Azure SQL Database のフェールオーバー グループを構成する
適用対象:![]() Azure SQL Database
Azure SQL Database
このトピックでは、Azure portal、Azure PowerShell と Azure CLI を使用して、Azure SQL データベース内の単一データベースとプールされたデータベースのフェールオーバー グループを構成する方法について説明します。
エンド ツー エンドスクリプトについては、 Azure PowerShellまたは Azure CLI を使用してフェールオーバー グループに単一データベースを追加する方法を確認します。
前提条件
単一データベースのフェールオーバー グループを作成するには、次の前提条件を考慮してください。
- セカンダリ サーバーのサーバー ログインとファイアウォールの設定は、プライマリ サーバーのものと一致している必要があります。
フェールオーバー グループの作成
フェールオーバー グループを作成し、Azure portal を使用して単一データベースを追加します。
Azure portal の左側のメニューで [Azure SQL] を選択します。 [Azure SQL] が一覧にない場合は、 [すべてのサービス] を選択し、検索ボックスに「Azure SQL」と入力します。 (省略可能) [Azure SQL] の横にある星を選択してお気に入りに追加し、左側のナビゲーションに項目として追加します。
フェールオーバー グループに追加するデータベースを選択します。
[サーバー名] の下にあるサーバーの名前を選択し、サーバーの設定を開きます。

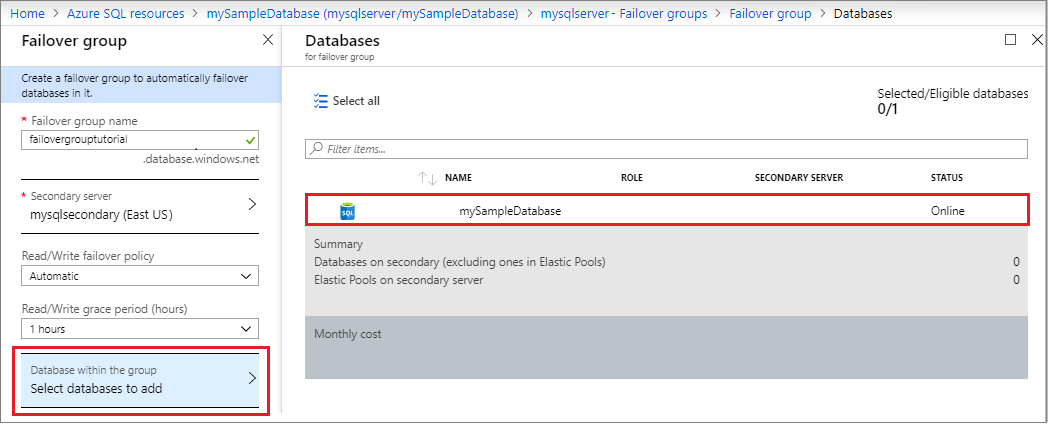
[設定] ウィンドウで [フェールオーバー グループ] を選択し、 [グループの追加] を選択して新しいフェールオーバー グループを作成します。
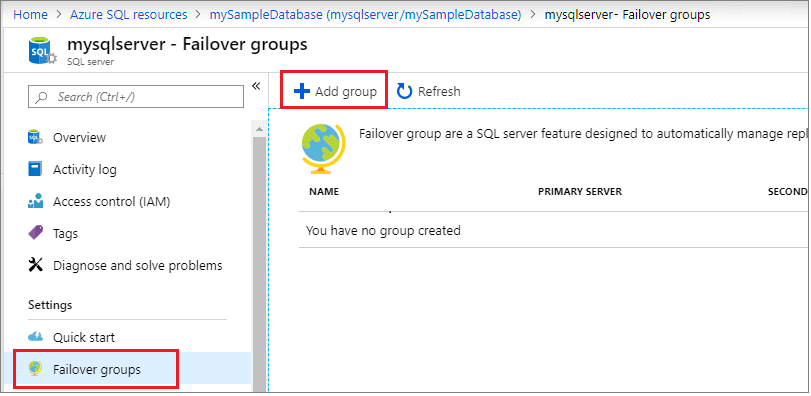
[フェールオーバー グループ] ページで、必要な値を入力するか選択してから、 [作成] を選択します。 新しいセカンダリ サーバーを作成するか、既存のセカンダリ サーバーを選択します。 フェイルオーバー・グループのセカンダリ・サーバは、プライマリ・サーバとは異なる地域にある必要があります。
- グループ内のデータベース:フェールオーバー グループに追加するデータベースを選択します。 フェールオーバー グループにデータベースを追加すると、geo レプリケーション プロセスが自動的に開始されます。
計画フェールオーバーをテストします
Azure portal または PowerShell を使用して、フェールオーバー グループのフェールオーバーを損失なしでテストします。
Azure portal を使用して、フェールオーバー グループのフェールオーバーをテストします。
Azure portal の左側のメニューで [Azure SQL] を選択します。 [Azure SQL] が一覧にない場合は、[すべてのサービス] を選択してから、検索ボックスに「Azure SQL」と入力します。 (省略可能) [Azure SQL] の横にある星を選択してお気に入りに追加し、左側のナビゲーションに項目として追加します。
フェールオーバー グループに追加するデータベースを選択します。
[設定] ウィンドウで [フェールオーバーグループ] を選択し、先ほど作成したフェールオーバー グループを選択します。
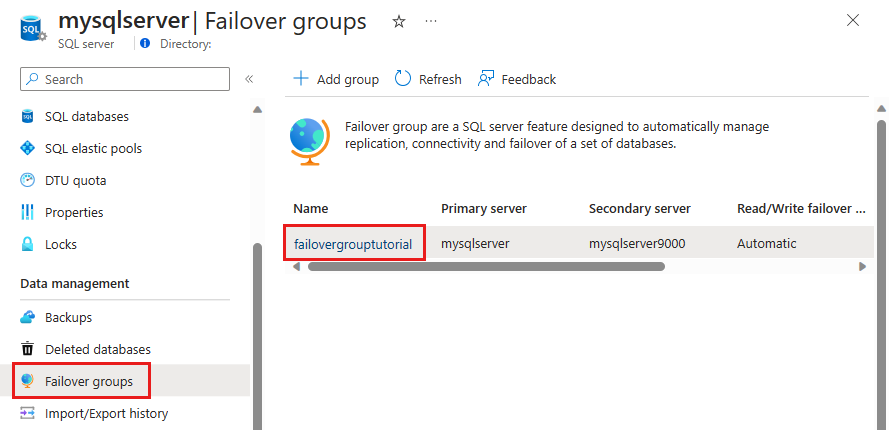
どのサーバーがプライマリで、どのサーバーがセカンダリかを確認します。
作業ウィンドウで [フェールオーバー] を選択し、データベースが含まれるフェールオーバー グループをフェールオーバーします。
TDS セッションが切断されることが通知される警告で [はい] を選択します。
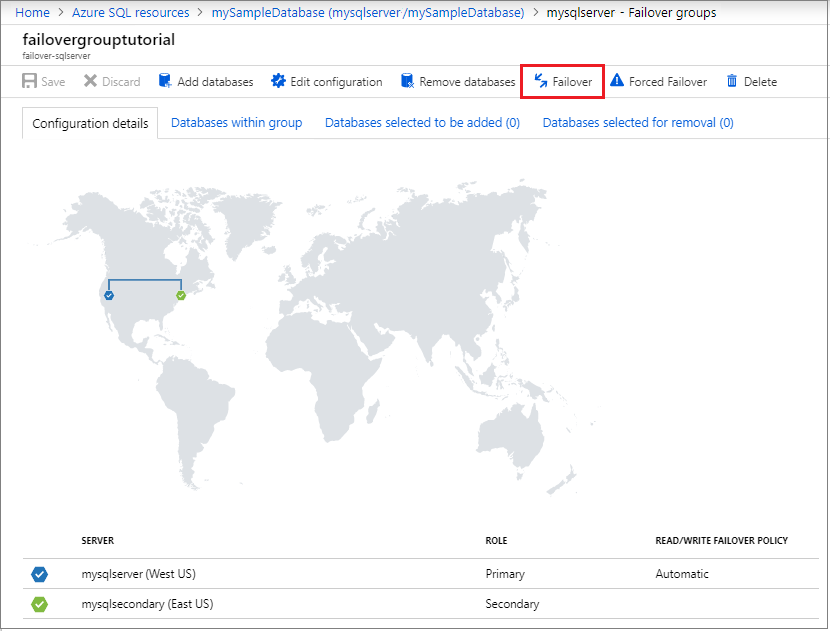
現在、どのサーバーがプライマリで、どのサーバーがセカンダリかを確認します。 フェールオーバーが成功すると、2 つのサーバー ロールがスワップされているはずです。
サーバーを元のロールにフェールバックするには、もう一度 [フェールオーバー] を選択します。
重要
セカンダリ データベースを削除する必要がある場合は、削除する前にそれをフェールオーバー グループから削除します。 セカンダリ データベースをフェールオーバー グループから削除する前に削除すると、予期しない動作が発生する可能性があります。
エンドツーエンドのスクリプトについては、Azure PowerShell または Azure CLI を使用して、エラスティック プールをフェールオーバー グループに追加する方法を確認します。
前提条件
プールされたデータベースのフェールオーバー グループを作成するには、次の前提条件を考慮してください。
- セカンダリ サーバーのサーバー ログインとファイアウォールの設定は、プライマリ サーバーのものと一致している必要があります。
フェールオーバー グループの作成
Azure portal または PowerShell を使用して、エラスティック プールのフェールオーバー グループを作成します。
Azure portal を使用して、フェールオーバー グループを作成し、エラスティック プールを追加します。
Azure portal の左側のメニューで [Azure SQL] を選択します。 [Azure SQL] が一覧にない場合は、[すべてのサービス] を選択してから、検索ボックスに「Azure SQL」と入力します。 (省略可能) [Azure SQL] の横にある星を選択してお気に入りに追加し、左側のナビゲーションに項目として追加します。
フェールオーバー グループに追加するエラスティック プールを選択します。
[概要] ウィンドウの [サーバー名] でサーバーの名前を選択し、サーバーの設定を開きます。
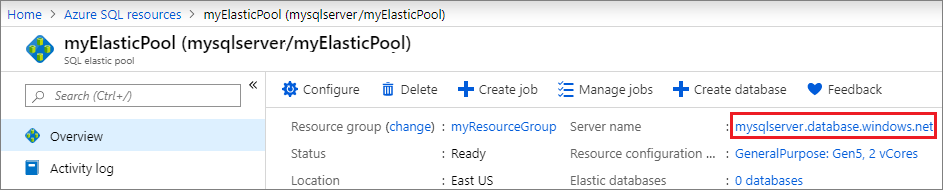
[設定] ウィンドウで [フェールオーバー グループ] を選択し、 [グループの追加] を選択して新しいフェールオーバー グループを作成します。
[フェールオーバー グループ] ページで、必要な値を入力するか選択してから、 [作成] を選択します。 新しいセカンダリ サーバーを作成するか、既存のセカンダリ サーバーを選択します。
グループ内のデータベースを選択し、フェールオーバー グループに追加するエラスティック プールを選択します。 エラスティック プールがセカンダリ サーバーにまだ存在しない場合は、セカンダリ サーバーにエラスティック プールを作成するように求める警告が表示されます。 警告を選択し、 [OK] を選択して、セカンダリ サーバー上にエラスティック プールを作成します。
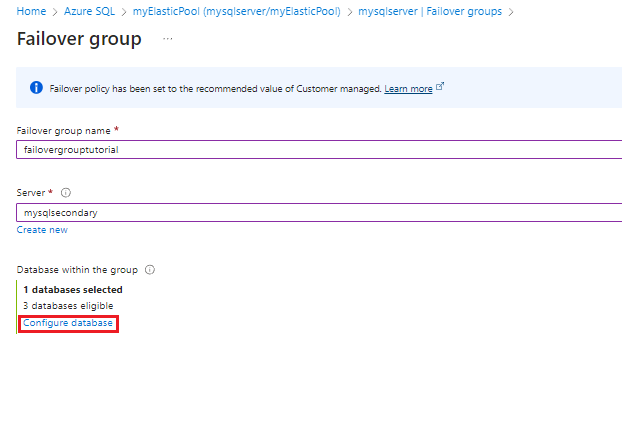
[選択] を使用してエラスティック プール設定をフェールオーバー グループに適用した後、 [作成] を選択してフェールオーバー グループを作成します。 フェールオーバー グループにエラスティック プールを追加すると、geo レプリケーション プロセスが自動的に開始されます。
計画フェールオーバーをテストします
Azure portal または PowerShell を使用して、エラスティック プールのフェールオーバーを損失なしでテストします。
フェールオーバー グループをセカンダリ サーバーにフェールオーバーしてから、Azure portal を使用してフェールバックします。
Azure portal の左側のメニューで [Azure SQL] を選択します。 [Azure SQL] が一覧にない場合は、[すべてのサービス] を選択してから、検索ボックスに「Azure SQL」と入力します。 (省略可能) [Azure SQL] の横にある星を選択してお気に入りに追加し、左側のナビゲーションに項目として追加します。
フェールオーバーするエラスティック プールを選択します。
[概要] ウィンドウの [サーバー名] でサーバーの名前を選択し、サーバーの設定を開きます。
[設定]で[フェールオーバーグループ] を選択し、先ほど作成したフェールオーバー グループを選択します。
どのサーバーがプライマリで、どのサーバーがセカンダリかを確認します。
作業ウィンドウで [フェールオーバー] を選択し、エラスティック プールを含むフェールオーバー グループをフェールオーバーします。
TDS セッションが切断されることが通知される警告で [はい] を選択します。
どのサーバーがプライマリで、どのサーバーがセカンダリかを確認します。 フェールオーバーが成功すると、2 つのサーバー ロールがスワップされているはずです。
フェールオーバー グループを元の設定に戻すには、 [フェールオーバー] をもう一度選択します。
重要
セカンダリ データベースを削除する必要がある場合は、削除する前にそれをフェールオーバー グループから削除します。 セカンダリ データベースをフェールオーバー グループから削除する前に削除すると、予期しない動作が発生する可能性があります。
Private Link を使用する
Private Link を使用すると、論理サーバーを、仮想ネットワークとサブネット内の特定のプライベート IP アドレスに関連付けることができます。
フェールオーバー グループで Private Link を使用するには、次の手順を実行します。
- プライマリ サーバーとセカンダリ サーバーが、ペアになっているリージョン内にあることを確認します。
- 各リージョンに仮想ネットワークとサブネットを作成して、プライマリ サーバーとセカンダリ サーバーのプライベート エンドポイントをホストします。これにより、重複しない IP アドレス空間が存在するようになります。 たとえば、10.0.0.0/16 のプライマリ仮想ネットワーク アドレス範囲と、10.0.0.1/16 のセカンダリ仮想ネットワーク アドレス範囲は重複しています。 仮想ネットワーク アドレス範囲の詳細については、Azure 仮想ネットワークの設計に関するブログを参照してください。
- プライマリ サーバーのプライベート エンドポイントと Azure プライベート DNS ゾーンを作成します。
- セカンダリ サーバーのプライベート エンドポイントも作成しますが、今回は、プライマリ サーバー用に作成されたプライベート DNS ゾーンと同じものを再利用することを選択します。
- Private Link が確立されたら、この記事で概要を説明した手順に従って、フェールオーバー グループを作成できます。
リスナー エンドポイントを特定する
フェールオーバー グループを構成したら、アプリケーションのリスナー エンドポイントへの接続文字列を更新します。 これで、アプリケーションから、プライマリ データベースまたはエラスティックプールではなく、フェールオーバー グループ リスナーへの接続が維持されます。 このようにすると、データベース エンティティがフェールオーバーするたびに接続文字列を手動で更新する必要がありません。また、トラフィックは、その時点でプライマリであるエンティティにルーティングされます。
リスナー エンドポイントは fog-name.database.windows.net という形式であり、Azure portal でフェールオーバー グループを表示すると確認できます。
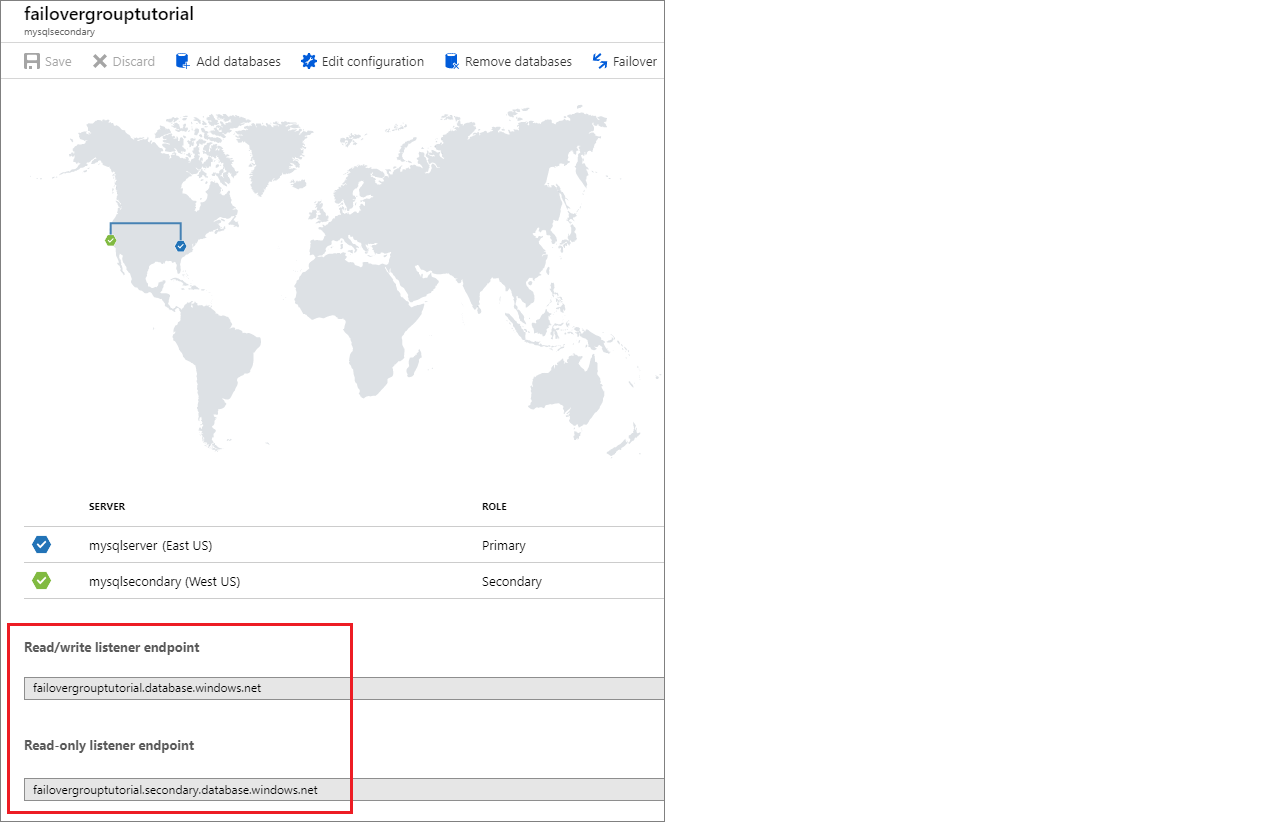
フェールオーバー グループ内のデータベースをスケーリングする
Geo セカンダリを切断せずに、プライマリデータベースを (同じサービスレベル内の) 別のコンピューティングサイズにスケールアップまたはスケールダウンすることができます。 スケールアップするときは、まず geo セカンダリをスケールアップしてから、プライマリをスケールアップすることをお勧めします。 スケールダウンする場合は、順序を逆にします。最初にプライマリをスケールダウンし、次にセカンダリをスケールダウンします。 データベースを別のサービス階層にスケーリングする場合は、この推奨設定が適用されます。
より低い SKU のセカンダリが過負荷になり、アップグレードまたはダウングレードのプロセス中に再シードする必要があるという問題を回避するために、このシーケンスが特に推奨されます。 プライマリを読み取り専用にすることでこの問題を回避することもできます。その場合、プライマリへのすべての読み取り/書き込みワークロードに影響が出ることになります。
Note
フェールオーバー グループの構成の一部として geo セカンダリを作成した場合は、geo セカンダリをスケールダウンしないことをお勧めします。 これは、geo フェールオーバー後の通常のワークロードを処理するのに十分な容量がデータ層にあることを確認するためのものです。 障害が原因で以前の geo プライマリが使用できない場合、計画外のフェールオーバー後に geo セカンダリをスケーリングできないことがあります。 これは、既知の制限です。
重要なデータが失われないようにする
ワイドエリアネットワークの待機時間が長いため、geo レプリケーションは非同期レプリケーションメカニズムを使用します。 非同期レプリケーションを使用すると、プライマリに障害が発生した場合にデータ損失が回避される可能性があります。 重要なトランザクションをデータ損失から保護するために、アプリケーション開発者はトランザクションをコミットした直後に sp_wait_for_database_copy_sync ストアドプロシージャを呼び出すことができます。 sp_wait_for_database_copy_sync を呼び出すと、最後にコミットされたトランザクションが転送され、セカンダリデータベースのトランザクションログに書き込まれるまで、呼び出し元のスレッドがブロックされます。 ただし、転送されたトランザクションがセカンダリで再生 (再実行) されるのを待つことはありません。 sp_wait_for_database_copy_sync は、特定の geo レプリケーションリンクにスコープが設定されています。 プライマリ データベースへの接続権限を持つユーザーが、このプロシージャを呼び出すことができます。
Note
sp_wait_for_database_copy_sync は、特定のトランザクションの geo フェールオーバー後のデータ損失を防ぎますが、読み取りアクセスの完全同期は保証しません。 sp_wait_for_database_copy_sync プロシージャ呼び出しによって発生する遅延は大きくなる可能性があり、呼び出し時のプライマリでまだ転送されていないトランザクションログのサイズによって異なります。
セカンダリ リージョンを変更する
変更のシーケンスを説明するために、サーバー A はプライマリ サーバー、サーバー B は既存のセカンダリ サーバー、サーバー C は 3 番目のリージョンの新しいセカンダリであると仮定します。 移行を行うには、次の手順を実行します。
- サーバー A の各データベースの追加のセカンダリを、アクティブ geo レプリケーションを使用してサーバー C に作成します。 サーバー A の各データベースには、2 つのセカンダリがあり、1 つはサーバー B に、もう 1 つはサーバー C にあります。これにより、移行中、プライマリ データベースが確実に保護された状態を維持できます。
- フェールオーバー グループを削除します。 この時点で、フェールオーバー グループ エンドポイントを使用したログイン試行は失敗し始めます。
- サーバー A と C の間に同じ名前でフェールオーバー グループを作成し、もう一度作成します。
- サーバー A のすべてのプライマリ データベースを新しいフェールオーバー グループに追加します。 この時点で、ログイン試行は失敗しなくなります。
- サーバー B を削除します。B のすべてのデータベースは自動的に削除されます。
プライマリ リージョンを変更する
変更のシーケンスを説明するために、サーバー A はプライマリ サーバー、サーバー B は既存のセカンダリ サーバー、サーバー C は 3 番目のリージョンの新しいプライマリであると仮定します。 移行を行うには、次の手順を実行します。
- 計画的 geo フェールオーバーを実行してプライマリ サーバーを B に切り替えます。サーバー A は新しいセカンダリ サーバーになります。 フェールオーバーによって、数分間のダウンタイムが発生する場合があります。 実際の時間は、フェールオーバー グループのサイズによって異なります。
- サーバー B の各データベースの追加のセカンダリを、アクティブ geo レプリケーションを使用してサーバー C に作成します。 サーバー B の各データベースには、2 つのセカンダリがあり、1 つはサーバー A に、もう 1 つはサーバー C にあります。これにより、移行中、プライマリ データベースが確実に保護された状態を維持できます。
- フェールオーバー グループを削除します。 この時点で、フェールオーバー グループ エンドポイントを使用したログイン試行は失敗し始めます。
- サーバー B と C の間で同じ名前でフェールオーバー グループを作成し、もう一度作成します。
- B のすべてのプライマリ データベースを新しいフェールオーバー グループに追加します。 この時点で、ログイン試行は失敗しなくなります。
- フェールオーバー グループの計画的 geo フェールオーバーを実行して、B と C を切り替えます。これで、サーバー C がプライマリになり、B がセカンダリになります。 サーバー A 上のすべてのセカンダリ データベースは、自動的に C のプライマリにリンクされます。手順 1 と同様に、フェールオーバーによって数分間のダウンタイムが発生する場合があります。
- サーバー A を削除します。A のすべてのデータベースは自動的に削除されます。
重要
フェールオーバー グループを削除すると、リスナー エンドポイントの DNS レコードも削除されます。 その時点で、他のユーザーがフェールオーバー グループまたは同じ名前のサーバー DNS エイリアスを作成する確率は 0 以外です。 フェールオーバー グループ名と DNS エイリアスはグローバルに一意である必要があります。これにより、同じ名前を再度使用する必要はありません。 このリスクを最小限に抑えるには、汎用フェールオーバーグループ名を使用しないでください。
フェールオーバー グループとネットワーク セキュリティ
一部のアプリケーションでは、セキュリティ規則により、データ層へのネットワーク アクセスを、VM や Web サービスなどの特定の 1 つまたは複数のコンポーネントに制限することが要求されています。この要件により、ビジネス継続性の設計とフェールオーバー グループの使用に関するいくつかの課題が生じます。 このような制限付きアクセスを実装する場合は、次のオプションを検討してください。
フェールオーバーグループと仮想ネットワークサービスエンドポイントの使用
仮想ネットワーク サービス エンドポイントおよび規則を使用して データベースへのアクセスを制限する場合、各仮想ネットワーク サービス エンドポイントは 1 つの Azure リージョンだけにしか適用されないことに注意してください。 そのエンドポイントにより、他のリージョンでサブネットからの通信の受け入れが可能になることはありません。 そのため、同じリージョンにデプロイされているクライアント アプリケーションのみが、プライマリ データベースに接続できます。 geo フェールオーバーによって、SQL Database のクライアントセッションが別の (セカンダリ) リージョンのサーバーに再ルーティングされるため、このようなセッションは、そのリージョンの外部のクライアントから発生した場合に失敗することがあります。 そのため、参加するサーバーが仮想ネットワーク規則に含まれている場合、マイクロソフトマネージドフェールオーバー ポリシーを有効にすることはできません。 手動フェールオーバーポリシーをサポートするには、次の手順を行います。
- アプリケーションのフロントエンドコンポーネント (web サービス、仮想マシンなど) の冗長コピーをセカンダリリージョンにプロビジョニングします。
- プライマリサーバーとセカンダリサーバーに対して、仮想ネットワークルール を個別に構成します。
- Traffic manager の構成を使用してフロントエンドフェールオーバーを有効にします。
- 障害が検出されたときに、手動 geo フェールオーバーを開始します。 このオプションは、フロント エンドとデータ層の間で一貫した待機時間を必要とするアプリケーションに対して最適化されており、フロント エンド、データ層、またはこの両方が機能停止の影響を受ける場合に回復をサポートします。
Note
読み取り専用リスナーを使用して読み取り専用ワークロードの負荷を分散する場合は、このワークロードを必ずセカンダリ リージョン内の VM などのリソースで実行することで、セカンダリ データベースに接続できるようにします。
フェールオーバー グループおよびファイアウォール規則を使用する
ビジネス継続性計画でフェールオーバーを含むグループを使用したフェールオーバーが必要な場合は、パブリック IP ファイアウォール規則を使用して SQL Database でデータベースへのアクセスを制限できます。 この構成では、自動 geo フェールオーバーによって、フロントエンド コンポーネントからの接続がブロックしないことを保証し、アプリケーションがフロントエンドとデータ層の間の長いレイテンシーを許容できることを前提としています。
フェールオーバーグループをサポートするには、次の手順を行います。
- パブリック IP を作成します。
- パブリック ロード バランサーを作成し、パブリック IP を割り当てます。
- フロントエンドコンポーネント用の仮想ネットワークと仮想マシンを作成します。
- ネットワーク セキュリティ グループを作成し、受信接続を構成します。
Sql.<Region>サービス タグを使用して、発信接続がリージョン内の Azure SQL Database に開かれていることを確認します。- SQL Database ファイアウォール規則を作成して、手順 1 で作成したパブリック IP アドレスからの受信トラフィックを許可します。
送信アクセスを構成する方法と、ファイアウォール規則で使用する IP の詳細については、ロード バランサー送信接続に関するページを参照してください。
重要
地域的な障害発生時のビジネス継続性を保証するには、フロントエンドコンポーネントとデータベースの両方で地理的な冗長性を確保する必要があります。
アクセス許可
フェールオーバー グループに対するアクセス許可は、Azure ロールベースのアクセス制御 (Azure RBAC) によって管理されます。
フェールオーバー グループを作成および管理するには、Azure RBAC 書き込みアクセスが必要です。 SQL Server 共同作成者ロールには、フェールオーバー グループを管理するために必要なすべてのアクセス許可があります。
次の表に、Azure SQL Database の具体的なアクセス許可のスコープを示します。
| 操作 | 権限 | スコープ |
|---|---|---|
| フェールオーバー グループの作成 | Azure RBAC 書き込みアクセス | プライマリ サーバー セカンダリ サーバー フェールオーバー グループ内のすべてのデータベース |
| フェイルオーバー グループを更新する | Azure RBAC 書き込みアクセス | フェールオーバー グループ 現在のプライマリ サーバー上のすべてのデータベース |
| フェールオーバー グループをフェールオーバーする | Azure RBAC 書き込みアクセス | 新しいサーバー上のフェールオーバー グループ |
制限事項
次の制限事項に注意してください。
- 同じ Azure リージョン内の 2 つのサーバー間で、フェールオーバー グループを作成することはできません。
- フェールオーバー グループでは、グループ内のすべてのデータベースを別のリージョンの 1 つのセカンダリ論理サーバーにのみ geo レプリケートできます。
- フェールオーバー グループの名前を変更することはできません。 グループを削除し、別の名前で再作成する必要があります。
- データベース名の変更は、フェールオーバー グループ内のデータベースではサポートされていません。 データベースの名前を変更したり、フェールオーバー グループからデータベースを削除したりするには、フェールオーバー グループを一時的に削除する必要があります。
- 単一データベースまたはプールされたデータベースのフェールオーバー グループを削除しても、レプリケーションは停止されず、レプリケートされたデータベースは削除されません。 単一またはプールされたデータベースを削除した後にフェールオーバー グループに追加し直す場合は、geo レプリケーションを手動で停止し、セカンダリ サーバーからデータベースを削除する必要があります。 いずれかの操作を行わないと、データベースをフェールオーバー グループに追加しようとしたときに
The operation cannot be performed due to multiple errorsのようなエラーが発生する可能性があります。 - フェールオーバー グループ名には名前付けの制限があります。
フェールオーバーグループをプログラムで管理する
フェールオーバー グループは、Azure PowerShell、Azure CLI、および REST API を使用してプログラムで管理することもできます。 次の表では、使用できるコマンド セットについて説明します。 フェールオーバーグループには、管理のための Azure Resource Manager API 一式 (Azure SQL データベース REST API、Azure PowerShell コマンドレットなど) が含まれています。 これらの API では、リソース グループを使用する必要があり、Azure のロール ベースのアクセス制御 (Azure RBAC) がサポートされます。 アクセス ロールの実装方法の詳細については、Azure のロール ベースのアクセス制御 (Azure RBAC) に関するページをご覧ください。
| コマンドレット | 説明 |
|---|---|
| New-AzSqlDatabaseFailoverGroup | このコマンドはフェールオーバー グループを作成し、それをプライマリとセカンダリの両方のサーバーに登録します。 |
| Remove-AzSqlDatabaseFailoverGroup | フェールオーバー グループをサーバーから削除します。 |
| Get-AzSqlDatabaseFailoverGroup | フェールオーバー グループの構成を取得します。 |
| Set-AzSqlDatabaseFailoverGroup | フェールオーバー グループの構成を変更します。 |
| Switch-AzSqlDatabaseFailoverGroup | セカンダリ サーバーへのフェールオーバー グループのフェールオーバーをトリガーします |
| Add-AzSqlDatabaseToFailoverGroup | 1 つまたは複数のデータベースをフェールオーバー グループに追加します。 |
Note
Az.SQL 3.11.0 以降の Azure Powershell では、-PartnerSubscriptionId パラメーターを使って、サブスクリプション全体にフェールオーバー グループをデプロイできます。 詳細については、以下の例を参照してください。
次のステップ
Azure SQL データベースの高可用性オプションの概要については、geo レプリケーションとフェールオーバー グループに関する記事を参照してください。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示