HDInsight Spark クラスターを使用して Data Lake Storage Gen1 内のデータを分析する
この記事では、HDInsight Spark クラスターで利用できる Jupyter Notebook を使用して、Data Lake Storage アカウントからデータを読み取るジョブを実行します。
前提条件
Azure Data Lake Storage Gen1 アカウント。 「Azure portal で Azure Data Lake Storage Gen1 の使用を開始する」の手順に従ってください。
Data Lake Storage Gen1 をストレージとして使用する Azure HDInsight Spark クラスター。 「クイック スタート: HDInsight のクラスターを設定する」の手順に従います。
データを準備する
Note
Data Lake Storage を既定のストレージとして使用する HDInsight クラスターを作成した場合は、この手順を行う必要はありません。 クラスター作成処理で、クラスター作成中に指定する Data Lake Storage アカウントにいくつかのサンプル データが追加されるためです。 スキップして、「Data Lake Storage で HDInsight Spark クラスターを使用する」のセクションに進みます。
Data Lake Storage を追加ストレージとして使用し、Azure Storage Blob を既定のストレージとして使用する HDInsight クラスターを作成した場合は、まず、いくつかのサンプル データを Data Lake Storage アカウントにコピーする必要があります。 HDInsight クラスターに関連付けられている Azure Storage Blob のサンプル データを使用することができます。
コマンド プロンプトを開き、AdlCopy がインストールされているディレクトリ (通常は
%HOMEPATH%\Documents\adlcopy) に移動します。次のコマンドを実行して、ソース コンテナーの特定の BLOB を Data Lake Storage にコピーします。
AdlCopy /source https://<source_account>.blob.core.windows.net/<source_container>/<blob name> /dest swebhdfs://<dest_adls_account>.azuredatalakestore.net/<dest_folder>/ /sourcekey <storage_account_key_for_storage_container>/HdiSamples/HdiSamples/SensorSampleData/hvac/ にある HVAC.csv サンプル データ ファイルを Azure Data Lake Storage アカウントにコピーします。 コード スニペットを次に示します。
AdlCopy /Source https://mydatastore.blob.core.windows.net/mysparkcluster/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv /dest swebhdfs://mydatalakestore.azuredatalakestore.net/hvac/ /sourcekey uJUfvD6cEvhfLoBae2yyQf8t9/BpbWZ4XoYj4kAS5Jf40pZaMNf0q6a8yqTxktwVgRED4vPHeh/50iS9atS5LQ==警告
ファイル名とパス名で大文字と小文字が適切に使用されていることを確認します。
Data Lake Storage アカウントがある Azure サブスクリプションの資格情報を入力するように求められます。 次のスニペットのような出力が表示されます。
Initializing Copy. Copy Started. 100% data copied. Copy Completed. 1 file copied.データ ファイル (HVAC.csv) が、Data Lake Storage アカウントの /hvac フォルダーにコピーされます。
Data Lake Storage Gen1 で HDInsight Spark クラスターを使用する
Azure portal のスタート画面で Apache Spark クラスターのタイルをクリックします (スタート画面にピン留めしている場合)。 [すべて参照]>[HDInsight クラスター] でクラスターに移動することもできます。
Spark クラスター ブレードで、 [クイック リンク] をクリックし、 [クラスター ダッシュボード] ブレードで [Jupyter Notebook] をクリックします。 入力を求められたら、クラスターの管理者資格情報を入力します。
Note
ブラウザーで次の URL を開き、クラスターの Jupyter Notebook にアクセスすることもできます。 CLUSTERNAME をクラスターの名前に置き換えます。
https://CLUSTERNAME.azurehdinsight.net/jupyter新しい Notebook を作成します。 [新規] をクリックし、 [PySpark] をクリックします。
PySpark カーネルを使用して Notebook を作成したため、コンテキストを明示的に作成する必要はありません。 最初のコード セルを実行すると、Spark および Hive コンテキストが自動的に作成されます。 このシナリオに必要な種類をインポートすることから始めることができます。 このためには、次のコード スニペットをセルに貼り付けて、 Shift + Enterキーを押します。
from pyspark.sql.types import *Jupyter でジョブを実行するたびに、Web ブラウザー ウィンドウのタイトルに [(ビジー)] ステータスと Notebook のタイトルが表示されます。 また、右上隅にある PySpark というテキストの横に塗りつぶされた円も表示されます。 ジョブが完了すると、白抜きの円に変化します。

Data Lake Storage Gen1 アカウントにコピーした HVAC.csv ファイルを使用して、サンプル データを一時テーブルに読み込みます。 Data Lake Storage アカウントのデータにアクセスするには、次の URL パターンを使用します。
Data Lake Storage Gen1 を既定のストレージとしている場合、HVAC.csv は次の URL と同じようなパスになります。
adl://<data_lake_store_name>.azuredatalakestore.net/<cluster_root>/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csvまたは、次のように簡略化された形式を使用することもできます。
adl:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csvData Lake Storage を追加ストレージとしている場合、HVAC.csv は、次のようなコピーした場所にあります。
adl://<data_lake_store_name>.azuredatalakestore.net/<path_to_file>空のセルに次のコード例を貼り付けて、MYDATALAKESTORE を Data Lake Storage アカウント名に置き換え、Shift + Enter キーを押します。 このコード サンプルは、 hvacという一時テーブルにデータを登録します。
# Load the data. The path below assumes Data Lake Storage is default storage for the Spark cluster hvacText = sc.textFile("adl://MYDATALAKESTORazuredatalakestore. net/cluster/mysparkclusteHdiSamples/HdiSamples/ SensorSampleData/hvac/HVAC.csv") # Create the schema hvacSchema = StructType([StructField("date", StringTy(), False) ,StructField("time", StringType(), FalseStructField ("targettemp", IntegerType(), FalseStructField("actualtemp", IntegerType(), FalseStructField("buildingID", StringType(), False)]) # Parse the data in hvacText hvac = hvacText.map(lambda s: s.split(",")).filt(lambda s: s [0] != "Date").map(lambda s:(str(s[0]), s(s[1]), int(s[2]), int (s[3]), str(s[6]) )) # Create a data frame hvacdf = sqlContext.createDataFrame(hvac,hvacSchema) # Register the data fram as a table to run queries against hvacdf.registerTempTable("hvac")
PySpark カーネルを使用しているため、
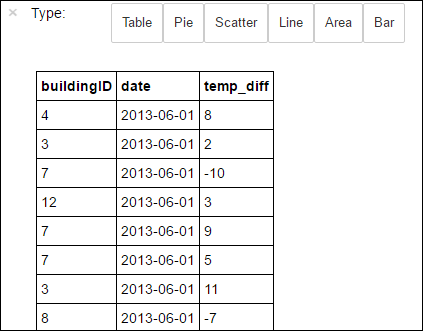
%%sqlマジックを使用して、作成した一時テーブル hvac に対して SQL クエリを直接実行できます。%%sqlマジックの詳細と、PySpark カーネルで使用できるその他のマジックの詳細については、Apache Spark HDInsight クラスターと Jupyter Notebook で使用可能なカーネルに関する記事を参照してください。%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"ジョブが正常に完了すると、既定で次の出力が表示されます。
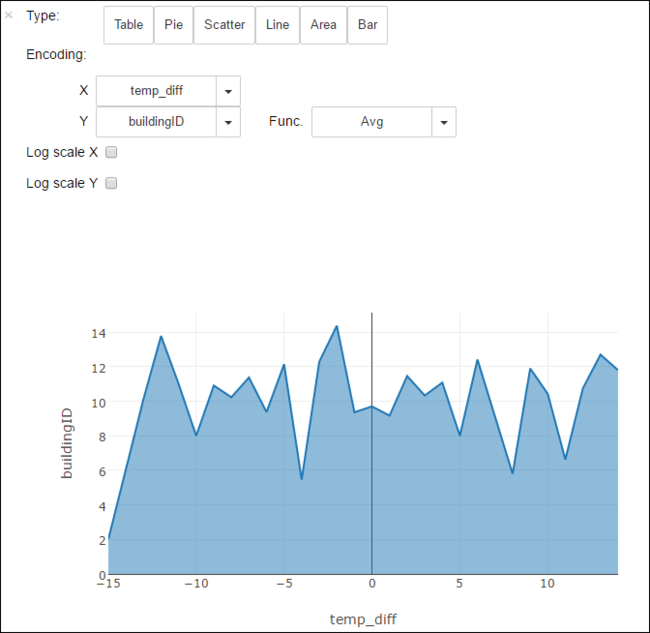
他の視覚化でも結果を表示できます。 たとえば、ある出力の領域グラフは次のようになります。
アプリケーションの実行が完了したら、Notebook をシャットダウンしてリソースを解放する必要があります。 そのためには、Notebook の [ファイル] メニューの [Close and Halt] (閉じて停止) をクリックします。 これにより、Notebook がシャットダウンされ、閉じられます。
次のステップ
- スタンドアロン Scala アプリケーションを作成して、Apache Spark クラスターで実行する
- Azure Toolkit for IntelliJ の HDInsight ツールを使用して HDInsight Spark Linux クラスター向けの Apache Spark アプリケーションを作成する
- Azure Toolkit for Eclipse の HDInsight ツールを使用して HDInsight Spark Linux クラスター向けの Apache Spark アプリケーションを作成する
- Azure HDInsight クラスターで Azure Data Lake Storage Gen2 を使用する