カスタムの質問に回答するための書式ガイドライン
コンテンツに最適な結果を得るには、以下の書式設定ガイドラインを確認してください。
書式設定の考慮事項
ファイルまたは URL をインポートした後、カスタムの質問に回答すると、コンテンツがマークダウン形式で変換されて格納されます。 変換プロセスによって、テキストに \n\n などの新しい行が追加されます。 マークダウン形式の知識があると、変換されたコンテンツを理解し、プロジェクト コンテンツを管理するために役立ちます。
プロジェクトのコンテンツを直接追加または編集する場合は、マークダウンの書式設定を使用してリッチ テキスト コンテンツを作成するか、既に回答に含まれているマークダウン形式コンテンツを変更します。 カスタムの質問の回答では、コンテンツにリッチ テキスト機能を提供するためのマークダウン形式の多くがサポートされています。 ただし、チャット ボットなどのクライアント アプリケーションは、同じマークダウン形式のセットをサポートしていない場合があります。 クライアント アプリケーションの回答の表示をテストすることが重要です。
基本的なドキュメントの書式設定
カスタムの質問に回答すると、次のような視覚的な手がかりに基づいて、ファイル内のセクションとサブセクションとリレーションシップが識別されます。
- フォント サイズ
- フォント スタイル
- 番号付け
- 色
Note
現在、アップロードされたドキュメントからの画像の抽出はサポートされていません。
製品マニュアル
一般にマニュアルは、製品に付属するガイダンス資料です。 ユーザーにとっては、製品のセットアップ、使用、保守、トラブルシューティングにあたっての貴重な情報源となります。 カスタムの質問の回答がマニュアルを処理すると、見出しと小見出しが質問として抽出され、その後の内容が回答として抽出されます。 こちらの例を参照してください。
次に示すのは、索引ページと階層的なコンテンツを持ったマニュアルの例です

Note
抽出の対象として最も適しているのは、目次やインデックス ページがあり、階層化された見出しから成る明確な構造を持ったマニュアルです。
パンフレット、ガイドライン、論文、およびその他のファイル
明確な構造とレイアウトがあれば、他の多くの種類のドキュメントも処理して質問と応答のペアを生成することができます。 これには以下が含まれます。パンフレット、ガイドライン、レポート、ホワイト ペーパー、科学論文、ポリシー、書籍などが含まれます。こちらの例を参照してください。
次に示すのは、索引のない半構造化ドキュメントの例です。

非構造化ドキュメントのサポート
カスタム質問と回答で、非構造化ドキュメントがサポートされるようになりました。 コンテンツが十分に定義された階層的な方法で整理されていない、設定された構造が欠落している、またはコンテンツが自由に流れるドキュメントは、非構造化ドキュメントと見なされます。
非構造化 PDF ドキュメントの例を下に示します。

Note
非構造化ソースの [ソースの編集] タブでは、QnA ペアは抽出されません。
重要
非構造化ファイル/コンテンツのサポートは、カスタムの質問への回答でのみ使用できます。
構造化されたカスタムの質問に回答するドキュメント
次に示すように、DOC ファイルでの構造化された質問応答の形式は、質問と応答を 1 行ずつ交互に並べる、つまり、1 行に 1 つの質問があり、次の行にその答えが続く形式です。
Question1
Answer1
Question2
Answer2
単語文書に回答する構造化されたカスタム質問の例を次に示します。

構造化 TXT、TSV、および XLS ファイル
構造化された.txt、.tsv、または.xlsファイルの形式で回答するカスタム質問は、プロジェクトを作成または拡張するためのカスタム質問の回答にアップロードすることもできます。 これらはプレーン テキストでも、RTF または HTML のコンテンツが含まれていても構いません。 質問応答ペアには、質問応答ペアをカテゴリにグループ化するために使用できる省略可能なメタデータ フィールドがあります。
| Question | Answer | メタデータ (1 つのキー: 1 つの値) |
|---|---|---|
| 質問 1 | 回答 1 | Key1:Value1 | Key2:Value2 |
| 質問 2 | 回答 2 | Key:Value |
これより後の列は、ソース ファイルに含まれていても無視されます。
インポートでの構造化データ形式
プロジェクトをインポートすると、既存のプロジェクトの内容が置き換えられます。 インポートでは、データ ソース情報を含んだ .tsv 形式の構造化ファイルが必要となります。 この情報によって質問と応答のペアをグループ化し、それらを特定のデータ ソースに帰属させるのに役立ちます。 質問応答ペアには、質問応答ペアをカテゴリにグループ化するために使用できる省略可能なメタデータ フィールドがあります。 インポート形式は、エクスポートされたナレッジ ベース形式に類似している必要があります。
| Question | Answer | source | メタデータ (1 つのキー: 1 つの値) | QnaId |
|---|---|---|---|---|
| 質問 1 | 回答 1 | URL 1 | Key1:Value1 | Key2:Value2 |
QnaId 1 |
| 質問 2 | 回答 2 | 編集 | Key:Value |
QnaId 2 |
複数ターンのドキュメントの書式設定
- 階層を示すには、見出しと小見出しを使用します。 たとえば、h1 を使用して親の質問の応答を示し、h2 により、プロンプトとして表示する必要がある質問の応答を示します。 後続の階層を示すには、小さい見出しサイズを使用する。 スタイル、色、またはその他のメカニズムを使用してドキュメント内の構造を示さないでください。カスタムの質問への回答では、複数ターンのプロンプトは抽出されません。
- 見出しの最初の文字は大文字にしなくてはなりません。
- 見出しの末尾に疑問符
?を付けないでください。
サンプル ドキュメント:
Surface Pro (docx)
Contoso Benefits (docx)
Contoso Benefits (pdf)
FAQ URL
カスタムの質問への回答では、FAQ Web ページを 3 つの異なる形式でサポートできます。
- 基本的な FAQ ページ
- リンク付き FAQ ページ
- トピック ホームページがある FAQ ページ
基本的な FAQ ページ
これは最も一般的なタイプの FAQ ページです。質問と回答が同じページにあり、質問のすぐ下に回答が記載されます。
リンク付き FAQ ページ
このタイプの FAQ ページでは、質問が 1 か所に集約され、同じページ上の別のセクションまたは別のページのどちらかにある回答にリンクされます。
次に示すのは、同じページ上のセクションへのリンクがある FAQ ページの例です。
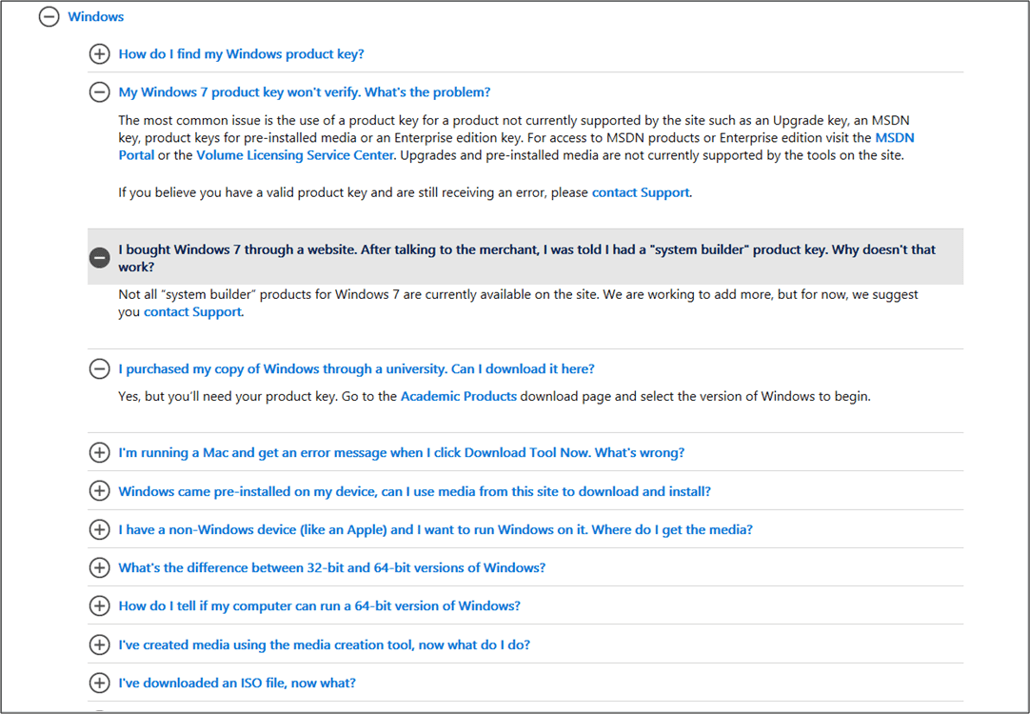
親トピック ページの子回答ページへのリンク
この種類の FAQ にはトピック ページがあり、各トピックが別ページの対応する質問と回答のセットにリンクされています。 質問の回答では、リンクされているすべてのページがクロールされ、対応する質問と回答が抽出されます。
次に、別ページの FAQ セクションへのリンクがあるトピック ページの例を示します。
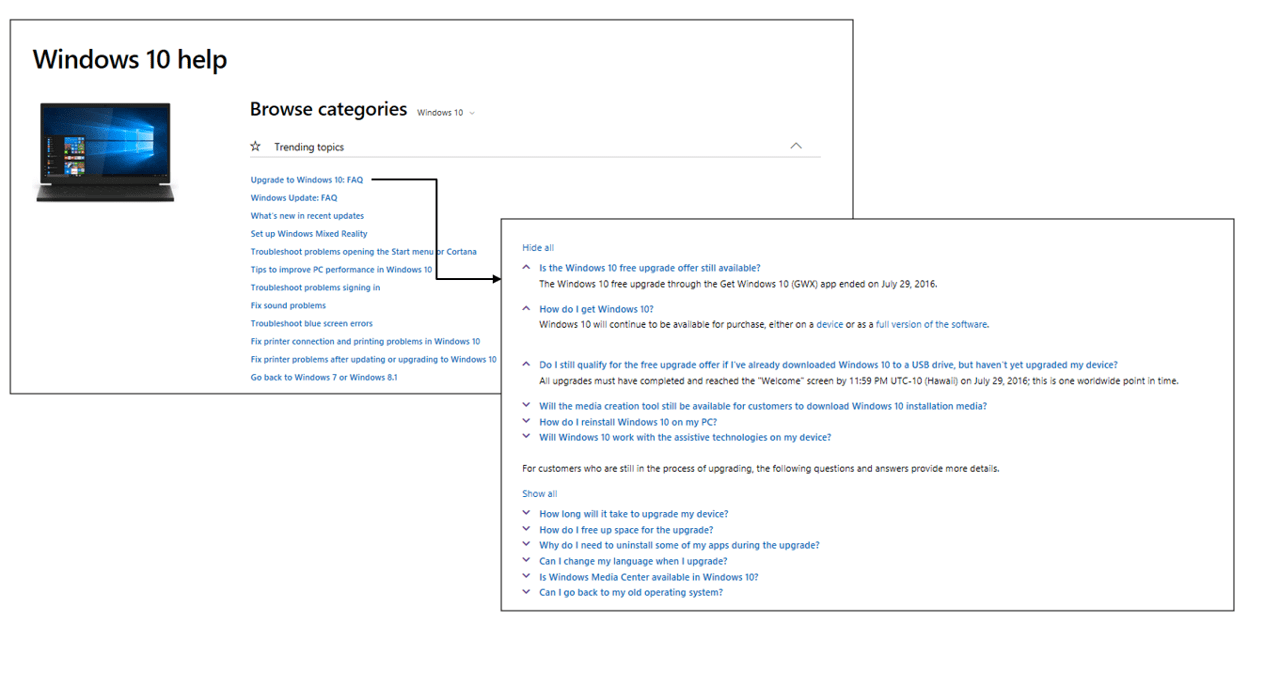
サポート URL
カスタムの質問の回答では、半構造化されたサポート Web ページ (特定のタスクの実行方法、特定の問題の診断と解決方法、特定のプロセスのベスト プラクティスを説明する Web 記事など) を処理できます。 抽出が最もうまくいくのは、階層的な見出しのある明確な構造を持ったコンテンツです。
Note
サポートの記事の抽出は新機能であり、初期段階にあります。 適切に構造化された、複雑なヘッダー/フッターが含まれていないシンプルなページで最適に動作します。
プロジェクトのインポートとエクスポート
エクスポートされたプロジェクトからの TSV および XLS ファイルは、Language Studio の [設定] ページからファイルをインポートすることによってのみ使用できます。 プロジェクトの作成中に、または [設定] ページの [+ ファイルの追加] または [+ URL の追加] 機能から、それらをデータ ソースとして使用することはできません。
これらの TSV および XLS ファイルを通じてプロジェクトをインポートする場合、質問応答ペアは、エクスポートされたプロジェクトでの質問と応答の抽出元のソースではなく、編集ソースに追加されます。