AutoML の予測方法の概要
この記事では、時系列データを準備して予測モデルを構築するために AutoML で使用される方法について説明します。 AutoML で予測モデルをトレーニングする手順と例については、時系列予測用に AutoML を設定するの記事を参照してください。
AutoML では、複数の方法を使用して時系列値を予測します。 これらの方法は、大まかに 2 つのカテゴリに分類できます。
- ターゲット数量の履歴値を使用して将来の予測を行う時系列モデル。
- 予測変数を使用してターゲットの値を予測する回帰 (説明) モデル。
例として、食料品店の特定ブランドのオレンジ ジュースの毎日の需要を予測する問題を考えてみましょう。 $t$ 日におけるこのブランドの需要を $y_t$ とします。 時系列モデルは、次の過去の需要の関数を使用して、$t+1$ で需要を予測します。
$y_{t+1} = f(y_t, y_{t-1}, \ldots, y_{t-s})$。
関数 $f$ には、多くの場合、過去に観測された需要を使用して調整するパラメーターが含まれます。 $f$ が予測に使用する過去の量 ($s$) は、モデルのパラメーターと見なすこともできます。
オレンジジュースの需要の例では、過去の需要に関する情報のみが使用されるため、時系列モデルの精度が十分でない可能性があります。 価格、曜日、休日かどうかなど、将来の需要に影響を与える可能性がある要因は他にもたくさんあります。 次の予測変数を使用する回帰モデルを考えてみましょう。
$y = g(\text{price}, \text{day of week}, \text{holiday})$
繰り返しになりますが、$g$ には通常、正則化を制御するパラメーターを含む一連のパラメーターがあります。これらは、需要と予測子の過去の値を使用して AutoML によって調整されます。 式から $t$ を省略して、回帰モデルが "同時に" 定義された変数間の相関パターンを使用して予測を行っていることを強調します。 つまり、$g$ から $y_{t+1}$ を予測するには、$t+1$ が何曜日に当たるか、休日かどうか、$t +1$ 日のオレンジ ジュースの価格を知る必要があります。 最初の 2 つの情報は、カレンダーを見ればいつでも簡単に見つけることができます。 通常、小売価格は事前に設定されているため、オレンジ ジュースの価格も 1 日前にわかっている可能性があります。 ただし、10 日先の価格はわからない場合があります。 この回帰の有用性は、どのくらい先の予測が必要か (予測ホライズンとも呼ばれます) と、予測変数の将来の値がどの程度わかっているかによって制限されることを理解することが重要です。
重要
AutoML の予測回帰モデルでは、ユーザーによって提供されるすべての特徴が、将来にわたって (少なくとも予測ホライズンまで) 認識されていることを前提としています。
AutoML の予測回帰モデルを拡張して、ターゲットと予測子の過去の値を使用することもできます。 結果は、時系列モデルと純粋回帰モデルの特性を持つハイブリッド モデルになります。 過去の数量は、回帰における追加の予測変数であり、それらをラグ数量と呼びます。 ラグの "順序" は、値がどれだけ遡ってわかっているかを示します。 たとえば、オレンジ ジュースの需要の例のターゲットで、順序 2 ラグの現在の値は、2 日前から観測されたジュースの需要です。
時系列モデルと回帰モデルのもう 1 つの注目すべき違いは、予測を生成する方法です。 時系列モデルは一般に再帰関係によって定義され、一度に 1 つずつ予測を生成します。 将来にわたって多くの期間を予測するために、予測ホライズンまで反復し、以前の予測をモデルにフィードバックして、必要に応じて次の 1 期間先の予測を生成します。 対照的に、回帰モデルは、ホライズンまでの "すべての" 予測を一度に生成する、いわゆる直接予測です。 再帰モデルは、以前の予測をモデルにフィードバックするときに予測エラーが増えるため、直接予測の方が再帰モデルよりも望ましい場合があります。 ラグ特徴量が含まれている場合、回帰モデルが直接予測として機能できるように、AutoML によってトレーニング データにいくつかの重要な変更が加えられます。 詳細については、ラグ特徴量に関する記事を参照してください。
AutoML でのモデルの予測
次の表に、AutoML に実装されている予測モデルと、それらが属するカテゴリを示します。
各カテゴリのモデルは、組み込むことができるパターンの複雑さ (モデル容量とも呼ばれます) の順で大まかに一覧表示されています。 最後に観測された値を単純に予測する Naive モデルは容量が少ないのに対し、何百万ものチューニング可能なパラメーターを持つディープ ニューラル ネットワークである Temporal Convolutional Network (TCNForecaster) には多くの容量があります。
重要なことに、AutoML には、精度をさらに向上させるために、最もパフォーマンスの高いモデルの重み付けされた組み合わせを作成するアンサンブル モデルも含まれています。 予測には、Caruana のアンサンブル選択アルゴリズムを介して構成と重みが検出されるソフト投票アンサンブルを使用します。
Note
予測モデルのアンサンブルには、次の 2 つの重要な注意事項があります。
- TCN は現在、アンサンブルに含めることはできません。
- AutoML の既定の回帰および分類タスクに含まれている、別のアンサンブル メソッドであるスタック アンサンブルは、AutoML では既定で無効になります。 スタック アンサンブルは、最適なモデル予測にメタモデルを当てはめ、アンサンブルの重みを見つけます。 Microsoft 内のベンチマークでは、この戦略は時系列データに過剰に適合する傾向が強いことがわかりました。 これにより、一般化が不十分になる可能性があるため、スタック アンサンブルは既定で無効になっています。 ただし、AutoML 構成で必要に応じて有効にすることができます。
AutoML でのデータの使用方法
AutoML では、表形式の "ワイド" 形式の時系列データが受け入れられます。つまり、各変数には、対応する独自の列が必要です。 AutoML では、問題を予測するために列のうち 1 つが時間軸である必要があります。 この列は、datetime 型に解析できる必要があります。 最も単純な時系列データ セットは、時刻列と数値のターゲット列で構成されます。 ターゲットは、将来予測しようとする変数です。 この単純なケースでの形式の例を次に示します。
| timestamp | 数量 |
|---|---|
| 2012-01-01 | 100 |
| 2012-01-02 | 97 |
| 2012-01-03 | 106 |
| ... | ... |
| 2013-12-31 | 347 |
より複雑なケースでは、データに時間インデックスと一致する他の列が含まれている場合があります。
| timestamp | SKU | price | アドバタイズ済み | 数量 |
|---|---|---|---|---|
| 2012-01-01 | JUICE1 | 3.5 | 0 | 100 |
| 2012-01-01 | BREAD3 | 5.76 | 0 | 47 |
| 2012-01-02 | JUICE1 | 3.5 | 0 | 97 |
| 2012-01-02 | BREAD3 | 5.5 | 1 | 68 |
| ... | ... | ... | ... | ... |
| 2013-12-31 | JUICE1 | 3.75 | 0 | 347 |
| 2013-12-31 | BREAD3 | 5.7 | 0 | 94 |
この例では、タイムスタンプとターゲット数量に加えて、SKU、小売価格、アイテムがアドバタイズされたかどうかを示すフラグがあります。 このデータセットには明らかに 2 つの系列があります。1 つは JUICE1 SKU 用で、もう 1 つは BREAD3 SKU 用です。SKU 列は、これでグループ化すると、それぞれ 1 つの系列を含む 2 つのグループが得られるため、時系列 ID 列です。 モデルをスイープする前に、AutoML によって入力構成とデータの基本的な検証が行われ、エンジニアリングされた特徴が追加されます。
データの長さの要件
予測モデルをトレーニングするには、十分な量の履歴データが必要です。 このしきい値の数量は、トレーニングの構成によって異なります。 検証データを指定した場合、時系列ごとに必要なトレーニング観測の最小数は、次によって求めます。
$T_{\text{user validation}} = H + \text{max}(l_{\text{max}}, s_{\text{window}}) + 1$
ここで、$H$ は予測期間、$l_{\text{max}}$ は最大ラグ順序、$s_{\text{window}}$ はローリング集計機能のウィンドウ サイズです。 クロス検証を使用している場合、観測値の最小数は次のとおりです。
$T_{\text{CV}} = 2H + (n_{\text{CV}} - 1) n_{\text{step}} + \text{max}(l_{\text{max}}, s_{\text{window}}) + 1$
ここで、$n_{\text{CV}}$ はクロス検証フォールドの数、$n_{\text{step}}$ は CV ステップ サイズ、つまり CV フォールド間のオフセットです。 これらの数式の背後にある基本的なロジックは、時系列ごとに少なくとも 1 つのトレーニング監視期間を常に持つ必要があるということです。これには、ラグやクロス検証分割のためのパディングが含まれます。 予測のクロス検証の詳細については、予測モデルの選択に関する記事を参照してください。
欠落しているデータの処理
AutoML の時系列モデルでは、時間間隔が一定の観測値が必要です。 ここでの一定の間隔には、月単位や年単位の観測など、観測間の日数が異なる場合があります。 モデリングの前に、系列の値に欠落がないこと、"および" 観測値が規則的であることを AutoML で確認する必要があります。 そのため、データが欠落しているケースが 2 つあります。
- 表形式データの一部のセルに値がない
- 時系列の頻度を指定すると、予期される観測値に対応する "行" がない
最初のケースでは、AutoML は一般的な構成可能な手法を使用して欠損値を補完します。
欠落している予期される行の例を次の表に示します。
| timestamp | 数量 |
|---|---|
| 2012-01-01 | 100 |
| 2012-01-03 | 106 |
| 2012-01-04 | 103 |
| ... | ... |
| 2013-12-31 | 347 |
この系列は表面上は毎日の頻度ですが、2012 年 1 月 2 日の観測値がありません。 この場合、AutoML は 2012 年 1 月 2 日のために新しい行を追加してデータの入力を試みます。 その後、quantity 列の新しい値と、データ内の他の列は、他の欠損値と同様に補完されます。 このような観測ギャップを埋めるために、AutoML が系列の頻度を認識している必要があるのは明白です。 この頻度は AutoML によって自動的に検出されますが、必要に応じて、ユーザーが構成で指定することもできます。
欠損値を埋める補完方法は、入力で構成できます。 既定の方法を次の表に示します。
| 列の型 | 既定の補完メソッド |
|---|---|
| 移行先 | 前方埋め込み (最後の観測を繰り越す) |
| 数値特徴量 | 中央値 |
カテゴリ特徴の欠損値は、欠損値に対応する追加のカテゴリを含めることで、数値エンコード中に処理されます。 この場合、補完は暗黙的です。
自動化された特徴エンジニア リング
モデリングの精度を向上させるために、通常は AutoML によってユーザー データに新しい列が追加されます。 エンジニアリングされた特徴には、次のものが含まれます。
| 機能グループ | 既定値/省略可能 |
|---|---|
| 時間インデックスから派生したカレンダー特徴量 (曜日など) | Default |
| 時系列 ID から派生したカテゴリ特徴量 | Default |
| 数値型へのカテゴリ型のエンコード | Default |
| 特定の国または地域に関連付けられている休日のインジケーター特徴量 | オプション |
| ターゲット数量のラグ | オプション |
| 特徴列のラグ | オプション |
| ターゲット数量のローリング ウィンドウの集計 (ローリング平均など) | オプション |
| 季節性の分解 (STL) | オプション |
特徴量化は、ForecastingJob クラスを介して AutoML SDK から、または Azure Machine Learning スタジオ Web インターフェイスから構成できます。
非定常な時系列の検出と処理
時間の経過に伴って平均と分散が変化する時系列を非定常と呼びます。 たとえば、確率的傾向を示す時系列は、本質的に非定常です。 これを視覚化するために、次の画像では、全般的に上昇傾向にある系列をプロットします。 次に、系列の前半と後半の平均値を計算して比較します。 これらは同じでしょうか? ここで、プロットの前半の系列の平均は、後半よりも大幅に低くなっています。 系列の平均が、見ている時間間隔に依存するという事実は、時系列モーメントの 1 つの例です。 ここで、系列の平均は最初のモーメントです。
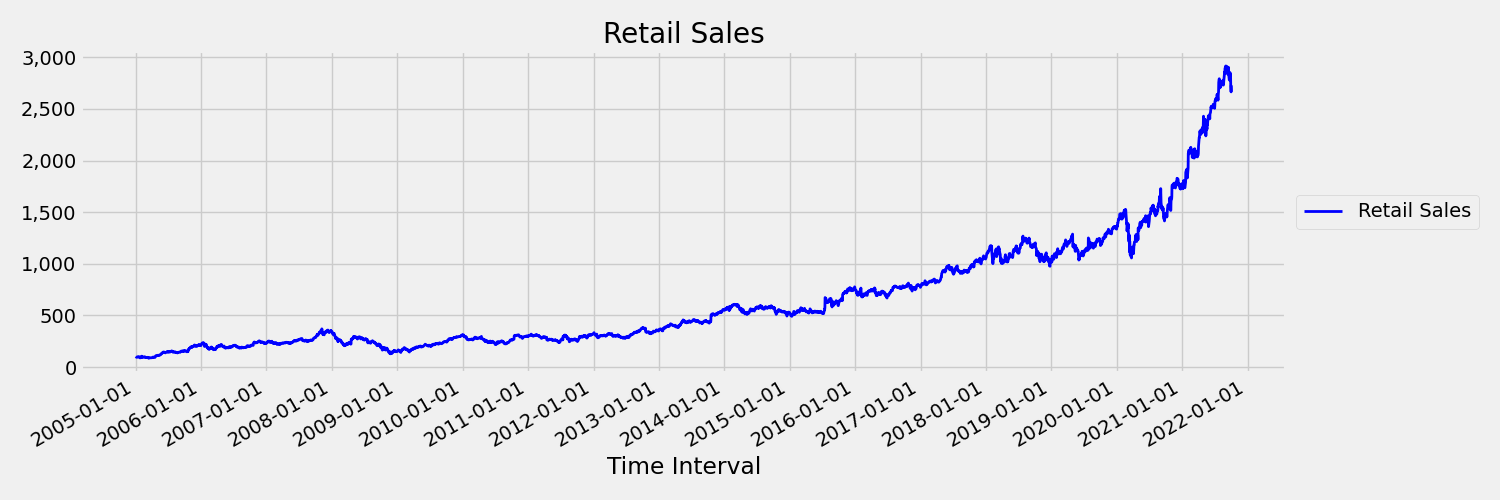
次に、最初の差分 $\Delta y_{t} = y_t - y_{t-1}$ で元の系列をプロットした次の図を見てみましょう。 この系列の平均は時間範囲でほぼ一定ですが、分散は変化しているように見えます。 したがって、これは first order 定常時系列の例です。
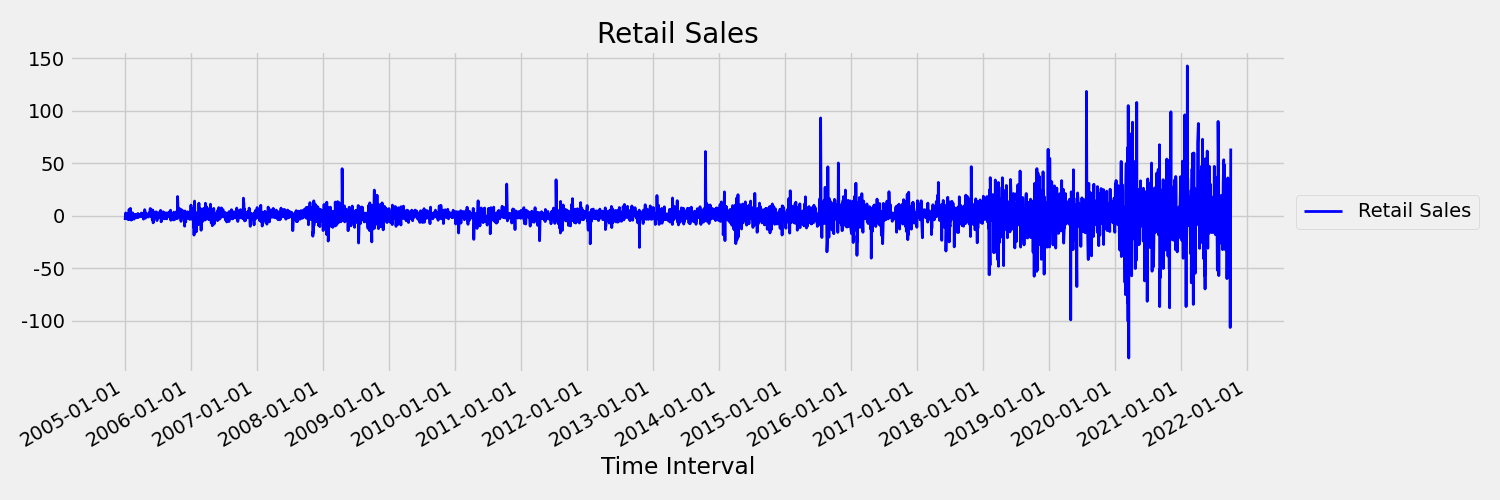
AutoML 回帰モデルでは、本質的に、確率的傾向や、非定常時系列に関連するその他の既知の問題に対処することはできません。 その結果、そのような傾向がある場合、サンプル外の予測精度が低くなることがあります。
AutoML では、時系列データセットが自動的に分析され、定常性が判別されます。 非定常時系列が検出されると、非定常の動作の影響を軽減するために、AutoML によって自動的に差分変換が適用されます。
モデルのスイープ
欠損データの処理と特徴量エンジニアリングを使用してデータが準備されると、AutoML はモデル レコメンデーション サービスを使用して一連のモデルとハイパーパラメーターをスイープします。 モデルは検証またはクロス検証のメトリックに基づいてランク付けされ、必要に応じて、上位のモデルをアンサンブル モデルで使用できます。 最適なモデルまたはトレーニング済みモデルのいずれかを検査、ダウンロード、またはデプロイして、必要に応じて予測を生成できます。 詳細については、モデルのスイープと選択に関する記事を参照してください。
モデルのグループ化
与えられたデータ例のように、データセットに複数の時系列が含まれる場合、そのデータをモデル化する方法は複数あります。 たとえば、単純に時系列 ID 列でグループ化し、系列ごとに独立したモデルをトレーニングすることができます。 より一般的な方法は、データをそれぞれ複数の関連する系列を含むグループにパーティション分割し、グループごとにモデルをトレーニングすることです。 AutoML 予測でのモデルのグループ化には、既定で混合アプローチが使用されます。 時系列モデル (および ARIMAX と Prophet) では、1 つのグループに 1 つの系列が割り当てられ、他の回帰モデルではすべての系列が 1 つのグループに割り当てられます。 次の表は、一対一と多対一の 2 つのカテゴリのモデルのグループ化をまとめたものです。
| 独自のグループに各系列 (1:1) | 1 つのグループにすべての系列 (N:1) |
|---|---|
| Naive、Seasonal Naive、Average、Seasonal Average、Exponential Smoothing、ARIMA、ARIMAX、Prophet | Linear SGD、LARS LASSO、Elastic Net、K Nearest Neighbors、Decision Tree、Random Forest、Extremely Randomized Trees、Gradient Boosted Trees、LightGBM、XGBoost、TCNForecaster |
その他の一般的なモデルのグループ化は、AutoML の多数モデル ソリューションで使用できます。多数モデル - 自動 ML ノートブックのページを参照してください。
次のステップ
- AutoML での予測のためのディープ ラーニング モデルについて学習する
- AutoML での予測のためのモデルのスイープと選択の詳細を確認します。
- AutoML でカレンダーから特徴量を作成する方法について確認します。
- AutoML がラグ特徴量を作成する方法について確認します。
- AutoML での予測に関するよくある質問への回答を確認します。