対話型開発時に Azure クラウド ストレージからデータにアクセスする
適用対象:  Python SDK azure-ai-ml v2 (現行)
Python SDK azure-ai-ml v2 (現行)
通常、機械学習プロジェクトは、探索的データ分析 (EDA)、データ前処理 (クリーニング、特徴エンジニアリング) から開始され、仮説を検証するための ML モデルのプロトタイプの構築が含まれます。 プロトタイプ作成プロジェクト フェーズは、本質的に非常に対話型であり、Jupyter ノートブックまたは Python 対話型コンソールを使用した IDE での開発に適しています。 この記事では、以下を行う方法について説明します。
- Azure Machine Learning データストア URI から、ファイル システムであるかのようにデータにアクセスします。
mltablePython ライブラリを使用して、データを Pandas に具体化します。mltablePython ライブラリを使用して、Azure Machine Learning データ資産を Pandas に具体化します。azcopyユーティリティで、明示的なダウンロードを通してデータを具体化します。
前提条件
- Azure Machine Learning ワークスペース。 詳細については、「ポータルまたは Python SDK (v2) を使用して Azure Machine Learning ワークスペースを管理する」を参照してください。
- Azure Machine Learning データストア。 詳細については、「データストアの作成」を参照してください。
ヒント
この記事のガイダンスでは、対話型開発時のデータ アクセスについて説明します。 これは、Python セッションを実行できる任意のホストに適用されます。 これには、ローカル コンピューター、クラウド VM、GitHub Codespace などがあります。Azure Machine Learning コンピューティング インスタンス (フル マネージドで事前に構成されたクラウド ワークステーション) を使用することをお勧めします。 詳細については、「Azure Machine Learning コンピューティング インスタンスの作成」を参照してください。
重要
Python 環境に最新の azure-fsspec および mltable Python ライブラリがインストールされていることを確認します:
pip install -U azureml-fsspec mltable
ファイルシステムのようなデータストア URI からデータにアクセスする
Azure Machine Learning データストアは、Azure 上の既存のストレージ アカウントへの参照です。 データストアを作成して使用することには、次のような利点があります。
- さまざまなストレージの種類 (Blob/Files/ADLS) と対話するための一般的で使いやすい API。
- チームでの運用に役立つデータストアの簡単な検出。
- データにアクセスするための、資格情報ベース (SAS トークンなど) と ID ベース (Microsoft Entra ID またはマネージド ID を使用) の両方のサポート。
- 資格情報ベースのアクセスの場合、接続情報はセキュリティで保護され、スクリプトでのキーの公開を無効にします。
- Studio UI でデータを参照し、データストア URI をコピーして貼り付けます。
データストア URI は Uniform Resource Identifier であり、Azure Storage アカウント上のストレージの場所 (パス) への参照です。 データストア URI の形式は次のとおりです。
# Azure Machine Learning workspace details:
subscription = '<subscription_id>'
resource_group = '<resource_group>'
workspace = '<workspace>'
datastore_name = '<datastore>'
path_on_datastore = '<path>'
# long-form Datastore uri format:
uri = f'azureml://subscriptions/{subscription}/resourcegroups/{resource_group}/workspaces/{workspace}/datastores/{datastore_name}/paths/{path_on_datastore}'.
これらのデータストア URI は、次のファイルシステム仕様 (fsspec) の既知の実装です: ローカル、リモート、および埋め込みファイル システムとバイト ストレージへの統合された Python インターフェイス。
azureml-fsspecパッケージとその依存関係azureml-dataprepパッケージを pip インストールできます。 その後、Azure Machine Learning データストア fsspec 実装を使用できます。
Azure Machine Learning データストア fsspec 実装では、Azure Machine Learning データストアによって使用される資格情報/ID パススルーが自動的に処理されます。 スクリプトでのアカウント キーの公開と、コンピューティング インスタンスでの追加のサインイン手順の両方を回避できます。
たとえば、Pandas でデータストア URI を直接使用できます。 この例では、CSV ファイルを読み取る方法を示します。
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
ヒント
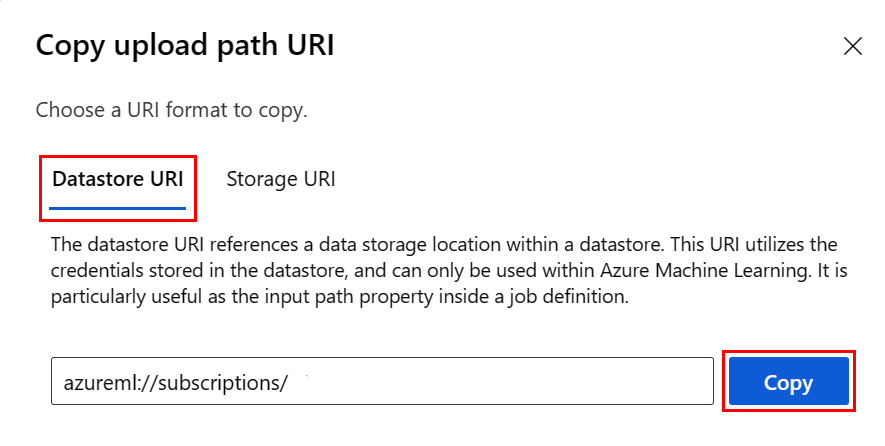
データストア URI 形式を記憶する代わりに、次の手順を使用して、Studio UI からデータストア URI をコピーして貼り付けることができます:
- 左側のメニューから [データ] を、次に [データストア] タブを選択します。
- データストア名を、次に [参照] を選択します。
- Pandas に読み込むファイル/フォルダーを見つけ、その横にある省略符号 (...) を選択します。 メニューから [URI のコピー] を選択します。 ノートブック/スクリプトにコピーするデータストア URI を選択できます。
また、Azure Machine Learning ファイルシステムをインスタンス化し、 ls、glob、exists、open など、ファイルシステムのようなコマンドを処理することもできます。
ls()メソッドは、特定のディレクトリ内のファイルを一覧表示します。 ls()、ls(.)、ls (<<folder_level_1>/<folder_level_2>) を使用してファイルを一覧表示できます。 相対パスでは、'.' と '..' の両方がサポートされています。glob()メソッドは、 '*' および '**' を使用したグロビングをサポートしています。exists()メソッドは、指定したファイルが現在のルート ディレクトリに存在するかどうかを示すブール値を返します。open()メソッドはファイルのようなオブジェクトを返します。これは、Python ファイルとともに動作することを想定している他のライブラリに渡すことができます。 コードでは、通常の Python ファイル オブジェクトであるかのようにこのオブジェクトを使用することもできます。 これらのファイルのようなオブジェクトは、次の例で示すように、withコンテキストの使用を尊重します。
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastore*s*/datastorename')
fs.ls() # list folders/files in datastore 'datastorename'
# output example:
# folder1
# folder2
# file3.csv
# use an open context
with fs.open('./folder1/file1.csv') as f:
# do some process
process_file(f)
AzureMachineLearningFileSystem を使用してファイルをアップロードする
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastorename>/paths/')
# you can specify recursive as False to upload a file
fs.upload(lpath='data/upload_files/crime-spring.csv', rpath='data/fsspec', recursive=False, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
# you need to specify recursive as True to upload a folder
fs.upload(lpath='data/upload_folder/', rpath='data/fsspec_folder', recursive=True, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
lpath はローカル パスで rpath はリモート パスです。
rpath で指定したフォルダーがまだ存在していない場合は、それらのフォルダーが作成されます。
次の 3 つの "上書き" モードがサポートされています。
- APPEND: 宛先パスに同じ名前のファイルが存在する場合、元のファイルが保持されます
- FAIL_ON_FILE_CONFLICT: 宛先パスに同じ名前のファイルが存在する場合、エラーがスローされます
- MERGE_WITH_OVERWRITE: 同じ名前のファイルが宛先パスに存在する場合、その既存のファイルが新しいファイルで上書きされます
AzureMachineLearningFileSystem を使用してファイルをダウンロードする
# you can specify recursive as False to download a file
# downloading overwrite option is determined by local system, and it is MERGE_WITH_OVERWRITE
fs.download(rpath='data/fsspec/crime-spring.csv', lpath='data/download_files/, recursive=False)
# you need to specify recursive as True to download a folder
fs.download(rpath='data/fsspec_folder', lpath='data/download_folder/', recursive=True)
例
これらの例は、一般的なシナリオでのファイルシステム仕様の使用を示しています。
単一の CSV ファイルを Pandas に読み取る
次に示すように、単一の CSV ファイルを Pandas に読み取ることができます:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
CSV ファイルのフォルダーを Pandas に読み取る
Pandas read_csv() メソッドは、CSV ファイルのフォルダーの読み取りをサポートしていません。 csv パスを glob し、Pandas concat() メソッドを使用してデータ フレームに連結する必要があります。 次のコード サンプルは、Azure Machine Learning ファイルシステムでこの連結を実現する方法を示しています:
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append csv files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.csv'):
with fs.open(path) as f:
dflist.append(pd.read_csv(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
Dask への CSV ファイルの読み取り
この例では、CSV ファイルを Dask データ フレームに読み込む方法を示します。
import dask.dd as dd
df = dd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
Parquet ファイルのフォルダーを Pandas に読み取る
Parquet ファイルは通常、ETL プロセスの一部としてフォルダーに書き込まれます。これにより、進行状況、コミットなどの ETL に関連するファイルを出力できます。この例は、データの Parquet ファイルを生成する ETL プロセス (_ で始まるファイル) から作成されたファイルを示します。
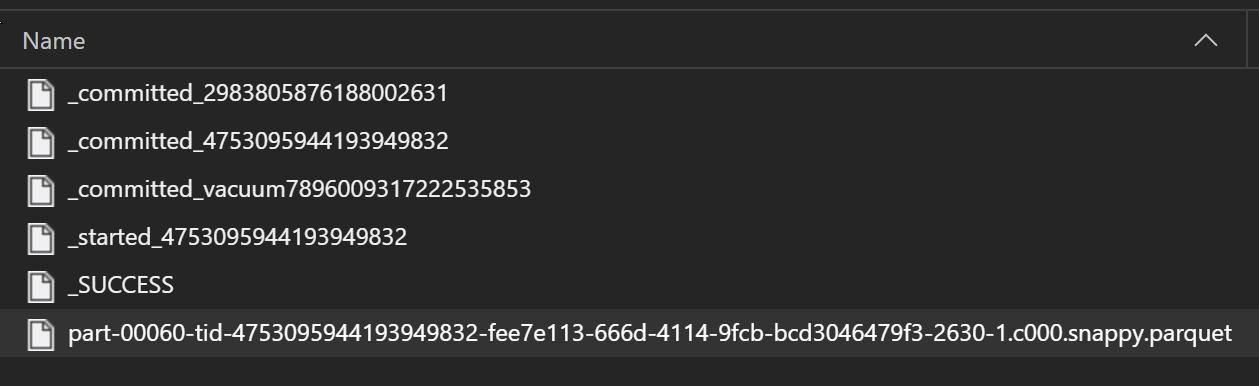
これらのシナリオでは、フォルダー内の Parquet ファイルのみを読み取り、ETL プロセス ファイルを無視します。 このコード サンプルは、glob パターンでフォルダー内の Parquet ファイルのみを読み取る方法を示しています:
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append parquet files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.parquet'):
with fs.open(path) as f:
dflist.append(pd.read_parquet(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
Azure Databricks ファイルシステムからデータにアクセスする (dbfs)
ファイルシステム仕様 (fsspec) にはさまざまな既知の実装があり、これには Databricks Filesystem (dbfs) が含まれます。
dbfs からデータにアクセスするには、次のものが必要です:
- インスタンス名。これは
adb-<some-number>.<two digits>.azuredatabricks.netの形式です。 この値は、Azure Databricks ワークスペースの URL にあります。 - 個人用アクセス トークン (PAT)。PAT の作成の詳細については、「Azure Databricks 個人用アクセス トークンを使用した認証」を参照してください
これらの値を取得したら、PAT トークンのコンピューティング インスタンスに環境変数を作成する必要があります:
export ADB_PAT=<pat_token>
その後、次の例に示すように Pandas のデータにアクセスできます。
import os
import pandas as pd
pat = os.getenv(ADB_PAT)
path_on_dbfs = '<absolute_path_on_dbfs>' # e.g. /folder/subfolder/file.csv
storage_options = {
'instance':'adb-<some-number>.<two digits>.azuredatabricks.net',
'token': pat
}
df = pd.read_csv(f'dbfs://{path_on_dbfs}', storage_options=storage_options)
pillow による画像の読み取り
from PIL import Image
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
with fs.open('/<folder>/<image.jpeg>') as f:
img = Image.open(f)
img.show()
PyTorch カスタム データセットの例
この例では、画像を処理するための PyTorch カスタム データセットを作成します。 この全体的な構造を持つ注釈ファイル (CSV 形式) が存在すると仮定します。
image_path, label
0/image0.png, label0
0/image1.png, label0
1/image2.png, label1
1/image3.png, label1
2/image4.png, label2
2/image5.png, label2
サブフォルダーには、ラベルに従ってこれらのイメージが格納されます:
/
└── 📁images
├── 📁0
│ ├── 📷image0.png
│ └── 📷image1.png
├── 📁1
│ ├── 📷image2.png
│ └── 📷image3.png
└── 📁2
├── 📷image4.png
└── 📷image5.png
カスタム PyTorch Dataset クラスでは、次に示すように、__init__、__len__、__getitem__ の 3 つの関数を実装する必要があります。
import os
import pandas as pd
from PIL import Image
from torch.utils.data import Dataset
class CustomImageDataset(Dataset):
def __init__(self, filesystem, annotations_file, img_dir, transform=None, target_transform=None):
self.fs = filesystem
f = filesystem.open(annotations_file)
self.img_labels = pd.read_csv(f)
f.close()
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
f = self.fs.open(img_path)
image = Image.open(f)
f.close()
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
その後、次に示すようにデータセットをインスタンス化できます:
from azureml.fsspec import AzureMachineLearningFileSystem
from torch.utils.data import DataLoader
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# create the dataset
training_data = CustomImageDataset(
filesystem=fs,
annotations_file='/annotations.csv',
img_dir='/<path_to_images>/'
)
# Prepare your data for training with DataLoaders
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
mltable ライブラリを使用してデータを Pandas に具体化する
mltable ライブラリは、クラウド ストレージ内のデータへのアクセスにも役立ちます。 mltable を使用して Pandas にデータを読み込むには、次の一般的な形式があります。
import mltable
# define a path or folder or pattern
path = {
'file': '<supported_path>'
# alternatives
# 'folder': '<supported_path>'
# 'pattern': '<supported_path>'
}
# create an mltable from paths
tbl = mltable.from_delimited_files(paths=[path])
# alternatives
# tbl = mltable.from_parquet_files(paths=[path])
# tbl = mltable.from_json_lines_files(paths=[path])
# tbl = mltable.from_delta_lake(paths=[path])
# materialize to Pandas
df = tbl.to_pandas_dataframe()
df.head()
サポートされているパス
mltable ライブラリでは、さまざまなパスの種類からの表形式データの読み取りがサポートされています。
| Location | 例 |
|---|---|
| ローカル コンピューター上のパス | ./home/username/data/my_data |
| パブリック HTTP(S) サーバー上のパス | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Azure Storage 上のパス | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path> abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
| 長い形式の Azure Machine Learning データストア | azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<wsname>/datastores/<name>/paths/<path> |
注意
mltable は、Azure Storage と Azure Machine Learning のデータストア上のパスに対してユーザー資格情報パススルーを実行します。 基になるストレージ上のデータに対するアクセス許可がない場合は、データにアクセスできません。
ファイル、フォルダー、glob
mltable では、次のものからの読み取りがサポートされています:
- ファイル - 例:
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-csv.csv - フォルダー - 例:
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/ - glob パターン - 例:
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/*.csv - ファイル、フォルダー、または glob パターンの組み合わせ
mltable が柔軟であるため、ローカル ストレージ リソースとクラウド ストレージ リリースの組み合わせと、ファイル/フォルダー/glob の組み合わせから、1 つのデータフレームにデータを具体化できます。 次に例を示します。
path1 = {
'file': 'abfss://filesystem@account1.dfs.core.windows.net/my-csv.csv'
}
path2 = {
'folder': './home/username/data/my_data'
}
path3 = {
'pattern': 'abfss://filesystem@account2.dfs.core.windows.net/folder/*.csv'
}
tbl = mltable.from_delimited_files(paths=[path1, path2, path3])
サポートされるファイル形式
mltable では、次のファイル形式がサポートされています:
- 区切りテキスト (CSV ファイルなど):
mltable.from_delimited_files(paths=[path]) - Parquet:
mltable.from_parquet_files(paths=[path]) - 差分:
mltable.from_delta_lake(paths=[path]) - JSON 行形式:
mltable.from_json_lines_files(paths=[path])
例
CSV ファイルの読み取り
このコード スニペット内のプレースホルダー (<>) を具体的な詳細で更新します:
import mltable
path = {
'file': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/<file_name>.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
フォルダー内の Parquet ファイルを読み取る
次の例は、mltable で glob パターン (ワイルドカードなど) を使用して、Parquet ファイルのみが読み取られるようにする方法を示しています。
このコード スニペット内のプレースホルダー (<>) を具体的な詳細で更新します:
import mltable
path = {
'pattern': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/*.parquet'
}
tbl = mltable.from_parquet_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
データ資産の読み取り
このセクションでは、Azure Machine Learning データ資産にアクセスして Pandas に読み込む方法を示します。
テーブル資産
Azure Machine Learning (mltable、または V1 TabularDataset) でテーブル資産を以前に作成してある場合は、次のコードを使用してそのテーブル資産を Pandas に読み込むことができます:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
tbl = mltable.load(f'azureml:/{data_asset.id}')
df = tbl.to_pandas_dataframe()
df.head()
ファイル資産
ファイル資産 (CSV ファイルなど) を登録した場合は、次のコードを使用してその資産を Pandas データ フレームに読み込むことができます。
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'file': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
フォルダー資産
フォルダー資産 (uri_folder または V1 FileDataset) (CSV ファイルを含むフォルダーなど) を登録した場合は、次のコードを使用してその資産を Pandas データ フレームに読み込むことができます:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'folder': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Pandas での大きなデータ ボリュームの読み取りと処理に関する注記
ヒント
Pandas は、大規模なデータセットを処理するようには設計されていません。Pandas では、コンピューティング インスタンスのメモリに収まるデータのみを処理できます。
大規模なデータセットの場合は、Azure Machine Learning マネージド Spark を使用することをお勧めします。 これにより、PySpark Pandas API が提供されます。
リモートの非同期ジョブにスケールアップする前に、大規模なデータセットの小さなサブセットに対して迅速に反復処理することができます。 mltable には、take_random_sample メソッドを使用して大きなデータのサンプルを取得するための組み込みの機能が用意されています:
import mltable
path = {
'file': 'https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
# take a random 30% sample of the data
tbl = tbl.take_random_sample(probability=.3)
df = tbl.to_pandas_dataframe()
df.head()
次の操作を使用して、大きなデータのサブセットを取得することもできます:
azcopy ユーティリティを使用したデータのダウンロード
azcopy ユーティリティを使用して、データをホスト (ローカル コンピューター、クラウド VM、Azure Machine Learning コンピューティング インスタンス) のローカル SSD、およびローカル ファイルシステムにダウンロードします。 Azure Machine Learning コンピューティング インスタンスにプレインストールされている azcopy ユーティリティがこれを処理します。 Azure Machine Learning コンピューティング インスタンスまたは Data Science Virtual Machine (DSVM) を使用しない場合、azcopy をインストールすることが必要な場合があります。 詳細については、azcopy を参照してください。
注意事項
コンピューティング インスタンス上の /home/azureuser/cloudfiles/code の場所にデータをダウンロードすることはお勧めしません。 この場所は、データではなく、ノートブックとコードの成果物を格納するように設計されています。 この場所からデータを読み取ると、トレーニング時にかなりのパフォーマンス オーバーヘッドが発生します。 代わりに、計算ノードのローカル SSD である home/azureuser にデータを格納することをお勧めします。
ターミナルを開き、次の例のように新しいディレクトリを作成します:
mkdir /home/azureuser/data
次を使用して azcopy にサインインします:
azcopy login
次に、ストレージ URI を使用してデータをコピーできます
SOURCE=https://<account_name>.blob.core.windows.net/<container>/<path>
DEST=/home/azureuser/data
azcopy cp $SOURCE $DEST