チュートリアル: 集計関数を使用する
集計関数 を使用すると、複数の行のデータをグループ化して集計値に結合できます。 集計値は、選択した関数 (カウント、最大値、平均値など) によって異なります。
このチュートリアルで学習する内容は次のとおりです。
このチュートリアルの例では、ヘルプ クラスターで公開されているテーブルを使用StormEventsします。 独自のデータを使用して探索するには、 独自の無料クラスターを作成します。
このチュートリアルは、最初のチュートリアル「 Learn common operators」の基礎に基づいています。
前提条件
- ヘルプ クラスターにサインインするための Microsoft アカウントまたはMicrosoft Entraユーザー ID
summarize 演算子を使用する
summarize 演算子は、データに対して集計を実行するために不可欠です。 演算子は summarize 、 句に基づいて行を by グループ化し、指定された集計関数を使用して各グループを 1 つの行に結合します。
count 集計関数で を使用してsummarize、状態別にイベントの数を検索します。
StormEvents
| summarize TotalStorms = count() by State
出力
| State | TotalStorms |
|---|---|
| テキサス州 | 4701 |
| KANSAS | 3166 |
| アイオワ州 | 2337 |
| ILLINOIS | 2022 |
| MISSOURI | 2016 |
| ... | ... |
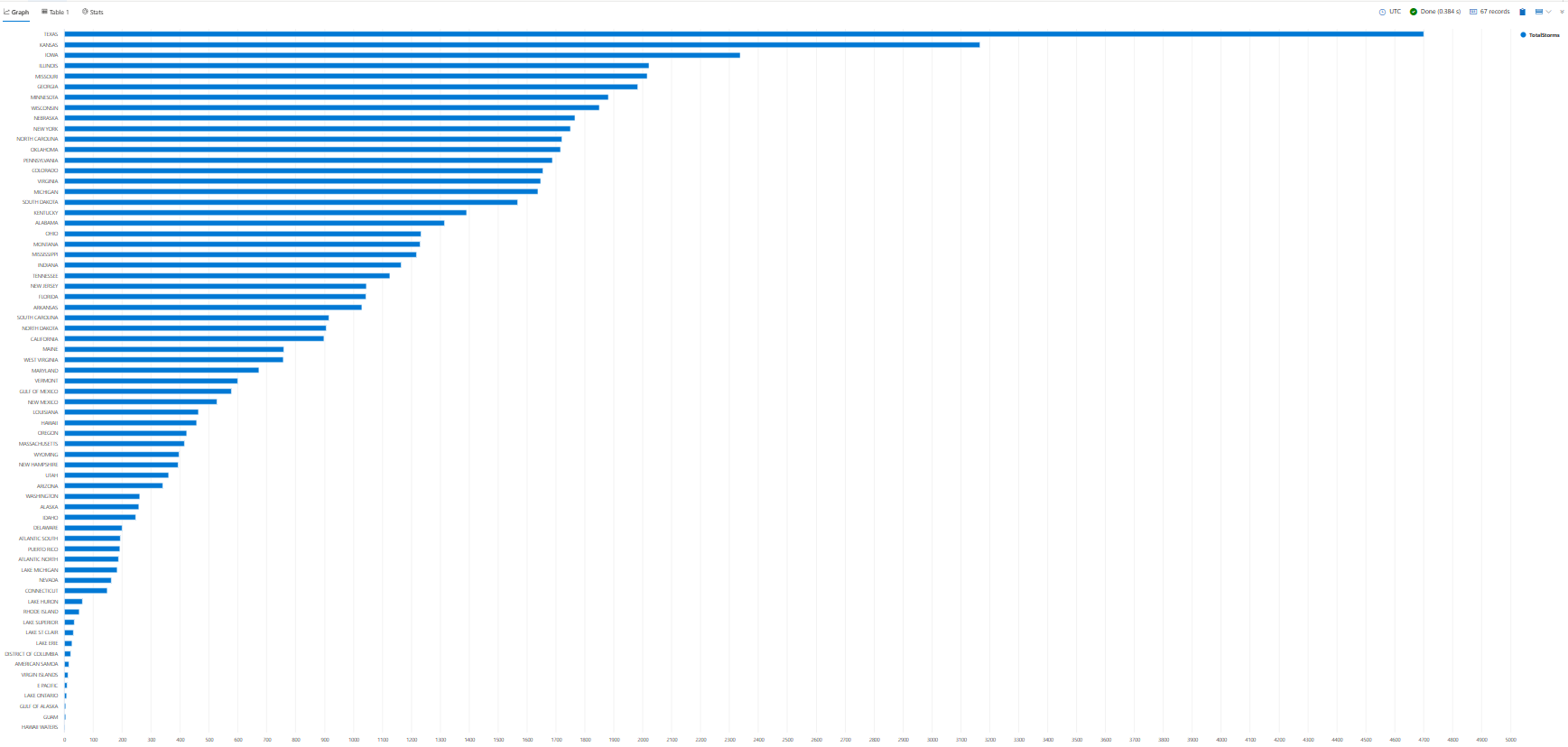
クエリ結果を視覚化する
グラフまたはグラフでクエリ結果を視覚化すると、データのパターン、傾向、外れ値を特定するのに役立ちます。 これを行うには、 render 演算子を使用します。
チュートリアル全体を通して、結果を表示するためにを使用 render する方法の例が表示されます。 ここでは、 を使用 render して、前のクエリの結果を横棒グラフで表示してみましょう。
StormEvents
| summarize TotalStorms = count() by State
| render barchart
条件付きで行をカウントする
データを分析するときは、 countif() を使用して特定の条件に基づいて行をカウントし、指定された条件を満たす行の数を把握します。
次のクエリでは、 を使用 countif() して、損害を引き起こした嵐の数をカウントします。 その後、クエリでは 演算子を top 使用して結果をフィルター処理し、嵐による作物被害の量が最も多い状態を表示します。
StormEvents
| summarize StormsWithCropDamage = countif(DamageCrops > 0) by State
| top 5 by StormsWithCropDamage
出力
| State | StormsWithCropDamage |
|---|---|
| アイオワ州 | 359 |
| ネブラスカ | 201 |
| MISSISSIPPI | 105 |
| ノースカロライナ | 82 |
| MISSOURI | 78 |
データをビンにグループ化する
数値または時刻の値で集計するには、まず bin() 関数を使用してデータを bin にグループ化します。 を使用 bin() すると、特定の範囲内で値がどのように分散されるかを理解し、異なる期間間で比較を行うことができます。
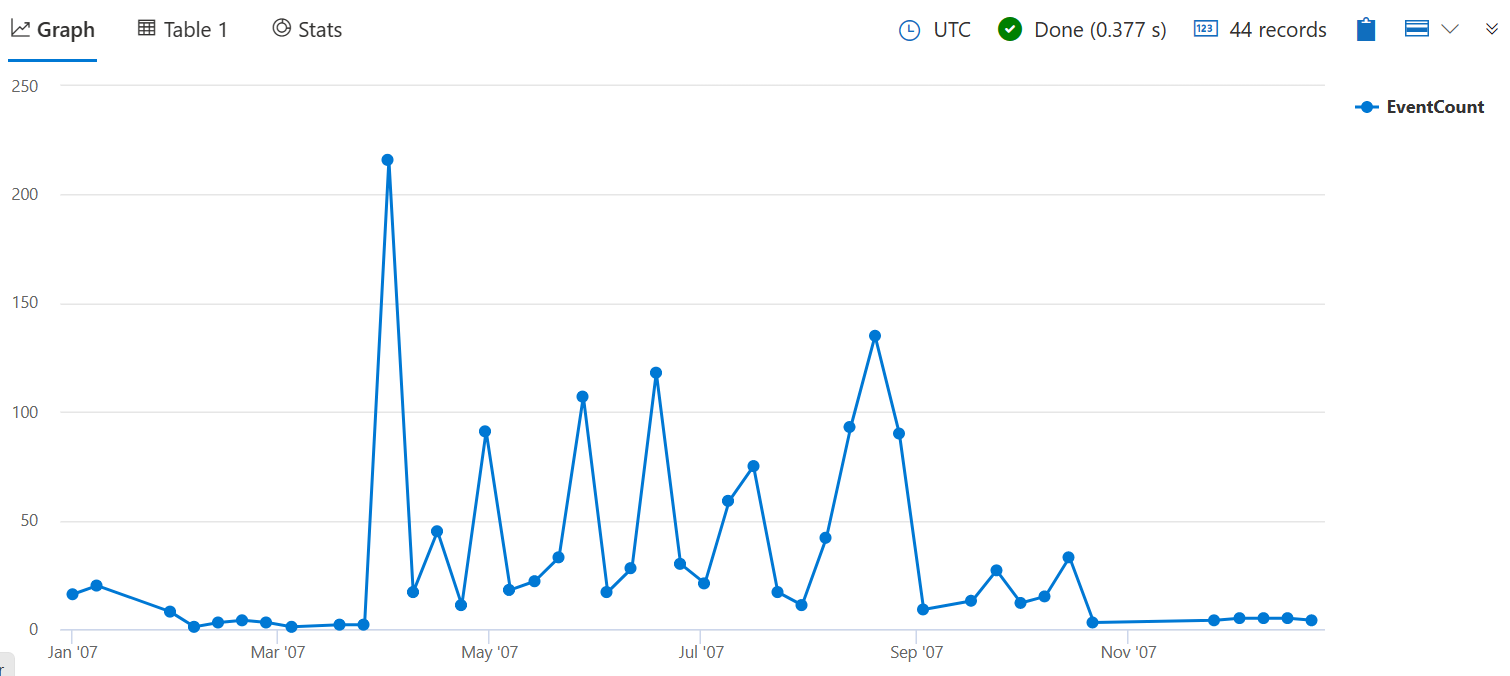
次のクエリでは、2007 年の週ごとに作物の被害を引き起こした嵐の数をカウントします。 関数には有効なタイムスパン値が必要です。引数は 7d 1 週間を表します。
StormEvents
| where StartTime between (datetime(2007-01-01) .. datetime(2007-12-31))
and DamageCrops > 0
| summarize EventCount = count() by bin(StartTime, 7d)
出力
| StartTime | EventCount |
|---|---|
| 2007-01-01T00:00:00Z | 16 |
| 2007-01-08T00:00:00Z | 20 |
| 2007-01-29T00:00:00Z | 8 |
| 2007-02-05T00:00:00Z | 1 |
| 2007-02-12T00:00:00Z | 3 |
| ... | ... |
クエリの末尾に を追加 | render timechart して、結果を視覚化します。
注意
bin() は、他の floor() プログラミング言語の 関数に似ています。 これにより、すべての値が指定した剰余の最も近い倍数に減り、 summarize 行をグループに割り当てることができます。
最小、最大、平均、合計を計算する
作物の損傷を引き起こす嵐の種類の詳細については、イベントの種類ごとに min()、 max()、 avg() のトリミングの損傷を計算し、平均ダメージで結果を並べ替えます。
1 つの summarize 演算子で複数の集計関数を使用して、複数の計算列を生成できることに注意してください。
StormEvents
| where DamageCrops > 0
| summarize
MaxCropDamage=max(DamageCrops),
MinCropDamage=min(DamageCrops),
AvgCropDamage=avg(DamageCrops)
by EventType
| sort by AvgCropDamage
出力
| EventType | MaxCropDamage | MinCropDamage | AvgCropDamage |
|---|---|---|---|
| フロスト/フリーズ | 568600000 | 3000 | 9106087.5954198465 |
| Wildfire | 21000000 | 10000 | 7268333.333333333 |
| 干ばつ | 700000000 | 2000 | 6763977.8761061952 |
| 洪水 | 500000000 | 1000 | 4844925.23364486 |
| 雷雨風 | 22000000 | 100 | 920328.36538461538 |
| ... | ... | ... | ... |
前のクエリの結果は、Frost/Freeze イベントが平均で最も作物の損傷を受けたことを示しています。 しかし、 bin() クエリ では、主に夏の間に作物の損傷を伴うイベントが発生したことを示しました。
前の bin() クエリで行われたcount()ように、損傷を引き起こしたイベントの量ではなく、破損したトリミングの合計数をチェックするには、sum() を使用します。
StormEvents
| where StartTime between (datetime(2007-01-01) .. datetime(2007-12-31))
and DamageCrops > 0
| summarize CropDamage = sum(DamageCrops) by bin(StartTime, 7d)
| render timechart
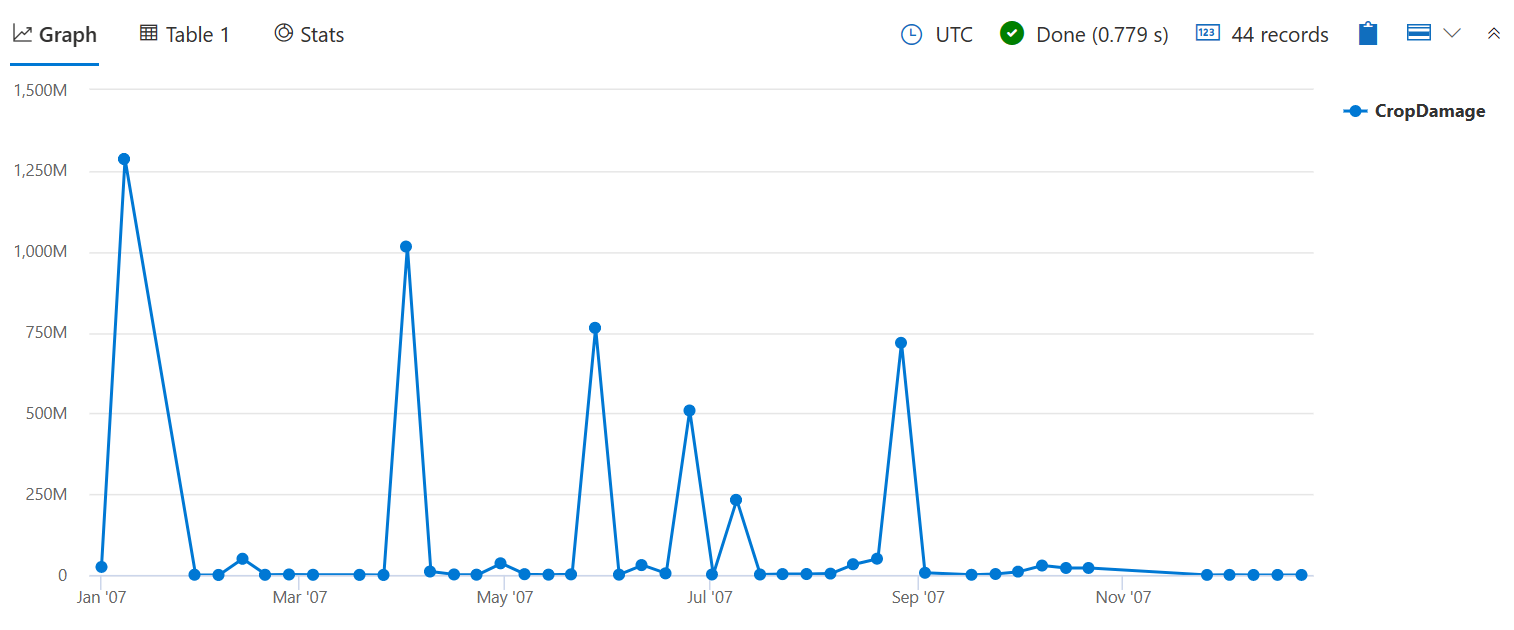
今、あなたはおそらくフロスト/フリーズが原因だった1月に作物の被害のピークを見ることができます。
パーセンテージを計算する
パーセンテージを計算すると、データ内のさまざまな値の分布と割合を理解するのに役立ちます。 このセクションでは、Kusto 照会言語 (KQL) を使用してパーセンテージを計算する 2 つの一般的な方法について説明します。
2 つの列に基づいてパーセンテージを計算する
count() と countif を使用して、各状態で作物の損傷を引き起こした嵐イベントの割合を確認します。 まず、各状態の嵐の合計数をカウントします。 次に、各状態で作物の損傷を引き起こした嵐の数をカウントします。
次に、 extend を使用して、2 つの列の間の割合を計算します。そのためには、作物の被害を受けた嵐の数を嵐の合計数で割り、100 を乗算します。
10 進数の結果が得られるようにするには、 todouble() 関数を使用して、除算を実行する前に、整数カウント値の少なくとも 1 つを double に変換します。
StormEvents
| summarize
TotalStormsInState = count(),
StormsWithCropDamage = countif(DamageCrops > 0)
by State
| extend PercentWithCropDamage =
round((todouble(StormsWithCropDamage) / TotalStormsInState * 100), 2)
| sort by StormsWithCropDamage
出力
| State | TotalStormsInState | StormsWithCropDamage | PercentWithCropDamage |
|---|---|---|---|
| アイオワ州 | 2337 | 359 | 15.36 |
| ネブラスカ | 1766 | 201 | 11.38 |
| MISSISSIPPI | 1218 | 105 | 8.62 |
| ノースカロライナ | 1721 | 82 | 4.76 |
| MISSOURI | 2016 | 78 | 3.87 |
| ... | ... | ... | ... |
Note
パーセンテージを計算する場合は、除算の整数値の少なくとも 1 つ を todouble() または toreal() で変換します。 これにより、整数除算のために結果が切り捨てられなくなります。 詳細については、「 算術演算の型規則」を参照してください。
テーブル サイズに基づいてパーセンテージを計算する
イベントの種類別に嵐の数をデータベース内の嵐の合計数と比較するには、まずデータベース内のストームの合計数を変数として保存します。 Let ステートメント は、クエリ内で変数を定義するために使用されます。
表形式の式ステートメントは表形式の結果を返すので、toscalar() 関数を使用して関数の表形式の結果をcount()スカラー値に変換します。 次に、パーセンテージ計算で数値を使用できます。
let TotalStorms = toscalar(StormEvents | summarize count());
StormEvents
| summarize EventCount = count() by EventType
| project EventType, EventCount, Percentage = todouble(EventCount) / TotalStorms * 100.0
出力
| EventType | EventCount | パーセント |
|---|---|---|
| 雷雨風 | 13015 | 22.034673077574237 |
| ひょう | 12711 | 21.519994582331627 |
| 鉄砲水 | 3688 | 6.2438627975485055 |
| 干ばつ | 3616 | 6.1219652592015716 |
| 冬の天気 | 3349 | 5.669928554498358 |
| ... | ... | ... |
一意の値を抽出する
テーブル内の行の選択を一意の値の配列に変換するには、 make_set() を使用します。
次のクエリでは、 を使用 make_set() して、各状態で死亡を引き起こすイベントの種類の配列を作成します。 結果のテーブルは、各配列内の storm 型の数で並べ替えられます。
StormEvents
| where DeathsDirect > 0 or DeathsIndirect > 0
| summarize StormTypesWithDeaths = make_set(EventType) by State
| project State, StormTypesWithDeaths
| sort by array_length(StormTypesWithDeaths)
出力
| State | StormTypesWithDeaths |
|---|---|
| CALIFORNIA | ["Thunderstorm Wind","High Surf","Cold/Wind Chill","Strong Wind Chill","Rip Current","Heat","Excessive Heat","Wildfire","Dust Storm","Astronomical Low Tide","Dense Fog","Winter Weather"] |
| テキサス州 | ["Flash Flood","Thunderstorm Wind","Tornado","Lightning","Flood","Ice Storm","Winter Weather","Rip Current","Excessive Heat","Dense Fog","Hurricane (Typhoon)","Cold/Wind Chill"] |
| オクラホマ | ["フラッシュ フラッド","トルネード","コールド/風の寒さ","冬の嵐","重雪","過剰な熱","熱","氷の嵐","冬の天気","濃い霧"] |
| ニューヨーク | ["Flood","Lightning","Thunderstorm Wind","Flash Flood","Winter Weather","Ice Storm","Extreme Cold/Wind Chill","Winter Storm","Heavy Snow"] |
| KANSAS | ["Thunderstorm Wind","Heavy Rain","Tornado","Flood","Flash Flood","Lightning","Heavy Snow","Winter Weather","Blizzard"] |
| ... | ... |
条件別のバケット データ
case() 関数は、指定された条件に基づいてデータをバケットにグループ化します。 関数は、最初に満たされた述語の対応する結果式、または述語が満たされていない場合は最後の else 式を返します。
この例では、市民が持続した嵐関連の傷害の数に基づいて状態をグループ化します。
StormEvents
| summarize InjuriesCount = sum(InjuriesDirect) by State
| extend InjuriesBucket = case (
InjuriesCount > 50,
"Large",
InjuriesCount > 10,
"Medium",
InjuriesCount > 0,
"Small",
"No injuries"
)
| sort by State asc
出力
| State | InjuriesCount | InjuriesBucket |
|---|---|---|
| ALABAMA | 494 | Large |
| ALASKA | 0 | けが人なし |
| AMERICAN SAMOA | 0 | けが人なし |
| ARIZONA | 6 | Small |
| ARKANSAS | 54 | Large |
| ATLANTIC NORTH | 15 | Medium |
| ... | ... | ... |
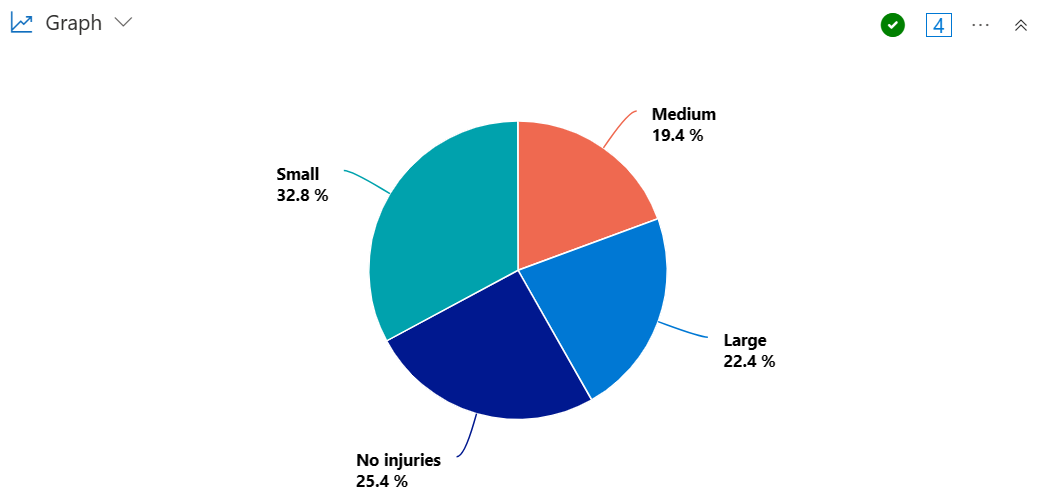
円グラフを作成して、暴風雨が発生した状態の割合を視覚化し、大、中、または少数の負傷者を発生させます。
StormEvents
| summarize InjuriesCount = sum(InjuriesDirect) by State
| extend InjuriesBucket = case (
InjuriesCount > 50,
"Large",
InjuriesCount > 10,
"Medium",
InjuriesCount > 0,
"Small",
"No injuries"
)
| summarize InjuryBucketByState=count() by InjuriesBucket
| render piechart
スライディング ウィンドウの集計を実行する
次の例は、スライディング ウィンドウを使用して列を集計する方法を示しています。
クエリでは、7 日間のスライディング ウィンドウを使用して、竜巻、洪水、山火事の最小、最大、および平均のプロパティ損傷を計算します。 結果セットの各レコードには前の 7 日間が集計されており、結果には分析期間の日ごとのレコードが含まれます。
クエリの詳細な説明を次に示します。
- 各レコードを に対して 1 日にビン分割します
windowStart。 - bin 値に 7 日間を追加して、各レコードの範囲の末尾を設定します。 値が と
windowEndの範囲外windowStartの場合は、それに応じて値を調整します。 - レコードの現在の日から始まる、レコードごとに 7 日間の配列を作成します。
- mv-expand を使用して手順 3 の配列を展開して、各レコードを 1 日間隔で 7 つのレコードに複製します。
- 各日の集計を実行します。 手順 4 により、この手順は実際には過去 7 日間を要約しています。
- 7 日間のルックバック期間がないため、最終結果から最初の 7 日間を除外します。
let windowStart = datetime(2007-07-01);
let windowEnd = windowStart + 13d;
StormEvents
| where EventType in ("Tornado", "Flood", "Wildfire")
| extend bin = bin_at(startofday(StartTime), 1d, windowStart) // 1
| extend endRange = iff(bin + 7d > windowEnd, windowEnd,
iff(bin + 7d - 1d < windowStart, windowStart,
iff(bin + 7d - 1d < bin, bin, bin + 7d - 1d))) // 2
| extend range = range(bin, endRange, 1d) // 3
| mv-expand range to typeof(datetime) // 4
| summarize min(DamageProperty), max(DamageProperty), round(avg(DamageProperty)) by Timestamp=bin_at(range, 1d, windowStart), EventType // 5
| where Timestamp >= windowStart + 7d; // 6
出力
次の結果テーブルは切り捨てられます。 完全な出力を表示するには、クエリを実行します。
| Timestamp | EventType | min_DamageProperty | max_DamageProperty | avg_DamageProperty |
|---|---|---|---|---|
| 2007-07-08T00:00:00Z | Tornado | 0 | 30000 | 6905 |
| 2007-07-08T00:00:00Z | 洪水 | 0 | 200000 | 9261 |
| 2007-07-08T00:00:00Z | Wildfire | 0 | 200000 | 14033 |
| 2007-07-09T00:00:00Z | Tornado | 0 | 100000 | 14783 |
| 2007-07-09T00:00:00Z | 洪水 | 0 | 200000 | 12529 |
| 2007-07-09T00:00:00Z | Wildfire | 0 | 200000 | 14033 |
| 2007-07-10T00:00:00Z | Tornado | 0 | 100000 | 31400 |
| 2007-07-10T00:00:00Z | 洪水 | 0 | 200000 | 12263 |
| 2007-07-10T00:00:00Z | Wildfire | 0 | 200000 | 11694 |
| ... | ... | ... |
次のステップ
一般的なクエリ演算子と集計関数について理解したら、次のチュートリアルに進み、複数のテーブルのデータを結合する方法について説明します。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示