モデルのテスト
モデルのトレーニングが正常に完了したら、翻訳を使用してモデルの品質を評価できます。 標準モデルを使用するかカスタム モデルを使用するかについて、情報に基づいた決定を行うために、カスタム モデルの BLEU スコアと標準モデルのベースライン BLEU の差分を評価する必要があります。 狭いドメインに対してモデルがトレーニングされ、トレーニング データとテスト データとの一貫性がある場合は、BLEU スコアが高くなることが予想されます。
BLEU スコア
BLEU (Bilingual Evaluation Understudy) は、ある言語から別の言語に機械翻訳されたテキストの精度または正確性を評価するためのアルゴリズムです。 カスタム翻訳ツールでは、翻訳精度を確認する 1 つの方法として BLEU メトリックを使用しています。
BLEU スコアは、0 から 100 の数値です。 スコアが 0 の場合、リファレンスと全く一致しない低品質の翻訳を示します。 スコアが 100 の場合、リファレンスと完全に一致する完全な翻訳を示します。 スコアを 100 にする必要はありません。BLEU スコアが 40 から 60 の範囲であれば高品質な翻訳であることを示しています。
モデルの詳細
[モデルの詳細] ブレードを選択します。
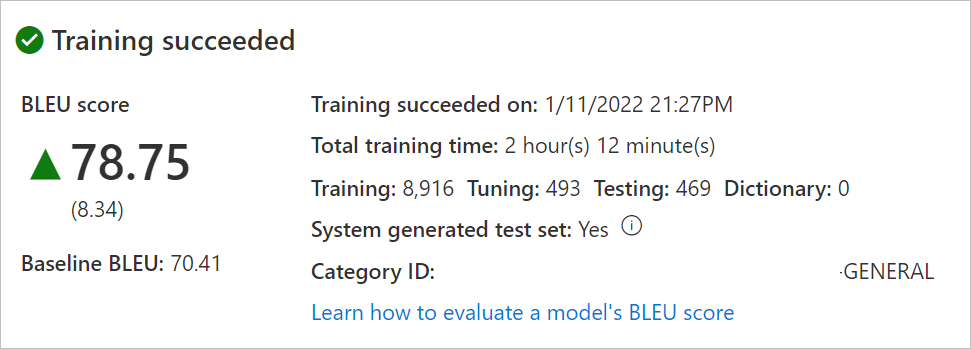
モデル名を選択します。 トレーニングの日付と時刻、合計トレーニング時間、トレーニング、チューニング、テスト、辞書に使用される文の数を確認します。 システムがテスト セットとチューニング セットを生成したかどうかを確認します。 翻訳要求を行うには、
Category IDを使用します。モデルの BLEU スコアを評価します。 テスト セットの確認: BLEU スコアはカスタム モデルのスコアで、ベースライン BLEU はカスタマイズに使用された事前トレーニング済みのベースライン モデルです。 BLEU スコアの方が高い場合、カスタム モデルを使用した翻訳品質が高いことを意味します。
モデルの翻訳の品質をテストする
[テスト モデル] ブレードを選択します。
モデルの名前を選択します。
カスタム モデルとベースライン モデル (カスタマイズに使用される事前トレーニング済みのベースライン) からの翻訳を、人間がリファレンス (テスト セットからのターゲット翻訳) に照らして評価します。
トレーニング結果に満足したら、トレーニング済みモデルのデプロイを要求します。
次の手順
- カスタム モデルを発行/デプロイする方法について確認します。
- カスタム モデルを使用してドキュメントを翻訳する方法を確認します。