Apache HBase から Azure Cosmos DB for NoSQL アカウントにデータを移行する
適用対象: ![]() NoSQL
NoSQL
Azure Cosmos DB は、グローバルに分散された、スケーラブルなフル マネージド データベースです。 短い待機時間でのデータへのアクセスが保証されます。 Azure Cosmos DB の詳細については、概要に関する記事をご覧ください。 この記事では、HBase から Azure Cosmos DB for NoSQL アカウントにデータを移行する方法について説明します。
Azure Cosmos DB と HBase の相違点
移行する前に、Azure Cosmos DB と HBase の相違点を理解する必要があります。
リソース モデル
Azure Cosmos DB には次のリソース モデルがあります: 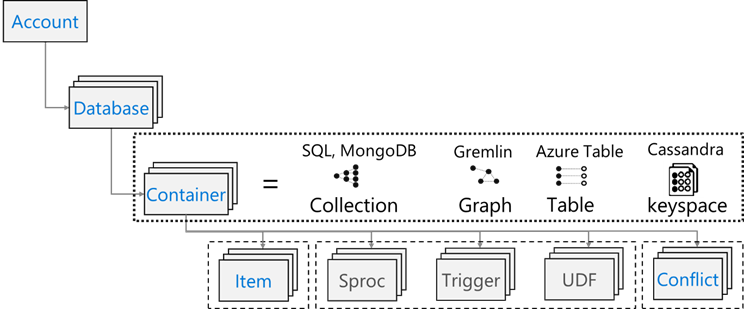
HBase には次のリソース モデルがあります: 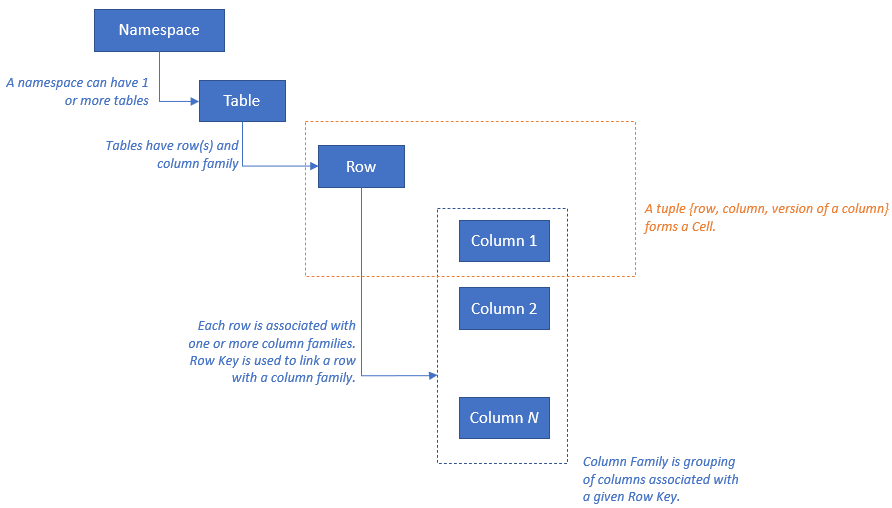
リソース マッピング
次の表は、Apache HBase、Apache Phoenix、および Azure Cosmos DB の間の概念のマッピングを示しています。
| HBase | Phoenix | Azure Cosmos DB |
|---|---|---|
| クラスター | クラスター | Account |
| 名前空間 | スキーマ (有効な場合) | データベース |
| テーブル | テーブル | コンテナー/コレクション |
| 列ファミリ | 列ファミリ | 該当なし |
| 行 | 行 | 項目/ドキュメント |
| バージョン (タイムスタンプ) | バージョン (タイムスタンプ) | 該当なし |
| 該当なし | 主キー | Partition Key |
| 該当なし | インデックス | インデックス |
| 該当なし | セカンダリ インデックス | セカンダリ インデックス |
| 該当なし | 表示 | 該当なし |
| 該当なし | シーケンス | 該当なし |
データ構造の比較と相違点
Azure Cosmos DB と HBase のデータ構造の主な違いは次のとおりです。
RowKey
HBase では、データは RowKey によって格納され、テーブルの作成時に指定された RowKey の範囲によってリージョンに水平方向にパーティション分割されます。
一方 Azure Cosmos DB は、指定されたパーティション キーのハッシュ値に基づいて、データをパーティションに分散します。
列ファミリ
HBase では、列は列ファミリ (CF) 内でグループ化されます。
Azure Cosmos DB (NoSQL 用 API) では、データを JSON ドキュメントとして格納します。 そのため、JSON データ構造に関連付けられているすべてのプロパティが適用されます。
タイムスタンプ
HBase はタイムスタンプを使用して、特定のセルの複数のインスタンスをバージョン管理します。 タイムスタンプを使用して、異なるバージョンのセルにクエリを実行できます。
Azure Cosmos DB には、コンテナーに対して行われた変更の永続的な記録を発生した順番に追跡する変更フィード機能があります。 変更されたドキュメントは、変更された順に並べ替えられた一覧に出力されます。
データ形式
HBase データ形式は、RowKey、列ファミリ: 列名、タイムスタンプ、値で構成されます。 HBase テーブル行の例を次に示します。
ROW COLUMN+CELL 1000 column=Office:Address, timestamp=1611408732448, value=1111 San Gabriel Dr. 1000 column=Office:Phone, timestamp=1611408732418, value=1-425-000-0002 1000 column=Personal:Name, timestamp=1611408732340, value=John Dole 1000 column=Personal:Phone, timestamp=1611408732385, value=1-425-000-0001Azure Cosmos DB for NoSQL では、JSON オブジェクトはデータ形式を表します。 パーティション キーはドキュメント内のフィールドに存在し、コレクションのパーティション キーであるフィールドを設定します。 Azure Cosmos DB には、列ファミリまたはバージョンに使用される timestamp の概念は存在しません。 前に説明したように、変更フィードがサポートされており、この機能を使用すると、コンテナーに対して実行された変更を追跡/記録できます。 以下はドキュメントの例です。
{ "RowId": "1000", "OfficeAddress": "1111 San Gabriel Dr.", "OfficePhone": "1-425-000-0002", "PersonalName": "John Dole", "PersonalPhone": "1-425-000-0001", }
ヒント
HBase はバイト配列にデータを格納します。そのため、2 バイト文字を含むデータを Azure Cosmos DB に移行する場合は、データは UTF-8 エンコードである必要があります。
整合性モデル
HBase は、厳密に整合性のある読み取りと書き込みを提供します。
Azure Cosmos DB では、5 つの整合性レベルが明確に定義されています。 各レベルには、可用性とパフォーマンスのトレードオフが存在します。 最も強いレベルから最も弱いレベルまで、サポートされる整合性レベルは次のとおりです。
- Strong
- Bounded staleness
- Session
- 一貫性のあるプレフィックス
- 最終的
サイズ変更
HBase
HBase のエンタープライズ規模のデプロイの場合、Master、リージョン サーバー、および ZooKeeper は一括サイズ設定を行います。 他の分散アプリケーションと同様に、HBase はスケールアウトするように設計されています。HBase のパフォーマンスは、主に HBase RegionServers のサイズによって駆動されます。 サイズ設定は主に、HBase に格納する必要があるデータセットのスループットとサイズという 2 つの主要な要件によって決定されます。
Azure Cosmos DB
Azure Cosmos DB は Microsoft が提供する PaaS サービスであり、基盤となるインフラストラクチャのデプロイの詳細はエンド ユーザーから抽象化されています。 Azure Cosmos DB コンテナーがプロビジョニングされている場合、Azure プラットフォームは、特定のワークロードのパフォーマンス要件をサポートするために、基になるインフラストラクチャ (コンピューティング、ストレージ、メモリ、ネットワーク スタック) を自動的にプロビジョニングします。 すべてのデータベース操作のコストは Azure Cosmos DB によって正規化され、要求ユニット (RU) によって表されます。
ワークロードに使用される RU 数を推定するには、次の要因を考慮してください。
RU のサイズ設定の演習に使用できる容量計算ツールがあります。
Azure Cosmos DB で自動スケーリング プロビジョニング スループットを使用して、お使いのデータベースまたはコンテナーのスループット (RU/秒) を自動的かつ即座にスケーリングできます。 ワークロードの可用性、待機時間、スループット、またはパフォーマンスに影響を与えずに、使用量に基づいてスループットがスケーリングされます。
データ分散
HBase HBase は RowKey に従ってデータを並べ替えます。 その後、データはリージョンにパーティション分割され、RegionServers に格納されます。 自動パーティション分割では、パーティション分割ポリシーに従ってリージョンが水平方向に分割されます。 これは、HBase パラメーターに割り当てられた値によって制御されます hbase.hregion.max.filesize (既定値は 10 GB です)。 指定された RowKey を持つ HBase の行は、常に 1 つのリージョンに属します。 さらに、データは列ファミリごとにディスク上で分離されます。 これにより、HFile での I/O の読み取り時と分離時のフィルター処理が可能です。
Azure Cosmos DB Azure Cosmos DB では、パーティション分割を使用してデータベース内の個々のコンテナーをスケーリングします。 パーティション分割は、コンテナー内の項目を "論理パーティション" と呼ばれる特定のサブセットに分割します。 論理パーティションは、コンテナー内の各項目に関連付けられている "パーティション キー" の値に基づいて形成されます。 1 つの論理パーティション内のすべての項目のパーティション キーの値は同じです。 各論理パーティションには、最大 20 GB のデータを保持できます。
各物理パーティションには、データのレプリカと Azure Cosmos DB データベース エンジンのインスタンスが含まれます。 この構造により、データの持続性と高可用性が実現されます。スループットは、ローカルの物理パーティション間で均等に分割されます。 物理パーティションは自動的に作成され、構成されます。そのサイズ、場所、または格納される論理パーティションを制御することはできません。 論理パーティションは物理パーティション間で分割されません。
HBase RowKey と同様に、パーティション キーの設計は、Azure Cosmos DB にとって重要です。 HBase の行キーはデータを並べ替え、連続データを格納することで機能し、Azure Cosmos DB のパーティション キーはデータをハッシュ分散する別のメカニズムです。 HBase を使用するアプリケーションが HBase へのデータ アクセス パターン用に最適化されていると仮定すると、パーティション キーに同じ RowKey を使用すると、適切なパフォーマンス結果が得られません。 HBase 上のデータが並べ替えられた場合、Azure Cosmos DB 複合インデックスが役に立つ場合があります。 これは、複数のフィールドで ORDER BY 句を使用する場合に必要です。 また、複合インデックスを定義して、多くの等値クエリと範囲クエリのパフォーマンスを向上させることもできます。
可用性
HBase HBase は Master、リージョン サーバー、および ZooKeeper で構成されています。 1 つのクラスターでの高可用性は、各コンポーネントを冗長化することで実現できます。 geo 冗長性を構成する場合、異なる物理データ センターに HBase クラスターをデプロイし、レプリケーションを使用して複数のクラスターを最新に保つことができます。
Azure Cosmos DB Azure Cosmos DB では、クラスター コンポーネントの冗長性などの構成は必要ありません。 高可用性、整合性、待機時間に関する包括的な SLA が提供されます。 詳細については、「Azure Cosmos DB の SLA」をご覧ください。
データの信頼性
HBase HBase は Hadoop 分散ファイル システム (HDFS) 上に構築され、HDFS に格納されているデータは 3 回レプリケートされます。
Azure Cosmos DB Azure Cosmos DB は、主に 2 つの方法で高可用性を実現します。 まず、Azure Cosmos DB は、Azure Cosmos DB アカウント内で構成されたリージョン間でデータをレプリケートします。 次に、Azure Cosmos DB は、リージョン内のデータの 4 つのレプリカを保持します。
移行前の考慮事項
システムの依存関係
計画のこの側面は、Azure Cosmos DB に移行される HBase インスタンスのアップストリームとダウンストリームの依存関係の理解に重点を置いています。
ダウンストリームの依存関係の例としては、HBase からデータを読み取るアプリケーションがあります。 これらは、Azure Cosmos DB から読み取るようにリファクターする必要があります。 移行の一環として、次の点を考慮する必要があります。
依存関係の評価に関する質問 - 現在の HBase システムは独立したコンポーネントですか? または、別のシステムでプロセスを呼び出すのか、それとも別のシステム上のプロセスによって呼び出されるのか、それともディレクトリ サービスを使用してアクセスされるのですか? 他の重要なプロセスが HBase クラスターで動作していますか? 移行の影響を特定するには、これらのシステム依存関係を明確化する必要があります。
オンプレミスでの HBase デプロイ用の RPO と RTO。
オフライン移行とオンライン移行
データ移行を正常に行うには、データベースを使用するビジネスの特性を理解し、その方法を決定することが重要です。 システムを完全にシャットダウンし、データ移行を実行し、移行先でシステムを再起動できる場合は、オフライン移行を選択します。 また、データベースが常にビジー状態で長時間停止する余裕がない場合は、オンラインでの移行を検討してください。
Note
このドキュメントでは、オフライン移行についてのみ説明します。
オフライン データ移行を実行する場合は、現在実行している HBase のバージョンと使用可能なツールによって異なります。 詳細については、「データ移行」セクションをご覧ください。
パフォーマンスに関する考慮事項
計画のこの側面は、HBase のパフォーマンス ターゲットを理解し、それらを Azure Cosmos DB セマンティクスに変換します。 たとえば、HBase で "X" IOPS を実現するには、Azure Cosmos DB で必要な要求ユニット (RU/秒) はいくつでしょうか。 HBase と Azure Cosmos DB には違いがあります。この演習では、HBase のパフォーマンス ターゲットを Azure Cosmos DB に変換する方法のビューを構築する方法に重点を置きます。 こうすることによって、スケーリングの演習を進めます。
質問:
- HBase デプロイは読み取り負荷が大きいですか、書き込み負荷が大きいですか?
- 読み取りと書き込みを分割するものは何ですか?
- ターゲット IOPS を割合で表すとどうなりますか?
- HBase にデータを読み込むには、どのようなアプリケーションが使用されますか?
- HBase からデータを読み取るには、どのようなアプリケーションが使用されますか?
並べ替えたデータを要求するクエリを実行すると、データが RowKey で並べ替えられるため、HBase は結果をすばやく返します。 ただし、Azure Cosmos DB にはこのような概念は存在しません。 パフォーマンスを最適化するために、必要に応じて複合インデックスを使用できます。
デプロイに関する考慮事項
Azure portal または Azure CLI を使用して、Azure Cosmos DB for NoSQL をデプロイできます。 移行先は Azure Cosmos DB for NoSQL であるため。デプロイ時にパラメーターとして API に "NoSQL" を選択します。 さらに、可用性の要件に従って、geo 冗長性、複数リージョンの書き込み、および可用性ゾーンを設定します。
ネットワークに関する考慮事項
Azure Cosmos DB には、3 つの主要なネットワーク オプションがあります。 1 つ目は、パブリック IP アドレスを使用し、IP ファイアウォール (既定) でアクセスを制御する構成です。 2 つ目は、パブリック IP アドレスを使用し、特定の仮想ネットワーク (サービス エンドポイント) の特定のサブネットからのみアクセスを許可する構成です。 3 つ目は、プライベート IP アドレスを使用してプライベート ネットワークに参加する構成 (プライベート エンドポイント) です。
3 つのネットワーク オプションの詳細については、次のドキュメントをご覧ください。
既存のデータを評価する
データの検出
移行するデータを特定するために、既存の HBase クラスターから事前に情報を収集します。 これらは、移行方法の特定、移行するテーブルの決定、それらのテーブル内の構造の理解、データ モデルの構築方法の決定に役立ちます。 たとえば、次のような詳細を収集します。
- HBase のバージョン
- 移行ターゲット テーブル
- 列ファミリ情報
- テーブルの状態
次のコマンドは、Hbase シェル スクリプトを使用して上記の詳細を収集し、オペレーティング マシンのローカル ファイル システムに格納する方法を示しています。
HBase バージョンを取得する
hbase version -n > hbase-version.txt
出力:
cat hbase-version.txt
HBase 2.1.8.4.1.2.5
テーブルの一覧を取得します。
HBase に格納されているテーブルの一覧を取得できます。 既定以外の名前空間を作成した場合は、"名前空間: テーブル" 形式で出力されます。
echo "list" | hbase shell -n > table-list.txt
HBase 2.1.8.4.1.2.5
出力:
echo "list" | hbase shell -n > table-list.txt
cat table-list.txt
TABLE
COMPANY
Contacts
ns1:t1
3 row(s)
Took 0.4261 seconds
COMPANY
Contacts
ns1:t1
移行するテーブルを特定する
移行するテーブル名を指定して、テーブル内の列ファミリの詳細を取得します。
echo "describe '({Namespace}:){Table name}'" | hbase shell -n > {Table name} -schema.txt
出力:
cat {Table name} -schema.txt
Table {Table name} is ENABLED
{Table name}
COLUMN FAMILIES DESCRIPTION
{NAME => 'cf1', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
{NAME => 'cf2', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
2 row(s)
Took 0.5775 seconds
テーブル内の列ファミリとその設定を取得する
echo "status 'detailed'" | hbase shell -n > hbase-status.txt
出力:
{HBase version}
0 regionsInTransition
active master: {Server:Port number}
2 backup masters
{Server:Port number}
{Server:Port number}
master coprocessors: []
# live servers
{Server:Port number}
requestsPerSecond=0.0, numberOfOnlineRegions=44, usedHeapMB=1420, maxHeapMB=15680, numberOfStores=49, numberOfStorefiles=14, storefileUncompressedSizeMB=7, storefileSizeMB=7, compressionRatio=1.0000, memstoreSizeMB=0, storefileIndexSizeKB=15, readRequestsCount=36210, filteredReadRequestsCount=415729, writeRequestsCount=439, rootIndexSizeKB=15, totalStaticIndexSizeKB=5, totalStaticBloomSizeKB=16, totalCompactingKVs=464, currentCompactedKVs=464, compactionProgressPct=1.0, coprocessors=[GroupedAggregateRegionObserver, Indexer, MetaDataEndpointImpl, MetaDataRegionObserver, MultiRowMutationEndpoint, ScanRegionObserver, SecureBulkLoadEndpoint, SequenceRegionObserver, ServerCachingEndpointImpl, UngroupedAggregateRegionObserver]
[...]
"Contacts,,1611126188216.14a597a0964383a3d923b2613524e0bd."
numberOfStores=2, numberOfStorefiles=2, storefileUncompressedSizeMB=7168, lastMajorCompactionTimestamp=0, storefileSizeMB=7, compressionRatio=0.0010, memstoreSizeMB=0, readRequestsCount=4393, writeRequestsCount=0, rootIndexSizeKB=14, totalStaticIndexSizeKB=5, totalStaticBloomSizeKB=16, totalCompactingKVs=0, currentCompactedKVs=0, compactionProgressPct=NaN, completeSequenceId=-1, dataLocality=0.0
[...]
ヒープ メモリのサイズ、リージョンの数、クラスターの状態としての要求の数、テーブルの状態として圧縮/圧縮されていないデータのサイズなど、便利なサイズ設定情報を取得できます。
HBase クラスターで Apache Phoenix を使用している場合は、Phoenix からもデータを収集する必要があります。
- 移行ターゲット テーブル
- テーブル スキーマ
- インデックス
- Primary key (プライマリ キー)
クラスターの Apache Phoenix に接続する
sqlline.py ZOOKEEPER/hbase-unsecure
テーブルの一覧を取得する
!tables
テーブルの詳細を取得する
!describe <Table Name>
インデックスの詳細を取得する
!indexes <Table Name>
主キーの詳細を取得する
!primarykeys <Table Name>
データの移行
移行オプション
データをオフラインで移行するにはさまざまな方法がありますが、ここでは Azure Data Factory の使い方を紹介します。
| 解決策 | ソース バージョン | 考慮事項 |
|---|---|---|
| Azure Data Factory | HBase < 2 | セットアップが簡単です。 大規模なデータセットに適しています。 HBase 2 以降はサポートされていません。 |
| Apache Spark | すべてのバージョン | HBase のすべてのバージョンをサポートします。 大規模なデータセットに適しています。 Spark のセットアップが必要です。 |
| カスタム ツールと Azure Cosmos DB バルク エグゼキューター ライブラリ | すべてのバージョン | ライブラリを使用してカスタム データ移行ツールを作成できる柔軟性が最も高いです。 セットアップにはさらに多くの労力が必要です。 |
次のフローチャートでは、使用可能なデータ移行方法に到達するためにいくつかの条件を使用します。
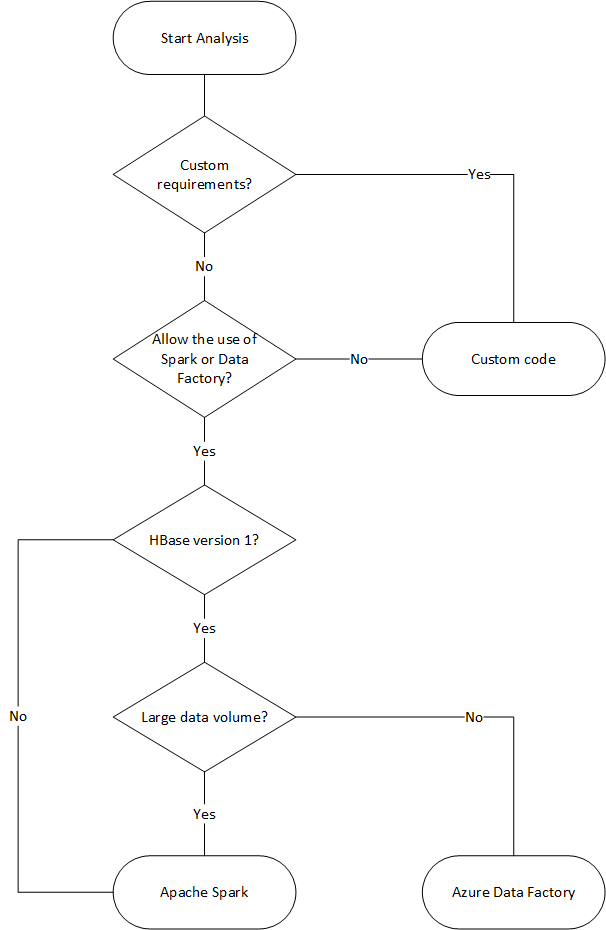
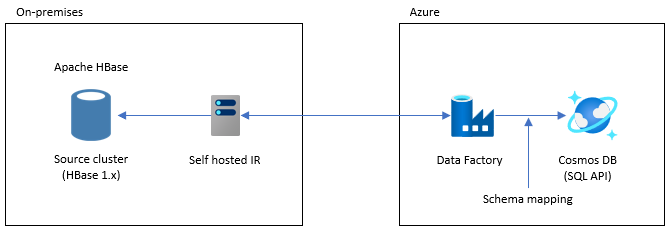
Data Factory を使用した移行
このオプションは、大規模なデータセットに適しています。 Azure Cosmos DB Bulk Executor ライブラリが使用されます。 チェックポイントはないので、移行中に問題が発生した場合は、最初から移行プロセスを再開する必要があります。 Data Factory のセルフホステッド統合ランタイムを使用して、オンプレミスの HBase に接続したり、Data Factory をマネージド VNET にデプロイしたり、VPN または ExpressRoute 経由でオンプレミス ネットワークに接続したりすることもできます。
Data Factory の Copy アクティビティは、データ ソースとして HBase をサポートします。 詳細については、「Azure Data Factory を使用して HBase からデータをコピーする」をご覧ください。
データの移行先に Azure Cosmos DB (NoSQL 用 API) を指定できます。 詳細については、Azure Data Factory を使用して Azure Cosmos DB (NoSQL 用 API) のデータをコピーおよび変換するの記事を参照してください。
Apache Spark を使用して移行する - Apache HBase Connector と Azure Cosmos DB Spark コネクタ
Azure Cosmos DB にデータを移行する例を示します。 HBase 2.1.0 と Spark 2.4.0 が同じクラスターで実行されていることを想定しています。
Apache Spark – Apache HBase Connector リポジトリは Apache Spark - Apache HBase Connector にあります。
Azure Cosmos DB Spark コネクタについては、「クイック スタート ガイド」を参照し、ご使用の Spark バージョンに適したライブラリをダウンロードしてください。
Spark hbase-site.xml を Spark の構成ディレクトリにコピーします。
cp /etc/hbase/conf/hbase-site.xml /etc/spark2/conf/Spark HBase コネクタと Azure Cosmos DB Spark コネクタを使用して spark -shell を実行します。
spark-shell --packages com.hortonworks.shc:shc-core:1.1.0.3.1.2.2-1 --repositories http://repo.hortonworcontent/groups/public/ --jars azure-cosmosdb-spark_2.4.0_2.11-3.6.8-uber.jarSpark シェルが起動したら、次のように Scala コードを実行します。 HBase からデータを読み込むのに必要なライブラリをインポートします。
// Import libraries import org.apache.spark.sql.{SQLContext, _} import org.apache.spark.sql.execution.datasources.hbase._ import org.apache.spark.{SparkConf, SparkContext} import spark.sqlContext.implicits._HBase テーブルの Spark カタログ スキーマを定義します。 ここで、名前空間は "default" で、テーブル名は "Contacts" です。 行キーはキーとして指定されます。 列、列ファミリ、および列は Spark のカタログにマップされます。
// define a catalog for the Contacts table you created in HBase def catalog = s"""{ |"table":{"namespace":"default", "name":"Contacts"}, |"rowkey":"key", |"columns":{ |"rowkey":{"cf":"rowkey", "col":"key", "type":"string"}, |"officeAddress":{"cf":"Office", "col":"Address", "type":"string"}, |"officePhone":{"cf":"Office", "col":"Phone", "type":"string"}, |"personalName":{"cf":"Personal", "col":"Name", "type":"string"}, |"personalPhone":{"cf":"Personal", "col":"Phone", "type":"string"} |} |}""".stripMargin次に、HBase Contacts テーブルからデータを DataFrame として取得するメソッドを定義します。
def withCatalog(cat: String): DataFrame = { spark.sqlContext .read .options(Map(HBaseTableCatalog.tableCatalog->cat)) .format("org.apache.spark.sql.execution.datasources.hbase") .load() }定義したメソッドを使用して DataFrame を作成します。
val df = withCatalog(catalog)次に、Azure Cosmos DB Spark コネクタを使用するために必要なライブラリをインポートします。
import com.microsoft.azure.cosmosdb.spark.schema._ import com.microsoft.azure.cosmosdb.spark._ import com.microsoft.azure.cosmosdb.spark.config.Configデータを Azure Cosmos DB に書き込むための設定を行います。
val writeConfig = Config(Map( "Endpoint" -> "https://<cosmos-db-account-name>.documents.azure.com:443/", "Masterkey" -> "<comsmos-db-master-key>", "Database" -> "<database-name>", "Collection" -> "<collection-name>", "Upsert" -> "true" ))DataFrame データを Azure Cosmos DB に書き込みます。
import org.apache.spark.sql.SaveMode df.write.mode(SaveMode.Overwrite).cosmosDB(writeConfig)
高速で並列に書き込みます。そのパフォーマンスは高いです。 一方、Azure Cosmos DB 側で消費される RU/秒 が増大する可能性があります。
Phoenix
Phoenix は Data Factory データ ソースとしてサポートされています。 手順については、次のドキュメントをご覧ください。
コードの移行
このセクションでは、Azure Cosmos DB for NoSQL でのアプリケーション作成と HBase でのアプリケーション作成の相違点について説明します。 例では、Apache HBase 2.x API と Azure Cosmos DB Java SDK v4 を使用します。
これらの HBase のサンプル コードは、HBase の公式ドキュメント で説明されているコードに基づいて作成されています。
ここで示す Azure Cosmos DB のコードは、Azure Cosmos DB for NoSQL: Java SDK v4 の例に関するドキュメントに基づいて作成されています。 完全なコード例は、ドキュメントからアクセスできます。
コード移行のマッピングを次に示しますが、これらの例で使用される HBase RowKeys と Azure Cosmos DB パーティション キーは、必ずしも十分に設計されているとは限りません。 移行ソースの実際のデータ モデルに従って設計してください。
接続を確立する
HBase
Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum","zookeepernode0,zookeepernode1,zookeepernode2");
config.set("hbase.zookeeper.property.clientPort", "2181");
config.set("hbase.cluster.distributed", "true");
Connection connection = ConnectionFactory.createConnection(config)
Phoenix
//Use JDBC to get a connection to an HBase cluster
Connection conn = DriverManager.getConnection("jdbc:phoenix:server1,server2:3333",props);
Azure Cosmos DB
// Create sync client
client = new CosmosClientBuilder()
.endpoint(AccountSettings.HOST)
.key(AccountSettings.MASTER_KEY)
.consistencyLevel(ConsistencyLevel.{ConsistencyLevel})
.contentResponseOnWriteEnabled(true)
.buildClient();
データベース/テーブル/コレクションを作成する
HBase
// create an admin object using the config
HBaseAdmin admin = new HBaseAdmin(config);
// create the table...
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf("FamilyTable"));
// ... with single column families
tableDescriptor.addFamily(new HColumnDescriptor("ColFam"));
admin.createTable(tableDescriptor);
Phoenix
CREATE IF NOT EXISTS FamilyTable ("id" BIGINT not null primary key, "ColFam"."lastName" VARCHAR(50));
Azure Cosmos DB
// Create database if not exists
CosmosDatabaseResponse databaseResponse = client.createDatabaseIfNotExists(databaseName);
database = client.getDatabase(databaseResponse.getProperties().getId());
// Create container if not exists
CosmosContainerProperties containerProperties = new CosmosContainerProperties("FamilyContainer", "/lastName");
// Provision throughput
ThroughputProperties throughputProperties = ThroughputProperties.createManualThroughput(400);
// Create container with 400 RU/s
CosmosContainerResponse databaseResponse = database.createContainerIfNotExists(containerProperties, throughputProperties);
container = database.getContainer(databaseResponse.getProperties().getId());
行/ドキュメントを作成する
HBase
HTable table = new HTable(config, "FamilyTable");
Put put = new Put(Bytes.toBytes(RowKey));
put.add(Bytes.toBytes("ColFam"), Bytes.toBytes("id"), Bytes.toBytes("1"));
put.add(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"), Bytes.toBytes("Witherspoon"));
table.put(put)
Phoenix
UPSERT INTO FamilyTable (id, lastName) VALUES (1, ‘Witherspoon’);
Azure Cosmos DB
Azure Cosmos DB は、データ モデルを介してタイプ セーフを提供します。 ここでは、"Family" という名前のデータ モデルを使用しています。
public class Family {
public Family() {
}
public void setId(String id) {
this.id = id;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
private String id="";
private String lastName="";
}
上記はコードの一部です。 「完全なコード例」を参照してください。
Family クラスを使用してドキュメントを定義し、項目を挿入します。
Family family = new Family();
family.setLastName("Witherspoon");
family.setId("1");
// Insert this item as a document
// Explicitly specifying the /pk value improves performance.
container.createItem(family,new PartitionKey(family.getLastName()),new CosmosItemRequestOptions());
行/ドキュメントを読み取る
HBase
HTable table = new HTable(config, "FamilyTable");
Get get = new Get(Bytes.toBytes(RowKey));
get.addColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
Result result = table.get(get);
byte[] col = result.getValue(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
Phoenix
SELECT lastName FROM FamilyTable;
Azure Cosmos DB
// Read document by ID
Family family = container.readItem(documentId,new PartitionKey(documentLastName),Family.class).getItem();
String sql = "SELECT lastName FROM c";
CosmosPagedIterable<Family> filteredFamilies = container.queryItems(sql, new CosmosQueryRequestOptions(), Family.class);
データの更新
HBase
HBase の場合は、append メソッドと checkAndPut メソッドを使用して値を更新します。 append は、現在の値の末尾にアトミックに値を追加するプロセスであり、checkAndPut は現在の値を期待される値とアトミックに比較し、一致する場合にのみ更新します。
// append
HTable table = new HTable(config, "FamilyTable");
Append append = new Append(Bytes.toBytes(RowKey));
Append.add(Bytes.toBytes("ColFam"), Bytes.toBytes("id"), Bytes.toBytes(2));
Append.add(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"), Bytes.toBytes("Harris"));
Result result = table.append(append)
// checkAndPut
byte[] row = Bytes.toBytes(RowKey);
byte[] colfam = Bytes.toBytes("ColFam");
byte[] col = Bytes.toBytes("lastName");
Put put = new Put(row);
put.add(colfam, col, Bytes.toBytes("Patrick"));
boolearn result = table.checkAndPut(row, colfam, col, Bytes.toBytes("Witherspoon"), put);
Phoenix
UPSERT INTO FamilyTable (id, lastName) VALUES (1, ‘Brown’)
ON DUPLICATE KEY UPDATE id = "1", lastName = "Whiterspoon";
Azure Cosmos DB
Azure Cosmos DB では、更新はアップサート操作として扱います。 つまり、ドキュメントが存在しない場合は挿入されます。
// Replace existing document with new modified document (contingent on modification).
Family family = new Family();
family.setLastName("Brown");
family.setId("1");
CosmosItemResponse<Family> famResp = container.upsertItem(family, new CosmosItemRequestOptions());
行/ドキュメントを削除する
HBase
Hbase では、値で行を直接削除する方法はありません。 ValueFilter などと組み合わせて削除プロセスを実装している可能性があります。この例では、削除する行を RowKey で指定します。
HTable table = new HTable(config, "FamilyTable");
Delete delete = new Delete(Bytes.toBytes(RowKey));
delete.deleteColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("id"));
delete.deleteColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
table.dalate(delete)
Phoenix
DELETE FROM TableName WHERE id = "xxx";
Azure Cosmos DB
ドキュメント ID による削除方法を次に示します。
container.deleteItem(documentId, new PartitionKey(documentLastName), new CosmosItemRequestOptions());
行/ドキュメントのクエリを実行する
HBase HBase では、スキャンを使用して複数の行を取得できます。 フィルターを使用して、詳細なスキャン条件を指定できます。 HBase の組み込みフィルターの種類については、「クライアント要求フィルター」をご覧ください。
HTable table = new HTable(config, "FamilyTable");
Scan scan = new Scan();
SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes("ColFam"),
Bytes.toBytes("lastName"), CompareOp.EQUAL, New BinaryComparator(Bytes.toBytes("Witherspoon")));
filter.setFilterIfMissing(true);
filter.setLatestVersionOnly(true);
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
Phoenix
SELECT * FROM FamilyTable WHERE lastName = "Witherspoon"
Azure Cosmos DB
フィルター操作
String sql = "SELECT * FROM c WHERE c.lastName = 'Witherspoon'";
CosmosPagedIterable<Family> filteredFamilies = container.queryItems(sql, new CosmosQueryRequestOptions(), Family.class);
テーブル/コレクションを削除する
HBase
HBaseAdmin admin = new HBaseAdmin(config);
admin.deleteTable("FamilyTable")
Phoenix
DROP TABLE IF EXISTS FamilyTable;
Azure Cosmos DB
CosmosContainerResponse containerResp = database.getContainer("FamilyContainer").delete(new CosmosContainerRequestOptions());
その他の考慮事項
HBase クラスターは、HBase ワークロードや、MapReduce、Hive、Spark などと一緒に使用できます。 現在の HBase に他のワークロードがある場合は、そのワークロードも移行する必要があります。 詳細については、各移行ガイドをご覧ください。
- MapReduce
- hbase
- Spark
サーバー側プログラミング
HBase には、サーバー側のプログラミング機能がいくつか用意されています。 これらの機能を使用している場合は、それらの処理も移行する必要があります。
HBase
-
HBase では既定でさまざまなフィルターを使用できますが、独自のカスタム フィルターを実装することもできます。 HBase で既定で使用可能なフィルターが要件を満たしていない場合は、カスタム フィルターを実装できます。
-
コプロセッサは、リージョン サーバーで独自のコードを実行できるフレームワークです。 コプロセッサを使用すると、サーバー側のクライアント側で実行された処理を実行できます。処理によっては、より効率的に実行できます。 コプロセッサには、オブザーバーとエンドポイントの 2 種類があります。
オブザーバー
- オブザーバーは、特定の操作とイベントをフックします。 これは、任意の処理を追加する関数です。 これは、RDBMS トリガーに似た機能です。
エンドポイント
- エンドポイントは、HBase RPC を拡張する機能です。 これは、RDBMS ストアド プロシージャに似た関数です。
Azure Cosmos DB
-
- Azure Cosmos DB ストアド プロシージャは JavaScript で記述され、Azure Cosmos DB コンテナー内の項目の作成、更新、読み取り、クエリ、削除などの操作を実行できます。
-
- トリガーは、データベースの操作に対して指定できます。 2 つの方法が用意されています。データベース項目が変更される前に実行されるプリトリガーと、データベース項目の変更後に実行されるポストトリガーです。
-
- Azure Cosmos DB を使用すると、ユーザー定義関数 (UDF) を定義できます。 UDF は JavaScript でも記述できます。
ストアド プロシージャとトリガーは、実行される操作の複雑さに基づいて RU を消費します。 サーバー側の処理を開発する場合は、必要な使用状況を確認して、各操作で消費される RU の量をより深く理解してください。 詳細については、「Azure Cosmos DB の要求ユニット」および「Azure Cosmos DB での要求コストを最適化する」をご覧ください。
サーバー側プログラミングのマッピング
| hbase | Azure Cosmos DB | 説明 |
|---|---|---|
| カスタム フィルター | ここで句 | カスタム フィルターによって実装された処理が Azure Cosmos DB の WHERE 句で実現できない場合は、UDF を組み合わせて使用します。 |
| コプロセッサ (オブザーバー) | トリガー | オブザーバーは、特定のイベントの前と後に実行されるトリガーです。 オブザーバーが事前呼び出しと事後呼び出しをサポートするのと同様に、Azure Cosmos DB のトリガーはプリトリガーとポストトリガーもサポートします。 |
| コプロセッサ (エンドポイント) | ストアド プロシージャ | エンドポイントは、リージョンごとに実行されるサーバー側のデータ処理メカニズムです。 これは RDBMS ストアド プロシージャに似ています。 Azure Cosmos DB のストアド プロシージャは JavaScript を使用して記述されます。 ストアド プロシージャを使用して Azure Cosmos DB で実行できるすべての操作にアクセスできます。 |
注意
HBase に実装される処理に応じて、Azure Cosmos DB で異なるマッピングと実装が必要になる場合があります。
セキュリティ
データのセキュリティは、お客様自身とデータベース プロバイダーの共同責任です。 オンプレミス ソリューションの場合、お客様は、エンドポイントの保護から物理的なハードウェアのセキュリティまですべてを行う必要があります。これは簡単な作業ではありません。 Azure Cosmos DB などの PaaS クラウド データベース プロバイダーを選択すると、お客様の作業が軽減されます。 Azure Cosmos DB は Azure プラットフォーム上で実行されるため、HBase とは異なる方法で拡張できます。 Azure Cosmos DB では、セキュリティのために追加のコンポーネントをインストールする必要はありません。 次のチェックリストを使用して、データベース システムのセキュリティ実装の移行を検討することをお勧めします。
| セキュリティ コントロール | HBase | Azure Cosmos DB |
|---|---|---|
| ネットワークのセキュリティとファイアウォールの設定 | ネットワーク デバイスなどのセキュリティ機能を使用してトラフィックを制御します。 | 受信ファイアウォールでポリシーベースの IP ベースのアクセス制御をサポートします。 |
| ユーザー認証ときめ細かいユーザー制御 | LDAP と Apache Ranger などのセキュリティ コンポーネントを組み合わせたきめ細かなアクセス制御。 | アカウントの主キーを使用して、各データベースのユーザー リソースとアクセス許可リソースを作成できます。 リソース トークンは、ユーザーがデータベース内のアプリケーション リソースにアクセスする方法 (読み取り/書き込み、読み取り専用、またはアクセスなし) を決定するために、データベース内のアクセス許可に関連付けされます。 Microsoft Entra ID を使用して、データ要求を認証することもできます。 これにより、きめ細かな RBAC モデルを使用してデータ要求を承認できます。 |
| 局地的な障害に対応するためにデータをグローバルにレプリケートする能力 | HBase のレプリケーションを使用して、リモート データ センターでデータベース レプリカを作成します。 | Azure Cosmos DB は構成フリーのグローバル分散を実行し、ボタンを選択して Azure の世界中のデータ センターにデータをレプリケートできます。 セキュリティ面では、グローバル レプリケーションによって、データが局所的な障害から保護されます。 |
| あるデータ センターから別のデータ センターにフェールオーバーする能力 | フェールオーバーは自分で実装する必要があります。 | 複数のデータ センターにデータをレプリケートし、リージョンのデータ センターがオフラインの場合、Azure Cosmos DB は操作を自動的にロールオーバーします。 |
| データ センター内でのローカルなデータのレプリケーション | HDFS メカニズムを使用すると、1 つのファイル システム内のノード間で複数のレプリカを作成できます。 | Azure Cosmos DB は、単一のデータ センター内でも高可用性を維持するためにデータを自動的にレプリケートします。 整合性レベルは自分で選択できます。 |
| データの自動バックアップ | 自動バックアップ機能はありません。 データ バックアップは自分で実装する必要があります。 | Azure Cosmos DB は定期的にバックアップされ、geo 冗長ストレージに格納されます。 |
| 機密データの保護と分離 | たとえば、Apache Ranger を使用している場合は、Ranger ポリシーを使用してテーブルにポリシーを適用できます。 | 個人データや他の機密データを特定のコンテナーに分離したり、読み取り/書き込みアクセスや読み取り専用アクセスを特定のユーザーに制限することができます。 |
| 攻撃の監視 | サード パーティ製品を使用して実装する必要があります。 | 監査ログとアクティビティ ログを使用すると、アカウントの正常なアクティビティと異常なアクティビティを監視できます。 |
| 攻撃への対応 | サード パーティ製品を使用して実装する必要があります。 | Azure サポートに連絡し、攻撃の可能性を報告すると、5 段階のインシデント対応プロセスが開始されます。 |
| データ ガバナンス制約に対してデータをジオフェンスで準拠させる能力 | 各国およびリージョンの制限を確認し、自分で実装する必要があります。 | ソブリン リージョン (ドイツ、中国、米国政府など) のデータ ガバナンスを保証します。 |
| 保護されたデータセンター内でのサーバーの物理的な保護 | これは、システムがあるデータ センターによって異なります。 | 最新の認定の一覧については、グローバルの Azure コンプライアンス サイトをご覧ください。 |
| 認定資格 | Hadoop ディストリビューションによって異なります。 | 「Azure コンプライアンス ドキュメント」をご覧ください。 |
セキュリティの詳細については、「Azure Cosmos DB のセキュリティ - 概要」をご覧ください。
監視
HBase は通常、クラスター メトリック Web UI または Ambari、Cloudera Manager、またはその他の監視ツールを使用してクラスターを監視します。 Azure Cosmos DB では、Azure プラットフォームに組み込みの監視メカニズムを使用できます。 Azure Cosmos DB の監視の詳細については、「Azure Cosmos DB を監視する」をご覧ください。
環境で HBase システム監視を実装して電子メールなどのアラートを送信する場合は、これを Azure Monitor アラートに置き換えることができます。 Azure Cosmos DB アカウントのメトリックまたはアクティビティ ログ イベントに基づいてアラートを受信できます。
Azure Monitor のアラートの詳細については、「Azure Monitor を使用して Azure Cosmos DB のアラートを作成する」をご覧ください
また、Azure Monitor で収集できる Azure Cosmos DB のメトリックおよびログの種類も参照してください。
バックアップとディザスター リカバリー
バックアップ
HBase のバックアップを取得するには、いくつかの方法があります。 スナップショット、エクスポート、CopyTable、HDFS データのオフライン バックアップ、その他のカスタム バックアップなどです。
Azure Cosmos DB は定期的なサイクル間隔でデータを自動的にバックアップします。これは、データベース操作のパフォーマンスや可用性には影響を及ぼしません。 バックアップは Azure Storage に格納され、必要に応じてデータの復旧に使用できます。 Azure Cosmos DB のバックアップは 2 種類あります。
障害復旧
HBase はフォールト トレラントな分散システムですが、データ センター レベルで障害が発生した場合に備えてバックアップの場所でフェールオーバーが必要な場合は、スナップショットやレプリケーションなどを使用してディザスター リカバリーを実装する必要があります。 HBase レプリケーションは、3 つのレプリケーション モデル (リーダーフォロー、リーダーリーダー、循環) で設定できます。 ソース HBase にディザスター リカバリーが実装されている場合は、Azure Cosmos DB でディザスター リカバリーを構成し、システム要件を満たす方法を理解する必要があります。
Azure Cosmos DB は、組み込みのディザスター リカバリー機能を備え、グローバルに分散されたデータベースです。 DB データは、任意の Azure リージョンにレプリケートできます。 Azure Cosmos DB は、一部のリージョンで障害が発生した場合でも、データベースの高可用性を維持します。
1 つのリージョンのみを使用する Azure Cosmos DB アカウントでは、リージョンの障害が発生した場合に可用性が失われる可能性があります。 高可用性を常に確保するために、少なくとも 2 つのリージョンを構成することをお勧めします。 書き込みと読み取りの高可用性を確保するには、書き込みと読み取りの高可用性を確保するために、書き込みリージョンが複数ある少なくとも 2 つのリージョンにまたがる Azure Cosmos DB アカウントを構成します。 複数の書き込みリージョンで構成される複数リージョン アカウントの場合、リージョン間のフェールオーバーが検出され、Azure Cosmos DB クライアントによって処理されます。 これらは一瞬であり、アプリケーションからの変更は必要はありません。 この方法で、Azure Cosmos DB のディザスター リカバリーを含む可用性構成を実現できます。 前述のように、HBase レプリケーションは 3 つのモデルで設定できますが、Azure Cosmos DB は、単一書き込みリージョンと複数書き込みリージョンを構成することで SLA ベースの可用性で設定できます。
高可用性の詳細については、「Azure Cosmos DB で高可用性を実現する方法」をご覧ください。
よく寄せられる質問
Azure Cosmos DB の他の API ではなく NoSQL 用 API に移行する理由を教えてください。
NoSQL 用 API は、インターフェイス、サービス SDK クライアント ライブラリに関して、最適なエンドツーエンド エクスペリエンスを提供します。 Azure Cosmos DB に展開される新機能は、NoSQL 用 API アカウントで最初に使用できます。 さらに、NoSQL 用 API は分析をサポートし、実稼働ワークロードと分析ワークロード間のパフォーマンスを分離できます。 最新のテクノロジを使用してアプリを構築する場合は、NoSQL 用 API をお勧めします。
HBase RowKey を Azure Cosmos DB パーティション キーに割り当てできますか?
そのままでは最適化されない場合があります。 HBase では、データは指定された RowKey で並べ替えられ、リージョンに格納され、固定サイズに分割されます。 これは、Azure Cosmos DB でのパーティション分割の動作と異なります。 そのため、ワークロードの特性に応じてデータをより適切に分散するために、キーを再設計する必要があります。 詳細については、「ディストリビューション」セクションをご覧ください。
データは、HBase では RowKey で並べ替えられますが、Azure Cosmos DB ではキーで並べ替えられます。 Azure Cosmos DB では並べ替えと併置はどのように実行されますか?
Azure Cosmos DB では、複合インデックスを追加して昇順または降順でデータを並べ替え、等値クエリおよび範囲クエリのパフォーマンスを向上できます。 製品ドキュメントの「ディストリビューション」セクション「複合インデックス」をご覧ください。
分析処理は、Hive または Spark を使用して HBase データに対して実行されます。 Azure Cosmos DB でデータを最新にする方法を教えてください。
Azure Cosmos DB 分析ストアを使用して、運用データを別の列ストアに自動的に同期できます。 列ストア形式は、最適化された方法で実行される大規模な分析クエリに適しています。このため、このようなクエリの待機時間が向上します。 Azure Synapse Link を使用すると、Azure Synapse Analytics から Azure Cosmos DB 分析ストアに直接リンクすることで、ETL フリーの HTAP ソリューションを構築できます。 これにより、運用データの大規模でほぼリアルタイムの分析を実行できます。 Synapse Analytics は、Apache Spark と Azure Cosmos DB 分析ストア内のサーバーレス SQL プールをサポートしています。 この機能を利用して、分析処理を移行できます。 詳しくは、「分析ストア」をご覧ください。
ユーザーは HBase のタイムスタンプ クエリを Azure Cosmos DB でどのように使用できますか?
Azure Cosmos DB には、HBase とまったく同じタイムスタンプ バージョン管理機能はありません。 ただし、Azure Cosmos DB には、変更フィードにアクセスする機能があり、バージョン管理に利用できます。
すべてのバージョン/変更を個別の項目として格納します。
変更フィードを読み取り、変更をマージ/統合し、"_ts" フィールドでフィルター処理することで、適切なアクションをダウンストリームでトリガーします。 さらに、古いバージョンのデータの場合は、TTL を使用して古いバージョンを期限切れにできます。
次のステップ
パフォーマンス テストを実行するには、「Azure Cosmos DB のパフォーマンスとスケールのテスト」という記事を参照してください。
コードを最適化するには、Azure Cosmos DB のパフォーマンスに関するヒントについての記事をご覧ください。
Java Async V3 SDK、SDK リファレンス GitHub リポジトリを参照してください。