できます。 サポート 要求には、Azure Monitor ワークスペースの ID、内部 ID、場所またはリージョンが含まれている必要があります。これは、Azure portal の Azure Monitor ワークスペースの [プロパティ] メニューにあります。