Azure Machine Learning スタジオで責任ある AI ダッシュボードを使用する
Responsible AI ダッシュボードは、登録済みのモデルにリンクされます。 Responsible AI ダッシュボードを表示するには、モデル レジストリに移動し、責任ある AI ダッシュボードを生成した登録済みのモデルを選択します。 次に、[責任ある AI] タブを選択して、生成されたダッシュボードの一覧を表示します。

複数のダッシュボードを構成して、登録済みのモデルにアタッチできます。 それぞれのResponsible AI ダッシュボードには、さまざまな組み合わせのコンポーネント (解釈可能性、エラー分析、原因分析など) をアタッチできます。 次の図は、ダッシュボードのカスタマイズと、その中で生成されたコンポーネントを示しています。 各ダッシュボードでは、ダッシュボード UI 自体でさまざまなコンポーネントを表示したり非表示にしたりすることができます。

ダッシュボードの名前を選択すると、ブラウザーに全画面表示で開きます。 ダッシュボードの一覧に戻る場合は、いつでも [モデル詳細に戻る] を選択できます。

統合されたコンピューティング リソースを使用するすべての機能
Responsible AI ダッシュボードの一部の機能では、動的、オン ザ フライ、リアルタイムの計算が必要です (What-If 分析の場合など)。 コンピューティング リソースをダッシュボードに接続しないと、一部の機能が表示されないことがあります。 コンピューティング リソースに接続すると、次のコンポーネントでResponsible AI ダッシュボードのすべての機能が有効になります。
- エラー分析
- グローバル データ コーホートを任意のコーホートに設定すると、エラー ツリーが無効になるのではなく、更新されます。
- その他のエラーまたはパフォーマンス メトリックの選択がサポートされています。
- エラー ツリー マップをトレーニングするための特徴量のサブセットを選択することがサポートされています。
- リーフ ノードごとに必要なサンプルの最小数とエラー ツリーの深さを変更することがサポートされています。
- 最大 2 つの特微量に対するヒート マップの動的な更新がサポートされています。
- 特徴の重要度
- [個別の特徴量の重要度] タブの個々の条件付き期待値 (ICE) プロットがサポートされています。
- 反事実条件 What-If
- 望ましい結果を出すのに必要な最小限の変化を理解するために、新しい What-If 反事実条件データ ポイントを生成することがサポートされています。
- 原因分析
- 個別のデータ ポイントを選択し、その処理の特徴量を摂動し、サポートされている因果効果の What-If の想定される因果効果の結果を表示します (回帰機械学習シナリオの場合のみ)。
この情報は、次の図に示すように、[情報] アイコンを選択することで、Responsible AI ダッシュボード ページでも確認できます。

Responsible AI ダッシュボードのすべての機能を有効にする
ダッシュボードの上部にある [コンピューティング] ドロップダウン リストで、実行中のコンピューティング インスタンスを選択します。 実行中のコンピューティングがない場合は、ドロップダウンの横にあるプラス記号 (+) を選択して、新しいコンピューティング インスタンスを作成します。 または、[コンピューティングの開始] ボタンを選択して、停止したコンピューティング インスタンスを開始できます。 コンピューティング インスタンスの作成または開始には数分かかる場合があります。

コンピューティングが "実行中" 状態のときに、Responsible AI ダッシュボードではコンピューティング インスタンスへの接続が開始されます。 これを実現するために、選択したコンピューティング インスタンスでターミナル プロセスが作成され、そのターミナルで責任ある AI エンドポイントが開始されます。 現在のターミナル プロセスを表示するには、[ターミナル出力の表示] を選択します。

Responsible AI ダッシュボードがコンピューティング インスタンスに接続されると、緑色のメッセージ バーが表示されます。これでダッシュボードが完全に機能するようになります。

プロセスに時間がかかっていて、責任ある AI ダッシュボードがまだコンピューティング インスタンスに接続されない場合、または赤いエラー メッセージ バーが表示される場合は、責任ある AI エンドポイントの起動に問題が生じています。 [View terminal outputs] (ターミナル出力の表示) を選択し、下にスクロールしてエラー メッセージを確認します。

"コンピューティング インスタンスへの接続に失敗しました" の問題を解決する方法がわからない場合は、右上にある [スマイル] アイコンを選択します。 発生したエラーや問題に関するフィードバックを送信してください。 フィードバック フォームには、スクリーンショットやメール アドレスを含めることができます。




Responsible AI ダッシュボードの UI の概要
Responsible AI ダッシュボードには、機械学習モデルの分析やデータ ドリブンのビジネスの意思決定に役立つ、信頼の高い豊富な視覚化と機能のセットが含まれています。
グローバル コントロール
ダッシュボードの上部で、コーホート (指定された特性を共有するデータ ポイントのサブグループ) を作成して、各コンポーネントの分析に集中できます。 ダッシュボードに現在適用されているコーホートの名前が、常にダッシュボードの左上に表示されます。 ダッシュボードの既定のビューはデータセット全体であり、[すべてのデータ (既定)] というタイトルです。

- コーホートの設定: サイド パネルで各コーホートの詳細を表示および変更できます。
- ダッシュボードの構成: サイド パネルでダッシュボード全体を表示し、レイアウトを変更できます。
- コーホートの切り替え: 別のコーホートを選択し、その統計情報をポップアップ ウィンドウで表示できます。
- 新しいコーホート: 新しいコーホートを作成してダッシュボードに追加できます。
作成、編集、複製、または削除できるコーホートの一覧が表示されたパネルを開くには、[コーホートの設定] を選択します。

以下に基づいてフィルター処理するオプションが表示された新しいパネルを開くには、ダッシュボードの上部または [コーホートの設定] 内の [新しいコーホート] を選択します。
- インデックス: データセット全体の中のデータ ポイントの位置でフィルター処理します。
- データセット: データセット内の特定の特徴量の値でフィルター処理します。
- 予測された Y: モデルによって行われた予測でフィルター処理します。
- True Y: 対象の特徴量の実際の値でフィルター処理します。
- エラー (回帰): エラーでフィルター処理します (または分類結果 (分類): 分類の種類と正確性でフィルター処理します)。
- カテゴリ値: 含める必要がある値の一覧でフィルター処理します。
- 数値: 値に対するブール演算でフィルター処理します (たとえば、年齢が 64 歳未満のデータ ポイントを選択します)。

新しいデータセット コーホートに名前を付け、[フィルターの追加] を選択して使用する各フィルターを追加し、次のいずれかを行うことができます。
- [保存] を選択して、新しいコーホートをコーホートの一覧に保存します。
- [保存して切り替え] を選択して、保存して、すぐにダッシュボードのグローバル コーホートを新しく作成したコーホートに切り替えます。

ダッシュボードで構成済みのコンポーネントの一覧が表示されたパネルを開くには、[ダッシュボードの構成] を選択します。 次の図に示すように、[ごみ箱] アイコンを選択すると、ダッシュボードのコンポーネントを非表示にすることができます。

次の図に示すように、各コンポーネント間の区切り線の青い円形のプラス記号 (+) アイコンを使用して、コンポーネントをダッシュボードに追加し直すことができます。

エラー分析
次のセクションでは、エラー ツリー マップとヒート マップを解釈して使用する方法について説明します。
エラー ツリー マップ
エラー分析コンポーネントの最初のペインはツリー マップです。ここでは、ツリーの視覚化を使用して、モデルのエラーがさまざまなコーホート間でどのように分布しているかを示します。 任意のノードを選択し、エラーが見つかった特徴量の予測パスを確認します。

- ヒート マップ ビュー: エラー分布のヒート マップ視覚化に切り替えます。
- 特徴量の一覧: サイド パネルを使用してヒート マップで使用されている特徴量を変更できます。
- エラー カバレッジ: 選択したノードに集中した、データセット内のすべてのエラーの割合を表示します。
- エラー (回帰) またはエラー率 (分類): 選択したノード内のすべてのデータ ポイントのエラーまたはエラーの割合を表示します。
- ノード: データセットのコーホート (フィルターが適用されている可能性があります)、およびコーホート内のデータ ポイントの合計数に対するエラー数を表します。
- 塗りつぶし線: フィルターに基づいて子コーホートへのデータ ポイントの分布を視覚化します。データ ポイントの数は線の太さで表されます。
- 選択情報: 選択したノードに関する情報がサイド パネルに含まれます。
- 新しいコーホートとして保存する: 指定されたフィルターを使用して新しいコーホートを作成します。
- ベース コーホート内のインスタンス: データセット全体のポイントの合計数と、予測が正しかった、または正しくなかったそれぞれのポイントの数を表示します。
- 選択したコーホート内のインスタンス: 選択したノード内のポイントの合計数と、予測が正しかった、または正しくなかったそれぞれのポイントの数を表示します。
- 予測パス (フィルター): データセット全体に設定されたフィルターを一覧表示して、この小さなコーホートを作成します。
[特徴量の一覧] ボタンを選択してサイド パネルを開き、そこから特定の特徴量でエラー ツリーを再トレーニングできます。

- 特徴量を検索してください: データセット内の特定の特徴量を検索できます。
- 特徴量: データセット内の特徴量の名前を一覧表示します。
- 重要度: 特徴量がエラーとどのように関連しているかに関するガイドライン。 ラベル上の特徴量とエラーの間の相互情報スコアを使用して計算されます。 このスコアを利用して、エラー分析でどの特徴量を選択するかを決定できます。
- チェック マーク: ツリー マップから特徴量を追加または削除できます。
- 最大深度: エラーでトレーニングされたサロゲート ツリーの最大深度。
- リーフの数: エラーでトレーニングされたサロゲート ツリーのリーフの数。
- 1 つのリーフ内の最小サンプル数: 1 つのリーフの作成に必要なデータの最小量。
エラー ヒート マップ
データセット内のエラーの別のビューに切り替えるには、[ヒート マップ] タブを選択します。 1 つまたは多数のヒート マップ セルを選択し、新しいコーホートを作成できます。 1 つのヒート マップを作成するために、最大 2 つの特徴量を選択できます。

- セル: 選択したセルの数を表示します。
- エラー カバレッジ: 選択したセルに集中した、すべてのエラーの割合を表示します。
- エラー率: 選択したセル内のすべてのデータ ポイントのエラーの割合を表示します。
- 軸の特徴量: ヒート マップに表示する特徴量の交差部分を選択します。
- セル: データセットのコーホート (フィルターが適用されています)、およびコーホート内のデータ ポイントの合計数に対するエラーの割合を表します。 青い枠線は選択したセルを示し、赤の濃さはエラーの集中度を表します。
- 予測パス (フィルター): 選択したコーホートごとにデータセット全体に設定されたフィルターを一覧表示します。
モデルの概要と公平性のメトリック
モデルの概要コンポーネントには、モデルを評価するためのパフォーマンスと公平性のメトリックの包括的なセットと、指定された特徴量とデータセット コーホートに沿った主要なパフォーマンスの差異メトリックが用意されています。
データセット コーホート
[データセット コーホート] ペインでは、ユーザーが指定したさまざまなデータセット コーホートのモデル パフォーマンスを比較することで、モデルを調査できます (ダッシュボードの右上にある [コーホートの設定] アイコンを使用してアクセスできます)。

- メトリックの選択に関するヘルプ: テーブルに表示できるモデル パフォーマンス メトリックの詳細が示されたパネルを開くには、このアイコンを選択します。 表示するメトリックを簡単に調整するには、複数選択ドロップダウン リストを使用してパフォーマンス メトリックを選択および選択解除します。
- ヒート マップの表示: オンとオフを切り替えて、テーブル内のヒート マップの視覚化を表示または非表示にします。 ヒート マップのグラデーションは、各列の最小値と最大値の間で正規化された範囲に対応します。
- 各データセット コーホートのメトリックのテーブル: データセット コーホート、各コーホートのサンプル サイズ、各コーホートで選択したモデル パフォーマンス メトリックの列を表示します。
- 個々のメトリックを視覚化した横棒グラフ: 簡単に比較できるように、コーホート全体の平均絶対誤差を表示します。
- メトリック (X 軸) の選択: 横棒グラフに表示するメトリックを選択するには、このボタンを選択します。
- コーホート (Y 軸) の選択: 横棒グラフに表示するコーホートを選択するには、このボタンを選択します。 [特徴量コーホート] の選択は、コンポーネントの [特徴量コーホート] タブで目的の特徴量を最初に指定しない限り無効になる場合があります。
表示する適切なメトリックを選択するのに役立つ、モデル パフォーマンス メトリックとその定義の一覧が表示されたパネルを開くには、[メトリックの選択に関するヘルプ] を選択します。
| 機械学習シナリオ | メトリック |
|---|---|
| 回帰 | 平均絶対誤差、平均二乗誤差、R の 2 乗、平均予測。 |
| 分類 | 正確性、精度、リコール、F1 スコア、擬陽性率、擬陰性率、選択率。 |
特徴コーホート
[特徴量コーホート] ペインでは、ユーザーが指定した機密および非機密性の特徴量 (性別、人種、収入のさまざまなレベルのコーホートのパフォーマンスなど) 間でモデルのパフォーマンスを比較して、モデルを調査できます。

メトリックの選択に関するヘルプ: テーブルに表示できるメトリックの詳細が示されたパネルを開くには、このアイコンを選択します。 表示するメトリックを簡単に調整するには、複数選択ドロップダウンを使用してパフォーマンス メトリックを選択および選択解除します。
特徴量の選択に関するヘルプ: 各特徴量の記述子とビン分割機能を含む、テーブルに表示できる特徴量の詳細が示されたパネルを開くには、このアイコンを選択します (下記参照)。 表示する特徴量を簡単に調整するには、複数選択ドロップダウンを使用して選択および選択解除します。
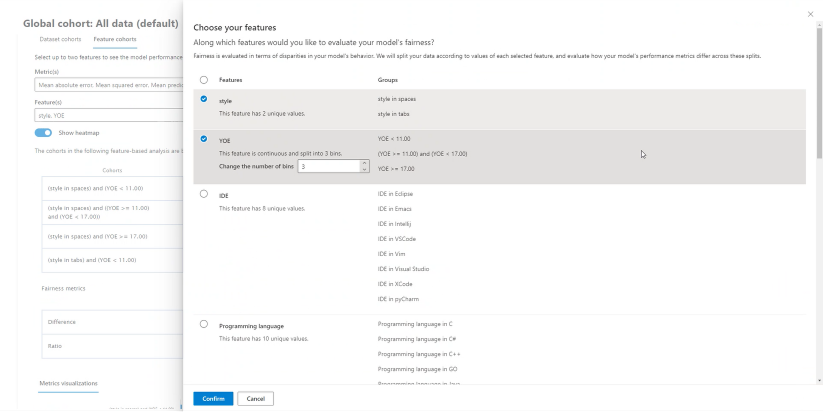
ヒート マップの表示: オンとオフを切り替えて、ヒート マップの視覚化を表示します。 ヒート マップのグラデーションは、各列の最小値と最大値の間で正規化された範囲に対応します。
各特徴量コーホートのメトリックのテーブル: 特徴量コーホート (選択した特徴量のサブコーホート) の列、各コーホートのサンプル サイズ、特徴量コーホートごとに選択されたモデル パフォーマンス メトリックを含むテーブル。
公平性メトリック/不均衡メトリック: メトリック テーブルに対応し、2 つの特徴量コーホート間のパフォーマンス スコアの最大差または最大比率を示すテーブル。
個々のメトリックを視覚化した横棒グラフ: 簡単に比較できるように、コーホート全体の平均絶対誤差を表示します。
コーホート (Y 軸) の選択: 横棒グラフに表示するコーホートを選択するには、このボタンを選択します。
[コーホートの選択] を選択すると、パネルが開き、その下の複数選択ドロップダウン リストで選択する内容に基づいて、選択したデータセット コーホートまたは特徴量コーホートの比較を表示するオプションが表示されます。 [確認] を選択して、横棒グラフ ビューに変更を保存します。
メトリック (X 軸) の選択: 横棒グラフに表示するメトリックを選択するには、このボタンを選択します。


データ分析
データ分析コンポーネントでは、[テーブル ビュー] ペインに、すべての特徴量と行のデータセットのテーブル ビューが表示されます。
[グラフ ビュー] パネルには、データポイントの集計プロットと個々のプロットが表示されます。 予測結果、データセットの特徴量、エラー グループなどのフィルターを使用して、X 軸と Y 軸に沿ってデータ統計情報を分析できます。 このビューは、データセット内の過大表現および過小表現を把握するのに役立ちます。

探索するデータセットのコーホートを選択: コーホートの一覧から、データ統計を表示するデータセットのコーホートを指定します。
X 軸: 横方向にプロットする値の種類を表示します。 値を変更するには、サイド パネルを開くためのボタンを選択します。
Y 軸: 縦方向にプロットする値の種類を表示します。 値を変更するには、サイド パネルを開くためのボタンを選択します。
グラフの種類: グラフの種類を指定します。 集計プロット (横棒グラフ) または個々のデータ ポイント (散布図) を選択します。
[グラフの種類] で [個々のデータ ポイント] オプションを選択すると、色軸を使用できるデータの非集計ビューに移行できます。

特徴量の重要度 (モデルの説明)
モデルの説明コンポーネントを使用すると、モデルの予測で最も重要だった特徴量を確認できます。 [特徴量の重要度集約] ペインでモデルの予測全体に影響を与えた特徴量を表示したり、[個別の特徴量の重要度] ペインで個々のデータ ポイントの特徴量の重要度を表示したりできます。
特徴量の重要度集約 (グローバルな説明)

上位 K の特徴量: 予測で最も重要なグローバル特徴量を一覧表示し、スライダー バーを使用して変更できるようにします。
特徴量の重要度集約: すべての予測にわたってモデルの意思決定に影響を与える、各特徴量の重みを視覚化します。
並べ替え: [特徴量の重要度集約] グラフの並べ替えに使用する、コーホートの重要度を選択できます。
グラフの種類: 各特徴量の平均重要度の棒プロット ビュー、またはすべてのデータの重要度のボックス プロットを選択できます。
棒プロット内の特徴量のいずれかを選択すると、次の図に示すように従属プロットにデータが設定されます。 この従属プロットは、特徴量の値と、モデルの予測に影響を与える、それに対応する特徴量の重要度の値との関係を示します。
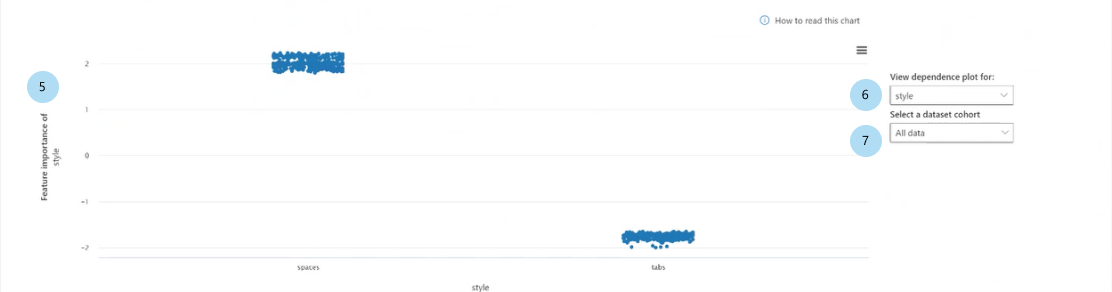
[特徴量] の特徴量の重要度 (回帰) または [予測されたクラス] での [特徴量] の特徴量の重要度 (分類): 予測全体にわたる特定の特徴量の重要度をプロットします。 回帰シナリオでは、重要度の値は出力に関するものであるため、正の特徴量の重要度は、出力に対して肯定的に寄与したことを意味します。 負の特徴量の重要度にはその逆が適用されます。 分類シナリオでは、正の特徴量の重要度は、特徴量の値が Y 軸のタイトルで示されている予測クラスに有利に寄与していることを意味します。 負の特徴量の重要度は、予測クラスに不利に寄与していることを意味します。
従属プロットの表示: 重要度をプロットする特徴量を選択します。
データセットのコーホートを選択: 重要度をプロットするコーホートを選択します。

個別の特徴量の重要度 (ローカルの説明)
次の図は、特定のデータ ポイントに対して行われる予測に特徴量がどのように影響するかを示しています。 特徴量の重要度を比較する対象として最大 5 つのデータ ポイントを選択できます。

ポイント選択テーブル: データ ポイントを表示し、テーブルの下の特徴量の重要度プロットまたは ICE プロットに表示するために最大 5 つのポイントを選択します。

特徴量の重要度プロット: 選択したデータ ポイントでのモデルの予測に対する各特徴量の重要度の棒プロット。
- 上位 K の特徴量: スライダーを使用して重要度を示す特徴量の数を指定できます。
- 並べ替え: 特徴量の重要度プロットに特徴量の重要度を降順で表示する、(上でオンにしたものの) ポイントを選択できます。
- 絶対値の表示: 絶対値で棒プロットを並べ替えるには、オンに切り替えます。 これにより、(方向が肯定的、否定的を問わず) 最も影響の大きい特徴量を確認できます。
- 棒プロット: 選択したデータ ポイントのモデル予測に対するデータセット内の各特徴量の重要度を表示します。
個別条件付き期待値 (ICE) プロット: 特定の特徴量の値の範囲にわたるモデル予測を示す ICE プロットに切り替えます。

- 最小 (数値特徴量): ICE プロット内での予測範囲の下限を指定します。
- 最大 (数値特徴量): ICE プロット内での予測範囲の上限を指定します。
- ステップ (数値特徴量): 間隔内の予測を示すポイントの数を指定します。
- 特徴量の値 (カテゴリ別特徴量): 予測を表示するカテゴリ別特徴量の値を指定します。
- 特徴量: 予測を行う特徴量を指定します。
反事実条件 What-If
反事実分析では、目的の予測クラス (分類) または範囲 (回帰) を生成するために、特徴量の値を最小限に変更して生成されたさまざまな What-If の例のセットが提供されます。

ポイントの選択: 反事実条件を作成するポイントを選択し、下の上位ランクの特徴量プロットに表示します。
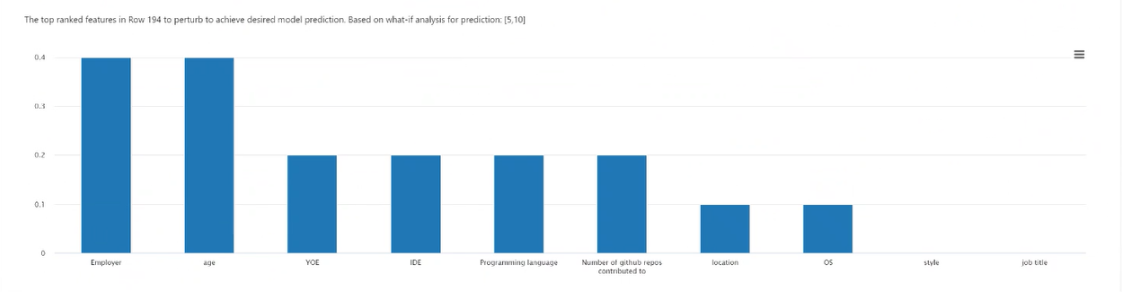
上位ランクの特徴量プロット: 目的のクラスのさまざまな反事実条件セットを作成するために摂動する特徴量を、平均頻度の降順で表示します。 反事実条件の数が少ないと正確性がなくなるため、このグラフを有効にするには、データ ポイントごとに少なくとも 10 個の多様な反事実条件を生成する必要があります。
選択されたデータ ポイント: ドロップダウン メニュー内を除き、テーブルでのポイント選択と同じアクションを実行します。
反事実条件の目的のクラス: 反事実条件を生成するクラスまたは範囲を指定します。
What-if 反事実条件の作成: 反事実条件 What-If データ ポイントを作成するためのパネルが開きます。
ウィンドウ パネル全体を開くには、[What-if 反事実条件の作成] ボタンを選択します。
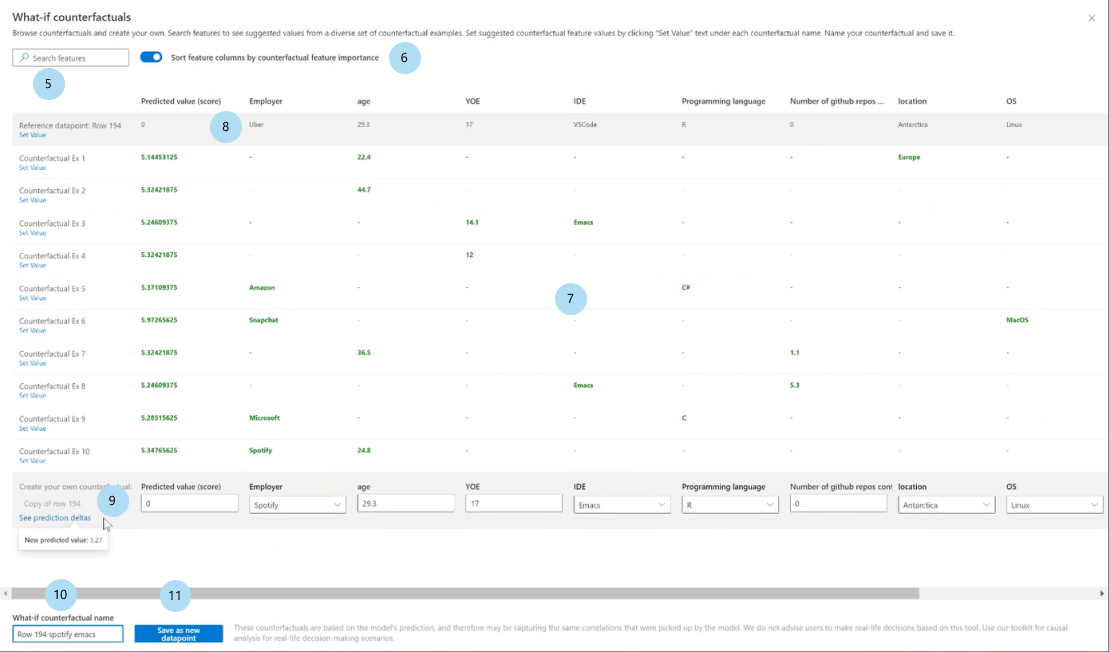
特徴量を検索してください: 値を確認および変更する特徴量を見つけます。
ランク付けされた特徴量で反事実条件を並べ替える: 反事実条件の例を摂動効果の順序で並べ替えます。 (前述の「上位ランクの特徴量プロット」も参照してください)。
反事実条件の例: 目的のクラスまたは範囲を持つ反事実条件の例の特徴量の値を一覧表示します。 最初の行は、元の参照データ ポイントです。 [値の設定] を選択し、生成済みの反事実条件の例の値を使用して、下部の行にある独自の反事実条件データ ポイントのすべての値を設定します。
予測された値またはクラス: これらの変更された特徴量を前提とした、反事実条件のクラスのモデル予測を一覧表示します。
自分自身の反事実条件を作成: 自分自身の特徴量を摂動して反事実条件を変更できます。 元の特徴量の値から変更された特徴量は太字のタイトル (例: 雇用主やプログラミング言語) で示されます。 新しい予測値と元のデータ ポイントとの差を表示するには、[予測の差分を表示] を選択します。
What-if 反事実条件名: 反事実条件に一意の名前を付けることができます。
新しいデータ ポイントとして保存: 作成した反事実条件を保存します。


原因分析
次のセクションでは、特定のユーザー指定の処理に関するデータセットの原因分析を読み取る方法について説明します。
集計因果効果
定義済みの処理の特徴量 (結果を最適化するために処理する特徴量) の平均因果効果を表示するには、原因分析コンポーネントの [集計因果効果] タブを選択します。
注意
原因分析コンポーネントでは、グローバル コーホート機能はサポートされていません。

直接集計因果効果テーブル: データセット全体および関連する信頼度統計で集計された、各特徴量の因果効果を表示します。
- 継続的な処理: このサンプルの平均では、この特徴量を 1 単位増やすと、クラスの確率が X 単位だけ増加します。この場合、X が因果効果です。
- バイナリの処理: このサンプルの平均では、この特徴量をオンにすると、クラスの確率が X 単位だけ増加します。この場合、X が因果効果です。
直接集計因果効果の箱ひげ図: テーブル内のポイントの因果効果と信頼区間を視覚化します。
個別の因果効果と因果効果の What-If
個別のデータ ポイントに対する因果効果の詳細なビューを取得するには、[個別の因果効果の What-If] タブに切り替えます。

- X 軸: X 軸にプロットする特徴量を選択します。
- Y 軸: Y 軸にプロットする特徴量を選択します。
- 個別の因果効果の散布図: テーブル内のポイントを散布図として視覚化して、因果効果の What-If を分析し、個別の因果効果を下に表示するためのデータ ポイントを選択します。
- 新しい処理の値を設定します。
- (数値): 実世界介入として数値特徴量の値を変更するためのスライダーを表示します。
- (カテゴリ別): カテゴリ別特徴量の値を選択するためのドロップダウン リストを表示します。
処理ポリシー
実世界介入を判断するためのビューに切り替えて、特定の結果を達成するために適用する処理を表示するには、[処理ポリシー] タブを選択します。

処理の特徴量の設定: 実世界介入として変更する特徴量を選択します。
推奨されるグローバル処理ポリシー: ターゲットの特徴量の値を改善するために、データ コーホートに対して推奨されている介入を表示します。 テーブルは左から右に読むことができ、データセットのセグメント化は最初に行で、次に列で行われます。 たとえば、雇用主が Snapchat ではなく、プログラミング言語が JavaScript ではない個人が 658 人いるとします。推奨される処理ポリシーは、投稿する GitHub リポジトリの数を増やすことです。
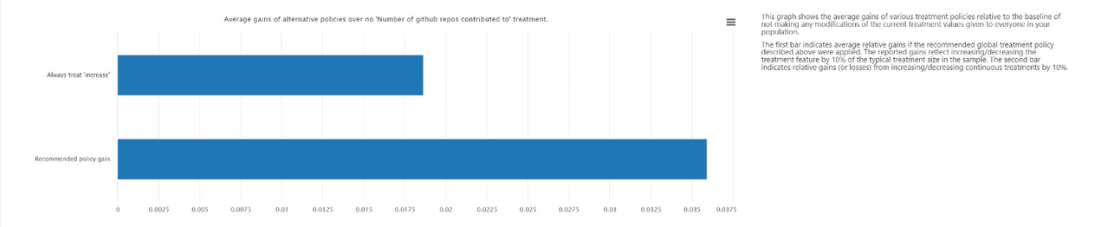
常に処理を適用することに対する代替ポリシーの平均利益: 常に処理を適用する場合に相対させた、上記の推奨処理ポリシーでの結果の平均利益の棒グラフに、ターゲットの特徴量の値をプロットします。
Recommended individual treatment policy (推奨される個人の処理ポリシー):
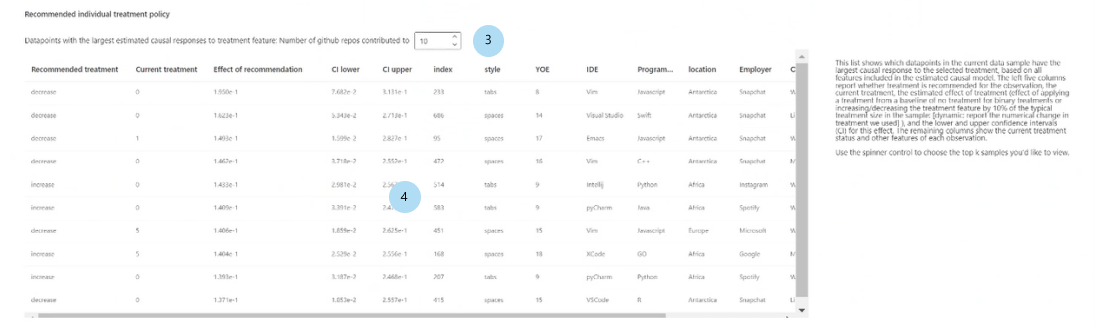
推奨される処理の特徴量の因果効果で順序付けられた上位 K 個のデータ ポイント サンプルを表示する: テーブルに表示するデータ ポイントの数を選択します。
推奨される個人の処理ポリシー テーブル: 介入によってターゲットの特徴量が最も改善されるデータ ポイントを、因果効果の降順で一覧表示します。


次の手順
- PDF エクスポートとしての責任ある AI スコアカードで、責任ある AI の分析情報をまとめて共有します。
- 責任ある AI ダッシュボードの背後にある概念と手法の詳細について確認します。
- サンプル YAML と Python ノートブックを表示して、YAML または Python を使用して責任ある AI ダッシュボードを生成します。
- この対話型 AI ラボ Web デモを使用して、責任ある AI ダッシュボードの機能を確認します。
- 責任ある AI ダッシュボードとスコアカードを使用してデータとモデルをデバッグし、この技術コミュニティのブログ投稿で、より良い意思決定を通知する方法について学習します。
- 実際の顧客事例で、責任ある AI ダッシュボードとスコアカードが英国の国民保健サービス (NHS) によってどのように使用されたかについて学習します。