Azure portal の変更の追跡を使用して、 Azure SQL Database から Azure BLOB Storage にデータを増分コピーする
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新たに試用を開始する方法については、こちらをご覧ください。
データ統合ソリューションでは、初回データ読み込みの後、増分データを読み込む手法が広く利用されています。 ソースデータ ストアの期間内の変更データを簡単にスライスすることができます(例:LastModifyTime、CreationTime)。 ただし、前回データを処理した時点からの差分データを明示的に特定する方法がない場合もあります。 こうした差分データは、Azure SQL Database や SQL Server などのデータ ストアでサポートされる変更追跡テクノロジを使用して特定することができます。
このチュートリアルでは、Azure Data Factory と変更の追跡を使用して、Azure SQL Database から Azure Blob Storage に差分データを増分読み込みする方法について説明します。 変更の追跡の詳細については、「SQL Server における変更の追跡」を参照してください。
このチュートリアルでは、以下の手順を実行します。
- ソース データ ストアを準備します。
- データ ファクトリを作成します。
- リンクされたサービスを作成します。
- ソース、シンク、変更追跡の各データセットを作成します。
- フル コピー パイプラインを作成、実行、監視します。
- ソース テーブルのデータを追加または更新します。
- 増分コピー パイプラインを作成、実行、監視します。
ソリューションの概略
このチュートリアルでは、次の操作を実行する 2 つのパイプラインを作成します。
注意
このチュートリアルでは、Azure SQL Database をソース データ ストアとして使用します。 SQL Server を使用することもできます。
履歴データの初回読み込み: ソース データ ストア (Azure SQL Database) からターゲット データ ストア (Azure Blob Storage) にデータ全体をコピーするコピー アクティビティを含んだパイプラインを作成します。
- Azure SQL Database のソース データベースの 変更の追跡テクノロジを有効にします。
- データベースからの初期値
SYS_CHANGE_VERSIONをベースラインとして取得し、変更済みデータをキャプチャします。 - ソース データベースから Azure Blob Storage にフル データを読み込みます。

スケジュールに基づく差分データの増分読み込み: 次のアクティビティを含むパイプラインを作成し、定期的に実行します。
2 つの検索アクティビティを作成し、Azure SQL Database から新旧の
SYS_CHANGE_VERSION値を取得します。Azure SQL Database から Azure Blob Storage に2 つの
SYS_CHANGE_VERSION値の間の挿入/更新/削除されたデータ (差分データ) をコピーする1 つのコピー アクティビティを作成します。差分データを読み込みます。これは、
sys.change_tracking_tablesから得られる変更済みの行 (2 つのSYS_CHANGE_VERSION値の間にある行) の主キーと、ソーステーブルのデータとを結合した後、その差分データをターゲットに移動することによって行います。次回のパイプライン実行に備えて
SYS_CHANGE_VERSIONの値を更新するストアド プロシージャ アクティビティを 1 つ作成します。

前提条件
- Azure サブスクリプション。 お持ちでない場合は、開始する前に無料アカウントを作成してください。
- Azure SQL データベース。 ソース データ ストアとして Azure SQL Database のデータベースを使用します。 データベースがない場合の作成ステップについては、Azure SQL Database のデータベースの作成に関するページを参照してください。
- Azure ストレージ アカウント。 シンク データ ストアとして使用する Blob Storage です。 ストレージ アカウントがない場合の作成手順については、「Azure Storage アカウントの作成」を参照してください。 adftutorial という名前のコンテナーを作成します。
注意
Azure を操作するには、Azure Az PowerShell モジュールを使用することをお勧めします。 作業を開始するには、Azure PowerShell のインストールに関する記事を参照してください。 Az PowerShell モジュールに移行する方法については、「AzureRM から Az への Azure PowerShell の移行」を参照してください。
Azure SQL Database にデータ ソース テーブルを作成する
SQL Server Management Studio を開き、Microsoft Azure SQL Database に接続します。
サーバー エクスプローラーで目的のデータベースを右クリックし、[新しいクエリ] を選択します。
データベースに対して次の SQL コマンドを実行し、
data_source_tableという名前のテーブルをソース データ ストアとして作成します。create table data_source_table ( PersonID int NOT NULL, Name varchar(255), Age int PRIMARY KEY (PersonID) ); INSERT INTO data_source_table (PersonID, Name, Age) VALUES (1, 'aaaa', 21), (2, 'bbbb', 24), (3, 'cccc', 20), (4, 'dddd', 26), (5, 'eeee', 22);次の SQL クエリを実行して、データベースとソース テーブル (
data_source_table) の変更の追跡を有効にします。注意
<your database name>を、data_source_tableを持つ Azure SQL Database のデータベース名に置き換えます。- 現行の例では、変更済みのデータが 2 日間維持されます。 変更済みデータを読み込む間隔を 3 日おき、またはそれ以上にした場合、変更済みデータの一部が読み込まれません。
CHANGE_RETENTIONの値を大きな数値に変更するか、変更されたデータを読み込む期間が 2 日以内であることを確認する必要があります。 詳細については、「データベースの変更の追跡を有効にする」を参照してください。
ALTER DATABASE <your database name> SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON) ALTER TABLE data_source_table ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)次のクエリを実行して、新しいテーブルと、規定値をもつ
ChangeTracking_versionというストアを作成します。create table table_store_ChangeTracking_version ( TableName varchar(255), SYS_CHANGE_VERSION BIGINT, ); DECLARE @ChangeTracking_version BIGINT SET @ChangeTracking_version = CHANGE_TRACKING_CURRENT_VERSION(); INSERT INTO table_store_ChangeTracking_version VALUES ('data_source_table', @ChangeTracking_version)注意
SQL Database の変更追跡を有効にした後、データが変更されていなければ、変更追跡バージョンの値は
0になります。次のクエリを実行して、データベースにストアド プロシージャを作成します。 このストアド プロシージャをパイプラインで呼び出すことによって、前のステップで作成したテーブルの変更追跡バージョンを更新します。
CREATE PROCEDURE Update_ChangeTracking_Version @CurrentTrackingVersion BIGINT, @TableName varchar(50) AS BEGIN UPDATE table_store_ChangeTracking_version SET [SYS_CHANGE_VERSION] = @CurrentTrackingVersion WHERE [TableName] = @TableName END
Data Factory の作成
Web ブラウザー (Microsoft Edge または Google Chrome) を開きます。 現時点では、Data Factory ユーザー インターフェイス (UI) をサポートしているのは、これらのブラウザーのみです。
Azure portal の左側のメニューで、[リソースの作成] を選択します。
[統合]>[Data Factory] を選択します。
[新しいデータ ファクトリ] ページで、名前に「ADFTutorialDataFactory」と入力します。
データ ファクトリの名前はグローバルに一意にする必要があります。 選択した名前が使用できないというエラーが発生した場合は、名前を変更し (たとえば、 yournameADFTutorialDataFactory)、データ ファクトリを再度作成してみてください。 詳細については、Azure Data Factory の名前付けルールに関する記事を参照してください。
データ ファクトリを作成する Azure サブスクリプションを選択します。
[リソース グループ] で、次の手順のいずれかを行います。
- [Use existing](既存のものを使用) を選択し、ドロップダウン リストから既存のリソース グループを選択します。
- [新規作成] を選択し、リソース グループの名前を入力します。
リソース グループの詳細については、 リソース グループを使用した Azure のリソースの管理に関するページを参照してください。
[バージョン] で、 [V2] を選択します。
[リージョン] で、データ ファクトリの領域を選択します。
ドロップダウン リストには、サポートされている場所のみが表示されます。 データ ファクトリによって使用されるデータ ストア (Azure Storage、Azure SQL Database など) やコンピューティング (Azure HDInsight など) は、他のリージョンに存在していてもかまいません。
[次へ: Git 構成] を選択します。 「構成方法 4: ファクトリの作成時」の手順に従ってリポジトリを設定するか、[後で Git を構成する] チェックボックスを選択します。
[Review + create](レビュー + 作成) を選択します。
[作成] を選択します
ダッシュボードの [Deploying Data Factory](データ ファクトリをデプロイしています) タイルに状態が表示されます。

作成が完了すると、[Data Factory] ページが表示されます。 [Launch studio](スタジオの起動) タイルを選択して、Azure Data Factory UI を別のタブで開きます。
リンクされたサービスを作成します
データ ストアおよびコンピューティング サービスをデータ ファクトリにリンクするには、リンクされたサービスをデータ ファクトリに作成します。 このセクションでは、Azure ストレージ アカウントと Azure SQL Database のデータベースに対するリンク サービスを作成します。
Azure Storage のリンクされたサービスを作成する
ストレージ アカウントをデータ ファクトリにリンクするには:
- Data Factory UI の [管理] タブの [接続] で、[リンク サービス] を選択します。 次に、[+ 新規] または [リンク サービスの作成] ボタンを選択します。
- [New Linked Service](新しいリンク サービス) ウインドウで [Azure Blob Storage] を選択し、[続行] を選択します。
- 次の情報を入力します。
- [名前] に「AzureStorageLinkedService」と入力します。
- [統合ランタイム経由で接続] で、統合ランタイムを選択します。
- [認証の型] で、認証方法を選択します。
- [ストレージ アカウント名] で、使用する Azure ストレージ アカウントを選択します。
- [作成] を選択します
Azure SQL Database のリンクされたサービスを作成する
データベースをデータ ファクトリにリンクさせるために:
Data Factory UI の [管理] タブの [接続] で[リンク サービス] を選択します。 次に、[+ 新規] を選択します。
[New Linked Service](新しいリンク サービス) ウィンドウで [Azure SQL Database] を選択し、[続行] をクリックします。
次の情報を入力します。
- [名前] に「AzureSqlDatabaseLinkedService」と入力します。
- [サーバー名] で、お使いのサーバーを選択します。
- [データベース名] で、使用するデータベースを選択します。
- [認証の型] で、認証方法を選択します。 このチュートリアルでは、デモンストレーションに SQL 認証を使用します。
- [ユーザー名] に、ユーザーの名前を入力します。
- パスワードに、 ユーザーのパスワードを入力します。 または、Azure Key Vault - AKV のリンク サービス、シークレット名、シークレット バージョンに関する情報を指定します。
[テスト接続] を選択して接続をテストします。
[作成] を選択して、リンク サービスを作成します。
データセットを作成する
このセクションでは、 SYS_CHANGE_VERSION の値の格納する場所とともに、データ ソース、データ ターゲットを表すデータセットを作成します。
ソース データを表すデータセットを作成する
Data Factory UI の [作成者] タブで、プラス記号 (+) を選択します。 次に、[データセット] を選択するか、データセット アクションの省略記号を選択します。
[Azure SQL Database] を選び、 [続行] を選びます。
[プロパティの設定] ウィンドウで、以下のステップを実行します。
- [名前]には、「SourceDataset」と入力します。
- [リンク サービス] で [AzureSqlDatabaseLinkedService] を選択します。
- [テーブル名] で dbo.data_source_table を選択します。
- [スキーマのインポート] で、[接続またはストアから] オプションを選択します。
- [OK] を選択します。

シンク データ ストアにコピーされるデータを表すデータセットを作成する
次の手順では、ソース データ ストアからコピーされたデータを表すデータセットを作成します。 前提条件の 1 つとして adftutorial コンテナーを Azure Blob Storage に作成しました。 このコンテナーが存在しない場合は作成するか、既存のコンテナーの名前を設定してください。 このチュートリアルでは、@CONCAT('Incremental-', pipeline().RunId, '.txt') という式をから出力ファイル名が動的に生成されます。
Data Factory UI の [作成者] タブで、+ を選択します。 次に、[データセット] を選択するか、データセット アクションの省略記号を選択します。
[Azure Blob Storage] を選択し、[続行] を選択します。
データ型の形式を DelimitedText として選択し、[続行] を選択します。
[プロパティの設定] ウィンドウで、以下のステップを実行します。
- 名前に、「SinkDataset」と入力します。
- [リンク サービス] で AzureBlobStorageLinkedService を選択します。
- [ファイル パス] に「adftutorial/incchgtracking」と入力します。
- [OK] を選択します。
ツリー ビューにデータセットが表示されたら、[接続] タブに移動し、[ファイル名] テキスト ボックスを選択します。 [動的コンテンツの追加] オプションが表示されたら、それを選択します。
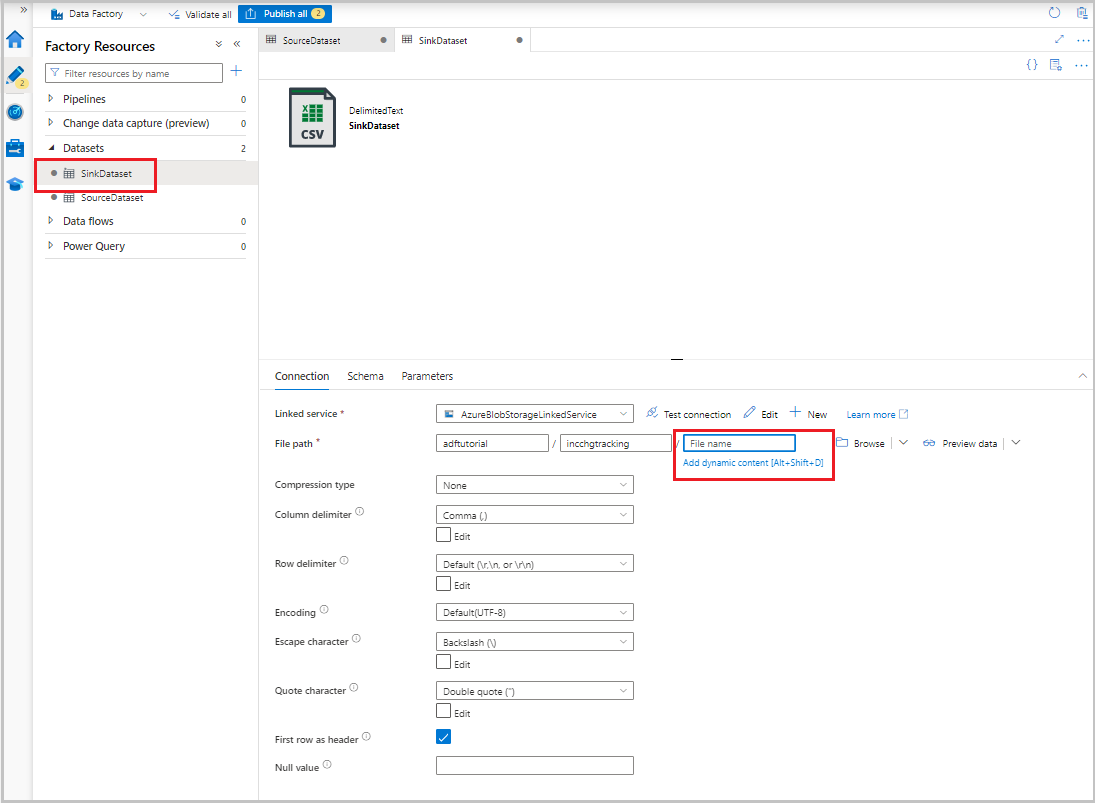
[パイプライン式ビルダー] ウィンドウが表示されます。 テキスト ボックスに
@concat('Incremental-',pipeline().RunId,'.csv')を貼り付けます。[OK] を選択します。
変更追跡データを表すデータセットを作成する
次の手順で、変更追跡バージョンを格納するためのデータセットを作成します。 前提条件の 1 つとして table_store_ChangeTracking_version テーブルを作成しました。
- Data Factory UI の [作成者] タブで、+ を選択 し、 [データセット] を選択 します。
- [Azure SQL Database] を選び、 [続行] を選びます。
- [プロパティの設定] ウィンドウで、次の手順を実行します。
- [名前]に、「ChangeTrackingDataset」と入力します。
- [リンク サービス] で [AzureSqlDatabaseLinkedService] を選択します。
- [テーブル名]で dbo.table_store_ChangeTracking_version を選択します。
- [スキーマのインポート] で、[接続またはストアから] オプションを選択します。
- [OK] を選択します。
完全コピーのパイプラインを作成する
次の手順では、ソース データ ストア (Azure SQL Database) からターゲット データ ストア (Azure Blob Storage) にデータ全体をコピーするコピー アクティビティを含んだパイプラインを作成します。
Data Factory UI の [作成者] タブで、+ を選択 し、 Pipeline>Pipeline を選択 します。
パイプラインを構成するための新しいタブが表示されます。 パイプラインはツリー ビューにも表示されます。 [プロパティ] ウィンドウで、パイプラインの名前を「FullCopyPipeline」に変更します。
[アクティビティ] ツールボックスで、[移動] および [変換] を展開します。 次のいずれかのステップを使用します。
- コピー アクティビティをパイプライン デザイナー画面にドラッグします。
- [アクティビティ] の下の検索バーで、データのコピー アクティビティを検索し、名前を FullCopyActivity に設定します。
[ソース] タブに切り替えます。[ソース データセット] で、[SourceDataset] を選択します。
[シンク] タブに切り替えて、[Sink Dataset](シンク データセット) で [SinkDataset] を選択します。
パイプライン定義を検証するために、ツール バーの [検証] を選択します。 検証エラーがないことを確認します。 パイプライン検証の出力を閉じます。
エンティティ (リンクされたサービス、データセット、およびパイプライン) を発行するには、[すべて発行] を選択します。 [正常に発行されました] というメッセージが表示されるまで待機します。
通知を表示するには、[通知の表示] ボタンを選択します。
フル コピー パイプラインを実行する
Data Factory UI のパイプラインのツール バーで、[トリガーの追加] を選択し、[今すぐトリガー] を選択します。
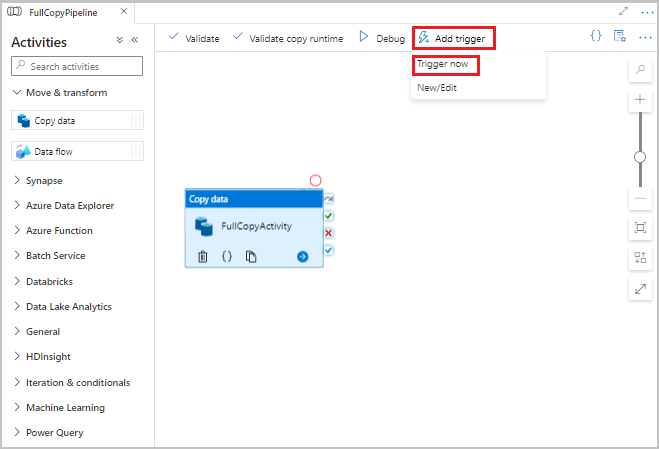
[Pipeline Run](パイプラインの実行) ウィンドウで [OK] を選択します。

フル コピー パイプラインを監視する
Data Factory UI で、[監視] タブを選択します。パイプラインの実行とその状態がリストに表示されます。 リストを更新するには、[最新の情報に更新] を選択します。 パイプラインの実行にカーソルを合わせると、[再実行] または [従量課金] オプションが表示されます。
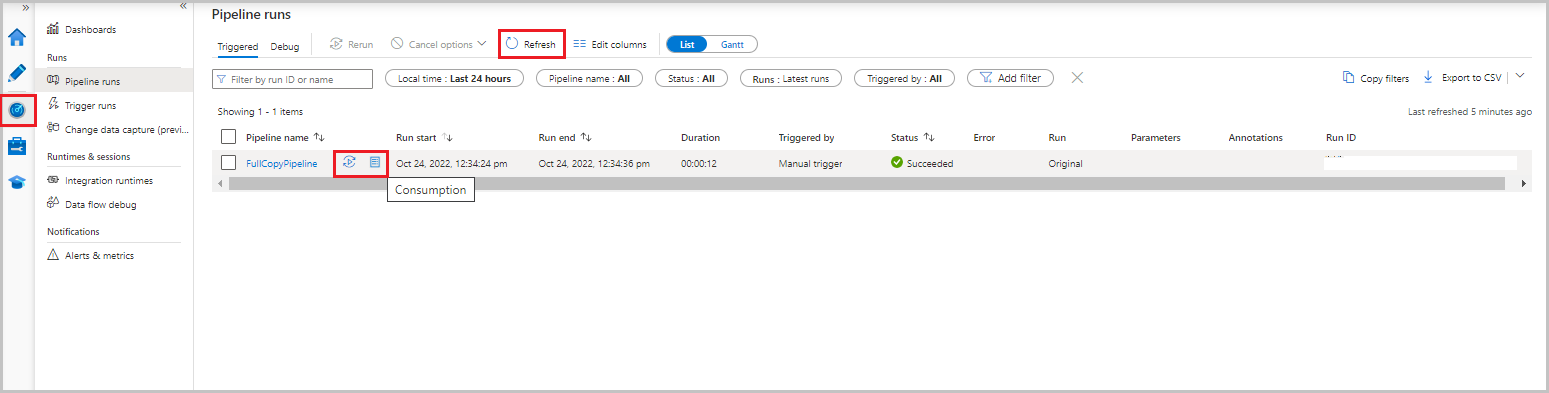
パイプラインの実行に関連付けられたアクティビティの実行を表示するには、[パイプライン名] 列でパイプライン名を選択します。 パイプライン内のアクティビティは 1 つだけであるため、リストにはエントリが 1 つだけあります。 パイプライン実行のビューに戻るには、上部の [すべてのパイプラインの実行] リンクを選択します。
結果の確認
adftutorial コンテナーの incchgtracking フォルダーには、 という名前incremental-<GUID>.csvのファイルが含まれています。
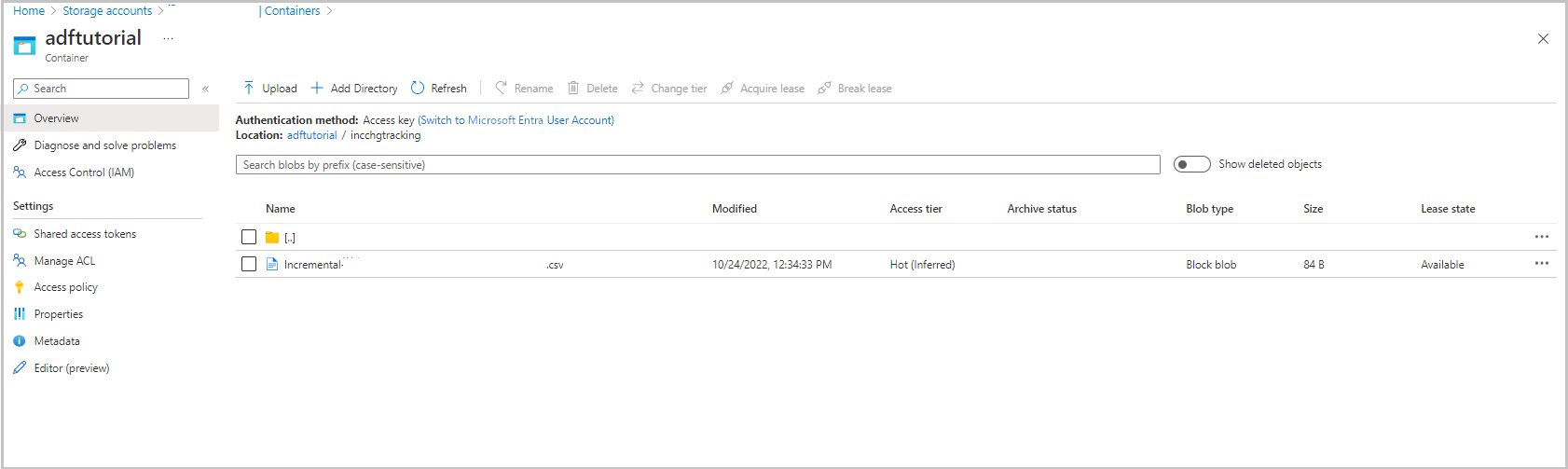
このファイルには、データベースからのデータが存在します。
PersonID,Name,Age
1,"aaaa",21
2,"bbbb",24
3,"cccc",20
4,"dddd",26
5,"eeee",22
5,eeee,PersonID,Name,Age
1,"aaaa",21
2,"bbbb",24
3,"cccc",20
4,"dddd",26
5,"eeee",22
ソース テーブルにデータを追加する
データベースに次のクエリを実行して行の追加と更新を行います。
INSERT INTO data_source_table
(PersonID, Name, Age)
VALUES
(6, 'new','50');
UPDATE data_source_table
SET [Age] = '10', [name]='update' where [PersonID] = 1
差分コピーのパイプラインを作成する
次の手順では、アクティビティを含んだパイプラインを作成し、それを定期的に実行します。 パイプラインの実行時。
- 検索回数アクティビティは、Azure SQL Database から新旧の
SYS_CHANGE_VERSIONの値 を取得し、コピー アクティビティに渡します。 - コピー アクティビティは、2 つの
SYS_CHANGE_VERSIONの値の間に存在する、挿入、更新、または削除されたデータを Azure SQL Database から Azure Blob Storage にコピーします。 - ストアド プロシージャ アクティビティは、次回のパイプライン実行に備えて
SYS_CHANGE_VERSIONの値を更新します。
Data Factory UI で、[作成者] タブに切り替えます。+ を選択し、[パイプライン]>[パイプライン] を選択します。
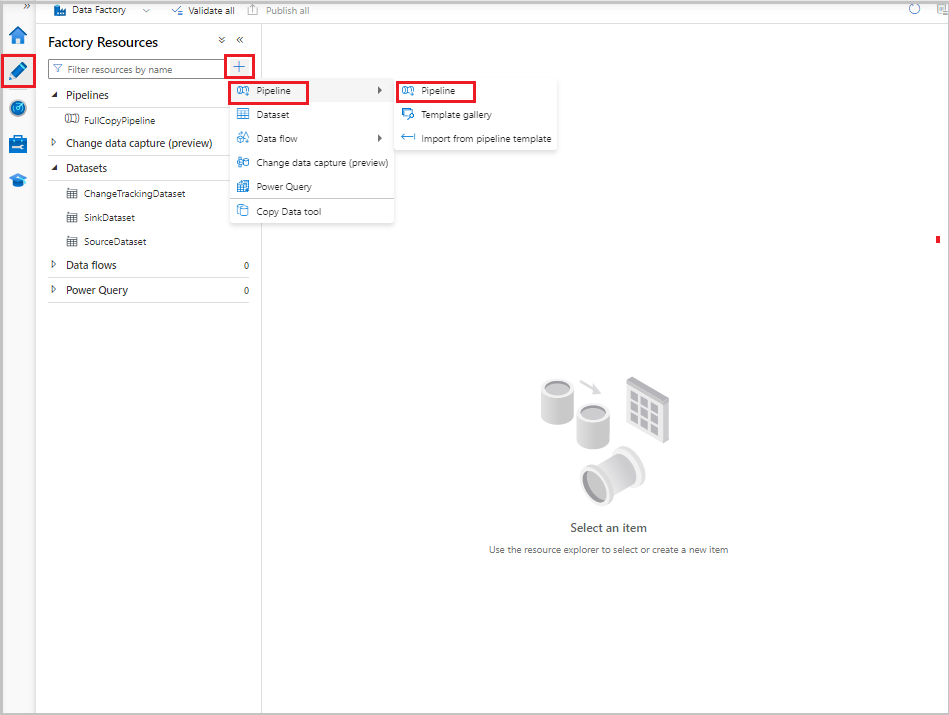
パイプラインを構成するための新しいタブが表示されます。 パイプラインはツリー ビューにも表示されます。 [プロパティ] ウィンドウで、パイプラインの名前を「IncrementalCopyPipeline」に変更します。
[アクティビティ] ツールボックスで [全般] を展開します。 パイプライン デザイナー画面に検索回数アクティビティをドラッグするか、[アクティビティーの検索] ボックスで検索します。 アクティビティの名前を「LookupLastChangeTrackingVersionActivity」に設定します。 このアクティビティは、直前のコピー操作で使用された変更追跡バージョンを取得します。この値は、テーブル
table_store_ChangeTracking_versionに格納されています。プロパティ ウィンドウで [設定] タブに切り替えます。 [ソース データセット] で、[ChangeTrackingDataset] を選択します。
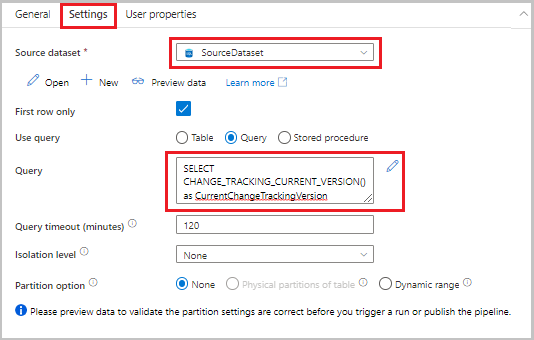
[アクティビティ] ツールボックスからパイプライン デザイナー サーフェスに検索アクティビティをドラッグします。 アクティビティの名前を「LookupCurrentChangeTrackingVersionActivity」に設定します。 このアクティビティは、現在の変更追跡バージョンを取得します。
プロパティ ウィンドウで [設定] タブに切り替え、以下のステップを行います。
[Source dataset](ソース データセット) で [SourceDataset] を選択します。
[クエリの使用] で、[クエリ] を選択します。
[クエリ] に、次の SQL クエリを入力します。
SELECT CHANGE_TRACKING_CURRENT_VERSION() as CurrentChangeTrackingVersion
[アクティビティ] ツールボックスで、[移動] および [変換] を展開します。 コピー データ アクティビティをパイプライン デザイナー画面にドラッグします。 アクティビティの名前を「IncrementalCopyActivity」に設定します。 このアクティビティは、直前の変更追跡バージョンと現在の変更追跡バージョンとの間のデータを、ターゲット データ ストアにコピーします。
プロパティ ウィンドウで [ソース] タブに切り替え、以下のステップを行います。
[Source dataset](ソース データセット) で [SourceDataset] を選択します。
[クエリの使用] で、[クエリ] を選択します。
[クエリ] に、次の SQL クエリを入力します。
SELECT data_source_table.PersonID,data_source_table.Name,data_source_table.Age, CT.SYS_CHANGE_VERSION, SYS_CHANGE_OPERATION from data_source_table RIGHT OUTER JOIN CHANGETABLE(CHANGES data_source_table, @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.SYS_CHANGE_VERSION}) AS CT ON data_source_table.PersonID = CT.PersonID where CT.SYS_CHANGE_VERSION <= @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}
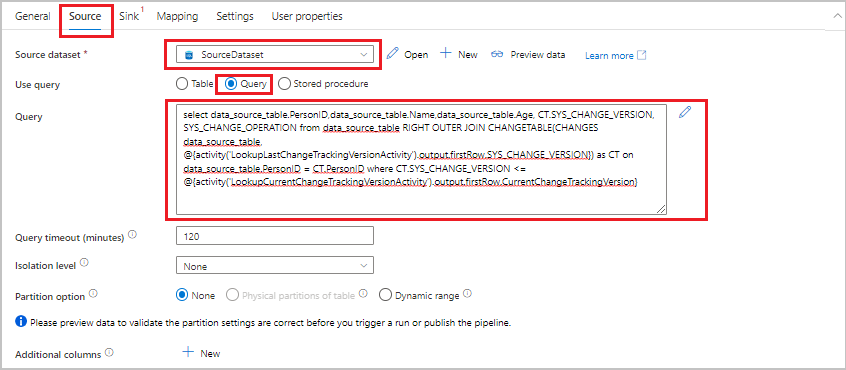
[シンク] タブに切り替えて、[Sink Dataset](シンク データセット) で [SinkDataset] を選択します。
1 つずつ、両方の検索アクティビティをコピー アクティビティに接続します。 検索アクティビティにアタッチされている緑のボタンをコピー アクティビティにドラッグします。
[アクティビティ] ツールボックスからパイプライン デザイナー画面にストアド プロシージャ アクティビティをドラッグします。 アクティビティの名前を「StoredProceduretoUpdateChangeTrackingActivity」に設定します。 このアクティビティは、
table_store_ChangeTracking_versionテーブル内の変更追跡バージョンを更新します。[設定] タブに切り替えて、次のステップを実行します。
- [リンク サービス] で [AzureSqlDatabaseLinkedService] を選択します。
- [ストアド プロシージャ名] に [Update_ChangeTracking_Version] を選択します。
- [インポート] を選択します。
- [ストアド プロシージャのパラメーター] セクションで、各パラメーターに次の値を指定します。
名前 Type 値 CurrentTrackingVersionInt64 @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}TableNameString @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.TableName}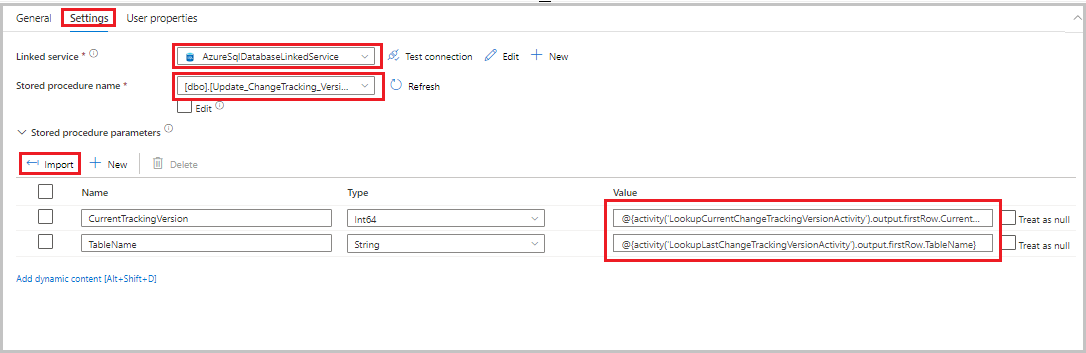
コピー アクティビティをストアド プロシージャ アクティビティに接続します。 コピー アクティビティにアタッチされている緑のボタンをストアド プロシージャ アクティビティにドラッグします。
ツール バーの [検証] を選択します。 検証エラーがないことを確認します。 [Pipeline Validation Report](パイプライン検証レポート) ウィンドウを閉じます。
[すべて公開] ボタンを選択して、エンティティ (リンクされたサービス、データセット、およびパイプライン) を Data Factory サービスに発行します。 [発行は成功しました] というメッセージが表示されるまで待機します。
増分コピー パイプラインを実行する
パイプラインのツール バーの [トリガーの追加] を選択し、[Trigger Now](今すぐトリガー) を選択します。
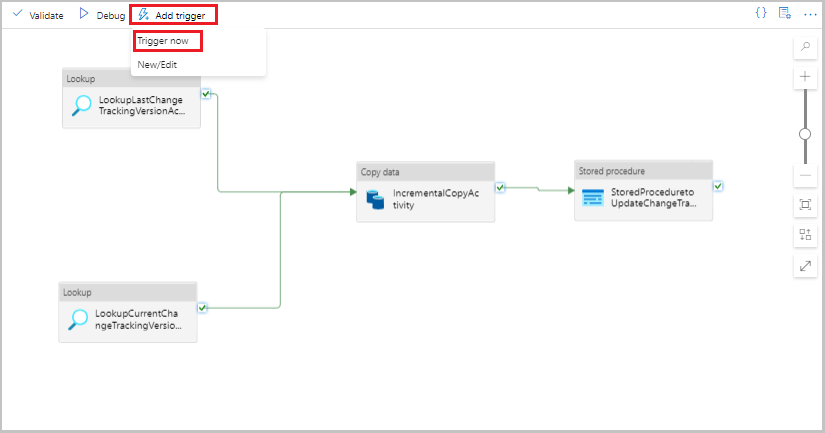
[Pipeline Run](パイプラインの実行) ウィンドウで [OK] を選択します。
増分コピー パイプラインを監視する
[監視] タブを選択します。パイプラインの実行とその状態がリストに表示されます。 リストを更新するには、[最新の情報に更新] を選択します。
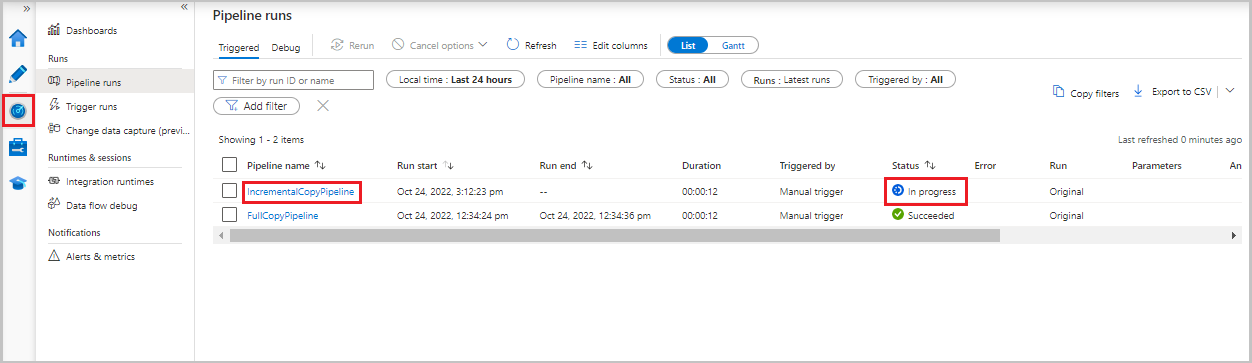
パイプラインの実行に関連付けられたアクティビティの実行を表示するには、[パイプライン名] 列で IncrementalCopyPipeline リンクを選択します。 アクティビティの実行がリストに表示されます。
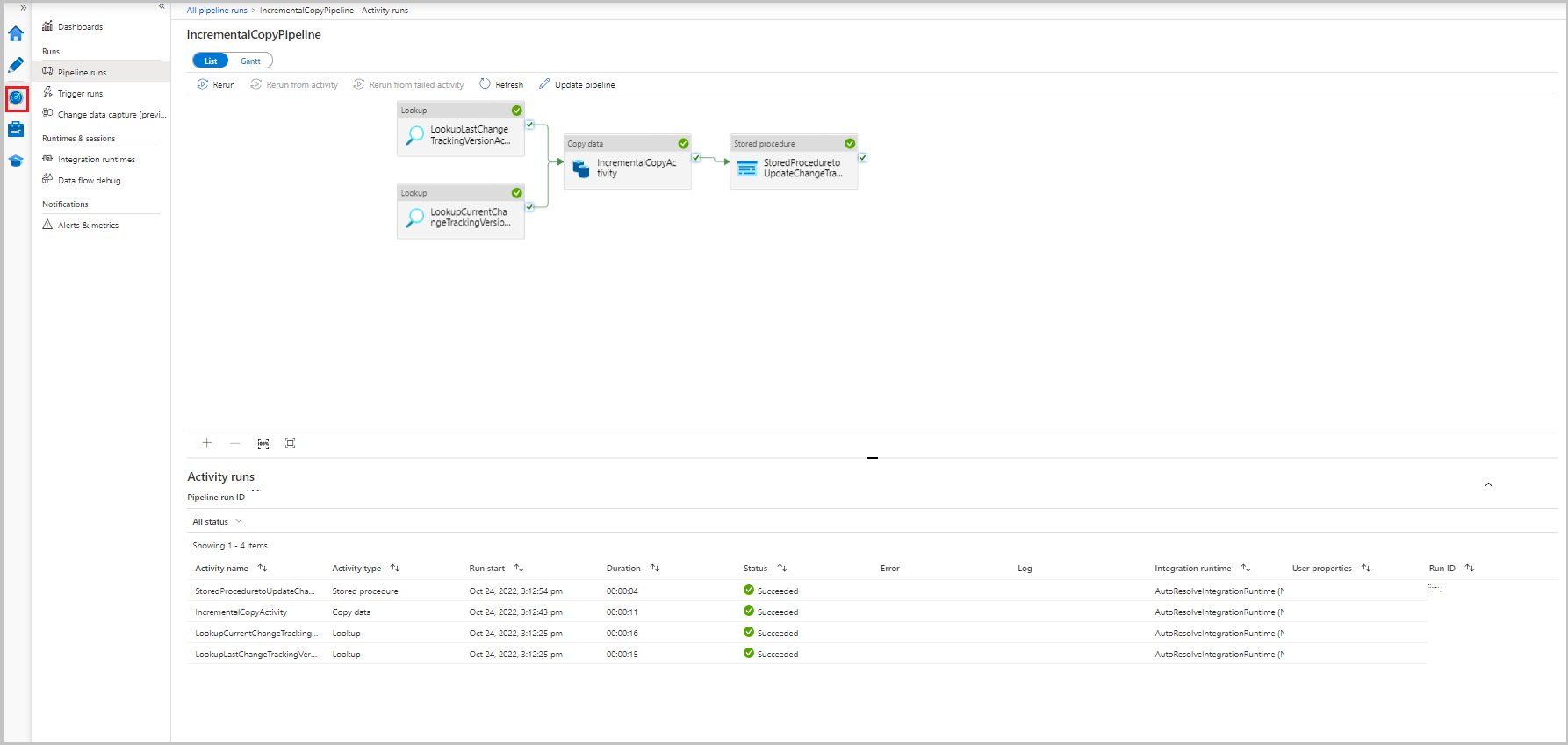
結果の確認
2 番目のファイルは、adftutorial コンテナーの incchgtracking フォルダーに表示されます。
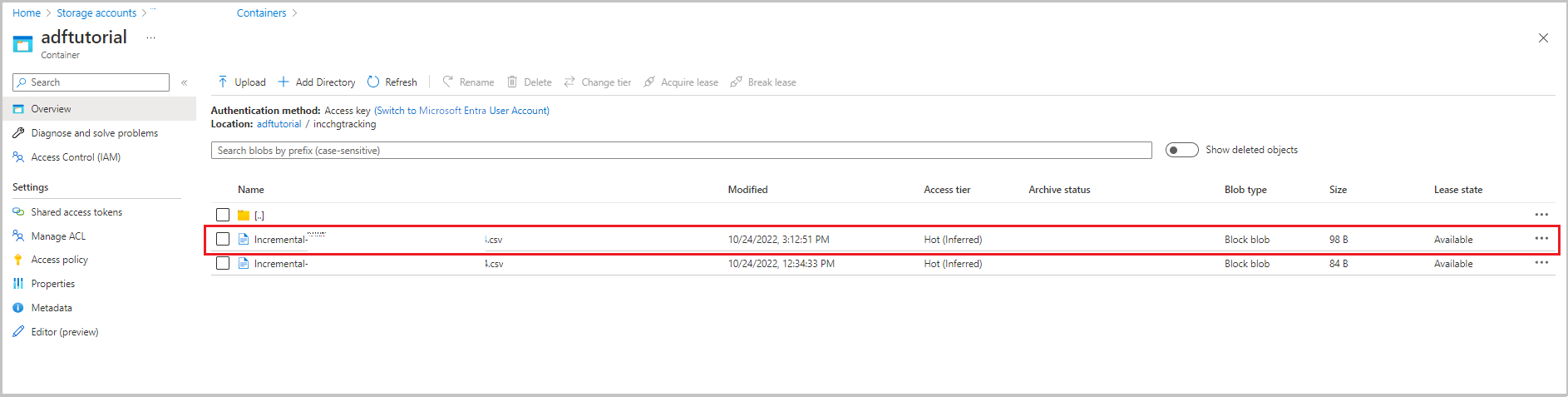
このファイルに含まれているのは、データベースからの差分データのみです。 U と記録されているレコードはデータベース内の更新された行で、I は追加された行です。
PersonID,Name,Age,SYS_CHANGE_VERSION,SYS_CHANGE_OPERATION
1,update,10,2,U
6,new,50,1,I
最初の 3 つの列は、data_source_table から変更済みデータです。 最後の 2 つの列は、変更追跡システム 用のテーブルのメタデータです。 4 つ目の列は、変更済みの各行の SYS_CHANGE_VERSION の値です。 5 つ目の列は実行された操作です。U は更新 (Update) を、I は挿入 (Insert) を表します。 変更追跡情報の詳細については、「CHANGETABLE」を参照してください。
==================================================================
PersonID Name Age SYS_CHANGE_VERSION SYS_CHANGE_OPERATION
==================================================================
1 update 10 2 U
6 new 50 1 I
関連するコンテンツ
次のチュートリアルに進んで、 LastModifiedDate に基づいて新規ファイルおよび変更されたファイルのみをコピーする方法について学習してください。