Azure Data Factory と Azure Data Share を使用したデータ統合
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
お客様が先進的なデータ ウェアハウスおよび分析のプロジェクトに着手すると、より多くのデータが必要になるだけでなく、自社のデータ資産全体に対するデータの可視性を高めることも必要になります。 このワークショップでは、Azure Data Factory と Azure Data Share の強化によって、Azure におけるデータの統合と管理がいかに簡素化されるについて詳しく説明します。
コーディングが不要な ETL (または ELT) の実現からデータに対する包括的なビューの作成まで、Azure Data Factory の強化によって、データ エンジニアはより多くのデータを安心して取り込むことができるようになり、ひいては、会社により大きな価値をもたらすことができます。 Azure Data Share を使用すれば、統制された形で企業間の共有を行えます。
このワークショップでは、Azure Data Factory (ADF) を使用して Azure SQL Database から Azure Data Lake Storage Gen2 (ADLS Gen2) にデータを取り込みます。 レイクにデータを配置したら、データ ファクトリのネイティブ変換サービスであるマッピング データ フローを介してそれを変換し、Azure Synapse Analytics にシンクします。 その後、Azure Data Share を使用して、変換済みのデータが含まれたテーブルを別のいくつかのデータと共に共有します。
このラボで使用されるデータは、ニューヨーク市のタクシーのデータです。 これを SQL Database のデータベースにインポートするために、taxi-data.bacpac ファイルをダウンロードしてください。 GitHub で [raw ファイルのダウンロード] オプションを選択します。
前提条件
Azure サブスクリプション:Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。
Azure SQL Database: SQL Database がない場合は、SQL Database の作成方法を確認してください。
Azure Data Lake Storage Gen2 ストレージ アカウント: ADLS Gen2 ストレージ アカウントがない場合は、ADLS Gen2 ストレージ アカウントの作成方法を確認してください。
Azure Synapse Analytics: Azure Synapse Analytics ワークスペースがない場合は、Azure Synapse Analytics の使用を開始する方法を確認してください。
Azure Data Factory: データ ファクトリを作成していない場合は、データ ファクトリの作成方法を確認してください。
Azure Data Share: データ共有を作成していない場合は、データ共有の作成方法を確認してください。
Azure Data Factory 環境を設定する
このセクションでは、Azure portal から Azure Data Factory ユーザー エクスペリエンス (ADF UX) にアクセスする方法について説明します。 ADF UX に移動したら、使用するデータ ストア (Azure SQL Database、ADLS Gen2、Azure Synapse Analytics) ごとに 3 つのリンク サービスを構成します。
Azure Data Factory では、リンク サービスによって外部リソースへの接続情報が定義されます。 Azure Data Factory では現在、85 を超えるコネクタをサポートしています。
Azure Data Factory UX を開く
Microsoft Edge または Google Chrome で Azure portal を開きます。
ページの上部にある検索バーを使用して、「Data Factories」を検索します。
データ ファクトリ リソースを選択して、左側のペインでそのリソースを開きます。
[Open Azure Data Factory Studio](Azure Data Factory Studio を開く) を選択します。 Data Factory Studio は、adf.azure.com から直接アクセスすることもできます。
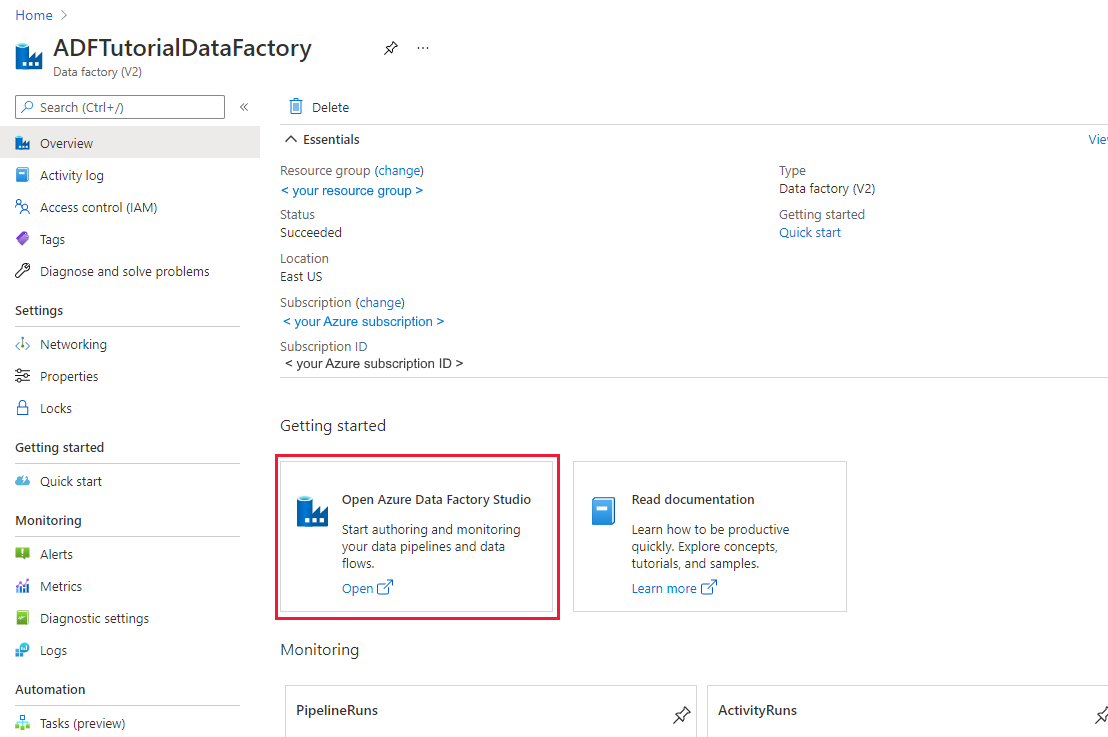
Azure portal の ADF のホームページにリダイレクトされます。 このページには、データ ファクトリの概念について確認できるクイックスタート、説明ビデオ、チュートリアルへのリンクが記載されています。 作成を開始するには、左側のバーにある鉛筆アイコンを選択します。


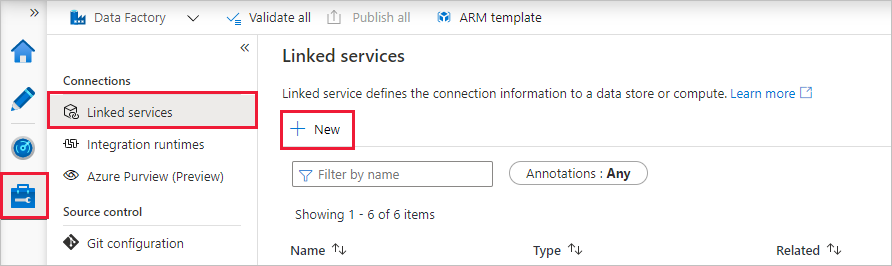
Azure SQL Database のリンクされたサービスを作成する
リンク サービスを作成するには、左側のバーにある [管理] ハブを選択して、 [接続] ペインの [リンクされたサービス] を選択し、 [New](新規) を選択して新しいリンク サービスを追加します。
最初に構成するリンク サービスは Azure SQL Database です。 検索バーを使用して、データ ストアの一覧をフィルタリングできます。 [Azure SQL Database] タイルを選択して [続行] を選択します。

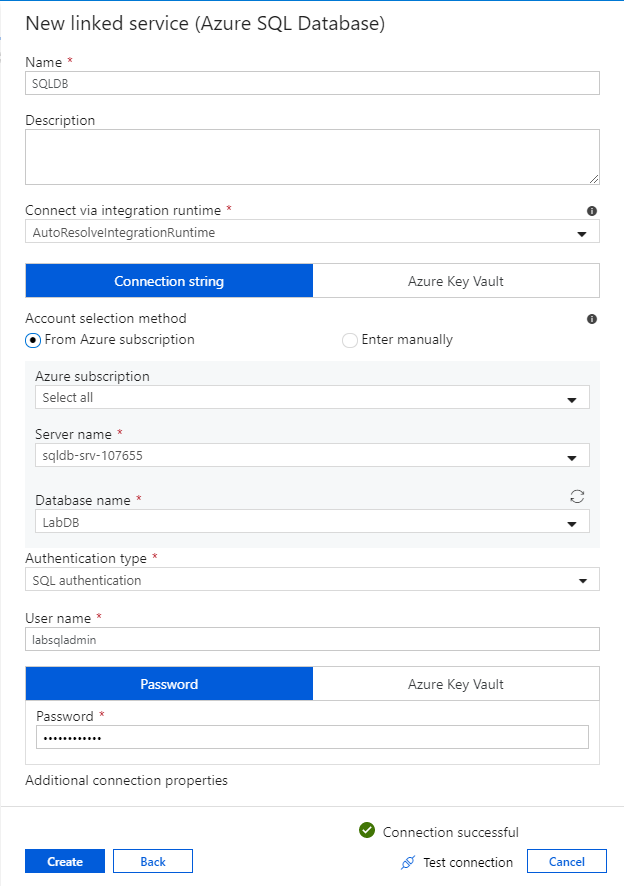
SQL Database 構成ペインで、リンク サービスの名前として「SQLDB」を入力します。 データ ファクトリが自分のデータベースに接続できるように資格情報を入力します。 SQL 認証を使用する場合は、サーバー名、データベース、自分のユーザー名とパスワードを入力します。 [Test connection](接続のテスト) を選択すると、接続情報が正しいことを確認できます。 入力し終えたら [作成] を選択します。

Azure Synapse Analytics のリンクされたサービスを作成する
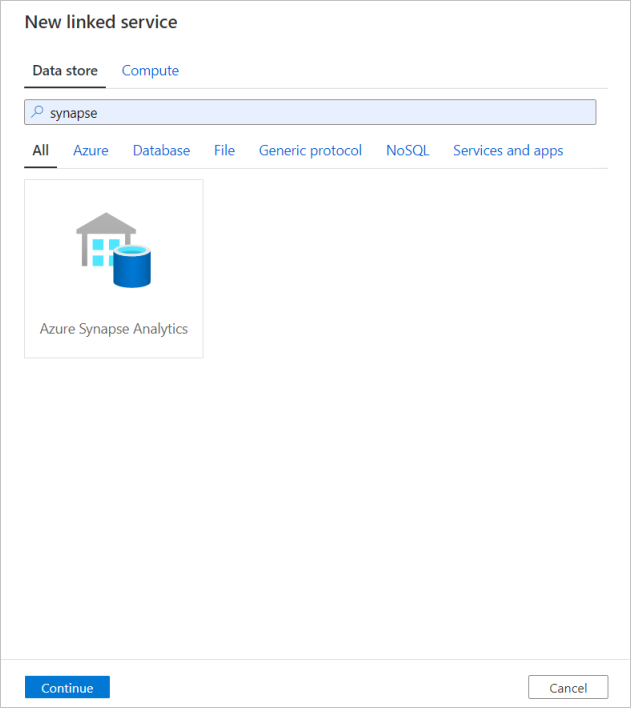
同じ手順を繰り返して、Azure Synapse Analytics のリンクされたサービスを追加します。 [接続] タブで、[新規] を選択します。 [Azure Synapse Analytics] タイルを選択して [続行] を選択します。
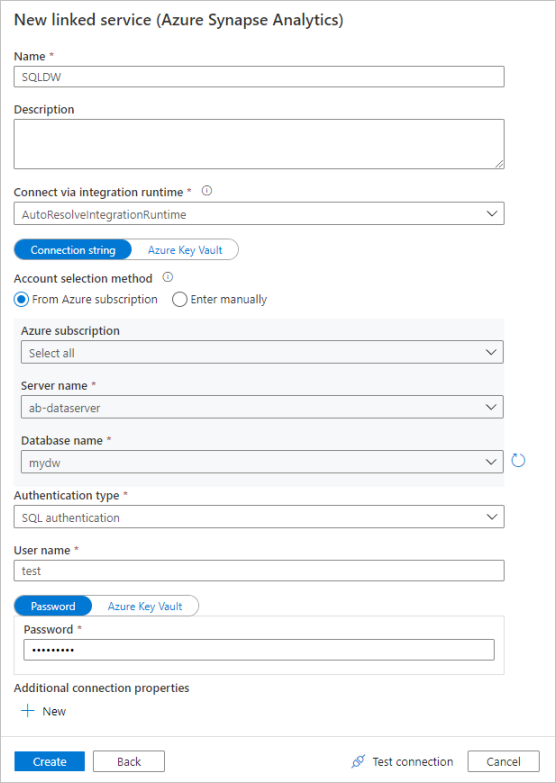
リンク サービスの構成ペインで、リンク サービスの名前として「SQLDW」を入力します。 データ ファクトリが自分のデータベースに接続できるように資格情報を入力します。 SQL 認証を使用する場合は、サーバー名、データベース、自分のユーザー名とパスワードを入力します。 [Test connection](接続のテスト) を選択すると、接続情報が正しいことを確認できます。 入力し終えたら [作成] を選択します。
Azure Data Lake Storage Gen2 のリンクされたサービスを作成する
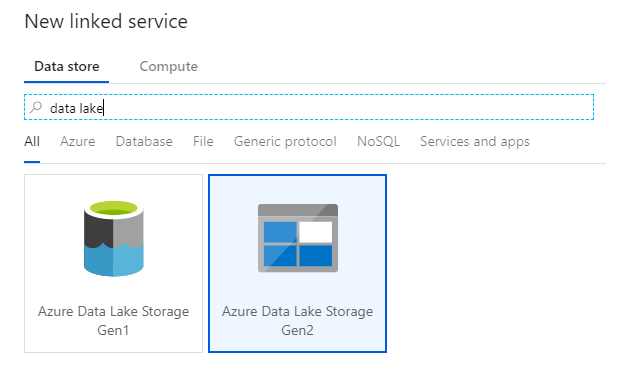
このラボに必要な最後のリンク サービスは、Azure Data Lake Storage Gen2 です。 [接続] タブで、[新規] を選択します。 [Azure Data Lake Storage Gen2] タイルを選択し、[続行] を選択します。
リンクされたサービスの構成ペインで、リンクされたサービスの名前として「ADLSGen2」を入力します。 アカウント キー認証を使用する場合は、[ストレージ アカウント名] ドロップダウン リストから目的の ADLS Gen2 ストレージ アカウントを選択します。 [Test connection](接続のテスト) を選択すると、接続情報が正しいことを確認できます。 入力し終えたら [作成] を選択します。
データ フローのデバッグ モードを有効にする
「マッピング データ フローを使用してデータを変換する」セクションでは、マッピング データ フローを作成します。 マッピング データ フローを作成する前に、デバッグ モードを有効にしておくことをお勧めします。これにより、アクティブな Spark クラスターで変換ロジックを数秒でテストできます。
デバッグを有効にするには、[データ フロー] アクティビティがある状態で、データ フロー キャンバスまたはパイプライン キャンバスの上部のバーにある [データ フローのデバッグ] スライダーを選択します。 確認のダイアログが表示されたら [OK] を選択します。 クラスターは約 5 分から 7 分で起動します。 初期化されている間に、「コピー アクティビティを使用して Azure SQL Database から ADLS Gen2 にデータを取り込む」に進んでください。

コピー アクティビティを使用してデータを取り込む
このセクションでは、Azure SQL Database から ADLS Gen2 ストレージ アカウントにテーブルを 1 つ取り込むコピー アクティビティを含んだパイプラインを作成します。 ADF UX を介してパイプラインを追加し、データセットを構成して、パイプラインをデバッグする方法を見ていきましょう。 このセクションで使用される構成パターンは、リレーショナル データ ストアからファイルベースのデータ ストアへのコピーに適用できます。
Azure Data Factory におけるパイプラインは、1 つのタスクを連携して実行するアクティビティの論理的なグループです。 自分のデータに対して実行する操作は、アクティビティによって定義されます。 リンクされたサービスでは、使用するデータがデータセットによって参照されます。
コピー アクティビティを含むパイプラインを作成する
ファクトリ リソース ペインのプラス アイコンを選択して、新しいリソースのメニューを開きます。 [パイプライン] を選択します。
パイプライン キャンバスの [General](全般) タブで、パイプラインにわかりやすい名前を付けます (例: "IngestAndTransformTaxiData")。
パイプライン キャンバスのアクティビティ ペインで [移動と変換] アコーディオンを開き、 [データ コピー] アクティビティをキャンバスにドラッグします。 コピー アクティビティにわかりやすい名前を付けます (例: "IngestIntoADLS")。
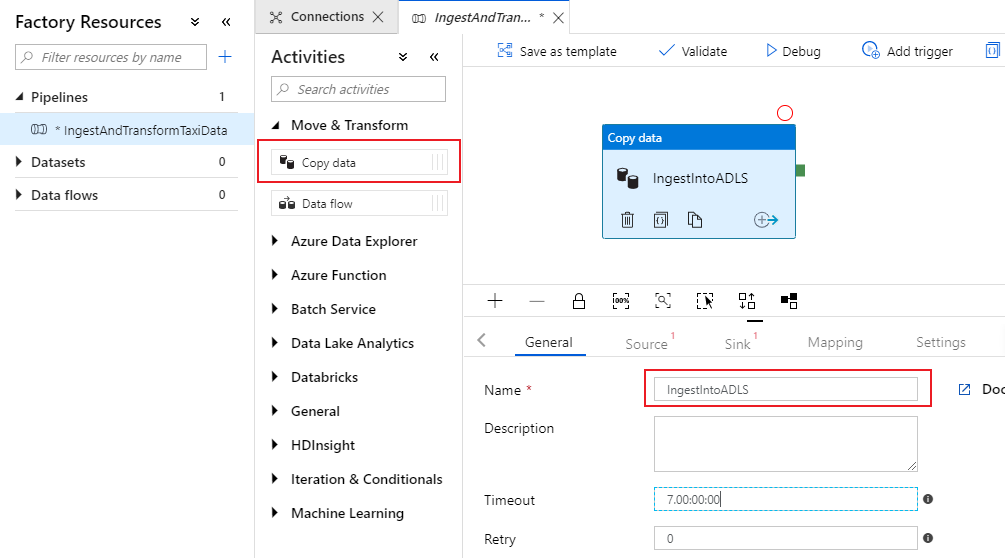


Azure SQL DB ソース データセットを構成する
コピー アクティビティの [ソース] タブを選択します。 新しいデータセットを作成するには、[新規] を選択します。 ソースは、先ほど構成したリンク サービス 'SQLDB' にある
dbo.TripDataテーブルになります。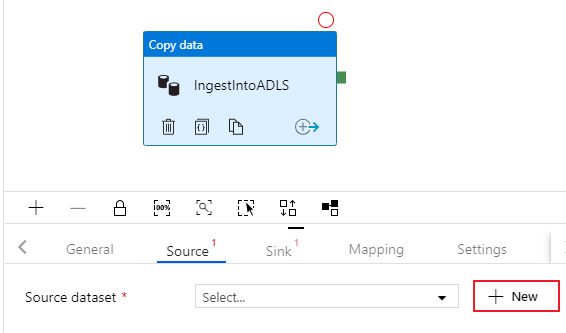
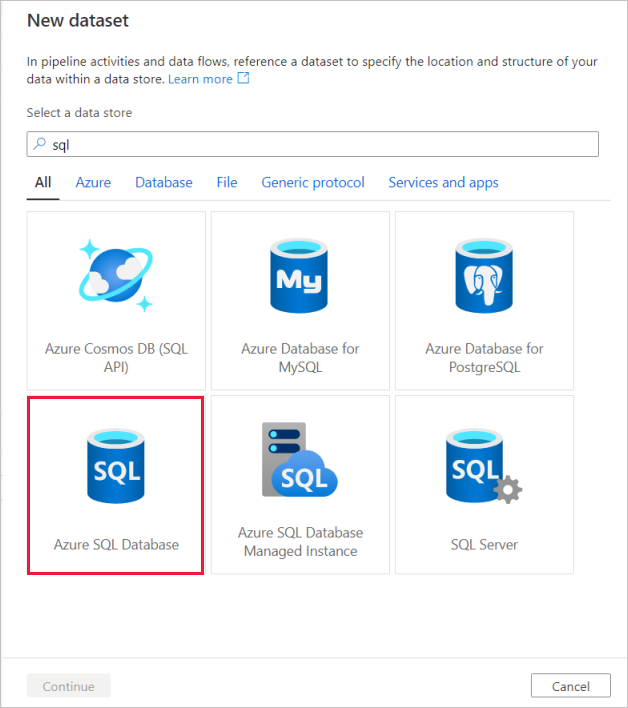
[Azure SQL Database] を検索して [続行] を選択します。
データセットに "TripData" という名前を付けます。 リンクされたサービスとして、[SQLDB] を選択してください。 テーブル名のドロップダウン リストからテーブル名
dbo.TripDataを選択します。 [From connection/store](接続/ストアから) スキーマをインポートします。 終わったら [OK] を選択します。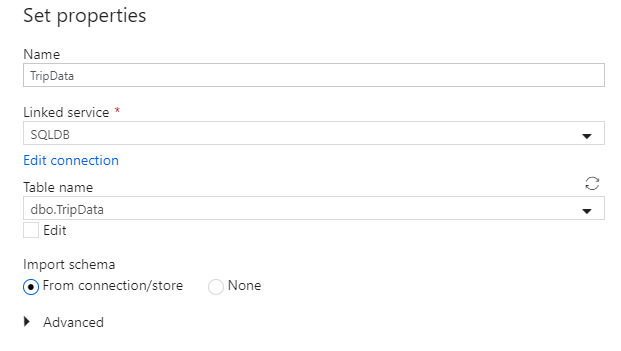
これでソース データセットが正しく作成されました。 ソースの設定の [use query](クエリの使用) フィールドで、既定値である [テーブル] が選択されていることを確認してください。
ADLS Gen2 シンク データセットを構成する
コピー アクティビティの [シンク] タブを選択します。 新しいデータセットを作成するには、[新規] を選択します。
[Azure Data Lake Storage Gen2] を検索し、[続行] を選択します。
[形式の選択] ペインで [DelimitedText] を選択します。ここでは、CSV ファイルに書き込みます。 [続行] を選択します。

シンク データセットに "TripDataCSV" という名前を付けます。 リンクされたサービスとして、[ADLSGen2] を選択してください。 CSV ファイルの書き込み先を入力します。 たとえば、
staging-containerというコンテナー内のファイルtrip-data.csvにデータを書き込むことができます。 出力データにヘッダーを含めたいので、 [First row as header](先頭の行を見出しとして使用) を true に設定します。 コピー先にはまだファイルが存在しないため、 [スキーマのインポート] は [なし] に設定します。 終わったら [OK] を選択します。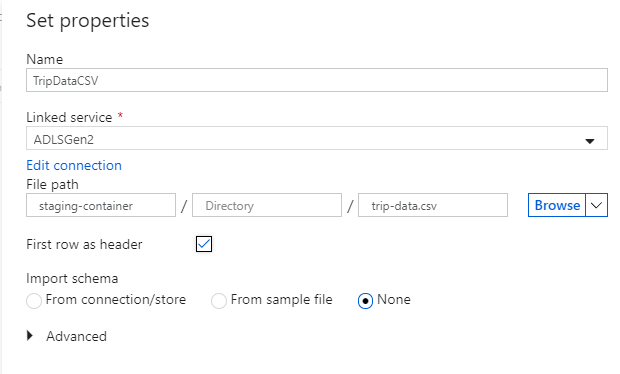
パイプラインのデバッグ実行でコピー アクティビティをテストする
コピー アクティビティが正しく動作していることを確認するために、パイプライン キャンバスの上部にある [デバッグ] を選択してデバッグを実行します。 デバッグ実行では、データ ファクトリ サービスに発行するパイプラインを、あらかじめエンド ツー エンドで、またはブレークポイントまでテストすることができます。
デバッグ実行を監視するために、パイプライン キャンバスの [出力] タブに移動します。 監視画面は、[更新] ボタンを手動で選択したとき、または 20 秒おきに自動更新されます。 コピー アクティビティには、特殊な監視ビューが用意されています。このビューには、[アクション] 列の眼鏡アイコンを選択するとアクセスできます。
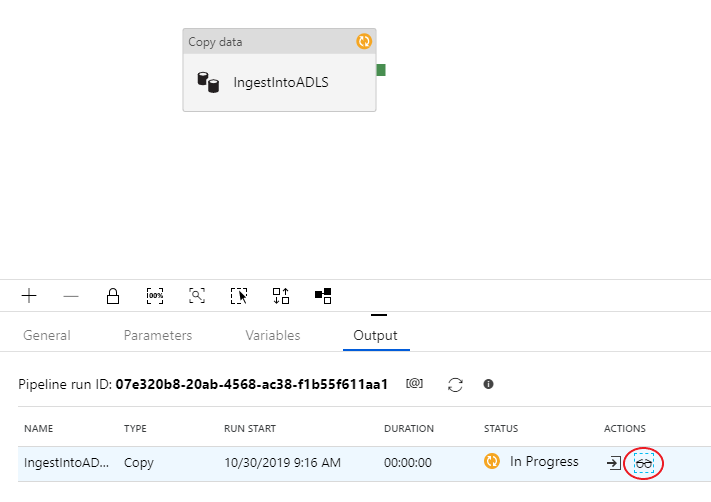
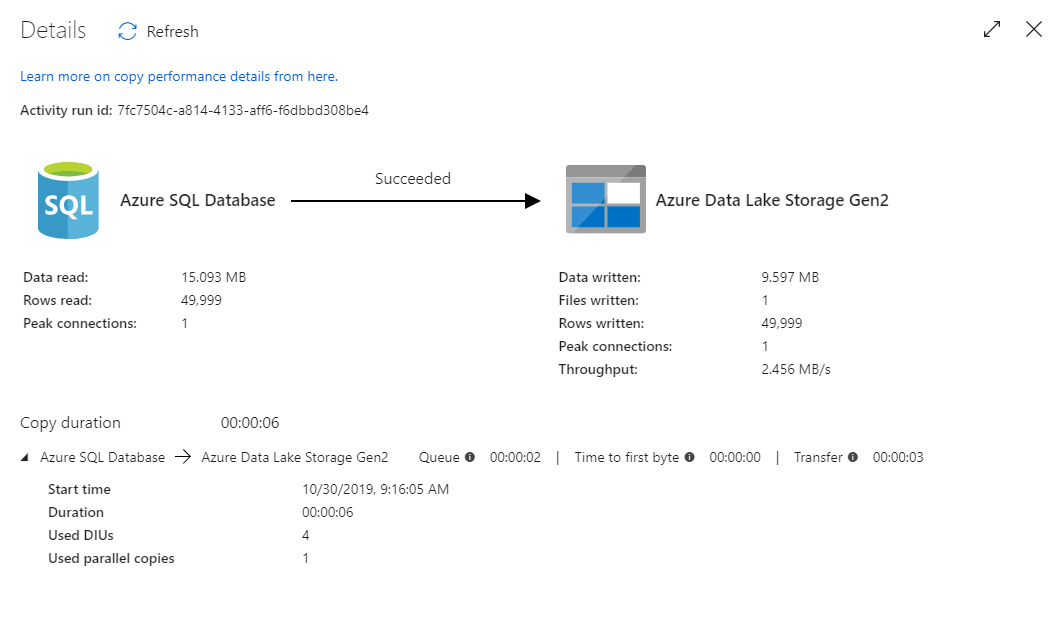
コピーの監視ビューには、アクティビティの実行に関する詳しい情報やパフォーマンス特性が表示されます。 読み書きされたデータ、読み書きされた行、読み書きされたファイル、スループットなどの情報を確認できます。 すべて正しく構成されていれば、ADLS シンク内の 1 つのファイルに書き込まれた 49,999 件の行が表示されるはずです。
次のセクションに進む前に、ファクトリ上部のバーにある [すべて発行] を選択して、変更内容をデータ ファクトリ サービスに発行しておくことをお勧めします。 このラボでは説明しませんが、Azure Data Factory では Git との完全な統合がサポートされます。 Git 統合によって、バージョン コントロール、リポジトリへの反復的保存、データ ファクトリでのコラボレーションが可能となります。 詳細については、「Azure Data Factory でのソース管理」を参照してください。


マッピング データ フローを使用してデータを変換する
Azure Data Lake Storage にデータを正しくコピーできたら、そのデータを結合し、集約してデータ ウェアハウスに格納します。 ここでは、視覚的に設計できる Azure Data Factory の変換サービス、マッピング データ フローを使用します。 マッピング データ フローを使用するとユーザーは、コーディングなしで変換ロジックを開発し、ADF サービスによって管理された Spark クラスターでそれらを実行することができます。
この手順で作成したデータ フローは、前セクションで作成した 'TripDataCSV' データセットと、'SQLDB' に格納された dbo.TripFares テーブルとを 4 つのキー列に基づいて内部結合します。 その後、データは payment_type 列に基づいて集計され、特定のフィールドの平均が計算されて、Azure Synapse Analytics テーブルに書き込まれます。
データ フロー アクティビティをパイプラインに追加する
パイプライン キャンバスのアクティビティ ペインで [移動と変換] アコーディオンを開き、 [データ フロー] アクティビティをキャンバスにドラッグします。
開いたサイド ペインで [Create new data flow](新しいデータ フローの作成) を選択し、 [マッピング データ フロー] を選択します。 [OK] を選択します。

変換ロジックを構築するためのデータ フロー キャンバスに誘導されます。 [General](全般) タブで、データ フローに "JoinAndAggregateData" という名前を付けます。



乗車データの CSV ソースを構成する
最初に、2 つのソース変換を構成する必要があります。 1 つ目のソースの参照先は、'TripDataCSV' DelimitedText データセットです。 ソース変換を追加するには、キャンバスにある [ソースの追加] ボックスを選択します。
ソースに 'TripDataCSV' という名前を付け、ソースのドロップダウン リストから 'TripDataCSV' データセットを選択します。 最初、このデータセットを作成するときにはデータが存在していなかったため、スキーマをインポートしなかったことを思い出してください。 現在は
trip-data.csvが存在するので、[編集] を選択して、データセットの設定タブに移動します。
[スキーマ] タブに移動し、[スキーマのインポート] を選択します。 ファイル ストアから直接インポートするには、 [From connection/store](接続/ストアから) を選択します。 文字列型の 14 個の列が表示されます。
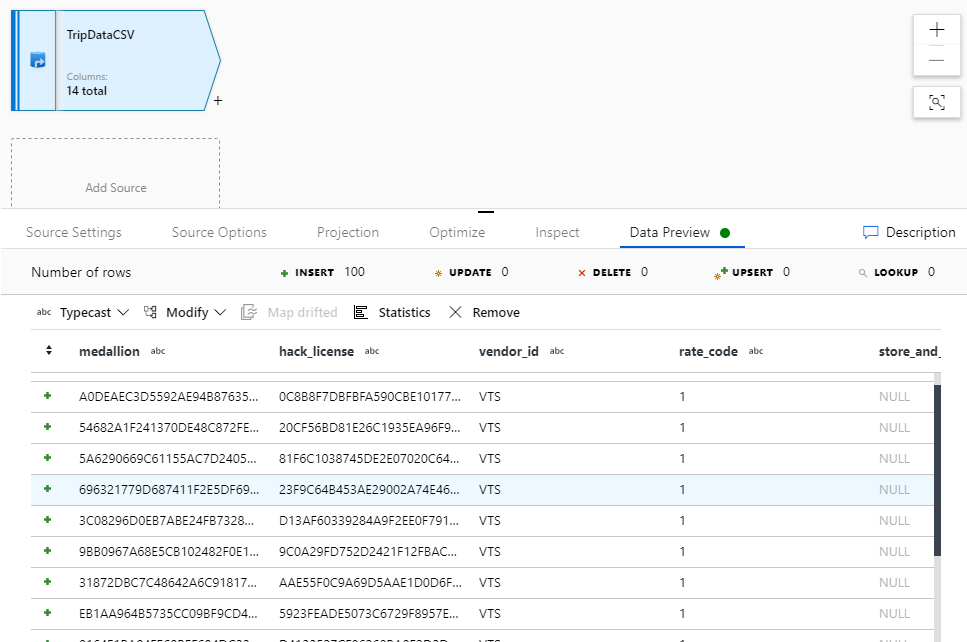
データ フロー "JoinAndAggregateData" に戻ります。 デバッグ クラスターが起動済み (デバッグ スライダーの横の緑色の円で示されます) である場合、[データのプレビュー] タブでデータのスナップショットを取得できます。[最新の情報に更新] を選択して、データのプレビューを取得します。


Note
データのプレビューでは、データは書き込まれません。
乗車料金の SQL Database ソースを構成する
追加する 2 つ目のソースは、SQL Database テーブル
dbo.TripFaresを参照します。 'TripDataCSV' ソースの下に、別の [ソースの追加] ボックスが表示されます。 これを選択して、新しいソース変換を追加します。
このソースには "TripFaresSQL" という名前を付けます。 ソース データセット フィールドの横にある [新規] を選択して、新しい SQL Database データセットを作成します。
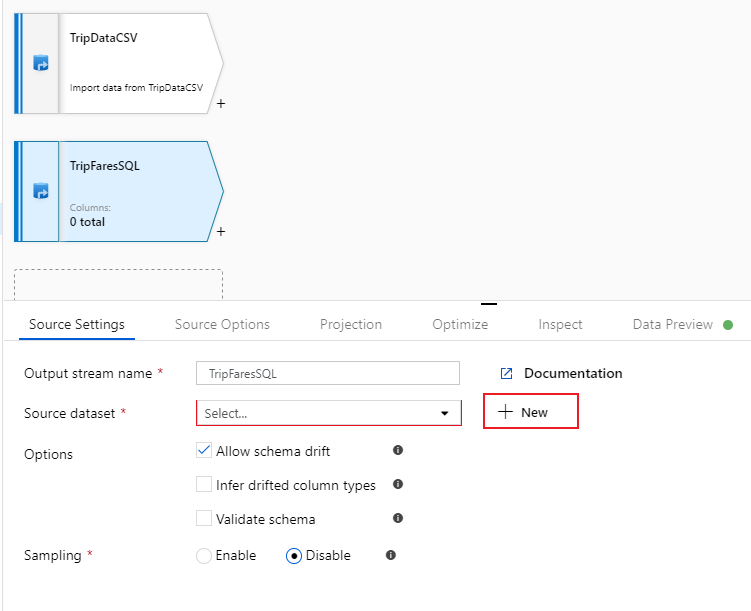
[Azure SQL Database] タイルを選択して [続行] を選択します。 お気付きかもしれませんが、データ ファクトリにあるコネクタの多くが、マッピング データ フローではサポート対象外となっています。 これらのソースのいずれかからデータを変換するには、コピー アクティビティを使用して、サポート対象のソースにデータを取り込んでください。

データセットに "TripFares" という名前を付けます。 リンクされたサービスとして、[SQLDB] を選択してください。 テーブル名のドロップダウン リストからテーブル名
dbo.TripFaresを選択します。 [From connection/store](接続/ストアから) スキーマをインポートします。 終わったら [OK] を選択します。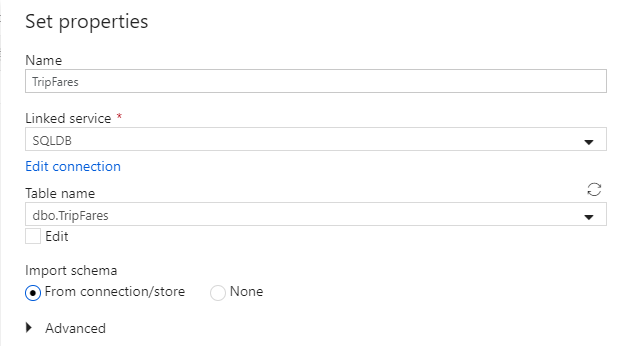
データを確認するために、 [データのプレビュー] タブでデータ プレビューをフェッチします。
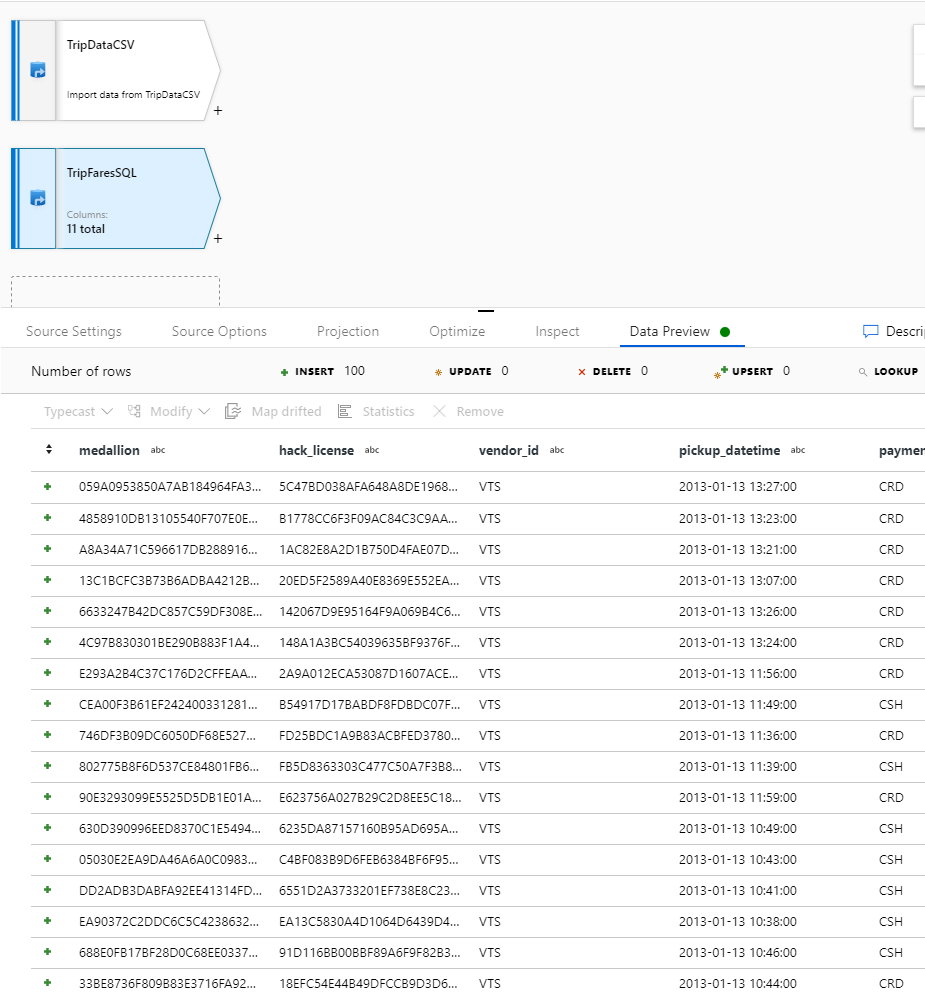

TripDataCSV と TripFaresSQL を内部結合する
新しい変換を追加するには、"TripDataCSV" の右下隅にあるプラス アイコンを選択します。 [Multiple inputs/outputs](複数の入出力) の [結合] を選択します。
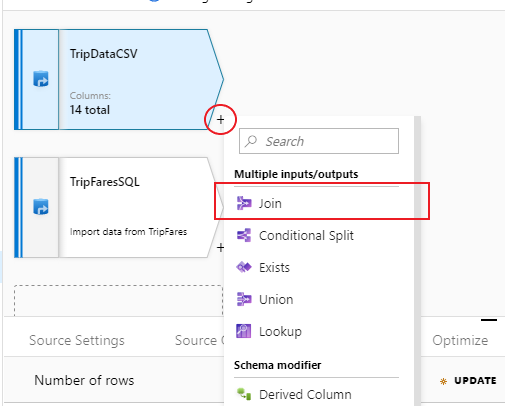
結合変換に "InnerJoinWithTripFares" という名前を付けます。 右側のストリームのドロップダウン リストから 'TripFaresSQL' を選択します。 結合の種類として [内部] を選択します。 マッピング データ フローにおけるさまざまな結合の種類について詳しくは、結合の種類に関するセクションを参照してください。
[結合条件] ドロップダウン リストで、それぞれのストリームから突き合わせる列を選択します。 さらに結合条件を追加したければ、既存の条件の横にあるプラス アイコンを選択してください。 既定では、すべての結合条件が AND 演算子で組み合わされます。つまり、すべての条件が満たされたときに初めて一致と見なされます。 このラボでは、
medallion、hack_license、vendor_id、pickup_datetimeの各列で突き合わせを行います。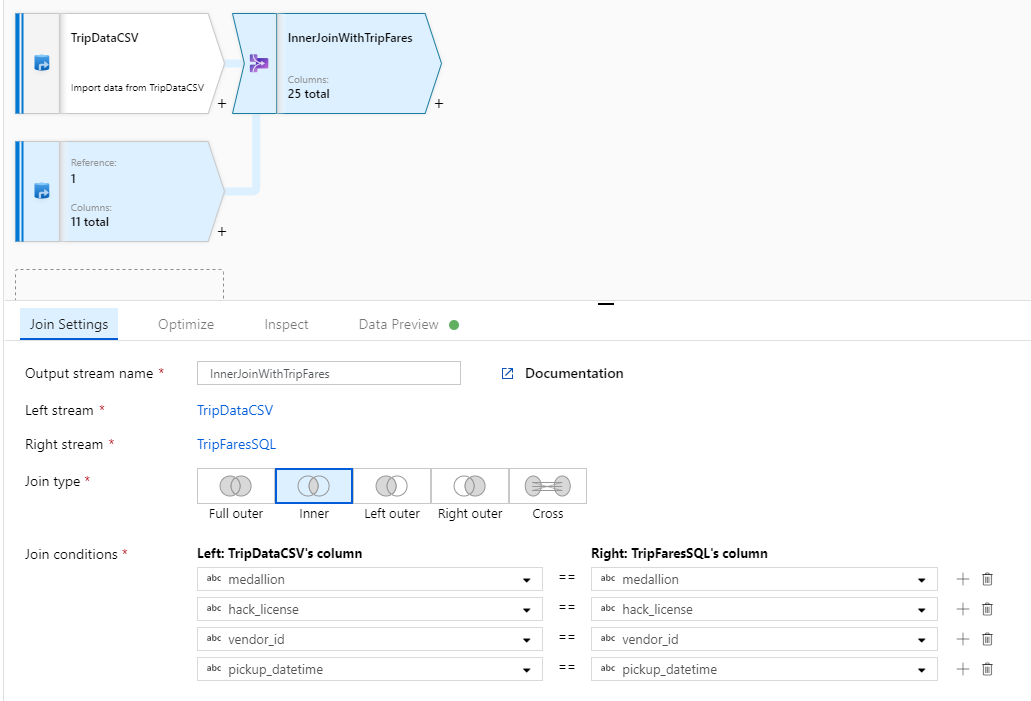
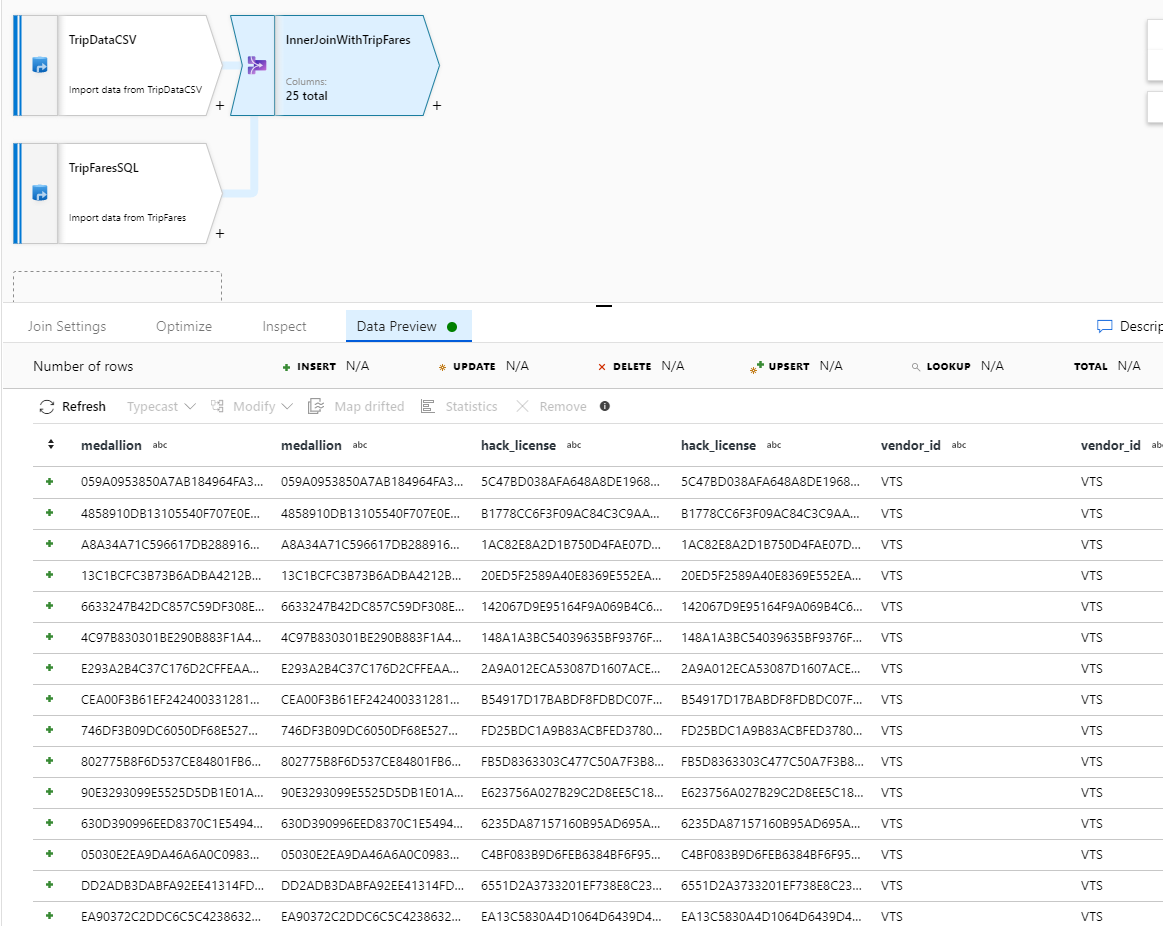
データのプレビューで、25 個の列が正常に結合されたことを確認します。


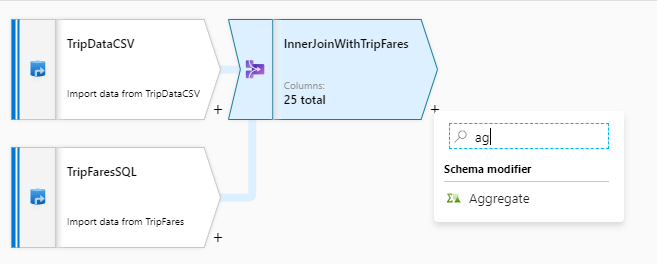
payment_type ごとに集計する
結合変換が完了したら、InnerJoinWithTripFares の横にあるプラス アイコンを選択して集計変換を追加します。 [Schema modifier](スキーマ修飾子) の [Aggregate](集計) を選択します。
集計変換に "AggregateByPaymentType" という名前を付けます。 グループ化列として
payment_typeを選択します。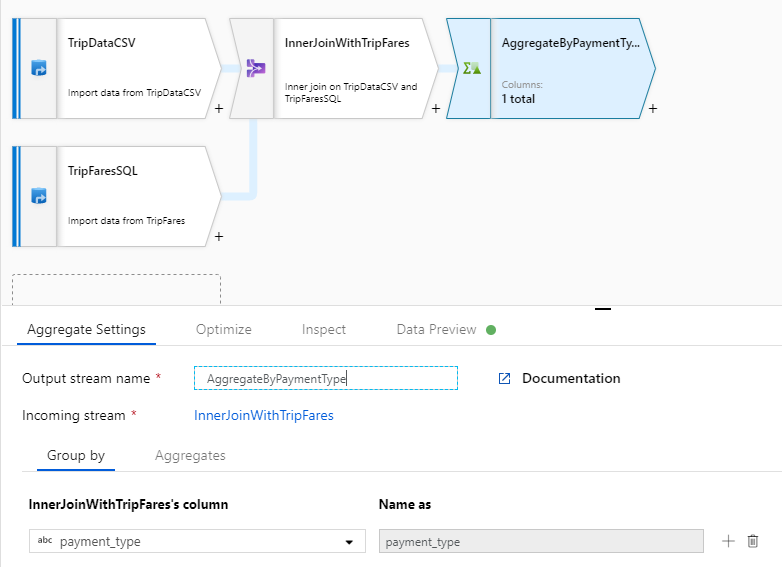
[集計] タブに移動します。次の 2 つの集計を指定します。
- 支払いの種類ごとにグループ化された平均料金
- 支払いの種類ごとにグループ化された合計乗車距離
まず、平均料金の式を作成しましょう。 [Add or select a column](列の追加または選択) テキスト ボックスに「average_fare」と入力します。
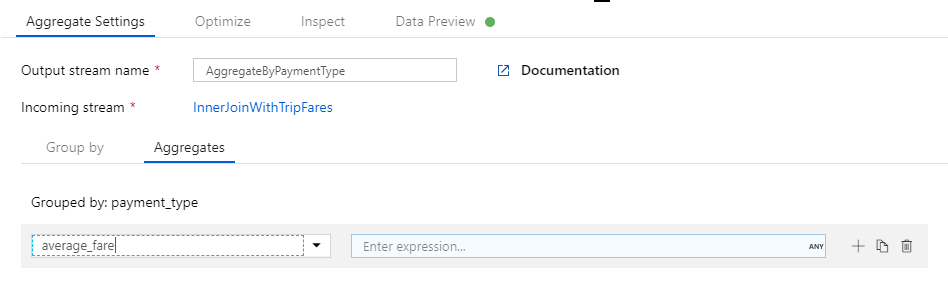
集計式を入力するには、Enter 式というラベルの付いた青いボックスを選択し、データ フローの式ビルダーを起動します。これは、入力スキーマや組み込みの関数と演算子、ユーザー定義のパラメーターを使用してデータ フローの式を視覚的に作成するためのツールです。 式ビルダーの機能について詳しくは、式ビルダーのドキュメントを参照してください。
平均料金を取得するために、
total_amount列をtoInteger()で整数にキャストした結果を、avg()集計関数を使用して集計します。 データ フロー式の言語では、avg(toInteger(total_amount))として定義されます。 完了したら、[Save and finish](保存して終了する) を選択します。
もう 1 つ集計式を追加するために、
average_fareの横にあるプラス アイコンを選択します。 [Add column](列の追加) を選択してください。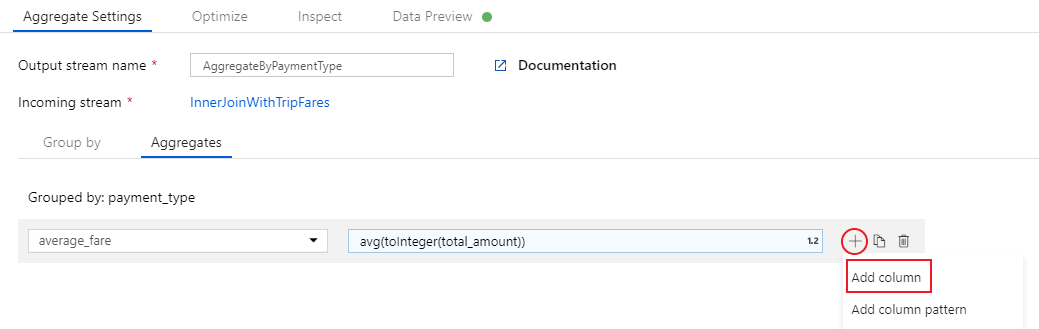
[Add or select a column](列の追加または選択) テキスト ボックスに「total_trip_distance」と入力します。 直前の手順と同様に、式ビルダーを開いて式を入力します。
合計乗車距離を取得するには、
trip_distance列をtoInteger()で整数にキャストし、sum()集計関数を使用してその結果を集計します。 データ フロー式の言語では、sum(toInteger(trip_distance))として定義されます。 完了したら、[Save and finish](保存して終了する) を選択します。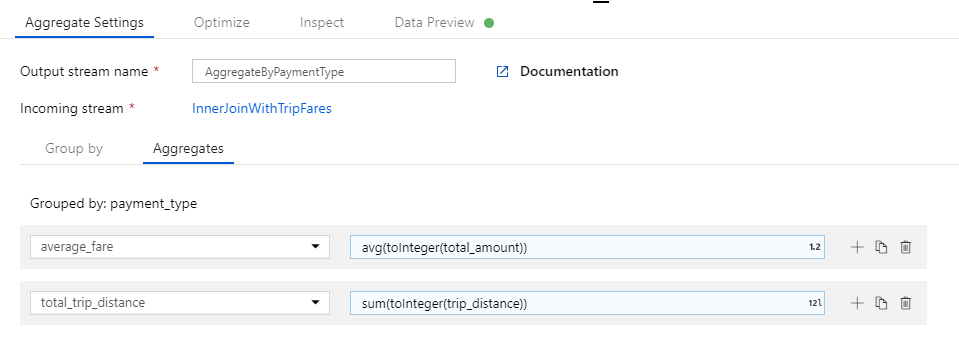
[データのプレビュー] タブで変換ロジックをテストします。ご覧のように、行と列が先ほどと比べ大幅に少なくなっていることがわかります。 この変換で定義されているグループ化列と集計列は 3 つだけです。その 3 つが引き続きダウンストリームに送られることになります。 このサンプルには、支払いの種類のグループが 5 つしか存在しないため、出力される行も 5 つだけです。
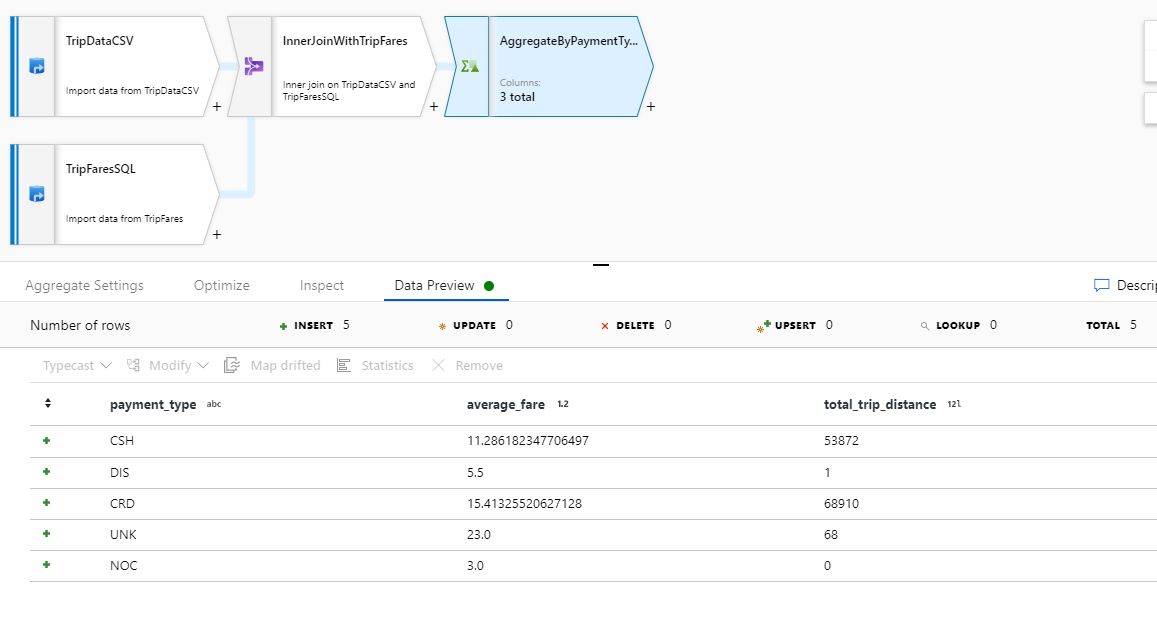





Azure Synapse Analytics シンクを構成する
変換ロジックが完成し、Azure Synapse Analytics テーブルにデータを書き込む準備が整いました。 [Destination](コピー先) セクションの下にシンク変換を追加します。
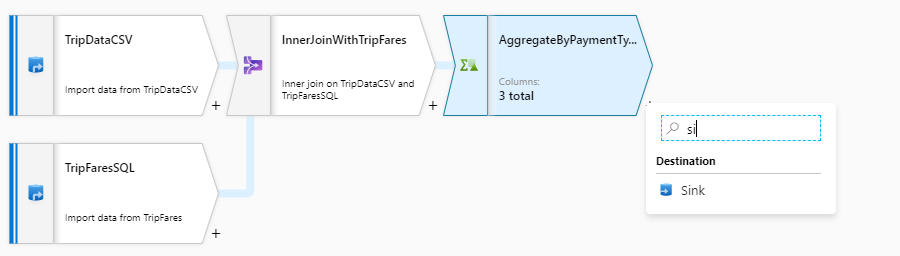
シンクに "SQLDWSink" という名前を付けます。 シンク データセット フィールドの横にある [新規] を選択して、新しい Azure Synapse Analytics データセットを作成します。
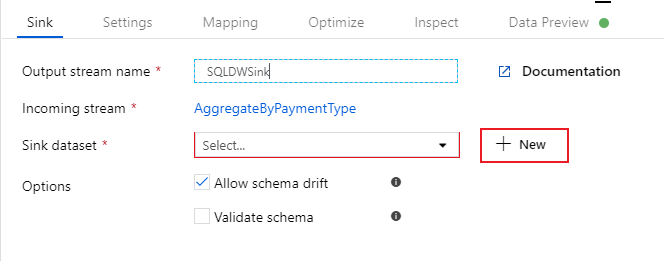
[Azure Synapse Analytics] タイルを選択して [続行] を選択します。
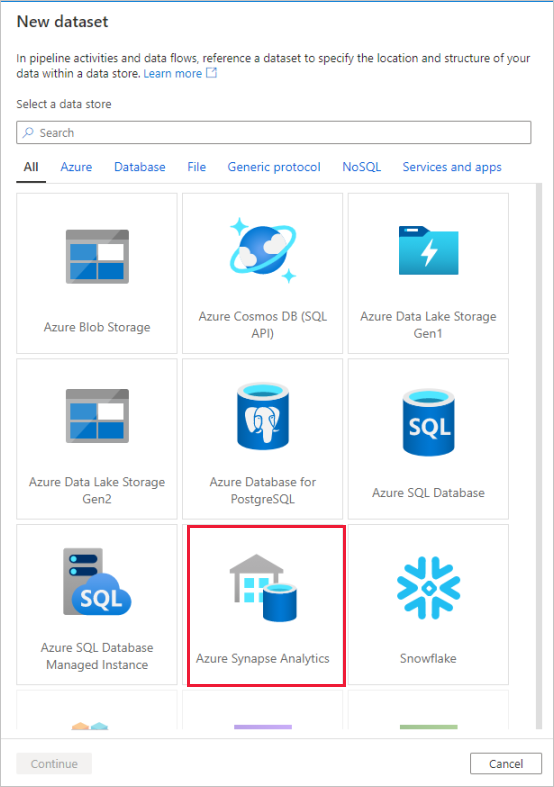
データセットに "AggregatedTaxiData" という名前を付けます。 リンクされたサービスとして、[SQLDW] を選択してください。 [新しいテーブルの作成] を選択し、新しいテーブルに
dbo.AggregateTaxiDataという名前を付けます。 完了したら、OK を選択します。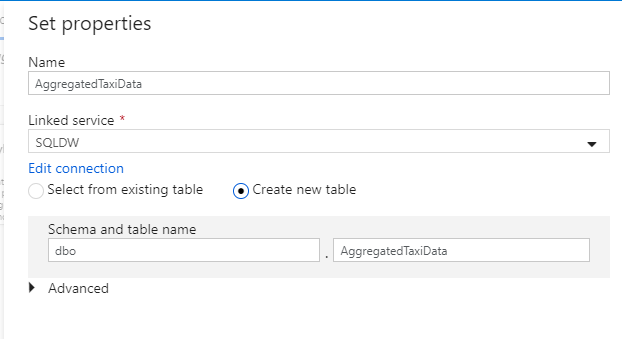
シンクの [設定] タブに移動します。 新しいテーブルを作成することになるので、[Table action](テーブル アクション) の [Recreate table](テーブルの再作成) を選択する必要があります。 挿入を行単位で行うか一括で行うかを切り替える [Enable staging](ステージングの有効化) はオフにしてください。
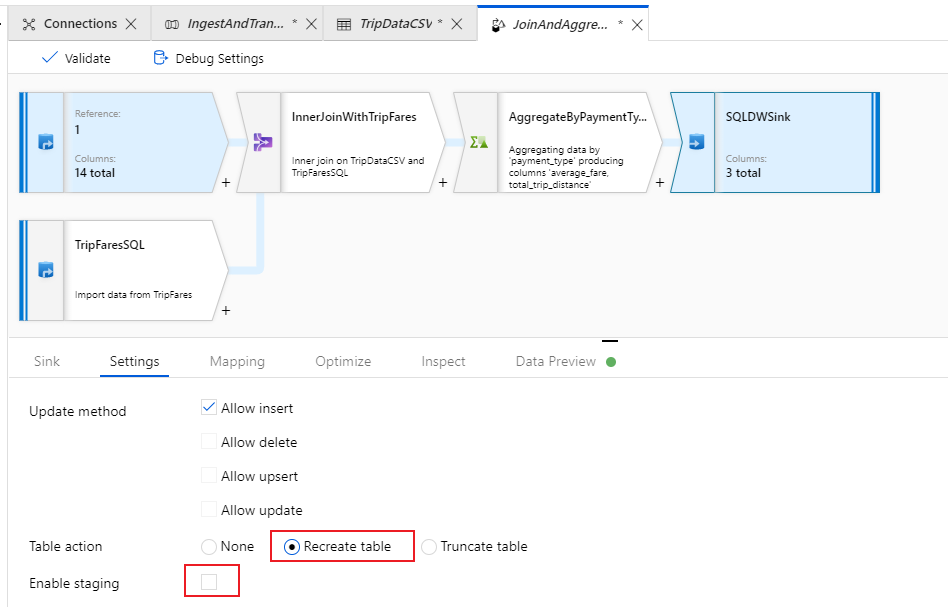


これでデータ フローが正常に作成されました。 今度は、それをパイプライン アクティビティの中で実行してみましょう。
パイプラインをエンド ツー エンドでデバッグする
IngestAndTransformData パイプラインのタブに戻ります。 "IngestIntoADLS" コピー アクティビティの緑色のボックスに注目してください。 これを "JoinAndAggregateData" データ フロー アクティビティにドラッグします。 "on success" が作成され、コピーが成功した場合にのみデータ フロー アクティビティが実行されます。
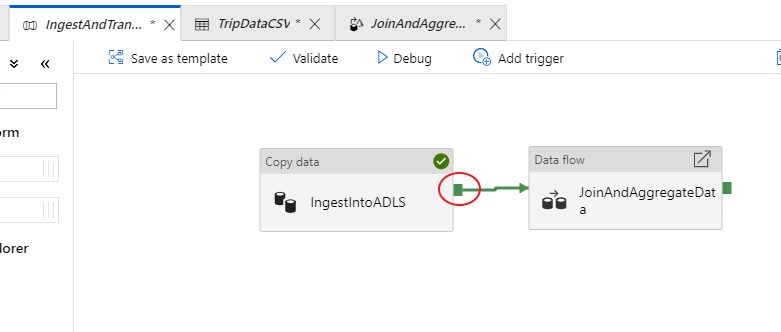
コピー アクティビティで行ったように、[デバッグ] を選択してデバッグを実行します。 デバッグ実行では、新しいクラスターは起動されずに、アクティブなデバッグ クラスターがデータ フロー アクティビティで使用されます。 このパイプラインは、実行に 1 分強かかります。
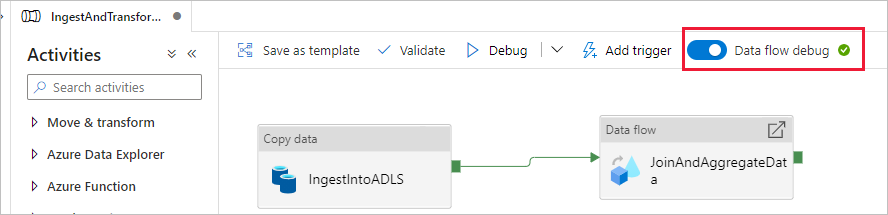
コピー アクティビティと同様、データ フローには、アクティビティの完了時に眼鏡アイコンでアクセスできる特殊な監視ビューが用意されています。
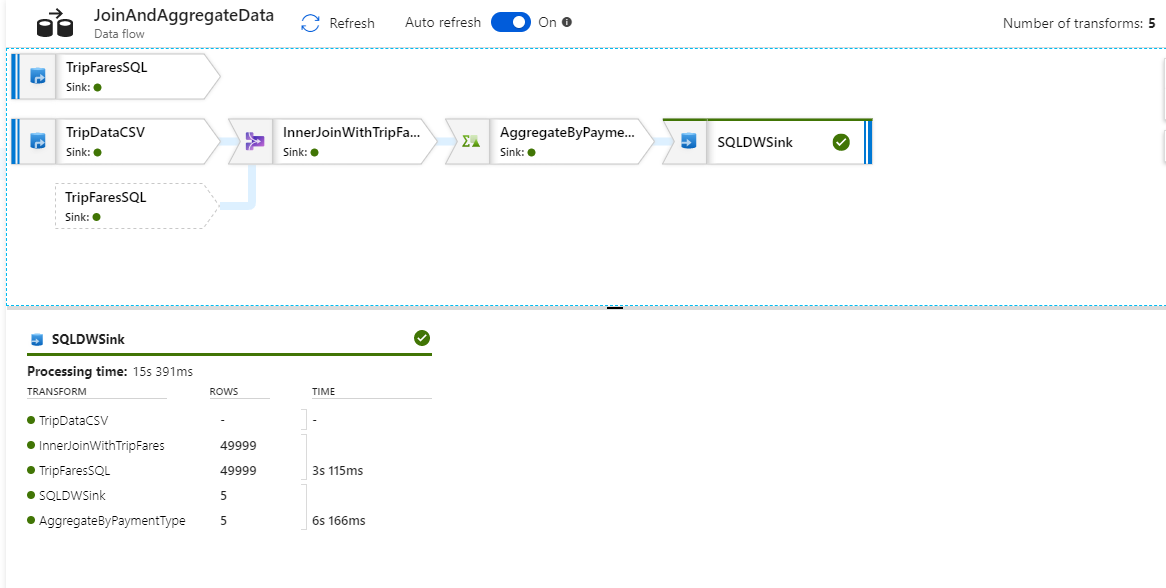
監視ビューで、実行ステージごとの行数や実行時間と共に、簡略化されたデータ フロー グラフを確認できます。 正しく行えば、このアクティビティでは、49,999 件の行が集計されて、5 つの行に格納されているはずです。
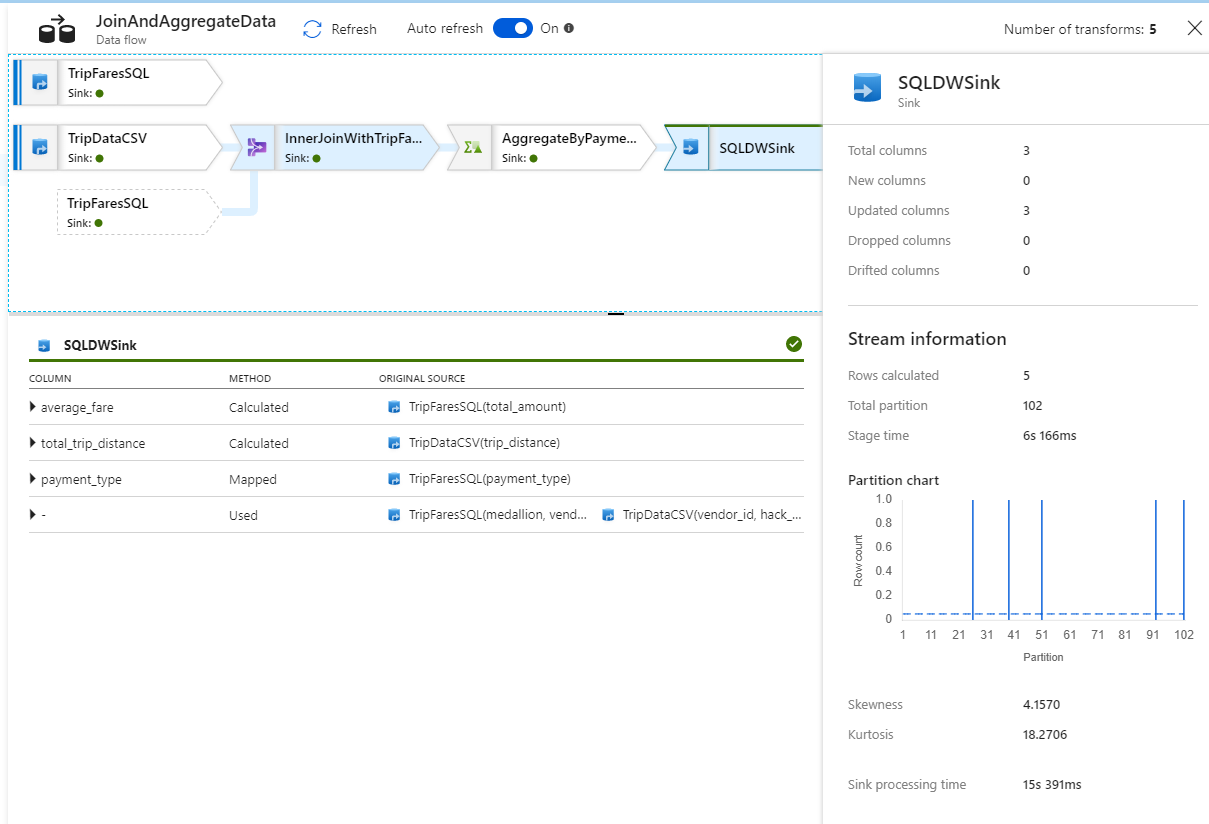
変換を選択すると、パーティション分割情報や、新しい列、更新された列、削除された列など、実行に関するさらに詳しい情報を取得できます。




このラボのデータ ファクトリの部分は、これで完成です。 トリガーを使用して運用したければ、リソースを発行します。 コピー アクティビティを使用して Azure SQL Database から Azure Data Lake Storage にデータを取り込んだ後、そのデータを集計して Azure Synapse Analytics に格納するパイプラインを正常に実行できました。 SQL Server 自体を調べれば、データが正常に書き込まれたことを確認できます。
Azure Data Share を使用したデータの共有
このセクションでは、Azure portal を使用して、新しいデータ共有を設定する方法について説明します。 これには、Azure Data Lake Storage Gen2 と Azure Synapse Analytics からのデータセットを格納する新しいデータ共有を作成する作業が伴います。 その後、スナップショット スケジュールを構成します。データ コンシューマーは、自分に共有されたデータを必要に応じて自動的に更新することができます。 さらに、データ共有に受信者を招待してみましょう。
データ共有を作成したら、"データ コンシューマー" の立場に入れ替わります。 データ コンシューマーとして、データ共有の招待状を受け取るフローをひととおり行いながら、データの受信場所を構成し、異なる保存場所にデータセットをマッピングします。 その後、スナップショットをトリガーすると、共有されたデータが、指定した保存先にコピーされます。
データの共有 (データ プロバイダーのフロー)
Microsoft Edge または Google Chrome で Azure portal を開きます。
ページの上部にある検索バーを使用して、Data Shares を検索します。
名前に "Provider" を含むデータ共有アカウントを選択します (例: DataProvider0102)。
[Start sharing your data](データの共有を開始する) を選択します。
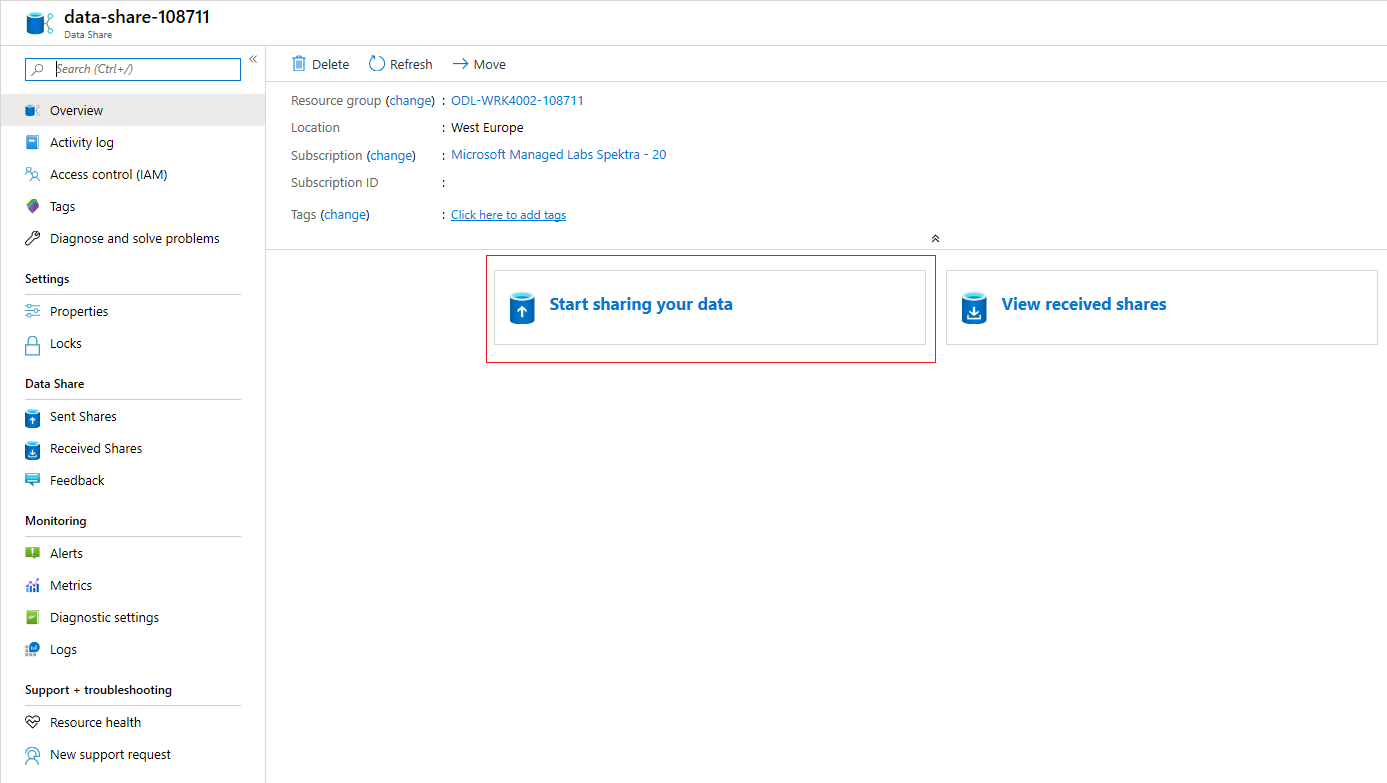
[+ 作成] を選択して、新しいデータ共有の構成を開始します。
[共有名] に、任意の名前を指定します。 データ コンシューマーに表示される共有名であるため、わかりやすい名前 (例: TaxiData) を付けるようにしてください。
[説明] に、データ共有の内容を表す文を入力します。 データ共有には、Azure Synapse Analytics や Azure Data Lake Storage を含むさまざまなストアに格納された世界各地のタクシー乗車データが格納されます。
データ コンシューマーに守ってほしい使用条件を [Terms of use](利用規約) に指定します。 たとえば、「このデータを社外に配布しないこと」や「契約書を参照のこと」と入力します。
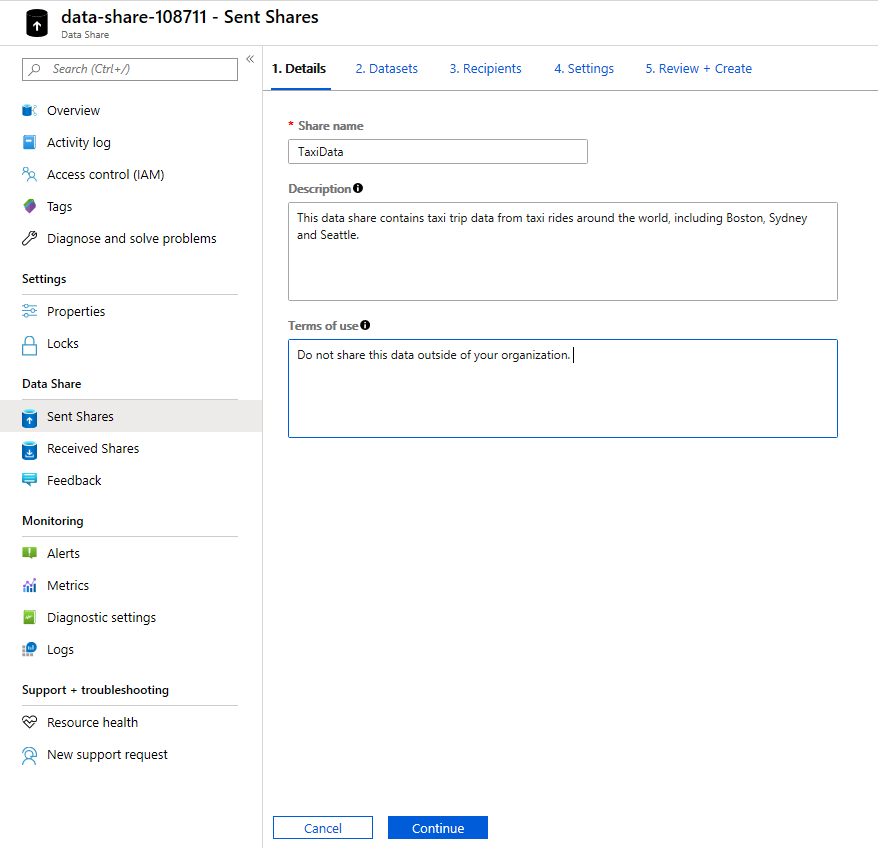
続行を選択します。
[データセットの追加] を選択します。
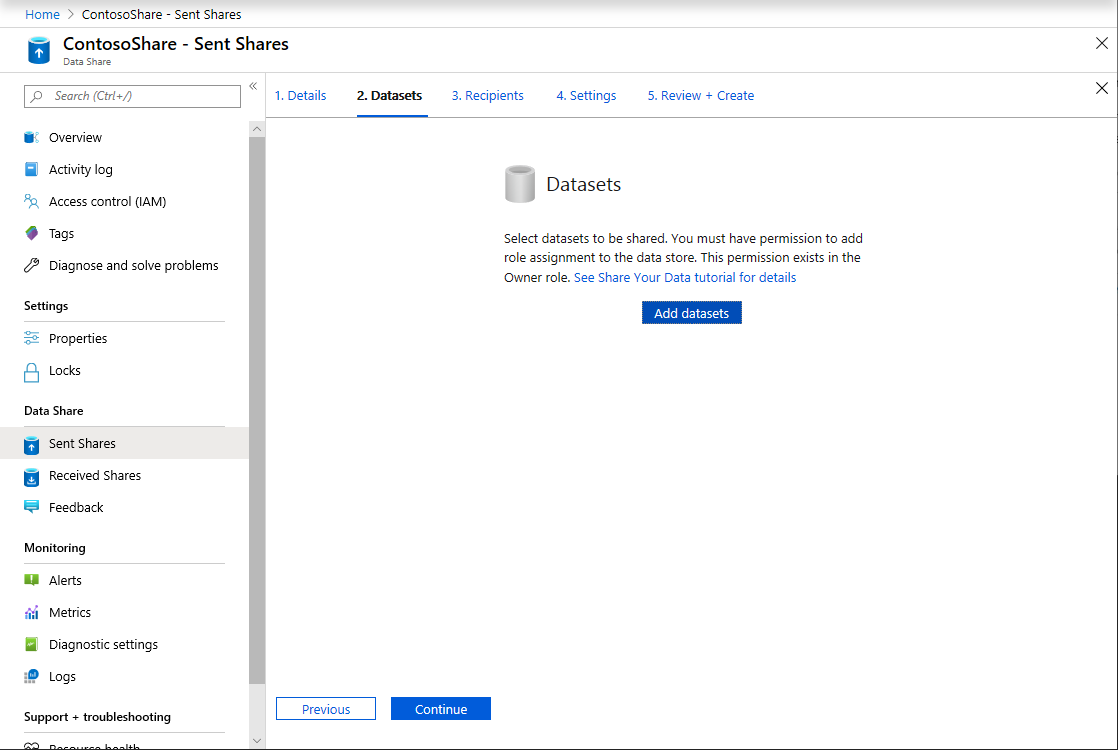
ADF の変換結果が格納される Azure Synapse Analytics からテーブルを選択するため、 [Azure Synapse Analytics] を選択します。
次に進む前に実行すべきスクリプトが提供されます。 提供されたスクリプトによって、Azure Data Share MSI が自己を認証するためのユーザーが SQL データベースに作成されます。
重要
スクリプトを実行する前に、自分自身を Azure SQL Database の論理 SQL サーバーの Active Directory 管理者として設定する必要があります。
新しいタブを開いて Azure portal に移動します。 提供されたスクリプトをコピーして、データの共有元となるユーザーをデータベースに作成します。 これを行うには、Azure portal のクエリ エディターを使用し、Microsoft Entra 認証で EDW データベースにサインインします。 次のサンプル スクリプトでユーザーを変更する必要があります。
CREATE USER [dataprovider-xxxx@contoso.com] FROM EXTERNAL PROVIDER; ALTER ROLE db_owner ADD MEMBER [wiassaf@microsoft.com];先ほどデータセットを追加したデータ共有の Azure Data Share にもう一度切り替えます。
[EDW] を選択し、テーブルに [AggregatedTaxiData] を選択します。
[データセットの追加] を選択します。
これで、データセットの一部である SQL テーブルが完成しました。 次に、Azure Data Lake Storage から別のデータセットを追加します。
[データセットの追加] を選択し、[Azure Data Lake Storage Gen2] を選択します
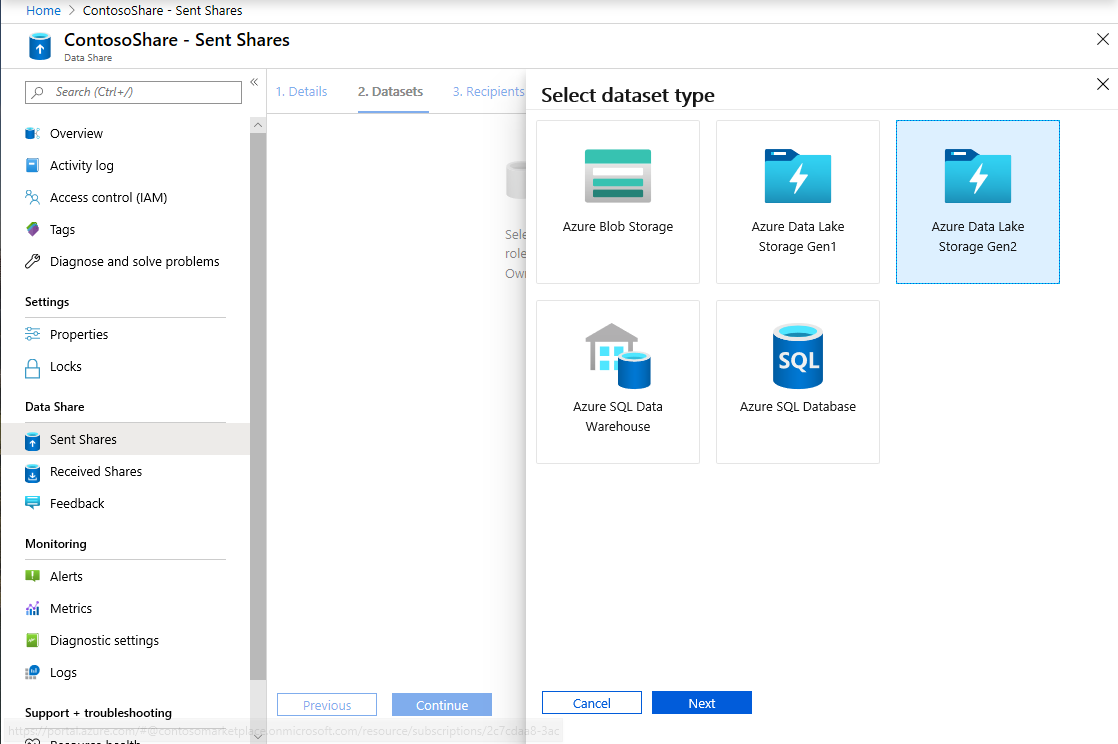
[次へ] を選択します
[wwtaxidata] を展開します。 [Boston Taxi Data](ボストン タクシー データ) を展開します。 ファイル レベルまで共有できます。
Boston Taxi Data フォルダーを選択し、そのフォルダー全体をデータ共有に追加します。
[データセットの追加] を選択します。
追加したデータセットを確認します。 SQL テーブルと ADLS Gen2 フォルダーがデータ共有に追加されているはずです。
[続行] を選択します
この画面では、データ共有に受信者を追加することができます。 追加した受信者には、データ共有への招待状が送信されます。 このラボの目的上、次に示す 2 つの電子メール アドレスを追加する必要があります。
ご利用の Azure サブスクリプションの電子メール アドレス。
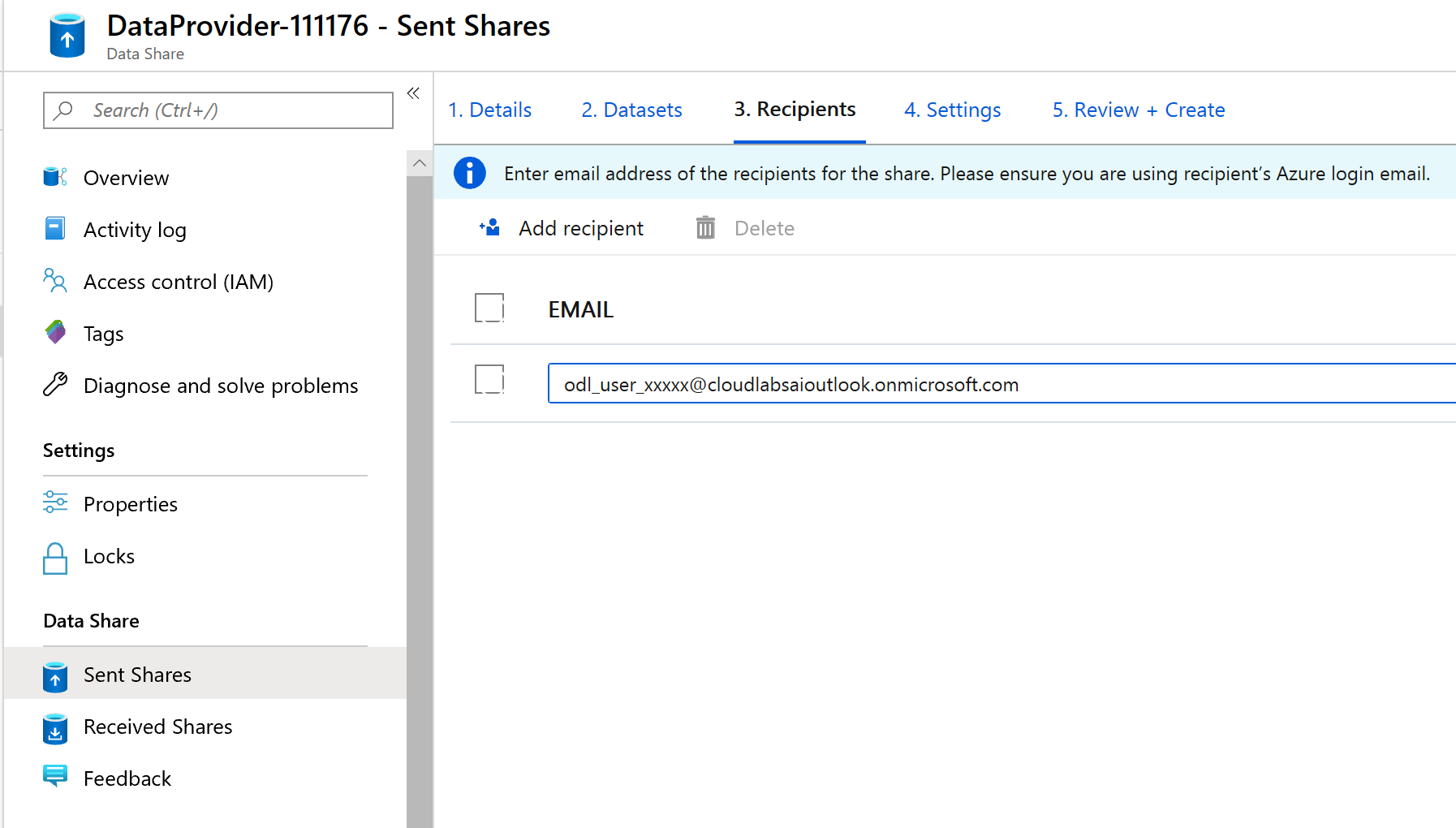
janedoe@fabrikam.com という名前の架空のデータ コンシューマーを追加します。
この画面では、データ コンシューマーのスナップショット設定を構成できます。 そうすることで、自分が定義した間隔で定期的に最新のデータを受信することができます。
[スナップショット スケジュール] チェック ボックスをオンにし、[繰り返し] ドロップダウン リストを使用して、1 時間ごとにデータが更新されるように構成します。
[作成] を選択します
これでアクティブなデータ共有が完成しました。 データ プロバイダーとしてデータ共有を作成する際に何が見えるか確認してみましょう。
作成したデータ共有 (DataProvider) を選択します。 [Data Share] の [送信した共有] を選択して移動できます。
[スナップショット スケジュール] を選択します。 スナップショット スケジュールは、必要に応じて無効にすることもできます。
次に、 [データセット] タブを選択します。このデータ共有には、作成後、さらに別のデータセットを追加することができます。
[共有サブスクリプション] タブを選択します。この時点では、データ コンシューマーがまだ招待を受け入れていないため、共有サブスクリプションは存在しません。
[招待] タブに移動します。ここには、保留中の招待が一覧表示されます。
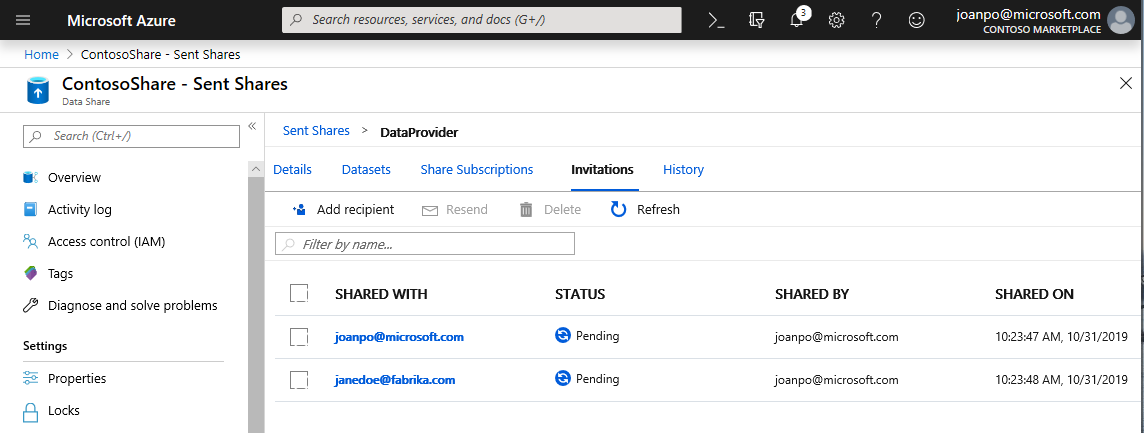
janedoe@fabrikam.com への招待を選択します。 [削除] を選択します。 受信者がまだ招待を受け入れていない場合、以後、招待を受け入れることはできなくなります。
[履歴] タブをクリックします。データ コンシューマーがまだ招待を受け入れておらず、またスナップショットもトリガーしていないため、何も表示されません。






データを受信する (データ コンシューマーのフロー)
以上、データ共有を確認してきました。今度は、データ コンシューマーの立場から見ていきましょう。
受信トレイに、Microsoft Azure から Azure Data Share の招待状が届いているはずです。 Outlook Web Access (outlook.com) を起動し、ご利用の Azure サブスクリプションの資格情報を使用してサインインします。
受信したメールの [招待を表示 >] を選択します。 この時点で、データ プロバイダーから送信されたデータ共有への招待を受け入れるデータ コンシューマーの操作をシミュレートすることになります。

サブスクリプションの選択を求められることがあります。 このラボで使用しているサブスクリプションを選択してください。
DataProvider というタイトルの招待を選択します。
この [招待] 画面を見ると、先ほどデータ プロバイダーとして構成したデータ共有について、さまざまな詳細情報が表示されていることがわかります。 詳細を確認し、提示された利用規約に同意します。
あらかじめラボ用に存在するサブスクリプションとリソース グループを選択します。
[Data share account](データ共有アカウント) で [DataConsumer] を選択します。 新しいデータ共有アカウントを作成することもできます。
[受信した共有名] の横を見ると、既定の共有名が、データ プロバイダーによって指定された名前になっていることがわかります。 受信しようとしているデータを表すわかりやすい共有名を付けてください (例: TaxiDataShare)。
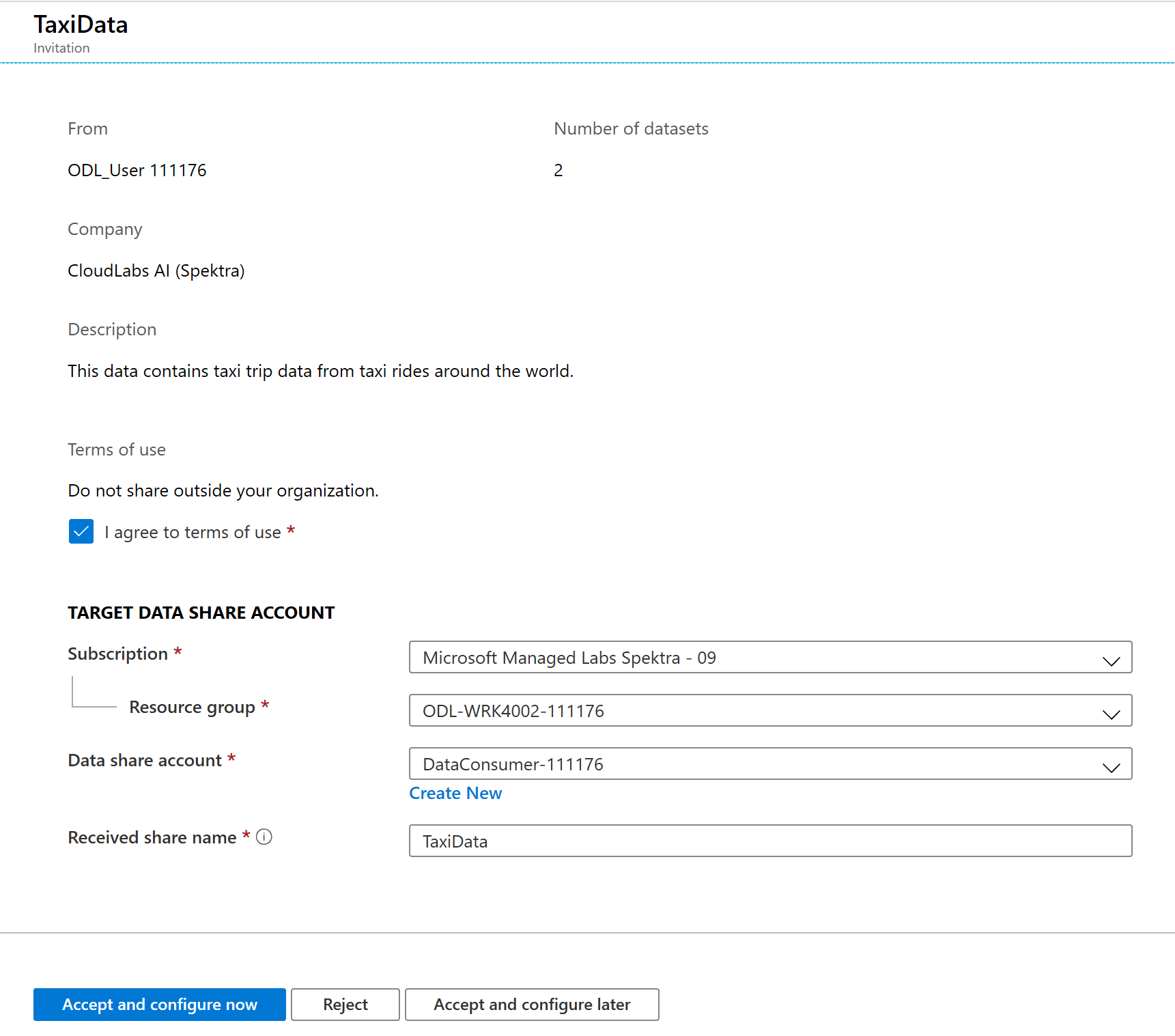
[Accept and configure now](受け入れて今すぐ構成する) または [Accept and configure later](受け入れて後で構成する) を選択できます。 受け入れて今すぐ構成することを選択する場合は、すべてのデータのコピー先となるストレージ アカウントを指定します。 [Accept and configure later](受け入れて後で構成する) を選択した場合は、共有内のデータセットはマッピングされません。後で手動でマッピングする必要があります。 ここでは、後者を選択することにします。
[Accept and configure later](受け入れて後で構成する) を選択します。
このオプションを構成する際に、共有サブスクリプションは作成されますが、コピー先がマッピングされないため、データの配置場所は未指定となります。
次に、データ共有におけるデータセットのマッピングを構成します。
受信した共有 (手順 5. で指定した名前) を選択します。
[スナップショットのトリガー] は灰色表示されますが、共有はアクティブです。
[データセット] タブを選択します。いずれのデータセットもマッピング解除済みです。これは、データのコピー先が存在しないことを意味します。
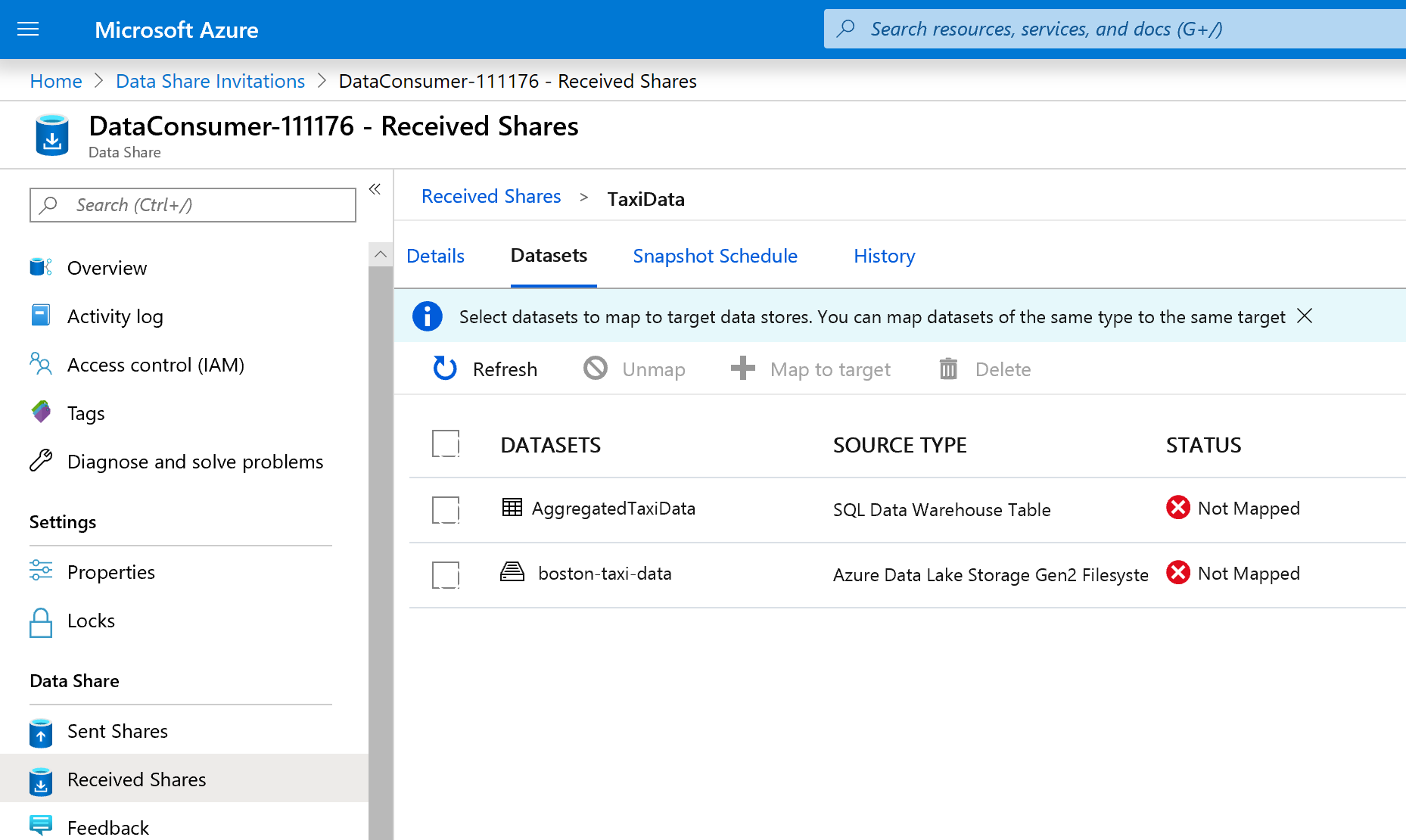
Azure Synapse Analytics テーブルを選択し、 [+ ターゲットへのマップ] を選択します。
画面の右側にある [ターゲット データの種類] ドロップダウン リストを選択します。
SQL データはさまざまなデータ ストアにマッピングすることができます。 ここでは、Azure SQL Database にマッピングします。
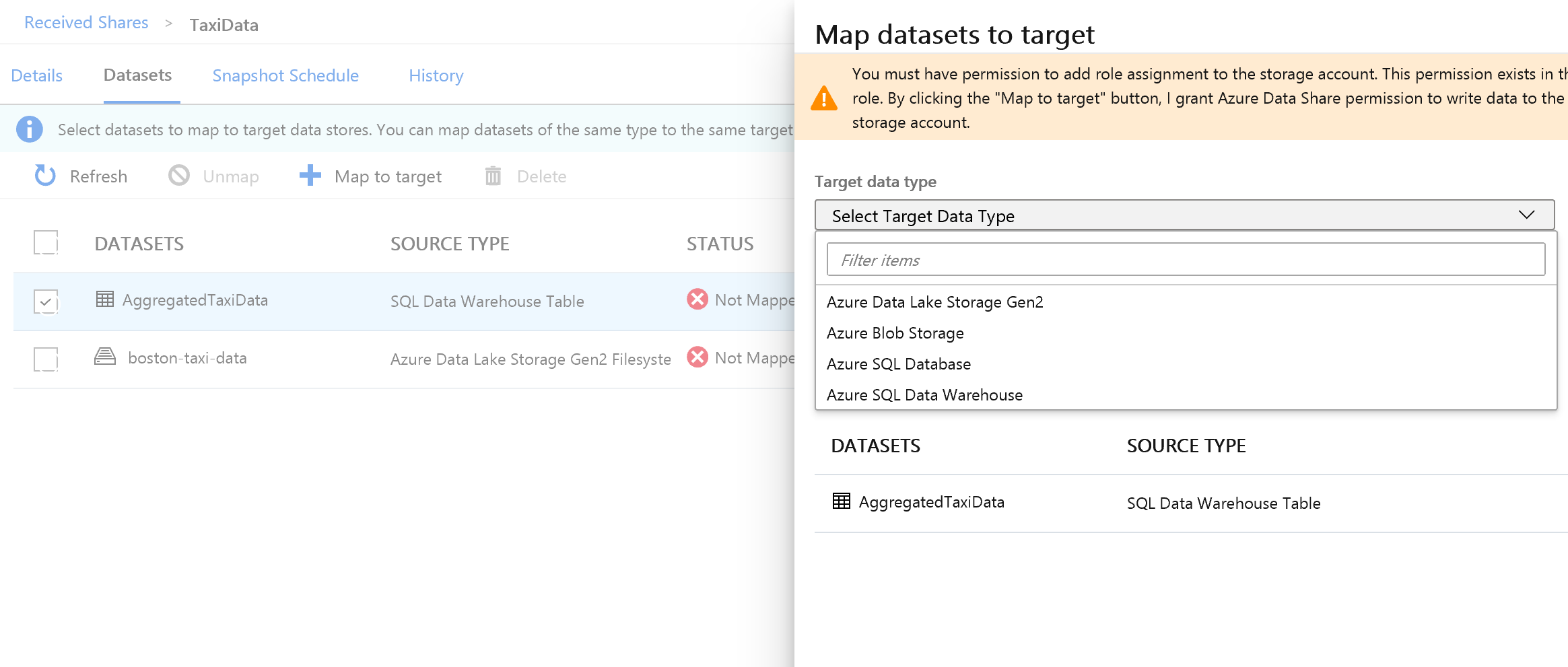
(省略可) ターゲット データの種類として [Azure Data Lake Storage Gen2] を選択します。
(省略可) ご利用のサブスクリプション、リソース グループ、ストレージ アカウントを選択します。
(省略可) データ レイクへのデータを CSV 形式または Parquet 形式で受信することを選択できます。
[ターゲット データの種類] の横にある [Azure SQL Database] を選択します。
ご利用のサブスクリプション、リソース グループ、ストレージ アカウントを選択します。
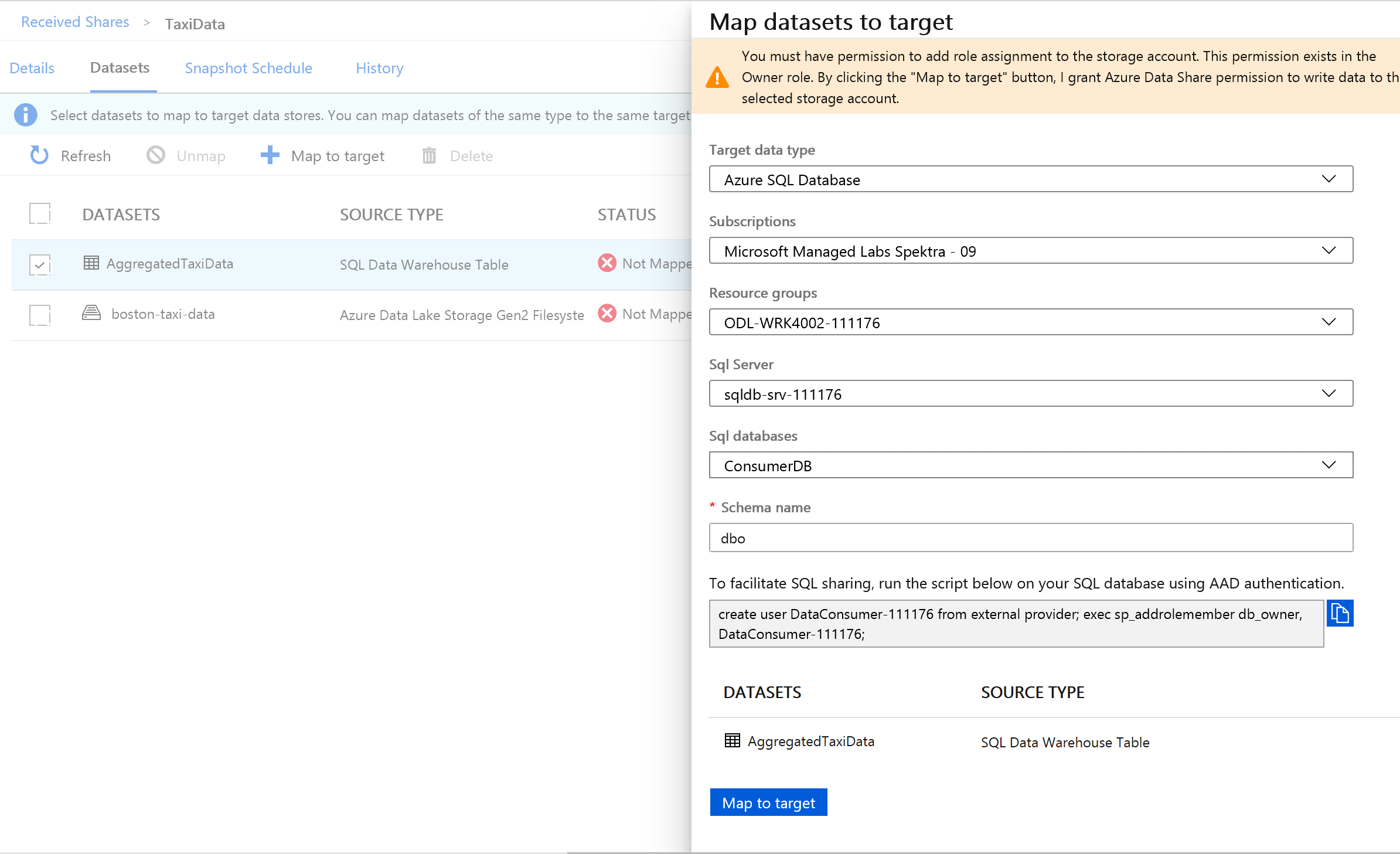
次に進む前に、提供されたスクリプトを実行して、SQL Server に新しいユーザーを作成する必要があります。 まず、提供されたスクリプトをクリップボードにコピーします。
新しい Azure portal タブを開きます。既存のタブは閉じないでください。すぐに元のタブに切り替える必要があります。
新しく開いたタブで、 [SQL データベース] に移動します。
SQL データベース (ご利用のサブスクリプションに 1 つだけ存在する必要があります) を選択します。 データ ウェアハウスを選択しないようご注意ください。
[クエリ エディター (プレビュー)] を選択します。
Microsoft Entra 認証を使用してクエリ エディターにサインインします。
データ共有で、提供された (手順 14. でクリップボードにコピーした) クエリを実行します。
Azure Data Share サービスは、このコマンドにより、Azure サービスのマネージド ID を使用して SQL Server に対する認証を行い、SQL Server にデータをコピーすることができます。
元のタブに戻って、 [ターゲットへのマップ] を選択します。
次に、データセットに含まれる Azure Data Lake Storage Gen2 フォルダーを選択し、Azure Blob Storage アカウントにマッピングします。
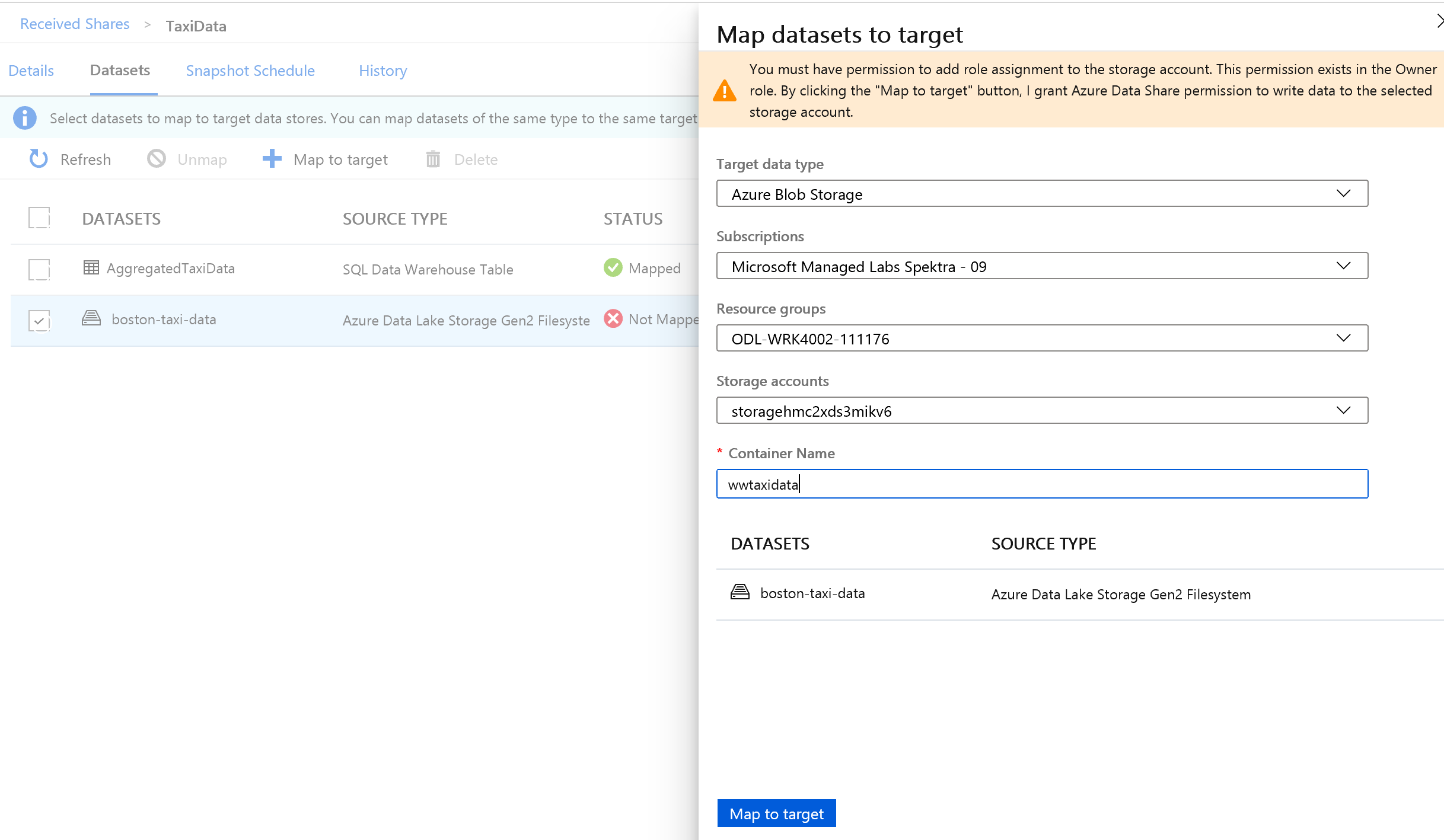
すべてのデータセットのマッピングが済んだら、データ プロバイダーからデータを受信する準備は完了です。
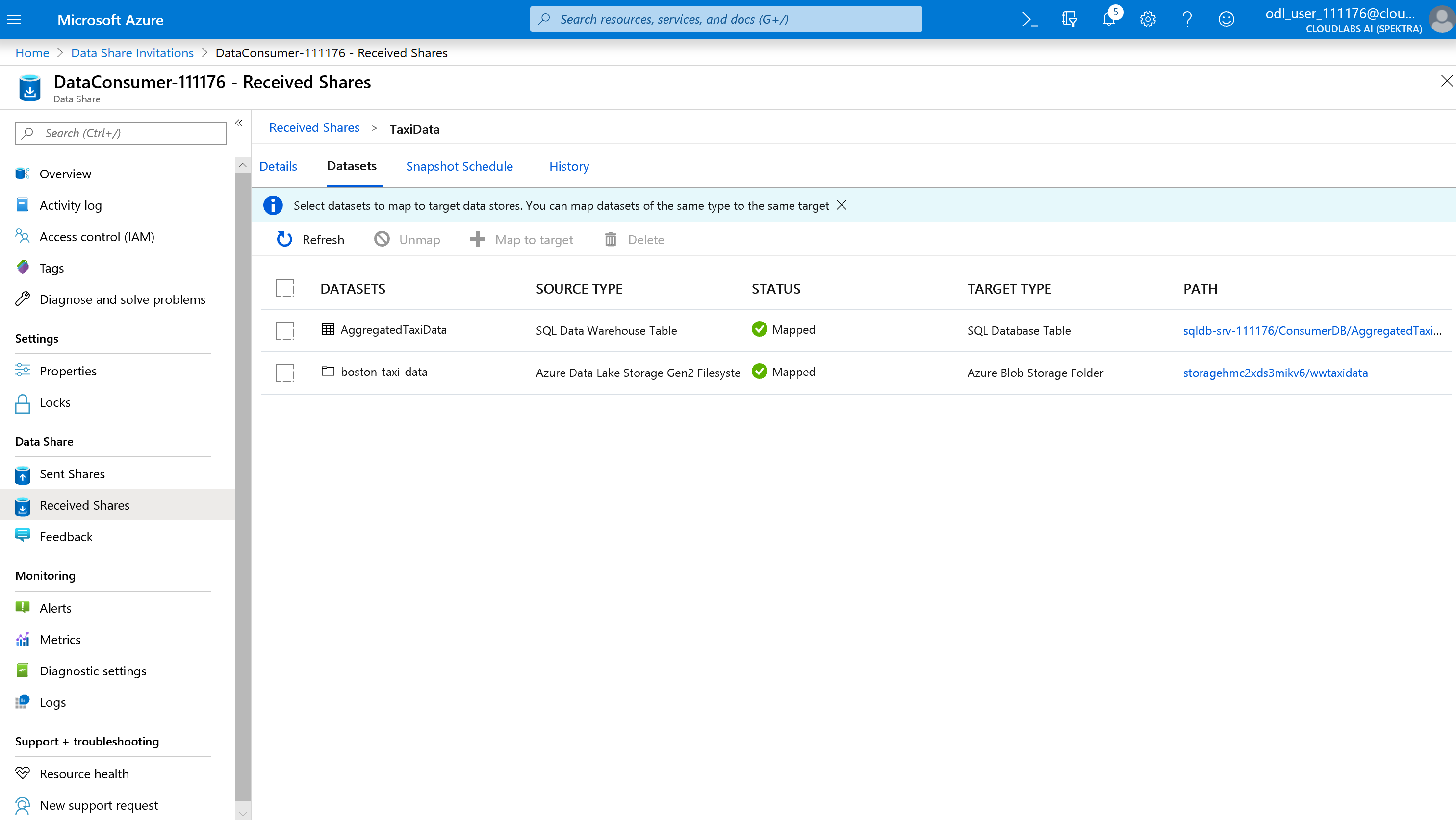
[詳細] を選択します。
今はデータ共有にコピー先が存在するため、[スナップショットのトリガー] は灰色表示されていません。
[スナップショットのトリガー] ->[完全なコピー] を選択します。
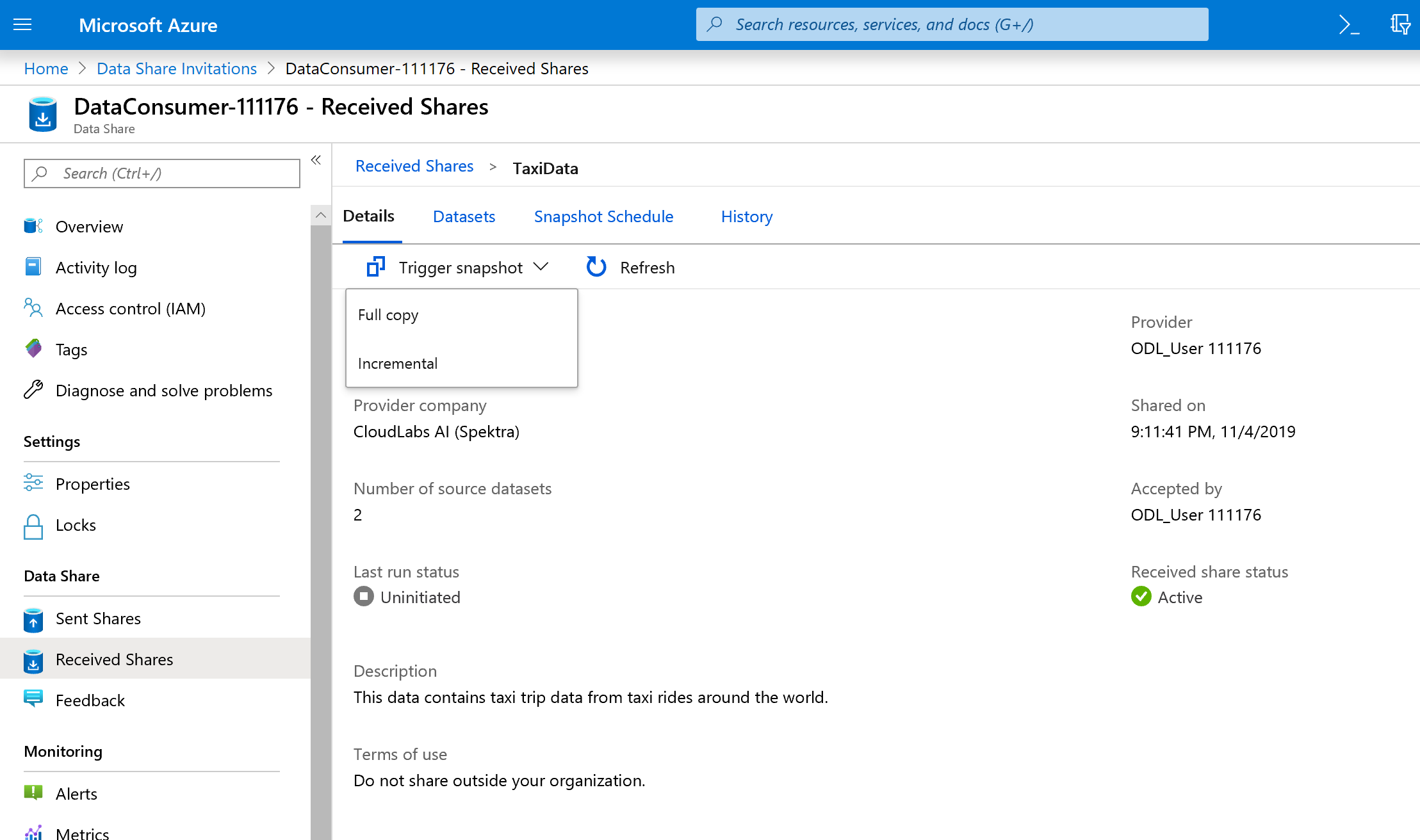
新しいデータ共有アカウントへのデータのコピーが開始されます。 現実のシナリオなら、このデータはサード パーティから受信することになるでしょう。
データが到着するまでには 3 分から 5 分程度かかります。 [履歴] タブを選択すると、進行状況を監視できます。
待っている間、元のデータ共有 (DataProvider) に移動し、[共有サブスクリプション] と [履歴] タブの状態を見てください。今度はアクティブなサブスクリプションが存在しています。また、共有されたデータをデータ コンシューマーがいつ受信し始めたかを、データ プロバイダーとして監視することもできます。
データ コンシューマーのデータ共有に戻ります。 トリガーの状態が "成功" になったら、コピー先の SQL データベースとデータ レイクに移動し、それぞれのストアにデータが格納されていることを確認します。







お疲れさまでした。これでラボは終了です。