大規模な抽出、変換、および読み込み (ETL)
抽出、変換、および読み込み (ETL) は、さまざまなソースからデータを取得するプロセスです。 データは標準の場所に収集され、クリーンアップおよび処理されます。 データは最終的にデータストアに読み込まれ、そこからクエリを実行できます。 従来の ETL プロセスは、データをインポートし、所定の場所でクリーニングした後、リレーショナル データ エンジンに格納します。 Azure HDInsight では、さまざまな Apache Hadoop 環境コンポーネントで、大規模な ETL がサポートされます。
ETL プロセスでの HDInsight の使用は、次のパイプラインにまとめられます。
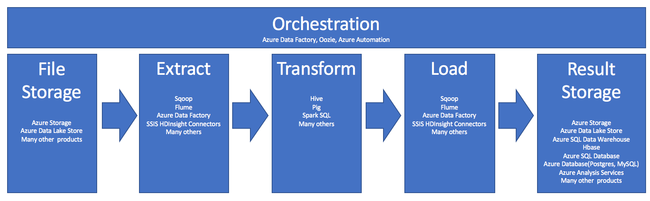
次のセクションで、ETL の各フェーズとその関連コンポーネントについて説明します。
オーケストレーション
オーケストレーションは、ETL パイプラインのすべてのフェーズにまたがります。 HDInsight の ETL ジョブには、多くの場合、相互に連携して動作する複数の異なる製品が含まれます。 次に例を示します。
- Apache Hive を使用してデータの一部をクリーンアップし、また Apache Pig を使用して別の部分をクリーンアップすることがあります。
- Azure Data Factory を使用して、Azure Data Lake Store から Azure SQL Database にデータを読み込むことがあります。
オーケストレーションは、適切なタイミングで適切なジョブを実行するために必要です。
Apache Oozie
Apache Oozie は、Hadoop ジョブを管理するワークフロー調整システムです。 Oozie は HDInsight クラスター内で実行され、Hadoop スタックと統合されます。 Oozie は、Apache Hadoop MapReduce、Pig、Hive、Sqoop の Hadoop ジョブをサポートします。 Oozie を使用して、Java プログラムやシェル スクリプトなど、システム固有のジョブをスケジュールできます。
詳細については、「Apache Hadoop で Apache Oozie を使用して Linux ベースの Azure HDInsight でワークフローを定義して実行する」を参照してください。 データ パイプラインの運用化に関する記事も参照してください。
Azure Data Factory
Azure Data Factory は、オーケストレーション機能をサービスとしてのプラットフォーム (PaaS) の形で提供します。 Azure Data Factory は、クラウドベースのデータ統合サービスです。 これを使用して、データ移動とデータ変換を調整し、自動化するためのデータ駆動型ワークフローを作成できます。
Azure Data Factory を使用すると、以下を行うことができます。
- データ駆動型ワークフローを作成およびスケジュールする。 これらのパイプラインによって、さまざまなデータ ストアからデータが取り込まれます。
- HDInsight や Hadoop などのコンピューティング サービスを使用してデータを処理および変換する。 この手順では、Spark、Azure Data Lake Analytics、Azure Batch、または Azure Machine Learning も使用できます。
- BI アプリケーションから利用できるよう、Azure Synapse Analytics などのデータ ストアに出力データを公開する。
Azure Data Factory の詳細については、こちらのドキュメントを参照してください。
ファイル ストレージと結果ストレージの取り込み
ソース データ ファイルは、通常、Azure Storage または Azure Data Lake Storage 上の場所に読み込まれます。 ファイルは通常、CSV のようなフラット形式です。 ただし、どのような形式でもかまいません。
Azure Storage
Azure Storage には、固有の適応性ターゲットがあります。 詳細については、「BLOB ストレージのスケーラビリティとパフォーマンスのターゲット」を参照してください。 大半の分析ノードでは、Azure Storage は、多数の小さなファイルを処理する場合に最善のスケーリングを行います。 アカウントの制限内である限り、Azure Storage では、ファイルのサイズに関係なく同じパフォーマンスが保証されます。 テラバイト単位のデータを保存しても、一貫したパフォーマンスを得ることができます。 このことは、データのサブセットを使用する場合でもすべてを使用する場合でも当てはまります。
Azure Storage には、複数の種類の BLOB があります。 "追加 BLOB" は、Web ログやセンサー データを格納するための優れたオプションです。
複数の BLOB を数多くのサーバーに分散して、アクセスをスケールアウトすることができます。 ただし、単一の BLOB は単一サーバーでのみ提供されます。 BLOB は BLOB コンテナーに論理的にグループ化できますが、このグループ化によるパーティション分割の影響はありません。
Azure Storage には、BLOB ストレージ用の WebHDFS API レイヤーがあります。 HDInsight のすべてのサービスから、データのクリーニングとデータの処理のために Azure Blob Storage 内のファイルにアクセスできます。 これは、これらのサービスで Hadoop 分散ファイル システム (HDFS) を使用する方法と似ています。
データは、通常は、PowerShell、Azure Storage SDK、または AzCopy を介して Azure Storage に取り込まれます。
Azure Data Lake Storage
Azure Data Lake Storage は、分析データ用のマネージド ハイパースケール リポジトリです。 これは、HDFS と互換性があり、HDFS に似た設計パラダイムを使用します。 Data Lake Storage では、合計容量と個々のファイルのサイズに対して無制限の適応性が提供されます。 これは、大きいファイルの操作に適しています。大きいファイルを複数のノードに格納できるためです。 Data Lake Storage でのデータのパーティション分割は、バックグラウンドで行われます。 数百のテラバイトのデータに対する読み取りと書き込みを効率的に行う数千の同時実行される Executor によって、分析ジョブの実行で非常に高いスループットを得ることができます。
データは通常、Azure Data Factory を通じて Data Lake Storage に取り込まれます。 Data Lake Storage SDK、AdlCopy サービス、Apache DistCp、または Apache Sqoop も使用できます。 選択するサービスは、データの場所によって異なります。 それが既存の Hadoop クラスターにある場合は、Apache DistCp、AdlCopy サービス、または Azure Data Factory を使用できます。 データが Azure Blob Storage にある場合は、Azure Data Lake Storage .NET SDK、Azure PowerShell、または Azure Data Factory を使用できます。
Data Lake Storage は、Azure Event Hubs を使用したイベント取り込み用に最適化されています。
両方のストレージ オプションに関する考慮事項
テラバイトの範囲のデータセットをアップロードする場合、ネットワーク待機時間が大きな問題になる可能性があります。 これは、データがオンプレミスの場所から送信される場合に特に当てはまります。 このような場合は、次のオプションを使用できます。
Azure ExpressRoute: Azure データセンターとオンプレミスのインフラストラクチャの間でプライベート接続を作成します。 これらの接続により、大量のデータを転送するための信頼性の高いオプションが提供されます。 詳細については、 Azure ExpressRoute のドキュメントをご覧ください。
ハード ディスク ドライブからのデータのアップロード:Azure Import/Export サービスを使用して、データが格納されたハード ディスク ドライブを Azure データ センターに発送できます。 データは最初に Azure BLOB Storage にアップロードされます。 その後、Azure Data Factory または AdlCopy ツールを使用して、Azure BLOB Storage から Data Lake Storage にデータをコピーできます。
Azure Synapse Analytics
Azure Synapse Analytics は、準備された結果を格納するための適切な選択肢です。 Azure HDInsight を使用して、それらのサービスを Azure Synapse Analytics に対して実行できます。
Azure Synapse Analytics は、分析ワークロード用に最適化されたリレーショナル データベース ストアです。 これにより、パーティション分割されたテーブルに基づいてスケーリングが行われます。 テーブルは、複数のノードにパーティション分割できます。 ノードは作成時に選択されます。 それらは後でスケーリングできますが、データ移動が必要になるのはアクティブ プロセスです。 詳細については、「Azure Synapse Analytics でのコンピューティングの管理」をご覧ください。
Apache HBase
Apache HBase は、Azure HDInsight で利用可能なキー値ストアです。 これは、オープン ソースの NoSQL データベースであり、Hadoop 上に構築され、Google BigTable をモデルにしています。 HBase では、大量の非構造化データと半構造化データに対する効率の良いランダム アクセスと強力な一貫性が提供されます。
HBase はスキーマレス データベースであるため、使用する前に列とデータ型を定義する必要はありません。 データはテーブルの行内に格納され、列ファミリによってグループ化されます。
オープン ソース コードは、直線的な拡張により何千ものノード上でペタバイト級のデータを扱うことができます。 HBase は、Hadoop 環境の分散アプリケーションによって提供されるデータ冗長性やバッチ処理などの機能に依存します。
HBase は、今後の分析のためにセンサー とログ データを格納するための適切な宛先です。
HBase の適応性は、HDInsight クラスター内のノードの数に依存します。
Azure SQL データベース
Azure には、3 つの PaaS リレーショナル データベースが用意されています。
- Azure SQL Database は、Microsoft SQL Server の実装です。 パフォーマンスの詳細については、「Azure SQL Database のパフォーマンスのチューニング」を参照してください。
- Azure Database for MySQL は、Oracle MySQL の実装です。
- Azure Database for PostgreSQL は、PostgreSQL の実装です。
これらの製品をスケールアップするには、CPU とメモリを追加します。 I/O パフォーマンスを向上させるため、製品と共にプレミアム ディスクを使用することも選択できます。
Azure Analysis Services
Azure Analysis Services は、意思決定支援とビジネス分析に使用される分析データ エンジンです。 これにより、Power BI などのビジネス レポートとクライアント アプリケーション用に分析データが提供されます。 この分析データは、Excel、SQL Server Reporting Services レポート、およびその他のデータ視覚化ツールでも機能します。
分析キューブは、個別のキューブの階層を変更することによってスケーリングします。 詳しくは、「Azure Analysis Services の価格」をご覧ください。
抽出と読み込み
Azure 内にデータが存在すれば、多数のサービスを使用してデータを抽出し、他の製品に読み込むことができます。 HDInsight では、Sqoop と Flume をサポートします。
Apache Sqoop
Apache Sqoop は、構造化データ ソース、半構造化データ ソース、および非構造化データ ソース間でデータを効率的に転送するように設計されたツールです。
Sqoop では、MapReduce を使用してデータのインポートとエクスポートを実行し、並列操作とフォールト トレランスを提供しています。
Apache Flume
Apache Flume は、大量のログ データを効率的に収集、集計、および移動するために使用できる信頼性の高い分散サービスです。 その柔軟なアーキテクチャは、ストリーミング データ フローに基づいています。 Flume は、堅牢でフォールト トレラントであり、チューニング可能な信頼性メカニズムを備えています。 多数のフェールオーバーと復旧のメカニズムがあります。 Flume は、オンライン分析アプリケーションで使用できるシンプルな拡張可能データ モデルを使用しています。
Apache Flume は、Azure HDInsight では使用できません。 ただし、オンプレミスの Hadoop インストールでは、Flume を使用して、Azure Blob Storage または Azure Data Lake Storage にデータを送信できます。 詳細については、HDInsight での Apache Flume の使用に関する記事を参照してください。
変換
選択した場所にデータが存在すれば、データのクリーニング、結合、または特定の使用パターンに合わせた準備を行う必要があります。 Hive、Pig、および Spark SQL は、すべてがその種の作業を行うための適切な選択肢です。 それらはすべて HDInsight でサポートされています。