フィルターに基づく特徴選択
この記事では、Azure Machine Learning デザイナーのフィルターに基づく特徴選択コンポーネントを使用する方法について説明します。 このコンポーネントは、入力データセット内で予測能力が最も高い列を特定するのに役立ちます。
一般に、"特徴選択" とは、指定された出力を前提として、統計的検定を入力に適用するプロセスを指します。 この目標は、出力の予測能力が高い列を特定することです。 フィルターに基づく特徴選択コンポーネントには、選択肢となる複数の特徴選択アルゴリズムが用意されています。 このコンポーネントには、ピアソンの相関やカイ二乗値などの相関法が含まれています。
フィルターに基づく特徴選択コンポーネントを使用する場合は、データセットを指定し、ラベルまたは従属変数を含む列を特定します。 その後、特徴の重要度の測定に使用する 1 つの方法を指定します。
このコンポーネントは、予測能力によってランク付けされた最適な特徴列を含むデータセットを出力します。 また、選択されたメトリックから特徴の名前とそのスコアも出力します。
フィルターに基づく特徴選択とは
この特徴選択のためのコンポーネントが "フィルターに基づく" と呼ばれるのは、選択したメトリックを使用して関連性のない属性を見つけるからです。 その後、冗長な列をモデルから除外します。 データに適した 1 つの統計的尺度を選択すると、コンポーネントによって各特徴列のスコアが計算されます。 列は、特徴スコアによってランク順に返されます。
適切な特徴を選択することで、分類の精度と効率が向上する可能性があります。
予測モデルを構築するには、通常はスコアが最適な列のみを使用します。 特徴選択スコアが低い列はデータセットに残しておくことができ、モデルの構築時には無視できます。
特徴選択メトリックを選択する方法
フィルターに基づく特徴選択コンポーネントには、各列の情報値を評価するためのさまざまなメトリックが用意されています。 このセクションでは、各メトリックの一般的な説明と、その適用方法について説明します。 各メトリックを使用するための追加要件については、「テクニカル ノート」と、各コンポーネントを構成するための手順を参照してください。
ピアソンの相関
ピアソンの相関統計 (ピアソンの相関係数) は、
r値としての統計モデルでも知られています。 任意の 2 つの変数に対して、相関関係の強度を示す値を返します。ピアソンの相関係数は、2 つの変数の共分散を求め、その標準偏差の積で割ることによって計算されます。 2 つの変数の尺度の変更は係数に影響しません。
カイ二乗
双方向カイ二乗検定は、期待値が実際の結果にどれだけ近いかを測定する統計的手法です。 この手法は、変数がランダムであり、独立変数の適切な標本から抽出されることを前提としています。 結果として得られるカイ二乗統計は、期待される (ランダムな) 結果からどの程度遠いかを示します。
ヒント
カスタムの特徴選択手法に別のオプションが必要な場合は、R スクリプトの実行コンポーネントを使用します。
フィルターに基づく特徴選択の構成方法
標準の統計メトリックを選択します。 このコンポーネントでは、列のペア (ラベル列と特徴列) の間の相関関係が計算されます。
フィルターに基づく特徴選択コンポーネントをパイプラインに追加します。 これは、デザイナーの特徴選択カテゴリにあります。
特徴である可能性がある列が少なくとも 2 つ含まれている入力データセットを接続します。
確実に列が分析され、特徴スコアが生成されるように、メタデータの編集コンポーネントを使用して IsFeature 属性を設定します。
重要
入力として指定する列が特徴である可能性があることを確認してください。 たとえば、1 つの値が含まれている列に情報値がないとします。
不適切な特徴になる列がいくつかあることがわかっている場合は、それらを列の選択から削除できます。 また、メタデータの編集コンポーネントを使用して、カテゴリ別としてフラグを付けることもできます。
特徴スコア付けの方法の場合は、スコアの計算に使用する次のいずれかの統計手法を選択します。
Method 必要条件 ピアソンの相関 ラベルはテキストまたは数値にできます。 特徴は数値でなければなりません。 カイ二乗 ラベルと特徴はテキストまたは数値にできます。 2 つのカテゴリ列の特徴の重要度を計算するには、この手法を使用します。 ヒント
選択したメトリックを変更すると、その他すべての選択がリセットされます。 そのため、このオプションは必ず最初に設定してください。
[Operate on feature columns only](特徴列のみを処理) オプションを選択すると、以前に特徴としてマークされた列に対してのみスコアが生成されます。
このオプションをオフにすると、コンポーネントによって、それ以外で条件を満たしている任意の列 (最大で [Number of desired features](目的の特徴の数) で指定された列の数まで) に対してスコアが作成されます。
[Target column](ターゲット列) では、 [Launch column selector](列セレクターの起動) を選択して、名前またはインデックスのいずれかでラベル列を選択します (インデックスは 1 から始まります)。
ラベル列は、統計的相関に関わるすべての手法で必要です。 ラベル列を選択しない場合や複数のラベル列を選択した場合は、コンポーネントがデザイン時エラーを返します。[Number of desired features](目的の特徴の数) には、結果として返される特徴列の数を入力します。
指定できる特徴の最小数は 1 ですが、この値を大きくすることをお勧めします。
指定された目的の特徴の数がデータセット内の列数よりも大きい場合は、すべての特徴が返されます。 スコアがゼロの特徴であっても返されます。
特徴列よりも少ない数の結果列を指定した場合、特徴は降順のスコアによって順位付けされます。 返されるのは、上位の特徴のみです。
パイプラインを送信します。
重要
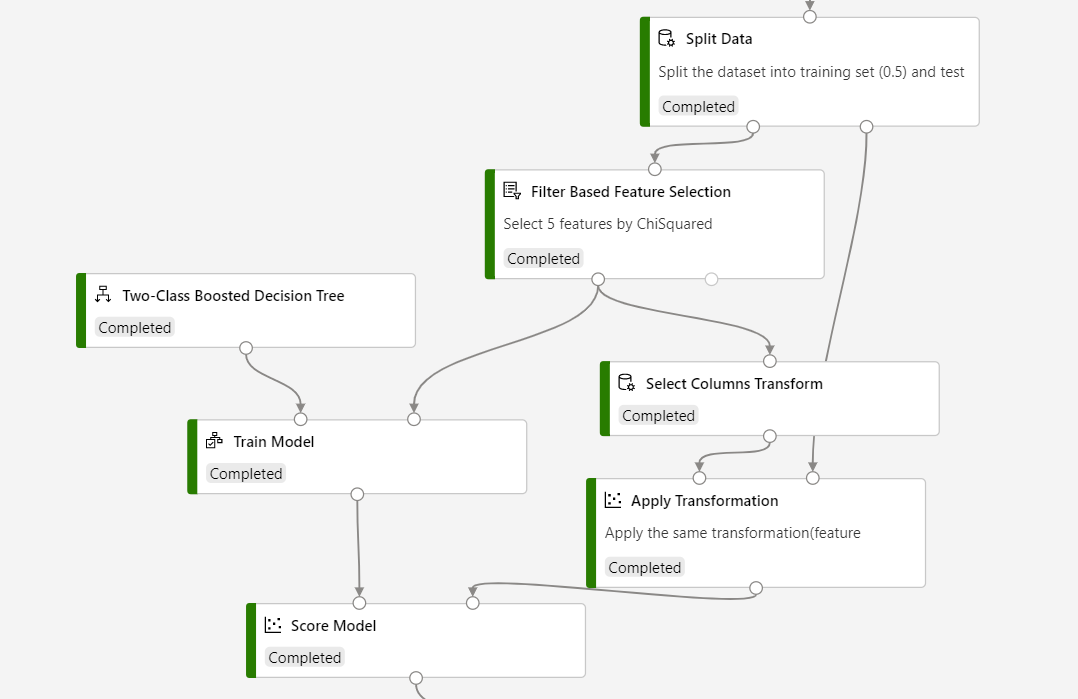
推論で Filter Based Feature Selection (フィルターに基づく特徴選択) を使用する場合、Select Columns Transform (列変換の選択) を使用して特徴が選択された結果を格納し、Apply Transformation (変換の適用) を使用して特徴が選択された変換をスコア付け用データセットに適用する必要があります。
次のスクリーンショットを参照してパイプラインを構築し、スコア付けプロセスで列の選択が同じであることを確認します。
結果
処理の完了後は、次の操作を実行します。
分析された特徴列とそのスコアの完全な一覧を表示するには、コンポーネントを右クリックして [可視化] を選択します。
特徴選択条件に基づいたデータセットを表示するには、コンポーネントを右クリックして [可視化] を選択します。
データセットに含まれる列の数が予想よりも少ない場合は、コンポーネントの設定を確認します。 また、入力として指定された列のデータ型も確認します。 たとえば、 [Number of desired features](目的の特徴の数) を 1 に設定した場合、出力データセットには、ラベル列と最も高いランクの特徴列の 2 つの列のみが含まれます。
テクニカル ノート
実装の詳細
数値の特徴とカテゴリ ラベルにピアソンの相関を使用する場合、特徴スコアは次のように計算されます。
カテゴリ列のレベルごとに、数値列の条件付き平均値を計算します。
条件付き平均値の列と数値列を相関させます。
必要条件
ラベルまたはスコア列として指定されている列に対しては、特徴選択スコアを生成できません。
スコア付けの方法でサポートされていないデータ型の列でその方法を使用しようとすると、このコンポーネントでエラーが発生します。 または、ゼロのスコアが列に割り当てられます。
列に論理 (true/false) 値が含まれている場合、それらは
True = 1およびFalse = 0として処理されます。列は、ラベルまたはスコアとして指定されている場合に特徴にすることができません。
欠損値の処理方法
すべての欠損値を含む列は、ターゲット (ラベル) 列として指定できません。
列に欠損値が含まれている場合、コンポーネントでその列のスコアを計算するときに無視されます。
特徴列として指定された列にすべての欠損値が含まれている場合は、コンポーネントによってゼロのスコアが割り当てられます。
次の手順
Azure Machine Learning で使用できる一連のコンポーネントを参照してください。